
本文来自于网易云音乐数仓团队,将分享他们近一年在数据治理上的实践,具体内容将从数据背景、治理思路,项目方案、治理实践、项目成果及未来展望几个方面展开。
数据背景
1.1 业务背景
云音乐目前发布了 9 款独立的产品,国内产品有 6 款,除了云音乐本身之外、还有 5 款社交娱乐产品,分别为 look 直播、心遇、声波、音街和 mus;海外的社交娱乐产品有海外心遇 heatup,海外直播 kaya,游戏社交产品 ruffgo。
1.2 数据现状
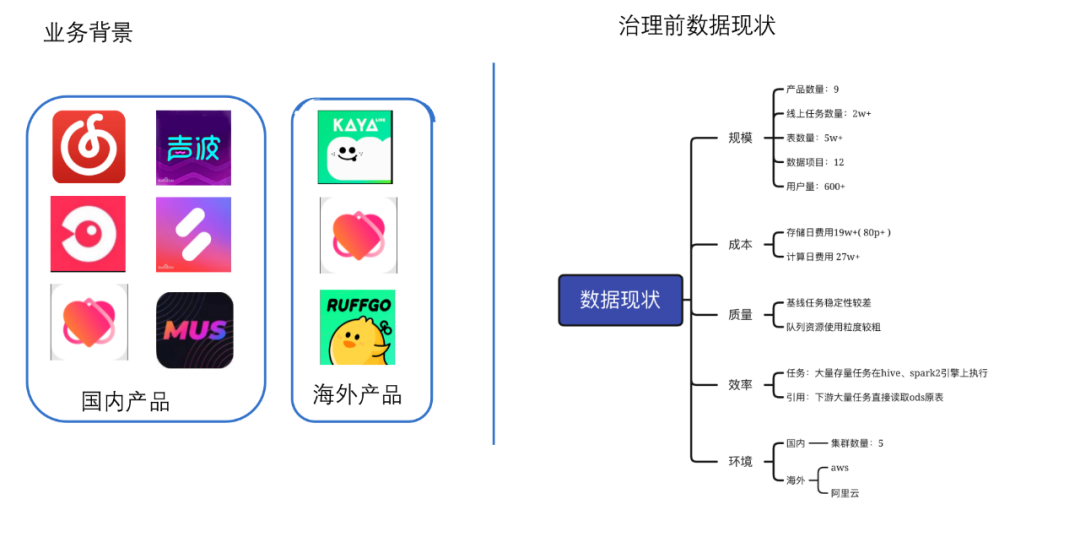
规模上
承载了 9 款产品
线上调度任务数有 2 万以上
表数量在 5W 以上
数据项目有 12 个
目前数据服务的人群有,算法、分析师、数据产品、业务服务端、业务中台、客户端等,服务的对象在 600 以上
数据成本方面,存储日费用合计有 19w+,计算成本日费用在 27w+
质量上
一方面任务稳定性较差,核心任务和报告不能稳定产出
队列资源使用方面粒度比较粗、运维成本较大
效率方面
历史原因有大量任务仍然运行在 hive 引擎和 spark2 引擎上,这类任务耗资源、执行慢、小文件问题较多。下游引用比较随意,存在大量任务直接读取 ods 表的情况,特别是涉及到日志数据,小需求耗大资源。
环境方面
目前包含了国内环境和海外环境,国内环境目前有 5 个集群,海外环境当前包含了阿里云和 aws。
总体来讲,针对目前的数据现状,治理面临的问题是 体量大、环境杂、缺规范、存在大量的资源浪费。
治理思路
2.1 找问题
针对当前的数据现状,数据治理可以从哪些方面来找到治理方向呢?我们从技术视角对问题进行了分类。目前大数据环境下数据相关内容的分布情况如图中所示:
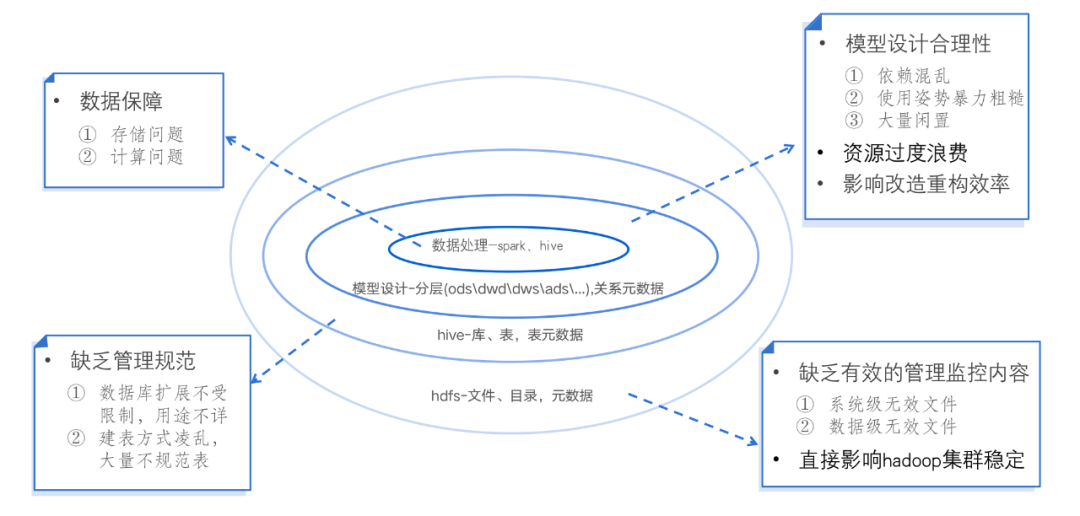
首先我们所有的数据都是存储在 hadoop 的 hdfs 文件系统之上的,在 hdfs 之上我们会建立一系列 hive 库和表用来管理数据;基于库表的管理,数据开发会在上面进行模型设计和数据分层设计;再往上则是数据处理方面的内容,包括任务调度、执行引擎等。
随着业务的快速发展,数仓的不断迭代, 每块内容可能或者必然存在着哪些问题呢?
先来看一下 hdfs 这个模块,此前的情况是 hdfs 文件缺乏有效的管理监控内容,无效文件无法探查和处理,这种无效文件越多必然影响 hadoop 集群的稳定性。
库表方面,此前数据库扩展没有严格限制,滋生了非常多的数据库,迭代下来很多库的用途不详。建表方式也比较凌乱,有众多以用户名字命名的表,为之后的移交和管理工作带来了较大困扰。
模型设计方面,早期设计比较粗暴混乱,众多任务直接依赖 ods 层数据,cdm 层复用率较低,也存在大量闲置任务和表。引起资源的过度浪费,在数仓的改造重构过程中也制造了不少困难。
任务调度执行引擎方面也有众多任务是跑在 hive 和 spark2 引擎上的,存储、计算、小文件问题都存在较大提升空间。
2.2 问题解法
针对以上存在的问题,如何来更有效的找到问题所在;
在 hdfs 文件上,我们把一直存在于集群中又脱离管控、不被使用却占用着资源的文件称之为“游离 hdfs 文件”。如何定位到这些文件,这里就需要获取到 hdfs 文件的元数据信息进行分析。
库表的使用现状上,云音乐主集群的库有 70 多个,表的数量达到了 5w 以上,实际上常用的库表是非常有限的;库方面我们实际常用的库在 20 个左右,表方面我们也存在着大量的临时表和无效表,正规表的生命周期覆盖度也比较低。这方面我们需要用到库表元数据信息进行梳理和分析。
模型设计的合理性衡量,我们引入了“三度”指标来衡量整个模型设计的健康情况,“三度”指标的计算需要用到数据血缘的信息。
任务信息的执行调度情况,我们这里也缺乏一个宏观的视图进行分析。计算治理这块需要有一个比较全面的执行元信息进行分析和监控,更直观的看到可优化的空间。
以上这些问题的解决方案都指向了元数据信息,拥有了完整的元数据,我们才具备了放手去干的基础。

项目方案
3.1 构建整个治理方案

要解决问题找到问题,我们第一步就是获取完整的元数据内容
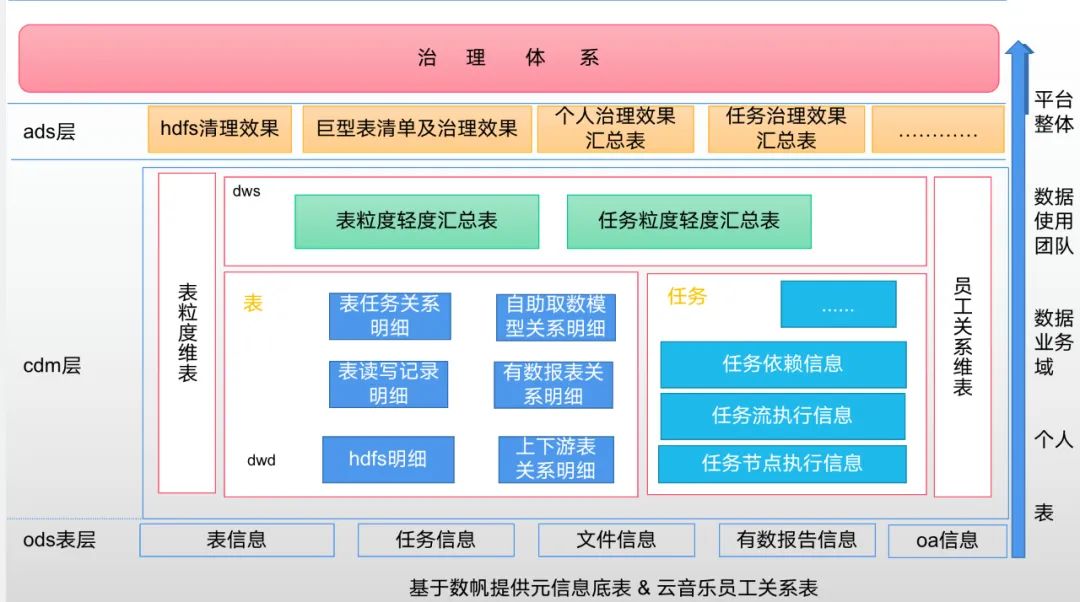
22 年年初开始,从网易数帆大数据团队拿到了比较完备的元数据内容,涵盖了表粒度的元数据信息、任务粒度元数据信息、hdfs 文件元数据信息等。
基于获取的元数据内容进行元数据建模。通过对元数据和云音乐内部数据的一系列的处理,产出了丰富的元数据 cdm 层的宽表和维表。通过模型产出的报告可实现从更多的视角观测数据现状和任务现状,可以分析的粒度有:整体平台数据,数据使用团队、数据业务域、个人、表。整个建模内容支撑了体系化的治理方案。
3.2 治理体系
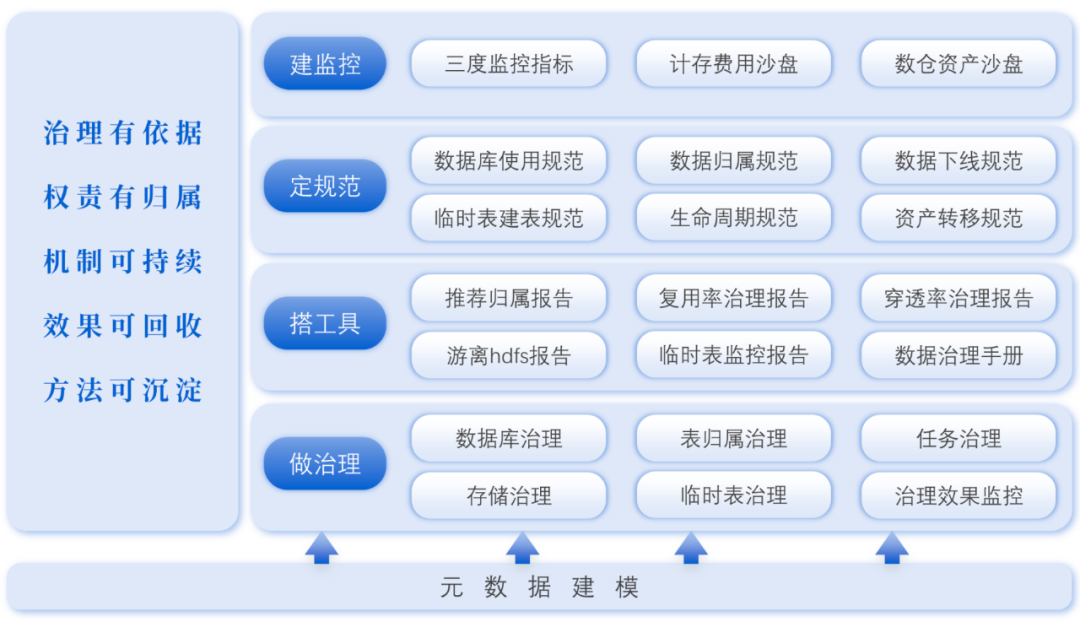
云音乐的整个数据治理体系中,我们遵循的原则是治理有依据、权责有归属、机制可持续、效果可回收、方法可沉淀。
治理的依据是元数据;权责有归属是定位谁的问题谁来治理;机制可持续是在治理的过程中沉淀出一套可推行的机制和原则;效果可回收是每一项都能拿到相应的结果;方法可沉淀整个治理方案可以进行横向复制推广。
治理的动作可归纳为建监控、定规范、搭工具、做治理。上面三个动作都是为了最后一个动作做铺垫的。在规范、监控、工具都做好了的前提下,治理的动作才能更有效的推进落地;做治理的过程中也可以逐步丰富规范内容,同时也可以进一步沉淀和落地监控及工具。
上面讲到的治理原则中,权责有归属和机制可持续是治理事项推进的两个基本点,所以在推进其他治理事项前要先落地这两项原则。
治理实践
4.1 权责有归属
所有要推进的治理项都是要人来治理的。所有的数据、任务、表都需要有责任人对其进行负责,云音乐的所有 ods 的 dump 任务是在云村平台上实现的,dump 任务的配置都是由云村平台的开发统一配置的,表和任务的责任人都是归在配置任务的开发身上,n 个业务几千个任务都是有平台开发来运维管控,表和任务的生命周期管理基本上是没有管制的。另外一些历史原因,存在大量的表归属在离职人员和项目账号下,这些表及相关的任务也是出于脱管的状态。针对这几种情况分别做了 ods 治理、离职人员表任务归属治理、项目账号表归属治理。
ods 治理项,这里先是数仓按业务承接云村平台所有 dump 任务和表。第二是推动产品功能落地,用户按业务划分提交 dump 任务,数仓审批并负责相关的任务和表的管理。
离职人员表任务归属,通过拉取离职人员组织关系、拉专项群对任务和表进行认领。
项目账号表归属,通过定制表推荐归属规则,计算出表的推荐归属责任人。并实现表批量归属工具,实现批量表的归属。
4.2 机制可持续
在进行实际治理项目执行的过程中,每个治理事项所面临的问题、治理的内容和治理步骤都是差异且多元化的;治理项都面临着跨部门,多团队协作,在人力精力投入比较分散;在这些问题的背景下我们建立了统一的推进机制以及推进原则。
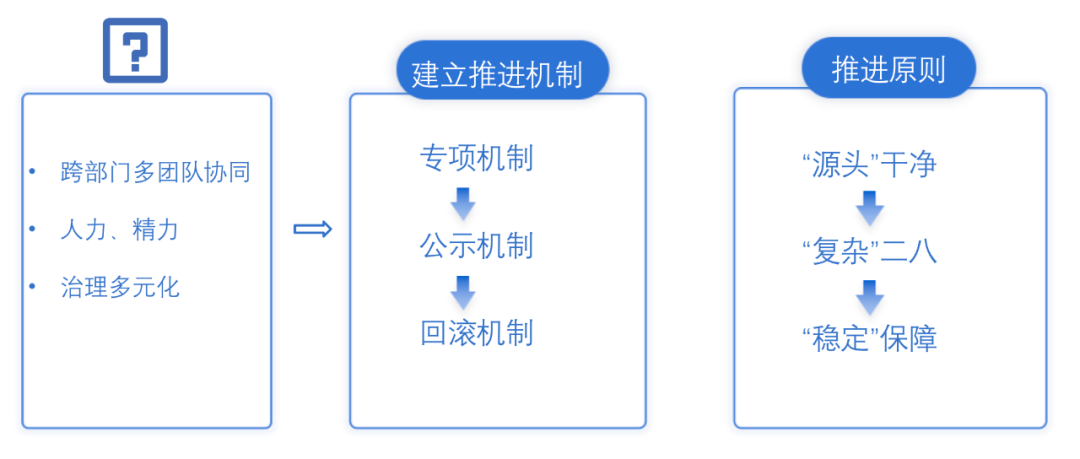
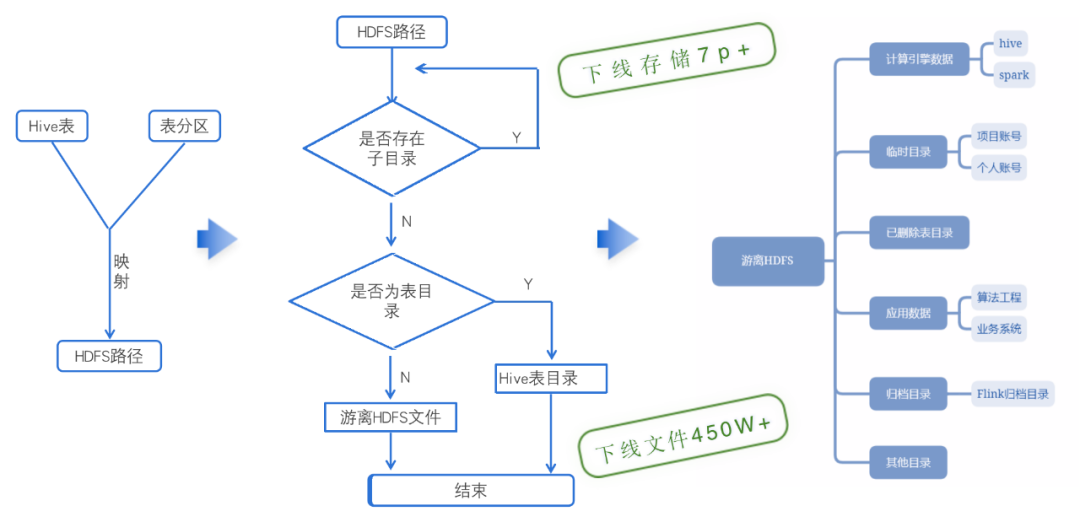
4.3 hdfs 层面 - 游离 hdfs 文件治理
在游离 hdfs 文件的治理,通过 hdfs 元数据和 hive 元数据的关联匹配逻辑和文件的访问情况,进一步计算出游离的 hdfs 文件;通过找到游离文件的生产方进一步确认文件是否还有存在的必要,并推进无效文件下线动作。现阶段通过这种方式梳理出来的游离文件有计算引擎遗留数据、未清理的临时目录数据、删表未删文件的数据,算法和工程任务的无效应用数据、实时任务无效归档数据等。通过对这些游离数据的清理,目前拿到的效果是非常显著的,释放了 7p+以上的逻辑存储空间,清理掉了 450w 以上的文件和目录。
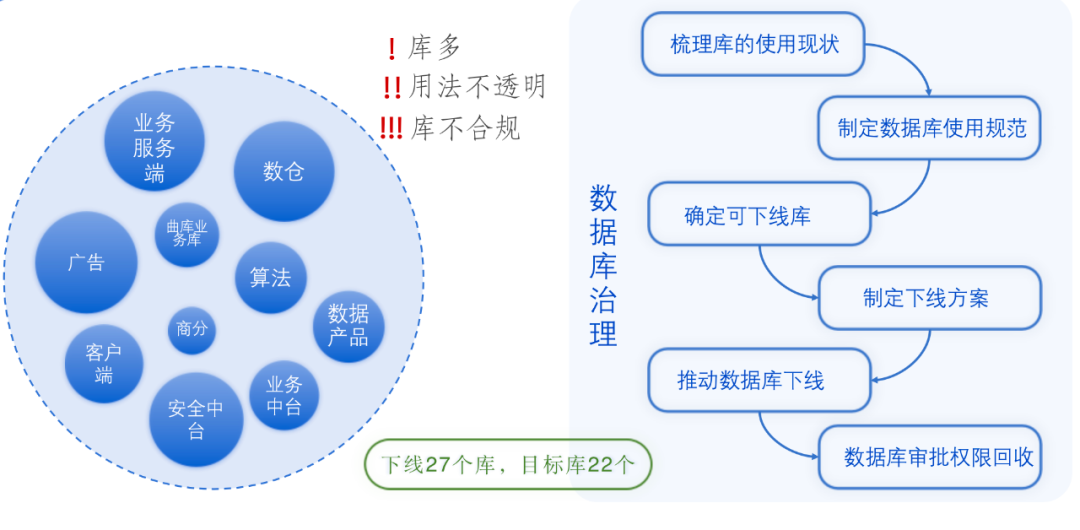
4.4 库表层面 - 数据库治理
云音乐数据目前服务的角色比较广泛,除了数仓、分析师、算法、我们还服务了所有和技术挂钩的角色,包括客户端、业务服务端、安全中台、曲库业务、广告、业务中台等等。
由于之前对数据库申请的审核比较随意,云音乐主项目下已经存在了 70 多个库,其中大部分库的用途是不详的,有一些库映射的 hdfs 目录是非法的,在数据库的用法上也存在比较多不规范的地方。所以在这个背景下启动了对数据库的一波治理,整个治理流程是通过元数据,梳理库的使用现状,根据现状进一步定制数据库使用规范;确定出可下线库明细,制定下线方案,通过专项、数据迁移,公示下线等手段推进数据库的下线。并回收数据库的审批权限来规范库的使用。目前已经下线了 27 个无效库,数据库使用规范中明确了库的最终态,之后新增的数据都会归在目前的 22 个数据库中。
4.5 库表层面 - 表治理
表治理主要是针对表的存储治理的过程,这里介绍一下四个比较有代表的存储治理专项。
第一个是临时表治理,早期临时表面临着存量大,增速快的问题,经过一期的的治理解决了大量存量的问题,增速快的问题后面通过元数据建模产出的报表,推进线上任务改造的方式较好的解决了增速快的问题。
第二个是生命周期管理的推进,早期面临的问题是缺乏规范,生命周期覆盖低,设置随意。在出台了生命周期管理设置规范之后,生命周期覆盖上获得了较好的成果。
第三个是巨型表的治理,这里定义出日费用在 100 以上的表为巨型表,总共涉及 163 张表,存储占比却达到了 80%,,单独把巨型表拉出来治理是居于二八原则,拉大头重点治理,获得的收益是显著的。
第四个是 abtest 专项治理,abtest 任务的特点是实验数据量大,任务复杂耗资源。当前正在推进 ab 系统的升级改造,天秤系统将会代替掉老的 ab 系统,正好趁着这个机会把老的任务和存储进行下线。当前这个治理事项正在推进过程中,还有其他类似的这种产品换代的事项也会按专项进行推进。

4.6 模型设计层面 -“三度”指标治理
22 年我们在模型设计层面引入了“三度”指标的概念,通过一系列指标在进度 健康度 价值度上通过数值化来衡量我们模型建设的一个合理度。
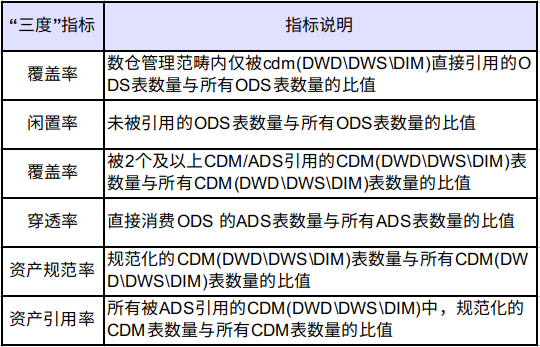
覆盖率和闲置率是针对 ods 表利用率的一个衡量。通过对 ods 层表的治理可以进一步提升覆盖率,降低闲置率。这个过程中我们可以下线大量的无效 ods 表以及相应的任务。
复用率和穿透率是用来反馈我们 cdm 层表引用健康度情况,目前通过一系列的治理。复用率已经又 30%提升到了 60%,穿透率由 20%下降到了 10%。
资产规范率和资产引用率是针对我们 cdm 层表的规范化情况的一个衡量,这两个指标我们是保持在 85%以上,并且通过一系列的规范落地,指标会逐步提升。
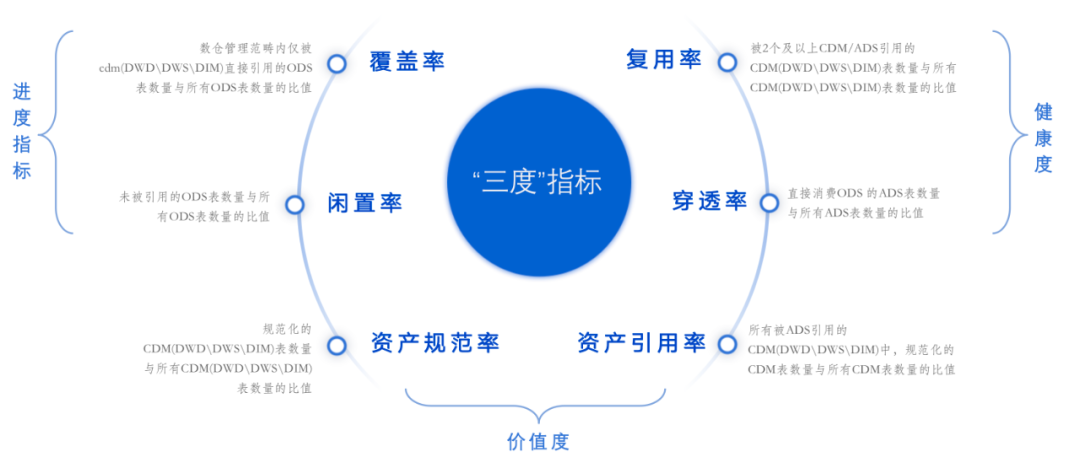
通过三度指标的一个治理,可以清理掉大量无效的任务和表,在存储资源和计算资源上可以减少不少成本。
4.7 数据处理层面 - 计算治理
计算治理当前阶段主要是针对计算引擎升级做治理。
云音乐集群是在 21 年年中上线了 spark3 执行引擎,经过大半年的使用,我们确实在 spark3 上体验到了非常棒的效果,网易数帆大数据团队的同学也在 spark3 上进一步做了大量的优化,例如 AQE 增强优化、zorder 功能以及 shuffle 阶段采用 zstd 压缩算法。为了能够更好的兼容升级过程,大数据团队也在 spark 引擎上内置了大量优化参数。当前 spark3 引擎在计算资源、存储资源、小文件问题上获得了大幅的提升。在这个背景下我们在 22 年 Q2 阶段开始任务迁移至 spark3 的专项。涉及的迁移事项有
hive 迁移 spark3
spark2 版本的 sql 任务迁移至 spark3,
核心任务和高成本任务的 spark3+zorder+gzip 升级。
spark 工程任务迁移 spark3 的专项。
每一项在节省资源上都获得了巨大的提升。

项目成果
5.1 成本收益
经过一系列的治理动作,我们在存储和计算方面获得了颇丰的收益。
存储上
累计下线的存储占整体存储的 30%
存储增量趋势放缓,由原来的日增 170T,下降到日增 55T
计算上
核心 &耗资源任务计算资源节省 30%以上
集群稳定性提升
核心任务产出提前,基线保障由 9 点提前至 5 点 30
5.2 治理资产沉淀
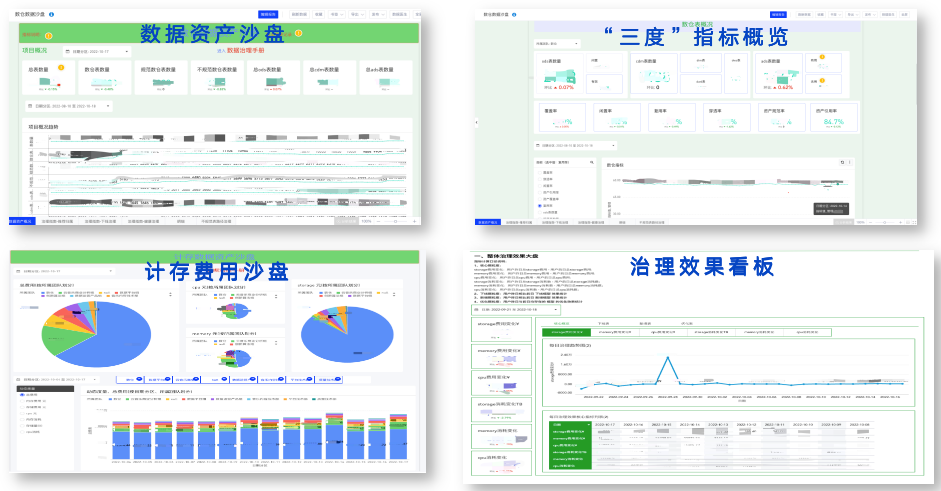
在整个治理过程中我们也将方法论和治理思路沉淀了一系列的可视化监控看板和治理跟进工具,确保整个治理事情是有序进行并且过程可控的。
可视化监控看板方面,
数据资产沙盘,可以在大盘的角度观察我们整体数据的变化情况。
"三度"指标概览,可以从不同的粒度,反馈数仓整体建设健康度的情况。
计存沙盘,可以看到不同数据使用方在存储成本和计算成本上的表现,也可以监测异动情况。
治理效果看板,汇总了我们每一项专项治理过程中产生的收益情况。
游离文件监控、任务监控等等…
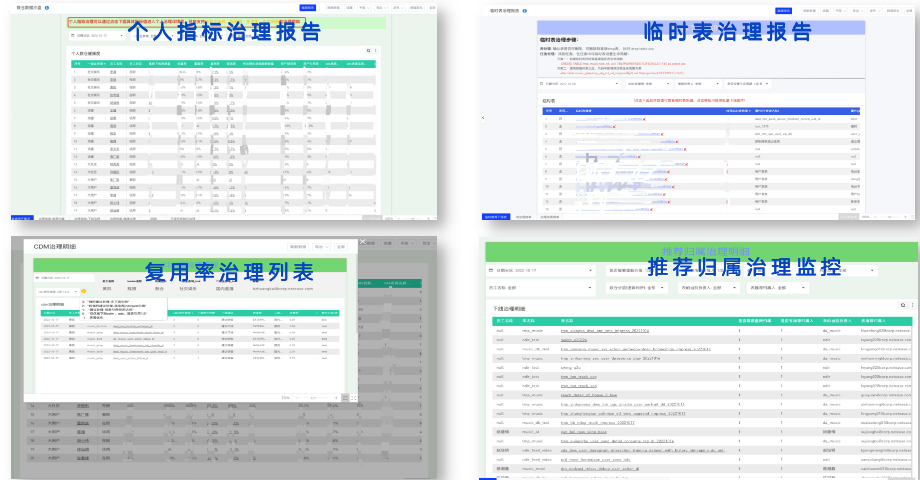
针对每一项治理,我们都有产出相关的跟进工具,例如 个人指标治理报告、临时表治理监控报告、“三度”指标治理列表、推荐归属治理监控、下线治理报告、任务升级跟踪报告等等
5.3 规范沉淀
治理过程中我们也逐步丰富了我们的数据开发规范
数据库使用规范
临时表建表规范
节点命名规范
队列使用规范
任务上线规范
数据治理下线流程规范
…
未来展望
数据治理是一件长期并且持续要进行的事情,如何达到更好的治理效果?我们整个治理过程遵循理念是:从分散到集约、从被动到主动到自动、从经验到智能。在这个理念的基础上,我们的治理是按事前、事中、事后三个步骤管理治理事项。其中最为重点的是事前事项,事前的动作都是预防性的动作,预防做好、事后无忧。

事前:我们在推进的动作有,推广数据开发规范,推广数仓资产白皮书的使用,推进猛犸产品优化功能迭代,控制好上线审核机制等等。
事中:针对事前没有遵循规范或者遗漏下来的问题,在事中我们会丰富各种治理监控指标工具,及时发现并反馈问题。
事后:事后我们也会产出各项治理指引报告,给出治理理由、治理方案,并同步提供更便捷有效的治理工具。
事中和事后的动作都是在为事前的规范事项提供思路,进一步推进治理的自动化和智能化。接下来我们会在自动化和智能化上发力,让我们整个数据能够在完善的系统化环境中发挥数据价值和业务价值。
结语:以上是对云音乐数据治理实践的分享,在这里感谢网易数帆大数据团队对我们的各种支持。




