
微服务和高度分布式的系统是非常复杂的。系统中有许多移动部件,包括应用程序本身、基础设施、版本和配置。通常,这会导致运维人员难以跟踪生产或其他开发环境(QA、开发、预生产)中的实际情况,而当你需要对系统进行排障时这又成了一个问题。
在这篇文章中,我将围绕监控和可观察性的不同用例澄清一些内容,讲一下什么时候用到这两个概念,以及如何正确使用它们。然后我将专注于变更感知(Change Intelligence)这个主题,这种新方法能够遥测可操作的指标、日志和跟踪等信息,以便实时有效地对事件排障。到目前为止,可观察性一直专注于集合与你系统相关的数据,而监控则是标准化的检查,以验证基于这些数据的一切工作是否正常。变更感知构成了对现有遥测技术的增强,在所有东西都是分布式、公司有几十甚至几百个服务都在相互通信的当今世界里提供了更多上下文。这样运维人员就可以在最近的变更之间建立联系,并最终了解它们对整个系统的影响。
可观察性和监控之谜
我们先来了解一下监控和可观察性,以及今天在具有复杂的微服务运维活动的工程组织中一般是如何实现它们的。
你经常会听到有人说,可观察性是指标、日志和跟踪的总和,但事实上,这种遥测只是正确获得可观察性的前提。为了让数据真正可用,你需要确保它与你的业务需求和应用程序的工作方式建立联系。
谈到监控时,大多数人想到的是仪表板。它们可能非常漂亮,但大多数开发人员并不真的想花一整天的时间盯着它们。这些往往是静态警报,需要开发人员预先确定什么东西可能出错。
我看到的一个有趣的趋势是,运维人员实际上利用可观察性工具来找到问题的根因,然后将这种学习成果纳入监控工具,以监控在未来重复出现的问题。如果你有适当的文档和运行手册,监控和可观察性之间的结合可以为你的可靠性计划创造奇迹。
这些检查可以是各种形式,简单的例子是确保某个系统的延迟低于某个阈值,或更复杂的例子,检查一个完整的业务流程是否符合预期(将物品添加到购物车,并成功结账)。你可能认为你已经掌握了系统中发生的全部情况,因为你已经有了监控和可观察性,但是你仍然需要一块关键的拼图才能够看到完整的情况。
缺少的拼图:变更感知
为了能够在问题出现时从系统中真正获得你所需要的洞察力,你需要在拼图中加入另一块内容,那就是变更感知。变更感知不仅包括了解某些东西何时发生了变更,还要了解它为什么发生了变更,谁改变了它,以及变更对你的系统产生了什么影响。
对于运维工程师来说,现有的数据冲击往往让人不知所措。因此,引入变更感知是为了提供关于遥测的更广泛的上下文,以及你已经拥有的信息。例如,如果你有三个服务在相互交流,而其中一个服务的错误率升高,根据你的遥测,这就是一个很好的指标,说明出了什么问题。
这是怀疑你的系统出了问题的一个很好的依据,然而,下一步,也是更关键的一步,你总是要开始挖掘,找到这个异常遥测数据背后的根因。如果没有变更感知,你需要分析无数的问题来了解根因,即使你是按照你之前所做的那样一步步遵循某个指南也无济于事,因为到头来,每个事件都是独一无二的。
那么,变更感知包括哪些内容呢?
首先,如果你正确实现了变更感知,它应该包括与“哪个服务正在与哪个服务通信”有关的所有上下文(如服务映射)、在服务 A 中做出的变更如何影响其他服务(由于依赖关系,包括下游和上游)的信息、在应用程序层面做出的配置变更和在基础设施层或云环境中做出的配置变更、没有被钉住导致你无法控制的雪球效应的版本、云环境中断,以及任何可能影响业务连续性的东西。
因此,把这三个概念联系在一起就会是:
可观察性为你提供符合你业务需求的数据格式。
监控是一组检查,以确保你的业务在正常运行。
变更感知将所有这些信息联系起来,使你能够了解系统中的变更内容/原因/对象/方式,从而更快找到事件根因。
实践中的事件排障
在转向微服务之前,我曾在单体环境中工作,所以对这些类型的环境之间的巨大差异有第一手经验。在单体系统中,监控和可观察性是很好的元素,而在微服务中它们是完全必要的。
试图对系统中具有不同目的和执行不同任务的多个服务进行排障是非常复杂的任务。这些较小的服务通常被分割成较小的块状,并同时运行几个操作,因此需要在它们之间不断交流信息。
所以举个例子——当你收到一个警报(通常是以页面或 Slack 上的消息的形式),通知你业务的某个部分没有正常工作——很多时候,在真正的大规模分布式环境中,这可以归因于许多不同的服务。如果没有适当的监控和可观察性,你并不能马上看出来哪个服务出现了故障。它们可以帮助你了解在这个微服务的管道中问题出在哪里,以及具体是哪个组件出现了故障。
当你处于某个事件产生的漩涡中时,你将花大部分时间试图了解问题的根因来排障。你首先要弄清楚问题发生在你的数百个应用程序或服务器中的什么地方,然后一旦你隔离掉出故障的服务或应用程序,你就会想了解到底发生了什么。这假定了一些并不总是被满足的先决条件:
你有所有相关系统的必要权限
你了解整个堆栈和所有这些系统中的所有技术
你有足够的经验来充分理解问题,进而解决问题
作为一名 DevOps 工程师(今天在 Komodor,以前在 Rookout),我经常遇到这些类型的场景,所以这里有一个来自前线的简短故事。我记得有一次,我和我的团队开始收到来自我们系统中一个关键服务的大量错误[剧透:我们收到了数字值,当试图将它们插入我们的数据库时,列类型不匹配]。
我们唯一可以使用的错误信息是:无效值。然后我们不得不搜索我们的系统和最近的变更,试图了解我们正在处理的数据和错误——我们花了一整天的时间来研究这个错误,最终了解到这是七个月前实现的一个变更。数据库中的列类型是整数,而我们试图插入更大的数字,因此需要一个大整数数据/列类型。如果没有任何平台或系统来帮助我们将这些错误与相关的变更联系起来,对于七个多月前发生的配置来说,即使是像数字太大这样简单的事情,也会让整个有经验的团队花上一整天的时间,因为我们没有变更感知来帮助我们解决问题。
所以——记住这个例子,现在让我们看看其他一些例子,我将展示在有和没有变更感知参与的情况下,排障工作分别会是什么样子。
可观察性实例
在这个例子中,你会看到一个显示请求数、错误数和响应时间的延迟的仪表板。
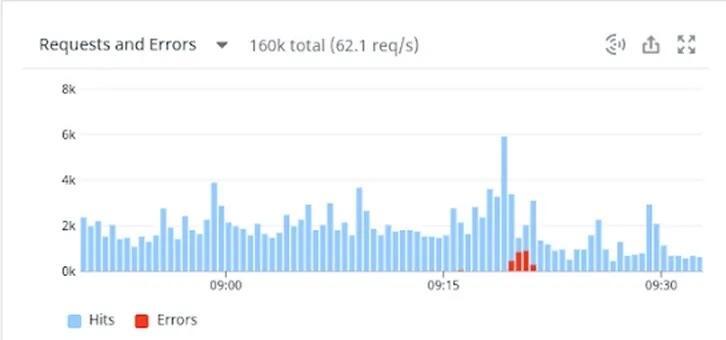
基于可观察性的监控
接下来监控会进来摄取这些数据,然后提供对适当阈值的理解,以检查在它历史的上下文下这是否可以接受。
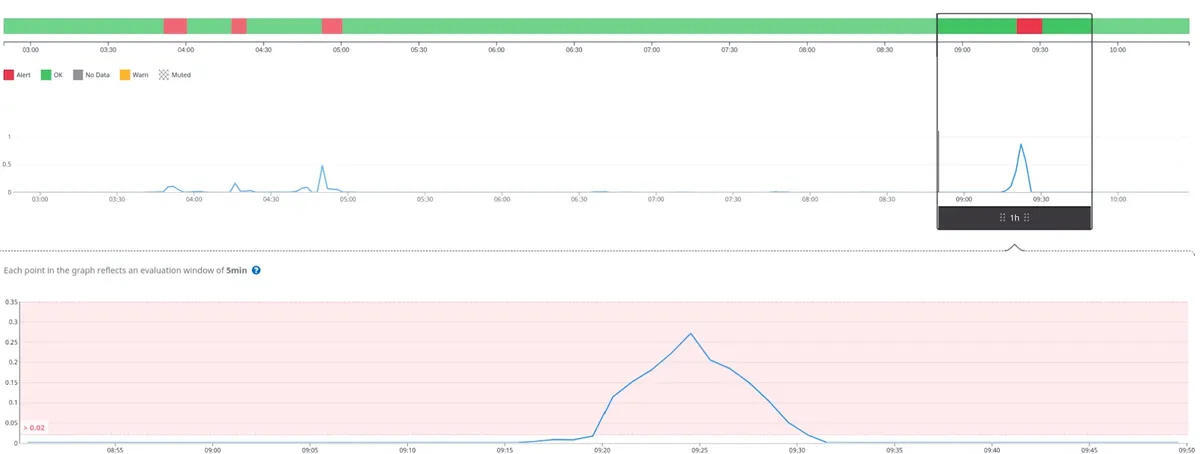
这是一个"查询"的结果,其定期检查历史和实时数据,以对任何超过 2%误差的活动发出提醒,例如:
avg(last_5m):sum:trace.authorization.worker.handle.errors{env:production,service:authorization,resource_name:web} by {resource_name} / sum:trace.authorization.worker.handle.hits{env:production,service:authorization,resource_name:web} by {resource_name} > 0.02如果没有变更感知,接下来会发生什么:
如果没有变更感知解决方案,你会收到来自 DataDog 的警报(基于上面的例子),告诉你活动超过了 2%的错误阈值。你开始想"为什么会发生这种情况?"并想出一些理论,如:应用程序代码可能被修改、网络问题、云提供商或第三方工具问题,甚至问题可能与另一个服务有关,而该服务本身也有问题。为了找到真正的答案,你需要翻阅许多指标和日志,然后试图拼凑出问题的全貌以便找到根因,但没有太多的迹象表明系统发生了什么事情,在哪里发生,以及是如何发生的,因为目前的监控和观察工具中缺乏这种数据。
用变更感知进行监控和观察:
你会收到来自 DataDog 的警报,但不同的是,你的下一个排障步骤将大大简化,因为你有了一个变更感知解决方案,已经为你提供了有关上述所有理论的必要上下文。使用变更感知解决方案作为你的唯一真相来源后,你就可以立即看到最近历史上的变更,将这些变更与可能影响服务的因素关联起来(例如代码变更、配置变更、上游资源或相关服务的变更),然后迅速找到根因,而不是在多个解决方案及其日志和指标中搜寻踪迹,并试图将它们拼凑成完整的图像,就像试图在干草堆中找到一根针一样。
这种变更感知可以基于发布说明、审计日志、版本差异和属性(谁做出的变更)。然后,这一变更的相关映射被交叉引用到无数不同的连接服务中,以找到最可能的故障罪魁祸首,从而实现更快速的恢复。
以时间轴和服务映射的形式提供数据(而不仅仅是带有阈值和限制的仪表板),可以为整个系统提供更好的上下文。
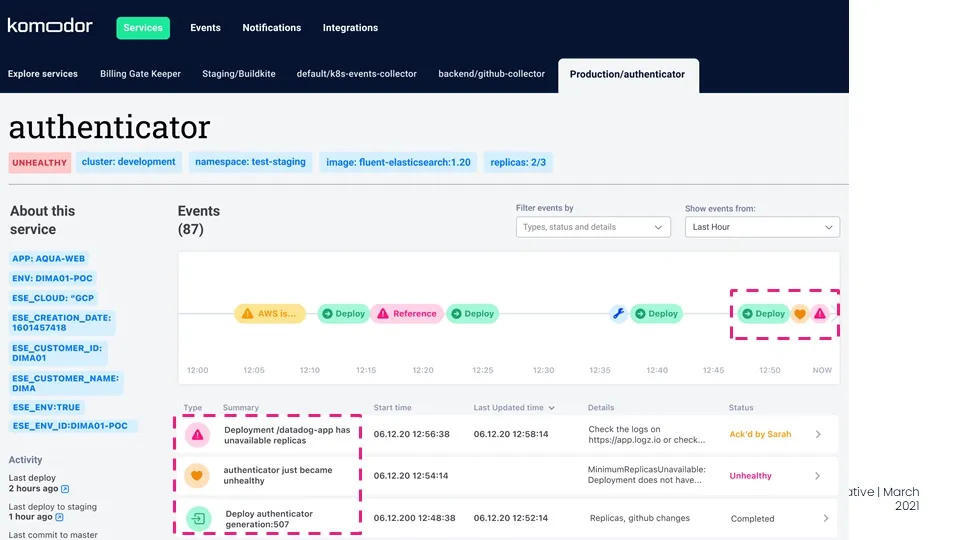
上面的截图显示了 K8s(Komodor)的变更感知解决方案的一个例子,它显示了一个由 DataDog 触发的警报。现在你有了一个时间线,显示出在问题发生之前,特定服务中发生的所有变更;所以你有了相关的上下文,可以更快地找到根因。
正如上面的截图所示,我们可以利用这些信息,从 Datadog 监控器触发的起点开始追踪,看看系统中到底发生了什么或改变了什么,从而更快地确定问题根因。在这个简单的案例中,就在 Datadog 警报被触发之前,我们可以看到有一个健康状况变更事件,表明这个应用程序没有足够的可用副本。在这之前,该应用的一个新版本部署完毕。可能是在部署过程中,可用性没有得到保证,或者是代码变更影响了这个应用,并引入了一个错误或重大变更。只要放大该部署的细节,我们就能在几秒钟内搞清楚触发该警报的原因到底是什么。
当数据+自动化还不够的时候
系统正变得越来越复杂,有许多不同的服务、应用、服务器、基础设施、版本等等元素,而且所有这些的规模都是以前闻所未闻的。让组织走到今天的工具,可能不足以为明天的系统和堆栈提供动力。
从前人们有日志,然后有了跟踪,之后是指标,这些都被汇集到仪表板中,为我们的运维健康提供可视化的指示。随着时间的推移,越来越多的工具被添加到这个链条中,以帮助推动和管理涌入的大量数据、警报和信息。
变更感知将是增强未来堆栈能力的一个关键部分,并在现有的监测和观察工具之上提供一个额外的可操作的洞察力层。这种方法最终能够帮助我们快速恢复,维护今天的严格 SLA,并减少昂贵、痛苦和可能很漫长的停机时间。
作者介绍:
Mickael Alliel 是一位自学成才的开发人员,后来转变成 DevOps 工程师,对自动化、创新和创造性地解决问题充满热情。Alliel 喜欢挑战自己,尝试新的技术和方法。目前他正在 Komodor 开发下一代 K8s 故障排除平台,并兼任法国美食鉴赏家。
原文链接:
Why Change Intelligence is Necessary to Effectively Troubleshoot Modern Applications




