编者按:本文由 ArchSummit 大会演讲整理而来。演讲嘉宾是奇虎 360 高级系统工程师王浩宇。奇虎 360 公司是业务驱动型,业务线众多、差异大、迭代周期快,Web 平台部为业务线提供虚拟机、数据库、负载均衡等基础设施资源。运维要帮助公司的业务线兄弟解决很多问题后,产品才能上线,比如:如何帮助业务线快速部署运行环境?业务集群如何快速扩容?集群服务器如何快速切换环境?如何支持业务团队自主定制和操控集群环境。这些都得益于自主设计、开发的一些管理工具和系统,本文与大家分享在这方面的经验。
今天给大家介绍的这一块是在运维开发这一块,是比较聚焦的一个局部,这个局部是关于业务线环境部署这一块。今天的介绍分三部分,第一部分先交代一下场景和我们面临的一些挑战。第二部分是一些对策,第三部分会介绍一些细节。
我干过运维和开发。所以很懂得运维,这个流程肯定都是运维所经历的。
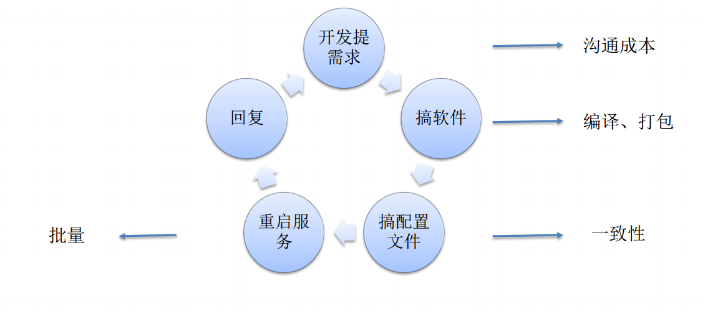
一般开发的同事都会给运维提需求,要求安装一个 OPS,并给一份写好的配置文件,然后给运维部署。运维就去装软件,配置文件,服务还要确保重启,有的时候没启起来还要检查。然后给开发反馈需求已经完成。有一些公司内部有专门的流程管理软件。这个流程简单来说有如图上所示的五步。第一个步骤,沟通成本很大。第二个是软件。软件是不是要打包,肯定是没有现成的软件包直接装,大部分情况下是某个特定的版本。再就是配置文件,比如说一致性问题,最要命的就是批量问题。如果是一台机器,那 OPS 其实就很享受,那每天就管这一台机器就行了,但实际情况肯定不是,机器是成千上万的。所以这几个步骤看着简单,其实其中每一个步骤都非常的消耗。
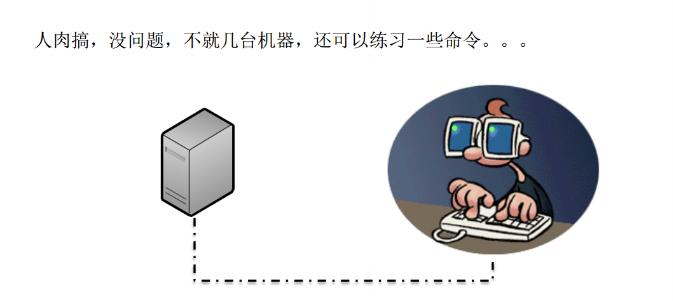
那应该怎么办呢?最原始的方式,是靠人工手动操作,如果现在就三五台机器,那没问题。靠工作人员手工配置还可以练习一些命令。但是当机器多了以后该怎么办呢?肯定不能说跟老板要人,跟老板要人的话那等于说就是堆人肉了。再有如果开发同事让你一天变 N 回,刚才那个流程一天走一次还好,如果一天走一次呢,如果有 N 个开发团队让你一天变 N 次呢,那就是 N×N 了。
再有业务环境如果多种多样,小一点的公司可能非常的单一,但是大一点的公司如 360,环境非常复杂。这些问题一旦抛出来之后,上面的所讲的部署流程就会变的更加复杂。解决批量的问题,可以靠写脚本,咱们做运维的都写过 N 多的脚本,SSH 或者里面可以封装 SSH,批量的问题可以解决。但是写 SSH 脚本一定解决不了环境复杂的问题,除非写的非常牛。环境有 N 种,比如说需要支持一个 Nginx 团队,或者一个团队想运行另外一个 Solr 搜索引擎等等。如何比较清晰的管理配置文件,有条不紊的不会弄错,不会互相之间污染。其次是同一个业务的集群,配置文件能够保持一致性等。再就是扩容的问题,如何快速的扩容,还有环境切换,比如说业务集群中把原有环境拿掉,马上部署另外的环境。这就是快速切换。再就是像一些人为的不注意造成的一些运维上的问题。比如说有人把某一台配置文件改错了,跟这集群其他的机器不一样了等等。
如果能提供一些工具和平台系统还好,让他自己去做这运维的事。那运维就能从本质上得到解放,可以去定制自己的环境,自己可以去变更环境,那个流程就不需要走了,不用沟通也不用干这活,剩下的时间可以研究一些知识去造一些工具、造一些文字。所以最后一点我认为非常重要。
在我们的环境里是如何解决这个事的?刚才说了我来自与奇虎 360 的 Web 平台部,我们分为:
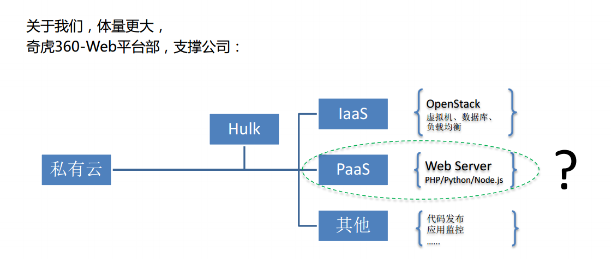
Iaas 主要是支持 Web 服务端的环境部署。比如说 OpenStack,还有代码发布应用监控等等。今天介绍的内容主要集中在第二块,就是 Pass 环境的快速部署。
Pass 这一块呢,我们现在的平台大概支撑着全公司几乎 90%,几乎就是所有的 360Web 服务端。我统计了一下产品线大概有 130 多个主产品线。像访问流量比较大的,比如大家所熟知的网址导航、360 云盘,Web 平台都在做支撑。环境运行的差异比较大,光 PHP 就有三个版本:5.3、5.4、5.5,马上要支持 PHP7,还有用人 Python 或是 Nodejs。第三个问题就是不同的业务线它的环境是不同的,然后它的服务器的集群也是单独的。所以这些服务器的集群要单独的去管理。
解决主要矛盾
解决这个问题,我们抓主要矛盾。

主要矛盾就是这三个环节,第一个环节是软件,如何管好你的软件,比如说软件仓库,如何做一个自己用的很舒服的软件仓库,这是根本。只有有了一个比较好使的软件仓库,才能快速的给它部署软件。第二步才是搞定配置文件,配置文件一般是在安装的时候装一个默认的配置文件。后面的各个业务线都会根据自己的需要去修改。再就是服务。软件、配置文件服务这三点,是我们认为三个最核心的关键。
我们的对策
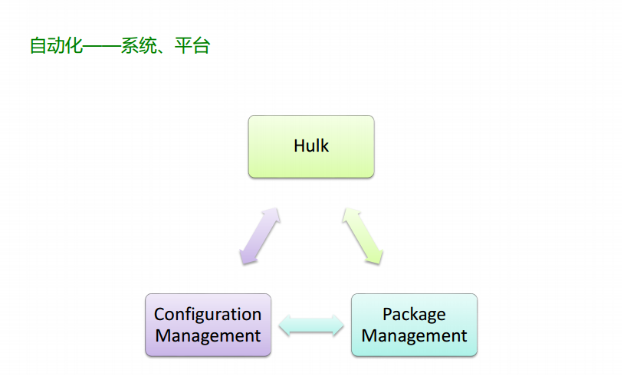
对策肯定就是自动化了,这个肯定这是最终的结论,如何自动化呢?我们做一些子系统,这些子系统只负责把该干的做好就行,但是这些子系统之间要有对接,要对外提供接口,他们之间能够互相拼接,去做更多的事情。这是我们的一个思路。
在今天的议题里面主要就涉及这三个子系统。
(点击放大图像)

第一个子系统是HULK,HULK 是一个管理平台,我们内部自己开发的。取这名字是因为360 不是喜欢绿色吗?再有就是取站在巨人的肩膀的含义,它是一个管理平台。下面是Configuration Mangagement,另外一个是Package Mangagement。
第一个是控制平台是面向业务的,页面非常的美观。操作的用户体验也可以说非常的好,它不是给我用的,是给公司的开发用的。360 有非常强的产品体验意识,页面漂亮,用户体验也好。比如说一个导航,有一定的权限可以登陆,进来之后他可以看到自己的业务一些相关的资源,比如说云服务器、监控、负载均衡等等。Hulk 包括集群、软件管理和配置文件管理。
下面我们介绍软件这一块。
我们采用CentOS,以及RPM、YUM 工具,REPO 软件仓库,YUM 软件仓库,我们软件仓库有自己自己建,还有公共的。一些公共的开源软件如果提供了一些YUM 的REPO 我们会引进过来。还有自己编译的一些软件,根据公司业务的需求。另外就是RPM 软件包的制作、分发、更新的问题。还有就是一个RPM 信息查询的问题,为什么说有一个信息查询的问题呢?主要是解决HULK 是如何知道现在所有的REPO 有哪些包。所以说我们需要开发一些HTTP 接口,HULK 去请求这些接口就能拿到所有的信息。
这是上一张说的软件仓库管理一个架构图,最下面呢是制作环节,就是所谓的RPM Builder,肯定是按照操作环节来的。第二个环节是校验环节,需要检查制作的RPM 包是不是正常,能不能正常的安装等等。
最上面的一层就是线上的分发环节,所有的服务器其实都会用Mirror 服务器来安装。YUM 通过HTTP 请求仓库。
(点击放大图像)

最后一部分介绍的是配置管理,也是最主要的一部分,它是真正干活的,也是相对来说较复杂的一部分。它的核心是完成软件安装,保证配置文件的准确无误的同步和服务。
我们使用的是Puppet 管理系统架构,尽量不去完全重复造轮子。如果开源的行业里面有适合的,我们会选择这个方案。Puppet agent 通过解析到负载均衡器。后面挂的是puppet master,puppet master 都完全一样,只要多加机器就能提升水平。
跟Web 对接也就是Hulk,页面里面选择哪些包、哪些版本等等。Hulk 只是一个展示,是一个控制台。子系统之间的对接是由Hulk 给Puppet 推过来的。
如何用Puppet 进行配置管理
(点击放大图像)

语法是Puppet,主要用来定义配置。第一个是软件包。第二个是跟这个包有关的文件。第三个是和包、文件有关系的服务。逻辑流程是,定义要装什么包,定义这个包的文件,服务是不是要重启,这是Puppet 的一个典型的配置。
我们却不是这么用的,为什么?因为主要的两个缺点,一个缺点是传统的方法会要求把所有受控制节点都写在一个文件里。这样可维护性变的比较差,我们现在受配置管理系统的虚拟机有三千多台,一个机器的配置如果有50 行,3000×50,这个文件就会变的巨大,可维护性差。后面会介绍我们用的一个另外的解决方案,Hiera。Hiera 是Puppet 的一个组件,我们用的是3.1 版本,Puppet 是4.2 或是4.3。Hiera 当时是一个新推出的小组件。
第二个问题就是抽象层次低,不便于未来扩展,不便于系统化和其他集成。什么意思呢?计算机通用的思想是抽象和封装。为何不便于未来的扩展和自动化?配置文件的内容、格式并不是一个通用的格式,是使用Puppet 的,需要解析文件就需要实现Puppet 解析器,这是一个问题。
那这个地方的解决方法是什么呢?我们去开发了一些Puppet 模块。Puppet Hiera 可以直接把刚才那种格式的配置换一种写法,提供一个json 的文件就可以了。注意我强调json 是因为它是一种通用的标准的数据结构,不管使用任何的程序语言,都很方便的能够处理这种结构,这是很重要的。

而且每一个受控节点可以单独一个文件,我们现在这个文件有3000 多个,虽然数量多了,但是觉得换回来的是可维护性。文件数量多了也是一个问题,当这个数量到10 万或者是一百万,可能我们也该面临问题了。但是现在还是觉得拆开来比较好,每个机器单独拆开,而不是都集在一个巨大的文件里。
文件是json 结构,它的格式是类似于模块+ 参数这种方式。
如果让Hulk 来提供这样一个结构是不是非常便利?在我们的实践中确实证明是非常便利才改造成这样的结构的。
(点击放大图像)

这个例子只是入口文件,入口只要传参数就行了,内部怎么封装,内部是什么流程、什么逻辑完全不用管。内部的流程改了,只要接口参数不变,HULK 就不用动,也不用受任何影响。
配置管理如何使用
(点击放大图像)

比如说一个开发的同事想改一个配置文件,他就可以到他的配置文件管理里来针对它的那个域名进行编辑。这个时候就会把它最新的配置文件展现出来,可以全屏在浏览器里进行编辑,还有一定的预防检查,编辑完了之后保存。保存之后提示红色字体,选择同步,或批量同步。批量同步其实不是一开始批量同步,是一种测试同步。就像可以在现在的集群里面随意选择的一台机器,只对这一台机器进行同步。Puppet 把同步流程的工作都做了,当然做这个事是模块里的代码。如果发现测试里没有问题,就可以选择全部同步,全部同步就是把整个集群的配置做到一致性。
总结
可以总结为三点。
首先我们有一个软件仓库的基础,这里面会管理好软件包,然后部署系统要有高的稳定性、可靠性。稳定可靠这个很重要,比高效更重要。业务集群部署环境,是一分钟还是十分钟,关系不是特别大,但是如果总出问题,或者有的机器没有部署上,或者服务没起来等等,这些可靠性问题是非常要命的。再一个就是控制中心HULK,它可以让用户自主的管理环境,减轻了很多的沟通成本。
第二点,子系统都是可以解耦的,至少可适当的解耦,对外能提供一定的互通的标准接口,大家只要能拼装就行,只要配置管理也可以,如果其他部门想接入也可以,只要像HULK 一样对接就行了。
第三点,今天介绍的这些组件,2013 年上线,现在大概运行了两年。现在3000 多台虚拟机,涉及一百多个业务线。有一些业务线的机器集群部署管理还是老的脚本方式,都在慢慢的迁往这个环境上迁移。
那这套系统消耗了多少资源呢?我大概算了一下,不管是软件包的这套系统还是Puppet 的机器都是四核的虚拟机,一共加起来不到10 台。资源消耗其实还是挺理想的。而且现在承载能力也很宽裕,主要是Puppet 集群负载非常低,现在处理3000 多台的受控节点,保守估计6000 台都没有问题,所以这个资源不会再追加。
演讲嘉宾介绍
王浩宇,生物物理学硕士,对计算机技术充满兴趣,遂弃暗投明,2010 年毕业加入新浪,2013 年加入奇虎360 的Web 平台部,担任运维开发工程师,主要负责自动化运维、私有云平台建设相关工作,实现了Hulk 云平台的集群管理功能,以支持大规模集群的快速部署,目前的主要研究方向是云计算、OpenStack 等。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




