
2023 年以来,全球掀起了一场有关大模型的“热潮”,国内外企业纷纷入局参与大模型的研发与训练,调研和推动大模型技术与产业结合落地方案,大模型生态蓬勃发展。
2023 年过半,我们发现,业内对于大模型技术的关注点已经逐渐从“AI 大模型可以做到什么”、“国内哪些企业拥有大模型技术”等话题,转至“企业如何接入大模型”、“企业如何实际应用大模型技术降本增效”上,越来越多的企业开始关注大模型的具体接入与应用。而大模型的典型应用场景,对话式搜索服务一直备受行业关注,高效、低成本搭建高质量对话式搜索服务,进一步提升用户的信息检索体验则成为了新时代每个企业都需要探索的方向。
对此,近期 InfoQ 获悉,阿里云开放搜索 OpenSearch 重磅推出 LLM 智能问答版,提供基于大模型的 LLM 智能对话产品,帮助企业在 1 个小时以内,从 0 搭建起自己的对话式搜索服务。自开放搜索 OpenSearch LLM 智能问答版正式发布一个月以来,已有数百家企业接入使用,在最新发布的钉钉个人版中,也大规模应用了产品所提供的能力。
钉钉个人版的智能问答能力由阿里云开放搜索 OpenSearch LLM 智能问答版提供支持
据悉,企业只需要将原始数据导入实例,开放搜索 OpenSearch LLM 智能问答版即可为其搭建完整的一站式对话式搜索技术链路,企业客户再通过简单的 API 对接,即可将生成搜索结果和传统搜索结果集成在自己的应用中。本文将以阿里云开放搜索 OpenSearch 产品为引,剖析企业接入大模型的痛点、难点,并为大家进一步解读阿里云开放搜索 OpenSearch LLM 智能问答版的技术实践与能力亮点。
企业接入 AI 大模型的趋势已经到来
目前,企业接入大模型的需求场景主要围绕在电商行业选品、智能对话客服、企业内部知识库资料智能对话检索,以及企业自有 App 的搜索推荐系统搭建等。
来自阿里云 OpenSearch 的行业调查结果显示,企业自行接入大模型,普遍面临着二次开发任务繁重、模型 finetune 困难、运维工作量大、缺乏清晰的业务目标测评方法等实际难题。具体而言,在接入大模型方面往往面临以下六大“拦路虎”:
人才储备与技术能力不足:大模型的研发训练和维护需要专业的技术团队支持,但是部分企业没有招聘和培养相应的人才,无法确保大模型能够得到有效支持和维护。
合规与数据安全难保障:企业需保障大模型的对话结果基于业务数据生成、生成内容安全合规,并且保障企业数据安全,避免相关法务风险。
硬件基础不够:大模型需要大量的计算资源,包括 GPU、TPU 等硬件设备,这对于个人或小型企业来说,可能是难以承担的开销。
模型优化和解释性问题:随着模型参数数量的增加,调整参数的复杂度也在增加。如果企业研发人员经验不够,参数调节不当,可能会导致过拟合或欠拟合等问题;大模型的可解释性比较差,所以对于一些对模型解释性能力要求比较高的领域(例如医疗、金融等)而言调整难度更大。
维护成本困境:维护大模型的调优、数据更新需要占用较多人力与时间成本。
训练语料不充分:大模型的训练需要大量训练数据和语料信息,如果企业相关数据较少,很难获得较好的大模型训练效果。
目前,多家国内外知名企业均已发布自主研发的大模型,并宣布未来旗下产品将全面接入大模型。这意味着,大模型技术本身已经具备企业接入与业务落地的成熟度,接入大模型是各行业的整体趋势,但对于大部分企业来说,与其自行训练大模型,不如直接选用大模型的应用层解决方案,将资源聚焦在业务与需求本身,用更绿色、更低碳的方式推动整个信息产业技术升级。
阿里云 OpenSearch LLM 如何让企业具备智能对话能力?
阿里云 OpenSearch 始终致力于帮助企业客户构建高质量的端到端搜索服务,本次快速推出 LLM 智能问答版,提供端到端全托管的对话式搜索服务,也是 OpenSearch 产品希望帮助企业解决算力不够、人力时间成本高昂等大模型接入问题,让每一家企业都能够便捷地接入大模型,享受全新一代的搜索体验,提升信息检索效率,感受 AI 为业务带来的改变的新使命。
OpenSearch 的智能对话与文本生成能力通过 LLM 提供,这里我们以阿里云自研的通义千问为例,介绍 OpenSearch LLM 智能问答版的技术实现。
OpenSearch LLM 智能问答版系统架构
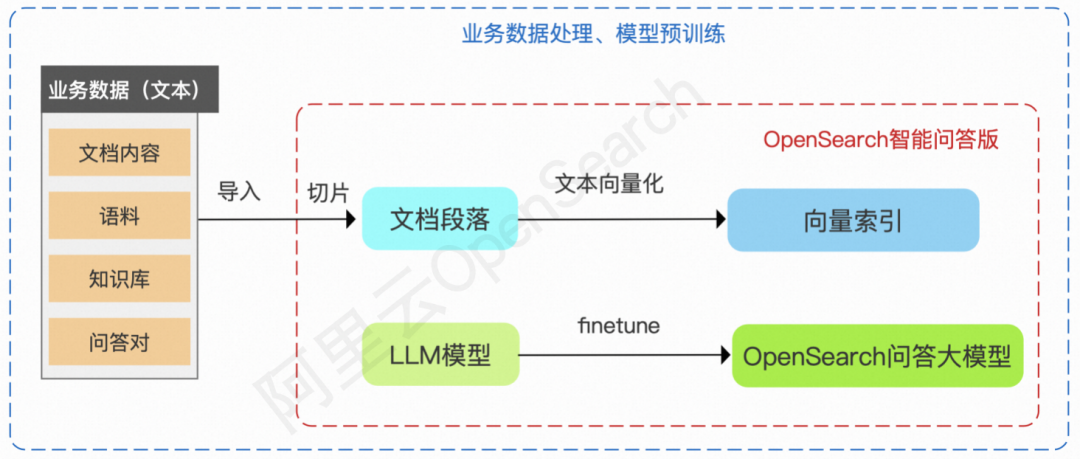
OpenSearch LLM 智能问答版系统架构主要包含业务数据处理、对话搜索在线服务、大模型预训练三个部分。
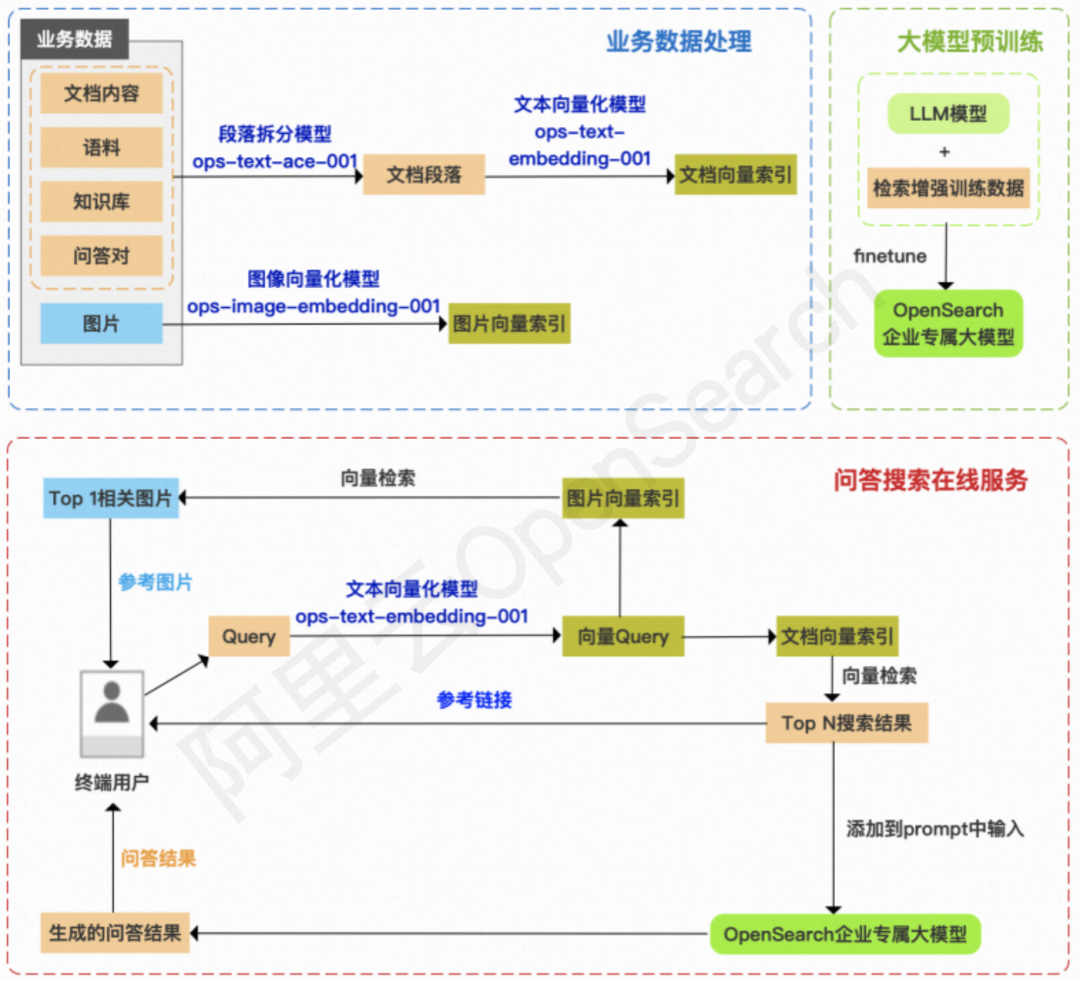
业务处理数据
相比传统的搜索引擎,OpenSearch LLM 智能问答版离线数据处理流程最大的变化点在于对业务数据的处理:
传统搜索引擎的数据源是结构化文本,而这里需要处理的往往是非结构化文本,并且数据的格式会更加多样(HTML、Markdown、纯文本、PDF 等)。
传统搜索引擎构建索引是基于文档的唯一主键,而这里由于数据源的差异,需要先对文档进行段落拆分,对拆分后的段落生成新的段落主键。
传统搜索引擎基于文本索引进行内容匹配,而这里采用向量索引,更加容易适配丰富的数据格式和长文本搜索。
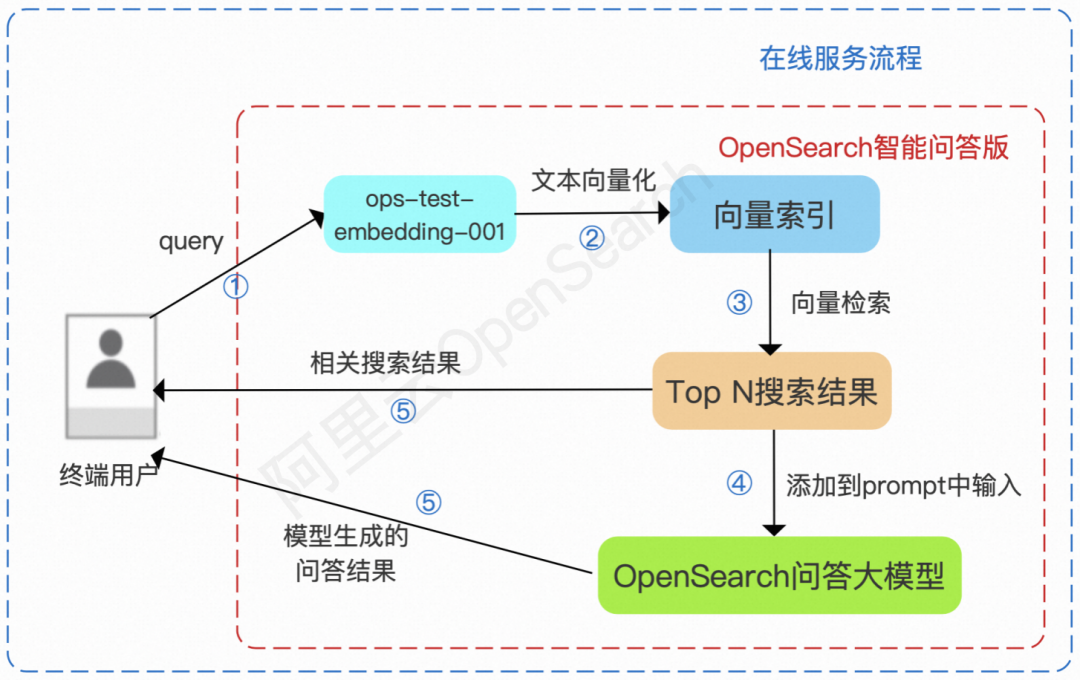
对话搜索在线服务
据悉,相比传统的搜索引擎,OpenSearch 智能问答版在线服务架构变化非常大,主要区别有:
传统搜索一般会返回 10 个以上的结果,并且经常会以翻页查询的方式呈现结果,而这里的检索是为了找到相关度相对最高的段落内容,Top N 中的 N 不宜过大(一般在 3 以内),且需要控制相关性,确保不召回相关性过低的段落带来误导。
检索完成得到 Top N 搜索结果后,将结果添加到 prompt 中输入大模型,这一阶段耗时一般较大,OpenSearch 智能问答版支持流式输出以缓解等待时间过长的体验问题。
返回结果时,基于用户业务数据,通过 API 输出指定 Query 下的参考链接、参考图片和模型生成的对话结果。
大模型预训练
阿里云 OpenSearch 深度整合和应用通义千问模型,为了提升模型在检索增强场景下的有效性,减少有害性,OpenSearch LLM 智能问答版还对模型进行了有监督的模型微调(Supervised Finetune,SFT)进一步强化检索增强的能力。对比 SFT 后的对话搜索模型与原始 LLM,阿里云 OpenSearch 团队发现:经过 SFT 的模型更擅于总结输入文档中的内容,从而精准简练地回答用户问题,达到智能对话搜索效果。
此外,OpenSearch 还可以支持包括 Llama2、openbuddy、falcon 在内的多种开源模型,用户无需开发、集成、部署,即可直接使用 LLM 能力。

强大的对话检索能力
阿里云 OpenSearch LLM 底层采用了阿里巴巴自研的大规模高性能搜索引擎,可以保障搜索环节的召回准确度与性能,擅长处理向量维度更高的大模型场景。
除了引擎优势之外,阿里云 OpenSearch LLM 智能问答版通过内置段落拆分模型、内置文本向量化模型、内置图片向量化模型,保证了对话搜索结果的精准度。同时已支持多轮对话,结合上下文挖掘用户需求,对话搜索结果全部基于客户数据生成,保障内容的可靠性和相关性。
在此基础上,阿里云 OpenSearch LLM 智能问答版提供了充分开放的模型能力,包含多种底座 LLM 可替换,自定义 prompt,模型参数调优与排序策略优化等,此外还支持对话结果人工干预,满足对语言、风格等对话式搜索效果的更高要求。
在工程架构方面,阿里云 OpenSearch 诞生于电商场景,经过内部业务多年打磨沉淀,能够稳定承载千亿级数据、百万级 QPS 的业务流量。读写分离的架构使得数据写入与查询相互不影响,能够有效保障服务的稳定性。此外,产品支持对话结果的流式输出,能够缓解由于回答生成速度慢带来的用户体验问题。
段落拆分模型:ops-text-ace-001
模型最终生成的效果很大程度上是由检索结果决定的。传统文档检索系统只需要针对 Query 给出最相关的文档列表。检索增强式 LLM 则需要给出具体与 Query 相关的段落。权衡效率与效果,OpenSearch 智能问答版的段落拆分模型支持结构化数据及包含 doc、pdf、html 在内的多种非结构化数据的快速导入,并能够实现自适应段落长度,保障语义段落的完整性。
文本向量化模型:ops-text-embedding-001
相比于传统搜索,在与 LLM 的交互中,一个很大的改变是用户可以非常自然地口语化输入。对于口语化输入,基于语义的向量检索架构天然契合。OpenSearch 内置自研高性能向量检索引擎,擅长处理向量维度更高的大模型场景,可以达到数倍于开源引擎的搜索性能和更高的召回率。
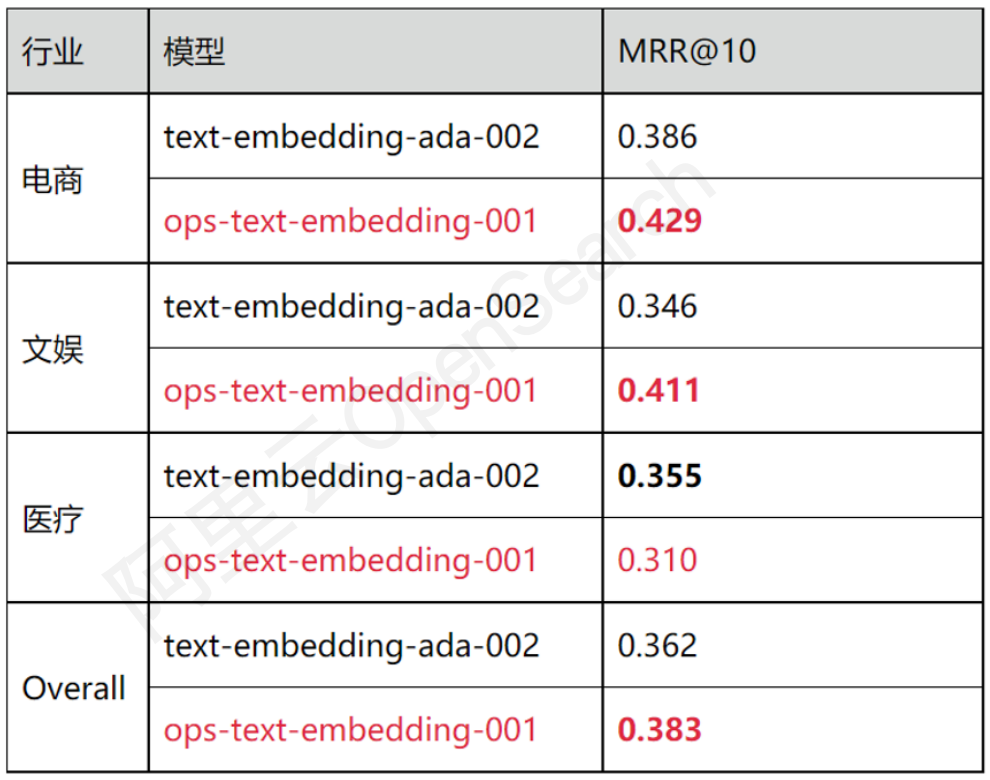
为了更加适配多语言、多行业的对话搜索场景,OpenSearch 算法团队进行了定制模型研发与效果调优,并对模型效率进行了针对性地优化,以满足搜索场景实时性的需求,最终产出 ops-text-embedding-001 模型。在中文数据集 Multi-CPR 上,ops-text-embedding-001 模型在 MRR@10 等关键指标上的表现已经优于行业标杆向量模型即 OpenAI 的 text-embedding-ada-002:
图像向量化模型:ops-image-embedding-001
对于内容行业而言,大量关键信息以图片的形式呈现,图文结合的多模态展现可以让企业专属智能对话搜索效果大幅提升。为了在对话式搜索中实现图文并茂的效果,OpenSearch 智能问答版也提供了图片向量化模型 ops-image-embedding-001,该模型结合多模态的信息,计算 Query 与文档中图片的图文相关性,最终返回相关性最高的图片作为参考图片结果。
对话式搜索效果调优
影响对话式搜索业务效果的环节通常包含三个方面:
底座大模型的效果
OpenSearch 支持多种底座大模型的选择,除阿里巴巴自研的通义千问大模型,还包含开源的 Llama2、openbuddy、falcon 等多种 LLM 可选,用户可基于自身的业务需求、场景、语言等,尝试并使用最适配的 LLM。同时,还支持调整部分模型参数,解决对话式搜索过程中的 bad case。
搜索召回的效果
除上文已经介绍过的段落切分模型和文本向量化模型外,OpenSearch 还内置多种搜索召回排序函数与规则,用户可以自行定制排序策略,召回最符合业务需求的结果。
Prompt 适配度
Prompt 中除了包含搜索召回的业务文档外,还需要包含对 LLM 的角色、指令控制,以实现预期的效果。OpenSearch 支持用户自行调整输入给 LLM 的基础 Prompt,用户可基于自身业务需求,灵活调整语言、语气、无结果时的回答语、输出格式等内容,充分满足灵活性和效果调优需求。
此外,针对搜索领域常见的高频 Query 干预与效果调优问题,OpenSearch 智能问答版还支持基于知识库的人工干预。用户可以指定干预问题与对应回答,OpenSearch 智能问答版会识别相似问题,并根据知识库中的预设结果给出相应答案,从而实现针对指定 Query、活动等场景的运营干预,使对话结果更安全可靠、服务于企业业务。
目前,OpenSearch LLM 版本已与多个阿里巴巴内部业务、云上客户合作实现方案落地,帮助机器硬件资源稀缺、不具备前期数据切片、向量化等环节的处理能力和经验的企业,基于垂直领域数据构建对话式搜索服务。
以阿里云产品文档数据作为业务数据,基于 OpenSearch LLM 智能问答版搭建对话式搜索系统,我们可以看到如下的对话搜索效果演示:


据悉,在上述效果演示中,企业只需将相应的文档数据导入 OpenSearch LLM 智能问答版,即可根据用户输入的 Query 返回对话模型生成的图文答案和相应的参考链接,实现智能对话搜索效果。
未来 OpenSearch LLM 智能问答版将提供更多行业的解决方案,为各垂直领域提供行业专属大模型,并将上线电商行业大模型。此外,OpenSearch 还将在现有能力基础上,推出 LLM 智能问答专业版,支持更定制化的专属模型 finetune、预训练等能力。未来 OpenSearch LLM 智能问答版将支持客户更高自由度的模型使用,满足业务对生成风格、生成效果的更高要求。
对话式搜索将迎来更广阔的应用
阿里云 OpenSearch 除了提供基于内置大模型的 LLM 智能问答版之外,也面向开发者推出基于 OpenSearch 向量检索版 +LLM 工具包的大模型应用解决方案,支持客户灵活选用文档切片方案、向量化模型、大语言模型,为客户提供高性价比的向量检索服务,并已经将向量检索版本核心引擎 Havenask 进行了开源。
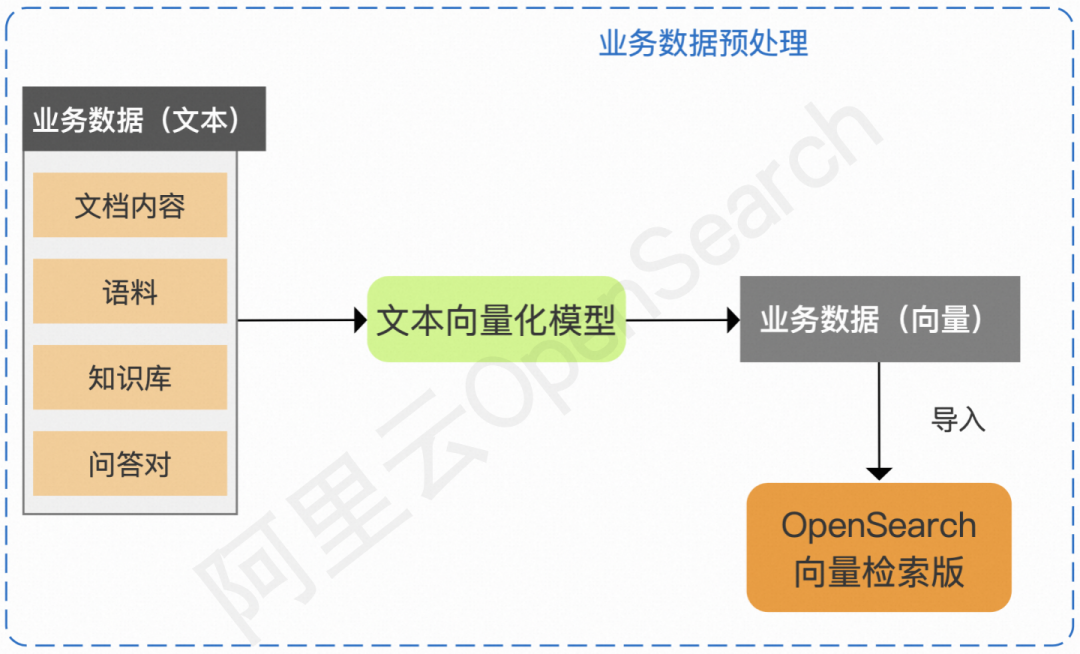

OpenSearch 向量检索版 + 大模型方案图示
对话式搜索将对电商场景、内容社区场景、金融场景、政企服务场景进行大规模的体验升级,用户与平台的交互方式也会因大模型技术而带来全新的改变,所以产品的落地形态和用户体验一定是这场大模型变革中的下一个重要战场。因此,无论是推出 LLM 智能问答版这种全托管的 MaaS(Model as a Service)产品,或是在云上提供更高性价比的 OpenSearch 向量检索引擎及 LLM 工具包,还是下定决心将核心引擎开源的一系列举措,OpenSearch 的目标就是希望为整个行业提供新的技术方案与选型,解决不同状态、不同阶段、不同预算的企业客户及开发者遇到的共性难题,即 OpenSearch 搞定对话式搜索场景的通用基础设施,企业级开发者专注进行场景级的业务优化与落地。
未来 OpenSearch 还会进一步“OPEN”,把整套工程链路彻底开放给大模型的开发者,任何通过认证的大模型都可以随时上架到 OpenSearch 平台,在合规的前提下为第三方开发者提供服务,这也是在全球 AI 行业飞速发展的今天,OpenSearch 与全行业共建的决心。




