1. 双 11 大促的业务分析
自 2013 年转型以来,蘑菇街电商平台历经了多次双 11 大促的洗礼。通常而言,大量的商家与商品参与双 11,用户规模相比平时也会剧增。今年双 11,蘑菇街还开辟了微信小程序作为新的支点,希望以此撬动新社交电商战略。平台为用户带来价值的关键是保障商品丰富、价格合理、服务可靠。在此背景下,有很多挑战需要在复杂的业务场景中去应对,其中包括:如何提高商品管理的效率,以及如何改善用户体验。在众多的技术和产品方案中,图像算法作为一项重要能力,运用于电商场景中,支持上述业务问题的改善。
2018 年 1 月 11-14 日,由 InfoQ 举办的 AICon 全球人工智能技术大会将于北京举行,一些大牛将首次分享 AI 在金融、电商、教育、外卖、搜索推荐、人脸识别、自动驾驶、语音交互等领域的最新落地案例,以及机器学习、深度学习、NLP、图像识别等技术如何用来解决业务问题,欢迎前来探讨交流。
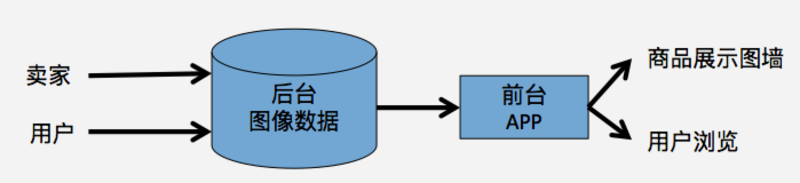
图 1. 电商中的图像数据
如同 1 所示,在电商平台中可以按照业务流向简单地描述图像数据。电商平台从商家或者用户处,获取到不同来源的图像数据,并且存放于后台图像数据库;前台 APP 产品作为面向用户的界面,基于图像数据和业务算法,把商品呈现在用户眼前,主要包括商品展示图墙页面和用户浏览页面。
蘑菇街在实践中,采用了两种类型的图像算法技术支持业务发展。第一个是图像搜索技术,用于后台商品管理和前台搜相似商品;第二个是图像标签技术,应用在商品属性管理的场景中。
2. 图像搜索技术的应用
2.1 技术原理简介
给定一个图像作为 query 输入,基于内容的图像搜索过程是在指定的图像数据库中检索,找到和 query 相同或者内容相似的图像。蘑菇街的图像搜索应用场景主要集中在商品搜索上,既有移动端的搜相似购物,也有后台运营选品的需求等。
