
每家公司都希望获得快速、高可用性和低延迟的服务。作为工程师,我们也有同样的愿望。然而,正如众所周知的定理所说,“天下没有免费的午餐”。实现这些目标需要大量的投资和努力。在本文中,我将分享 Wellhub 如何投资多区域架构以实现低延迟的自动完成服务。我将讨论我们采用的策略、我们学到的经验教训以及我们根据这些经验提出的建议。
背景
使用 Go 开发的自动完成服务原理是接收少量文本输入,并预测用户将要补全的内容。这种方法可以减少因为拼写错误的单词导致的搜索零结果,还能创造更流畅的用户体验,从而增强搜索体验。例如,输入“Yo”可能会返回“Yoga”和“Yoga for Kids”等建议。我们还利用 Elasticsearch 的地理查询功能,根据用户的位置来定制补全建议,从而提高相关性。
这项服务不仅可以帮助用户更快地找到他们正在寻找的内容;它还可以从我们的主要搜索基础设施中卸载大量流量,从而提高整体系统效率。考虑到很多搜索内容是特指的,大约 66% 的自动完成输入会使点击操作重定向到专用页面,绕过搜索结果页面。这简化并优化了搜索过程。
我们的公司基于 Amazon Web Services(AWS),所有服务都部署在 Kubernetes 中。我们尽可能使用托管解决方案,例如 Amazon Managed Streaming for Apache Kafka、DynamoDB 和 Amazon Aurora。但是,我们的 Elasticsearch 集群仍托管在我们自己的基础设施内(另一种选项是 AWS OpenSearch)。对于多区域部署,我们创建了 Landing Zones。它们提供了更好的隔离、安全性和数据管理,这些优点也不仅限于这个项目。
在实施多区域架构之前,我们考虑了其他解决方案,主要是因为该服务的处理时间约为 15 毫秒,几乎没有改进空间。我们考虑的一个选项是使用 地理散列(geohashing)来优化内容分发网络(CDN)中的缓存,在我们的例子中 CDN 是 Amazon CloudFront。但由于数据的高度可变性,这种方法被证明是无效的。我们的分析显示成功率仅为 28%,生存时间(TTL)为 7 天,地理哈希长度为 5,代表网格面积约为 4.89 公里 x 4.89 公里。
考虑到用户的全球分布情况,我们认定将数据移近用户是最有效的解决方案。
设计用于快速自动完成的多区域系统
我们开发了一个 RFC,提议构建一个多区域架构,这需要我们平台团队的协作。这个服务的迁移工作相对简单:我们复制了 Helm 图表定义、创建了用户、在新区域中应用了策略,并在 Vault 中配置了所有密钥。尽管如此,与其他绝大多数迁移一样,这里的主要挑战是处理数据。
最初,我们考虑使用 Elasticsearch 跨集群复制,因为它有双向、链式、灾难恢复功能。但这些功能对于我们的需求来说并不是必需的,而且需要获取许可证。我们的理由是基于索引更新的频率、所需的数据新鲜度以及我们不需要保持所有区域完全同步的事实。
作为最佳实践,我们将每日备份存储在 AWS S3 中,由一个 cron 作业触发,为灾难恢复拍摄索引快照。这里的关键是意识到 AWS S3 具有 跨区域复制 功能。我们可以将这些快照从美国弗吉尼亚州的主要区域恢复到其他区域,例如巴西圣保罗和爱尔兰都柏林 。
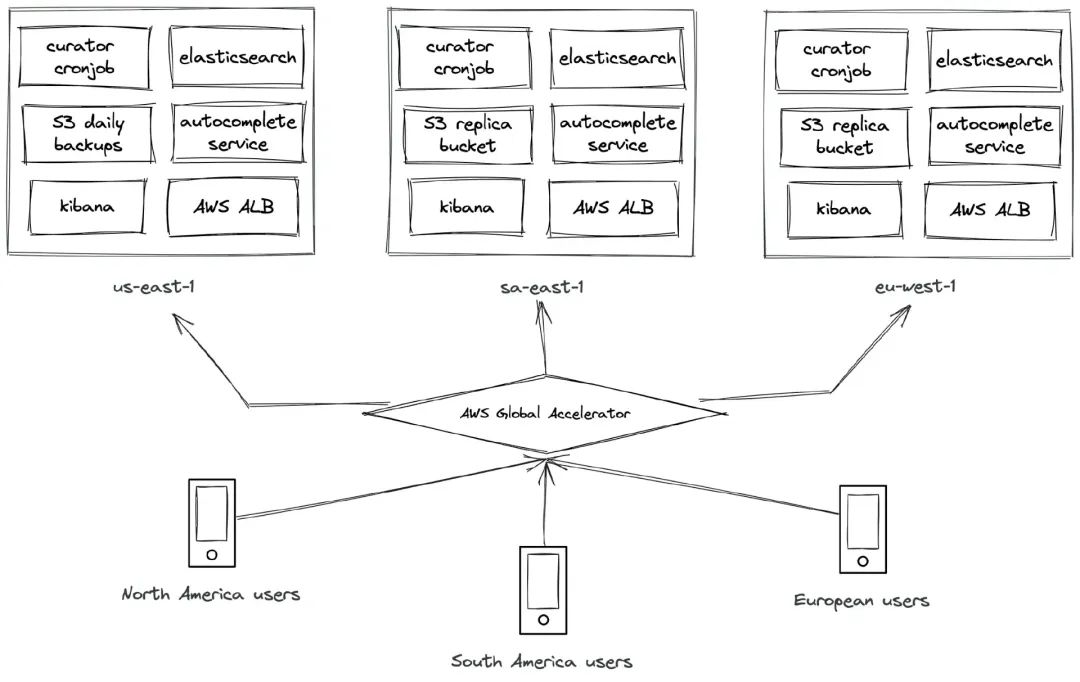
图 1:多区域自动完成服务架构
如背景部分所述,我们的自动完成数据属于我们的合作伙伴和他们的活动。虽然它们会发生更改(例如名称更新、活动添加和合作伙伴入职 / 离职),但它们不需要近乎实时的更新。以巴塞罗那的用户搜索活动为例,他们不需要第一时间知道洛杉矶的合作伙伴是否添加了新活动——除非他们正在那里旅行,但这种情况不太常见。因此,我们认定为期一天的最大复制滞后时间是可以接受的。
我们有两个每日 cron 作业;第一个在主区域中,创建快照并将其存储在 AWS S3 存储桶中。第二个作业在其他区域运行,遵循不同的流程。此过程使用一个用 Curator 构建的小型管道,以更好地处理和控制错误(特别是从 API 的角度来看)。读者可能想知道,如果我们必须在每次恢复操作期间创建一个新索引,API 该如何获知新索引的信息呢?这就是 Elasticsearch 的别名特性大展身手之处。我们使用别名来管理具体指向哪个底层索引的信息。管道首先将快照恢复到临时索引。然后,在一个原子操作中,我们将别名从主索引切换到临时索引,确保使用的是最新的数据。接下来,我们重新索引主索引,切换回别名,并删除临时索引。整个过程无缝进行,不会对服务造成任何中断,使我们能够继续无中断地处理请求。它还有合适的错误处理机制,利用了重试和超时,并有良好的可观察性。
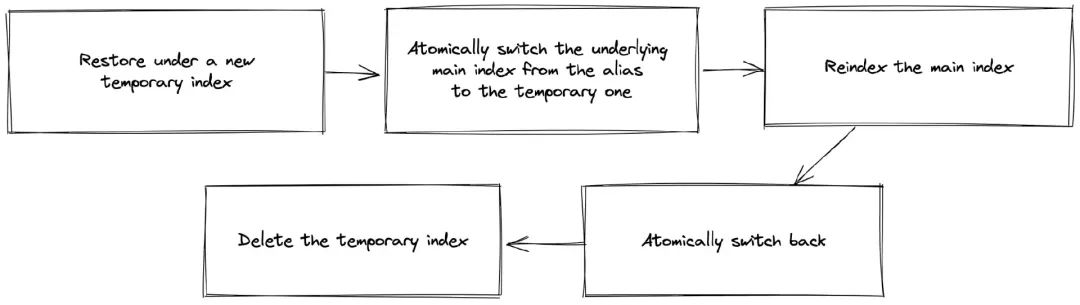
图 2:数据复制管道
我们的数据复制策略高效且成本低廉,并且不需要集群相互了解或实施领导者 / 追随者策略。处理过程很简单,因为唯一的变化是使用 Vault 提供的凭据对不同的集群进行身份验证。但有人可能会想,我们如何提供这些数据?我们的应用程序是否已将所有端点硬编码?我们如何决定将用户路由到哪个区域?
AWS Global Accelerator 配备了静态 IP 和自定义路由,可确定性地将流量路由到我们的服务实例。它利用了 AWS 全球网络的强大功能,通过减少首字节延迟、最小化抖动和增加吞吐量显著提高了性能。与公共互联网相比,它提供了更快、更一致的体验。它在边缘执行 TCP 终止,并使用流量拨号将流量定向到最近的区域,从而提供跨区域的快速故障转移。这使我们能在移动应用程序中维护单个端点,无需手动管理路由。
采用 AWS Global Accelerator 为我们提供了所需的性能改进,以及意想不到的好处:对路由的细粒度控制。这种增强的路由灵活性使我们能够执行无缝迁移、按区域逐步推出新功能,并控制流量分布——根据需要调整定向到不同区域的流量百分比。构建和维护低延迟服务的关键在于深入了解网络基础知识。
高性能的基石
我想在本文中强调的一个方面是,重点在于关注每个组件、注重细节和了解上下文以找到最佳解决方案。要做到这一点需要进行彻底的研究。以下部分基于 Ilya Grigorik 的经典 著作《高性能浏览器网络》。对于所有希望提供高质量软件的工程师和经理来说,这都是必读书籍。我们来简要回顾一下其中的一些片段。
传输控制协议(TCP)
TCP 是一种令人难以置信的协议,它允许我们对其内部运作进行微调以优化数据传输。例如,增加 TCP 初始拥塞窗口可以在第一次往返中实现更多数据传输并增强窗口增长。禁用空闲后的慢启动可以提高长寿命 TCP 连接的性能。窗口缩放可以在高延迟连接中实现更好的吞吐量,而 TCP Fast Open 有时可以将数据与 SYN 数据包一起发送。
AWS Global Accelerator 采用了其中的几项优化。它利用大型接收端窗口和 TCP 缓冲区、大型拥塞窗口以及对巨型帧的支持,使其能够在每个数据包中发送六倍以上的数据。这些功能共同增强了跨网络数据传输的性能和效率。
我们通常专注于后端,优化查询执行、应用缓存或重写整个服务。不过其他组件也对等式做出了贡献。
移动网络
使用移动应用程序时,重要的是要考虑到单个连接不会全程都以光速通过光纤电缆传输。是的,数据包可以通过光纤电缆在近 200 毫秒内(真空中为 133.7 毫秒)绕地球赤道(40,075 公里)跑一圈。但是,移动网络引入了影响性能的其他组件。
运营商架构
运营商架构是构建高性能移动应用程序时需要考虑的一个组件。这些架构可能因运营商而异,也可能因 4G 和 5G 等技术而异。典型的 LTE 网络的高级架构包括无线接入网络(RAN)和核心网络(CN)。
无线接入网络负责调解数据包流量并为用户设备提供对预留无线信道的访问。它还会将所有用户的位置告知核心网络。这是必要的,因为用户可以与任何无线基站连接,并且网络必须在用户移动时管理基站切换操作。有趣的是,RAN 的示意里提到了 cell,这也就是为什么手机被叫做 cell phone。
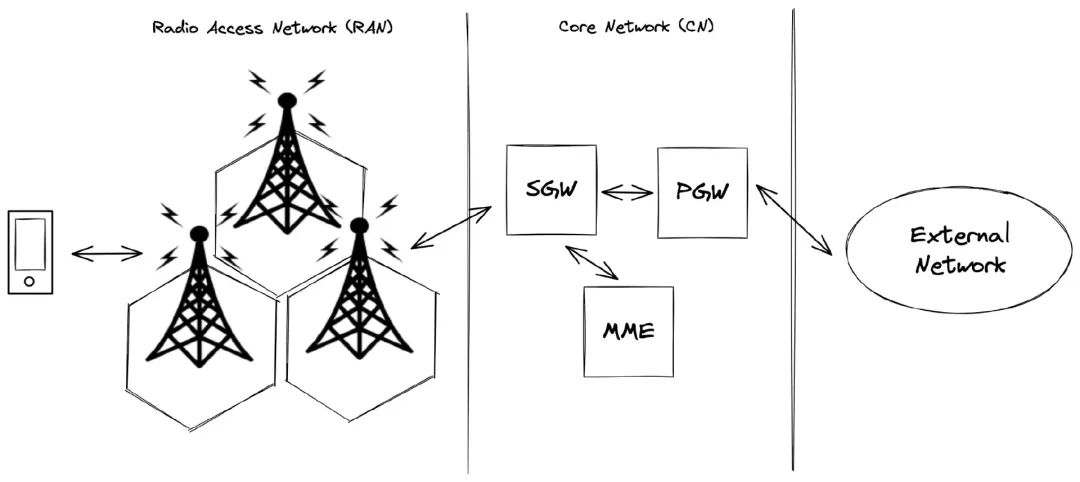
图 3:基本的 LTE 架构
核心网络负责数据路由、计费和策略管理,将无线网络连接到公共互联网。它由几个组件组成,每个组件对网络的功能都至关重要:
分组网关(PGW):管理与公共互联网的连接,包括为设备分配 IP 地址。它还处理数据包过滤、检查和针对拒绝服务(DoS)攻击的保护工作。
移动管理实体(MME):充当用户数据库,维护有关其位置、帐户类型和计费状态的信息。
服务网关(SGW):当 PGW 收到数据包时,它依靠 SGW 来确定用户的位置。它查询 MME 并与合适的无线基站建立连接以发送数据,确保整个网络的无缝通信。
这个复杂但透明的过程会显著影响你的移动应用程序的延迟和性能。
无线电资源控制器(RRC)
另一个组件是无线电资源控制器(RRC),它管理设备与无线基站之间的连接,影响延迟、吞吐量和电池寿命。要管理无线信道的数据传输,RRC 必须分配资源或向设备发送有关传入数据包的信号。RRC 使用状态机来定义每个状态下可用的无线电资源,会影响性能和能耗。关键状态包括 RRC 空闲和 RRC 连接。这些状态由超时控制。例如,在 HSPA+ 连接中,状态在 10 秒不活动后从高功率(具有专用的上行和下行网络资源)转换为低功率状态。这种低功率状态消耗的能量较少,但依赖共享的、有限的低速信道(低于 20 Kbps)。如果在此转换之后发生数据请求,则会切换回高功率状态。这一协商过程需要几毫秒,会增加延迟并消耗电池续航。
微调速度和效率
关于优化移动网络的文献提供了几个重要的评估点。一个重点是尽量减少轮询,因为在移动网络上频繁轮询的成本非常高。相反,文献建议尽可能使用推送和通知。此外,应合并和聚合出站和入站请求以减少传输次数。非关键请求应推迟到无线连接处于活动状态的时候,以免次要操作也唤醒无线连接。
消除不必要的应用程序保持活动也很关键,因为运营商网络管理连接生命周期时并不管设备的无线连接状态。预测网络延迟开销是另一个重要考虑因素。考虑到控制平面、DNS 查找、TCP 握手、TLS 握手和 HTTP 请求等因素,建立一个新连接在 4G 网络中最多需要 600 毫秒,在 3G 网络中最多需要 3500 毫秒。我们采用的一个有效策略是在用户与输入组件交互之前发送一个“空”请求,从而抢先建立连接并更快地发出后续请求。
此外,批量传输数据也大有裨益,因为它可以快速下载尽可能多的数据,然后让无线连接返回空闲状态。这种方法可以尽可能提高吞吐量和电池寿命,因为移动无线接口已为此进行了优化,为移动应用程序提供了显著的性能和效率改进。
衡量我们所做优化的影响
在实施多区域架构之前,我们的用户会遇到 600 毫秒到 700 毫秒的 p90 延迟,如图 4 和 5 所示,这导致了不好的体验。这种延迟严重影响了我们的自动完成服务的功能。等待这么长时间才能自动完成一个搜索词还不如没有这功能,因为用户可能更喜欢自己输入整个文本,即使冒着输入错误的风险。
之后,延迟有所改善,但没有我们希望的那么多。在 p90 时,延迟减少了 200 毫秒,比以前好很多,但考虑到我们的投资,对于多区域设置来说,延迟仍然没有预期的那么低。我们的目标是实现大约 100 毫秒的延迟,降低到用户认为是即时的水平。
然后,我们决定通过实现优化部分中提到的预取端点来预测延迟开销。经过这一改变,iOS 上 p90 的延迟降至 123.3 毫秒,Android 上 p90 的延迟降至 134.6 毫秒。预取端点处理了所有繁重的工作,Android 上的 p90 延迟为 561 毫秒,iOS 上的 p90 延迟为 471 毫秒。但是,用户这次没有察觉到,因为请求是及时预先发出的。
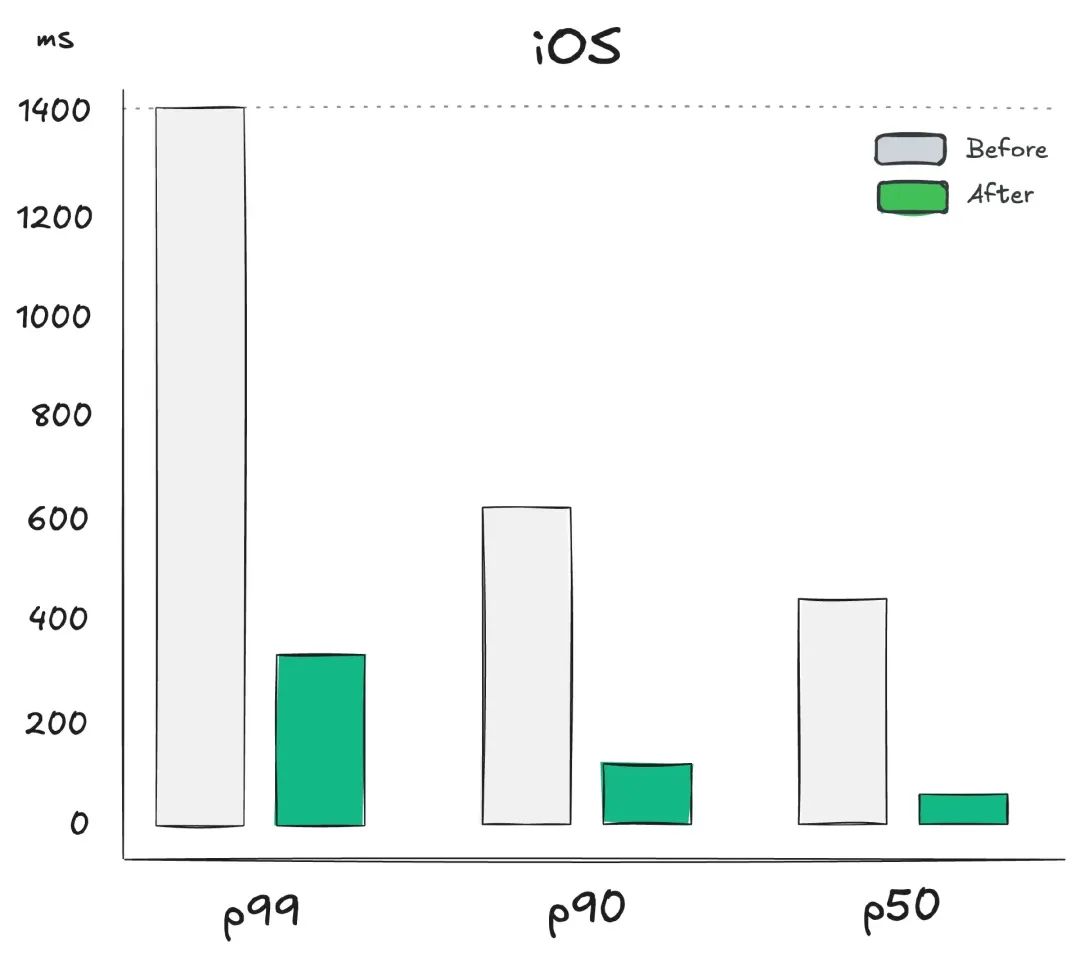
