
前言
视频直播是一种创新的在线娱乐形式,具有多人实时交互特性,在电商、游戏、在线教育、娱乐等多个行业都有着非常广泛的应用。随着网络基础设施的不断改善以及社交娱乐需求的不断增长,视频直播在持续渗透进大家的日常生活,并占据用户的零碎休闲时间。视频直播的技术支撑能力也在不断提高,从而促进视频直播市场规模从 2014 年的 212.5 亿元增长到 2020 年的 548.5 亿元,并将在未来五年继续以 12.8% 左右的增长率快速发展。

视频截帧需求概述
直播行业受到越来越多的法律、法规和政策的规限,在行业一般标准和运营规程的约束下,每一个直播平台都有义务对非法的直播内容,以及主播与观众之间的不当互动采取措施,为直播行业更为规范的发展做出贡献。如何第一时间监控到直播流中的非法内容,是直播平台需要面对的共同挑战,视频截帧就是满足内容审核需求的常规操作。
视频截帧可以根据视频直播的不同风险等级,选择不同的频率对直播流进行截帧处理,保存后的图片可以统一上传到自建或第三方内容审核平台,用于涉黄、涉政、广告等场景的识别。除此之外,某些特定的业务需求也需要通过视频截帧来实现,比如在线课堂类应用对学生的听课状态进行智能分析等。
视频截帧技术架构分析
对于视频流的截帧操作,可以通过 FFmpeg 命令实现。FFmpeg 的截帧命令使用非常简单,每次截取一张图片后,可以将图片上传到对象存储 OSS,同时将对应的截帧信息发送到消息队列 Kafka。这样审核服务(可以是第三方服务或是自建服务)就可以从 Kafka 获取截帧信息,并从 OSS 拉取对应的图片进行处理。在这个架构中,引入 Kafka 是为了通过异步处理机制缓解审核服务在业务高峰期的负载。
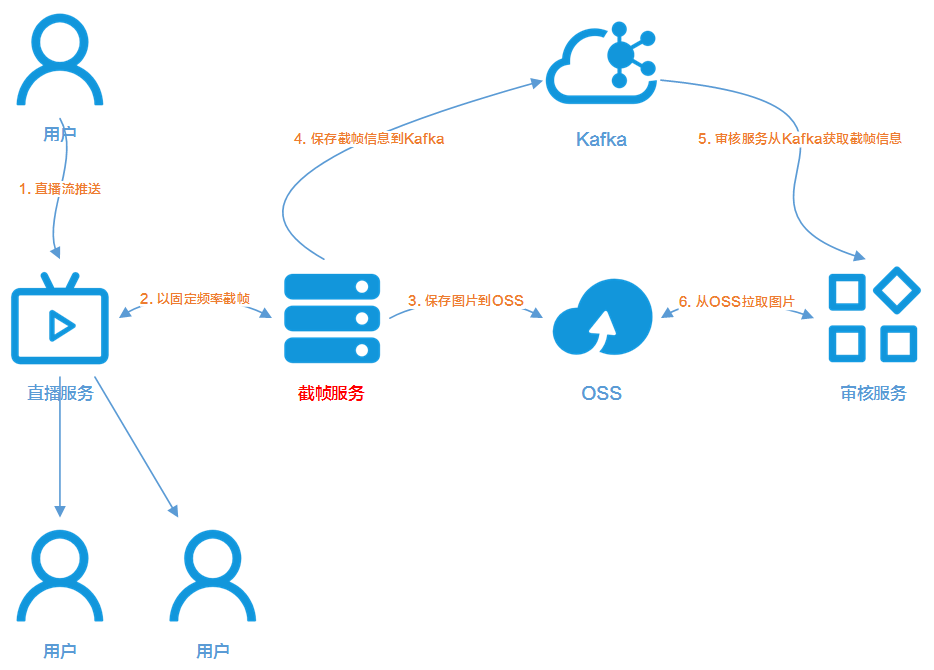
FFmpeg 使用虽然简单,但是这是一个对于 CPU 计算力需求量非常大的操作。如果按照 1 秒的固定频率对视频流进行截帧操作,1 台 16 核的 ECS 大概能同时承担 100 路视频流的截帧任务。为了确保业务高峰期的服务稳定,就需要准备大量 ECS 来部署视频截帧服务。而大多数互联网应用都存在明显的波峰波谷,比如每天晚上的黄金时间是业务高峰,而 24 点以后的业务量会呈明显下降的趋势。这样的业务波动对整体的资源规划带来了极大的挑战,如果按照固定的 ECS 集群规模来部署截帧服务,会存在两个非常明显的弊端:
为了支持业务高峰,必须按照高峰期的用户量来评估集群规模,在业务低峰期就会造成巨大的浪费。
在某些场景下,比如明星效应的带动,业务量会有突增,有可能需要对集群进行临时扩容,这种情况下往往扩容速度会滞后于业务流的增速,造成部分业务的降级处理。
为了更好地提升资源利用率,也可以通过弹性 ECS 实例配合容器化的方式部署应用,以实现集群规模动态适配真实业务量的变化。但在实际情况中,这样的方案弹性伸缩策略实现比较复杂,弹性伸缩能力相对滞后,效果可能并不会太好。其中的根本原因是在传统的服务架构中,一个应用启动后都是长期保持运行,在运行期间会并发处理多个业务需求,不管业务量如何变化,这个应用占据的计算力都不会有本质的变化。
有没有一种直截了当的方式,可以在一路直播视频流开启后,拉起对应的计算力承接截帧任务,而在视频流关闭后,自动将计算力释放呢?这样的方式不需要应用实例长驻,可以实现真正的计算资源按需分配,也不需要借助额外的手段动态调整截帧服务的集群规模,是一种最为理想的方案。
作为云原生 Serverless 技术的代表,阿里云函数计算 FC 就正好实现了这样的思路。
基于函数计算 FC 的 Serverless 架构
函数计算 FC 是事件驱动的全托管计算服务。使用函数计算,用户无需采购与管理服务器等基础设施,只需编写并上传代码。函数计算会自动准备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。借助函数计算 FC,可以快速构建任何类型的应用和服务,并且只需为任务实际消耗的资源付费。
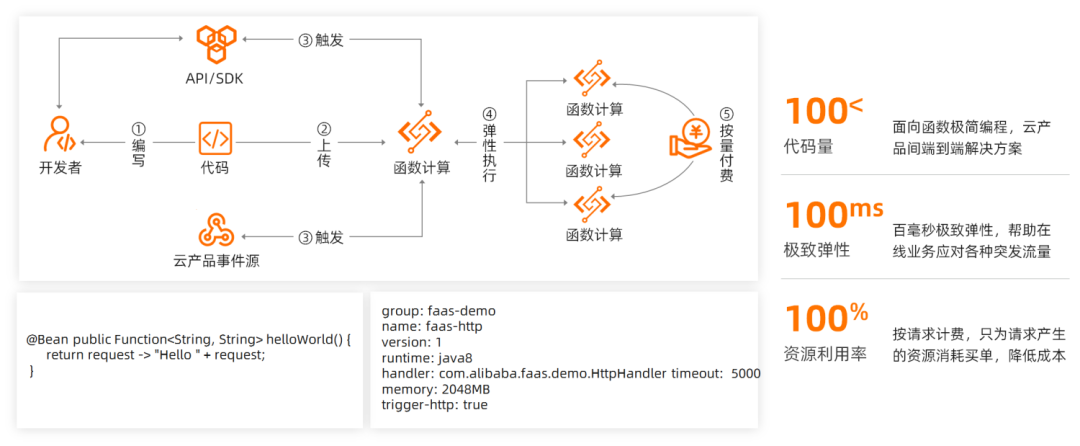
函数计算 FC 提供了一种事件驱动的计算模型,函数的执行是由事件驱动。函数的执行可以通过函数使用者自己触发,也可以由其它一些事件源来触发。可以在指定函数中创建触发器,该触发器描述了一组规则,当某个事件满足这些规则,事件源就会触发相应的函数。比如对于 HTTP 触发而言,用户的一次 HTTP 请求就能触发一个函数;而对于 OSS 触发器而言,OSS 上新增或修改一个文件就能触发一个函数。在视频截帧场景中,函数只需要在每一个直播流开始推送之前,通过业务程序主动触发一个截帧函数就可以了。因此原有的截帧架构只需要做很小的调整,就能迁移到函数计算平台上来,以享受 Serverless 的价值。
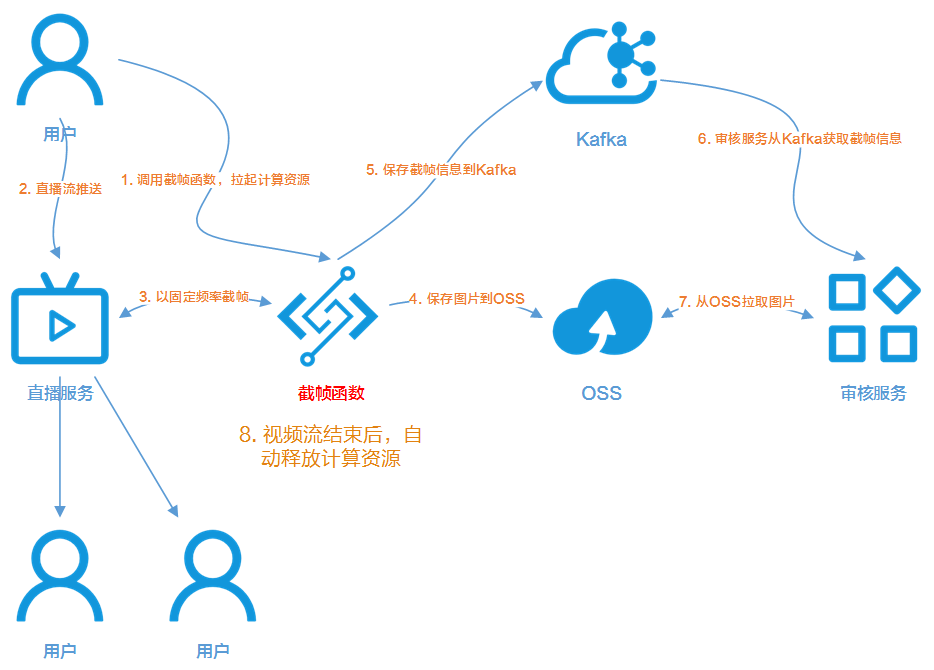
Serverless 架构视频截帧技术实现
现在,我们通过几个简单的步骤来搭建基于函数计算 FC 的 Serverless 架构,以实现视频截帧需求。函数计算 FC 对于 Node.js、Python、PHP、Java 等多种语言提供了原生的运行环境,特别是像 Python 这样的脚本语言,可以实现在函数计算平台上直接修改调度代码,使用非常简单,因此本文的示例代码通过 Python 来实现。
当然,函数计算 FC 对于开发语言没有要求,任何主流的开发语言都可以很好的支持。通过函数计算 FC 提供的 Custom Runtime,可以为任务语言建立自定义的运行环境。Custom Runtime 本质上是一个 HTTP Server,这个 HTTP Server 接管了函数计算系统的所有请求,包括来自事件调用或者 HTTP 函数调用。

输出视频流
我们完全可以通过第三方的视频流服务进行开发,但为了更方便地在本地进行调试,可以通过自建 RTMP 服务实现视频流的输出。其中比较简单的方式是购买 1 台 ECS,并部署 Nginx 实现 RTMP 服务,这需要加载 nginx-rtmp-module 模块,我们可以在互联网上找到很多相关的教程,本文不再赘述。
有了 RTMP 服务之后,我们就可以去 http://ffmpeg.org/ 下载编译好的 FFmpeg 程序包,通过 FFmpeg 命令让本地的视频文件推送到 RTMP 服务。比如用如下的方式:
ffmpeg -re -i test.flv -vcodec copy -acodec aac -ar 44100 -f flv rtmp://xxx.xxx.xxx.xxx:1935/stream/test接下来,我们打开浏览器,输入对应的 RTMP 直播地址,就能拉起对应的播放器观看直播了:rtmp://xxx.xxx.xxx.xxx:1935/stream/test。
安装 Funcraft
Funcraft 是一个支持 Serverless 应用部署的工具,可以帮助用户便捷地管理函数计算、API 网关、日志服务等资源。Funcraft 通过一个资源配置文件 template.yml,就能实现开发、构建、部署等操作,能够在我们使用函数计算 FC 实现 Serverless 架构的过程中,极大程度的减少配置和部署工作量。
有三种方式可以安装 Funcraft,包括 npm 包管理安装、下载二进制安装,以及 Homebrew 包管理器安装。对于没有安装 npm 的环境而言,最简单的方式是通过下载二进制安装。我们可以通过 https://github.com/alibaba/funcraft/releases 下载对应平台的 Funcraft 安装包,解压后就可以使用。可以通过以下命令检验 Funcraft 包是否安装成功:
fun --version如果执行命令后返回 Funcraft 对应的版本号,比如 3.6.20,那就代表安装成功了。
在第一次使用 fun 之前需要先执行fun config 命令进行初始化配置,这个操作需要提供阿里云 Account ID、Access Key Id、Secret Access Key、 Default Region Name 等常规信息, 这些信息可以从函数计算控制台(https://fc.console.aliyun.com/)首页的右上方获得。其他的信息比如 timeout 等直接使用默认值即可。
配置 OSS
由于截帧后保存的文件要上传到对象存储 OSS 备用,我们需要开通阿里云 OSS 服务,并创建对应的 Bucket,具体的操作我们可以参考 https://www.aliyun.com/product/oss 完成。
配置日志服务 SLS
日志服务 SLS(Log Service)是阿里云提供的针对日志类数据的一站式服务,通过日志服务存储函数日志需要在函数对应的服务中配置日志项目和日志仓库,并授予该服务访问日志服务的权限。函数日志会打印到配置的日志仓库中,同一个服务下的所有函数日志都会打印到同一个日志仓库中。可以将函数执行的日志存储至阿里云日志服务,再根据日志服务中存储的函数日志来执行代码调试、故障分析、数据分析等操作。
我们可以参考创建日志项目和日志仓库(https://help.aliyun.com/document_detail/54604.html)来配置日志服务 SLS,要确保日志项目和日志仓库都已经成功创建,在部署函数的时候,需要使用到日志项目和日志仓库的信息。
编写函数
现在我们通过一段最简单的 Python 代码,来体验如何通过函数计算 FC 实现截帧操作,为了让读者理解起来更轻松,我们暂时将业务逻辑简化,只做如下两个动作:
通过 FFmpeg 命令截取 1 张图片;
保存到 OSS。
import json, oss2, subprocessHELLO_WORLD = b'Snapshot OK!\n'OSS_BUCKET_NAME = b'snapshot'def handler(environ, start_response): logger = logging.getLogger() context = environ['fc.context'] request_uri = environ['fc.request_uri'] for k, v in environ.items(): if k.startswith('HTTP_'): pass try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 #获得直播流的地址 rtmp_url = request_body.decode("UTF-8") #通过FFmpeg命令截取一张图片 cmd = ['/code/ffmpeg', '-i', rtmp_url, '-frames:v', '1', '/tmp/snapshot.png' ] try: subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True) except subprocess.CalledProcessError as exc: err_ret = {'returncode': exc.returncode, 'cmd': exc.cmd, 'output': exc.output.decode(),'stderr': exc.stderr.decode()} print(json.dumps(err_ret)) raise Exception(context.request_id + ' transcode failure') #上传到OSS creds = context.credentials auth = oss2.StsAuth(creds.access_key_id, creds.access_key_secret, creds.security_token) bucket = oss2.Bucket(auth, 'http://oss-{}-internal.aliyuncs.com'.format(context.region), OSS_BUCKET_NAME) logger.info('upload pictures to OSS ...') for filename in os.listdir("/tmp"): bucket.put_object_from_file("example/" + filename, "/tmp/" + filename) status = '200 OK' response_headers = [('Content-type', 'text/plain')] start_response(status, response_headers) return [HELLO_WORLD]让我们分析一下这段代码。首先,除了 Python 的 标准模块,函数计算 FC 的 Python 运行环境中还包含了一些常用模块,其实就包括了 oss2,用于在函数中操作阿里云对象存储 OSS。因此,我们可以直接在代码中引入 oss2 这个模块。
函数计算 FC 集成了多种类型的触发器,这个示例函数使用的是 HTTP 触发器,每一个 HTTP 请求都会触发一个函数的执行。对于使用 HTTP 触发器的 Python 代码,入口函数就是handler,其中的 environ 参数携带了调用函数的客户端相关信息以及上下文信息。我们可以从 HTTP 请求 Body 中,解析出 STMP 直播流的地址,并通过 FFmpeg 命令截取一张图片。
在这段代码中,FFmpeg 可执行程序位于/code目录,可以通过/code/ffmpeg路径进行执行。这是因为我们在对函数进行部署的时候,已经将 FFmpeg 可执行程序和这段代码打包在了这个目录中,在接下来介绍函数部署的时候,我们会进一步介绍如何将函数代码与可执行程序一起打包。
在对 /tmp 目录保存的图片文件上传到 OSS 的过程中,我们可以直接从函数上下文中获取访问 OSS 的凭证,这样就不需要再通过配置文件拿到 accessKey,accessSecret 等信息,从而减少工作量。
部署函数
首先,我们在本地创建一个工作目录,并在这个目录下创建一个名为 code 的子目录,将 Linux 环境的 ffmpeg 可执行文件复制到code目录中,这样可以在代码中通过路径/code/ffmpeg调用 ffmpeg 命令。
接下来,开始最重要的工作,在当前工作目录中创建template.yml文件,描述所有的部署信息。
ROSTemplateFormatVersion: '2015-09-01'Transform: 'Aliyun::Serverless-2018-04-03'Resources: #服务 snapshotService: Type: 'Aliyun::Serverless::Service' Properties: Description: 'Snapshot Semo' Policies: - AliyunOSSFullAccess #之前创建的日志项目和日志仓库 LogConfig: Project: fc-bj-pro Logstore: fc-log #函数 snapshot: Type: 'Aliyun::Serverless::Function' Properties: Handler: index.handler Runtime: python3 MemorySize: 128 Timeout: 600 CodeUri: './code' # HTTP触发器 Events: http-test: Type: HTTP Properties: AuthType: ANONYMOUS Methods: ['POST']配置信息比较简单,我们需要先定义一个服务。服务是函数计算资源管理的单位。从业务场景出发,一个应用可以拆分为多个服务。从资源使用维度出发,一个服务可以由多个函数组成。例如一个数据处理服务,分为数据准备和数据处理两部分。数据准备函数资源需求小,可以选择小规格实例。数据处理函数资源需求大,可以选择大规格实例。创建函数前必须先创建服务,同一个服务下的所有函数共享一些相同的设置,例如服务授权、日志配置。在这段代码中,我们创建的服务名为snapshotService,其拥有对 OSS 的全部操作权限,并引用了之前所创建的日志项目和日志仓库。
在函数实例规格的配置上,由于每个计算实例只需要处理一路视频流,我们选择最低的规格,也就是 128M 内存的实例即可。
接下来,我们要定义一个函数,配置其对应的运行环境、入口方法、代码目录、超时时间等信息,并为这个函数定义一个 HTTP 触发器。在这段代码中,函数名为snapshot,对应的运行环境为 Python3,并且定义了一个名为http-test的 HTTP 触发器。
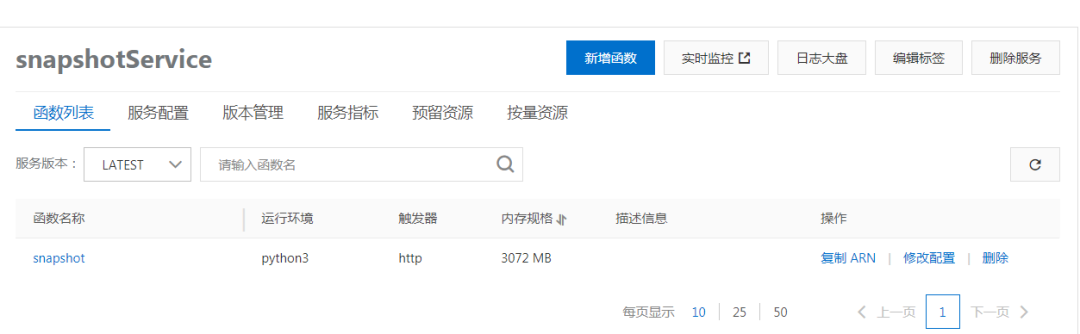
在这个工作目录,执行fun deploy,如果看到提示server SnapshotService deploy success,就代表代码和 ffmpeg 程序已经打包部署到云上了。
在控制台的服务与函数菜单,我们可以看到上传的服务以及函数信息,甚至可以在线查看和修改函数代码。
执行函数
由于这是一个 HTTP 类型的函数,我们可以通过 curl 命令或其他 HTTP 工具,比如 Postman 向函数计算 FC 发起一次 HTTP 请求,验证截帧操作的执行结果。当然,函数计算 FC 控制台也提供了一个可视化操作界面来对函数进行验证,在这个界面可以快速发起一次 HTTP 请求。
如果函数执行成功,我们就可以前往 OSS 控制台检查截取好的图片是否已经成功上传。至此,我们已经搭建好最基本的 Serverless 视频截帧架构,可以通过 HTTP 请求触发函数计算对视频流截取一张图片,并上传到 OSS。
连续截帧
单张图片的截帧操作非常简单,在 FFmpeg 命令执行完成后,就可以直接将临时文件夹中的图片上传到 OSS,然后完成函数的生命周期。单张图片截帧已经可以满足很多种业务场景,但如果需要按照固定频率进行连续截帧,并实时将保存好的图片上传到 OSS,就需要对代码做一些修改。
配置消息队列 Kafka
为了降低内容审核服务在业务高峰期的工作负荷,我们可以在截帧服务和内容审核服务中间引入消息队列 Kafka,这样内容审核服务就能通过消费从 Kafka 收到的消息,对保存的图片进行异步处理。在视频截帧架构中,Kafka 起到了非常重要的信息中转作用,直播的并发越大,截帧频率越高,Kafka 所承受的压力就会越大。特别是在业务高峰期,需要让 Kafka 在高负荷的工作中保持稳定性,直接使用阿里云提供的消息队列 Kafka 能够帮助我们大幅减少 Kafka 集群的维护工作量,用最简单的方式获得可以动态扩展的高可用 Kafka 服务。
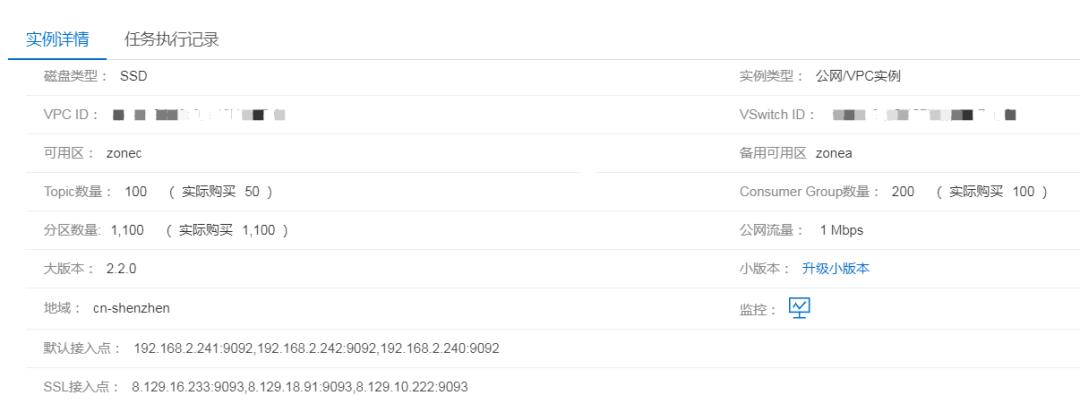
我们可以打开 Kafka 开通界面(https://common-buy.aliyun.com/?commodityCode=alikafka_pre®ionId=cn-hangzhou),根据实际场景的需求购买对应规格的 Kafka 实例。在 Kafka 控制台(https://kafka.console.aliyun.com/?spm=5176.167616.1kquk9v2l.2.6a3d5a1cqKUEUh#/InstanceList?instanceId=alikafka_post-cn-nif1osdl400w®ionId=cn-hangzhou0)的基本信息中,我们可以看到 Kafka 实例对应的默认接入点。
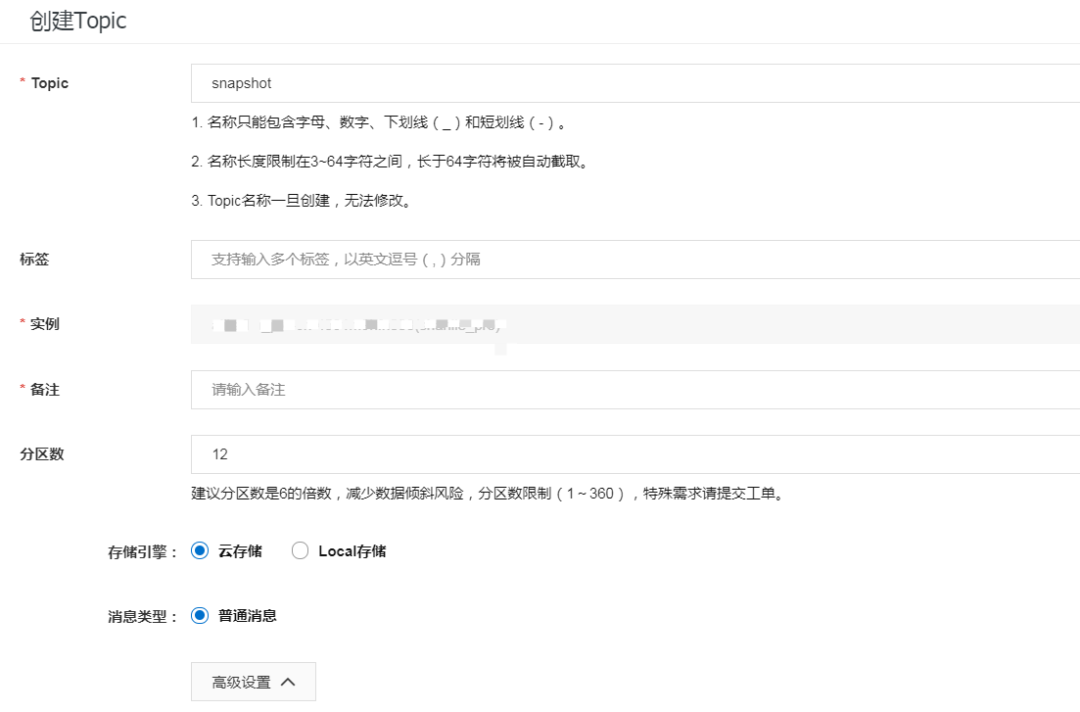
接下来,我们进入 Topic 管理界面,创建一个用于截帧服务的 Topic。
Kafka 实例的默认接入点和 Topic 名称是我们需要在后续步骤中使用到的信息。
安装 Kafka 客户端 SDK
在此之前,我们还需要通过一些额外的操作,获取函数对 Kafka 的写入能力。
因为需要使用到 Kafka SDK,我们可以通过 Funcraft 工具结合 Python 包管理工具 pip 进行 Kafka SDK 模块的安装:
fun install --runtime python3 --package-type pip kafka-python执行命令后有如下提示信息:

此时我们会发现在目录下会生成一个 .fun 文件夹 ,我们安装的依赖包就在该目录下:

打通对 VPC 内资源的访问能力
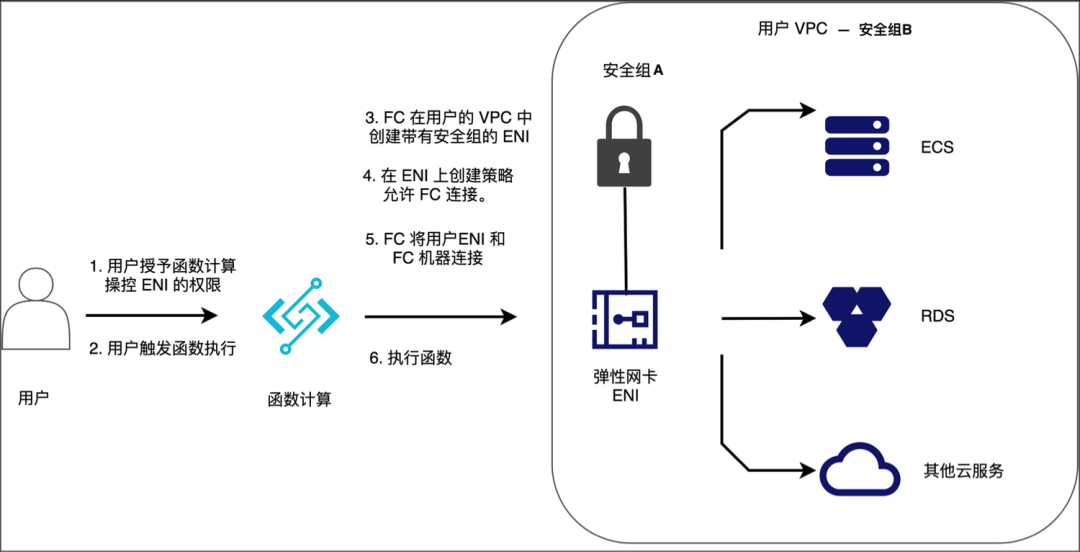
默认情况下,函数计算无法访问 VPC 中的资源,由于我们需要让函数访问部署在 VPC 内的 Kafka 服务需要手动为服务配置 VPC 功能和相关权限。我们可以参考配置函数访问 VPC 内资源(https://help.aliyun.com/document_detail/72959.html),打通函数与 Kafka 服务之间的连接,其原理就是通过授予弹性网卡 ENI 访问 VPC 的权限,并将此弹性网卡 ENI 插入到执行函数的实例上,从而使函数可以访问您 VPC 内的资源。
代码实现
可以通过如下 FFmpeg 命令实现按照指定频繁的连续截帧:
ffmpeg -i rtmp://xxx.xxx.xxx.xxx:1935/stream/test -r 1 -strftime 1 /tmp/snapshot/%Y%m%d%H%M%S.jpg
在命令运行的过程中,Python 程序当前进程会等待视频流推送结束,因此我们需要修改函数代码,启动一个新的扫描进程。扫描进程不断检查图片目录,一旦发现有新的图片生成,就将图片上传到 OSS,同时将截帧信息发送 到 Kafka,最后将图片从图片目录中删除。
import logging, json, oss2, subprocessfrom multiprocessing import Processfrom kafka import KafkaProducerHELLO_WORLD = b'Snapshot OK!\n'OSS_BUCKET_NAME = b'snapshot'logger = logging.getLogger()output_dir = '/tmp/shapshot'# 扫描图片目录def scan(bucket, producer): flag = 1 while flag: for filename in os.listdir(output_dir): if filename == 'over': # ffmpeg命令完成,准备停止扫描 flag = 0 continue logger.info("found image: %s", snapshotFile) try: full_path = os.path.join(output_dir, filename) # 上传到OSS bucket.put_object_from_file("snapshot/" + filename, full_path) # 发送到Kafka producer.send('snapshot', filename.encode('utf-8')) # 删除图片 os.remove(full_path) except Exception as e: logger.error("got exception: %s for %s", e.message, filename) time.sleep(1)def handler(environ, start_response): logger = logging.getLogger() context = environ['fc.context'] #创建图片输出文件夹 if not os.path.exists(output_dir): os.mkdir(output_dir) #解析HTTP请求,获得直播流的地址 request_uri = environ['fc.request_uri'] for k, v in environ.items(): if k.startswith('HTTP_'): pass try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 rtmp_url = request_body.decode("UTF-8") #启动Kafka Producer producer = KafkaProducer(bootstrap_servers='XX.XX.XX.XX:9092,XX.XX.XX.XX:9092') #启动OSS Bucket creds = context.credentials auth = oss2.StsAuth(creds.access_key_id, creds.access_key_secret, creds.security_token) bucket = oss2.Bucket(auth, 'http://oss-{}-internal.aliyuncs.com'.format(context.region), OSS_BUCKET_NAME) #启动扫描进程 scan_process = Process(target=scan, args=(bucket, producer)) #通过FFmpeg命令按每秒1帧的频繁连续截帧 cmd = ["/code/ffmpeg", "-y", "-i", rtmp_url, "-f", "image2", "-r", "1", "-strftime", "1", os.path.join(output_dir, "%Y%m%d%H%M%S.jpg")] try: subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True) except subprocess.CalledProcessError as exc: err_ret = {'returncode': exc.returncode, 'cmd': exc.cmd, 'output': exc.output.decode(),'stderr': exc.stderr.decode()} logger.error(json.dumps(err_ret)) raise Exception(context.request_id + ' transcode failure') #写入标志文件,子进程结束工作 os.system("touch %s" % os.path.join(output_dir, 'over')) scan_process.join() producer.close() status = '200 OK' response_headers = [('Content-type', 'text/plain')] start_response(status, response_headers) return [HELLO_WORLD]为了让 FFmpeg 命令执行完成后子进程正常退出,我们向图片目录写入一个标志文件,代码视频流正常结束,不会再有新的图片生成,因此子进程可以中止循环。这样我们就可以在视频流开始的时候,触发一个新的函数执行,随着视频流的持续播放,函数会不断的将截帧生成的图片上传到 OSS,当视频流结束的时候,函数的生命周期也就结束了。
进一步优化
长视频截帧
函数计算 FC 默认的弹性实例 600 秒,也就是 10 分钟的函数执行时长上限,也就是说,一个函数在触发后,如果运行了 10 分钟还没有完成计算任务,会自动退出。这个限制会影响播放时间大于 10 分钟以上的视频流截帧操作,长视频是非常普遍的,如何绕过这个限制对长视频进行截帧处理呢?我们可以通过如下三种方案解决:
每个函数只截 1 帧:当截帧频率比较低,或者只需要在某几个特定的时间点对视频流进行截帧的时候,我们不需要让函数的生命周期与视频流的播放周期保持一致,可以让每一个函数在启动后,只截取单帧图片。通过自定义的触发程序,可以在必要的时间点启动函数,也可以通过 Serverless 工作流来对函数进行更复杂的编排,更多关于 Serverless 工作流的介绍可以参考 https://www.aliyun.com/product/fnf。
通过多个函数接力完成:函数计算 FC 内置了 fc2 模块,可以用于函数之间的相互调用。这样我们可以控制每个截帧函数的运行时间控制在 10 分钟之内,比如 8 分钟为固定的运行周期。在一个函数结束前,启动另一个函数接力完成截帧任务,直到视频流结束。这种方案非常适合对于截帧频率的精确度要求不是特别高的场景,因为在两个函数进行任务交接的时候,会有一秒左右的时间无法严格保证截帧频率的精确度。
使用性能实例:除了默认的弹性实例以外,函数计算 FC 还提供了性能实例,性能实力属于大规格实例,资源上限更高,适配场景更多,能够突破 10 分钟的执行时长上限。性能实例扩容速度较慢,弹性伸缩能力不及弹性实例,但我们可以通过单实例多并发(https://help.aliyun.com/document_detail/144586.html)和预留模式(https://help.aliyun.com/document_detail/138103.html)的配合,来提升性能实例的弹性能力。具体介绍可以参考单实例多并发和预留模式。
费用优化
函数计算提供了丰富的计量模式、有竞争力的定价,以及详细的资源使用指标,结合 Serverless 以应用为中心的架构,让资源管理前所未有的便捷,在不同场景下都能获得极具竞争力的成本。
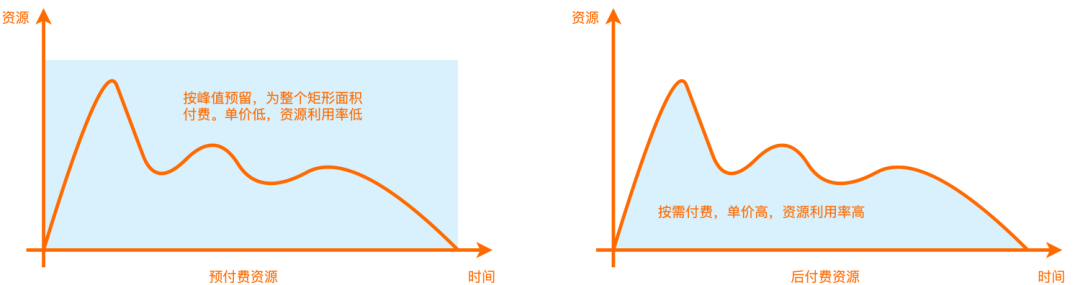
根据对资源的规格和弹性要求的差异,函数计算提供了预付费(包年包月)和后付费(按量付费)两种计量模式。在常规情况下,只需要使用按量付费模式,只需为实际使用的函数计算资源付费,不需要提前购买资源。但用户可以根据每天实际的资源使用情况,灵活选择预付费模式节省使用成本。预付费模式是指用户预先购买一定时长的计算力,在预购计算力的生命周期内,可以逐秒抵扣函数运行时所消耗的资源,而预付费模式的单价是永小于后付费模式的。
在函数计算控制台的资源中心页面,能够一目了然地看到当前账户下的资源实际使用情况,包括资源使用中稳定和弹性的部分,通过这些信息,能够合理分配的预付费和后付费资源。在资源使用详情图中,绿色曲线为每天的实际资源使用量,黄色直线代表其中可以被预付费资源抵扣的使用量,我们可以根据实际情况适当的提升预付资源的占比,使更多的资源使用量被预付费资源覆盖,从而降低整理的资源费用。
总结
在视频截帧场景中,Serverless 技术的价值是非常明显的,函数计算创新的实例调度引擎,将云计算在效率、性能、成本、开放性等方面的优势发挥到了极致。
截至 2021 年 2 月,已经有超过 5 家大型互联网企业开始基于函数计算 FC 实现视频截帧,在不同的截帧需求下,能比传统基于 ECS 部署服务的方式至少节省 20% 的使用成本,而且能够大幅度降低系统维护的工作量。而在迁移和改造方面,他们最多通过一周时间就能完成预研、开发、调试、测试、上线等所有流程,开始享受云计算时代 Serverless 技术带来的巨大红利。
在音视频处理领域,基于函数计算 FC 的 Serverless 技术架构还有更多丰富的应用场景,大家可以加入钉钉群 5712134,一起交流 Serverless 实战经验,在云原生时代探索更多 Serverless 应用实践。
本文转载自:阿里巴巴中间件(ID:Aliware_2018)