大规模商品图像检索所面临的主要挑战包括几个方面:
(1) 图像数据量大,一般电商平台的商品图像包含了主图、SKU 图、商品详情图和用户评论图等,规模达到千万至亿级别。
(2) 特征维度高,图像特征是描述图像视觉信息的基础,特征表达能力直接决定了图像检索的检索精度。
(3) 响应速度要快,检索系统需要具备可以快速响应用户查询的能力,一般要求检索系统能够满足实时或者准实时的要求。
针对这些挑战,蘑菇街图像搜索技术的工作主要集中在两个方面。
图像特征的表达能力
随着深度学习的兴起,利用 CNN 提取图像特征,已成为图像检索领域的共识。商品图片类别众多、背景复杂,如何从丰富的图像信息中提取关键特征依然是很有挑战的问题。图像特征模块主要包含三个重要部分:数据清洗、特征模型设计、模型压缩。
利用 CNN 提取图像特征,关键在分类标签的定义。有文章(ICLR 2017: On the Limits of Learning Representations with Label-based Supervision)指出:模型提取特征能力的上限,不在数据集的大小,而在标签质量。因此,设计监督更强、质量高的标签,更有利于特征的表示。我们的商品标签有两个来源,一个是商品在类目体系中从属的类别,另一个是商家对商品的描述。数据清洗过程主要解决商家打标的标签和图像实际内容不符合的问题。利用自动化图像标签模块,可对商品图片自动打标,辅之以人工矫正。通过这种方式我们累积了数以千万计的样本图像数据,所涉及的标签 label 数目有几千种,从而构建了高质量的训练样本。
特征模型的设计以 ResNet(残差网络) 为基础,根据 ResNet 是浅层网络集成学习的思想(NIPS 2016: Residual Networks Behave Like Ensembles of Relatively Shallow Networks),我们通过设计不同尺度卷积核并拼接(Concat)在一起,提高了浅层网络的表达能力;同时适当控制深度,并改进 ResNet 中影响优化的 Shortcut 结构。试验证明网络的改进是有效的,改进后的网络在实际数据集合上的 top1 accuracy 是 61.8%,而传统的 ResNet-50 是 56.6%。
特征模型部署在 GPU 服务器上,为控制系统的整体响应时间,需要缩短特征提取的时间,因此要对深度学习网络模型进行压缩。压缩算法采用的是(ICLR 2017: Pruning Filters for Efficient ConvNets)所提到的剪枝策略。具体的做法是:针对每个卷积核计算其绝对值和,然后排序,针对绝对值小的权值和通道进行剪枝。流程中包括两个主要步骤:首先按照一定比例 (比如 10%) 进行压缩,然后进行模型的 fine-tunning 训练;两者交替迭代进行,直至模型精度的下降超过预设的目标,流程结束。最终我们所获得的特征模型在 GPU 卡 K40 上,单次特征抽取的时间在 40ms 内。
近似最近邻查找
鉴于搜索数据库数据量级很大,对每个查询都要计算所有的距离是非常困难的,同时存储数千万图片的高维残差网络特征向量需要耗费巨大的存储空间。为了解决这些问题,采用了近似最近邻算法中的局部优化的乘积量化算法(Product Quantization,PQ),训练得到粗量化质心和细量化质心,粗量化的结果用来建立倒排索引,细量化的结果用来计算近似距离。通过这种方法,既能保证图像索引结果的存储需求合理,也能使检索质量和速度达到更好的水平。
