导言
我们都知道分布式计算的理论知识:通过在多个计算机上分布任务、而不是由一个中央计算机发起所有的进程,我们就能提高整体的吞吐量。问题是,在现实中真正实现这种设计是非常复杂的。
像 EJB 这样的技术应该能使其简单一些,但是它们已经被证明对设计和开发过程具有极度的侵入性。幸运的是,目前出现并融入主流的 JVM 级别集群技术,比如 Terracotta,提供了一个可行的替代方法。
最近 Shine Technologies 发布了使用 Terracotta 的一个应用,显著提高了性能。过去,我们应用的性能往往受限于其运行的服务器。使用 Terracotta 的话,这似乎不再是问题。在我们的性能测试过程中,当一台服务器能力不足时,我们只要增加另一台服务器,应用的整体吞吐量就会显著增加——直到数据库成为主要限制因素。
一些背景
Shine Technologies 是一家为许多澳大利亚能源产业公司服务的 IT 咨询和开发服务提供商。随着全面零售竞争(Full Retail Contestability,FRC)规定的实施,Shine 已经为这些公司开发出许多产品。
简要地说,这些产品有利于促进批发商和零售商之间关于网络使用情况的财务交互。这些交互是大批量的,大型零售商不得不处理每月数百万笔的交易。因此,应用的伸缩能力变成了业务的关键——尤其是所有交易都在同一天涌向零售商的情况下。
这一系列产品最近添加的部分已形成一个应用,电力零售商的服务提供商使用该应用。这个应用——也就是大家熟知的市场核对系统(Market Reconciliation System,MRS)——每周都接受大量的用电数据,还为零售商提供报告和核对机制,高亮显示他们期望的使用收费和实际收费之间的任何差异。
鉴于该产品的大数据量特性,伸缩性在应用架构中是一个很大的驱动因素。在进行了涉及各种分布式计算框架的概念验证之后,Terracotta 被认为是最有可能满足 MRS 需求的框架。
Terracotta 和主 / 从模式
Terracotta 能把应用部署在多个 JVM 上,但仍然能彼此交互,就像它们运行在同一个 JVM 上。用户透明地指定 JVM 和 Terracotta 之间共享的对象,使它们都能获取这些对象。Terracotta 为集群提供了预配置解决方案,特别是 Java 企业环境——例如 Tomcat 、 JBoss 或 Spring 。但是,在我们的情况中我们不使用容器,所以需要我们自己配置 Terracotta。
幸好我们找到一种办法:主 / 从设计模式,它既符合我们的应用,也已被证明能很好地与 Terracotta 一起工作。Jonas Bonèr 在他的精彩博文《如何使用 Open Terracotta 建立基于 POJO 的数据网格》中首次描述了主/ 从设计模式与Terracotta 结合的用法。
对那些不熟悉主/ 从模式的人来说,“Master”负责确定需要完成工作的每一项,以及每一项在共享队列上的位置。接着它继续监控每一项的完成状态,当所有项都完成时也就完成了。“Workers”则从队列中逐一获取工作项并处理它们,当工作完成时设定项的完成状态。
在我们的实现中,Master 和Workers 分别运行在它们各自的JVM 上。这些JVM 分布在大量的机器上。任何共享对象(比如工作队列和工作项状态)都由Terracotta 服务器管理(并有效地同步)。
有很多有用的方法来形象表示该架构。首先是一个纯物理图,显示机器、JVM、Master/Workers 怎样在网络上彼此关联。
 注意在一台机器上可能会有多个JVM。如果一个JVM 堆已达到其允许最大值,但机器上还有更多物理内存、另一个JVM 可以使用,你可以这样做。
注意在一台机器上可能会有多个JVM。如果一个JVM 堆已达到其允许最大值,但机器上还有更多物理内存、另一个JVM 可以使用,你可以这样做。
那么,Terracotta 在物理架构中放在哪里呢?它监视所有的JVM——那么,用第二种更合乎逻辑的可视化图也许能最好地阐明:
 我们看到Terracotta 装备了JVM,使这些JVM 能越过物理网络透明地共享工作项队列。它甚至可以添加另外的Masters,使它们也共享该队列。
我们看到Terracotta 装备了JVM,使这些JVM 能越过物理网络透明地共享工作项队列。它甚至可以添加另外的Masters,使它们也共享该队列。
学习Terracotta:一个例子
虽然Terracotta 不要求你明确地开发分布式代码,但从长远来看,如果master 和workers 之间共享的数据能降至最少,Terracotta 会有利于整体性能。workers 越是能自主执行它们的操作,Terracotta 服务器跨越多个JVM 管理的东西就越少。
用这个去开发解决方案会让我们遇到一些麻烦和错误。为了有助于解释遇到的一些障碍,我们来举一个简化的例子。
我们的应用处理多个文件,这些文件包含由逗号分隔值(comma-separated values,CSV)组成的记录。此外,每一条CSV 记录包含一个叫日最大使用量(Maximum Daily Usage,MDU)的属性。为简单起见,我们只说我们的任务是报告每个文件的MDU 最大值,当然还有其它东西(实际的处理远比这个要复杂)。
按照 Jonas 的博文,我们起初创建了实现 Work 接口的 WorkUnit,Work 接口由 CommonJ WorkManager 规范定义。WorkUnit 负责处理指定的文件,找出 MDU 最大值。代码如下:
public class WorkUnit implements Work<br></br> {<br></br> private String filePath;<br></br> private Reader reader;<p> public WorkUnit(String aFilePath)</p><br></br> {<br></br> filePath = aFilePath;<br></br> }<p> public void run()</p><br></br> {<br></br> private String maxMDU = "";<br></br> setReader(new BufferedReader(new FileReader(filePath)));<br></br> String record = reader.readLine();<br></br> while (record != null)<br></br> {<br></br> String[] fields = record.split(",");<br></br> String mdu = fields[staging:4];<br></br> if (mdu.compareTo(maxMDU) > 0)<br></br> {<br></br> setMaxMDU(mdu);<br></br> }<br></br> record = reader.readLine();<br></br> }<br></br> System.out.println("maximum MDU = " + maxMDU);<p> doStuffWithReader();</p><br></br> doMoreStuffWithReader();<br></br> doEvenMoreStuffWithReader();<br></br> }<br></br> private void setReader(Reader reader)<br></br> {<br></br> this.reader = reader;<br></br> }<br></br> ... }对于指定目录下的每个文件,Master 都创建一个 WorkUnit,向它提供要处理的文件的位置。接着 WorkUnit 封装在 WorkItem 里面——WorkItem 包含一个状态标志——并将其放在共享队列中被调度。然后我们的 Worker 实现获取 WorkItem、得到 WorkUnit,并调用它的 run() 方法,run() 方法反过来处理文件并报告 MDU 最大值。接着它会继续处理文件的其它内容。
需要注意的关键一点是,我们选择把 Reader 做为一个实例变量来存储——它实际上被很多方法用到,使用局部变量并到处传递也是不切实际的。
为了在 workers 之间共享队列,我们像下面所示的那样来配置 Terracotta 的 tc-config.xml 文件:
<application><br></br> <dso><br></br> <roots><br></br> <root><br></br> <field-name><br></br> com.shinetech.mrs.batch.core.queue.SingleWorkQueue.m_workQueue<br></br> </field-name><br></br> </root><br></br> </roots><br></br> <locks><br></br> <autolock><br></br> <method-expression>* *..*.*(..)</method-expression><br></br> <lock-level>write</lock-level><br></br> </autolock><br></br> </locks><br></br> <instrumented-classes><br></br> <include><br></br> <class-expression><br></br> com.shinetech.mrs.batch.core.queue..*<br></br> </class-expression></include> <include><br></br> <class-expression><br></br> com.shinetech.mrs.batch.input.workunit..*<br></br> </class-expression><br></br> </include><br></br> </instrumented-classes><br></br> </dso><br></br> </application>你不必明白这个文件的太多细节,除了知道它指定了共享的属性——这里就是我们的队列——并指定了应该装配哪个类来安全地共享它。
我们第一次使用 WorkUnit 运行时失败了——当 WorkUnit 去给 reader 变量赋值时,Terracotta 抛出了 UnlockedSharedObjectException 异常,异常信息是“Attempt to access a shared object outside the scope of a shared lock”。实质上 Terracotta 告诉我们,我们在更新由 Master 和 Worker 共享的对象的一个属性,但是我们并没告诉 Terracotta 这个属性需要加锁(或同步)。
关键问题是,尽管在运行 worker 之前我们都不实例化该实例变量,但是 Terracotta 认为它是由 master 和 worker 共享的,因为这个变量属于共享队列上的一个对象。(顺便说一下,Terracotta 的异常处理非常棒;如果你试图去做你不能做的事情,Terracotta 异常就会告诉你你做错了什么、以及做些什么去修复它)。
在这个阶段我们能采用几个不同的方法。其中一个方法是,在 WorkUnit 中添加一个同步的 setReader() 方法。Terracotta 会根据 tc-config.xml 中的 autolock 片段锁定对 reader 的访问。不改变源代码的选择是,我们可以在 tc-config.xml 文件的 locks 片段中添加一个 named-lock,它反过来告诉 Terracotta 有效地跨越 JVM 集群对 reader 的访问进行同步。
<named-lock><br></br> <lock-name>WorkUnitSetterLock</lock-name><br></br> <method-expression><br></br> * com.shinetech.mrs.batch.dataholder..*.set*(..)<br></br> </method-expression><br></br> <lock-level>write</lock-level><br></br> </named-lock>然而,这两个办法最终都不是我们所需要的。举一个更为现实和复杂的例子,WorkUnit 可能有很多实例变量,它们实际上只在由 Worker 运行的时候才是相关的。Master 不需要了解它们的任何东西,它们实际上也只在 run() 方法运行期间存在。从性能角度来看,如果 Master 永不访问 WorkUnit 的属性,那么我们是不希望 Terracotta 对这些属性的访问进行同步的。
我们真正想要的是 WorkUnit 不由 master 实例化的能力,而是在 Worker 从队列中获取 WorkItem 的时候实例化 WorkUnit。要做到这一点,我们引入了 WorkUnitGenerator:
public class WorkUnitGenerator implements Work<br></br> {<br></br> private String filePath;<p> public WorkUnitGenerator(String aFilePath)</p><br></br> {<br></br> filePath = aFilePath;<br></br> }<br></br> public void run()<br></br> {<br></br> WorkUnit workUnit = new WorkUnit(filePath);<br></br> workUnit.run();<br></br> }<br></br> }现在,Master 创建了 WorkUnitGenerator,提供给它要处理文件的位置。WorkUnitGenerator 封装在 WorkItem 里面,并被调度。Worker 实现获取 WorkItem、得到 WorkUnitGenerator,并调用它的 run() 方法。run() 方法实例化一个新的 WorkUnit 对象,并委托 WorkUnit 的 run() 方法完成文件处理。所以,在我们的情况中 WorkUnit 应该独立于 Master,现在的情形是 WorkUnit 实际上就是独立的,Terracotta 也不需要跨越 JVM 做任何不必要的同步。
上面概述的代码例子仅仅是实现主 / 从模式的一个方法。可能还有完成它的其它方法,随着积累更多的 Terracotta 经验,我们也可以找到更好的实现。主要的一点是,尽管 Terracotta 和主 / 从模式有跨多台机器分布工作的能力,但是你必须注意你想共享的和你不想共享的东西。
性能结果
Terracotta 的概念验证显示了很多希望,但它真的能交付吗?为此设计一个情景来测试应用的扩展性。89 个数据文件被加载,总共包含 872,998 条记录。这些都是从一个真实的生产系统里面获得的,因此使我们有信心建立一个真实的数据集。
Terracotta 服务器和单个主进程运行在一台机器上。不同数目的分布式 worker 机器用来处理数据,每台机器上运行 4 个 worker。结果如下:
Worker Machines Workers Time (seconds) 1 4 416 2 8 261 3 12 214 4 16 194 5 20 193 这些数据可图形展示,如下:
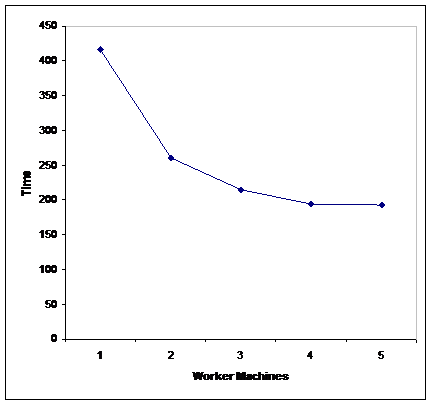 只在一台机器上运行 4 个 worker,加载 89 个文件花费的总时间是 416 秒。在我们的分布式计算系统中只增加了一台 worker 机器,加载 89 个文件的时间就几乎减半。每增加一台新的 worker 机器,都会获得进一步的性能提升。
只在一台机器上运行 4 个 worker,加载 89 个文件花费的总时间是 416 秒。在我们的分布式计算系统中只增加了一台 worker 机器,加载 89 个文件的时间就几乎减半。每增加一台新的 worker 机器,都会获得进一步的性能提升。
正如从上图中看到的一样,扩展性开始趋于稳定。随着添加更多的 worker,数据库服务器受到了增加负荷的影响,并在一些点上最终可能成为瓶颈。
结论
通过扩展 Joseph Boner 对 Terracotta 和主 / 从模式的工作,我们能在我们的应用中建立一个分布式计算组件。
在这一阶段,我们的应用运行在一个客户的生产环境里面,客户的数据处理需求只需要使用单机。但是,使用从另一个生产环境获得的更大的数据集跨多台机器进行性能测试后,我们仍然确信在时机成熟的时候 Terracotta 能够满足应用的规模扩大的要求。
最终证明数据库是瓶颈,但鉴于我们得到的性能,还是可以忍受的。如果你运行的进程是只受到 CPU 能力限制的,那么伸缩性上的提高就不可估量了。
目前在我们的架构中,所有 Masters(即创建被执行任务的进程)都与 Terracotta 一起运行在同一台机器上的,现在对我们来说,万一当前单个 Master 机器超载了,添加额外的 Master 机器来扩展 Master 负载还是一个繁琐的工作。
Terracotta 已经在背后帮我们的应用做了许多脏活累活。我们正期待着在接下来的几个月里,看着它的性能随真实数据集的增加而增加,并看到我们其它的应用怎样从我们的经验中受益。




