
欢迎阅读新一期数据库内核杂谈,这是 2022 年的第一期。首先,祝大家新年快乐,新年插的 flag 都能在年底拔掉!再次和大家说声抱歉,内核杂谈 2021 年的 flag 是每个月一篇,但是我,拖更了。新的一年,就不立 flag 了,随缘更新。希望大家继续支持。
这一篇,终于可以接上第十九期的话题,继续来学习 Andy Pavlo 的自动驾驶的数据库,NoisePage 项目。这篇文章 MB2: Decomposed Behavior Modeling for Self-Driving Database Management Systems 发表于 2021 年的 SIGMOD。去年的这届 SIGMOD 在西安召开,由于疫情,很多学者(包括 Andy)只能线上参会了。
内核杂谈第十九期讲的是 workload forecasting,用机器学习的方法来预测未来的 workloads 会是啥样的。这篇文章讨论的话题,接着上一篇文章,当我们知道未来的 workloads 后,如何去预测它们对数据库造成的影响,主要是从资源使用的角度(resource consumption)。我觉得,下一篇文章就该是,知道了预测的资源使用,如何去提前配置数据库做好应对,真正做到自动驾驶。
背景和简介
介于上两篇相关的博客都是很久之前了,再来复习一下自动驾驶数据库的概念:一个自动驾驶的数据库系统可以在没有 DBA 操作的情况下,自动配置,调参来优化自身的设置来应对未来可能的 workloads,数据以及运行环境的变化。自动驾驶数据库的架构,和自动驾驶汽车架构类似(当然是简化版本的):1)感知系统,用来收集周围环境和状态;2)Mobility Model:定义了车对于控制 action 造成的状态改变;3)规控(PnC):基于感知和 Mobility Model,决定该给车下达什么指令来完成驾驶。相对应的自动驾驶数据库,也有三套系统:1)预测系统:即第十九期介绍的如何预测未来 workloads; 2) behavior modeling: 即本篇文章介绍的通过对数据库的 action 做建模,来预测 workloads 对数据库的状态造成什么改变;3)就是 planning 系统来提前调优数据库以更好地应对状态改变。
先来看一下 behavior modeling 为啥这么难。首先就是系统复杂性高:一个数据库系统有太多的操作,配置,和状态变化去考虑了。二是,并行运行复杂度很高:一个数据库可以同时接受多个查询语句,这些查询语句在同时运行的时候,对系统造成的变化和它们分别单独运行肯定不一样,这增加了建模的难度。三就是训练,收敛,通用模型,以及可解释性。这其实是机器学习和深度学习都会遇到的问题。
目前的 research 对于 behavior modeling 分为两派,一派是 white-box 分析型,另一派就是机器学习派。White-box 分析型,如其名,通过针对具体的某个 DBMS 的内部架构,来为数据库的 behavior 建模。比如 buffer pool 或者是 lock manager 相关的 behavior 等。这类方法的好处在于,对于这类系统,定义非常准确,但是这样的 modeling 不通用,不能移植到其他数据库系统。另一派机器学习派则通过机器学些的方式定义 modeling,并且被证明了更通用也更 scalable。但它也有缺陷,至少目前的机器学习方法都只针对单个执行语句来建模。
本文介绍的系统 ModelBot2(MB2),采用了兼容两派的方法。首先,MB2 将一个数据库系统拆解成一个一个小的,互相独立的操作单元(operating unit, OU),每个 OU 就是一个 action,比如,创建一个 hash index,或者 flush log records。这之后,MB2 应用机器学习为每个 OU 都训练一个 OU-Model,这个模型可以预测在某一个具体的 OU 发生后,会对系统的运行时造成什么改变(状态和资源使用)。文中提到,相对于一个通用的大模型,针对每个 OU 训练 OU-model 的好处在于,结果更准确,并且训练成本相对更小。下一步,为了更好地预测并行的查询操作(转换成并行 OU)对整个数据库系统的影响,MB2 还引入了一个 interference model(干预模型)来预测当多个 OU 同时发生时,最终会对数据库系统的运行时造成什么改变。
详细架构
MB2 是一个嵌入式的 behavior modeling 框架。它有两个主要的设计理念:1)因为训练,构建模型,调参和测试是非常耗时的。因此,MB2 的模型训练是 offline 进行的。数据库系统可以通过加载训练完的模型来对预测运行时改变。2)MB2 的模型是可以解释,并易于 debug。结合下面的架构图,我们来看 MB2 的模型是如何训练出来的。
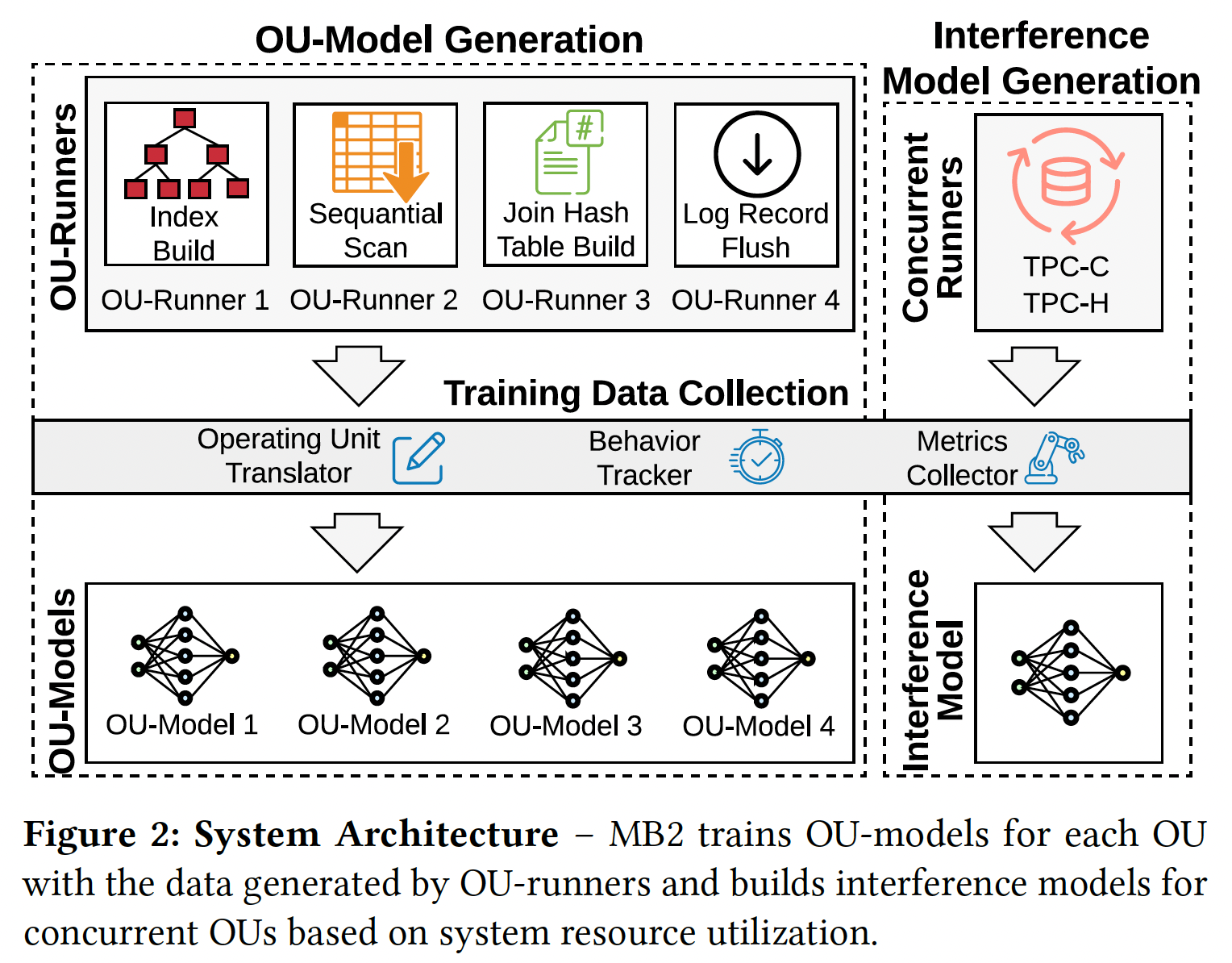
首先就是,对数据库系统进行解耦,把对它的改变定义成一个个相互独立的操作单元(OU)。一个 OU 对应了数据库系统的一个行动来完成一个对应的任务。这些任务可以是执行计划的任务比如创建一个 index,构建 hashTable,或者是数据库系统内部状态维护的任务,比如 garbage collection,或者 flush database log。对于一个 DBMS,它的开发者应该提供整个 OU 的集合(由于 NoisePage 是基于 CMU 开源的数据库系统,因此它们可以很容易地从代码层面提供 OU 的集合)。
定义好了 OU 集合,第二步就是为每一个 OU 配一个 OU-runner,用来训练对应的 OU 模型。OU-runner 需要从数据库系统层面收集对应 OU 所需要的 input(比如,sequential scan 需要知道有多少 tuple 被扫描,每个 tuple 有多少 column 等等),同时也收集相应的 output features(即 CPU, memory utilization, IO, 时间等硬件属性)。如此,每个 OU-runner,就可以单独训练相应的 OU-model。
最后一步,为了预测现实环境中的并行计算问题,MB2 定义了 interference model (干预模型),用来预测当多个 OU 在同时执行中,会对原本的 output features 造成什么影响。Interference model 的输入是多个 OU 的 output features,然后输出是 adjusted output features。 下图给出了细节。
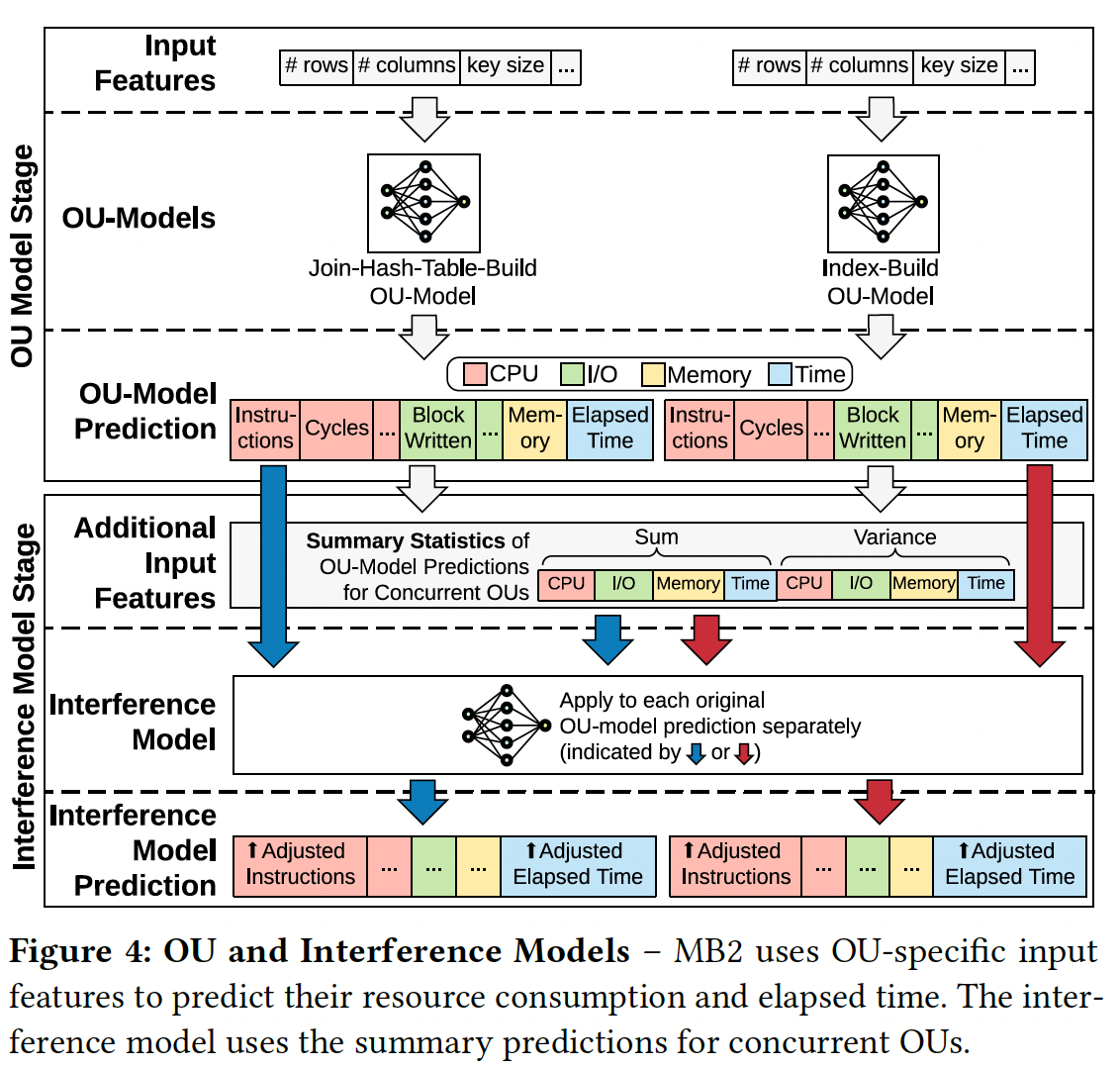
完成上面这三步,一个自动驾驶的数据库可以把 MB2 当成一个模拟器来预测 workloads 对于数据库运行时状态的改变。结合下图来看 MB2 是如何服务的。
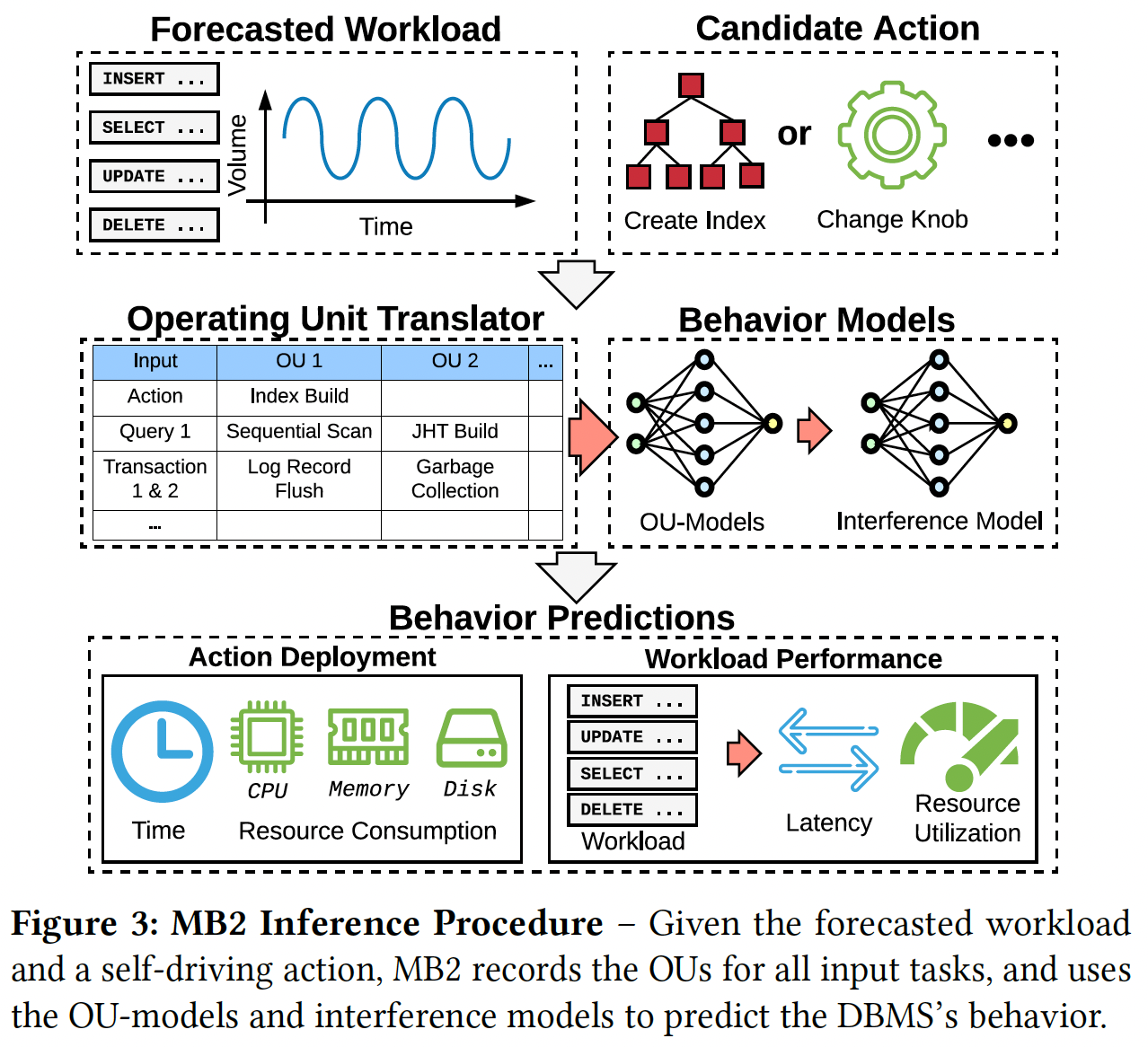
MB2 的输入是预测的 workloads 或者一个数据库状态维护指令。第一步,首先 MB2 从输入里抽取出对应的 OU list,并且得到对应 OU 的 input features。第二步,通过每个 OU model,预测这些 OU 对系统运行时带来的改变。第三步,用干预模型来修正并行运行 OU 的结果。最终的输出就是,对于某个 workloads(以及它们的并行运行状态),预测出它们对系统的资源使用,以及大致需要多长时间完成。
余下的部分
论文的后续章节介绍了 OU modeling 和 interference modeling 的细节。下图展示了 NoisePage 里定义的 OU。讲真,这些 OU 已经是被大大简化了。一个真实数据库系统的 OU 应该远比这个复杂得多,更别说,如果要定义分布式数据库或者云原生数据库的 OU 了(考虑到是 research paper,就原谅他了)。
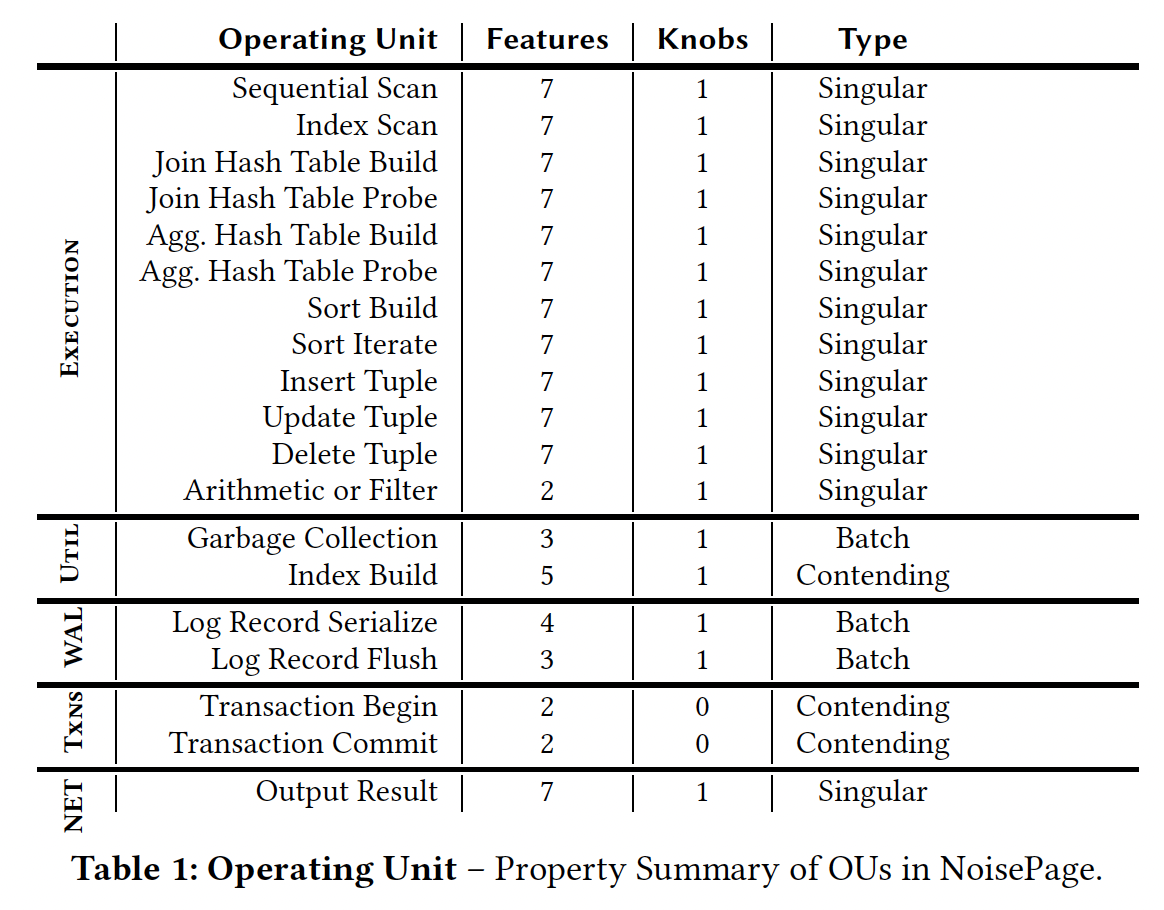
随后也介绍了如何定义 output feature(model)s,主要就是基本的硬件指标:如,时间,CPU time,CPU cycles,Cache references, Cache misses, IO 相关,和 memory consumption。
最后详细介绍了具体如何进行 experimental evaluation 的。这边就不赘述了,想要了解细节的同学可以去阅读原文。
总结
这一期,咱们一起学习了自动驾驶数据库的第二部分, behavior modeling。文中介绍的 MB2 把数据库系统的状态改变分解成一个个操作单元,再利用机器学习技术,定义和训练每个操作单元的 model 以及并行运行时的 interference model。最终通过这些模型,结合预测的 workloads,可以给出这个 workloads 大致什么时候完成,以及它们对系统资源使用的预测。一起期待最新的研究进展。
2022 年,虽然不立 flag,但还是想做出一些改变。创建了一个数据库内核杂谈交流群,如果你是忠实读者,欢迎加入交流。