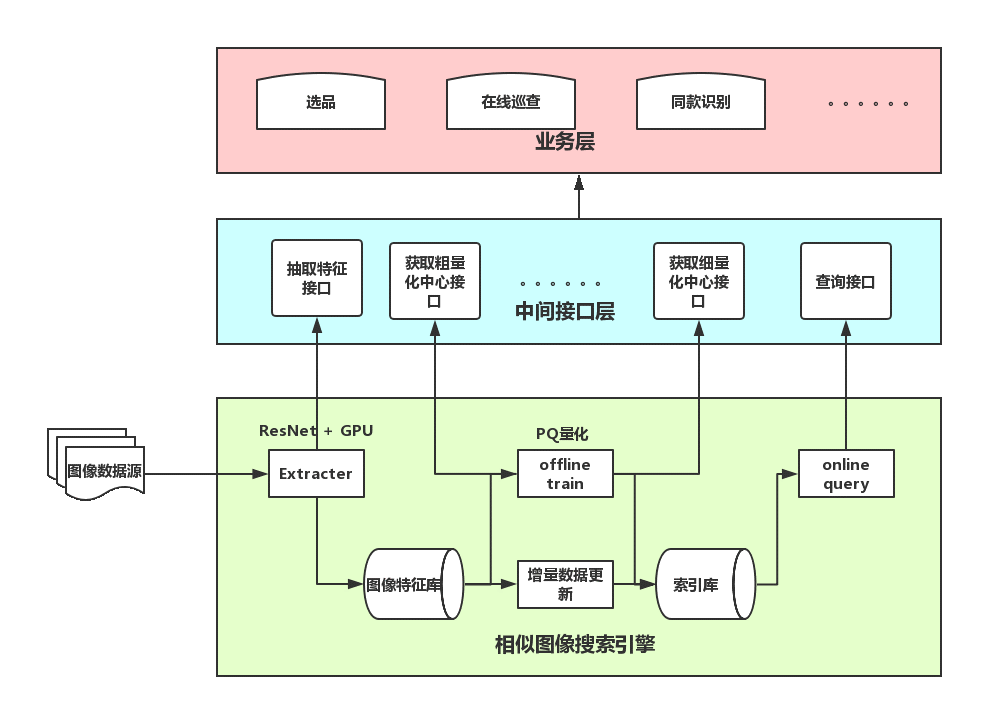
图 2. 图像检索的系统架构
图像检索系统的整体架构如图 2 所示。基于底层的图像搜索算法,通过中间接口层提供给具体的业务使用,提升了相似图像搜索的扩展性,能够快速地响应实际的需求和应用。
2.2 应用 1:同款商品识别
电商基础业务中,需要审核商家上传的商品图片。我们在实践中基于相似图像搜索技术,构建了同图识别系统。系统产出了全量图像数据的索引库,基于相似搜索引擎来查询商家图片是否为商品库中的相同图像。根据查询结果,结合业务规则,判断商品是否为同款。图 3 给出了同款商品识别的系统概要图。
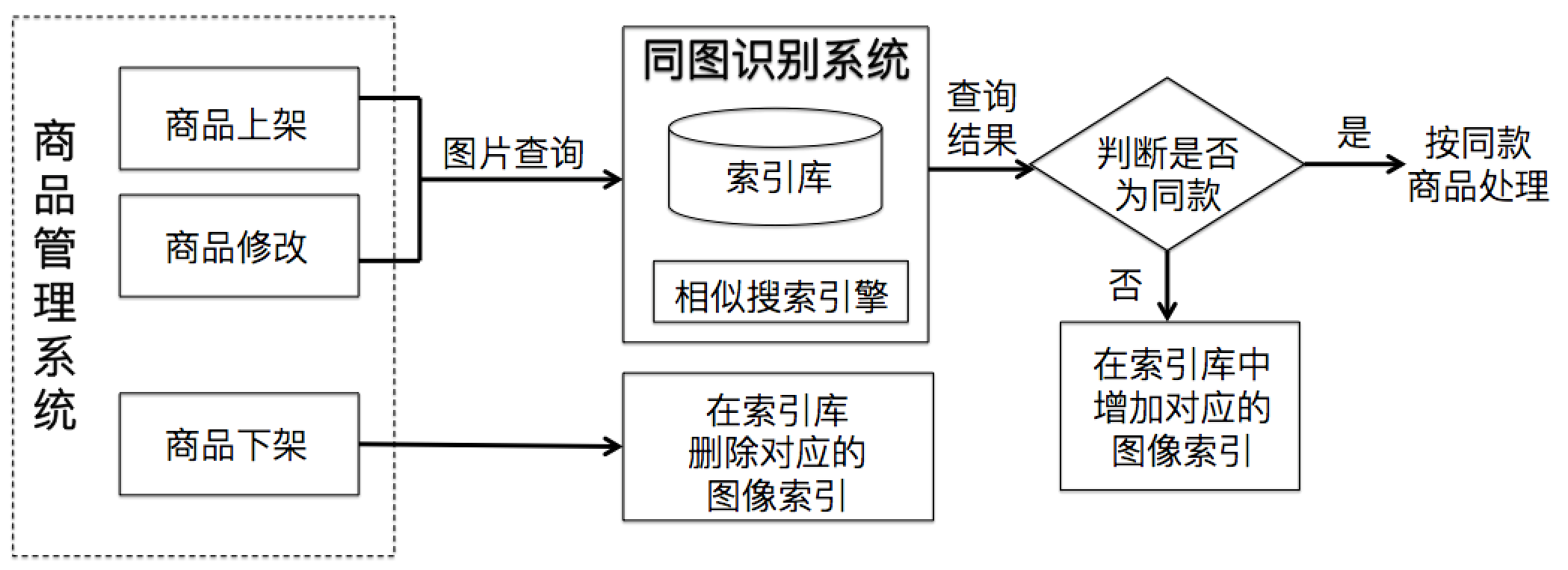
图 3. 结合图像信息的同款商品识别
目前该系统部署在蘑菇街电商平台中,提升了商品管理的效率。在亿级图像索引规模下,系统识别准确率为 99.06%,单张图像查询的整体响应时间为 20ms。
2.3 应用 2: 移动端搜相似商品
蘑菇街 APP 上提供了搜相似商品的功能。如图 4 所示,其过程是点击单个商品图像右下角的搜索图标,将与该图像相似的同类商品展现给用户。
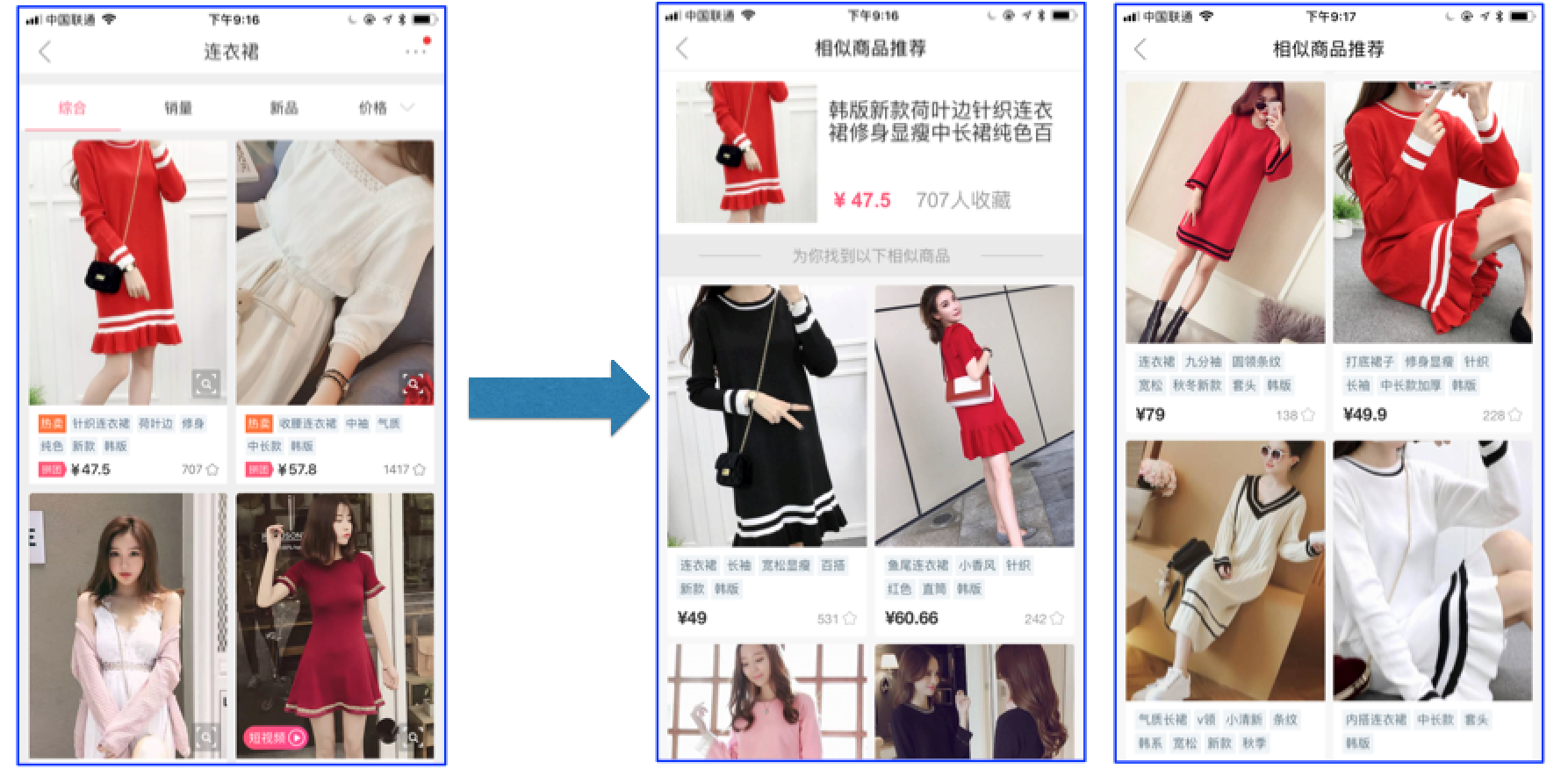
图 4. 搜相似的用户界面 (左 (a) 商品展示原图,右 (b) 相似商品列表页面)
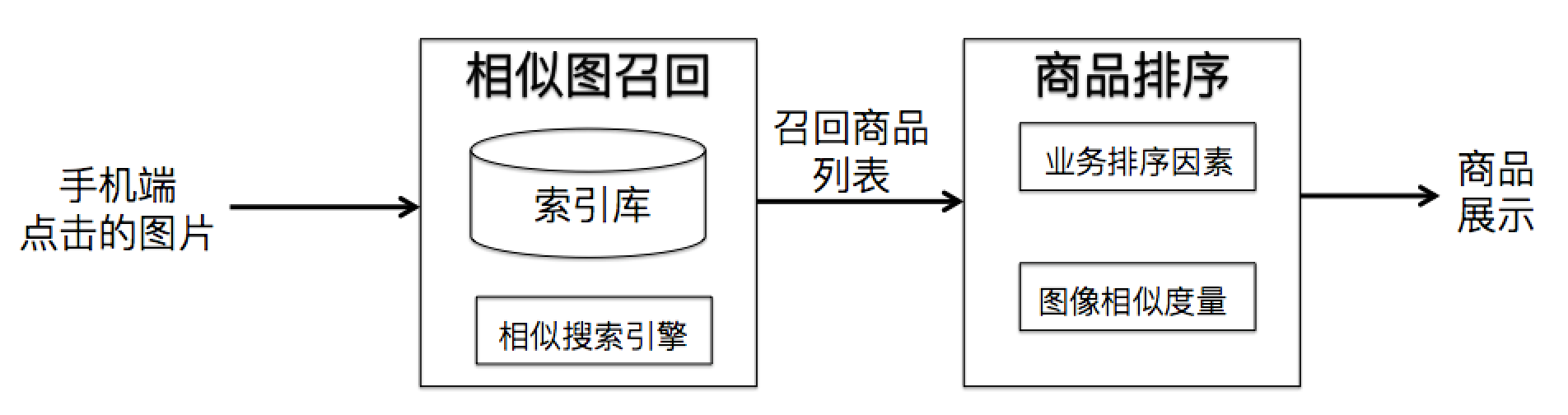
图 5. 搜相似商品的系统概要图
图 5 展示了系统概要图。在实现过程中,采用了图像搜索技术来承担相似图像查询,从而召回相似商品列表,然后结合业务因素和图像相似性,进行商品排序。通过该功能,能够提升用户在蘑菇街 APP 上的浏览体验,有利于发现更多相似商品;同时,用户的停留时长也有所增加。
3. 图像标签技术应用
3.1 技术原理介绍
图像标签技术的任务是通过图像算法,自动识别图片内容,如场景、风格、主体名称、颜色、图案等。通常来讲,在电商中对商品图片做图像标签的处理流程如图 6 所示,其中所涉及到的技术模块简述如下。
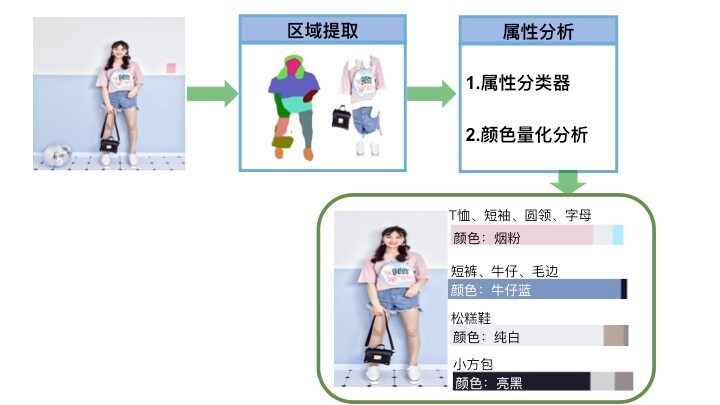
图 6. 图像标签处理流程
区域提取
这个阶段利用图像分割技术,将商品主体从背景中分离出来。以服装图像为例,区域提取的目标是对图片进行精细化语义分割,排除背景与服装、服装与服装之间的相互干扰。针对服装模特图片,我们通过 Human Parsing 算法,把主要区域提取出来,例如:头肩、上衣、裤子、鞋、包包等。
图像语义分割是图像理解的基础技术,在服饰信息分析、自动驾驶系统(具体为街景识别与理解)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。众所周知,图像是由像素组成,语义分割就是将像素按照图像中表达语义含义的不同进行分组和分割。如图 6 所示,紫色区域表示语义为“上衣”的图像像素区域,荧光蓝代表“下装”的语义区域,军绿色表示“包包”,橙色则表示“鞋子”区域。在图像语义分割任务中,输入为一张 H×W×3 的三通道彩色图像,输出则是对应的一个 H×W 矩阵,矩阵的每一个元素表明了原图中对应位置像素所表示的语义类别(Semantic label)。因此,图像语义分割也称为“图像语义标注”。
在语义分割领域,全卷积网络 (Fully Convolutional Networks,FCN) 推广了原有的 CNN 结构,在不带有全连接层的情况下能进行密集预测。FCN 使得分割图谱可以生成任意大小的图像,且与图像块分类方法相比提高了处理速度。实际上几乎所有关于语义分割的最新研究都采用了 FCN 结构;不过该框架中的池化层在增大上层卷积核的感受野、聚合背景的同时,却丢弃了部分位置结构信息。
在服装语义分割中,人体结构和服装位置之间的相对关系,对提高分割效果来说至关重要。我们在实际工作中,借鉴了 DeepLab 论文(DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv:1606.00915, 2016) 的空洞卷积(Atrous Convolution)思想,保留了池化层中所舍弃的位置结构信息。
丢失的位置结构信息主要由于重复池化和下采样造成,因此我们的网络中移除了最后的若干个最大池化层下采样操作,并对滤波器进行上采样,在非零的滤波器值之间加入空洞,进行空洞卷积。如图 7 所示,(a) 中的常规卷积只能获取到较小感受野上的稀疏特征;(b) 中方法采用空洞卷积后可以得到较大感受野对应的更丰富特征,对应到服装语义分割也就保留了人体和服装之间的位置结构信息,有助于服装分割效果的提升。
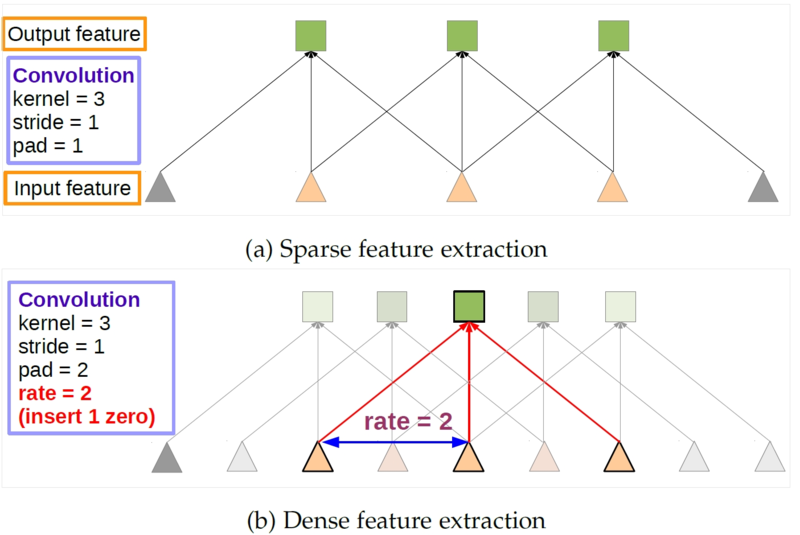
图 7. 图像语义分割中的卷积操作
属性分类
根据电商业务特点,主要从三个不同的维度来定义标签体系,包括类目、元素、颜色。类目主要描述商品是什么,元素和颜色体现商品有什么样的性质。
我们定义的类目包括服装类、生活类、化妆品,元素范围包括风格、纹理、版型等。以服装为例,标签信息比较复杂,覆盖到服装的多级类目、颜色、领型、衣长等,这导致同一张图存在多个标签。在实际工作中我们聚焦于以下两个方面的属性分类解决方案。
- 标签的层级关系建模。
电商商品的层级类目结构导致一件商品具有层级化的标签,例如 T 恤:它的一级类目是服装,二级类目是上衣,三级类目是 T 恤,因此一件 T 恤的商品图单类目标签就有 3 个。根据不同标签和相应的数据训练单独获得 3 个模型是一个可行方法,但是系统复杂度过高。
我们采用多级 word tree 结构来实现一个整合多套标签的模型,同时用标签间的关系来约束输出,概率表示为:P(T 恤)=P(T 恤|上衣)*P(上衣)。根据这个思路设计,用一个模型就能表示出层级关系的多套标签,不仅充分利用了同一批数据,而且通过条件约束之后输出的标签更精准。
2. 标签的多维度特性。
对于同一件商品会有不同维度的信息描述,以 T 恤为例,它有衣长、领型、袖型等维度的信息。因此对于多维度的标签模型,我们采用多任务(multi-task)的方法,用一个网络同时提取不同维度的图像特征,能够统一描述图片内容。
在实际系统中,我们利用了百万级别的样本进行模型训练,基础模型的网络结构是残差 18 层网络(ResNet-18)。业务测试中类目的准确率是 92.46%,元素分类的准确率是 91.10%。
颜色量化分析
用色彩来装饰自身是人类的原始本能,色彩在服饰审美中有着举足轻重的地位,自古至今都是服装三大要素之一,因此服装颜色标签识别是重要部分。通过区域提取过程获得上衣、裤子等服装单品的区域后,对单品图像采用改进的 Mean-Shift 算法进行颜色聚类,得到服装单品的主要颜色占比。
实际应用中,蘑菇街商品图片的颜色会受到拍摄光线和滤镜处理的影响,这给我们的颜色识别带来了挑战,主要表现为两个方面:
- 颜色空间的选择:不同的颜色空间有不同的特点,Lab 色彩空间具有单独的亮度通道,因此为了减小光照对聚类算法的影响、提升颜色聚类的准确度,我们会在 Lab 色彩空间对图片色彩进行一定的矫正,再进行颜色聚类,以尽可能减少光照和滤镜对颜色识别的影响。
- 服装色卡定义:根据蘑菇街服饰颜色分布及商品标签需要,定义了蘑菇街标准的 72 色服装色卡。基于颜色聚类的结果,获取到主体颜色的聚类中心信息,所占比例最大的聚类中心所对应的色卡,被定义为最终输出颜色名称。
3.2 应用:商品属性的自动填写
商家在发布新品时,需要填写商品的标题、上传图片,填写商品的属性值,以及详情页信息。当上新量很多的时候,特别是筹备双 11 期间,填写商品信息比较费时,加大了商家的工作量。而图像算法能够在商家上新的环节,通过分析上传的图片,得到图中的关键信息,为商家提供便利。
以服装类目举例,商家上传了商品图片后,我们通过图像标签技术模块,计算得到图中商品的一系列属性信息。例如图 8 所示,这些信息包括:类目(毛呢外套)、袖长(长袖)、版型(收腰)、领型(西装领)、衣长(长款)、风格(韩系)、颜色(藕粉色)等。利用这些信息,自动帮商家填写好对应的属性,节省了商家选择属性值的时间。当商家发现图像算法识别错误时,可以在自动填写的基础上,对已填写内容进行手动修改。整个流程能够大幅度减少商家上新填写信息所需时间,提升商家的业务效率。
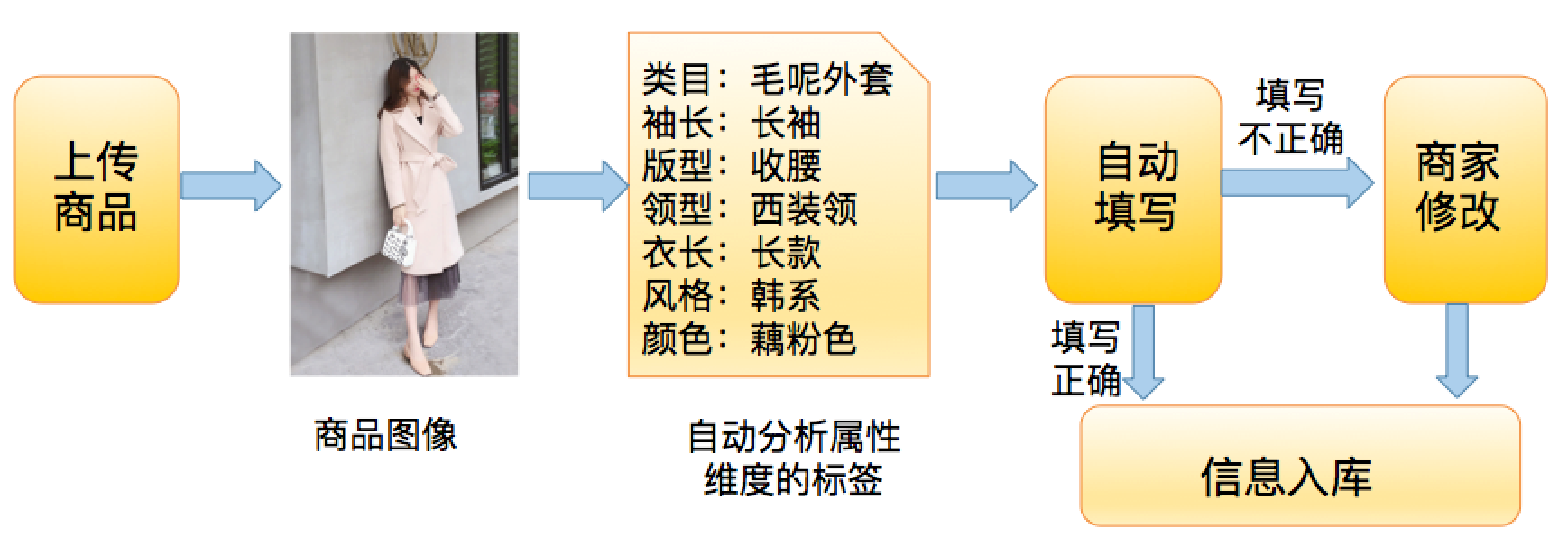
图 8. 商品属性自动填写
4. 结语
在实际的业务场景中,图像算法开发是基于应用来驱动的,为保障平台运营和用户体验提供价值。我们的工作,通过图像搜索技术可以自动识别平台上的同款商品,提升后台商品管理的效率;也能够帮助用户发现更多相似商品,改善用户体验。同时,运用图像标签技术,为商家发布新品节省信息填写时间,提升了商家效率。
我们在日常的开发过程中积累图像算法的基础模块,并在双 11 的业务开发中拓展其运用场景;未来将根据业务中的数据变化、场景变化,进行技术迭代开发,从而为不断升级的业务需求提供保障。
致谢:本文工作是蘑菇街图像算法组同学的共同贡献,特此致谢!




