本文整理自 #ArchSummit 微课堂#–赵成分享的蘑菇街 DevOps 实践及心路历程,主要介绍一些运维体系建设中的的经历和实践, 什么是 DevOps?为什么是 DevOps? 蘑菇街 DevOps 实践案例分享(持续集成与发布);运维一路走来的切身感受和思考,DevOps 带给我们的一些感悟和启示一并分享。
一、蘑菇街简介和运维发展过程
1、首先可能有很多同学还不是很了解蘑菇街,所以一张图简单介绍下:

我们现在的 APP 群

2、蘑菇街的技术和运维发展过程,这部分内容我在 AS2015 北京的专题演讲上分享过,但是为了本次分享的连贯性,所以这里还是再介绍一下
早期阶段(2011-2012)


这个阶段的运维很简单,确实没有什么过多写的,所以留白很多。原因么,早期的蘑菇街工程师真的是我见过的最具极客精神的一批工程师,写代码(前后通吃)、调 SQL、敲 Shell&Python&Perl、扛机器、拉网线统统都能搞定,我认为这才是真正意义上的全栈~
中期阶段(2013-2014)
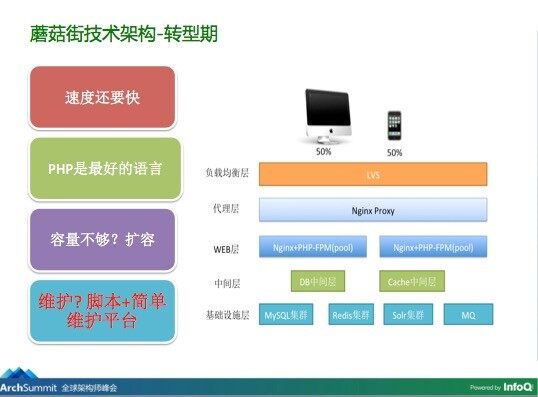

这个阶段的运维已经开始朝工具化的方向发展,这个时候我们没有靠堆人去做一些人肉运维的事情,从思路上还是非常正确的,虽然人不多,但是仍然把很多的精力花在一些自动化的工作,对维护效率的提升有很大的作用。
现阶段,2014 底 - 至今
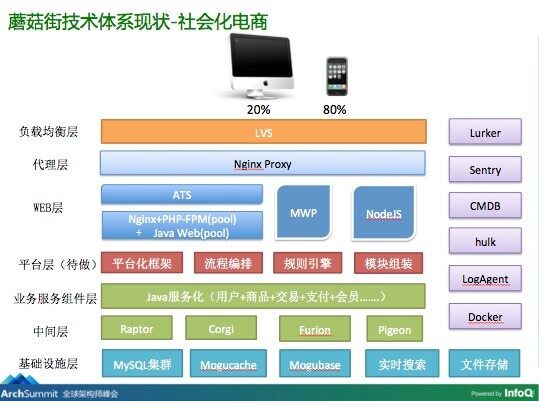
OK,到了这个阶段,技术架构上发生了很大的变化,主要是 PHP 向 Java 的转变。原来我们的业务开发一直是以 PHP 为主,随着业务复杂度增加,为了能够更灵活地响应需求变更,也为了架构上的灵活扩展,通用的思路我想大家也可以推测出,就是进行 Java 服务化的改造,将一个大的应用和一套代码,根据业务特性拆分成不同的服务,服务之间的调用通过 RPC 服务化框架来编排。
2014 年底的时候,运维开始逐步要面对“从几个应用,拆分成几十上百个应用,后面可能还会继续扩展“的问题,这么多应用该怎么管理?资源应该怎么管理?发布效率怎么提升?服务间的调用该怎么管理?稳定性该怎么保证?这些问题和矛盾暴露后,分别由不同的小组承担起了对应的解决方案设计,到目前为止也都产生出了对应的系统,这个后面会再提到。
这里重点说对运维冲击最大、矛盾最突出的,就是发布效率问题,主要有这么几个原因,可以对比来看,先看 PHP 的发布:
a. 原有的 PHP 代码,开发完成,自验证 ok,就可以把 PHP 文件灰度发布,然后上线,PHP 动态生效,过程相对简单
b. PHP 的应用单一,线上众多的主机只需一套代码就 OK
c. PHP 的技术架构相对简单,不涉及复杂的调用,更多的是内部逻辑的实现,对运维来说技术难度不大
但是对于 Java 应用,情况就要复杂的多:
a. 代码开发完成,要涉及打包编译、二方包依赖,上线前要将服务下线、应用停止,代码更新完成,启动应用、进行 check,然后再注册上线,环节复杂;
b. 多环境建设问题,因为一个服务可能被众多其它服务依赖,同时又依赖其它众多服务,如何保证服务的功能稳定?就要涉及日常开发、集成测试、预发、线上等环境的建设;
c. 同时应用个数也十几倍的上升,不同的代码要发布到不同的主机上。
