
谷歌亮出最新文本到图像生成模型 Parti
如今,文本到图像生成模式风靡一时,但谷歌公司最近密集的一系列新发布,却让大众有些出乎意料。而在 Google Research 之前的图像到文本生成模型 Imagen 发布之后,他们决定展示另一个模型构建来完成同样的任务。
据介绍,备受关注的这一最新模型被命名为Parti(Pathways Autoregressive Text-to-Image)。虽然Imagen和 DALL· E2 是一种扩散模型,但 Parti 遵循 DALL· E 的足迹作为自回归模型。无论其架构和培训方法如何,最终用途都是一样的:这些模型(包括 Parti)将根据用户的文本输入生成细致的图像。
Imagen 的图像生成具有与 Open AI 的DALL-E 2 相似的架构,但输入依据的是大型 AI 语言模型——由于具有更高的语言理解能力,因此可以从文本描述获得更好的图像生成结果。新的 AI 模型 Parti 尝试使用一种更接近大型语言模型功能的替代架构(自回归),这些语言模型能根据之前的单词和句子或段落的上下文预测合适的新词。Parti 将这一原则应用于图像,并取得了成功。
Parti 表明,与大型语言模型一样,图像 AI 通过更全面的训练和更多的参数获得了明显更好的结果。它还可以将长而复杂的文本输入准确地翻译成图像,这表明它可以更好地理解语言和主题之间的关系。
伴随着 Parti 的发布,还有一篇博客文章描述了使用 Google 的文本到图像模型创建图像的过程,可以在此处访问:https://blog.google/technology/research/how-ai-creates-photorealistic-images-from-text/
Parti 详细参数
研究人员创建了四种不同规模的 Parti 模型,其中包括 3.5 亿、7.5 亿、30 亿和 200 亿的参数计数。这些模型是使用 Google Cloud TPU 进行训练的,这些 TPU 能够轻松支持创建这些巨大的模型。网站上提供一些不同模型规模间的比较,但在这里仅分享一些从论文中摘取的比较(从左到右从小到大):

像所有其他文本到图像生成器一样,Parti 以各种类似的方式处理存在的各种问题,例如不正确的对象计数、混合特征、不正确的关系定位或大小、不正确处理否定,列表可能会继续等。以下是 Parti 进行处理的一些例子:

Parti 生成的图像分辨率为 256 x 256 像素,然后可以放大到 1024 x 1024 像素。下图显示了四种经过不同级别训练的 Parti 模型在相同命令提示下生成图像的质量差异。具有 200 亿参数的最大模型生成了与长文本输入匹配的无错误图像。最大版本的 Parti 模型甚至可以拼写单词,而 DALL-E 2 只能生成图像。

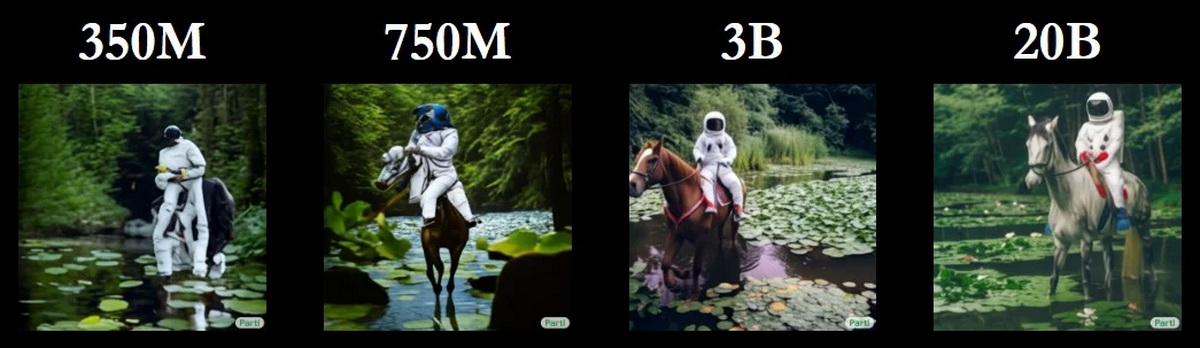

“20B 模型特别适合于需要世界知识、特定视角或符号书写和表示的抽象任务。”谷歌的研究团队写道。
另外,Parti 还可以生成超越培训材料及其主题的出色的图像。研究人员认为,这意味着图像 AI 能够准确地再现世界知识,以精细的细节和交互组合产生许多主角和对象,并遵循特定的图像格式和风格。
文本生成的图像过于逼真,背后风险令人担忧
尽管 Parti 已经有能力生成“以假乱真”的超逼真图片,但其实该系统存在的一些问题也不容忽视。
谷歌研究团队对模型生成的图像可能包含对人的刻板印象也感到担忧,这也是 Imagen 和 DALL-E 2 正在努力解决的问题。此外,由于可能会产生逼真的人物图像,因此存在额外的深度伪造风险。出于训练数据存在的偏见、对产生有害图像的担心,以及公众不可避免地滥用等原因,研究团队目前没有公布模型、代码和其他数据。
值得注意的是,Parti 这个 AI 模型的名字或许有着另外的深意:Parti 中的 P 代表 Pathways,这是谷歌的下一代 AI 架构,由谷歌人工智能主管 Jeff Dean 在 2021 年底首次引入。Pathways 的目标是一个智能的、多用途的 AI 系统,有朝一日能够泛化“跨越数百万个任务”。Parti 在其名称中包含 Pathway 的事实可能表明它正在接管这个未来架构中的图像部分。另外,Parti 和 Imagen 架构的组合也是可以想象的。
研究团队在网站上展示了 Parti 图像的许多其他交互式正面和负面示例,并详细解释了系统的结构。
所以,人们可能想知道这次是否可以使用这个最新推出的大型文本到图像生成器?如大家所料,答案是否定的。如 Imagen 一样,Parti 也只是让大家看看,不能使用。
参考链接:
https://blog.google/technology/research/how-ai-creates-photorealistic-images-from-text/




