
一、定义 Serverless
大家对于 Function as a Service 函数即服务应该都比较熟悉,例如腾讯的 SCF,Azure Functions 和 AWS Lambda 等等,这些服务中,你可以将一段代码(通常是无状态的应用代码)上传到云端,之后基于 API 调用或者配置触发器等方式,随时在云端执行你上传的代码。很棒的一点是,FaaS 服务是按需付费的,根据执行时间和调用次数计费。
那么对于 Backend as a Service 后端即服务,相信大家也都听说过,但并不了解 BaaS 的准确含义。其中的一个重要原因是,BaaS 这个词对于不同的人来说含义也不同,对我们来说,BaaS 是和 FaaS 相对应的概念,其中“即服务”指的是不以“服务器”的方式来提供服务。例如腾讯云的 COS 对象存储服务,AWS DynamoDB 等,都算做是后端即服务。
从定义可以看出,FaaS 和 BaaS 的特点相互呼应和紧密结合,例如 FaaS 是无状态的,而 BaaS 是有状态的;FaaS 基本上可以支持所有运行时的代码,而 BaaS 对编程模型的限制更严格,或者几乎不涉及编程模型,例如对象存储服务。但可以看到,双方的相同点在于弹性伸缩和按需付费。

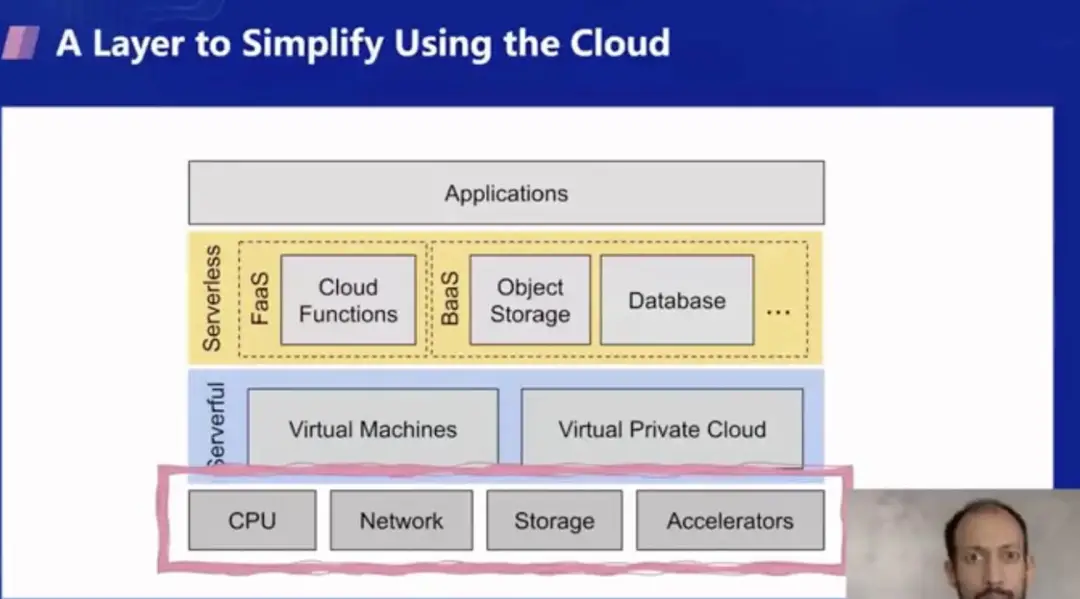
可以认为 Serverless Computing 是一种用云的简化方式。我们可以用下面这张图来说明。从最底下开始,在最底层你需要硬件,要有 CPU,网络,存储,和一些加速器(如 GPU 或者机器学习的加速器),在这之上云通过虚拟化技术提供了抽象层,硬件服务器被分隔成了多个互相隔离的虚拟机/虚拟私有网络,这一层的服务形态和底层架构是类似的,对于应用层面来说使用起来也有一些复杂,所以出现了 Serverless 的概念,在这一层中 Serverless 化的服务让调用基础设施变得更加简单。
接下来我们可以看下,为什么说传统的服务器托管比较复杂呢?主要是因为有太多方面需要考虑,即使对于一个简单的应用而言,你也要考虑下面这些方面:可用性,多地域部署,扩缩容,监控告警和排障,系统升级和安全漏洞,迁移策略等等。

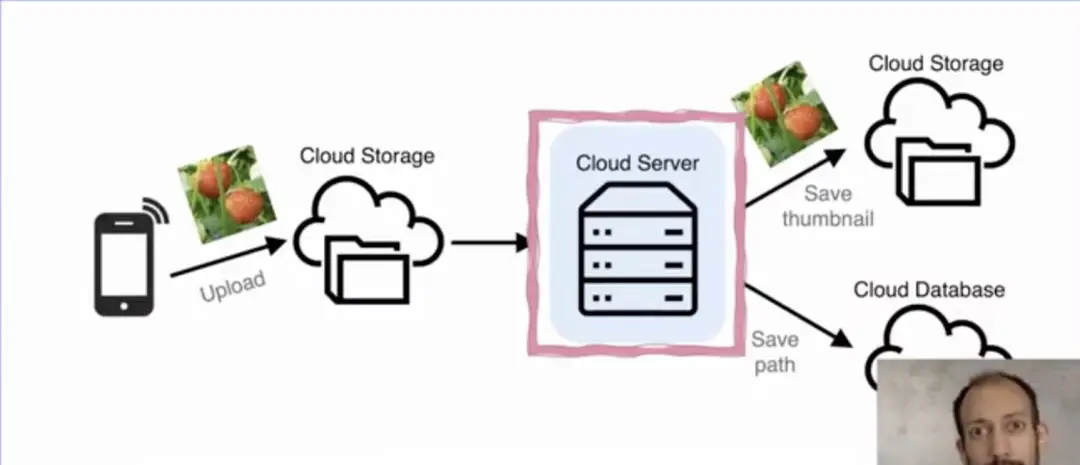
有个非常经典的案例可以说明传统和 Serverless 架构的区别。在这个例子中,希望实现非常简单的功能:上传图片,对图片做压缩后,提取并存储图片的点赞和路径等信息到数据库等。如果你要用服务器来做,则需要非常长的处理和搭建流程;但是如果用 Serverless 架构来做,则只需要负责 FaaS 的代码处理逻辑即可。但是这里要强调的是,该应用的实现不只需要 FaaS 的处理,也同样需要 BaaS 服务的配合,才能实现完整的 Serverless 架构。
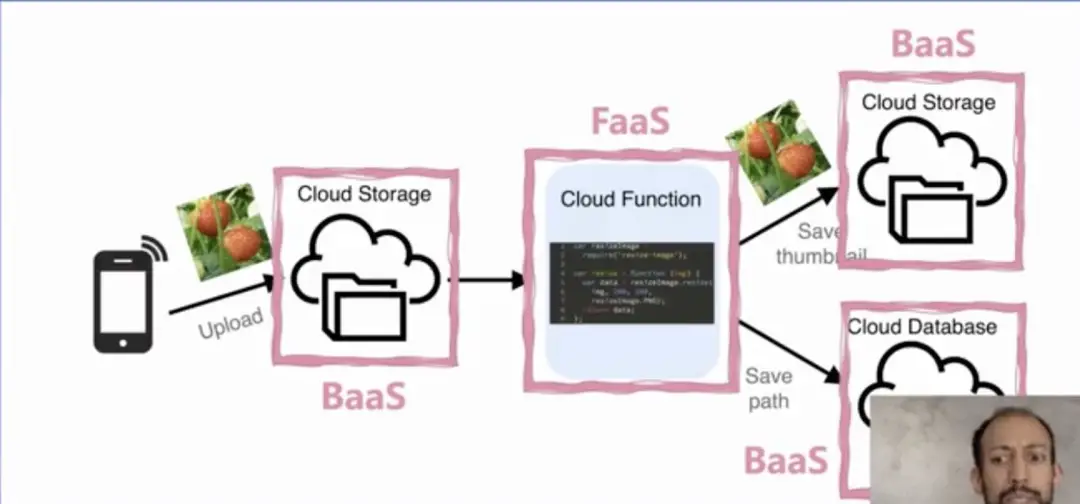
总结起来,在 UC Berkeley 我们认为 Serverless 需要满足下面三个关键特性:
隐藏了服务器的概念。虽然服务器依然存在,但开发者不感知,也无需针对服务器进行繁琐开发和运维操作
提供了一种按需付费的计费模型,并且在资源空闲时不收费
提供极致的弹性伸缩能力,从而让资源的提供完美适配业务需求
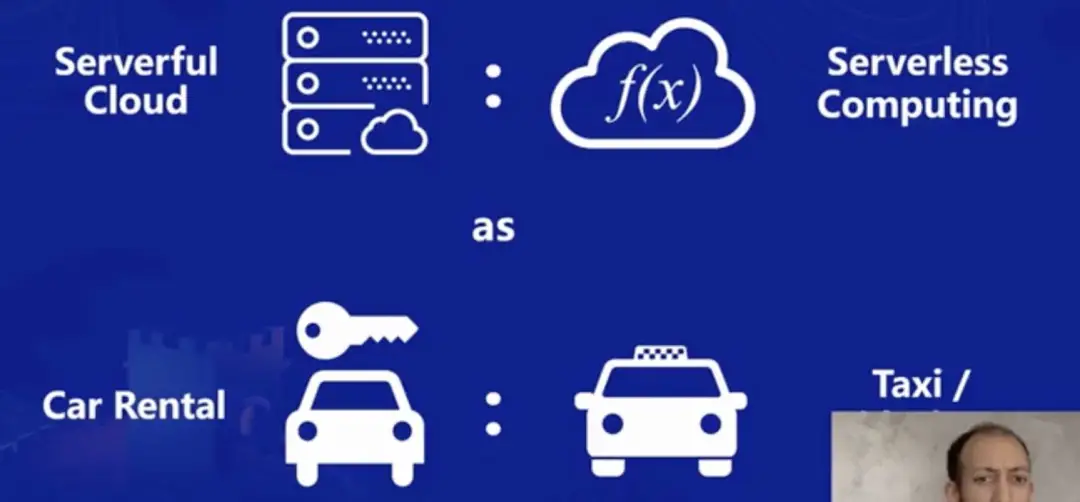
如果举例说明,可以将传统服务器和 Serverless 用租车和打车来做对比。(不展开)
云计算的进化历程可以从资源的分配和收费模型中看出,在传统的硬件时代,需要预分配物理资源来承载业务;而在服务器时代,则需要通过粒度较粗的服务器实例来进行扩缩容和计费,用于承载业务;在 Serverless 时代,才能真正做到极致弹性和按需付费。
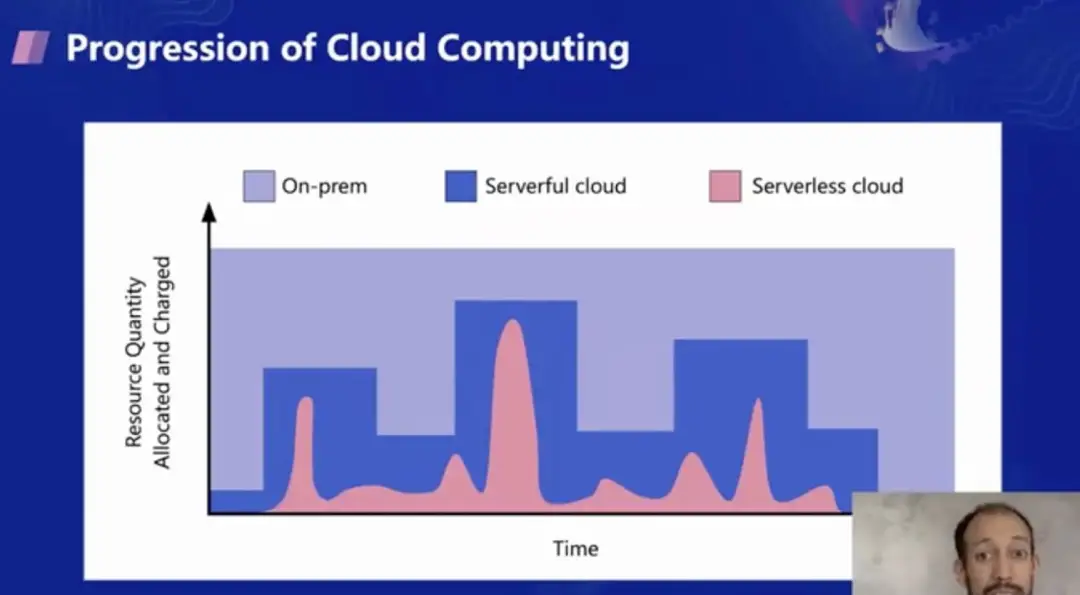
因此,在 Berkeley 我们认为 Serverless 是云计算的下一个阶段,不仅因为弹性伸缩和按需付费的特点,还有个重要原因是,我们认为 Serverless 改变了人和电脑协作的方式。
在云计算的第一阶段,极大的简化了系统管理员的职责,人们可以通过 API 的方式获得服务器,无需自建机房。这种获取资源的方式十分简单,开发者都可以轻易的实现资源的购买和配置。而在这一阶段,云服务商则负责管理并保证这些资源的稳定性。
在云计算的第二阶段,在运维/管理员之外,进一步简化了开发者的职责。开发者不需要关心复杂的资源分配/运维逻辑,只需要写好原生业务逻辑,上传到云端后就可以执行,无需担心扩缩容的问题。而云服务商则承担了系统管理员和资源管理的角色。在这阶段,云计算对开发者编程模式的改变,就好像十年前的第一阶段中,云计算对系统管理员的职责转变一样,是十分重大的转折。这一转变也极大的激励了开发者,拓展了他们的能力边界,开发者可以专注于业务实现,无需担心底层资源的运维。

二、Serverless 研究成果和亮点
在第二部分,我想分享一些 Berkeley 最近的研究成果。我们发现,Serverless 中 FaaS 部分很难解决所有问题,因为函数即服务从平台层面有诸多限制:
首先是运行时间的限制,当前各云平台对于 FaaS 的运行时间都有 10-15 分钟的限制,这种限制影响了许多场景的实现,尤其是一些强状态依赖的场景,例如长时间保持数据库连接的情况等。
此外,FaaS 平台只能支持短暂的有状态性(Ephemeral State),没有磁盘可以存储或者永久保存状态信息。
第三点,当前不能直接和函数服务进行网络通信,函数即服务可以提供外访能力,但对于入流量的支持不够友好,例如在你开发的应用中,获取到函数中的一些数据会比较困难,从而可能会影响软件原本的开发方式,需要做额外的适配。
最后一个限制是在硬件层面的,例如一个机器学习方面的应用利用了 GPU 硬件,在当前的 Serverless 计算层面是难以提供 Serverless GPU 计算资源的。

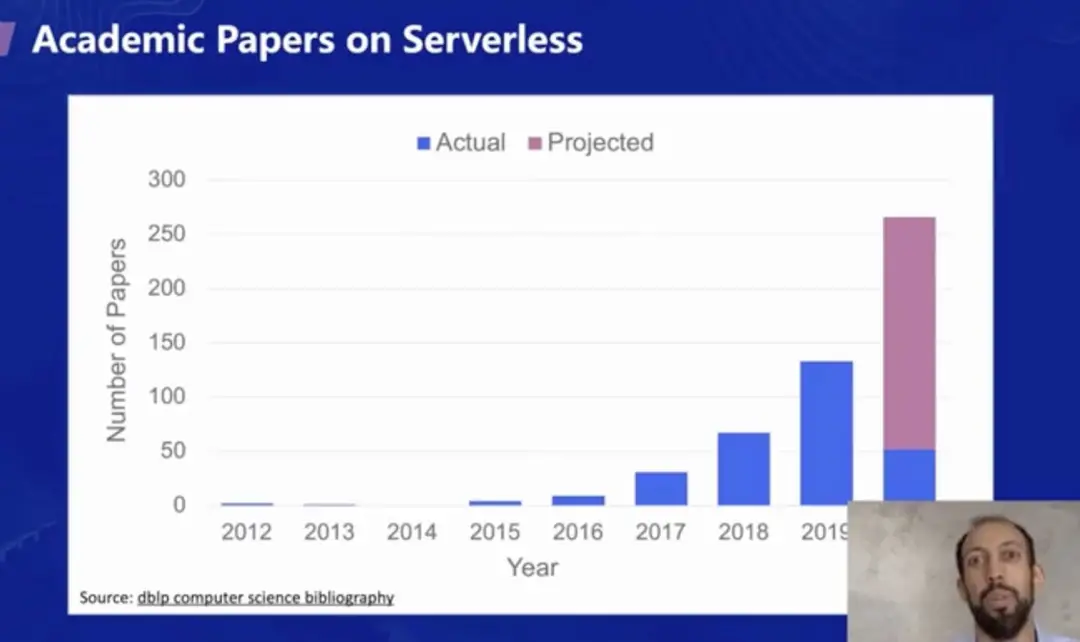
当新的技术趋势出现时,学术界往往非常活跃,从近几年的对 Serverless 方向研究的论文数就可以看出。如下图所示,最近几年来,Serverless 方向的论文数每年都在翻倍增长,在 2020 年,已发表+计划发表的论文将继续翻倍,达到近 300 篇。
在分享一些具体研究成果之前,我想先简单介绍下几种不同的 Serverless 研究方向:
具体应用的抽象:选取一个场景,将其 Serverless 化,不会做太多通用层面的抽象。例如针对大数据检索并生成报表等,只要用 Serverless 解决该场景下的问题即可。
通用的抽象:我认为这个层面的研究最有意思,并且自己也在做这方面的研究。即通过满足一些条件,即可让任意业务适配 Serverless 架构。本质上说,这就涉及到怎样针对分布式系统进行开发模式的简化。
实现层面:当函数即服务刚推出的时候,在效率等方面有很多待提升的地方。目前虽然已经有一些改善,但从学术层面依然有非常多可深入优化的地方,例如 FaaS 平台将不断追求更低的延迟,更好地状态共享,租户隔离,极致的弹性扩展等方面。

接下来我将分享 Berkeley 近期在以下五个方面的研究成果,分别是 Serverless 机器学习,以及用于支持机器学习的 GPU 相关的内核即服务,之后会分享状态性相关的云函数文件系统和 Starburst,最后会通过展望 Serverless 数据中心来收尾。

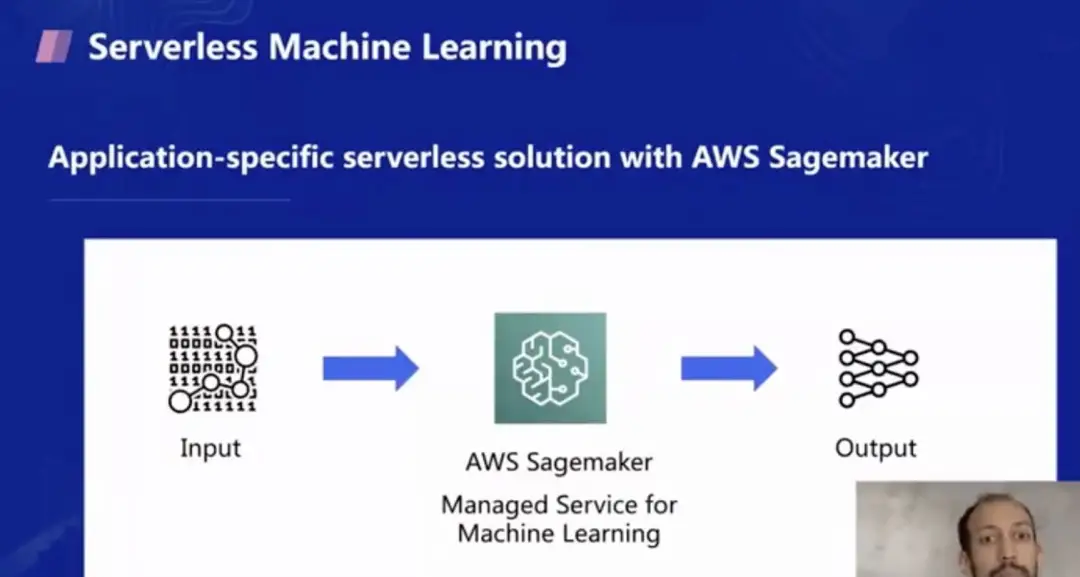
第一个是机器学习方面的研究,当前其实在云端已经提供了应用层面的 Serverless 机器学习服务,例如 AWS 的 Sagemaker 服务,用户只要输入数据,设置好模型,Sagemaker 就会帮忙做训练,并按照模型的训练时间来计费。但这个服务仅是针对机器学习这个特定场景的,并不具备普适性,此外,对于模型有定制化需求,或者训练步骤有改动场景(例如 Berkeley 的一些新的训练算法),这个服务并不能完全满足需求。
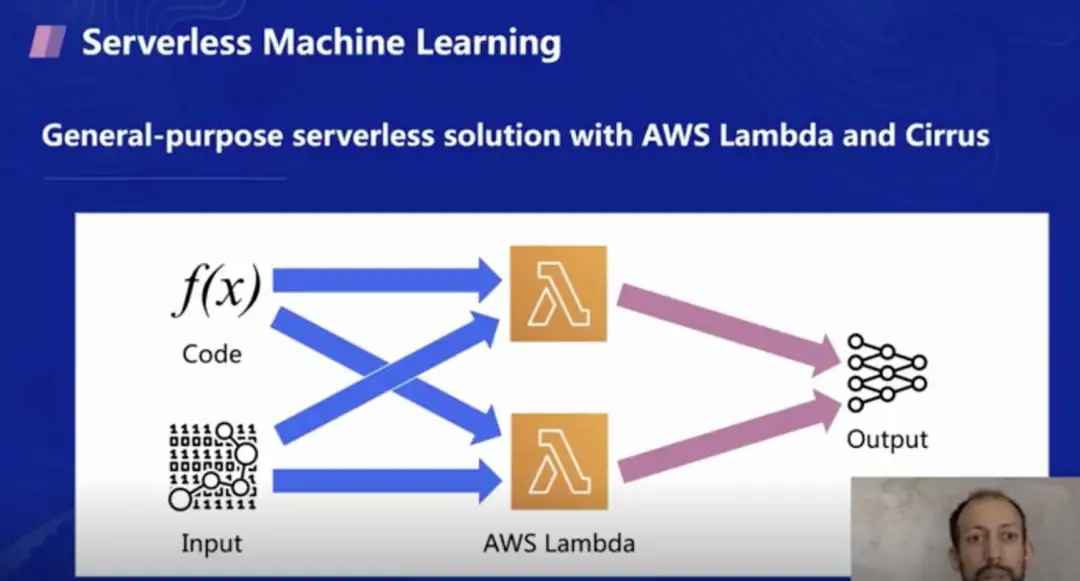
那么是否可以推出更加通用的机器学习解决方案呢?例如把数据或者代码作为函数的输入,并将其运行在 AWS Lambda 函数服务及 Cirrus 上进行机器学习训练。因此团队开发了 Cirrus 的机器学习库,可以让用户方便的在 Lambda 上端到端地进行机器学习训练,满足定制化需求。
Cirrus 团队在 FaaS 平台上做了很多尝试,也遇到了非常多平台的限制,例如内存过小,上传的代码包大小有限制,不支持 P2P (peer to peer) 点对点传输,没有快速的存储介质,实例的生命周期有限,会被回收和重启等。
但是根据右边的实验结果可以看出,在越短的执行时间内, Cirrus 的性能表现越好,甚至优于其他几种机器学习技术。因此你可以根据自己的训练模型和需求选择要不要使用 Cirrus 作为 Serverless 机器学习的训练方案。

参考文献:
https://github.com/ucbrise/cirrus
https://people.eecs.berkeley.edu/~joao/p13-Carreira.pdf
第二个研究课题是关于机器学习作为容器即服务 (Kernel as a Service) 的。大家都知道当前 FaaS 主要运行在 CPU 的硬件上,而在机器学习领域,GPU 针对许多算法和工作流提供了非常重要的加速作用。因此 Berkeley 团队希望提供一种方案,将 GPU 和 Serverless 计算更好地结合在一起。
由于成本/价格原因,目前商业化的云函数服务不提供 GPU 函数。因为 GPU 服务器价格高昂,需要针对机器利用率做进一步优化后才能真正进行商业化使用。因此,我们提出了 KaaS 容器即服务的概念,和 FaaS 的 Node.js 和 Python 等运行时一样,只不过 KaaS 中运行时支持的是面向 GPU 的语言如 CUDA 或 OpenCL。但当前研究的挑战在于,是否可以完全通过纯 GPU 语言来编写 KaaS 服务,完全摆脱对 CPU 代码的依赖呢?
下图可以进一步解释这个理念,一种方式是在函数平台中同时提供 CPU 和 GPU 的支持,即每个函数的底层架构中既有 CPU、内存卡,也有 GPU 加速器。
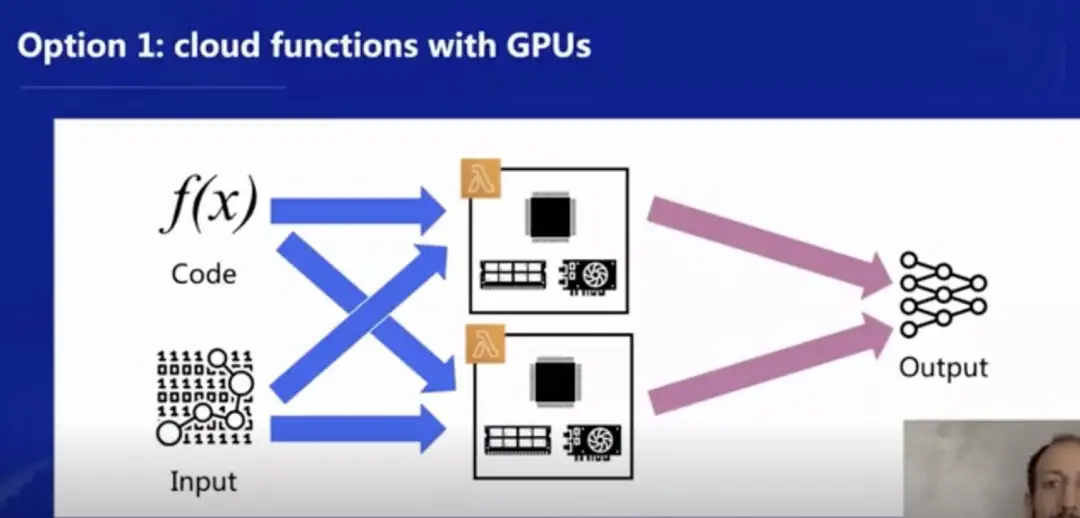
但是有挑战的地方在于,是否可以像下图一样,提供一个 GPU-only 的纯 GPU 底层来运行函数呢?这样可以彻底区分 CPU/内存型函数和 GPU 型函数,由于当前从通讯模式上还比较难将 CPU 和 GPU 从硬件上彻底分开,这将是研究中比较大的一个挑战。
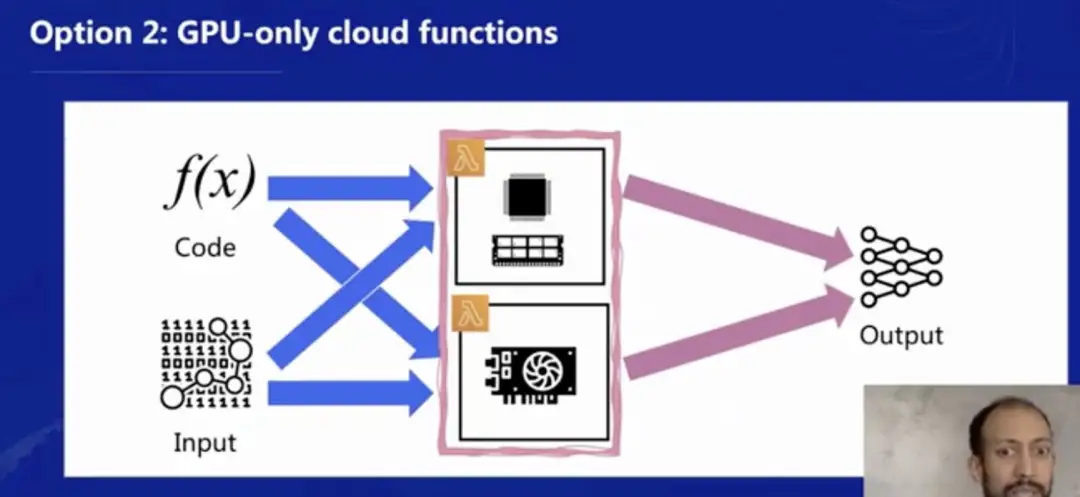
参考文献:https://people.eecs.berkeley.edu/~kubitron/courses/cs262a-F19/projects/reports/project9_report_ver5.pdf
第三个研究课题主要是 Serverless 文件系统 —— 状态性方面的优化,也是非常有价值的一个方向。
说明: 由于文章篇幅较长,剩余研究课题、方向预测和总结将在下一篇发布。敬请期待!
头图:Unsplash
作者:Johann
原文:https://mp.weixin.qq.com/s/jps7Y9yuNX4zf2SjM9XZCA
原文:权威指南:Serverless 未来十年发展解读 — 伯克利分校实验室分享(上)
来源:TencentServerless - 微信公众号 [ID:ServerlessGo]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