图 4:iOS 多区域架构前后感知延迟细分
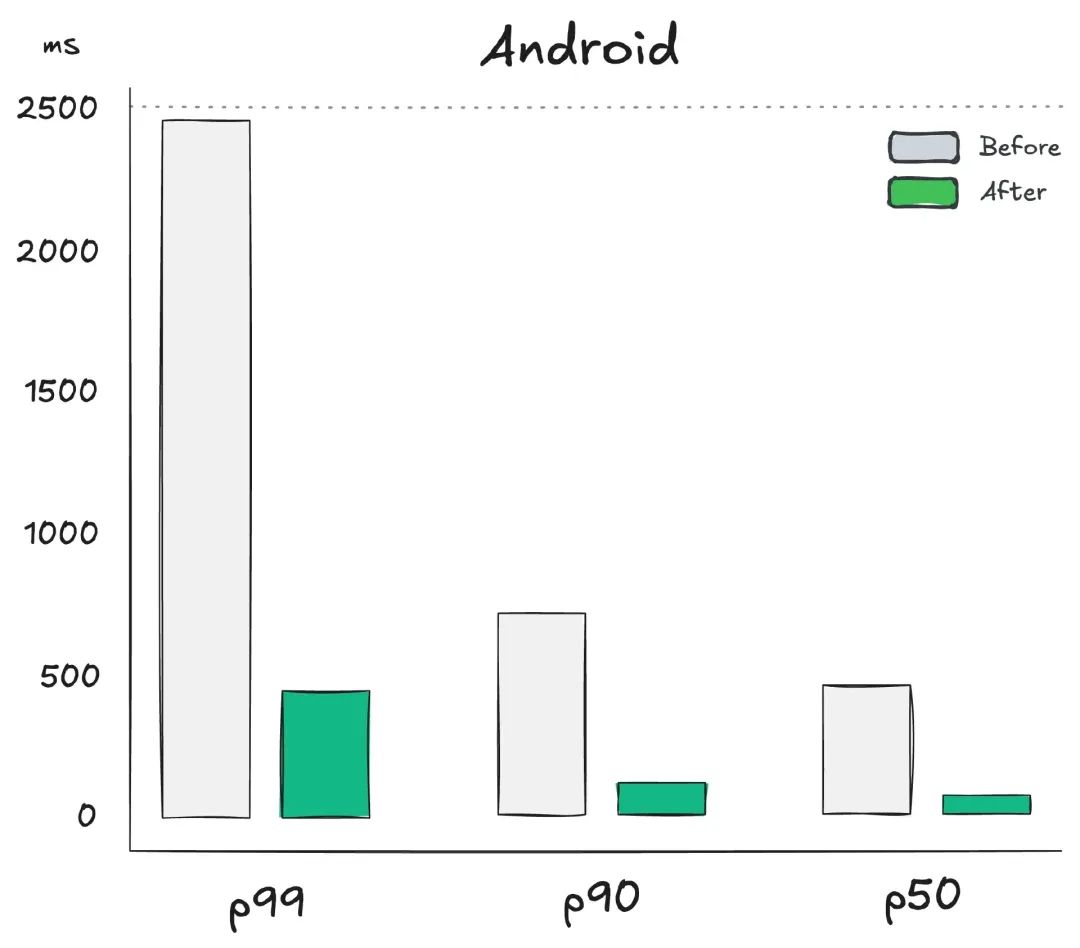
图 5:Android 多区域架构前后感知延迟细分
该项目带来的另一个重大变化是网络使用模式的明显转变。在 iOS 用户中,Wi-Fi 使用率从 63.47% 下降到 49.33%,这表明现在有更多用户通过移动网络访问应用程序。LTE 使用率的增加进一步证实了这一转变,从 24.58% 上升到 29.30%。
Android 用户也看到了类似的好处,Wi-Fi 使用率从 67.08% 下降到 51.18%。与此同时,LTE 使用率从 30.31% 增长到 44.46%。这些变化表明,网络优化使用户比以前更加依赖移动网络,从而增强了他们的整体体验。
图 6:多区域项目前后用户感知到的延迟
总结
用苏格拉底式的话来说,“理解问题就是答案的一半”。尽管软件大都遵循几种常见模式,但每款软件都是独一无二的。这种独特性源于各种因素,例如业务需求、技术限制和构建它的团队。关键在于评估和系统地分析权衡。
通过多区域方法优化服务可能不是许多用例的最佳选择,或者在其他用例中实施起来可能更复杂、更具挑战性。在我们的案例中,这种架构显著降低了我们最初预期的延迟,进一步的研究表明,一种简单的技术——预取——可以进一步降低感知延迟。
我们未来的努力可能包括使用更适合此类系统的更强大的指标进行更深入的分析,例如最小击键长度(MKS)和节约的工作量(e-Saved)。两者都是用户辅助指标,用于衡量服务的实用性:例如,e-Saved 表示用户无需键入即可完成查询的字符比例。此外,我们还会通过区分不同地区的指标来提高可观察性可以揭示不同的访问模式,可能需要针对特定区域进行优化。
作者介绍
Matheus Felisberto 是一位对计算机科学充满热情的工程师。凭借十年的技术行业经验,他在创建低延迟、高可用性应用程序方面拥有丰富的专业知识,专注于管理和优化大型系统。他拥有计算机科学学士学位、FIAP(圣保罗)大数据 MBA 学位、FIA(圣保罗)软件工程和架构研究生学位,目前正在里斯本新伊姆斯大学攻读数据科学和高级分析硕士学位,他的论文重点是信息检索和大型语言模型。
查看原文链接:




