DynamoDB 是一个高效而灵活的 NoSQL 数据库服务,它的主要特色就是便于管理,因此使用者不必担心各种管理方面的任务负担,例如操作和扩展数据库等等。使用者可以更关注于应用程序的设计,并且在通过几个简单的步骤后将其发布到 DynamoDB 服务上。
在本文中,我们将为你展示如何使用 Amazon DynamoDB 创建一个应用程序。
火星探测器应用程序
我们在本文中所讲述的示例应用将为读者展示 DynamoDB 数据库的强大功能。这一 web 应用展现了 NASA 向公众开放的数据,即好奇号火星探测器(Curiosity Mars Rover)从火星所发回的图像,以及用 JSON 格式描述的图像元数据。以下是 NASA JSON 数据的一个小片段,以及该示例应用的一张屏幕截图。你也可以自己尝试一下在线的示例应用!
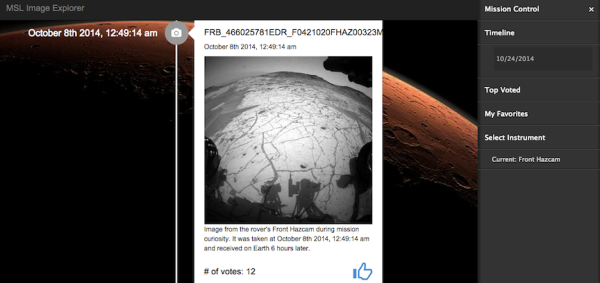
图 1:火星探测器示例应用的屏幕截图
以下是包含了图片细节的JSON 数据集。
(单击图片以放大)

图 2:来自NASA 的一段图片JSON 数据
在这个示例应用上线之前,我们特意收集了NASA 的所有数据,所上图所示。并把所有图片的JSON 数据都导入到一张DynamoDB 表中,为将来查询做准备。在所有数据都导入DynamoDB 之后,我们对数据表进行了大量的查询与更新,才最终得到了这个火星探测器应用,让它能够显示一个精美的图片浏览器,正如上图所示。
该应用程序的默认视图是来自于好奇号的摄像头、或摄像仪器中所返回的所有图像的时间线,以时间顺序倒序排列。用户可以投票选出他们最喜欢的图片,每张图片的投票数量都是实时维护的。此外,用户可以打开“任务控制”侧边菜单,以改变所使用的摄像仪器、时间范围、或是根据投票数量对图片进行排序。最好,用户也可以在“我的最爱”选项中查看所有投过票的图片。
以上所有这些特性的实现,都是通过对存储了图片数据的DynamoDB 表进行查询而实现的。为了创建这样一个应用程序,你通常需要考虑多种功能组件,例如访问控制、用户追踪、数据序列化/ 反序列化,等等。我们将通过对创建火星控制器这一示例的解释,为你展现用DynamoDB 实现以上这些功能是多么简单,并且你也可以使用DynamoDB 创建你自己的应用程序!不过,在我们深入讲解这个示例之前,让我们先快速地了解一下DynamoDB。
数据模型
DynamoDB 的数据模型概念中包含了表、项目和属性。一张表是一系列项目的集合,而每个项目又是一系列属性的集合。
与关系型数据库不同,DynamoDB 是一种无 schema 的 NoSQL 数据库。一张 DynamoDB 表中的每个项目都可以拥有不同数量的属性。每个项目中的属性是一个键 - 值对。每个属性既可以是单值的,也可以是多值的集合,稍后将讨论数据类型的细节。此外,最近发布的 JSON 文档支持功能允许 JSON 对象以项目的形式直接保存在 DynamoDB 中,最大可达每个项目 400KB。举例来说,NASA 以 JSON 对象的方式提供火星探测器传回的每张图片,因此每张图片都能够保存为 DynamoDB 中的一个独立的项目,而地点和时间等属性则能够被直接导入。
考虑一下将一系列从火星探测器所传回的图片保存在 DynamoDB 中的情形。你可以创建一张名为 marsDemoImages 的表,为每一张图片分配一个唯一的 imageid 属性(这也被称为表的主(哈希)键):marsDemoImages ( imageid,… )
这张表的每个项目都可以包含各种其它的属性,以下是一些属性的示例:
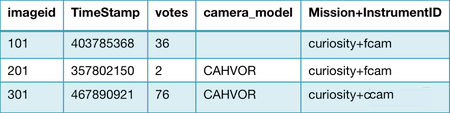
表 1:marsDemoImages 表中的一些示例项目
请注意:在本例中,“imageid”是唯一一个必需的属性,其它所有属性都能够自动从 NANA 的 JSON 图片数据集中进行导入。实际上,在这个示例中,101 这个项目并不包含“camera_model”这个属性。"Mission+InstrumentID"则是一个混合属性,在接下来的一节将对此进行解释。
主键
当你创建一张表时,你必须指定该表的主键。DynamoDB 支持以下两种类型的主键:
· 哈希类型主键:这种类型的主键由一个哈希属性所构成。在之前的示例中,marsDemoImages 表中的哈希属性就是“imageid”,正如下图所示。
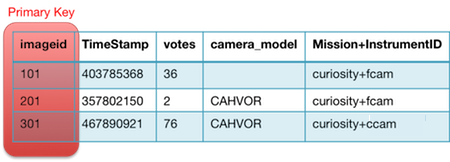
表 2:marsDemoImages 中的部分项目示例,其中的主哈希键高亮显示
· 哈希及范围类型主键:这种类型的主键由两个属性所构成。第一个属性是哈希属性,而第二个属性是范围属性。在火星探测器这个示例中,假设我们打算首先以“imageid”字段、随后以“votes”字段对项目进行分组。那么哈希属性就是“imageid”,而范围属性则是“votes”。
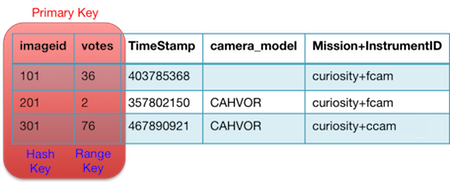
表 3:marsDemoImages 中的部分项目示例,其中的主哈希与范围键高亮显示
查询、更新与扫描
除了使用主键对特定的项目进行访问与操作之外,Amazon DynamoDB 也提供了多种方式对特定的数据进行搜索:即查询、更新与扫描。
查询:查询操作仅使用主键属性的值查找某张表中的特定项目。你必须提供一个哈希键的属性 - 值对,并可选择地提供一个范围键的属性 - 值对。
举例来说,在火星探测器应用中,我们可以通过“imageid = 201”这样的键 - 值对来查询某张特定的图片。
更新:更新操作与查询操作相类似,区分就在于你能够修改项目的属性了。条件式更新允许你在某个特定的条件满足之后,才能够对项目进行修改。稍后我们将看到这方面的一个示例,我们将对火星探测器应用中图片的投票数进行更新。
扫描:一次扫描操作将对整张表中的每个项目进行分析。在默认情况下,一次扫描操作会返回每个项目中的所有数据属性。
二级索引
对整张表进行扫描在某些情况下会降低效率,为了避免这种情况,我们可以创建二级索引,以辅助查询的处理。表中的二级索引能够帮助优化对非键属性的查询。DynamoDB 支持两种类型的二级索引:
- 本地二级索引:该索引持有一个与表相同的哈希键,但有一个不同的范围键。
- 全局二级索引:该索引持有一个哈希键与一个范围键,它们的值可以与表中的对应值不同。
可以将二级索引想象为额外的表,它们首先由哈希键进行、再由范围键进行分组。举例来说,在 marsDemoImages 表中,我们可能需要查找来自于某个特定任务与拍摄仪器的图片,并按照某个时间范围进行过滤。因此我们就可以创建一个二级索引,让它首先按照“Mission+Instrument”属性(哈希键)进行分组,随后按照“TimeStamp”属性(范围键)进行分组。下图是该索引的一个示例,在下一节关于 marsDemoImage 表的介绍中,我们还将详细分析二级索引的更多细节。

表 4:marsDemoImages 表中某个二级索引的示例
数据类型与 JSON 支持
Amazon DynamoDB 支持一系列新的数据类型:
- 标量类型:数字、字符串、二进制、布尔和 Null。
- 多值类型:字符串集、数字集和二进制集。
- 文件类型:List 和 Map。
比方说,在 marsDemoImages 表中,imageid 是数字类型的属性,而 camera_model 则是字符串类型的属性。
其中最值得注意的是最新发布的数量类型:List 和 Map,这两种类型非常适合用于 JSON 文档的保存。List 数据类型与 JSON 数组非常相似,而 Map 数据类型则类似于一个 JSON 对象。List 或 Map 元素能够保存的数据类型是没有限制的,只是每个项目最多不能超过 400KB,并且最多支持 32 个级别的内嵌属性。此外,DynamoDB 还允许你访问 list 和数组中的每个元素,即使这些元素的嵌套层数相当多。DynamoDB 的这个特性相当令人兴奋,它让开发使用 JSON 数据的 web 应用程序变得相当简单直接,接下来就让我们看看火星控制器这个示例的后台工作原理是什么。
火星探测器应用的后台工作原理
火星探测器应用的实际工作原理是什么?在这一节中,我们将让你了解,DynamoDB 中的 JSON 文档支持功能让这一应用的创建变得非常简便与直接。我们使用了 AngularJS 来创建这个应用程序,这是一个非常流行的 JavaScript web 应用框架,不过本文中的概念也适用于其它任何编程语言。如果你希望预览一下该应用的源代码,可以在GitHub 上的awslabs 帐号下找到完全公开的源代码。
为了理解这个应用程序的运行原理,让我们来看一看下图所示的火星探测器应用程序的整体架构,我们将一步一步地为你讲解每个组件的作用。
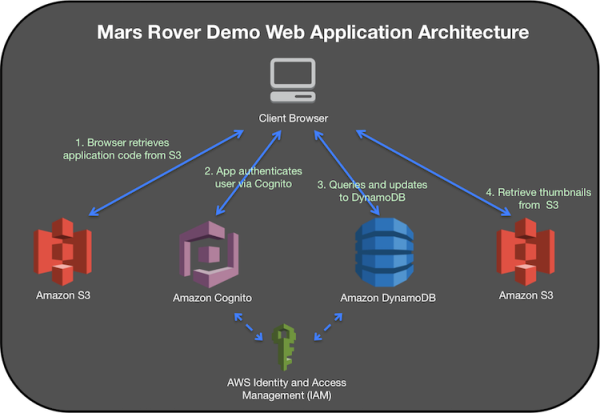
图 3:火星探测器的设计架构
浏览器客户端从Amazon S3 获取应用代码
当用户开始访问火星探测器示例的应用程序网站时,浏览器就会从 Amazon S3 获取应用程序代码,包括 HTML、CSS 和 JavaScript。通过使用 DynamoDB 和 S3,我们就能够在客户端完整地运行整个应用程序,就样就能够避免自己管理服务器的各种麻烦。
应用程序将通过 Amazon Cognito 对用户进行验证
在这一步骤中,应用程序将通过 Amazon Cognito 对用户进行授权,让用户得以访问 DynamoDB 表。Amazon Cognito 是一个简单的用户认证与数据同步服务,它能够在未认证访客与 DynamoDB 之间建立关联,允许任意用户对该应用程序所对应的 DynamoDB 数据表进行查询,并且对表中的某些属性进行有限制的更新操作。如果你打算自己部署这个示例,那么你也可以使用 DynamoDB Local 将整个应用程序运行在你自己的本地机器上,以进行开发或测试工作。在 GitHub 上的火星探测星应用源代码的 README 文档中可以找到在本地运行这一应用的操作指南。
让我们回到这个在线示例的认证环节,通过使用 Amazon Cognito,我们就能够轻易地管理访问对 DynamoDB 数据表的访问,并收集访问者的数量等相关的统计信息。下图是一个截图示例:
(单击图片以放大)

图 4: Cognito 统计数据界面的截图示例
通过使用 Amazon Cognito,你就可以使用各种公开的登录提供者,例如 Amazon、Facebook 和 Google,或是使用自己的用户身份系统为访问用户创建独立的用户身份信息,以访问 AWS 云服务。用户也可以选择作为未认证的访客身份访问你的应用。我们在这里使用了未认证访客访问特性,为 web 浏览器提供 AWS 身份信息,并对每个用户进行唯一识别。我们按照下面所列出的步骤将应用程序部署到生产环境中,你也可以用同样的步骤将你自己的应用程序进行部署:
- 为该应用程序创建一个 Amazon Cognito 身份池,这一步可以在 Amazon Cognito 的管理控制台中完成。你可以选择使用默认设置,只需确保“允许非认证身份访问”被选中即可。
- 对 AWS 身份与访问管理(IAM)进行配置,对于该示例应用运行所需的最小权限进行授权:
- 对 _marsDemoImages_ 表进行读取
- 使用 _date-gsi_ 与 _votes-gsi_ 进行 _ 查询 _
- GetItem
- 对 _marsDemoImages_ 进行写入
- 更新 _votes_ 字段
- 对 _userVotes_ 表进行读取
- _ 查询 _ 属于用户自己的项目,但不可查询其他人的项目
- 对 _userVotes_ 表进行写入
- 对属于用户自己的项目进行 _PutItem_ 操作,但不可操作其他人的项目
- 对应用的配置进行修改,以使用 Amazon Cognito 服务。火星探测器示例应用通过 viewer/app/scripts/services/AWS.js 这个文件启动 DynamoDB 客户端的功能,并根据预先完成的配置信息,为其提供 AWS 的身份认证。当你在本地运行该应用时,你可以在启动该示例前对这些配置信息进行改动,也可以通过使用 Grunt 创建可发布的包。如果你打算转而使用 Cognito 身份池认证方式,那么可以在 viewer/lib/mynconf.coffee 文件中进行相应的配置修改。
对 DynamoDB 进行查询与更新
用户可以根据日期、投票数和已保存图片等不同选项对图片进行选择。每次选择都是对 DynamoDB 数据表和索引的一次查询。为了充分理解这个过程的工作原理,我们需要深入了解 DynamoDB 的某些方面:
- 表 schema 和全局二级索引(GSI)的配置,
- 查询执行,以及……
- 更新执行
表 schema 和 GSI 的配置
让我们首先来创建一张 DynamoDB 数据表!你可以通过 AWS 管理控制台,或是 AWS 开发 SDK 来完成这一任务。我们在这个示例中使用了由 CoffeeScript 生成的 JavaScript 文件,可在 /viewer/lib/prepare_tables.coffee 找到源代码。其中最重要的部分是对 DynamoDB 数据表的 schema 的描述,以及 GSI 的配置,该数据表用于保存图片数据,以下是该表的具体形式:

表 5:marsDemoImages 的表 schema
我们决定将“Mission”与“InstrumentID”这两个数据字段进行组合,以允许对多个属性进行同时查询。由于应用程序中的每个视图通常都对应着某个特别任务的一个仪器,因此可以选择专注于“Mission”与“InstrumentID”,使用这个组合属性作为 GSI 的哈希键,并且另外选择一个属性作为 GSI 的范围键。举例来说,用户可以在火星探测器的进行探险任务时,从“前端避险摄像头”仪器获取所有的图片,并根据日期进行过滤。GSI 就能够提供这种类型的查询,该表中的 GSI 如下图所示:

表 6:marsDemoImages 表中的全局二级索引的 schema
创建 date 这个 GSI 的作用是允许用户根据基于某个特定的仪器和任务,根据图片的创建日期对图片进行过滤。GSI 通过索引哈希和范围键对项目进行分组,这意味着 date GSI 所包含的图片数据首先会根据“Mission+Instrument”属性进行分组,随后再根据“Timestamp”进行分组。这就允许应用程序能够快速地根据特定日期查找图片,例如找到于 10/04/2014,通过“Curiosity+Front Hazcam”这个任务 - 仪器组合所拍摄的图片。
与之类似,创建 vote 这个 GSI 的作用是为了火星探测器示例应用的“投票最多”这一视图所用。在这一情景下,索引哈希键依然是“Mission+Instrument”,而范围键则是“votes”。该索引首先通过“Mission+Instrument”对项目进行分组,接下来再使用“votes”进行分组,这意味着它能够优化这样的查询:基于某个特定的任务和仪器,并根据投票数进行排序的图片结果。
接下来,我们需要一张额外对数据表,以追踪用户为哪些图片进行了投票,这样可以避免用户对同样的图片进行多次投票。这张表的 schema 很简单,也不需要用到 GSI:

表 7:userVotes 表的 schema
最后,我们将调用 createTable 方法,以创建 DynamoDB 中的所有表和二级索引。这项任务由 /viewer/lib/prepare_tables.coffee 这个脚本所完成,如果你遵照源代码中的 README 文件的指令进行操作,就会自动调用这个脚本。
查询执行
火星探测器应用程序使用了目前非常流行的 web 开发框架 AngularJS 。从本质上说,该 web 应用的每个视图都是由对应的 controller 所创建的:timeline 视图对应着一个 timeline controller,而 favorites 视图对应着一个 favorites controller,等等。这些 controller 都会使用一个通用的 Amazon DynamoDB 服务与 DynamoDB 中的数据表进行通信。这个 MarsPhotoDBAccessservice 服务位于 viewer/app/scripts/services 目录下,其中包含了应用程序中所有的查询与更新操作。queryWithDateIndex 函数则用到了文档级别的 JavaScript SDK,使得对项目的访问更加简便与直接:
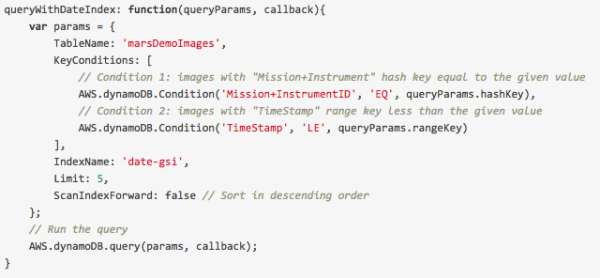
与之类似的是,可以对 vote GSI 进行查询请求,以允许用户对图片按照投票数量进行倒序排列:
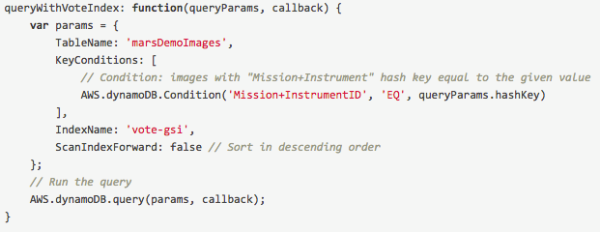
更新执行
对图片进行投票的工作方式与查询非常类似,区别仅在于我们需要对表中的现有项目进行更新操作。不过在那之前,我们首先需要检查一下,该用户之前是否已经为同样的图片投过票了。可以通过对 DynamoDB 中的第二张表 userVotes 进行一行条件式写入实现这一功能,创建这张表的目的是对已经为图片投过票的用户信息进行追踪。如下图所示,可以使用 Expected 参数进行条件设置。
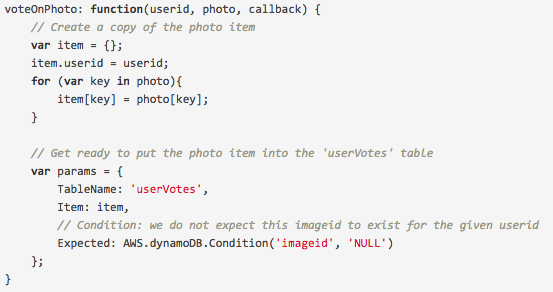
在以上代码片段中,我们设定的期望是在表中不存在这个指定的 imageid 与 userid 的组合,因为这应该是该用户首次对某张图片进行投票。之后,在满足了该条件的情况下,我们就尝试将该项目加入 userVotes 表中。
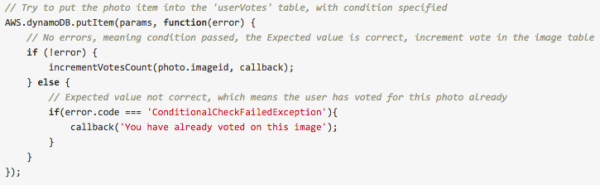
当检查过程结束之后,我们可以通过 JSON 文档 SDK 对“marsDemoImages”表中的投票总数进行更新,该 SDK 允许用户以一种简便且直接的方法对个别的 JSON 字段进行更新。让我们来看一下 incrementVotesCount 这个函数是如何运行的:

请注意:“UpdateExpression”和“ExpressionAttributeValues”这两个参数是由 JSON 文档 SDK 所引入的,它们提供了对 JSON 数据更多的访问方式。要想了解更多细节信息,请参考 GitHub 上的 awslabs 帐号下的代码库中与修改项目属性相关的文档。
从 Amazon DynamoDB 中获取缩略图
对 DynamoDB 中的数据表进行查询之后,JSON 结果就返回给浏览器端,此时可以从 Amazon S3 中获取图片的缩略图。我们目前在在线的示例网站中采取的就是这种实现方式。不过,我们也可以选择将所有的缩略图二进制数据保存在 DynamoDB 里,在每个项目的“data”属性中。DynamoDB 能够保存各种二进制数据,而无需指定它的类型、限制或 schema,只要该数据不作为哈希键或范围键属性,并且满足每个项目最大 400KB 的限制就可以了。我们之所以在这个公开的在线示例中选择从 S3 中获取图片,而不是直接从 DynamoDB 获取,原因是为了减少大量读取所带来的成本。不过 DynamoDB Free Tier 版本为用户提供了 25GB 的免费存储空间,并且读取与定入的最大限制为 25。如果你能够动手实验一下,创建属性自己的 web 应用程序和 DynamoDB,那是再好不过了。
结论
本文为读者介绍了如何使用 Amazon DynamoDB 服务创建一个火星探测器应用。你也可以应用本文中所介绍的概念来打造你自己的 web 应用程序。让我们来回顾一下整个应用开发的过程:
- 设计你自己的 DynamoDB 表,包括 schema、主哈希键、以及(可选的)范围键,以及二级索引。
- 使用 AWS 管理控制台,或使用我们的 AWS SDK 创建表与索引。在这个示例中,我们所使用的是 JavaScript SDK。
- 选择你打算使用的语言和 web 开发框架,我们所选择的是 JavaScript 语言及 AngularJS 框架。
- 开始为应用进行编码,编写对 DynamoDB 数据表进行查询或更新的各种函数。如果你选择使用 JSON 并使用我们提供的文档级别的 SDK ,那么这一过程将变得非常容易。
- 最后,发布你的应用吧!
关于作者
 Daniela Miao是一位负责 Amazon Web Services 的软件开发工程师,在 DynamoDB 开发者生态系统团队中工作。该团队的工作目标是为了改善 DynamoDB 的客户体验,通过编写各种类库与工具以简化 DynamoDB 应用程序的编写。她希望能通过诸如示例讲解、示例应用、博客帖子等等方式为开发者传授知识,减少他们在使用 DynamoDB 时可能会遇到的各种阻碍。如果你在 DynamoDB 的使用方法有任何疑问和建议,或者希望了解更多的相关信息,请通过 dynamodb-feedback@amazon.com 这个邮件与她取得联系。
Daniela Miao是一位负责 Amazon Web Services 的软件开发工程师,在 DynamoDB 开发者生态系统团队中工作。该团队的工作目标是为了改善 DynamoDB 的客户体验,通过编写各种类库与工具以简化 DynamoDB 应用程序的编写。她希望能通过诸如示例讲解、示例应用、博客帖子等等方式为开发者传授知识,减少他们在使用 DynamoDB 时可能会遇到的各种阻碍。如果你在 DynamoDB 的使用方法有任何疑问和建议,或者希望了解更多的相关信息,请通过 dynamodb-feedback@amazon.com 这个邮件与她取得联系。
 Kenta Yasukawa是 Amazon Web Services (AWS) 的一位高级解决方案架构师。他专注于为游戏商、移动应用后台、社交网络服务等客户设计基于云的解决方案。他对于利用 AWS 云的各种功能,设计具备高伸缩性和可靠性的架构有着很高的热情。Amazon DynamoDB 是整个架构设计中的关键组件,他已经看到有许多客户通过使用 Amazon DynamoDB 成功地创建了各种具备高伸缩性和可靠性的架构。如果你希望了解这些成功的故事,欢迎与我们进行联系。
Kenta Yasukawa是 Amazon Web Services (AWS) 的一位高级解决方案架构师。他专注于为游戏商、移动应用后台、社交网络服务等客户设计基于云的解决方案。他对于利用 AWS 云的各种功能,设计具备高伸缩性和可靠性的架构有着很高的热情。Amazon DynamoDB 是整个架构设计中的关键组件,他已经看到有许多客户通过使用 Amazon DynamoDB 成功地创建了各种具备高伸缩性和可靠性的架构。如果你希望了解这些成功的故事,欢迎与我们进行联系。
查看英文原文: Building a Mars Rover Application with DynamoDB
立即免费注册 AWS 账号,获得 12 个月免费套餐:点击注册
有云计算问题?立刻联系 AWS 云计算专家:立即联系




