
本文根据贝壳找房资深工程师肖赞老师在 2020 年"面向 AI 技术的工程架构实践"大会上的演讲速记整理而成。
1 贝壳 OLAP 平台架的构演化历程

如上图所示,贝壳 OLAP 平台架构的演化历程大致可以分成三个阶段:
第一个阶段是从 2015 年到 2016 年,Hive to MySQL 的初期阶段,这是一个无到有的阶段;
第二个阶段是从 2016 年到 2019 年初,基于 Kylin 的 OLAP 平台建设阶段,这个阶段围绕着 Apache Kylin 引擎构建 OLAP 平台;
第三个阶段是从 2019 年初到现在,灵活支持多种 OLAP 引擎的 OLAP 平台建设阶段,这个阶段解耦了 OLAP 平台与 Kylin 的强绑定,具备灵活支持 Kylin 之外多种不同 OLAP 引擎的能力;
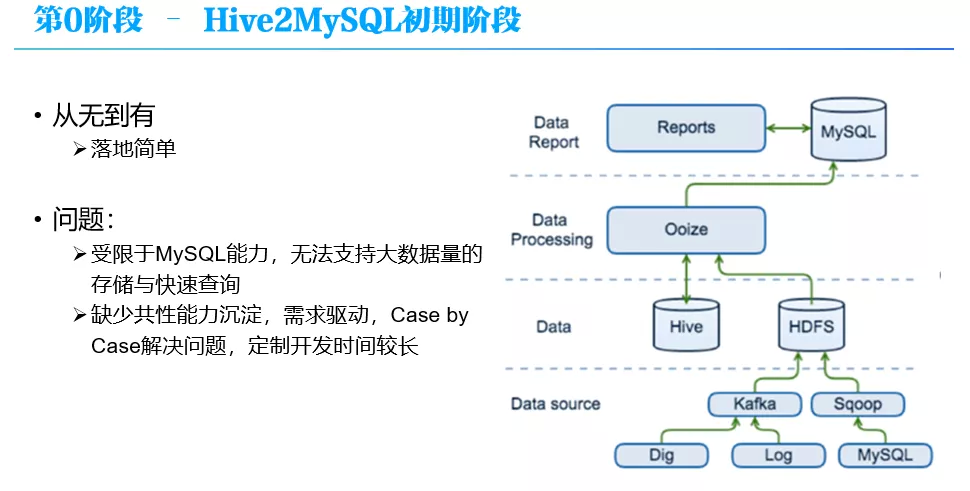
首先是第 0 阶段 - Hive2MySQL 初期阶段
在这个阶段,数据处理流程比较简单,数据包括日志、Dblog 等,经过 Sqoop 批量或 Kafka 实时接入大数据平台 HDFS 里,在大数据平台完成 ETL 处理后,通过大数据调度系统 Ooize 每天定时写入到关系型数据库 MySQL 中,然后再以 MySQL 中的数据为基础产出各种报表。
这是一个从无到有的过程,很多公司初期也都是这么做的。这种方式的优点是简单,很快能够落地跑通,但是问题也很明显:
整个平台受限于 MySQL 的能力,MySQL 无法支持大数据量的快速查询和分析,一般几百万上千万后,MySQL 就难以支撑;
这种方式缺少共性能力的沉淀,Case by Case 的处理用户需求,需求开发时间长;
这也是我们为什么称为第 0 阶段,因为这个阶段平台化工作比较少,严格说还称不上一个平台。
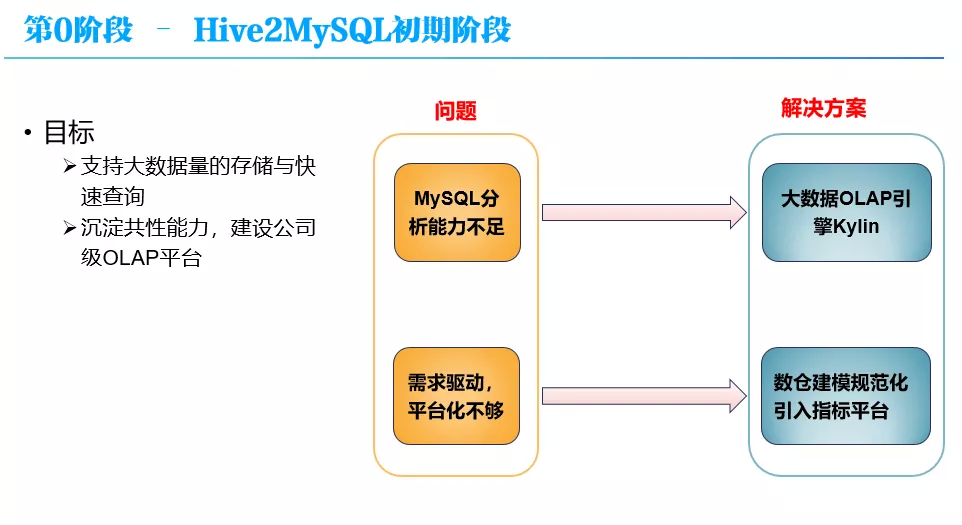
随着公司业务的迅速发展,数据应用需求的急剧增加,Hive2MySQL 的问题逐步突显,对这种原始架构进行升级改造是一个必然的选择。改造的目标很直接,首先解决 MySQL 无法支持海量数据分析查询的问题;第二就是要平台化,沉淀共性能力。
对于第一个问题的话,很直接就是引入一个能够支持大数据量的 OLAP 引擎,这块经过一系列对比调研,选择了 Kylin,对于 Kylin 后面会有介绍;另外,对平台化不够的问题,一方面规范化数仓建模,另一方面引入了一个指标和指标平台,通过指标来向公司各业务线提供数据分析服务。
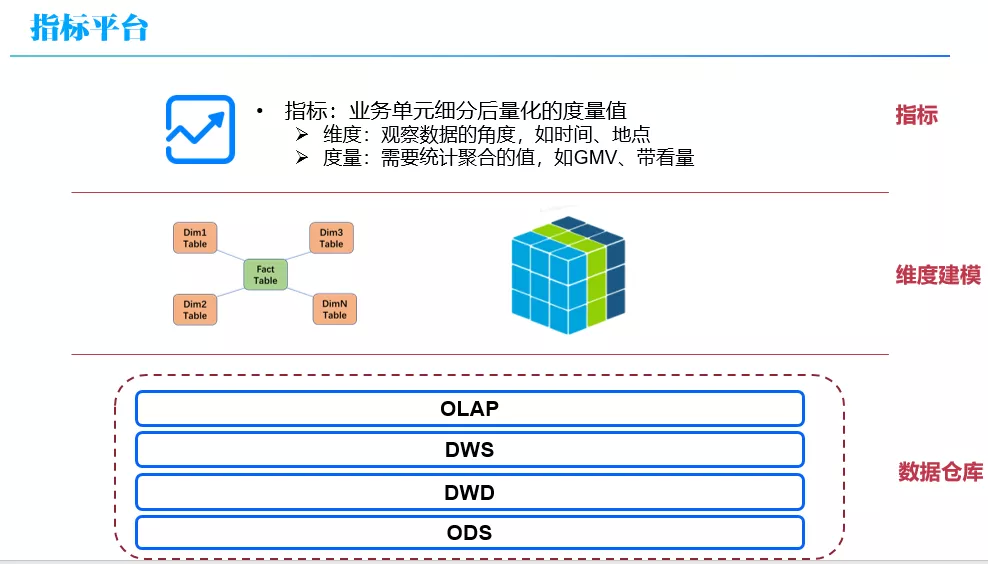
引入指标,一方面有利于业务方更好地与数仓开发人员进行沟通,业务方给出业务层面的指标定义和口径,然后由数仓开发人员转化为底层数仓表和维度模型(星型或雪花), 指标开发完成后业务方使用指标即可,而不是要了解数仓内部技术细节;另外也可以在指标的层面更好的实现复用。
指标是业务单元细分后量化的度量值,包括维度与度量:
维度:观察数据的角度,如时间、地点
度量:需要统计聚合的值,如 GMV、带看量
本质上指标是对维度建模(星型或雪花模型)在业务层的抽象。
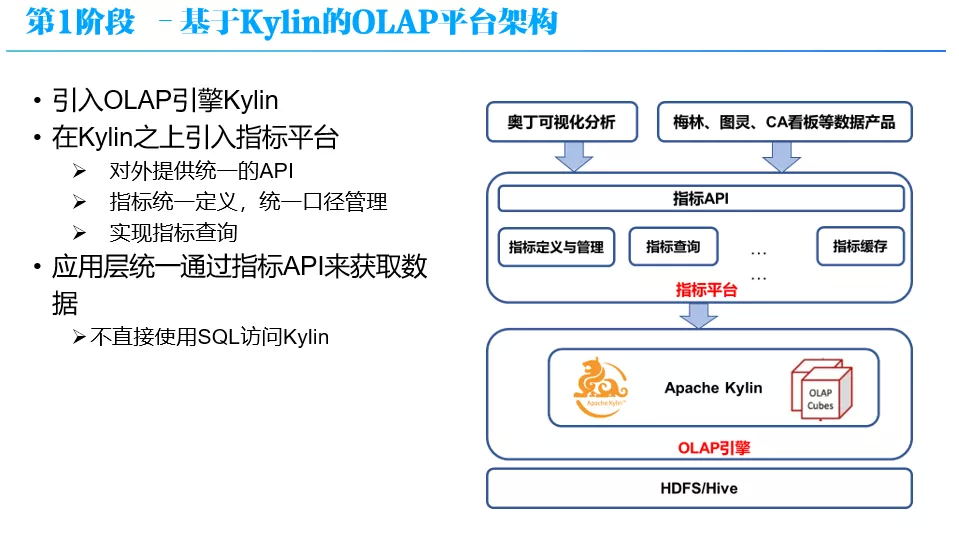
基于前面所述的思考,就有了第 1 阶段 - 基于 Kylin 的 OLAP 平台架构。
OLAP 平台的架构如上图所示,从底向上分为 3 层:OLAP 引擎层,这里就是 Apche Kylin;在 Kylin 之上是指标平台层,它对外提供统一 API、指标统一定义和口径管理,支持指标的查询;在最上面是应用层,就是奥丁(这是贝壳内部的一个数据可视化产品)和各种数据应用产品,它们通过统一的指标 API 来获得数据,不直接使用 SQL 访问 Kylin。另外,Kylin 下面的是数据仓库层,里面有 ODS、DWD、DWS、OLAP 各层数仓表,这里就不仔细介绍了。
下面先介绍一下指标平台层。
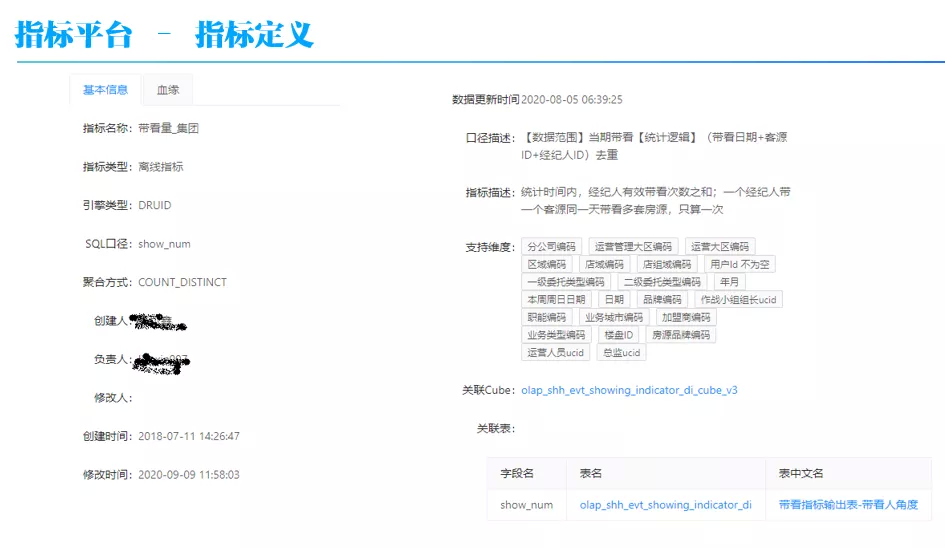
首先,先重点介绍一下指标的概念。在前面提到,指标是指是对维度建模(星型或雪花模型)的抽象,指标包括维度和度量,分别对应维度建模中的度量和维度。在这里给了一个指标平台上具体指标的示例,“带看量_集团”指标,可以看到它的度量是对 show_num 字段 count distinct 排重计数,支持分公司编码、运营管理大区编码、运营大区编码等将近 20 个维度。
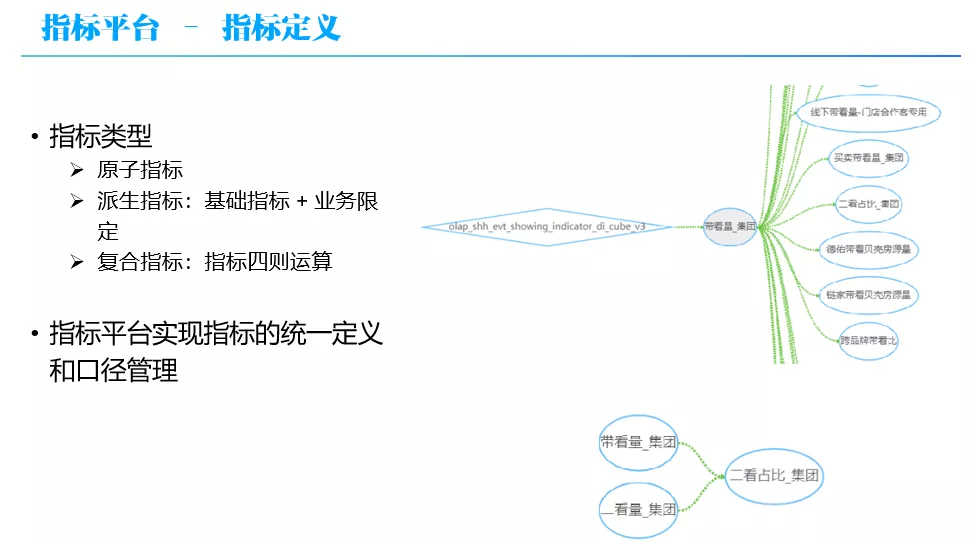
指标的类型可以分为 3 类:
原子指标:指标口径管理
派生指标:基础指标 + 业务限定
复合指标:指标间四则运算
所有的指标的定义和口径都是在指标平台进行管理的。各个业务方都主要通过在 OLAP 平台上定义和使用指标,来实现多维数据分析的。

接下来看一下指标查询,前面有说过,指标平台对外提供统一的 API 来获取指标数据,上图就是一个指标调用参数示例,参数传到指标平台,指标平台会根据调用参数自动转换为 Kylin 查询 SQL,对 Kylin 发起查询,获得数据,并根据需求做进一步处理,例如同环比计算、指标间运算等。上图中左边框架的示例调用参数,将转化成对应的 Kylin SQL,如右框所示。
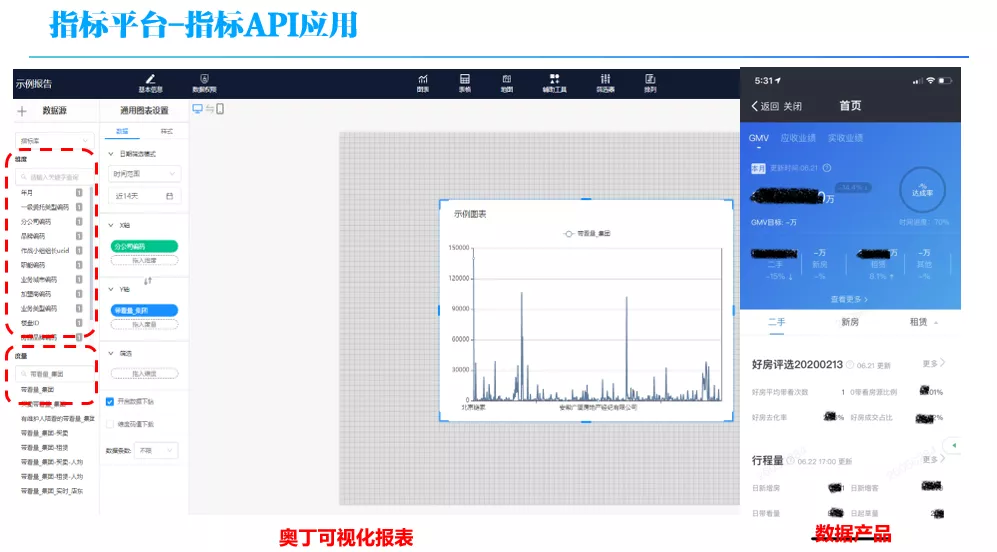
接下来看一下指标的应用,可以在奥丁可视化平台中利用指标配置各种报表,也可以自己开发数据应用产品,在产品里调用指标 API 获取数据。
了解了指标平台后,再看一下 Apache Kylin。
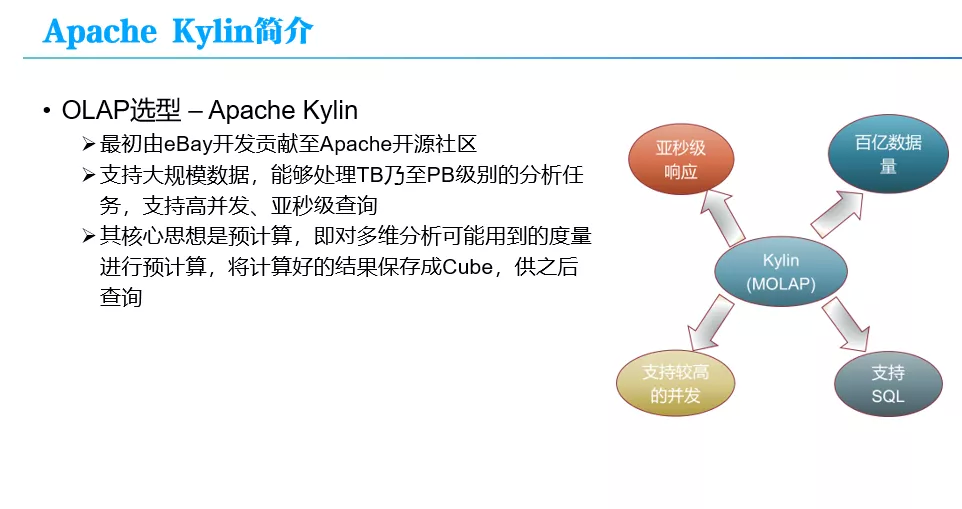
首先,为什么选型 Apache Kylin。其实很简单,就是因为当时 Kylin 对平台的几个诉求,如亚秒级响应、支持百亿数据量、支持较高的并发和支持 SQL 等都有较好的支持。
下面简单的介绍一下 Kylin,它是由中国人主导比较成功的 Apahce 开源项目之一,由国内 Kylingence 公司提供商业服务。
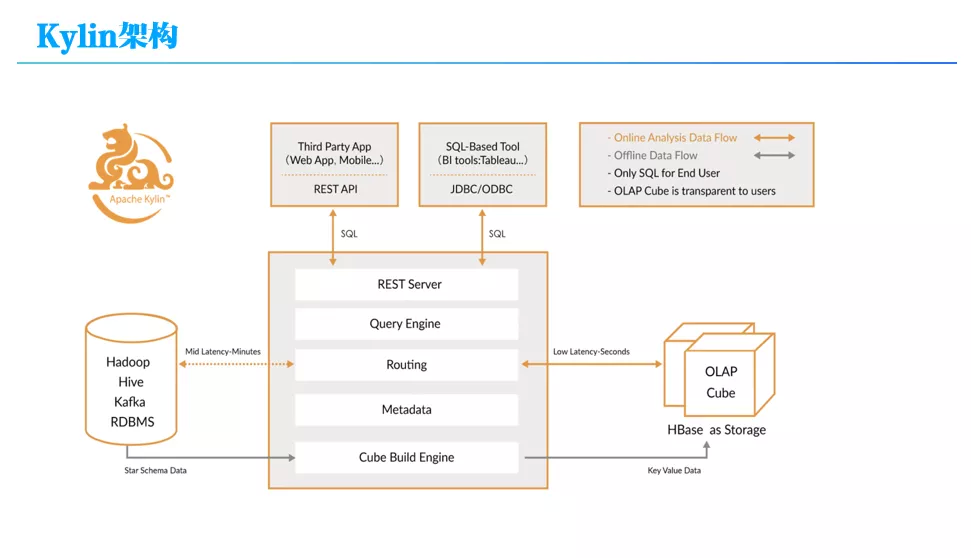
Kylin 的整体架构如上图所示,其核心思想是预计算,对多维分析可能用到的度量进行预计算,用空间换时间。要预算首先需要知道怎么去预计算,也就是需要知道有哪些维度和度量,Kylin 通过要求用户首先定义 Cube 来获得这些信息,Cube 定义支持星型或雪花模型,由 Kylin 的 Metadata 模块管理;
定义完 Cube 后,就通过 Kylin 的 Cube Build Engine 模块来进行预计算构建 Cube,具体可以通过 MR 任务,Spark 或 Flink 来实现,完成预计算后结果就存储在 HBase 中。
最后,用户可以通过 Restful 接口或 JDBC 协议利用 SQL 来查询 Cube 数据,Kylin 的 Query Engine 模块会把 SQL 查询自动转化为对 HBase 的查询。
预计算的一个最大的问题就是“维度爆炸”,也就维度组合太多,Kylin 提供了很多优化技巧来缓解这个问题,例如强制维度、层次维度、联合维度等。
其实 Cube 预计算这种方法并不是 Kylin 发明的,只是 Kylin 基于大数据平台来实现了这一套,使得它可以支持海量的数据,而之前没有大数据平台的支持,基于这种预计算方式的 OLAP 引擎支持的数据量很有限。
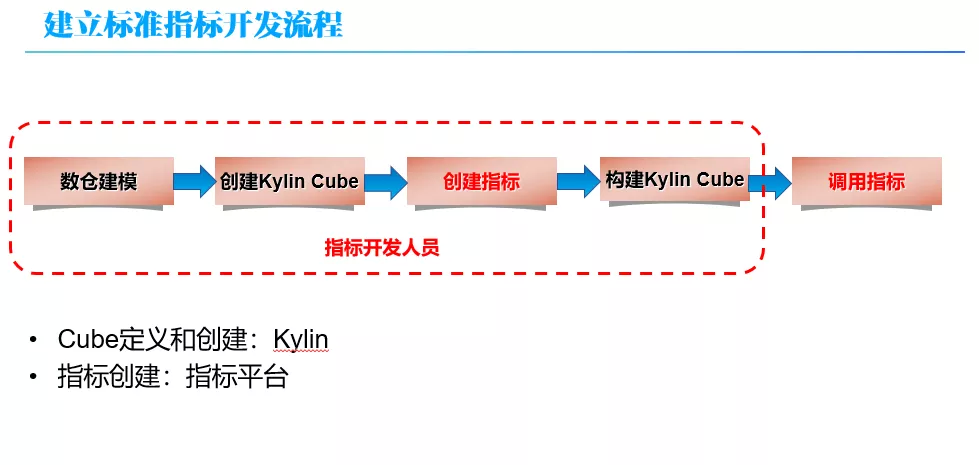
这样,在 OLAP 平台就建立了标准的指标开发流程。整个流程如上图所示。从上面的流程上看:有在 Kylin 中操作的部分,也有在指标平台操作的部分。这也是为什么说是围绕 Kylin 来构建的 OLAP 平台。

经过 2,3 年的推广应用,指标在公司内部获得广泛的应用。支撑公司整个指标体系的建立,覆盖公司所有的业务线:
6600+指标
日均调用量 2000w+
调用 3s 内返回 99.5%

围绕 Kylin 我们也做了很多工作,主要包括 3 个方面:
Kylin 监控管理平台建设:Kylin 承载着许多指标,其中很多是关键指标,一出问题会影响经纪人整个作业等,因此,需要把监控管理构建好,及时发现和解决各种线上问题;
Kylin 优化与定制改造;
Kylin 与公司内部大数据系统的整合:和公司大数据系统、元数据管理平台、调度系统等进行整合;
高峰期 Kylin 平台上有 800 多个 Cube,300 TB 以上的存储量、1600 亿行的数据,单个 Cube 最大有 60 多亿,日均查询有 2000+万。
这块工作公司其他同事进行过多次分享,此处就不再详述,感兴趣可以去了解一下。
那是不是这样就比较完美了?

在指标大量推广使用后,业务方也反馈了许多的问题。简单总结一下,主要包括以下几个方面。
Kylin 支持维度数量有限,而业务方对指标维度数量要求较多,很多指标需要有三、四十个维度,例如上面的示例指标集团带看量就有 20 多个维度;
没法满足业务需求的快速变更,新开发一个指标、变更指标维度都需要比较长的时间;
全量预计算,构建 Cube 时间比较长,导致指标产出时间较晚;
灵活性不够,每次修改 Cube 需回刷 Cube,耗时较长;
性能优化,需要熟悉 HBase 实现细节;
不支持实时指标(Kylin 3.0 引入实时指标支持)
那么,该怎么去解决这些问题?经过仔细分析,可以发现这些很多问题都是 Kylin 本身的原理所决定的,如果只依赖 Kylin 是没法解决的。因此,单一 Kylin 引擎无法满足公司不同业务场景下的应用需求,需要针对不同的业务场景来使用不同的 OLAP 引擎。为了让 OLAP 平台能够支持不同的 OLAP 引擎,OLAP 平台的架构就要做出相应的升级优化。
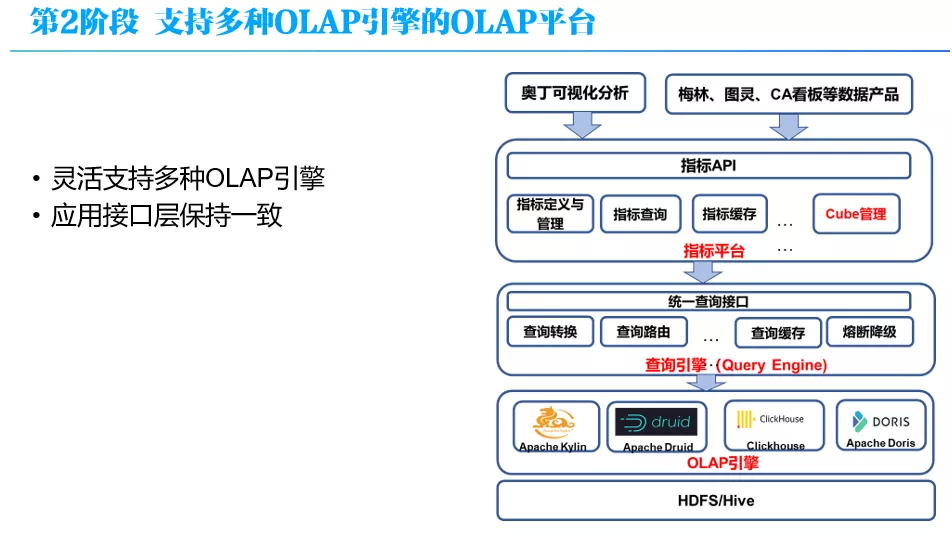
这就到了第 2 阶段- 灵活支持多种 OLAP 引擎的 OLAP 平台
这个阶段 OLAP 平台的架构如上图所示,从底向上分为 4 层:OLAP 层,这里包括 Kylin 等各种引擎,在 OLAP 层之上是查询引擎层,它负责为指标平台屏蔽底层 OLAP 引擎查询接口的差异;再上面是指标平台,它对外提供统一 API、指标统一定义和口径管理,支持指标的查询;在最上面是应用层,就是奥丁(这是我们一个数据可视化产品)和各种数据应用产品,它们通过统一的指标 API 来获得数据,不直接使用 SQL 访问 OLAP。
其中一个关键点就是,由于第 2 阶段中我们引入指标平台,通过指标 API 的方式对上层应用提供服务,这样我们可以在用户透明的情况下,扩展更多的 OLAP 引擎。
下面简单介绍下各层。

首先指标平台层,原来 Cube 管理这些功能是依赖 Kylin 的,现在把这部分抽象到指标平台里,也就将 Cube 定义和管理从 Kylin 解耦到指标平台里:
参考 Kylin、Mondrian 等 Cube 定义
相当于在指标平台和底层 OLAP 引擎之间引入一个抽象层
可将 Cube 动态绑定到不同的 OLAP 引擎

同时引入的查询引擎,它的功能主要包括:
提供统一的数据查询接口(结构化)
屏蔽底层 OLAP 引擎的差异
实现统一查询请求到对应 OLAP 引擎查询的转换
因此指标平台仅需要使用 QueryEngine 的查询接口,不需要关注底层 OLAP 引擎。除此外,QueryEngine 还具备查询优化(把 GroupBy 转 TopN)、缓存、路由、熔断等功能。
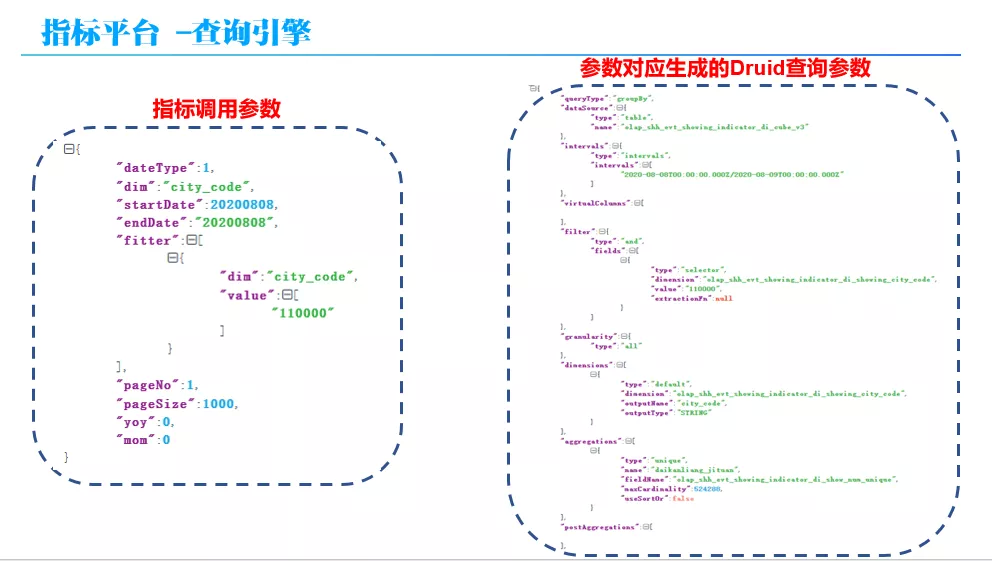
上面的例子,同一个调用参数,查询引擎分别生成的 Kylin SQL 和 Druid native 查询参数,如上图所示。
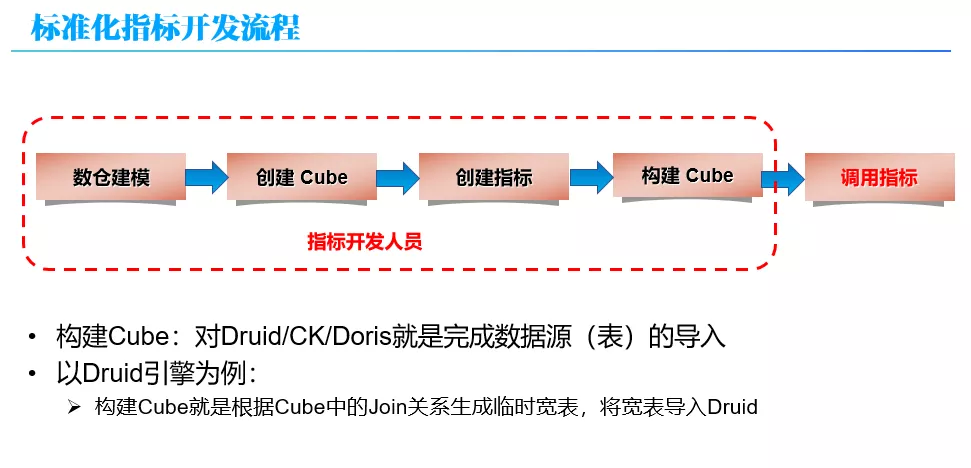
这样的在新的 OLAP 平台上,指标的开发流程如上图所示。所有的步骤都是在指标平台上完成,不再依赖于 Kylin 。同时,构建 Cube 对不同的引擎有不同的含义。例如,对于 Druid 引擎来说,构建 Cube 并不会像 Kylin 一样去枚举维度组合进行预计算,而只是根据 Cube 中的 Join 关系生成临时宽表,并将宽表导入 Druid。
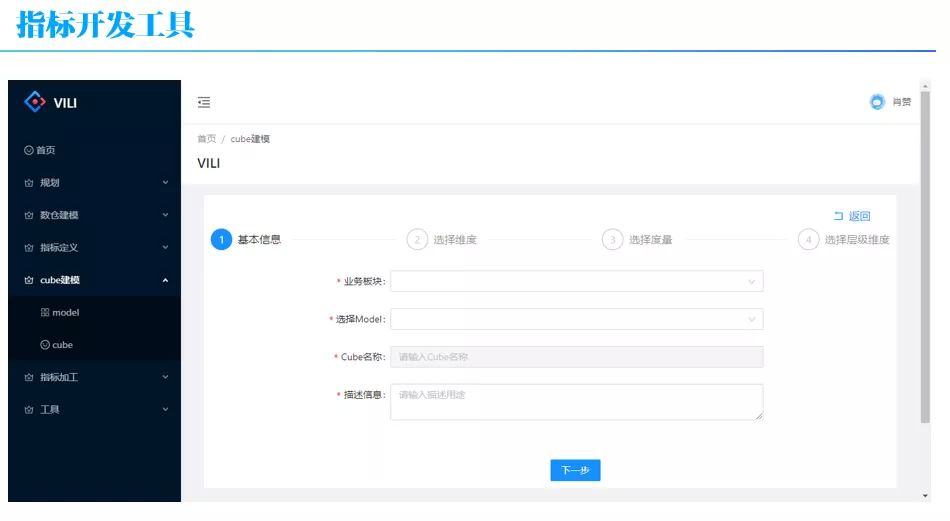
同时,我们开发一个配套的工具来支持多 OLAP 引擎指标的开发,包括指标定义、Cube 建模、指标加工等。
现在 OLAP 平台能够灵活地支持不同的 OLAP 引擎,那该选择哪些 OLAP 引擎?这就到了第 2 部分 OLAP 引擎选型与实践。
2 贝壳 OLAP 引擎选型与实践
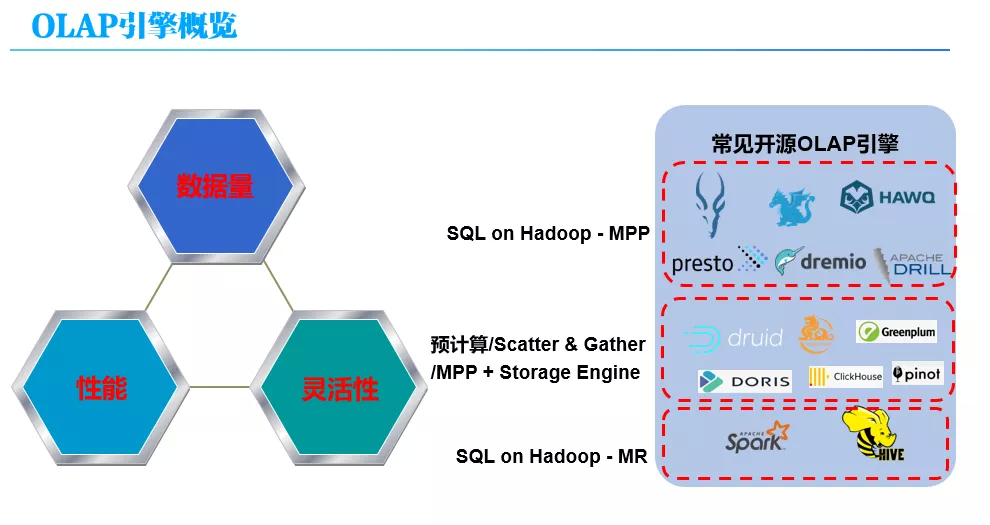
OLAP 选型一般关注三个方面:
数据量:能支持多大量级的数据量,例如 TB 级甚至更大;
查询性能,一是响应时间快不快,是否支持亚秒级响应;二是支持的 QPS,在高 QPS 的情况下整个查询的性能怎么样;
灵活性:灵活性没有具体的标准, OLAP 引擎是否支持 SQL、是否支持实时导入、是否支持实时更新、是否支持实时动态变更等等,这些都是灵活性的体现,具体需要是根据自己的应用需求来确定;
一般认为,目前没有一种开源 OLAP 引擎能够同时满足这三个方面,在 OLAP 引擎选型时,需要在这三个方面之间进行折衷,三选二。
上图中给出了一些常见的开源 OLAP 引擎。目前开源 OLAP 引擎数量比较多,往好的说是百花齐放,但其实也说明了这块很混乱。我们对它们进行了一个大概的分类,分类原则第一是看它的架构原理,MPP 或批处理等;第二看是否有自定义的存储格式,管理自己的数据,即是否存储与计算分离。
首先是 SQL on Hadoop,它又可以分为两类:第一类是 SQL on Hadoop – MPP,基于 MPP 原理实现的引擎,像 Presto、Impala、Drill 等,这类引擎的特点是通过 MPP 的方式去执行 SQL,且不自己管理存储,一般是查 HDFS,支持 Parquet 或 ORC 通用列式存储格式;它可以支持较大的数据量,具有较快的响应时间,但是支持的 QPS 不高,往往具有较好的灵活性,支持 SQL、Join 等;第二类是 SQL on Hadoop – Batch,也就是 Spark SQL 或 Hive,其原理是把 SQLl 转换成 MR 或 Spark 任务执行,可以支持非常大的数据量,灵活性强,对 SQL 支持度高,但是响应时间较长,无法支持亚秒级响应;
另外一类是存储计算不分离,即引擎自己管理存储的,其架构可能基于 MPP 或 Scatter-Gatter 的或预计算的,这类 OLAP 引擎的特点是,可以支持较大的数据量,具有较快的响应时间和较高的 QPS,灵活性方面各 OLAP 不同,各有特点,例如,有些对 SQL 支持较好,有些支持 Join,有些 SQL 支持较差。
了解这些之后,再结合我们的业务需求进行权衡。公司业务方一般对响应时间和 QPS 要求均较高,所以基本只能在自带存储引擎里的类型中选择。Kylin 是已经在用,其他的我们主要关注 了 Druid,Clickhouse 和 Doris,其比较如下图所示。
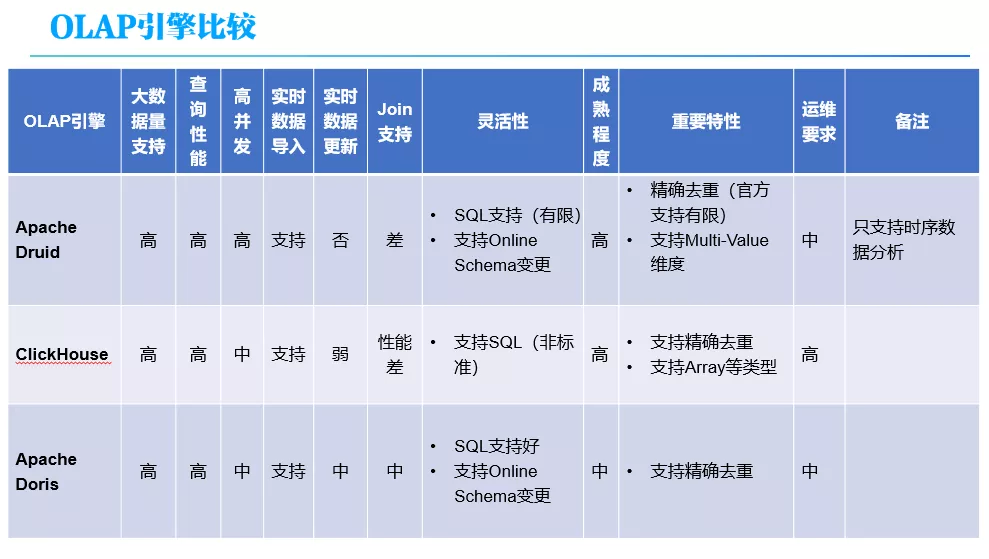
对于数据量和查询性能(包括响应时间和高并发),这几个引擎的支持都是不错的,可以满足公司 TB 级的需求。灵活性关注的几个方面主要包括对 SQL 的支持、实时数据导入、实时更新、Online Schema 变更等特性,这些是在业务需求处理中经常需要用到的特性。
接下来我简单介绍一下这几个引擎以及其在贝壳的应用情况,由于时间有限,将主要介绍 Druid。
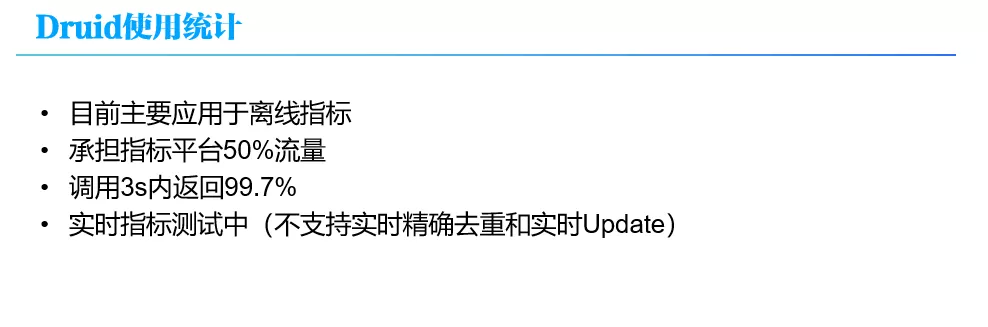
目前 Druid 主要用于离线指标,实时指标还在测试,大概承担了平台 50% 的流量,性能还不错,3s 的返回率大概在 99.7%。
相比于 Kylin,Druid 引擎在 Cube 构建速度和存储空间使用方面均有较大的优势,能够有效解决 Cube 构建时间长,指标产出较晚,和指标变更耗时的问题。
下图给出了以目前在 Druid 平台上访问量 Top 12 的表(Datasource)为对象,对比分析它们在 Kylin 和 Druid 上的数据导入时长和数据膨胀率情况。
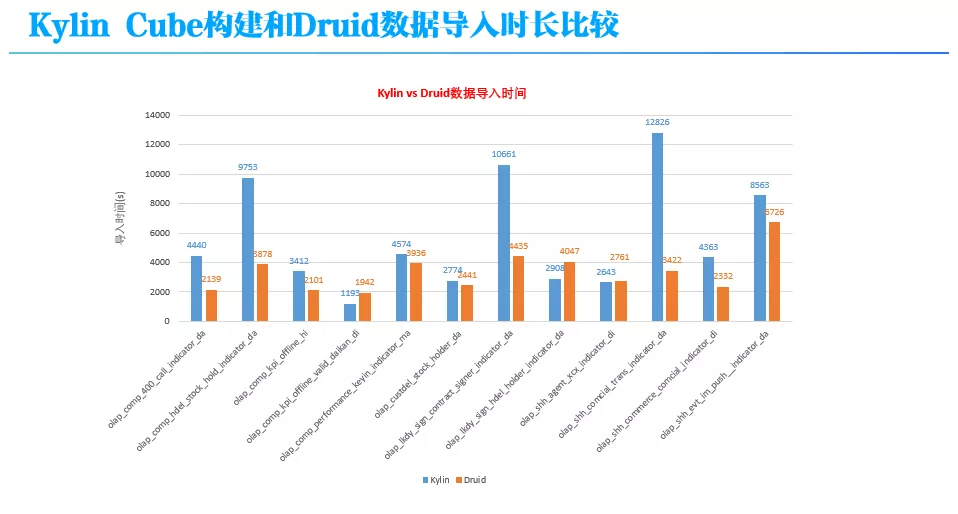
从上图可以看出,大部分表的 Cube 构建时长在 Druid 要比在 Kylin 上快 1 倍以上,而对一些维度多、基数大的表,Kylin 的预计算量巨大,Druid 上的导入时间要比 Kylin 上快 3、4 倍。
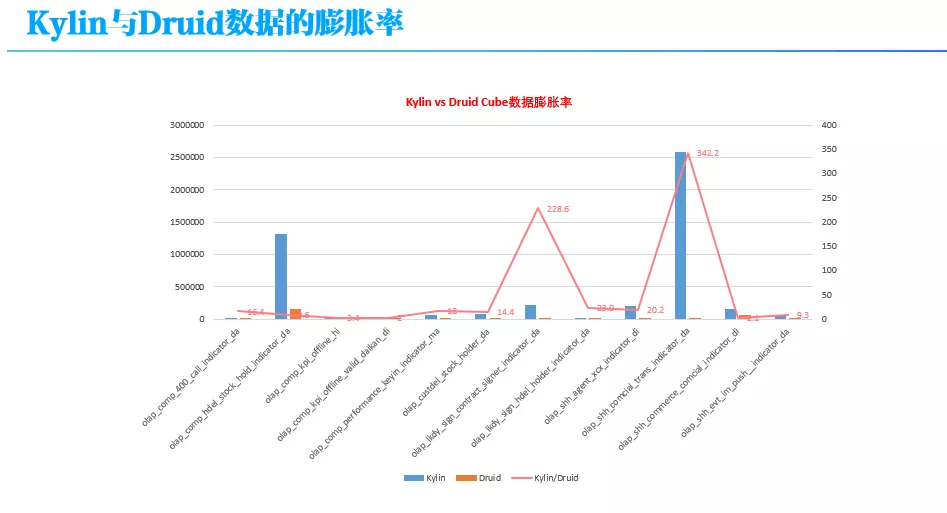
由于 Kylin 的基本原理就是 Cube 预计算,用空间换时间,因此 Kylin 上的数据膨胀率要远大于 Druid。从上图可以看出,对一些维度多、基数大的表,在 Kylin 上的膨胀率和在 Druid 上膨胀率之比高达 342 倍。

与 Kylin 类似,围绕 Druid 引擎我们做了很多工作,也主要包括 3 个方面:
Druid 监控管理平台建设:要能及时发现和解决 Druid 各种线上问题;
Druid 优化与定制改造:精确去重功能支持、大查询监控与处理、数据导入优化、查询优化等;
Druid 与公司内部大数据系统的整合:和公司大数据系统、元数据管理平台、调度系统等进行整合;
这方面工作,由于时间关系,此处不再详述。有机会可以单独交流讨论。

CK 和 Doris 就不过多介绍了,都是基于 MPP 的,有自定义的存储格式。目前主要用于实时指标和明细数据查询,承担了小部分流量,在 1%-2% 左右,现在还在进一步深度测试中。
3 未来工作规划

现在整个 OLAP 平台的基本架构已经确定了,能够支持 Druid、Clickhouse、Doris 等不同引擎,下一步工作将主要包括以下几个方面:
推广应用 Druid、Clickhouse、Doris 等不同引擎,进一步完善各 OLAP 引擎监控管理平台,优化和完善引擎能力;
实现多个 OLAP 引擎的智能路由,能够根据数据量、查询特征(例如 QPS 等)之间做自动/半自动的迁移和路由;
与 Adhoc 平台实现融合,对一些频率高查询慢的查询可以路由到 OLAP 平台上;
进一步完善和优化实时指标支持,目前实时指标只是基本上把整个流程走通了,引入多种 OLAP 引擎后将进一步考虑如何更好的支持实时指标;
我的分享就到这,谢谢大家。
本文转载自公众号贝壳产品技术(ID:beikeTC)。
原文链接:




