DevOps 能帮助开发人员开发更高质量的软件。
DevOps 这个术语描述的是经改良的开发团队与运维团队之间的协作。在软件工程中,数据库通常都位于关键路径之中。本文介绍了什么是 DevOps,并且解释了使用了具体概念和工具的数据库 DevOps 是什么样的。
让我们先从软件工程中发生的那些矛盾说起吧。
由于不同目标、过程及工具引发的矛盾
开发团队与运维团队之间经常会有矛盾,主要源于以下原因:
- 不同的目标:开发追求的是在短时间内做更多的变更;而运维追求的则是在生产环境中做更少的变更,从而让系统更稳定
- 不同的流程与概念:开发想要更注重实效的方法;运维则更关注与可重现能力
- 不同的工具:开发使用开发工具;运维使用更适用于生产环境的方法
这些区别往往会造成不同部门间的分歧或各自为阵,下文就会讲到这个话题。
不同的团队
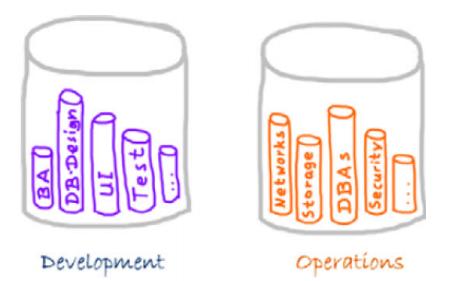
在传统环境下,“开发”这个词主要是指开发团队中的程序员(见图 1)。测试与 QA 也是团队的成员之一,但是他们通常有明确的项目角色,而且他们的工作要等程序员的工作完成后才能开始。
“运维”这个词指的是数据库管理员、系统管理员、网络管理员和其他类型的管理员。他们是把软件部署到生产环境并管理生产基础设施的专家(举例来说,配置并维护服务器和系统)。运维组基本都负责着交付过程中的“最后一英里”。
在一个障碍重重的环境里,两组人都是各自为阵,他们有着自己的优化目标、自己的流程和工具。
软件开发已经很难了;数据库开发就更难了。
关键路径上的数据库
关于日常工作中遇到的数据库开发的困境,让我来举几个具体的例子吧。应用程序开发者会运用持续集成,包括频繁签入和自动化测试,而且他们会经常进行持续部署,将业务应用程序部署到目标环境里。数据库开发者,与此相反,缺乏基本的对真实数据库的版本控制和持续部署。
这个分歧主要是因为应用程序的开发 / 部署与数据库的开发 / 部署之间存在着很大的不同。一般来说,应用程序部署是基于本地文件的,只有签入后才能将本地的变更发布出来。开发者能在本地修改并调试代码,不会干扰其他团队成员的工作。部署则是自动从构建服务器上将可分发的内容复制到对应环境里去。
另一方面,数据库开发经常是基于中心资源的,尽管在很多时候会用到本地开发库或中心数据库中的独立 Schema,通过它们来提供隔离的、高效的工作环境。
除此之外,数据库的部署也不是直接的复制和替换。举例来说,不能简单地删掉数据表随后用新结构重建。通常情况下,不会有两次相同的数据库部署过程,因为源和目标都被改变了,可以是被上次部署改变的,也可以是被新开发的东西改变的。
DevOps 能让软件开发更简单,包括跨越不同的部门,更全面地管理数据库的变更。接下来,让我们更详细地了解一下什么是 DevOps。
DevOps 概述
DevOps 描述了一些让软件交付过程更顺畅的实践,强调让生产到开发的反馈更加顺畅,并缩短生产周期(就是从开始到交付的时间)。DevOps 不仅让你能更快交付软件,还能帮助你开发成质量更高的软件,这更符合个性化需求和基本条件。
DevOps 试图让开发和运维找到一致的目标、概念和工具,通过这些东西(怎么做)让两者的协作更为顺畅(为什么)。
DevOps 能让组织的障碍最小化。“一个团队”的做法,让敏捷实践延伸到了运维中。开发和运维的专家现在都是“开发人员”了,也就意味着正他们紧密协作,在一同“开发”解决方案。
DevOps 针对了多个不同的活动和方面。
多个活动和方面
DevOps 包含了多个活动和方面,例如:
- 文化,这个概念强调人要胜过流程和工具。软件是由人开发,服务于人的。
- 自动化,这是 DevOps 能快速获得反馈的基础。
- 度量,DevOps 找到了明确的度量方法,质量和共同的(起码是对等的)动机是关键。
- 分享,这创造了交换思想、知识和经验的平台。
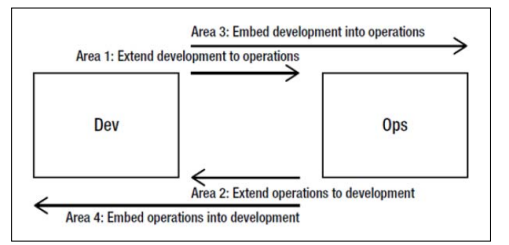
为了定义并带成数据库 DevOps 的概念,最好能分清四个不同的领域。图 2展示了 DevOps 的领域矩阵。领域 1 是将开发延伸到运维中,在数据库方面,常见的例子是将变化脚本放入版本控制系统,并且开发和运维都用相同的数据库迁移工具,比如 Flyway,我们后续会讲到这个工具。
领域 2 是将运维延伸到开发中。对数据库 DevOps 而言,这意味着在生产系统里提供锁定行、阻塞查询和资源竞争等方面的可视化信息。
领域 3 是将开发嵌入到运维中。比如针对非功能性需求设置约束和共同目标。举些例子来说明共同目标,80% 数据库搜索要在 2 秒钟内返回结果显示到屏幕上(共同的性能目标);系统中不能使用任何会妨碍从一个 Linux 发行版迁移到另一个发行版的技术(共同的可移植性目标);数据库要在保持性能目标的前提下,在特定硬件上保存两千万会员信息(共同的容量目标);必须要有针对所有组件的自动化测试,包括基础设施代码(共同的可维护性目标)。
领域 4 是将运维嵌入到开发中。这可以增强两者的协作,比如让开发能够在不牵扯数据库管理员的前提下访问数据,这就能避免 DBA 成为看门人。
数据库 DevOps
拥有一套健壮的数据库变更管理解决方案是应对日常挑战最有效的方法。有了版本控制、持续集成和自动化这样的特性,数据库变更管理让 DBA 和开发能更好地相互沟通与协作,避免潜在的陷阱——意外覆盖、冲突等等,当他们独立工作时很有可能发生此类情况。相应的,这也能让 DevOps 策略带来更大的回报。下面的一些模式能帮助促进 DevOps,尤其是数据库 DevOps。
使用数据库更新脚本。在 DevOps 里,数据库元素应该使用更新脚本自动发布。最好能区别对待数据库扩展脚本(expansion scripts)和收缩脚本(contraction scripts)这两种更新脚本。
扩展脚本涉及的数据库变更在应用时不会破坏数据库对现有应用程序版本的向后兼容性(例如,添加新表或字段这样的元素)。这些脚本可以在升级对应应用程序前的任意时间点运行。
收缩脚本改变了数据库并且会破坏向后兼容性(例如,移除某些结构)。
使用扩展和收缩脚本方便地将数据库迁移从应用程序部署过程中解耦了出来。
自动发布数据库。自动发布数据库时有一个比较高难度的挑战,就是如何将数据库的当前版本(即当前的结构元素,比如表、字段及其数据),也可以说是当前状态,与组成本次完整发布的其他部分的当前版本关联起来。通过把数据库元素纳入版本控制,你可以创建标签(tags,通常也被称为标记 [labels]),把所有配置项添加到一个规定的基线里。
要自动部署数据库变更,就需要有一套流程,它能支持增量应用数据库变更,同时还要保持当前的结构和内容。目前有不少方法都能更新现有数据库,他们都有如下共同的活动:
- 将所有代码和数据库元素(所有变更集)纳入版本控制。
- 创建用于将数据库推进至下一版本和回滚到上一版本的 SQL 脚本。这些脚本要放到一个变更集里。
- 调研一下是否需要回滚机制。可以通过提速开发流程来避免增加复杂性,打补丁(hot fix)也是个不错的策略。
- 针对每个变更集创建一个文件,在里面放置对应的变更内容。给文件一个唯一的名字,其中包含数字编号。变更集推动数据库向前或向后变化,而且变更集都是运用在一个基线上的。因此,一个变更集中的具体内容可能和上一个变更集里的内容是矛盾的,换言之,每个变更集都包含了多条 SQL 语句。为了管好一个特定的变更集,最好用一个文件而非多个文件,这能更好地实施基于任务的开发。
- 打造基线,其中会冻结应用程序的所有配置项,包含数据库元素。
- 为部署获取基线。在完整安装的情况下,要基于数据库元素的初始基线,运行所有增量变更集。在增量安装的情况下,检查特定数据库的当前状态(版本号),运行该版本之后的所有新变更集(之前没有运行过的)。
- 确保部署过程是从版本控制中获取基线的。把数据库变更集放到专门的工作目录里。
- 保存数据库版本。一种方法是使用那些持有元信息的数据表,特别是数据库表结构的版本。此外,还可以为要执行的 SQL 脚本或回滚脚本创建一些字段,这样 Shell 脚本就能使用数据库里保存的信息来执行变更或者回滚。
- 计划通过监控来最小化平均修复时间(MTTR,mean time to repair)、平均检测时间(MTTD,mean time to detect),还要计划执行冒烟测试。
你可以开发自己的解决方案,或者使用像 Flyway 这样的框架。后续的章节里,我们会演示一个例子,在一个完整的构建中使用 Flyway,整合了 Maven、Gradle、Git 和 Hudson。
Flyway,数据库迁移工具
Flyway 是一个能够支持上述理念的数据库迁移工具,既能用于开发也能用于运维。实际上,开发需要写变更集并在测试机上测试部署。Flyway 可以从将 Schema 从任意版本(包括空数据库)迁移到最新版本。它是基于纯 SQL 的,因此开发和运维都能在一起用它进行沟通,而且作为一个解决方案,Flyway 足够轻量化,还很直观。
Flyway 只需要少数几个依赖即可工作,你需要 Java 5 或更高版本,还需要一个 JDBC 驱动。Flayway 运用了惯例优于配置的模式,例如,它能自动通过 Classpath 扫描发现 SQL 迁移内容。它还支持很多不同的数据库,包括 Oracle 10g 及更高版本(所有版本,包括 Oracle Database, Express Edition),和 MySQL 5.1 及更高版本。Oracle 或 MySQL 导出的 DDL(Data Definition Language)文件无需修改即能用于 Flyway。
Flyway 所执行的 Oracle 和 MySQL 脚本都能在 SQL*Plus 和其他 Oracle 兼容工具中执行(在替换了占位符之后)。Flyway 有多种执行方式,包括 Maven 插件、Gradle 或 Ant,它还可以通过命令行来执行。接下来,让我们将注意力集中到 Flyway 的 MySQL 支持上。
Flyway 与 MySQL
Flyway 支持带语句分割符的标准 SQL 语法,包括针对存储过程用 DELIMITER 语句修改过分隔符的 SQL。可以使用mysqldump生成的注释(/!.../;),也可以使用 MySQL 风格的单行注释(# Comment)。
mysqldump导出的 DDL 不用修改就能用在 Flyway 里。Flyway 执行的所有 MySQL SQL 脚本都能在 MySQL 命令行工具和其他 MySQL 兼容工具中执行(在替换了占位符之后,使用占位符能实现参数化调用和配置)。
一个具体的例子
现在来看个具体的例子。让我们从放置迁移脚本的文件夹看起。它们被放置在项目源代码目录的资源文件夹里。
michael@michael-VirtualBox:~/talk/project/devops/src/main/resources/db/migration$
ls -la
total 16
drwxrwxr-x 2 michael michael 4096 Sep 22 11:16 .
drwxrwxr-x 3 michael michael 4096 Sep 22 11:16 ..
-rw-rw-r-- 1 michael michael 112 Sep 18 07:59 V1__Create_person_table.sql
-rw-rw-r-- 1 michael michael 149 Sep 18 07:28 V2__Insert_persons.sql
目前我们有两个 SQL 文件。第一个是V1__Create_person_table.sql。这是个 DDL 文件,内容如下所示。
create table PERSON (
ID int not null auto_increment,
NAME varchar(80) not null,
primary key (ID)
);
第二个文件是 DML(Data Manipulation Language)文件。V2__Insert_persons.sql文件由三条插入语句组成(内容如下所示),向之前创建的数据表中插入了三条数据。
INSERT INTO PERSON (NAME) VALUES ('Peter Meyer');
INSERT INTO PERSON (NAME) VALUES ('Peter Bonnd');
INSERT INTO PERSON (NAME) VALUES ('Klara Korn');
现在再来让我们看一下 Maven POM(Project Object Model),本项目使用的 Maven 构建工具的元信息文件。这个文件定义了如何使用 Flyway,告诉系统要连接的数据库信息,这段逻辑位于一个 Maven Profile 之中。下面是一段相关的代码片段。
<profile>
<id>db</id>
<build>
<plugins>
<plugin>
<groupId>com.googlecode.flyway</groupId>
<artifactId>flyway-maven-plugin</artifactId>
<version>2.1.1</version>
<configuration>
<user>fly</user>
<password>way</password>
<driver>com.mysql.jdbc.Driver</driver>
<url>jdbc:mysql://localhost:3306/mydb</url>
<baseDir>db/migration</baseDir>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.25</version>
</dependency>
</dependencies>
</profile>
现在让我们通过 Maven 来触发 Flyway。我们引入了一个明确的 Profile,我们会激活该 Profile。在这个简单的例子中,迁移本身紧跟在 Maven install 动作之后。请记住,Flyway 使用 Classpath 扫描:迁移脚本必须复制到目标目录(就是 Maven 的 target 目录)中才能被成功应用。Maven 调用是这样的:
clean install flyway:migrate -Pdb
为了让调用更加方便,并且获得其他好处,比如可视化,我们还要使用 Hudson,这是一个持续集成引擎,也可以用在数据库迁移上。我们可以手工触发构建,或者让 Hudson 在观察到版本控制系统中发生变化时自动执行构建,要执行构建只需调用构建脚本就可以了。调用后会有一些控制台输出,内容如下所示。
[INFO] --- flyway-maven-plugin:2.1.1:migrate (default-cli) @ devops ---
[INFO] Creating Metadata table: `mydb`.`schema_version`
[INFO] Current version of schema `mydb`: << Empty Schema >>
[INFO] Migrating schema `mydb` to version 1
[INFO] Migrating schema `mydb` to version 2
[INFO] Successfully applied 2 migrations to schema `mydb` (execution time
00:00.234s).
在我们的例子中,数据库是空的,之前没有执行过迁移。因此 Flyway 做了些初始化的工作(创建元信息,特别是 Schema 的版本号),并触发了我们的两个迁移脚本(因为我们在目录里放了两个 SQL 文件)。
查看一下数据库,现在有了两张新表,都是由 Flyway 创建的:
mysql> show tables;
+——————————————-—+
| Tables_in_mydb |
+———————————————-+
| PERSON |
| schema_version |
+—————————-——————+
2 rows in set (0.01 sec)
一张表是由我们的迁移脚本创建的。另一张包含了数据库及数据库上执行迁移的元信息——包括当前的数据库是什么版本,藉此可以确定在一个特定的环境或者运行里,哪些语句必须执行,哪些又无需执行。
现在让我们简单看下 PERSON 表,其中有三条记录(因为那两个迁移脚本创建了 PERSON 表并插入了三条记录):
mysql> select * from PERSON;
+——-+———————————-+
|ID |NAME |
+——-+———————————-+
| 1 |PeterMeyer |
| 2 |Peter Bonnd |
| 3 |KlaraKorn |
+——-+———————————-+
3 rows in set (0.00 sec)
触发flywayInfo命令执行 Flyway 的报表功能(在命令行或者通过 Hudson),还能获得当前的迁移状态信息。在构建工具 Gradle 中触发 Flyway,使用gradle flywayInfo可以获得如下的输出。
+----------------+----------------------------+---------------------+---------+
| Version | Description | Installed on | State |
+----------------+----------------------------+---------------------+---------+
| 1 | Create person table | 2013-09-19 20:52:32 | Success |
| 2 | Insert persons | 2013-09-19 20:52:32 | Success |
| 3 | InsertUpdate persons | 2013-09-19 20:55:52 | Success |
+----------------+----------------------------+---------------------+---------+
Gradle 是怎么做到这些的?下文是一个 Gradle 构建文件,从功能性角度来看和我们的 Maven POM 很类似。在 Gradle 中,项目和构建信息是用 Groovy 编程语言写的,Groovy 是 Java 虚拟机上的一等公民。同 Maven POM 一样,该文件同样也是版本控制系统中源代码的一部分。
apply plugin: 'java'
apply plugin: 'flyway'
flyway {
user = 'fly'
password = 'way'
driver = 'com.mysql.jdbc.Driver'
url = 'jdbc:mysql://localhost:3306/mydb'
baseDir = 'db/migration'
}
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath "com.googlecode.flyway:flyway-gradle-plugin:2.2"
classpath "mysql:mysql-connector-java:5.1.25"
}
}
repositories {
mavenCentral()
}
dependencies {
testCompile 'junit:junit:4.11'
}
在 Flyway 里,我们可以选择构建工具,用 Maven 或者 Gradle 都行,这很符合我们的需求。
现在让我们再加一个迁移迁移。多加一个文件,我们的第三个迁移脚本,名字是V3__InsertUpdate_persons.sql,其中更新了一条现有记录并创建了一个存储过程,结束时调用了该存储过程向数据表里插入了一条新记录。
UPDATE PERSON SET NAME='Peter Bond' WHERE ID=2;
DROP PROCEDURE IF EXISTS AddPerson;
delimiter //
CREATE PROCEDURE AddPerson (IN myvalue VARCHAR(80))
BEGIN
INSERT INTO PERSON (NAME) VALUES (myvalue);
END //
delimiter ;
CALL AddPerson('Donald Luck');
我们将这个新文件提交并推送到版本控制系统 Git 里。
git add V3__InsertUpdate_persons.sql
git commit -m "change" .
git push
Hudson 检测到了 Git 里的变更,使用构建脚本重新构建了项目,构建脚本同样是受版本控制的(见图 3)。
迁移框架检测到了数据库的当前版本——目前是 (2),得到该信息后就知道新的迁移号是 (3),得到的输出如下所示。
[INFO]
[INFO] --- flyway-maven-plugin:2.1.1:migrate (default-cli) @ devops ---
[INFO] Current version of schema `mydb`: 2
[INFO] Migrating schema `mydb` to version 3
[INFO] Successfully applied 1 migration to schema `mydb` (execution time 00:00.069s).
现在我们的 PERSON 表里有第四条记录了,还更新了一条记录,显然是为了修正上一个版本引入的拼写错误。新的那行是通过调用新写的存储过程来插入的。
mysql> select * from PERSON;
+——-+———————————-+
| ID| NAME |
+——-+———————————-+
| 1 |Peter Meyer |
| 2 |PeterBond |
| 3 |KlaraKorn |
| 4 |DonaldLuck |
+——-+———————————-+
4 rows in set (0.00 sec)
很不错吧!
结论
本文介绍了何为 DevOps,这是一种现代化的开发运维协作方式。通过一致的目标、一致的过程和一致的工具,将不同组织部门之间的障碍降到了最低。
本文还提供了一个具体的例子,演示了某些流程以及像 Hudson、Gradle、Maven 和 Git 这样的工具是如何在日常工作中让不同的利益方共同协作,更快、更高质量地交付软件。
感谢丁雪丰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




