
简介
Amazon Kinesis 可让您轻松收集、处理和分析实时流数据,以便您及时获得见解并对新信息快速做出响应。Amazon Kinesis 提供多种核心功能,可以经济高效地处理任意规模的流数据,同时具有很高的灵活性,让您可以选择最符合应用程序需求的工具。借助 Amazon Kinesis,您可以获取视频、音频、应用程序日志和网站点击流等实时数据,也可以获取用于机器学习、分析和其他应用程序的 IoT 遥测数据。借助 Amazon Kinesis,您可以即刻对收到的数据进行处理和分析并做出响应,无需等到收集完全部数据后才开始进行处理。
实际上,Amazon Kinesis 包含以下四个服务:
Amazon Kinesis Video Streams – 利用 Amazon Kinesis Video Streams,您可以轻松而安全地将视频从互联设备流式传输到 AWS,用于分析、机器学习 (ML) 和其他处理
Amazon Kinesis Data Streams – Amazon Kinesis Data Streams 是一种可扩展且持久的实时数据流服务,可以从成千上万个来源中以每秒数 GB 的速度持续捕获数据。
Amazon Kinesis Data Firehose – Amazon Kinesis Data Firehose 是将流数据可靠地加载到数据湖、数据存储和分析服务中的最简单方式。该服务可以捕获和转换流数据并将其传输给 Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、通用 HTTP 终端节点和服务提供商(如 Datadog、New Relic、MongoDB 和 Splunk)
Amazon Kinesis Data Analytics – Amazon Kinesis Data Analytics 是通过 SQL 或 Apache Flink 实时处理数据流的最简单方法,您无需了解新的编程语言或处理框架。
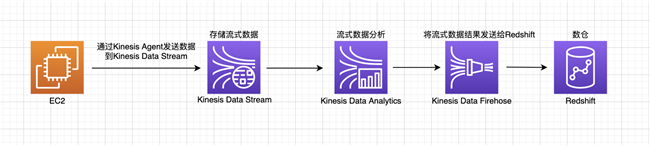
本篇文章将完整展示如何使用 Kinesis 构建流式数据分析架构,如下图所示:
提前准备
进入 Demo 之前,先提前创建好名字为 kinesis-demo-us2 的 S3 存储桶,创建过程可以参看:
https://docs.aws.amazon.com/quickstarts/latest/s3backup/step-1-create-bucket.html
然后,再创建 Redshift 集群,具体步骤可以参看:
https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-launch-sample-cluster.html
注意: 在 Redshift 的安全组里,需要加上对 Firehose 放行的规则,示例为 AWS 美西 2 区域的 IP 段

其他区域的 IP 可以参看此链接:
https://docs.aws.amazon.com/zh_cn/firehose/latest/dev/controlling-access.html
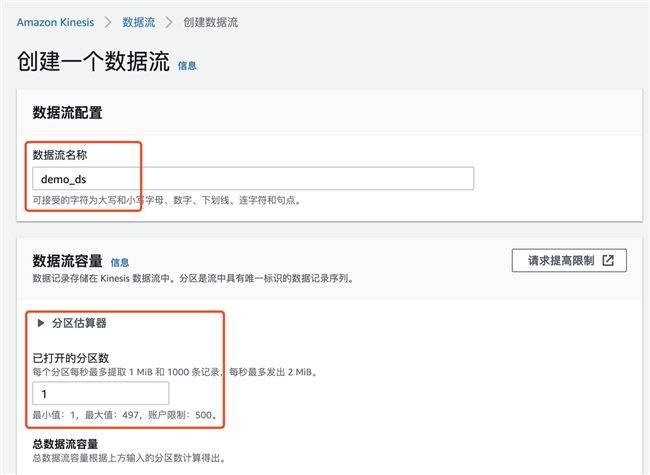
1. 创建 Kinesis Data Stream
输入名字 demo_ds,由于是测试使用,分片数量写 1 即可,实际生产环境的分片数量要根据数据量的吞吐决定。
2. 在 EC2 上安装配置 Kinesis Agent:
2.1 从https://mockaroo.com/准备一份样本数据,其中包含 id,first_name,last_name,email,gender,ip_address 字段,数据格式为 CSV
2.2 创建一台 EC2,然后按照如下文档,安装 Kinesis Agent https://docs.aws.amazon.com/zh_cn/firehose/latest/dev/writing-with-agents.html#download-install
修改配置文件如下,在此配置文件里默认数据是 CSV 格式,配置里把 CSV 转换为 JSON 格式,详细配置请参考链接https://docs.aws.amazon.com/zh_cn/firehose/latest/dev/writing-with-agents.html#agent-config-settings
[ec2-user@ip-172-31-52-232 ~]$ cat /etc/aws-kinesis/agent.json{ "cloudwatch.emitMetrics": true, "cloudwatch.endpoint": "https://monitoring.us-west-2.amazonaws.com", "kinesis.endpoint": "https://kinesis.us-west-2.amazonaws.com", "flows": [ { "filePattern": "/tmp/app1.csv", "kinesisStream": "demo_ds", "dataProcessingOptions": [ { "optionName": "CSVTOJSON", "customFieldNames": [ "id", "first_name", "last_name","email","gender","ip_address" ], "delimiter": "," }] } ] }2.3 配置后启动 Agent
[ec2-user@ip-172-31-52-232 ~]$ sudo /etc/init.d/aws-kinesis-agent start
2.4 通过如下脚本持续生成数据
[ec2-user@ip-172-31-52-232 ~]$ while true;do sleep 5;cat sample.csv >> /tmp/app1.csv;done
2.5 通过查看日志,可以看出数据被解析后,发送成功
[ec2-user@ip-172-31-52-232 ~]$ tail /var/log/aws-kinesis-agent/aws-kinesis-agent.log
2020-11-05 06:34:03.557+0000 (Agent.MetricsEmitter RUNNING) com.amazon.kinesis.streaming.agent.Agent [INFO] Agent: Progress: 5750745 records parsed (355242075 bytes), and 5750575 records sent successfully to destinations. Uptime: 236670045ms
3. 使用 Kinesis Data Analytics 分析 Data Stream 里的数据:
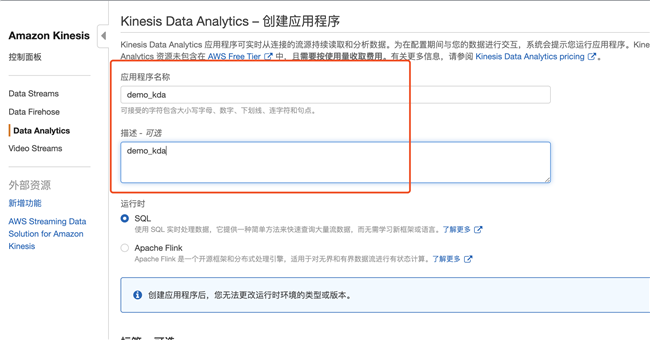
3.1 创建 Kinesis Data Analytics
3.2 连接流数据,即之前创建的 demo_ds
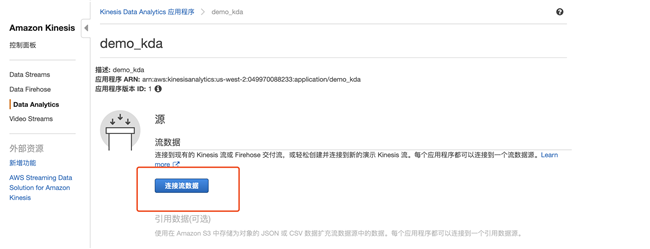
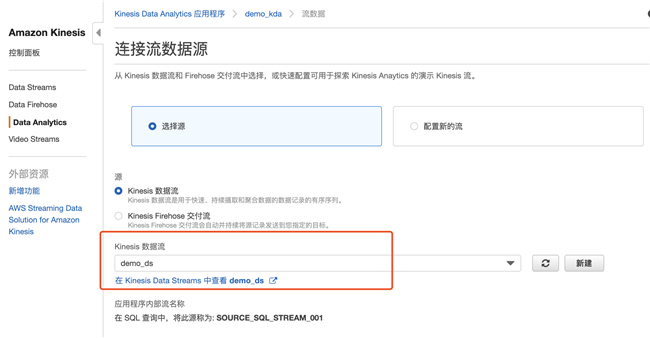
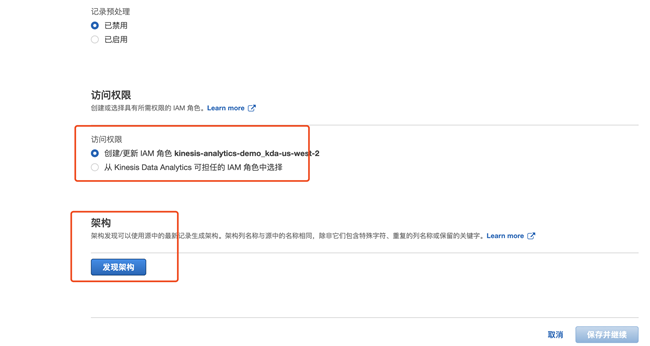
3.3 创建新的 IAM 权限会自动创建一个 IAM 角色,点击发现架构,系统会自动识别数据结构,并进入 SQL Editor 页面
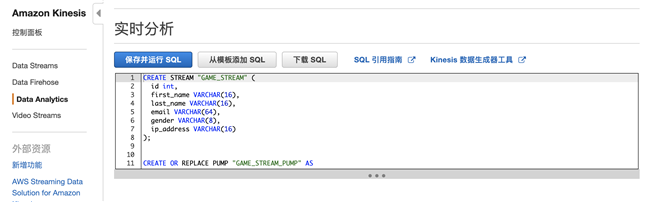
3.4 编写 SQL 语句对流数据进行分析,主要分 4 个语句
创建应用流 DEMO_STREAM
CREATE STREAM "DEMO_STREAM" ( id int, first_name VARCHAR(16), last_name VARCHAR(16), email VARCHAR(64), gender VARCHAR(8), ip_address VARCHAR(16));创建泵从现有的数据流持续插入到应用流 DEMO_STREAM 里
CREATE OR REPLACE PUMP "DEMO_STREAM_PUMP" ASINSERT INTO "DEMO_STREAM" SELECT STREAM "id", "first_name", "last_name", "email", "gender", "ip_address" FROM "SOURCE_SQL_STREAM_001";创建统计流,统计每分钟的 gender 的分布统计
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (r_time TIMESTAMP,gender VARCHAR(16),genderCount int);创建统计泵,从应用流里把数据汇总统计,并持续插入到统计流里
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM ROWTIME,gender, COUNT(*) AS genderCount FROM "GAME_STREAM"GROUP BY gender, FLOOR(("DEMO_STREAM".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') minute / 1 TO MINUTE);详细解释可以参看
https://docs.aws.amazon.com/zh_cn/kinesisanalytics/latest/dev/streams-pumps.html
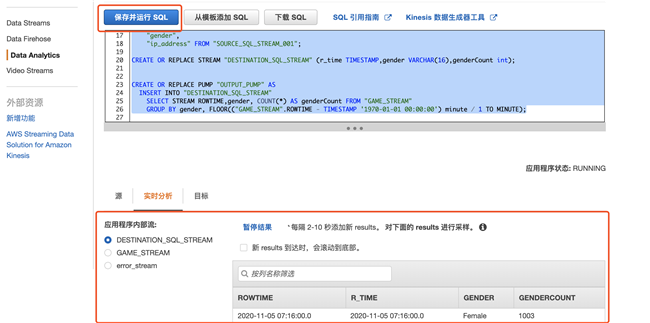
3.5 将结果导出,点击连接新目标,这里选择 Firehose 作为目标,最终把数据传送到 Redshift 上
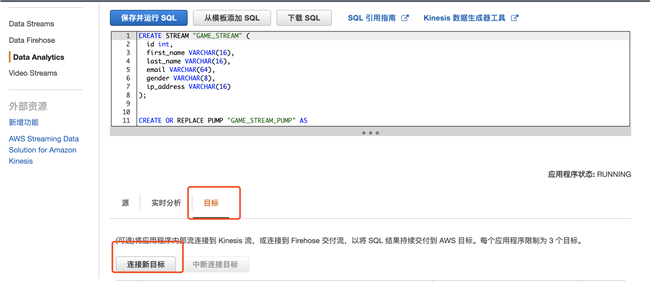
4. 使用 Kinesis Firehose 把 Kinesis Data Analytics 的结果发送到 Redshift 上:
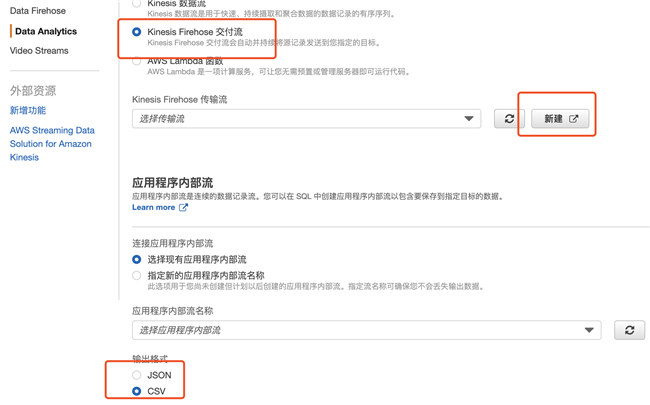
4.1 点击上面的连接新目标后,可以选择 Kinesis Firehose,创建一个新的 Firehose 交付流,同时输出格式选择 CSV
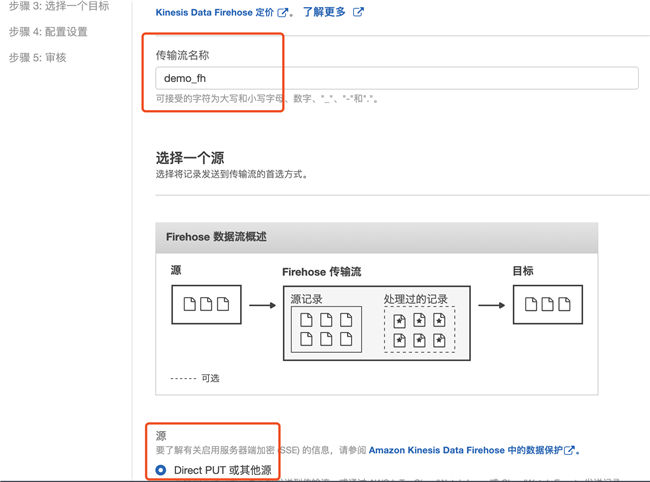
4.2 选择 Direct PUT 或其他源
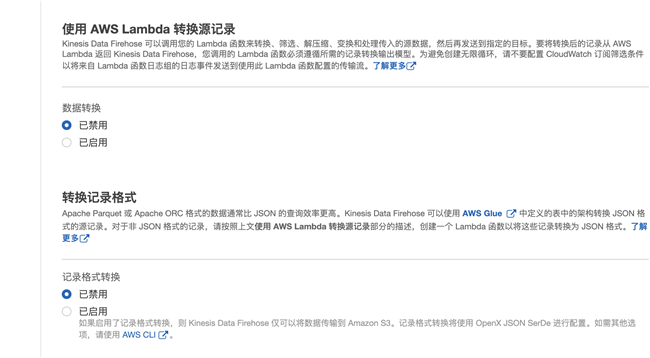
4.3 这次实验里我们不需要再处理数据,也不需要转换格式,禁用这两项后点击下一步
4.4 选择目标 Amazon Redshift
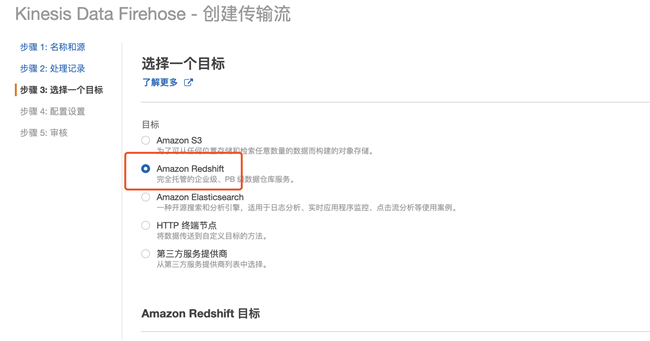
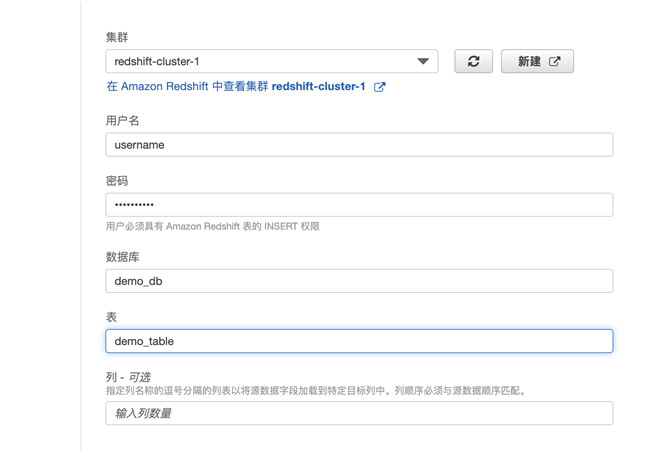
4.5 选择已经创建好的 Redshift 集群
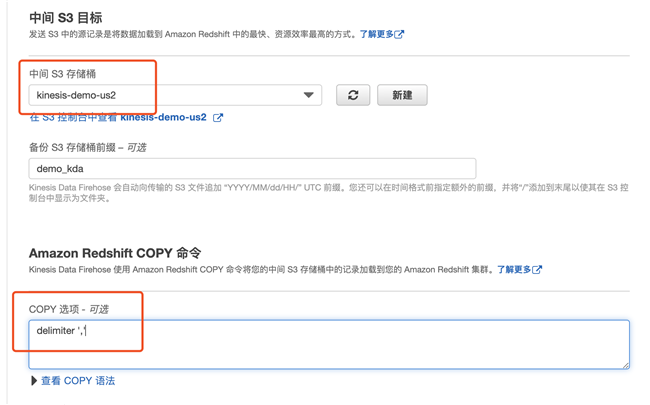
4.6 选择中间的 S3 目标,选择之前创建的 kinesis-demo-us2 的 S3 桶,并在 COPY 选项里加上 delimiter ‘,’ (因为 4.1 步选择的是 CSV 的输出)
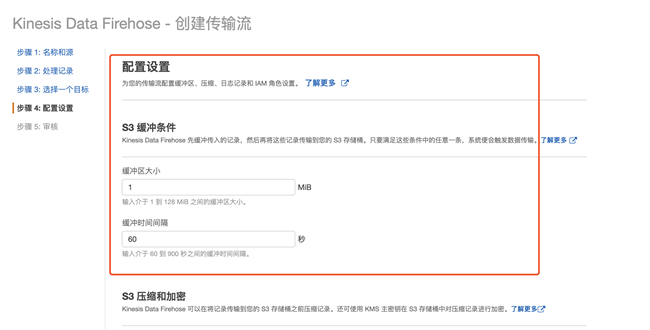
4.7 修改默认缓冲区时间和大小,加速数据导出,下面选择创建新的 IAM 角色,系统会自动为 Firehose 创建相应的权限
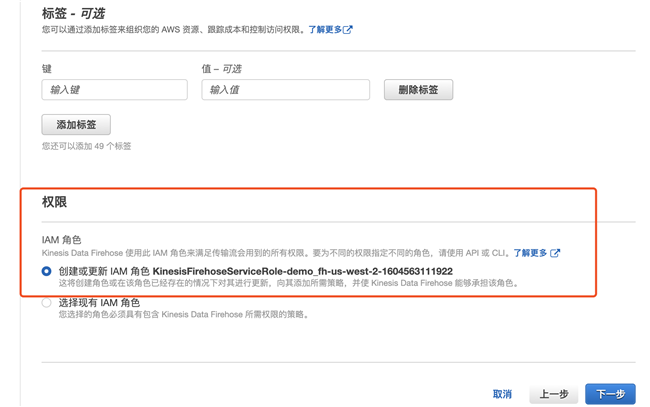
5. 在 Redshift 上创建表以接受数据:
5.1 在 Redshift 数据库中执行以下 SQL 语句
create table demo_table (r_time varchar(32),gender varchar(8),genderCount int)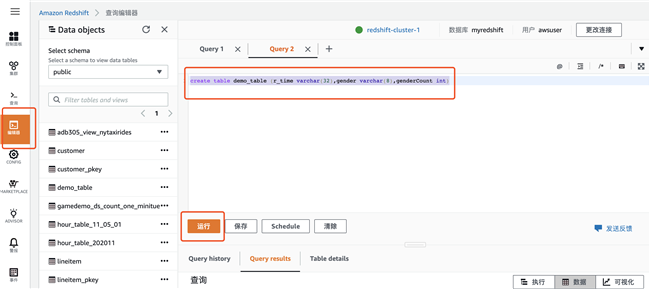
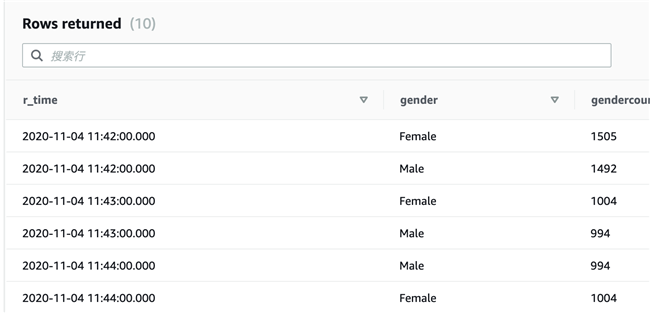
5.2 再通过 SQL 语句 select * from demo_table limit 10 进行查询;可以看到每分钟的数据在不断的流入
总结
从上述的实验可以看出来,使用 Kinesis Data Stream 和 Kinesis Data Analytics 构建流式数据架构非常简单,用 Kinesis Firehose 和 Redshift 可以把流式处理后的结果及时的发送到数仓,为业务提供见解。同时 Kinesis 是一项完全托管的服务,不需要额外的维护工作量,大大减少了运维的成本,数据工程师只需要专注通过 SQL 语句实现业务的需求即可。
作者介绍:
AWS 解决方案架构师,熟悉互联网的大数据业务场景,有丰富的基于 AWS 上大数据解决方案的经验,对开源 hadoop 组件有一定研究。在加入 AWS 之前,在猎豹移动任职大数据高级运维工程师,有 10 多年的运维经验,深入理解云架构设计,对云上的运维,Devops,大数据解决方案有丰富的实践经验
本文转载自亚马逊 AWS 官方博客。
原文链接:




