除了单体应用的代码,我们的项目还由几十个微服务组成。这些微服务都需要加以监控,而这些事情全部让 DevOps 工程师来做是不太可能的。所以我们开发了一个监控系统,为开发者提供服务。他们可以自由的配置监控系统,使用它们构建多维度的报表,设置阈值触发报警。DevOps 工程师只需要提供基础设施的信息和文档。
这篇博文是我在 RIT++ 的演讲稿。我们收到很多希望获取文字版本的 RIT++ 演讲的材料。如果你参加了会议或者看过录屏,你会发现本文和视频内容是一致的,如果没有参加或者看过,那么请参考本文,我会告诉您我们是如何演进到现在的方案,如何实现以及未来的计划。
过去:布局和计划
我们是如何演进到现在的监控系统的?为了回答这个问题,我们需要回到 2015,当时是这样的:
(点击放大图像)

我们有 24 个节点的用来负责监控,其中有大量的定时任务、脚本、后台进程用于监控和发消息、执行任务等等。我们意识到如果我们沿着这个方向走得越远,我们的系统会变得越难以维护,继续开发这个系统变得没有意义,太容易失控了。
我们决定在现有的系统中挑选一些能够重用的模块继续开发和维护,另外的都抛弃。这样我们选出了 19 个应用继续开发。这些仅仅包含了 Graphites、数据聚合器、Grafana 仪表盘。那么我们的新系统长什么样?如下图所示:
(点击放大图像)

我们有一个 metrics 仓库 — 高速 SSD 磁盘的图形化展示和指标聚合。同时,Grafana 负责仪表盘显示,Moira 负责报警。我们也需要开发一个系统来捕获所有的异常信息。
标准: Monitoring 2.0
这是我们 2015 年的状态。但我们不仅仅需要开发基础架构和服务本身,我们还需要写文档。我们开发了一个协作标准,叫做 Monitoring 2.0。 系统需求如下:
- 24/7 高可用,
- 指标存储间隔 = 10 秒,
- 结构化存储指标和报表,
- SLA > 99.99%,
- 通过 UDP 收集所有事件数据。
我们需要 UDP,因为我们有海量的流量和很多指标产生的事件。如果他们都实时存储到 Graphite,那么仓库会被压垮。我们还为所有指标选定了第一层前缀。
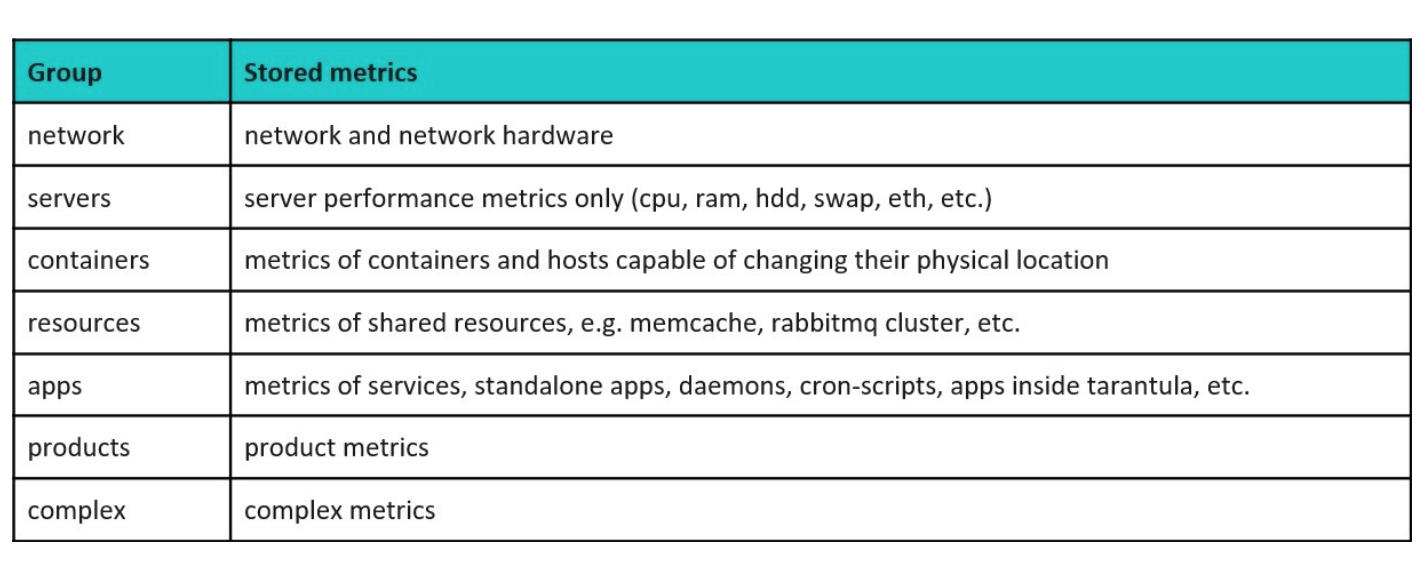
每个前缀都有一些属性,我们有服务器、网络、容器、资源、应用等等的监控数据。我们通过记录第一段前缀,去掉其他部分的方式来提供清晰的、严格的、基于类型的过滤。这就是我们看到的 2015 年的状态。而今天系统是什么样的?
今天: 监控组件之间的交互
第一,我们监控应用,包括我们的 PHP 代码、应用、微服务等等, 总而言之,即所有开发者所写的代码。所有应用通过 UDP 发送数据到 Brubeck 聚合器 (statsd, C 语言实现). 在综合测试中它性能最好。Brubecks 通过 TCP 发送聚合数据到 Graphite。
它有一类独特的指标叫 — timers。它们非常方便。例如,每个用户连接到服务,你可以发送服务的响应时间到 Brubeck。甚至发送 1 百万个响应时间的时候,Brubeck 聚合器也只生成 10 条数据。你可以知道访问人数的最大,最小值,平均响应时间。然后数据被转发到 Graphite,这样大家都能够看到。
我们也聚合硬件和软件的监控指标,系统指标和传统的监控系统 Munin (我们一直用到 2015 年) 的指标。我们使用 CollectD 收集所有的数据 (它内嵌了很多插件,可以查询出任何主机安装的资源,你只需要指定数据应该存到哪里) 然后发送数据到 Graphite。它也支持 python 插件和 Shell 脚本,所有你可以开发自定义的方案: CollectD 会从本地或者远程收集数据 (假设已有 Curl) 发送数据到 Graphite。然后,所有收集的数据会发送到 Carbon-c-relay。这是 Graphite 的 Carbon Relay 方案,用 C 语言修改。它作为一个路由收集所有聚合器发送过来的数据以及路由到这些节点。在路由的时候,它会检查所有监控数据。第一,他们必须匹配前缀,第二,他们必须符合 Graphite 的规范。否则就丢弃掉。
随后 Carbon-c-relay 发送数据到 Graphite 集群。作为主要的监控数据仓库,我们用 Go 修改了 Carbon-cache。因为它的多线程能力,Go-carbon 比 Carbon-cache 要强大很多。它获取数据,使用 whisper package 写入磁盘 (python 实现的标准包)。从我们的数据仓库读取数据,我们使用 Graphite API。它会比标准的 Graphite WEB 要效率高很多。数据接下来会如何处理?
数据会被发送到 Grafana。作为主要的数据源,我们使用 Graphite 集群,用 Grafana 作为统一的门户来显示监控数据,构建仪表盘。对于每个服务,开发者构建自己独有的报表。然后二维图形会显示来自他们应用的监控数据。除了 Grafana,我们还用 SLAM。这是一个用来基于 Graphite 的数据分析 SLA 的 python 进程。正如我所说,我们有几十个微服务,每个都有定制化的需求。我们使用 SLAM 查看文档,对比 Graphite 的数据,并且评估服务的可用性是不是达到了指标。
报警是下一步。它是基于 Moira 构建的强大系统。它内置了 Graphite,由 SKB Kontur 团队研发,使用 Python 和 Go 语言进行开发, 并且它是 100% 开源的。Moira 获取和 Graphites 相同结构的数据。如果出于某种原因仓库宕机,报警功能仍然能够工作。
我们将 Moira 部署在 Kubernetes,用 Redis 集群作为主要的数据库。因此,我们的系统是具备容错能力的。它依据一些列触发器来对比监控数据:如果监控数据项没有被匹配,则丢弃这些数据,所以它具备每分钟处理 GB 级别的数据。
我们也做了和 LDAP 的对接,得益于此,公司内部所有的员工都能够为已有的触发器设立报警。因为 Moira 已经自带 Graphite,它支持所有 Moira 的功能。所以,你可以选择一行代码拷贝到 Grafana,看看数据展示的如何,如果结果不错,你可以将这行代码拷贝到 Moira。设计阈值你就可以有一个报警了。你不需要特殊的技能就能做得到。Moira 可以通过 SMS, email, Jira, Slack, 等等发送消息。它也支持执行用户的脚本。当它被触发,且被脚本或二进制包订阅了,它会执行这个二进制文件,并且发送 JSON 到二进制的 stdin 里。你的程序需要解析这些数据,这取决于你想要怎么处理这些数据,例如发送数据到 Telegram,在 Jira 里自动创建任务等等。
对于报警功能,我们使用自己专有的方案 — Imagotag。我们支持了商场里的电子价签的需求。我们用它显示 Moira 的触发器。它会显示它们的时间和状态。一些开发者取消了 Slack 消息和邮件的订阅,而以此仪表盘取而代之了。

因为我们的业务是靠产品功能驱动的,我们也用这套系统监控 Kubernetes,我们使用 Heapster 引入了这套系统,部署到集群环境里收集数据,发送到 Graphite, 从而实现 kubernetes 的监控。结果如下图所示:
(点击放大图像)

监控组件
下面是我们使用到的所有组件,他们都是开源的。
Graphite:
- go-carbon: github.com/lomik/go-carbon
- whisper: github.com/graphite-project/whisper
- graphite-api: github.com/brutasse/graphite-api
Carbon-c-relay:
github.com/grobian/carbon-c-relay
Brubeck:
github.com/github/brubeck
Collectd:
collectd.org
Moira:
github.com/moira-alert
Grafana:
grafana.com
Heapster:
github.com/kubernetes/heapster
统计数据
这里有一些我们系统的性能数据:
Aggregator (brubeck)
数据条数: ~ 300,000/ 秒
发送数据到 Graphite 的时间间隔: 30 秒
物理资源使用率: ~ 6% CPU (这里指的是包含全服务集合的服务器); ~ 1 Gb 内存 ; ~ 3 Mbps 内网带宽
Graphite (go-carbon)
数据条数: ~ 1,600,000/ 分钟
数据刷新时间间隔: 30 秒
数据持久化时长: 30 秒 35 天, 5 分钟 90 天, 10 分钟 365 天 (可以了解服务在一段持续时间内表现的如何)
物理资源使用率: ~ 10% CPU; ~ 20 Gb 内存 ; ~ 30 Mbps 内网带宽
灵活性
我们十分受益于灵活的监控服务。为什么它如此灵活?第一,它的组件是可以变化的,包括它的组件本身和版本。第二,它具备很好的可维护性。因为整个项目是基于开源方案搭建的,你自己可以修改代码,变更,实现需要的功能。我们使用的是非常常见的软件栈,以 Go 和 Python 为主,所以很容易实现新功能。
这有一个实际的例子。在 Graphite 中一项指标是一个文件,都有一个名字。文件名即为指标名。另外它还有一个路径,在 Linux 里,文件名被限制在 255 个字符内。有些来自数据库团队的内部用户,他们说:“我们要监控我们的 SQL 查询,这些查询并不止 255 个字符,而是有 8 MB 那么大。我们需要让它显示在 Grafana 里,查看查询的参数,或者更进一步,查询所有 SQL 语句的热度。如果能实时显示这些信息将会更好,理论上,它们也应该集成报警功能。”
这有一个来自 postgrespro.ru SQL 查询的例子:
我们搭建了一个 Redis 服务,然后使用我们的 Collectd-plugins 连接到 Postgres,并获取数据,发送数据到 Graphite。但我们使用哈希码替换了数据名。同样的哈希码会被发送到 Redis 作为数据的 Key,将整个 SQL 查询作为值。剩下的事情交给 Grafana 去连接 Redis,并获取数据。我们开放了 Graphite API, 因为它是所有监控模块和 Graphite 之间的主要接口。当进入到 Grafana 的一个新方法 aliasByHash (),我们可以获取数据的名字,将名字作为 Redis 查询的 Key,返回值即是我们的 “SQL 查询”。因此,本来理论上不能显示的 SQL 查询,我们也可以显示,并且能够显示其他数据,包括调用次数,行数,总时间等等。
总结
可用性。对于任何应用,任何代码,我们的监控服务是 24/7 高可用的。如果你有权限访问数据仓库,你可以自行写入数据,不用关心语言和方案,你只需要知道如何开启 Socket 通信,上传数据,然后关闭 Socket。
可靠性。所有组件都具备容错性,在我们的现有的压力下表现的不错。
低门槛。如果想使用这个系统,你不需要了解 Grafana 的语言以及如何查询。你只需开发你的应用,建立 Socket 连接到 Graphite 并发送数据,然后关闭 Socket,打开 Grafana,新建仪表盘,然后就可以通过 Moira 的消息通知监控你的应用指标了。
自助式。所有这些都可以被自助式的使用,而不需要 DevOps 工程师的协助。这是一个显而易见的好处,因为你可以立刻开始监控你的项目,而不需要寻求其他人的帮助,既可以直接使用,也可以自定义开发。
我们追求的是什么?
下面列出的不仅仅是大概的想法,而是实际的目标,以及目前实现了的内容。
- 异常捕捉。我们希望建立一个连接到 Graphite 数据仓库的服务,使用不同的算法检查监控数据。我们已有算法来显示我们想要查看的东西,我们有数据,知道如何处理。
- 元数据。我们有很多服务,它们随时会更新,支持,使用它们的人也会变好。人工维护文档并不可行,因此,我们将很多元数据注入我们的微服务。元数据会记录谁开发了这个服务,支持什么语言,SLA 的要求,通知回执以及地址。一旦服务被部署,所有数据实体都会被独立地创建。因此,你会得到两个链接,一个是触发器,另一个是 Grafana 的仪表盘。
- 自助式的监控系统。我们认为所有开发者都应该使用这个系统。在这里,你可以随时知道你应用的流量压力在哪,发生了什么,问题和瓶颈在哪。如果服务中的某些部分挂掉了,通知你的不是来自客户服务提供商的电话,而是来自你的报警系统,并且可以立刻打开日志查看发生了什么。
- 高性能。我们的项目在持续的增加,目前已经产生将近每分钟 2,000,000 条监控数据,一年前,这个数字是 500,000。同时,我们仍在增加,过一阵 Graphite (whisper) 将会引爆子系统的磁盘。正如我所说,由于组件的易变性,我们的监控系统是非常通用的。某些人特别为 Graphite 选择扩容机器,但我们选择了另一条路,使用 ClickHouse 作为数据仓库来存储监控数据。这个转变即将完成,关于这部分我会很快介绍更多细节,包括我们做了什么,如何做的 —遇到什么挑战,如何解决,如何做迁移;我会介绍基础组件和他们如何配置。
感谢冬雨对本文的审校。




