
分享嘉宾 | 袁一 中国工商银行大数据平台负责人
本篇内容将通过三个部分来介绍工商银行实时大数据平台建设历程及展望。
一、工行实时大数据平台建设历程
二、工行实时大数据平台建设思路
三、展望

一、工行实时大数据平台建设历程
工商银行从 2002 年开始建设数据集市,当时主要使用 Oracle 类单机版的关系型数据库。随着数据量不断增加,开始引入 TD、ED 等国外高端一体机。2014 年工行正式基于 Hadoop 技术建设了大数据平台,在其之上构建了企业级数据湖及数据仓库。2017 年,随着 AI 技术的兴起,又开始建设机器学习平台,2020 年开始建设数据中台和高时效类场景。

为了满足数据时效,以及企业级大规模普惠用数的诉求,企业内部的大数据平台需要不仅支持批量计算,还需要满足各类用数场景全栈覆盖的技术体系。以工行为例,大数据平台内部除批量计算之外,包含实时计算,联机分析、数据 API 等平台,主要以 Flink 作为内部引擎,用于缩短数据端到端闭环时间,形成联机高并发的访问能力,提升数据赋能业务的时效。除此之外,还包含数据交换、数据安全等面向特定技术领域的二级平台。在最上面一层,我们向开发人员、数据分析师、运维人员提供了可视化的支撑工具。

二、工行实时大数据平台建设思路
工行实时大数据平台建设思路,主要会围绕时效、易用、安全可靠和降本增效来展开。
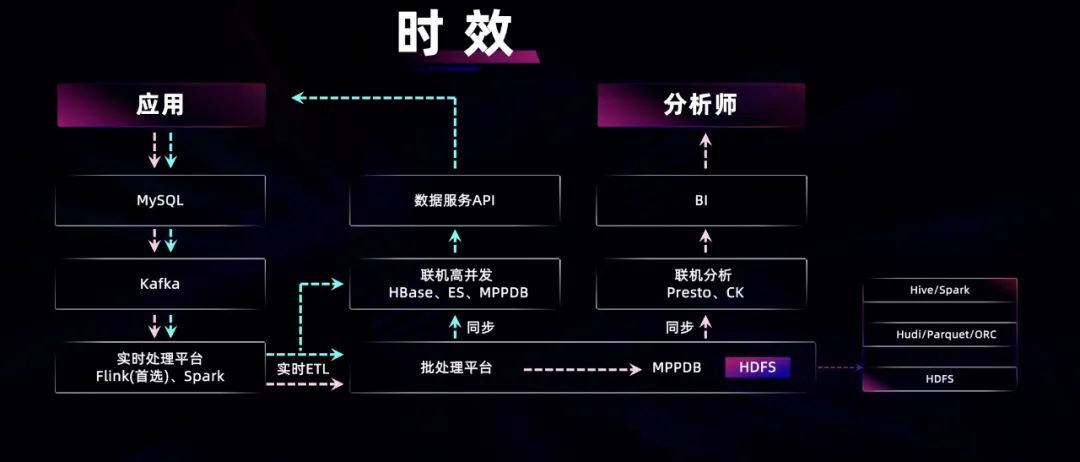
在数据时效方面,上图是描述数据流向的示意图,原始数据从左上角的应用产生,经过蓝色和粉色两条链路。其中,蓝色链路是业务视角上端到端闭坏的链路,应用产生的数据会写入 MySQL 或者 Oracle 等关系型数据库,之后通过 CDC 相关技术,将数据库产生的日志复制到 Kafka 消息队列中,将同一份数据的共享,避免多次读取数据库日志。
在 Kafka 之后,是实时计算平台。实时计算平台除了实现对时效要求较高的计算处理场景之外,它还可以通过 Flink 结合 HUDI/IceBerg 等产品实现实时数据入湖。而且能将 Flink 的结果输出到 HBase\ES 等联机数据库中。将这部分数据以服务的形式暴露,即数据中台服务,从而提供给应用调用。
粉色链路的数据,最终回到数据分析师那里,是蓝色链路的衍生。各个应用产生的数据,通过 Flink 和 HUDI 的实时数据入湖,通过 Presto 或 CK 等分析型引擎,供数据分析师进行 BI 分析。通过这条链路,数据时效得以提升,让分析师访问到分钟级延时的热数据,更加实时、准确地做出运营决策。一般高时效的业务场景,都包含在这条技术链路的体系之内。
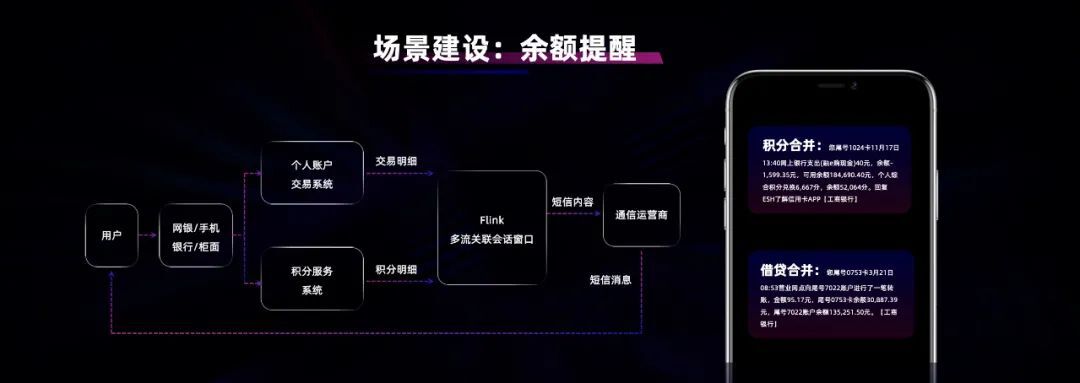
在余额变动场景,客户进行一次动账交易,可能触发多种通知内容,例如账户支出提醒、账户收入提醒、积分消费提醒等,造成客户手机连续收到短信提醒,用户体验不佳。因此,工行基于 Flink 多流合并和会话窗口的能力,将同一时刻发生的多条消息关联,将通知的逻辑合并在一起发送给客户。而当一条消息出现晚到的情况,通过会话窗口的 GAP 设置能自动降级,将逻辑分为两条消息发出去。大幅提升对用户的友好性。
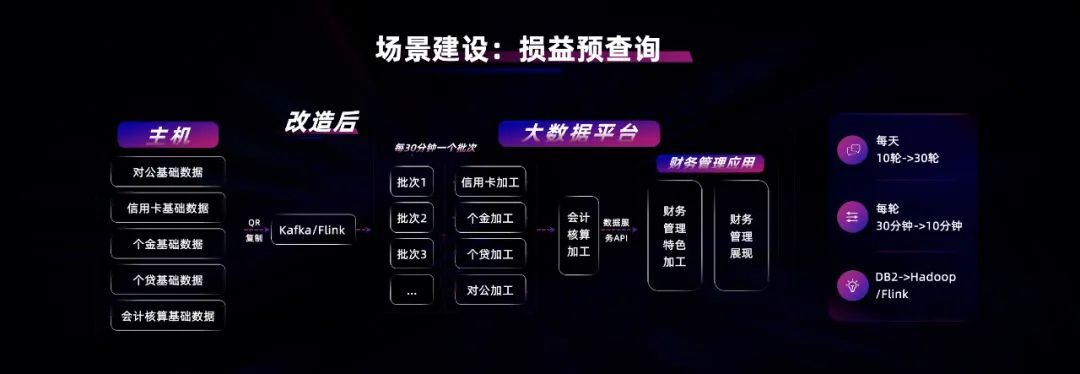
每家商业银行在每年 12 月 31 日时需要出年报,所以那天银行需要对全年的利润分配等指标进行试算。工行和其它商业银行一样早期使用 DB2 主机实现核心交易,年终时的损益、预查询都在主机上实现。但主机是按 MIPS 收费,所以当这种预查询多次执行时,成本很高。
因此工行做了架构改造,通过 CDC 数据复制技术,将主机实时发生的数据复制到大数据平台,通过 Flink 进行实时 ETL,数据搬运过来之后,充分利用大数据平台海量的计算能力,大幅提升预查询效率。原来每天跑 10 轮,现在每天可以跑 30 轮,原来每轮 30 分钟,现在每轮只要 10 分钟,既提升了时效又节省了成本。

实时大屏场景一般都是基于日志采集或 CDC 技术实现数据的统一汇集,基于 Flink 进行实时的业务量统计。工行也是通过这种方式实现的实时大屏,并使用了 Flink 的 mini-batch 的特性。虽然 Flink 能逐条实时处理数据,但在大部分场景,它会有 1ms 和 100ms 的延时,mini-batch 的特性类似于 Spark Streaming 微批的处理方式,在增加小量数据延时的情况下,大幅提升海量数据的吞吐能力,非常适用于实时大屏的场景。
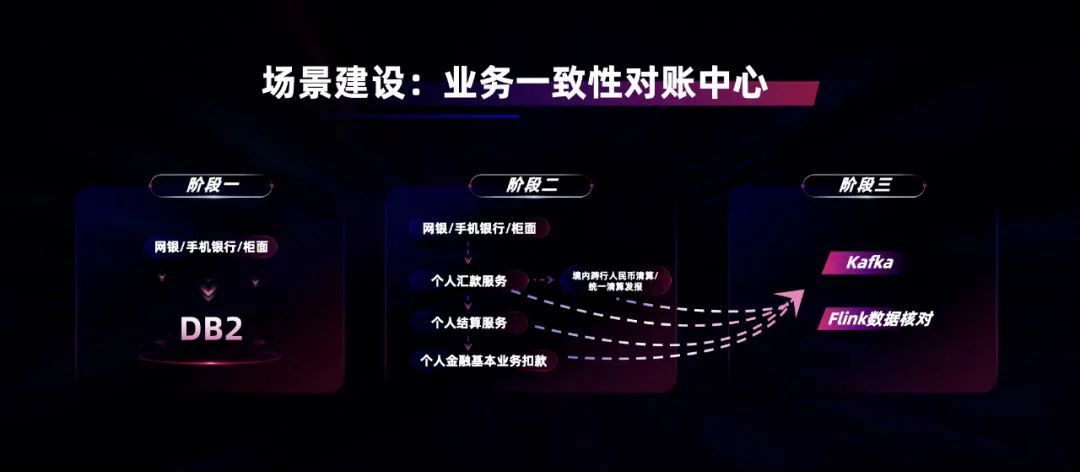
在银行业早期,大家基于 DB2 主机支撑核心业务。随着国内去 IOE 以及自主可控转型的浪潮,各家商业银行都开始将主机上的业务,迁移到分布式体系上,通过服务化接口的调用,满足不同业务系统之间的协作。业务迁移到分布式体系后,在调用多个服务化接口时,由于网络抖动等影响,会出现交易中,部分环节失败的情况。
为了解决这个问题,工行基于 Flink 研发了业务一致性对账中心,将服务化接口调用过程中的调用日志,统一汇集到 Kafka。基于 Flink 会话窗口的特性,判断交易中各个环节的调用是否完整。如果发现不完整的情况,会触发业务上的补账 / 核对动作,及时消除对客户账务的影响。
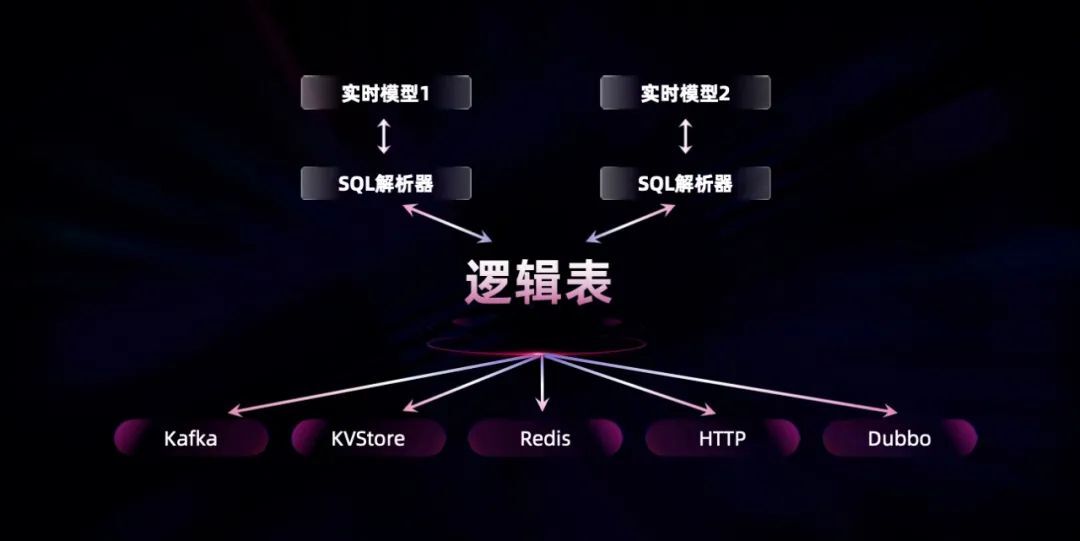
早期的实时计算模型都是基于 Java 等高级语言进行开发。在 Spark Dataframe 以及 Flink SQL 出现之后,开发人员可以通过 SQL 来开发实时计算模型。随着分布式体系以及数据中台的发展,很多实时计算模型在处理业务逻辑过程中,需要访问外部联机接口。

工行将调用的 HTTP、Dubbo、Redis 等外部接口,抽象成一张张外部表。直接通过一句 SQL 就能将 Kafka 中的流表与 Dubbo 的维表关联,然后将结果送到 HTTP 接口,大幅提升开发效率。

接下来,给大家分享一下工行在用数支撑工具方面的实践。在业务研发方面,通过借鉴业界 DataOps 的理念,工行打造了一条集开发、测试、版本制作及发布于一体的研发流水线。
相比于早期大数据工程师基于 UltraEdit 开发的模型,这种可视化 IDE 的开发效率至少提升 10 倍以上。同时工行的开发平台也于今年通过了中国信通院“数据开发平台”的认证测评,信通院在 12 月 10 日通过官方公众号公布了测评的结果。
在生产运维方面,工行为运维人员提供多个用于展示平台健康状态的仪表盘。同时,并通过机器学习和专家规则相结合的方式,实现了面向多类场景的故障根因自动分析的能力,降低运维门槛。

对于开发人员来说,他们更关心作业中断后运维平台能否帮助分析问题,所以在作业中断时,为开发人员提供问题诊断能力,95% 以上的常见问题都可以自动完成分析。
在 BI 平台,工行面向业务人员提供了自助数据分析探索的能力。主要解决用数最后一公里的问题。分析结果提供了多样化的展示仪表盘,不但支持基于拖拉拽的多维分析,而且支持数据下钻挖掘等功能。
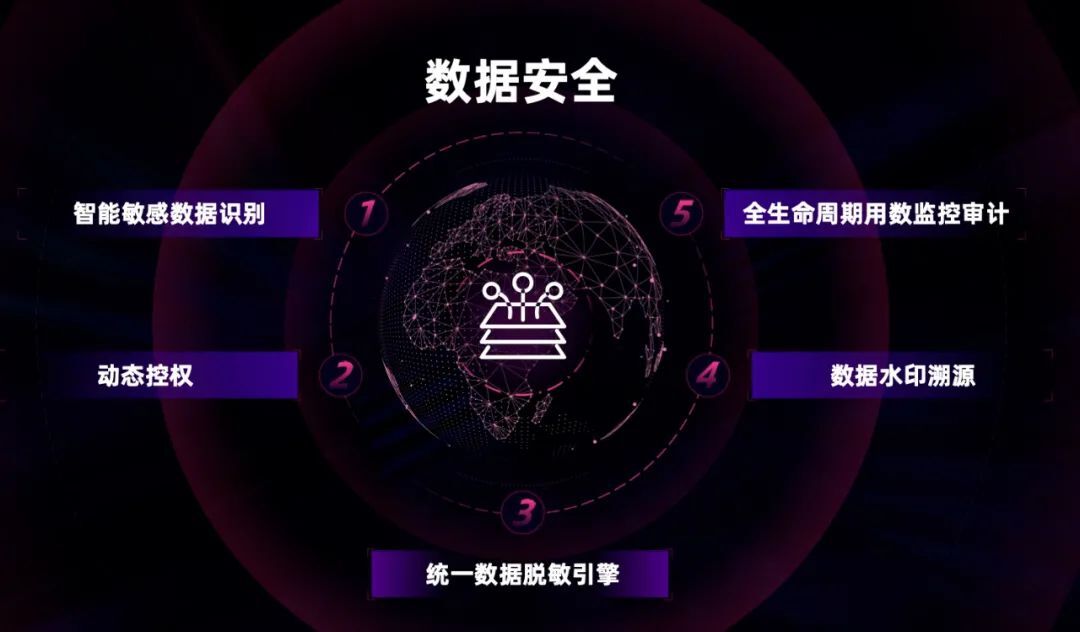
接下来,给大家介绍工行在大数据平台安全可靠性方面的实践。
近几年各个行业对数据安全的重视程度都越来越高,而大数据平台作为全集群数据的汇集地,对数据安全保障方面能力的建设就显得更加重要。大数据平台不但要存储很多数据,而且要提供的各式各样的数据访问方式。
因此工行设计了一套全生命周期用数监控审计,类似于 Ngnix 的 access.log,主要用于事后追溯审计。当用户将数据拖回到本地时,平台会对数据加上水印,当有些数据被非正常公开后,就可以知晓数据泄漏的来源,同时对身份证、手机号、卡号等敏感字段,在返回时动态脱敏,比如 11 号的手机号中间几位都会变成“********”。
动态控权是因为有些数据访问权限控制粒度较细,工行实现了一套 SQL 改写引擎,在运行时对 SQL 进行解析,根据用户与表权限的对照关系,对 SQL 加上控制条件及脱敏函数,避免数据被越权访问。敏感数据识别是基于专家规则或 ML 模型,自动识别海量数据中的敏感信息,并自动进行分类分级。同时,提醒管理员对敏感信息和分类分级结果进行核实确认。

在大数据平台建设的早期,大家主要将一些非关键的增值类业务放到大数据平台。随着技术的不断成熟,很多机构开始将核心的业务部署到大数据平台。为此工行在上海外高桥和嘉定两个数据中心建立了双活的大数据平台,通过系统级复制确保两边基础数据同步。对于部分关键业务会在两边同时运行,通过这种架构来确保关键业务的稳定。

上图是数据离线备份架构。金融机构在监管方面,对于数据存储可靠性的要求很高,所以,我们将 NBU 磁带备份系统和 Hadoop 以及 MPPDB 数据库的接口做了集成,实现了类似于 Oracle RMAN 的数据存储,增量备份的能力。
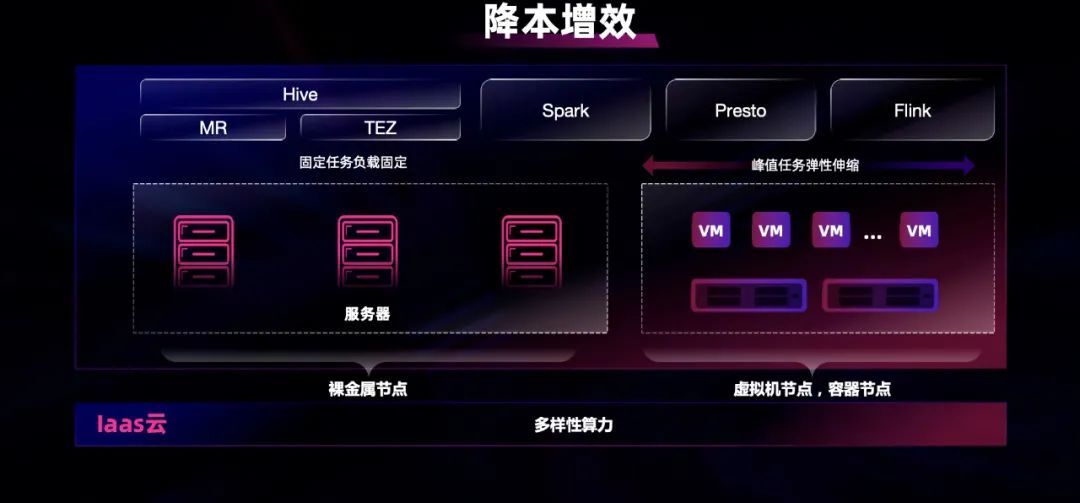
根据国家监管的要求,大部分金融机构的大数据平台一般都以私有化的部署方式为主。在早期 Hadoop 技术刚出现时,大数据平台的设备选型以物理机 + 本地磁盘为主,尽可能实现本地计算。目前,主流的公有云大数据云服务以存算分离的架构为主。那么在建设金融机构大数据私有云时,到底应为物理机 + 本地磁盘为主,还是以存算分离架构为主呢?
在公有云实现存算分离的最重要的原因就是:资源的超分配。超分配就是,假设公有云上有 10 个租户,每个租户分别申请了一个 10 节点的集群,但由于这 10 个租户的资源使用都会存在错峰的情况,因此云平台只要准备 50 台设备就可以满足上述需求,并不需要实际准备 100 台设备,这就是超分配。
私有云的大数据平台,一般会按业务线来划分集群。每个集群可能是数百台设备的规模,并不会出现大量的小租户、小集群,但集群间确实会存在一定错峰的情况。
对于这种情况,工行更倾向于使用固定资源 + 弹性资源混合部署架构。如图所示,左边基于裸金属的固定资源池,用于满足日常的资源需求。右边基于容器的弹性资源池,用于满足特定事件发生时突增的需求。同时,这部分弹性资源池,可以在不同的集群之间,动态调配复用。
三、展望

我们先来讲讲 Flink 1.14 版本中发布的 HybridSource 能力。目前,在上线一新的实时模型时,如果涉及到历史数据的统计指标,以金融行业为例,在一个反欺诈模型里,需要最近 7 天累计交易额的统计指标。这种情况下,我们一般会先跑 Hive,批量算出前 6 天的统计值,放进 Redis,然后基于 Flink 读取 Kafka 中的数据,统计当天的增量数据,再进一步汇总成最近 7 天的统计值。这个过程,需要分两个作业来实现。
而通过 HybridSource 可以将 Hive 和 Kafka 中的数据抽象成一张表,通过一个作业就可以统计出最近 7 天的值,在 Flink 内部自动实现类似于 union 的功能,大幅提升研发效率。

关于动态资源调整,随着平台规模越来越大,资源利用率的关注度就越来越高。实时计算在一定特定的场景,会出现交易量突增的情况。对于这类情况,工行目前还是采用手工扩容,或者通过业务侧将批和流结合的方式解决。比如在双十一大促之前,工行都会提前一周对交易相关的实时计算模型,进行手工扩容,大促之后再手工缩容。这个过程,总体比较复杂。
因此后续希望 Flink 通过具备动态扩缩容的自适应能力,配置 min 和 max,引擎可以自动根据数据量的负载在 min-max 之间,调整使用的资源量从而提高整个平台的资源利用率。
【点击链接】查看分享的完整视频并获取分享 PPT




