
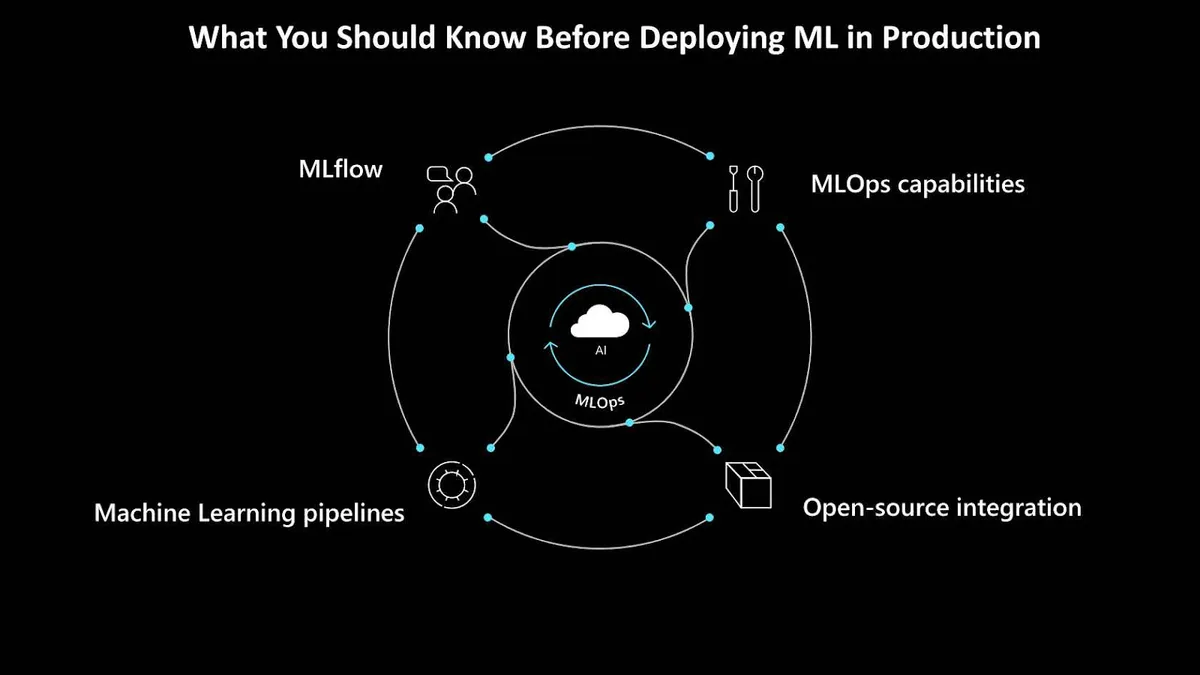
在将机器学习项目部署到生产环境之前,你应该知道哪些事?机器学习运营,或称 MLOps,有四个方面是每个人都应该首先了解的。它们可以帮助数据科学家和工程师克服机器学习生命周期中的局限性,并真正地将它们当成机会来看待。
MLOps 的必要性
MLOps 之所以重要,有几个原因。首先,机器学习模型依赖于大量的数据,对于数据科学家和工程师来说,要跟踪所有这些数据非常困难。跟踪机器学习模型中可以调整的各种参数也是一项挑战。有时候,一个小小的变化就会导致你从机器学习模型中得到的结果出现非常大的差异。你还必须跟踪模型所使用的特征;特征工程是机器学习生命周期的一个重要组成部分,对模型的准确性有很大影响。
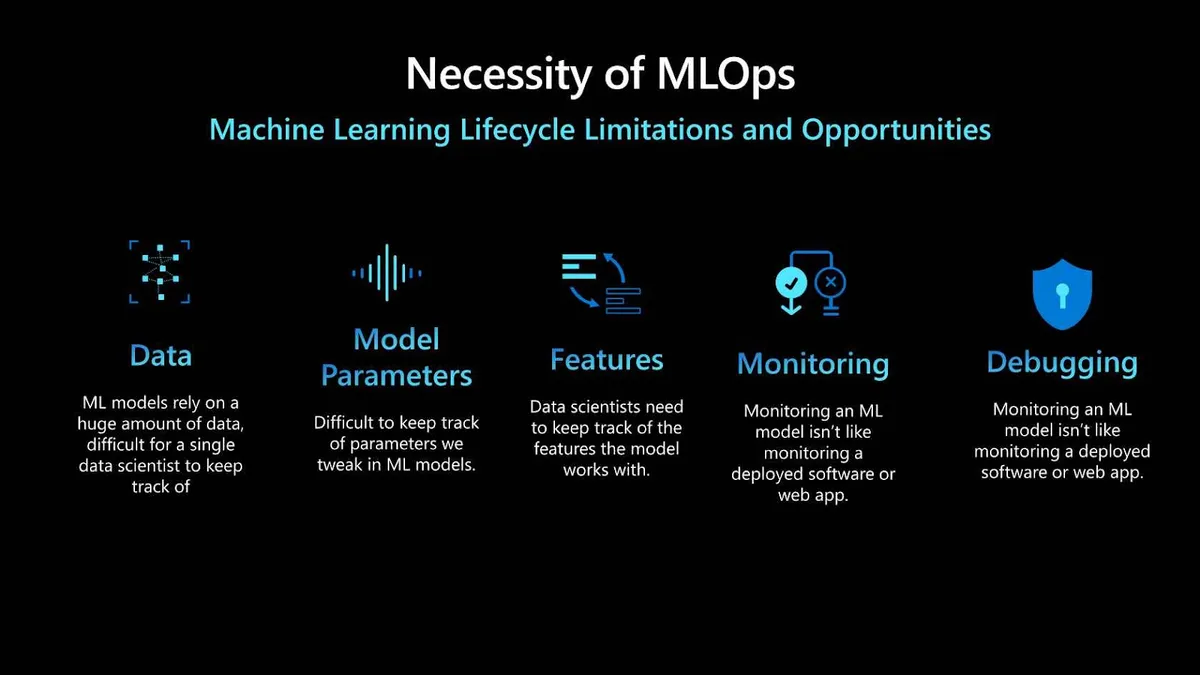
一旦投入生产环境,监控机器学习模型并不像监控其他类型的软件(如 Web 应用)那么简单,而且调试机器学习模型也很复杂。模型使用真实世界的数据来生成预测,而真实世界的数据可能会随着时间而改变。
随着数据的变化,跟踪模型性能并在需要时更新模型就很重要了。也就是说,你必须跟踪新的数据变化,并确保模型能从这些变化中学习。
本文探讨在生产环境中部署机器学习之前你应该知道的四个关键方面:MLOps 能力、开源集成、机器学习管道和 MLflow。
MLOps 能力
在部署到生产环境之前,有许多不同的 MLOps 能力需要考虑。首先是创建可重复机器学习管道的能力。机器学习管道允许你针对数据准备、训练和评分过程定义可重复且可重用的步骤。这些步骤应包括为训练和部署模型创建可重用的软件环境,以及从任何地方注册、打包和部署模型的能力。使用管道让你能够经常更新模型或与其他人工智能应用程序和服务一起推出新模型。
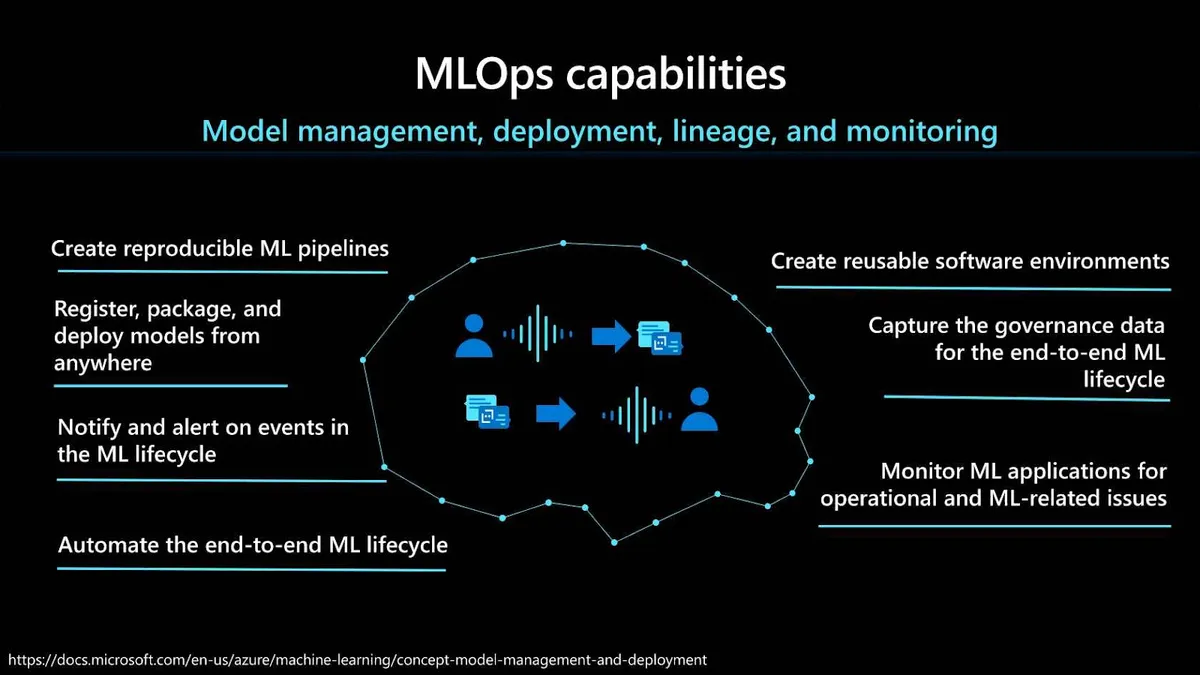
你还需要跟踪使用模型所需的相关元数据,并为端到端机器学习生命周期捕获治理数据。在后一种情况下,举例来说,谱系信息可以包括:谁发布的模型,为什么在某个时间点进行了修改,或者什么时候在生产环境中部署或使用了不同的模型。
对机器学习生命周期中的事件进行通知和提醒也很重要。例如,实验完成、模型注册、模型部署和数据漂移检测。你还需要监控机器学习应用程序,了解运营及 ML 相关的问题。在这里,重要的是,数据科学家能够比较模型输入的训练时间与推理时间,探索模型的具体指标,并配置机器学习基础设施的监控和告警。
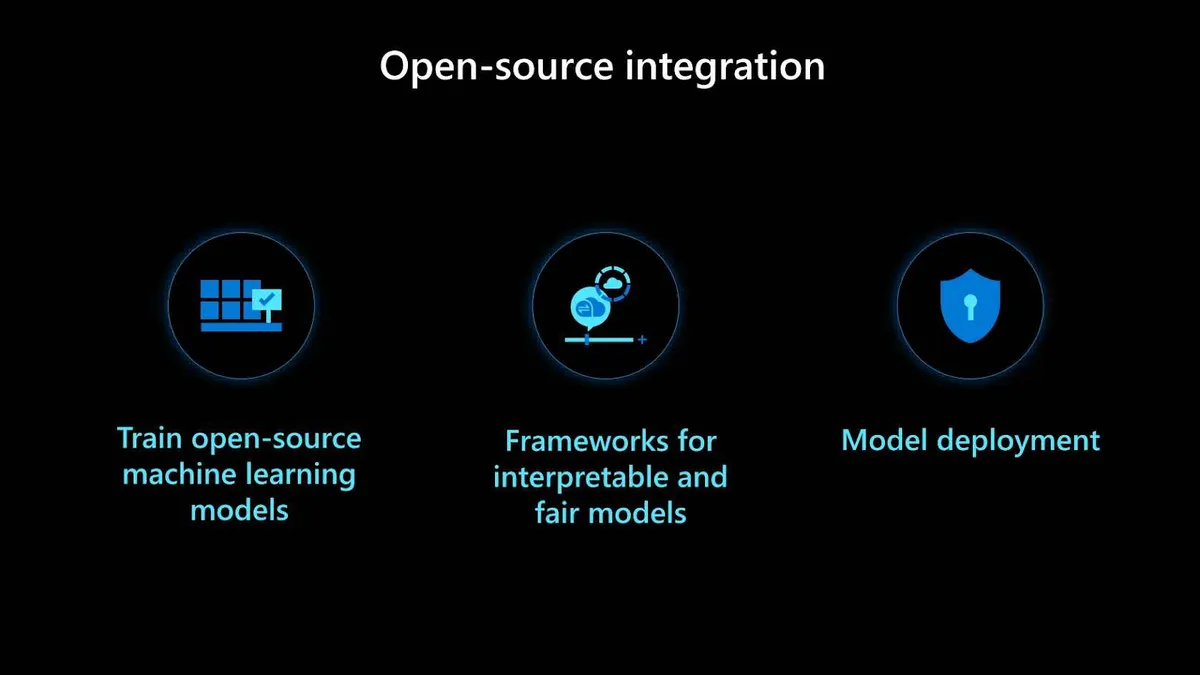
开源集成
在生产环境中部署机器学习之前,你应该知道的第二个方面是开源集成。在这里,有三种不同的开源技术极为重要。首先是要有开源的训练框架,这对于加速机器学习解决方案落地非常有利。接下来是可解释且兼具公平模型的开源框架。最后,还要有用于模型部署的开源工具。
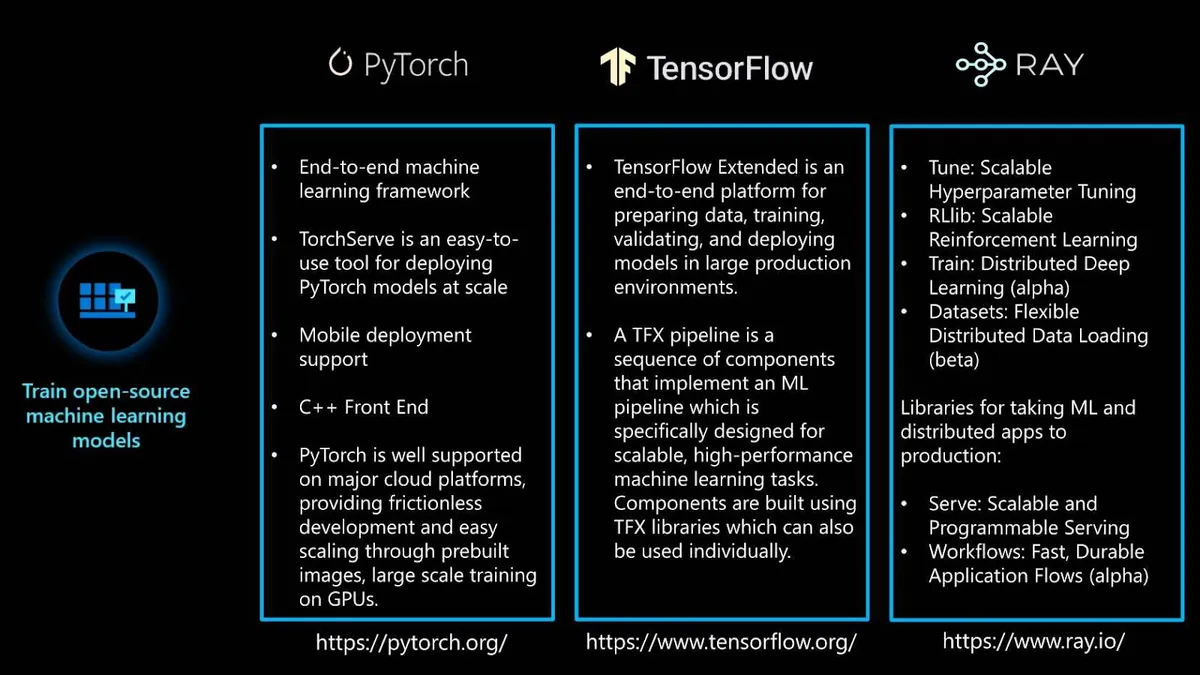
开源训练框架有许多。PyTorch、TensorFlow和RAY是其中最流行的三个。PyTorch 是一个端到端的机器学习框架。它包括一个易于使用的工具TorchServe,可用于 PyTorch 模型大规模部署。PyTorch 还提供移动部署支持和云平台支持。最后,PyTorch 支持C++前端:PyTorch 的纯 C++接口,遵循 Python 前端的设计和架构。
另一个端到端的机器学习框架是 TensorFlow,在业界也非常流行。对于 MLOps 来说,它有一个名为TensorFlow Extended(TFX)的特性。这是一个端到端的平台,用于在大型生产环境中准备数据、训练、验证和部署机器学习模型。TFX 管道是一个组件序列,专门为可扩展、高性能的机器学习任务而设计。
RAY 是一个强化学习(RL)框架,它包含多个有用的训练库:Tune、RLlib、Train和Dataset。Tune 对于超参数调优非常有用。RLlib 用于训练 RL 模型。Train 用于分布式深度学习。Dataset 用于分布式数据加载。另外,RAY 还有两个库:Serve和Workflows,它们在将机器学习模型和分布式应用部署到生产环境中时非常有用。
对于创建可解释且兼具公平性的模型,有两个框架非常有用,分别是InterpretML和Fairlearn。InterpretML 是一个开源软件包,包含多种机器学习解释技术。通过这个包,你可以训练可解释的明箱模型,也可以解释黑箱系统。此外,它还可以帮助你理解模型的全局行为,或者理解个别预测背后的原因。
Fairlearn 是一个 Python 软件包,可以提供指标用于评估哪些组受到模型的负面影响,并且可以从公平性和准确性方面比较多个模型。它还支持几种算法,用于缓解各种人工智能和机器学习任务中的不公平现象,并提供了各种公平性定义。

我们的第三项开源技术是针对模型部署。当使用不同的框架和工具时,你必须根据每个框架的要求来部署模型。为了使这个过程标准化,你可以使用 ONNX 格式。
ONNX是 Open Neural Network Exchange 的缩写。ONNX 是一种面向机器学习模型的开源格式,支持不同框架之间的互操作性。也就是说,你可以在任何流行的机器学习框架(如 PyTorch、TensorFlow 或 RAY)中训练一个模型,然后将其转换为 ONNX 格式,并在不同的框架中使用,例如在ML.NET中。
ONNX运行时(ORT)使用一套通用的运算符表示机器学习模型,它们是机器学习和深度学习模型的构件,让模型可以在不同硬件和操作系统上运行。ORT 优化并加速了机器学习推理,让客户感觉更快的同时,降低了产品成本。它支持来自深度学习框架(如 PyTorch 和 TensorFlow)的模型,也支持经典的机器学习库,如 Scikit-learn。
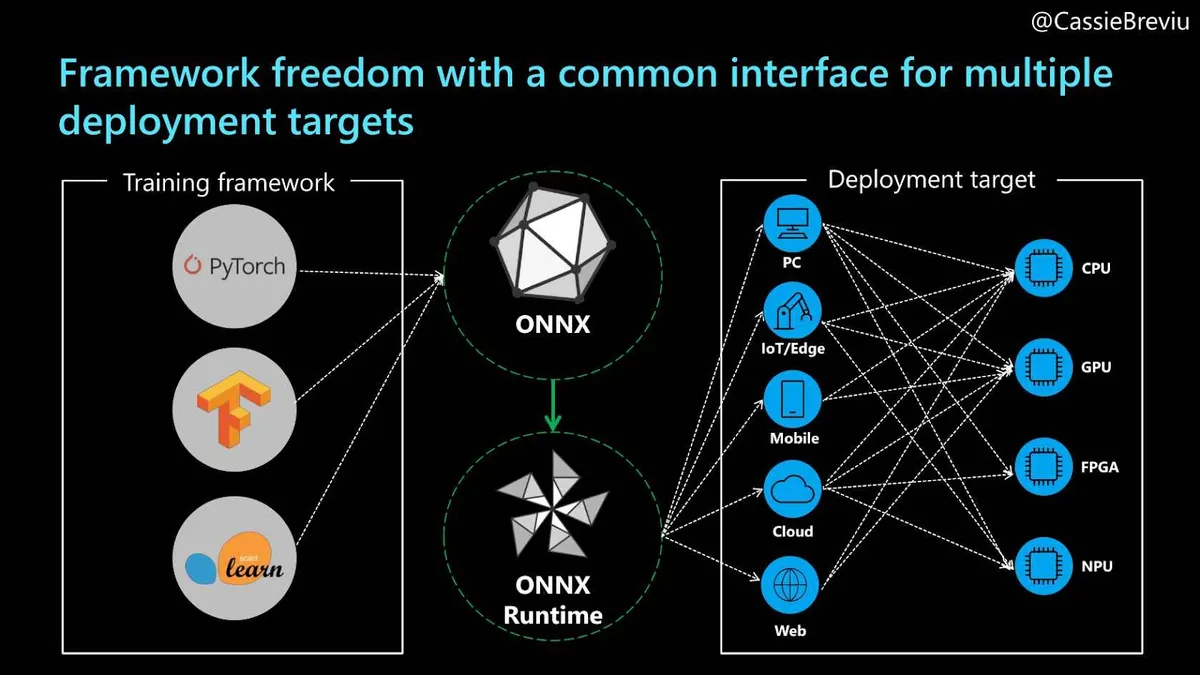
有许多不同的流行框架支持转换为 ONNX。其中一些,如 PyTorch,内置了 ONNX 格式导出。对于其他框架,如 TensorFlow 或Keras,有单独的安装包可以处理这种转换。这个过程非常简单明了:首先,模型在训练时使用的框架支持导出和转换为 ONNX 格式。然后,用 ONNX 运行时加载并运行该模型。最后,使用各种运行时配置或硬件加速器来优化性能。

机器学习管道
在生产环境中部署机器学习之前,你应该知道的第三个方面是如何为机器学习解决方案构建管道。管道中的第一个任务是数据准备,包括导入、验证、清理、转换和规范化。
接下来,管道包含训练配置,涉及参数、文件路径、日志和报告。然后是实际的训练和验证作业,它们以高效和可重复的方式执行。效率可能来自特定的数据子集、不同的硬件、计算资源、分布式处理,还有进度监控。最后是部署步骤,其中包括版本管理、扩展、配置和访问控制。
管道技术的选择取决于你的特定需求,通常是以下三种情况之一:模型编排、数据编排或代码和应用编排。每个场景都以一个角色为中心,该角色是这项技术的主要用户;每个场景还有一个典型的管道,也就是该场景下典型的工作流。

在模型编排场景中,主要的角色是数据科学家。在这种情况下,典型的管道是从数据到模型。就开源技术选择而言,Kubeflow Pipelines是这种情况下的一个流行选择。
对于数据编排场景,主要的角色是数据工程师,典型的管道是从数据到数据。在这种情况下,常见的开源选择是Apache Airflow。
最后,第三个场景是代码和应用编排。这里,主要的角色是应用开发人员。典型的管道是从代码加模型到服务。在这种情况下,Jenkins是一个典型的开源解决方案。
下图这个例子展示了一个在Azure Machine Learning上创建的管道。对于每个步骤,Azure 机器学习服务都会计算出硬件计算资源、Docker镜像等操作系统资源、Conda等软件资源以及数据输入需求。
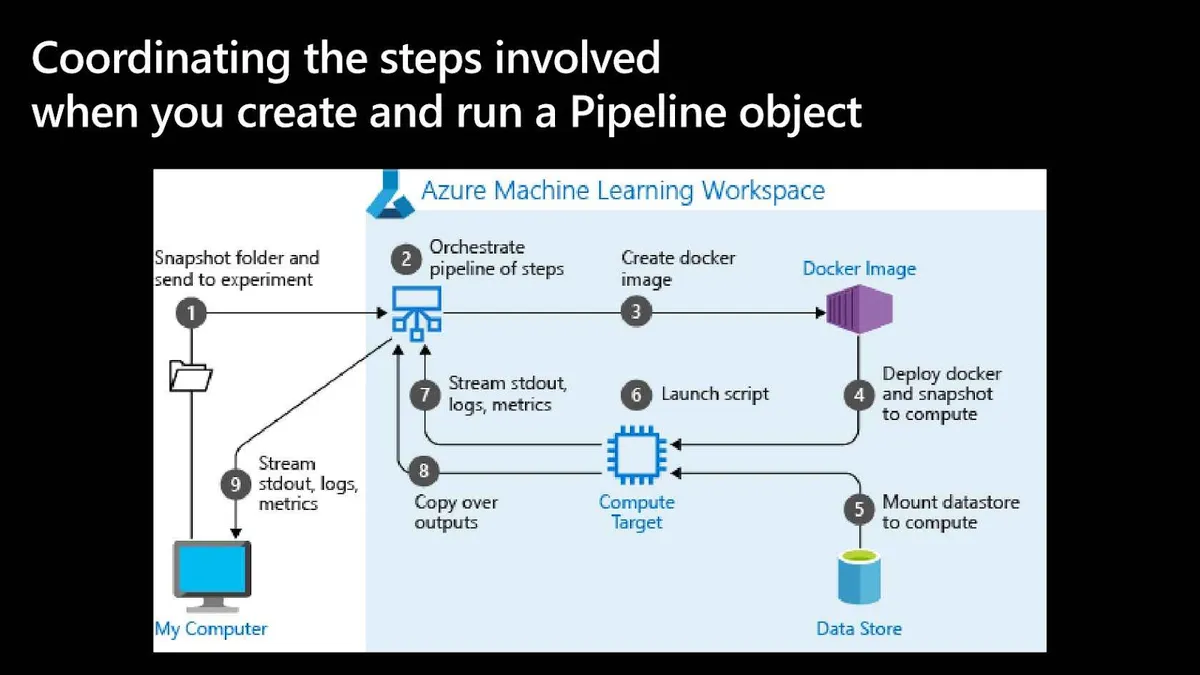
然后,该服务确定各步骤之间的依赖关系,从而形成一个高度动态的执行图。当执行图中的每个步骤运行时,该服务会配置必要的硬件和软件环境。该步骤还向其包含的实验对象发送日志和监测信息。当该步骤完成后,其输出将作为下一个步骤的输入。最后,回收并分离不再需要的资源。
MLflow
在生产环境中部署机器学习之前,你应该考虑的最后一个工具是 MLflow。MLflow是一个开源平台,用于对机器学习生命周期做端到端管理。它主要包含四个组件,它们在这个生命周期中极为重要。
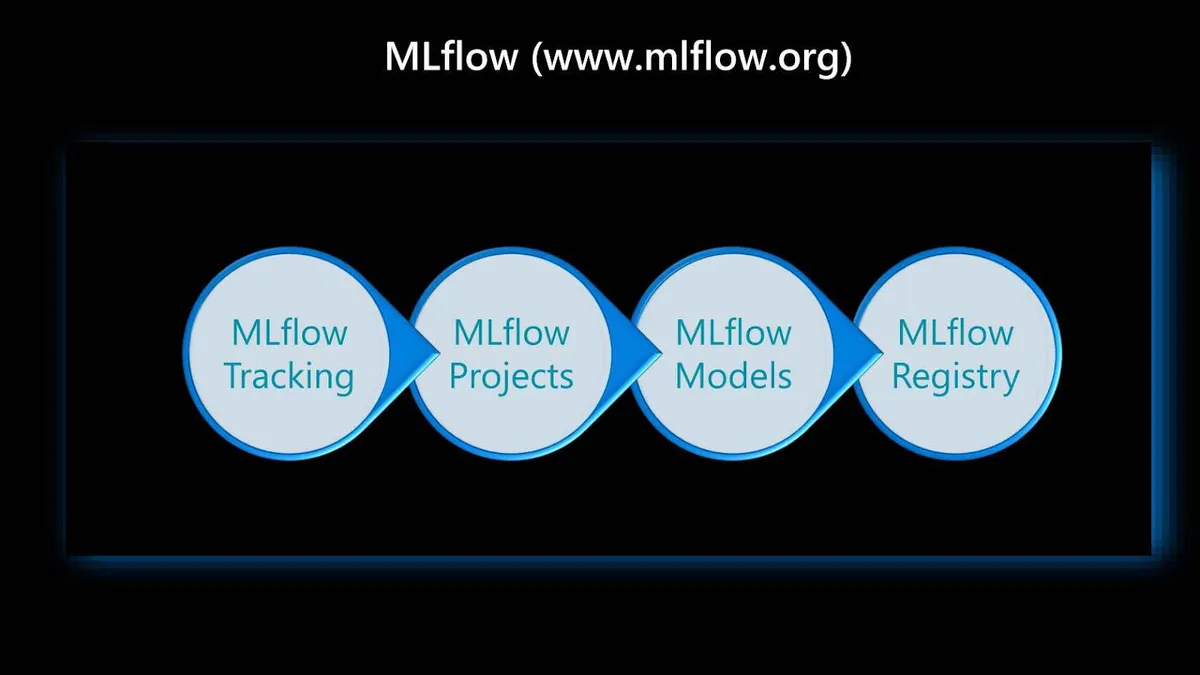
第一个是MLflow Tracking。它跟踪实验,记录并比较参数和结果。可以将 MLflow 运行(run)记录到本地文件、兼容SQLAlchemy的数据库或远程跟踪服务器。可以使用 Python、R、Java 或 REST API 记录运行数据。MLflow 允许在实验中对运行进行分组,举例来说,这对于比较运行以及比较旨在处理特定任务的运行非常有用。
接下来是MLflow Projects。它以可重用和可再现的形式将 ML 代码打包到一个项目中,以便与其他数据科学家共享或转移到生产环境。它指定了打包数据科学代码的格式,主要是基于惯例。此外,该组件还包括一个用于运行项目的 API 和命令行工具,使得将多个项目链接到工作流中成为可能。
然后是MLflow Models。它管理和部署来自各种机器学习库以及各种模型服务和推理平台的模型。模型是打包机器学习模型的标准格式,可用于各种下游工具;例如,通过Apache Spark上的 REST API 或批处理推理提供实时服务。每个模型都是一个包含任意文件的目录,在该目录的根目录中有一个模型文件,它可以定义多种模型查看方式。
最后一个组件是MLflow Registry。它提供了一个集中式的模型存储、一套 API 和一个用于 MLflow 模型全生命周期管理的协作式 UI。它提供了模型谱系、模型版本控制、阶段转换和标注。如果你正在寻找一个集中式模型存储和一套不同的 API 来管理机器学习模型全生命周期,那么 Registry 极其重要。
小结
这四个方面——MLOps 能力、开源集成、机器学习管道和 MLflow——可以帮你创建一个简捷、可重复的流程,用于在生产环境中部署机器学习。这使数据科学家能够快速、轻松地试验不同的模型和框架。此外,你还可以在生产环境中改进机器学习系统的运营流程,使你能够在真实数据随时间推移发生变化时快速地更新模型,将限制转变为机会。
作者简介
Francesca Lazzeri 博士是一位经验丰富的科学家和机器学习从业者。她有超过 12 年的学术和行业经验。她是《时间序列预测:基于机器学习和 Python 实现》一书(Wiley)的作者,她还在许多其他出版物(如技术期刊)上发表过文章,并参加过许多会议。Francesca 是哥伦比亚大学人工智能和机器学习教授,微软首席数据科学家经理。她领导着一个数据科学家和机器学习工程师团队,专注于在云上构建可扩展的数据科学解决方案。在加入微软之前,她是哈佛大学技术和运营管理部门的研究员。她还是数据科学女性(Women in Data Science,WiDS)顾问委员会成员,麻省理工学院机器学习导师,以及人工智能社区的活跃成员。
原文链接:




