
Acme 是一个基于 Python 的强化学习研究框架,由谷歌的 DeepMind 于 2020 年开源。它旨在简化新型 RL 代理的开发并加速 RL 研究。根据 DeepMind 自己的声明,这个强化学习和人工智能研究的先锋团队每天都在使用 Acme。
最近我参与了一个大学项目,为此决定学习 Acme 并使用它来实现不同的 RL 算法。我发现它的确很棒,我真的很喜欢用它。
Acme 的入门也相对容易。这是因为它有多条入门路径,分别有不同的复杂度。换句话说,这款框架不仅适用于高级研究人员,而且还能让初学者实现颇为简单的算法——这和对初学者与专家都很友好的 TensorFlow 和 PyTorch 差不多。
它的不足之处在于,由于这款框架还很新,因此没有真正完整的文档可用,也没有做得很好的教程。
这篇博文可能是朝着正确方向迈出的一步。它并不打算成为或取代完整的文档,而是对 Acme 的一篇简明实用的介绍。最重要的是,它应该能让你了解框架底层的设计选择,以及这些选择对 RL 算法的实现有着怎样的意义。
我将讨论我的两个简单算法的实现:SARSA 和 Q Learning,其目标是玩二十一点游戏。一旦你了解了 actor 和 agent 都是什么东西,以及它们在 Acme 中是如何设计的,我相信你将很快了解如何实现你能想到的任何强化学习算法。
Acme 的基本构建块
我们来深入研究一个实际案例。如前所述,我们希望我们的代理(agent)玩二十一点游戏。
环境
Acme 代理并非设计为与 Gym 环境交互。相反,DeepMind 有自己的 RL 环境API。区别主要在于时间步长的表示方式。
不过幸运的是你仍然可以使用 Gym 环境,因为 Acme 的开发人员为此提供了包装函数。
env = acme.wrappers.GymWrapper(gym.make('Blackjack-v0'))二十一点游戏中有 32x11x2 的状态,不过并非所有状态都可以在游戏中实际出现。另外还有两个动作,“拿牌(hit)”和“停牌(stick)”。想要了解这些维度的细节,以及为什么不是所有状态都可以出现,你可以在这里查看 GitHub 上的环境。我知道一开始学起来会有些难度。
参与者、学习者和代理
了解参与者(actor)、学习者(learner)和代理(agent)之间的区别至关重要。参与者与环境互动。也就是说,它们观察状态并根据某些动作选择策略采取动作。下图说明了这一点。
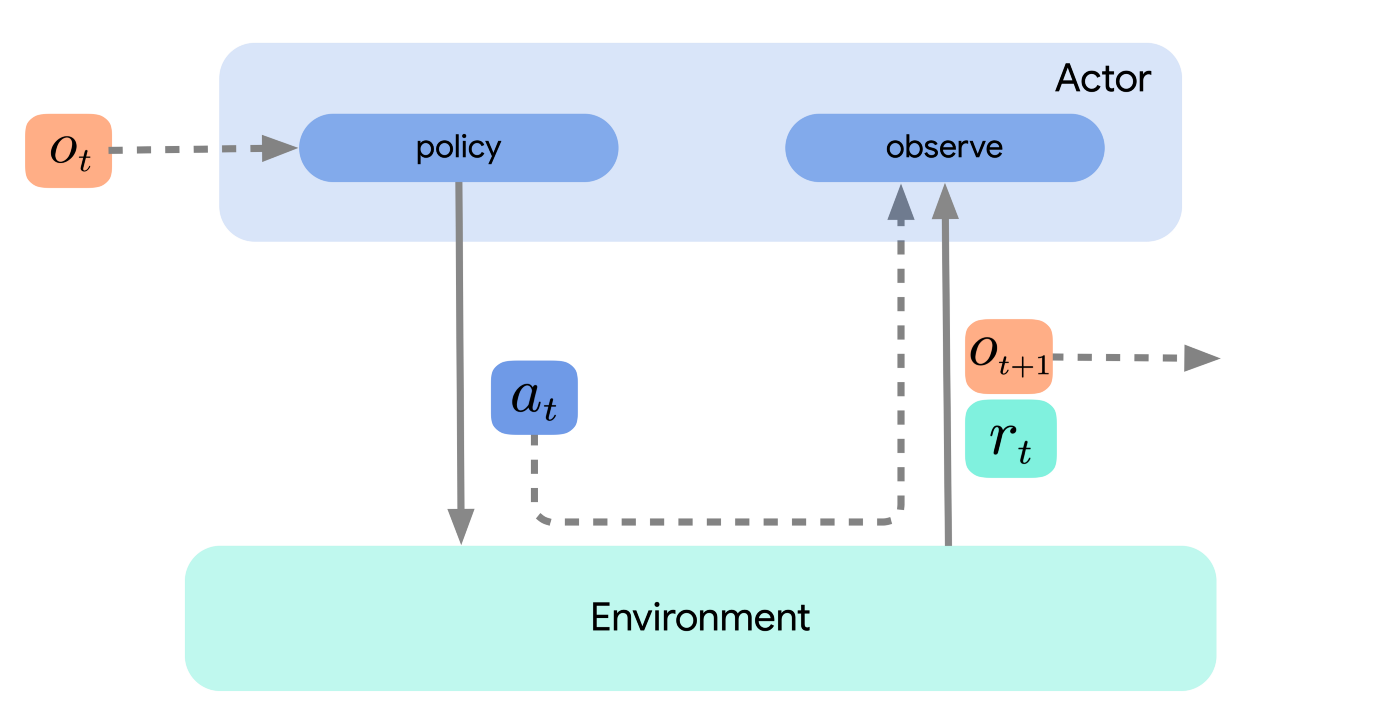
图 1:只有参与者的简单环境循环。
学习者使用参与者收集的数据来学习或改进策略,通常用的是在线迭代的方式。例如,学习内容可能包括对神经网络参数的更新。新参数被传递给参与者,然后参与者根据更新的策略行事。
代理就是行动和学习组件的简单结合,但通常不需要实现额外的强化学习逻辑。下图包括所有三个组件。
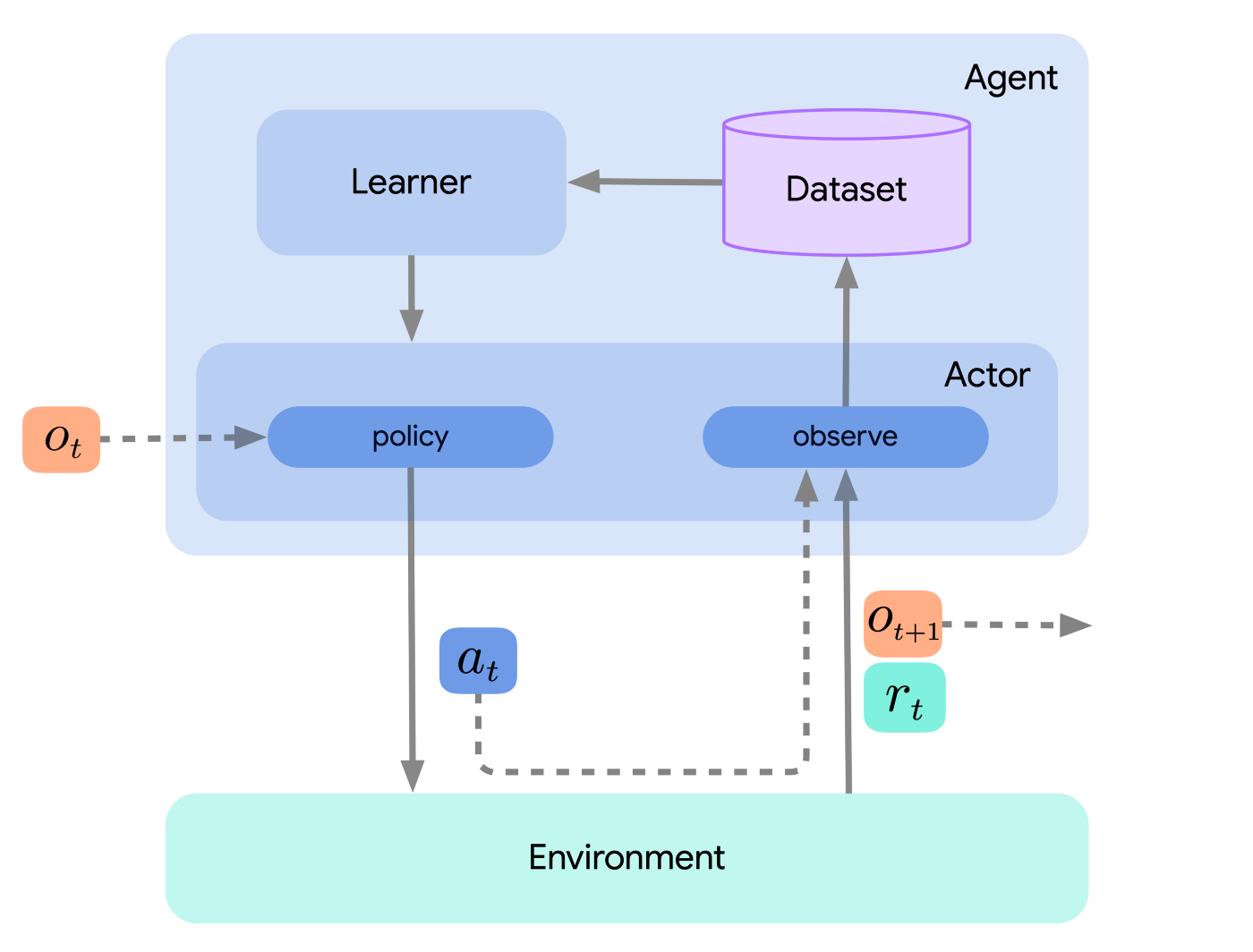
图 2:包括参与者和学习者的环境循环。
架构分解为参与者、学习者和代理的主要原因之一是为了促进分布式强化学习。但是,如果我们不关心这一点并且算法足够简单,那么仅实现参与者,并简单地将学习步骤集成到参与者的 update 方法也足够了。为简单起见,这也是我在这里采用的方法。
例如,下面的随机代理继承自 acme.Actor 类。必须由开发者(你)实现的方法是 select_action、observe_first、observe 和 update。如前所述,后者是在没有额外学习者组件的情况下进行学习的地方。请注意,这个代理将以相同的方式工作,只是无需子类化 acme.Actor。基类确定你必须覆盖的方法。这也确保了代理按预期与其他 Acme 组件(例如我将在下面介绍的环境循环)集成。
class RandomAgent(acme.Actor):"""A random agent for the Black Jack environment."""def __init__(self):# init action values, will not be updated by random agentself.Q = np.zeros((32,11,2,2))# specify the behavior policyself.behavior_policy = lambda q_values: np.random.choice(2)# store timestep, action, next_timestepself.timestep = Noneself.action = Noneself.next_timestep = Nonedef select_action(self, observation):"Choose an action according to the behavior policy."return self.behavior_policy(self.Q[observation])def observe_first(self, timestep):"Observe the first timestep."self.timestep = timestepdef observe(self, action, next_timestep):"Observe the next timestep."self.action = actionself.next_timestep = next_timestepdef update(self, wait = False):"Update the policy."# no updates occur here, it's just a random policy这个代理使用一个简单的随机选择拿牌或停牌的策略,但一般来说,这个框架在实现策略的方式方面有巨大的灵活性。稍后,你将看到一个 epsilon-greedy 策略。在其他情况下,策略可能包括一个神经网络,你可以使用 TensorFlow、PyTorch 或 JAX 来实现它。从这个意义上说,Acme 与框架无关,因此你可以与你喜欢的任何机器学习库搭配使用它。
在 update 方法中,参与者通常只从学习者中提取最新的参数。但如果你不使用单独的学习者,则 RL 逻辑将包含在 update 方法中(稍后你会看到这一点)。
EnvironmentLoop
如果你已经对强化学习有所了解并且已经实现了 RL 算法,那么你肯定会非常熟悉以下循环。每个 episode 由四个步骤组成,这些步骤重复执行,直到达到最终状态。
观察一个状态
根据行为策略采取一个行动
观察一个奖励
更新政策
代码:
# first initialize env and agent# env = ...agent = RandomAgent()# repeat for a number of episodesfor episode in range(10):# make first observationtimestep = env.reset()agent.observe_first(timestep)# run an episodewhile not timestep.last():# generate an action from the agent's policyaction = agent.select_action(timestep.observation)# step the environmenttimestep = env.step(action)# have the agent observe the next timestepagent.observe(action, next_timestep=timestep)# let the agent perform updatesagent.update()有时你可能需要实现这样的循环,特别是如果你希望对其自定义的时候。但大多数情况下,这个循环都是完全相同的。
方便的是,Acme 中有一个快捷方式:EnvironmentLoop,它执行的步骤与上述步骤几乎完全相同。你只需传递你的环境和代理实例,然后你就可以使用一行代码运行单个 episode 或任意多个 episode。还有许多日志记录器可用于跟踪重要指标,例如每个 episode 中使用的步数和收集的奖励。
# init Acme's environment looploop = EnvironmentLoop(env, agent, logger=InMemoryLogger())# run a single episodeloop.run_episode()# or run multiple episodesloop.run(10实现 SARSA 和 Q 学习代理
当然,随机代理不是很有用。我的承诺是展示如何实现一些实际的强化学习算法,所以我们开始吧。
顺便说一句,如果你根本不熟悉 RL,请参阅 Sutton 和 Barto 的《强化学习:简介》(2018 年)一书。大家通常最早学习的两种算法——无论是在书中还是在大学上的强化学习课程上——是 SARSA 和 Q 学习。
SARSA 代理
现在你已经知道 Acme 代理(或参与者)是如何设计的了。让我们看看如何在 Acme 中实现 SARSA 算法。
SARSA 是一种基于策略的算法,其更新取决于状态、动作、奖励、下一个状态和下一个动作(因此得名)。由于本文不是一篇理论 RL 教程,因此我不会在这里详细介绍算法本身。
首先,在代理的__init__方法中,我们初始化 Q、状态-动作值矩阵和行为策略——这里是一个 epsilon 贪婪策略。另请注意,这个代理必须始终存储其上一个时间步长、动作和下一个时间步长,因为 update 步骤中需要它们。所以我们也初始化它们。
class SarsaAgent(acme.Actor):def __init__(self, env_specs=None, epsilon=0.1, step_size=0.1):# in Black Jack, we have the following dimensionsself.Q = np.zeros((32,11,2,2))# epsilon for policy and step_size for TD learningself.epsilon = epsilonself.step_size = step_size# set behavior policyself.behavior_policy = lambda q_values: epsilon_greedy(q_values, self.epsilon)# store timestep, action, next_timestepself.timestep = Noneself.action = Noneself.next_timestep = Nonedef transform_state(self, state):# this is specifally required for the blackjack environmentstate = *map(int, state),return statedef select_action(self, observation):state = self.transform_state(observation)return self.behavior_policy(self.Q[state])def observe_first(self, timestep):self.timestep = timestepdef observe(self, action, next_timestep):self.action = actionself.next_timestep = next_timestepdef update(self):# get variables for conveniencestate = self.timestep.observation_, reward, discount, next_state = self.next_timestepaction = self.action# turn states into indicesstate = self.transform_state(state)next_state = self.transform_state(next_state)# sample a next actionnext_action = self.behavior(self.Q[next_state])# compute and apply the TD errortd_error = reward + discount * self.Q[next_state][next_action] - self.Q[state][self.action]self.Q[state][action] += self.step_size * td_error# finally, set timestep to next_timestepself.timestep = self.next_timestep在 observe 中你通常不需要做太多事情。在本例中,我们只存储观察到的时间步长和采取的行动。然而这并不总是必要的。比如有时候,你可能希望将时间步长(和整个轨迹)存储在一个数据集或重播缓冲区中。Acme 还为此提供了数据集和加法器组件。事实上,DeepMind 也开发了一个库。它被称为 Reverb(参见此处的GitHub)。
上面的 transform_state 方法只是一个辅助函数,用于将状态放入正确的格式以便正确索引 Q 矩阵。
最后,要在环境上训练 SARSA 500,000 episodes,只需运行
agent = SarsaAgent()loop = EnvironmentLoop(env, agent, logger=InMemoryLogger())loop.run(500000)Q 学习代理
下面的 Q 学习代理与 SARSA 代理非常相似。它们仅在更新 Q 矩阵的方式上有所不同。这是因为 Q 学习是一种离策略算法。
class QLearningAgent(acme.Actor):def __init__(self, env_specs=None, step_size=0.1):# Black Jack dimensionsself.Q = np.zeros((32,11,2,2))# set step sizeself.step_size = step_size# set behavior policy# self.policy = Noneself.behavior_policy = lambda q_values: epsilon_greedy(q_values, epsilon=0.1)# store timestep, action, next_timestepself.timestep = Noneself.action = Noneself.next_timestep = Nonedef state_to_index(self, state):state = *map(int, state),return statedef transform_state(self, state):# this is specifally required for the blackjack environmentstate = *map(int, state),return statedef select_action(self, observation):state = self.transform_state(observation)return self.behavior_policy(self.Q[state])def observe_first(self, timestep):self.timestep = timestepdef observe(self, action, next_timestep):self.action = actionself.next_timestep = next_timestepdef update(self):# get variables for conveniencestate = self.timestep.observation_, reward, discount, next_state = self.next_timestepaction = self.action# turn states into indicesstate = self.transform_state(state)next_state = self.transform_state(next_state)# Q-value updatetd_error = reward + discount * np.max(self.Q[next_state]) - self.Q[state][action]self.Q[state][action] += self.step_size * td_error# finally, set timestep to next_timestepself.timestep = self.next_timestep要在环境上训练 Q 学习代理 500,000 episodes,运行
agent = QLearningAgent()loop = EnvironmentLoop(env, agent, logger=InMemoryLogger())loop.run(500000)小结
我认为 Acme 是一个非常棒的强化学习框架,因为你不必从头开始开发算法。因此,与其自己弄清楚如何编写可读且可重复的 RL 代码,你大可依靠 DeepMind 那些聪明的研究人员和开发人员,他们已经为你完成了这些工作。
Acme 能让你实现任何强化学习算法,并且你可以将其与任何机器学习框架结合使用,包括 TensorFlow、PyTorch 和 JAX。
如果你想了解有关 Acme 的更多信息,可以阅读 DeepMind 的研究论文并查看他们的 GitHub存储库。
你还会在那里找到一些常见算法的实现,例如深度 Q 网络(DQN)、深度确定性策略梯度(DDPG)、蒙特卡洛树搜索(MCTS)、行为克隆(BC)、IMPALA 等。
无论你是高级研究员还是对强化学习感兴趣的初学者,我都鼓励你尝试一下。
链接
我的 Jupyter 笔记本(包括本文用到的代码)在这里。
如果有兴趣,也可以查看我的强化学习课程项目。除了 SARSA 和 Q-learning,我还实现了 dyna-Q、优先扫描和蒙特卡洛树搜索代理。
参考
Hoffman 等人(2020):Acme:一个分布式强化学习的研究框架。ArXiv。
Sutton 和 Barto(2018 年):强化学习:简介。
原文链接:
https://towardsdatascience.com/deepminds-reinforcement-learning-framework-acme-87934fa223bf