d. 服务化之后,RPC 的调用和依赖复杂,服务化框架实现原理等对技术和业务理解的要求明显上升,运维需要快速补充对应的技能,以及完善配套维护手段。
所以运维的发布效率在一段时间内明显已经跟不上开发的节奏,且过多的人肉介入和多环境建设的不完善也导致了故障的频发,经常会碰到一个服务还未下线,就做了升级,导致请求进来后报错、线下的配置发到了线上、应用对应的机器做了变更,但是代码依然发布到老机器上。
同时迫于业务需求的压力,开发对于运维的效率也开始产生质疑和抱怨,矛盾也随之产生。
那问题怎么解决?思路上,就是做持续集成和发布,至于怎么做、做什么,当时没有很明确的思路。我们当时做的几件事情其实比较朴素,踏踏实实、认认真真去做大量开发需求调研、新的技术架构学习、与业界公司进行交流,了解同行业的解决方案。经过一段时间的摸索和我们内部讨论,大致的解决方案也就基本成型。也正是在这个阶段,我们开始深入地去理解和思考 DevOps 的一些理念和方法论。
二、什么是 DevOps?为什么是 DevOps?
为了让大家尽快看到干货,关于 DevOps,这里我只简单提一下,不做过多解读,后面结合案例再细讲我们的理解。
关于 DevOps 的一些定义,如下:
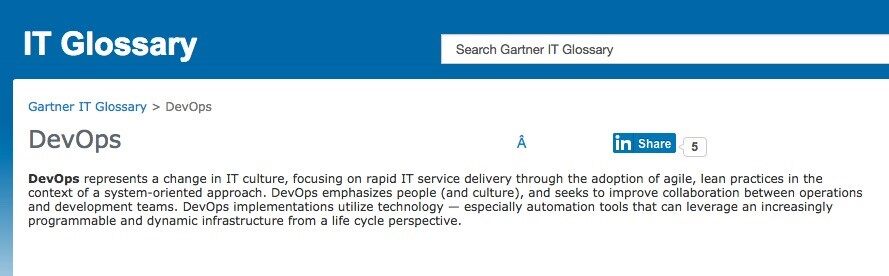
Gartner 的定义: http://www.gartner.com/it-glossary/devops/
WikiPedia 的定义: https://en.wikipedia.org/wiki/DevOps
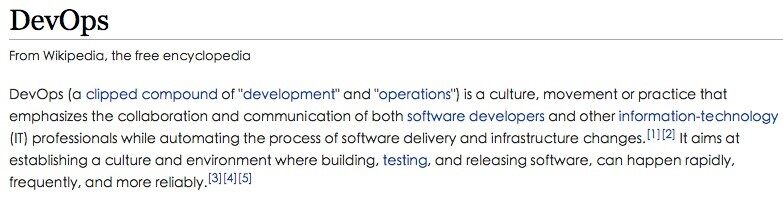
从定义可以看出,DevOps 的理念和方法论的提出,就是为了解决持续和高效的交付问题,强调的是 Dev 和 Ops 的紧密协作,共同打造持续、高效和稳定的交付文化和环境。
所以,我们在方向上也更加坚定下来,持续集成和发布就是我们提升效率的切入点。
三、蘑菇街 DevOps 实践案例分享——持续集成与发布
首先,要讲的一点是,持续集成与发布要依赖三个关键的事物或前提,一个是应用标准化,二是流程规范化、三是 CMDB:
a. 标准化,广义上,网络、主机、IDC、OS、DB、应用等等都需要标准化,但是本文以应用为主,主要讲应用的标准化。只有大家遵守同一套标准,才能够基于这套标准去建设统一的平台。
b. 流程规范化,主要是针对打包、多环境管理、发布流程的规范和约束,只有通过自动化流程的约束,再加上标准的执行,才是完善的体系。
c. CMDB,这个是一切运维自动化或体系建设的基石,或者是运维之根,只有有了它,其它如配置管理、监控、发布、稳定性等等这些运维平台才会有生命力,才能形成体系的力量,不然都将是碎片化的运维模式。
同时,CMDB 的建设也把我们前面提到的应用和资源的管理问题同时解决掉了,这一块的建设,主要靠运维。
关于应用标准化,我直接上图,大家看一下就好,主要是个思路

关于应用标准化的几个关键部分:


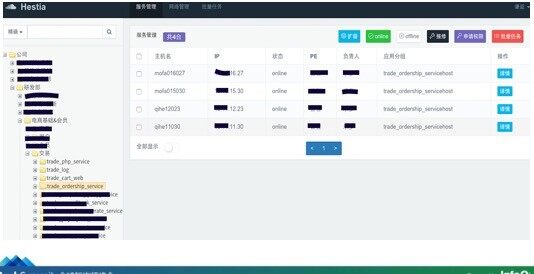
关于 CMDB,这里只说它的一个核心价值,就是通过应用标示(应用名)与硬件资源关联,从而通过应用和业务的维度去管理硬件资源。带两张图,做一下简单的解释:

具体示例如下,trade_ordership_service 这个应用名对应了 4 台服务器,通过“应用名 -IP”的关系来对应:
好了,前面铺垫了这么久,主要想说我们的发布是需要依赖一些基础的能力和工作,这些在后面的功能实现上会有很大的作用。下面正式进入我们的持续集成与发布,同时我们前面介绍的打包规范、发布流程规范和多环境管理会在案例中结合着讲解。
技术概貌及功能的规划,主要分为配置服务、发布服务和数据服务三大部分,主要功能已经在图中进行了详细描述。
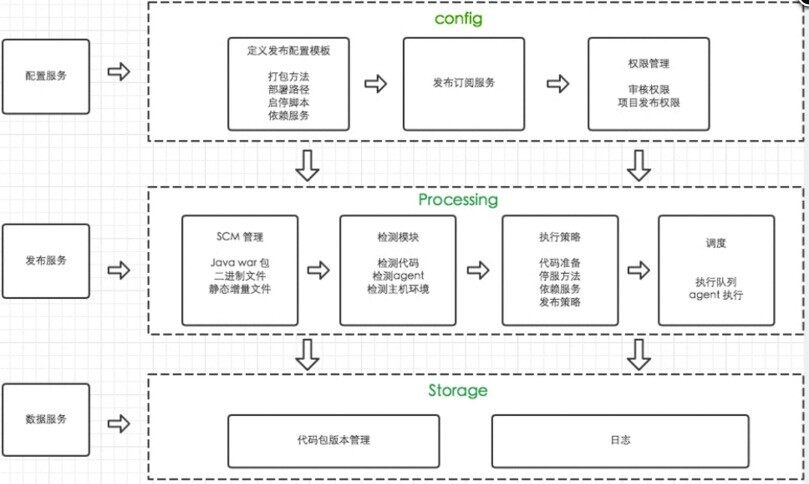
使用到的技术点,内部使用 gitlab 进行代码托管和版本管理,用 maven 作为构建工具以及二方包依赖的管理,用 Go 语言自研开发代码拉取和构建动作的调度引擎,通过前端界面触发各种打包、发布等动作。
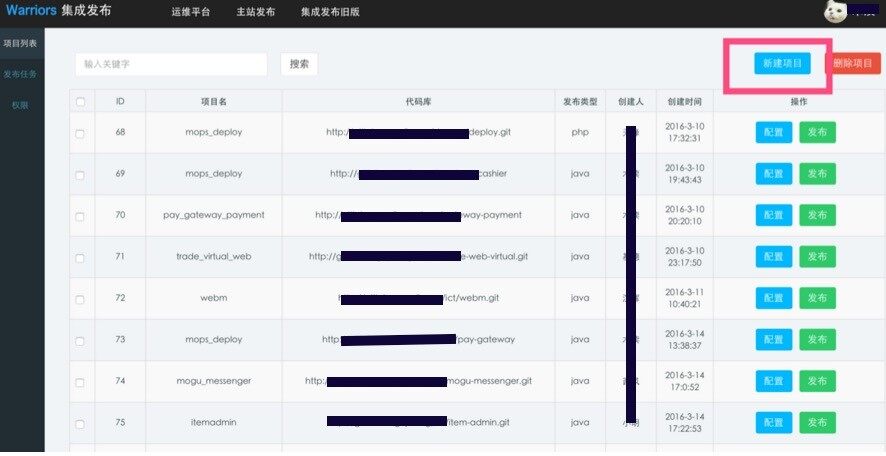
下面结合界面操作截图,进行实际案例的讲解,整个流程上主要是以下 4 步:
- 应用配置
- 发布策略配置
- Build 打包
- 发布到集成测试、预发及线上环境
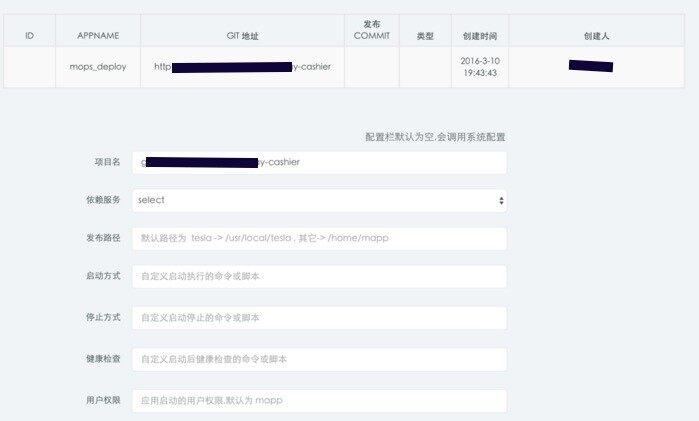
1、创建发布的应用及配置
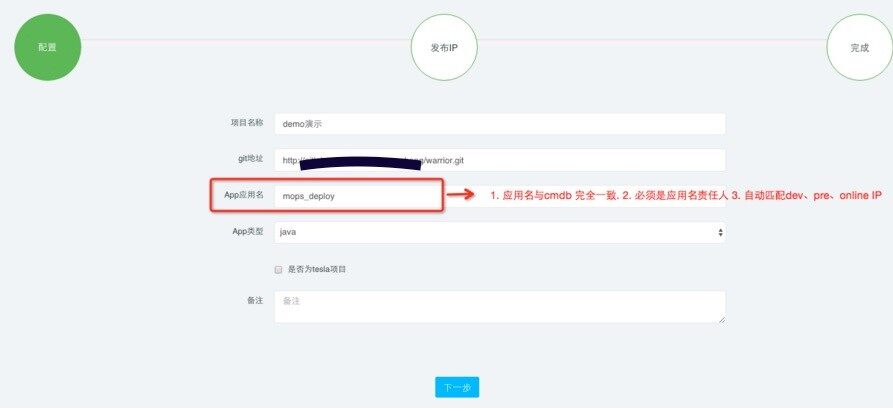

这个步骤主要是创建和配置过程,应用标准化和 CMDB 的威力就发挥出来了,默认情况下,如果一个应用是按照我们之前讲的标准化模板来配置和部署的,那发布系统使用到的发布目录、日志目录、启停和检测脚本目录等都会按照标准去寻找路径,最大程度上简化了发布系统适配的工作量。
同时,发布从本质上讲,是将代码发布到指定的环境和以 IP 地址为标示的机器上,这时 CMDB 中的“应用 - 资源”的关联关系就成为了非常关键的桥梁,发布系统只要关心发布自身的功能即可,而不用过多关注类似应用配置和关系维护的事情。
不过,因为历史原因,有一些老旧的应用标准化改造成本较大,我们也支持灵活地自定义:
2、应用相关的配置完成后,接下来就是发布策略配置
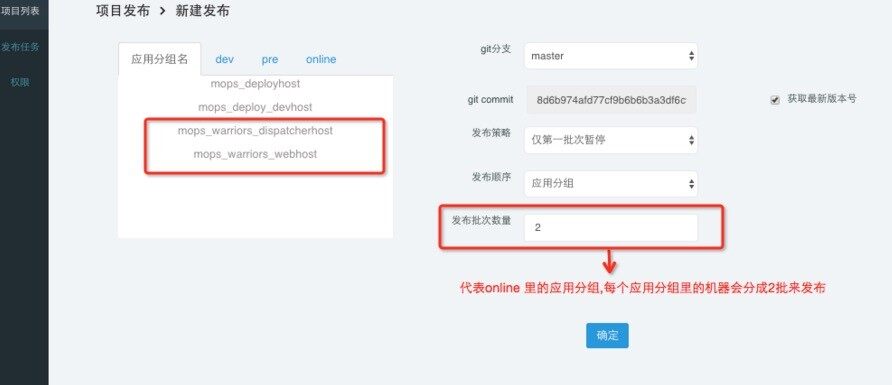
通过 git 发布的时候,会自动拉取 git 分支,同时也可以自动获取最新的 commit。对于线上的发布,一个应用不可能全部下线然后全部升级掉,这样就会出线上故障了,所以对于线上一定是分批次来发布,保障线上服务的持续性。
3、发布策略配置完成,进行 Build 打包
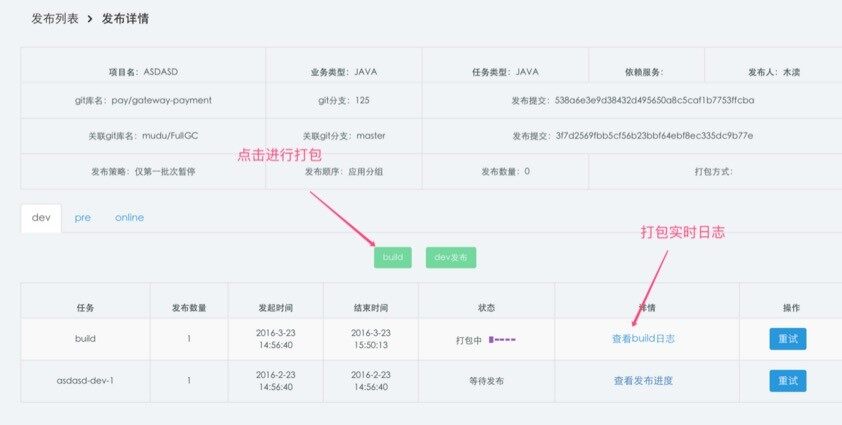
这个过程,就涉及到多环境的配置管理问题,因为要发布到多套环境,所以就需要一套代码 + 多套配置,这个逻辑我们的处理方式是,根据 Build 时选择的环境,规范约定好对应一个配置文件,比如 Dev 环境,就要配套对应一个 dev_config.properties,那打包时我们引擎就会自动从 gitlab 上把这个配置文件获取下来,并转换成正式的 config.properties 文件,最终将代码和配置打包到同一个 war 包中。示例如下:
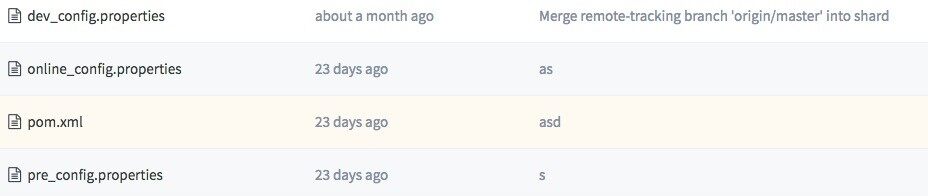
4、Build 打包完成后,进行发布
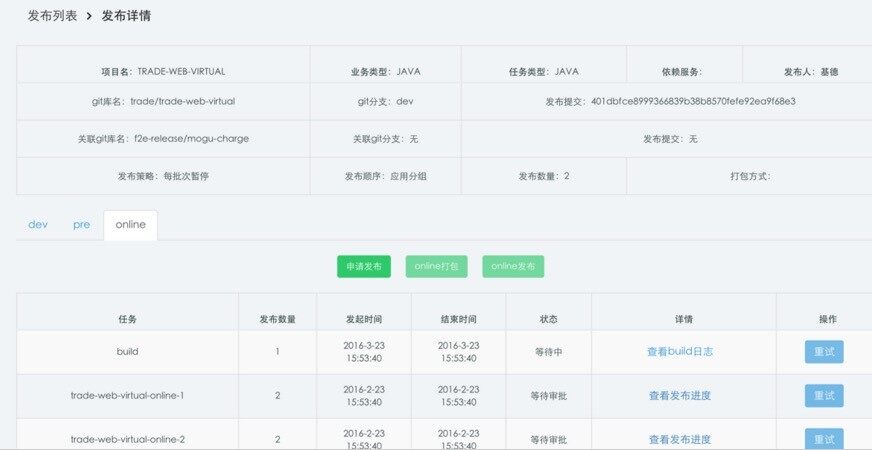
通过左下角 Dev、Pre、Online 进行环境选择,分别对应继承测试、线上预发、线上正式三个环境。并且通过流程上的强约束,要求三个环境的发布必须依次完成,并经过测试验证或主管审批后再进行到下一环节的发布。
对于环境的管理,测试环境完全跟线上物理隔离,预发环境也是完全独立,但是会跟线上共用 DB 和缓存,以最大程度真实的验证版本功能。每一套环境所对应的 IP,实际也是在 CMDB 的应用中做了分组的标示,所以可以看到 CMDB 的基础作用无时无刻不再体现着。
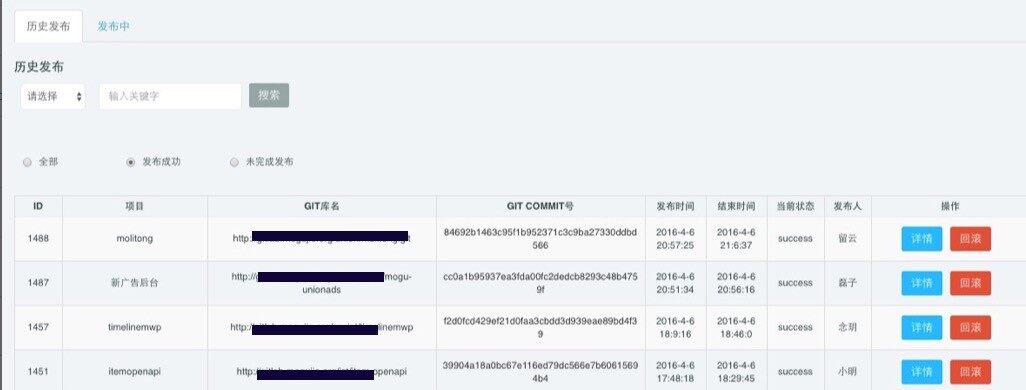
发布或打包过程中,可以通过一个应用的发布详情页查看打包和发布过程以及详细日志
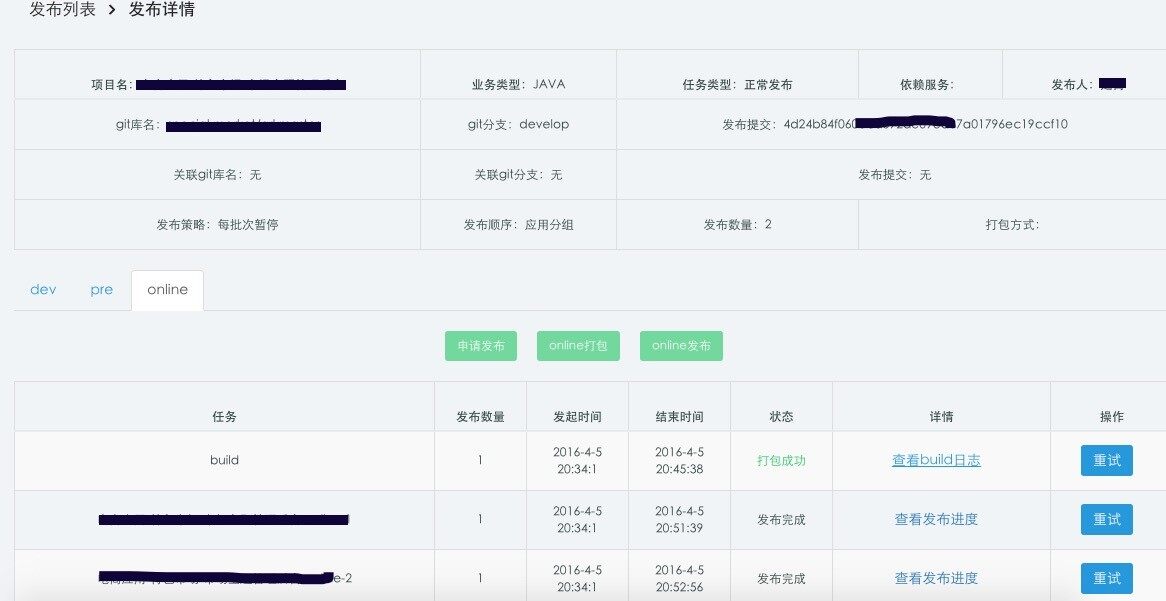
发布过程情况,在某一环节出现问题,可以进行重试
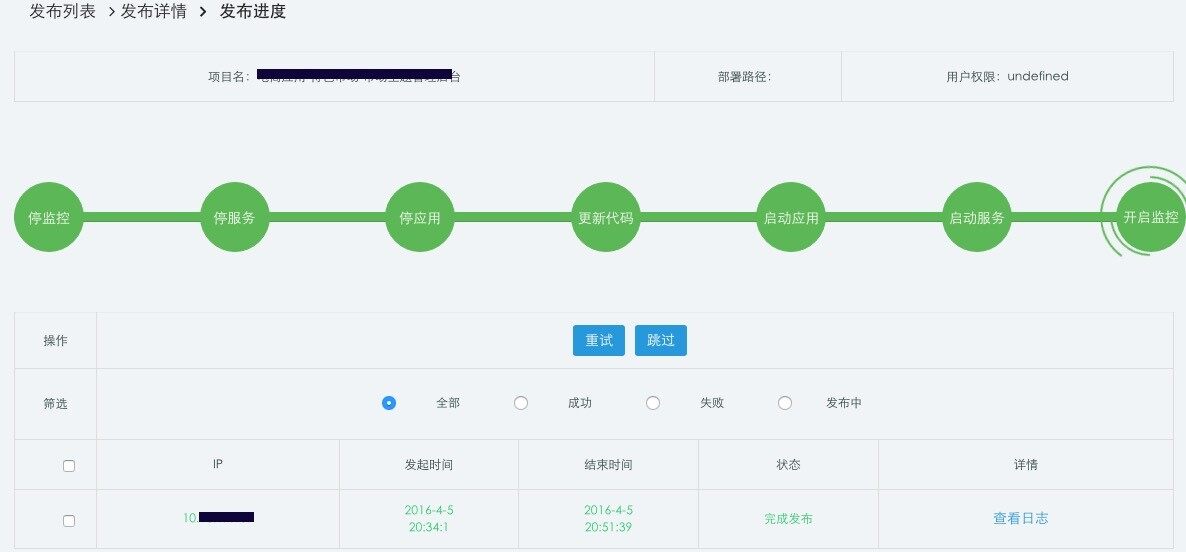
通过查看日志,可以看到后台具体的日志,再出现问题时可以方便快速的进行定位:
至此,一个完整的发布环节完成了,对于已经创建过的应用,则无需前面第一步相对繁琐的配置。直接进入 Build 和发布环节,整个过程中,绝大部分工作实际是由开发同学自助式的完成,但是最后一个线上发布环节,是需要开发主管和运维同学审核通过后才会上线,以便运维同学及时关注线上流量和服务质量情况,以应对发布后可能出现的突发情况。
带来的收益和效果如何呢?
我们直接看数据,目前接入发布系统的应用 200+ 以上,一天内我们目前可以支持三个环境(Dev、Pre、Online)1000+ 次的发布,正式发布到线上 400+ 次。如果还是原来的运维模式进行支撑,效率是明显无法跟上的。
四、DevOps 带给我们的一些感悟和启示
从上面的案例中,我们可以看到,运维同学从原来的大量的繁琐和人肉的发布工作中解脱出来,从一个执行者变成了审核者,可以把更多的精力投入到线上稳定和服务质量的维护中去。而开发同学也不必再过多的依赖运维的“人”,而是依赖运维的“服务能力“,更加高效和灵活地开展各自的开发、测试和发布工作。
整个过程中,Dev 仍然是 Dev,Ops 仍然是 Ops,其实谁也没有替代谁,所改变的只是大家的合作方式和工作方式,Dev 和 Ops 的协作不是越来越分离,而是越来越紧密。而促进这个变革的最主要的技术因素就是,Ops 具备了 Dev 的开发能力。
所以说到这里,对运维同学的一个建议是,运维的同学应该从现在、从自我改变开始,互联网时代我们应该或者说必须要具备开发能力,才能真正发挥出运维的价值和生产力。那我们掌握了开发技能,要去做些什么呢?
这就是 DevOps 带给我们的最大的启示—“我们要做的应当是将运维的能力服务化,让整个体系依赖于运维的服务能力,而不是运维的人“。
所以持续集成和发布只是我们的一个实践案例,我们现在在设计每一个系统的时候,要做的关键的事情,就是怎么最终把人的能力抽象和实现成平台的服务能力。今天限于时间和篇幅,没法再分享其它的一些实践案例,后续有机会可以跟再一起讨论。
最后给出,我们运维的现状:

五、Q&A
Q1:PHP 也有很不错的服务化改造方案实现方案,为什么要切换成 Java 来做?
确实,蘑菇街之前也有尝试过 PHP 的服务化方案,说实话我没有参与这个过程,所以只能谈一下我的理解。
这个从多个角度来看,从技术上来说,对于大并发的网站来说,Java 的并发能力还是先对出众,蘑菇街从体量和每次大促的情况来看,原有的 PHP 技术架构是无法满足性能的需求的,这个就引出了下一个原因,从技术生态上,PHP 的开发我们接触下来,真正有实力去做基础层面优化的人才不多,同样对于 PHP 服务化框架有持续优化和建设的人才也不多。而对比过来 Java 的人才相对就丰富很多,不管从应用开发还是底层优化,包括服务化框架开发等等,从这一点上来说,Java 的反而会更有效率和优势。
Q2:如何保证灰度发布的过程中业务的连贯性?对于携程之前的事故,是否也有相应的预案及预防措施?
我们有三套环境来保障功能的稳定,集成测试、预发和线上。同时线上会预留 1-2 台做极小流量的灰度验证,这个时候线上原有业务是没有影响的,只有灰度 ok 后,再分批发布到线上,这是我们会将正在发布代码的机器下线,变更过程中不会有流量进来。
对于提到的事故,我们的发布是有权限控制的,也就是开发和应用运维都只有自己所负责应用的发布权限,不是线上想发哪台就发哪台,同时如果出现误操作,发布系统也是支持快速回滚版本的。
Q3:DevOps 的关键切入点都是持续部署,往前需要持续集成的能力,理念上与我的实践非常一致。点赞~~ 我的问题是:平台的弹性伸缩,虚拟化能力如何支持? 应用的无状态化设计是如何引导的?
弹性伸缩我们的思路也是针对无状态的应用进行,这一块我们现在做的也不成熟,只能是通过一系列的脚本来完成。不过我们当前在做的一些事情也是为了解决这个问题,比如通过线上单机容量压测系统,通过闲时压测来获得无状态应用的单机容量,再结合线上日常 QPS 等指标,判断当前该无应用状态的集群是否扩容还是缩容。扩容时,我们选择的机器资源是 KVM 虚拟机,后续大促时,我们会跟公有云的厂商合作,进行弹性资源的使用,已解决资源成本问题。
讲师介绍
赵成,ArchSummit 明星讲师,花名谦益,现在负责蘑菇街运维团队的管理以及运维体系的建设工作。在运维行业中已经做了 7 年,之前有过 5 年左右的业务开发经历。加入蘑菇街之前在华为一直做电信级业务的开发和运维工作。
本文根据 ArchSummit 微信大讲堂邀请的大牛线上分享内容整理而成,扫描下方二维码,回复“架构师”,获取参与方式,加入围观大牛线上分享,同步大会筹备近况……





