编者按:本文作者汪榕曾写过一篇文章:《以什么姿势进入数据挖掘会少走弯路》,是对想入行大数据的读者的肺腑之言,其中也表达了作者的一些想法,希望大家不要随便去上没有结合业务的收费培训班课程;而后,他有了结合他本人的工作经验,写一系列帮助大家进行实践学习课程文章的想法,InfoQ 也觉得这是件非常有意义的事情,特别是对于大数据行业 1-3 年工作经验的人士,或者是没有相关工作经验但是想入行大数据行业的人。课程的名称是“数据挖掘与数据产品的那些事”,目的是:1. 引导目标人群正确学习大数据挖掘与数据产品;2. 协助代码能力薄弱的学习者逐渐掌握大数据核心编码技巧;3. 帮助目标人群理解大数据挖掘生态圈的数据流程体系;4. 分享大数据领域实践数据产品与数据挖掘开发案例;5. 交流大数据挖掘从业者职业规划和发展方向。这系列文章会在 InfoQ 上形成一个专栏,本文是专栏的第三篇。
前言:很多初学的朋友对大数据挖掘第一直观的印象,都只是业务模型,以及组成模型背后的各种算法原理。往往忽视了整个业务场景建模过程中,看似最普通,却又最精髓的特征数据清洗。可谓是平平无奇,却又一掌定乾坤,稍有闪失,足以功亏一篑。
一、数据清洗的那些事
构建业务模型,在确定特征向量以后,都需要准备特征数据在线下进行训练、验证和测试。同样,部署发布离线场景模型,也需要每天定时跑 P 加工模型特征表。
而这一切要做的事,都离不开数据清洗,业内话来说,也就是ETL 处理(抽取 Extract、转换 Transform、加载 Load),三大法宝。

来自于百度百科
在大数据圈里和圈外,很多朋友都整理过数据,我们这里称为清洗数据。
不管你是叱咤风云的 Excel 大牛,还是玩转 SQL 的数据库的能人,甚至是专注 HQL 开发 ETL 工程师,以及用 MapReduce\Scala 语言处理复杂数据的程序猿。(也许你就是小白一个)
我想说的是,解决问题的技术有高低,但是解决问题的初衷只有一个——把杂乱的数据清洗干净,让业务模型能够输入高质量的数据源。
不过,既然做的是大数据挖掘,面对的至少是 G 级别的数据量(包括用户基本数据、行为数据、交易数据、资金流数据以及第三方数据等等)。那么选择正确的方式来清洗特征数据就极为重要,除了让你事半功倍,还至少能够保证你在方案上是可行的。
二、大数据的必杀技
在大数据生态圈里,有着很多开源的数据 ETL 工具,每一种都私下尝尝鲜也可以。但是对于一个公司内部来说,稳定性、安全性和成本都是必须考虑的。
就拿 Spark Hive 和 Hive 来说,同样是在 Yarn 上来跑 P,而且替换任务的执行引擎也很方便。

修改任务执行引擎
的确,Spark 的大多数任务都会比 MapReduce 执行效率要快差不多 1/3 时间。但是,Spark 对内存的消耗是很大的,在程序运行期间,每个节点的负载都很高,队列资源消耗很多。因此,我每次提交 Spark 离线模型跑任务时,都必须设置下面的参数,防止占用完集群所有资源。
spark-submit --master yarn-cluster --driver-memory 5g --executor-memory 2g --num-executors 20
其中:
- driver-memory是用于设置 Driver 进程的内存,一般不设置,或者 1G。我这里调整到 5G 是因为 RDD 的数据全部拉取到 Driver 上进行处理,那要确保 Driver 的内存足够大,否则会出现 OOM 内存溢出。
- executor-memory是用于设置每个 Executor 进程的内存。Executor 内存的大小决定了 Spark 作业的性能。
- num-executors是用于设置 Spark 作业总共要用多少个 Executor 进程来执行。这个参数如果不设置,默认启动少量的 Executor 进程,会很大程度影响任务执行效率。
单独的提交 Spark 任务,优化参数还可以解决大部分运行问题。但是完全替换每天跑 P 加工报表的执行引擎,从 MapReduce 到 Spark,总会遇到不少意想不到的问题。对于一个大数据部门而言,另可效率有所延迟,但是数据稳定性是重中之重。

Spark 运行 Stage
所以,大部分数据处理,甚至是业务场景模型每天的数据清洗加工,都会优先考虑 Hive 基于 MapRedcue 的执行引擎,少部分会单独使用编写 MapReduce、Spark 程序来进行复杂处理。
三、实践中的数据清洗
这节要介绍的内容其实很多,单独对于 Hive 这方面,就包括执行计划、常用写法、内置函数、一些自定义函数,以及优化策略等等。
幸运的是,这方面资源在网上很全,这是一个值得欣慰的点,基本遇到的大多数问题都能够搜到满意答案。
因此,文章这个版块主要顺着这条主线来——(我在大数据挖掘实践中所做的模型特征清洗),这样对于大数据挖掘的朋友们来说,更具有针对性。
3.1 知晓数据源
(这里不扩展数据源的抽取和行为数据的埋点)
大数据平台的数据源集中来源于三个方面,按比重大小来排序:
60% 来源于关系数据库的同步迁移: 大多数公司都是采用 MySQL 和 Oracle,就拿互联网金融平台来说,这些数据大部分是用户基本信息,交易数据以及资金数据。
30% 来源于平台埋点数据的采集:渠道有 PC、Wap、安卓和 IOS,通过客户端产生请求,经过 Netty 服务器处理,再进 Kafka 接受数据并解码,最后到 Spark Streaming 划分为离线和实时清洗。
10% 来源于第三方数据:做互联网金融都会整合第三方数据源,大体有工商、快消、车房、电商交易、银行、运营商等等,有些是通过正规渠道来购买(已脱敏),大部分数据来源于黑市(未脱敏)。这个市场鱼龙混杂、臭气熏天,很多真实数据被注入了污水,在这基础上建立的模型可信度往往很差。
得数据,得天下?
3.2 业务场景模型的背景
看过我以前文章集的朋友都知道一点,我致力于做大数据产品。
在之前开发数据产品的过程中,有一次规划了一个页面——用户关系网络,底层是引用了一个组合模型。
简单来说是对用户群体细分,判断用户属于那一类别的羊毛党群体,再结合业务运营中的弹性因子去综合评估用户的风险。
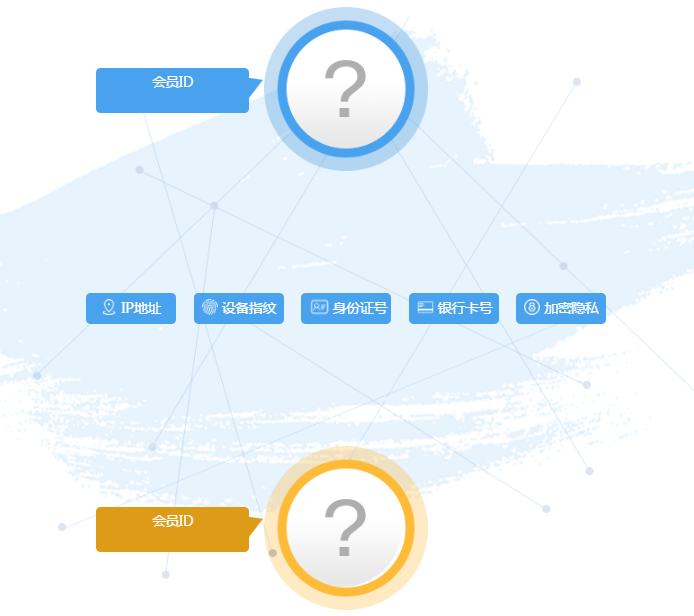
截图的原型 Demo
大家看到这幅图会有什么想法?
简单来说,原型展示的是分析两个用户之间在很多维度方面的关联度
当时这个功能在后端开发过程中对于特征数据的处理花了很多时间,有一部分是数据仓库工具 HQL 所不能解决的,而且还需要考虑完整页面(截图只是其中一部分)查询的响应时间,这就得预先标准化业务模型的输出结果。
我可以简单描述下需求场景:
- 拿 IP 地址来说,在最近 30 天范围内,用户使用互联网金融平台,不管是 PC 端,还是无线端,每个用户每个月都会产生很多 IP 数据集。
- 对于拥有千万级别用户量的平台,肯定会出现这样的场景——很多用户在最近一个月内都使用过相同的 IP 地址,而且数量有多有少。
- 对某个用户来说,他就好像是一个雪花中的焦点,他使用过的 IP 地址就像雪花一样围绕着他。而每个 IP 地址都曾被很多用户使用过。
简单来说,IP 地址只是一个媒介,连接着不同用户。——你中有我,我中有你。

雪花状
有了上面的背景描述,那么就需要每个读者都去思考下这三个问题:
问题一、如何先通过某个用户最近 30 天的 IP 列表去找到使用相同 IP 频数最多的那一批用户列表呢?
问题二、如何结合关系网络的每个维度(IP、设备指纹、身份证、银行卡和加密隐私等等),去挖掘与该用户关联度最高的那一批用户列表?
问题三、如何对接产品标准化模型输出,让页面查询的效应时间变得更快些?
思考就像吃大理核桃般,总是那么耐人寻味。
3.3 学会用 Hive 解决 70% 的数据清洗
对于 _70%_ 的数据清洗都可以使用 Hive 来完美解决,而且网络参考资料也很全,所以大多数场景我都推荐用Hive来清洗。——高效、稳定
不过在使用过程中,我有两点建议送给大家:
第一点建议:要学会顾全大局,不要急于求成,学会把复杂的查询拆开写,多考虑集群整个资源总量和并发任务数。
第二点建议:心要细,在线下做好充足的测试,确保安全性、逻辑正确和执行效率才能上线。
礼物也送了,继续介绍
对于上述的用户关系网络场景,这里举 IP 维度来实践下,如何利用 Hive 进行数据清洗。
下面是用户行为日志表的用户、IP 地址和时间数据结构。

用户、IP 和时间
回到上面的第一个思考,如何先通过某个用户最近 30 天的 IP 列表去找到使用相同 IP 频数最多的那一批用户列表呢?
我当时采取了两个步骤。
步骤一:清洗最近 30 天所有 IP 对应的用户列表,并去重用户
select ip,concat_ws('_',collect_set(cast(mid as string)))
from tmp.fraud_sheep_behavdetail_union
where ip is not null and systime='2016-12-06'
group by ip
这里解释三个内置函数concat_ws、collect_set和cast,先更了解必须去亲自实践:
- concat_ws,它是用来分隔符字符串连接函数。
- collect_set,它是用来将一列多行转换成一行多列,并去重用户。
- cast,它是用来转换字段数据类型。
果然很方便吧,下面是第一个步骤的执行结果。

IP 马赛克
步骤二:清洗用户在 IP 媒介下,所有关联的用户集列表
select s1.mid,concat_ws('_',collect_set(s2.midset)) as ip_midset
from (select ip,mid from tmp.fraud_sheep_behavdetail_union where systime>='2016-11-06' group by ip,mid) s1
join (
select ip,concat_ws('_',collect_set(cast(mid as string))) as midset
from tmp.fraud_sheep_behavdetail_union
where ip is not null and systime>='2016-11-06'
group by ip) s2 on (s1.ip=s2.ip)
group by s1.mid
最终对于 IP 媒介清洗的数据效果如下所示:
1816945284629847 1816945284629847_3820150008135667_1850212776606754_3820150012550757
_3820150006640108_1823227153612976_3820150001918669_1816945284629847
1816945284629848 1816945284629848_3820150002527117_100433_3820150009829678_
100433_100433_3820150002811537_3820150008901840_3820150012766737
_100433_3800000242066917_100433
同理对于其他维度的媒介方法一样,到这一步,算是完成 Hive 阶段的初步清洗,是不是很高效。
会员 ID 性别 加密隐私 身份证号 银行卡号 IP 地址 设备指纹
18231292 男 18231293: 男 18232394: 男 382015495: 男 _18232272: 男
38201500: 女 _38201509: 女 _382937: 女 3820152901: 男 _38204902: 男 _3820486: 男 _38201326: 女
但是对于分析用户细分来说,还需要借助 MapReduce,或者 Scala 来深层次处理特征数据。
3.4 使用 Scala 来清洗特殊的数据
对于使用 Spark 框架来清洗数据,我一般都是处于下面两个原因:
- 常规的 HQL 解决不了
- 用简洁的代码高效计算,也就是考虑开发成本和执行效率
对于部署本机的大数据挖掘环境,可以查看这两篇文章来实践动手下:
工欲善其事,必先利其器。有了这么好的利器,处理复杂的特征数据,那都是手到擒来。
借助于 Hive 清洗处理后的源数据,我们继续回到第二个思考——如何结合关系网络的每个维度,去初步挖掘与该用户关联度最高的那一批用户列表?
看到这个问题,又产生了这几个思考:
- 目前有五个维度,以后可能还会更多,纯手工显然不可能,再使用 Hive 好像也比较困难。
- 每个维度的关联用户量也不少,所以基本每个用户每行数据的处理采用单机串行的程序去处理显然很缓慢。不过每行的处理是独立性的。
- 同一个关联用户会在同一个维度,以及每一个维度出现多次,还需要进行累计。
如果才刚刚处理大数据挖掘,遇到这样的问题的确很费神,就连你们常用的 Python 和 R 估计也难拯救你们。但是如果实战比较多,这样的独立任务,完全可以并发到每台计算节点上去每行单独处理,而我们只需要在处理每行时,单独调用清洗方法即可。
这里我优先推荐使用 Spark 来清洗处理(后面给一个 MapReduce 的逻辑),整个核心过程主要有三个板块
预处理,对所有关联用户去重,并统计每个关联用户在每个维度的累计次数
// 循环每个维度下的关联用户集
for(j <- 0 until value.length){
// 用列表存放所有关联用户集
if(value.apply(j).split(SEPARATOR4).size==2 && value.apply(j).split(SEPARATOR4).apply(0)!=mid){
midList.append(value.apply(j))
}
if(setMap.contains(value.apply(j))){
// 对每个维度关联用户的重复次数汇总
val values = setMap.get(value.apply(j)).get
setMap=setMap.+((value.apply(j),1+values))
}else{
setMap=setMap.+((value.apply(j),1))
}
}
评分,循环上述关联用户集,给关联度打一个分
for(ii <- 0 until distinctMidList.size){
var reationValue = 0.0
// 分布取每个关联用户
val relation = distinctMidList.apply(ii)
// 关联用户的会员 ID
val mid = relation.split(SEPARATOR4).apply(0)
// 关联用户的性别
val relationSex = relation.split(SEPARATOR4).apply(1)
val featureStr = new StringBuilder()
// 循环每个关联维度去给关联用户打分
for(jj <- 1 to FeatureNum.toInt){
var featureValue = 0.0
// 获取该关联用户在每个维度下重复次数
val resultMap = midMap.get(jj).get.get(relation).getOrElse(0)
if(jj==1){
// 加密隐私, 确定权重为 10
featureValue=resultMap*10
}else if(jj==2 || jj==3){
标准化清洗处理,用户关联用 json 串拼接
3820150000934593 | 1 | [{"f1":"0","f2":"0","f3":"0","f4":"15","f5":"60","s":"1","r":"75"
,"m":"3820150000316460"},{"f1":"0","f2":"0","f3":"0","f4":"30","f
5":"30","s":"1","r":"60","m":"1816945313571344"},{"f1":"0","f2":"
0","f3":"0","f4":"45","f5":"90","s":"0","r":"135","m":"3820150000655195"}]
得到上面清洗结果,我们才能更好的作为模型的源数据输出,感觉是不是很费神,所以才印证了这句话——做 Data Mining,其实大部分时间都花在清洗数据
3.5 附加分:使用 MapReduce 来清洗特殊的数据
针对上述的数据清洗,同样可以 MapReduce 来单独处理。只是开发效率和执行效率有所影响。
当然也不排除适用于 MapReduce 处理的复杂数据场景。
对于在本地 Windows 环境写 MapRecue 代码,可以借鉴上述文章中部署的数据挖掘环境,修改下 Maven 工程的 pom.xml 文件就可以了。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
而我在以往做大数据挖掘的过程里,也有不少场景需要借助 MR 来处理,比如很早的一篇文章《一种新思想去解决大矩阵相乘》,甚至是大家比较常见的数据倾斜——特别是处理平台行为日志数据,特别容易遇到数据倾斜。
这里提供一个上述Spark 清洗数据的MR 代码逻辑,大家可以对比看看与Spark 代码逻辑的差异性。
Map 阶段
public static class dealMap
extends Mapper<Object,Text, Text,Text>{
@Override
protected void setup(Context context)
throws IOException,InterruptedException{
/**
* 初始化 Map 阶段的全局变量, 目前使用不上
*/
}
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
// 类似 Spark, 每一行读取文件, 按分隔符划分
String[] records = value.toString().split("\u0009");
StringBuffer k = new StringBuffer();
// 这里 Key 包含 Mid 和 Sex
String keys = k.append(records[0]).append("\u0009")
.append(records[1]).toString();
// 接下来对剩余维度数据进行循环
for(int i=2;i<records.length;i++){
// 解决两个问题, 和 Spark 类似
// 确定与该用户关联的用户列表
// 确定关联用户在每一个维度的累计频数
}
for(int j=2;j<records.length;j++){
// 循环计算用户关联得分, 和 Spark 类似
}
/**
* 设置用户 Mid 和 sex 作为 Map 阶段传输的 Key, 用户关联维度用户集作为 value 传输到 reduce 阶段
*/
context.write(new Text(keys.toString()), new Text(value.toString()));
}
}
Reduce 阶段(这里用不上)
public static class dealReduce
extends Reducer<Text,Text,Text,Text> {
public void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException{
/**
* 一般都会用 Reduce 阶段,但是这里用不上
*/
for (Text val : values) {
}
}
}
Drive 阶段
public static Boolean run(String input,String ouput)
throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "");
job.setJarByClass();
job.setMapperClass();
job.setReducerClass();
job.setNumReduceTasks(10);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path output = new Path(ouput);
FileInputFormat.setInputPaths(job,input);
FileOutputFormat.setOutputPath(job, output);
output.getFileSystem(conf).delete(output,true);
Boolean result=job.waitForCompletion(true);
return result;
}
上面这三个阶段就是 MR 任务常规的流程,处理上述问题的思路其实和 Spark 逻辑差不多。只是这套框架性代码量太多,有很多重复性,每写一个 MR 任务的工作量也会比较大,执行效率我并没有去测试作比较。
如果 Spark 跑线上任务模型会出现不稳定的话,我想以后我还是会迁移到 MapReduce 上去跑离线模型。
总结
说到这里,整篇文章概括起来有三点:
- 讲述了数据清洗在业务场景建模过程中的重要性和流程操作。
- 介绍了两款主流计算框架的适用场景和差异性。
- 更列举了不同数据处理工具在每个业务场景下的优势和不同。
但是,还是那么一句话——使用什么技术不在乎,我更迷恋业务场景驱动下的技术挑战。
与你沟通最关键的,也许会是直属领导,也许会是业务运营人员,甚至是完全不懂技术的客户。他们最关心的是你在业务层面上的技术方案能否解决业务痛点问题。
所以,做大数据挖掘要多关心业务,别一味只谈技术。
作者介绍
汪榕,3 年场景建模经验,曾累计获得 8 次数学建模一等奖,包括全国大学生国家一等奖,在国内期刊发表过相关学术研究。两年电商数据挖掘实践,负责开发精准营销产品中的用户标签体系。发表过数据挖掘相关的多篇文章。目前在互联网金融行业从事数据挖掘工作,参与开发反欺诈实时监控系统。微博:乐平汪二。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




