
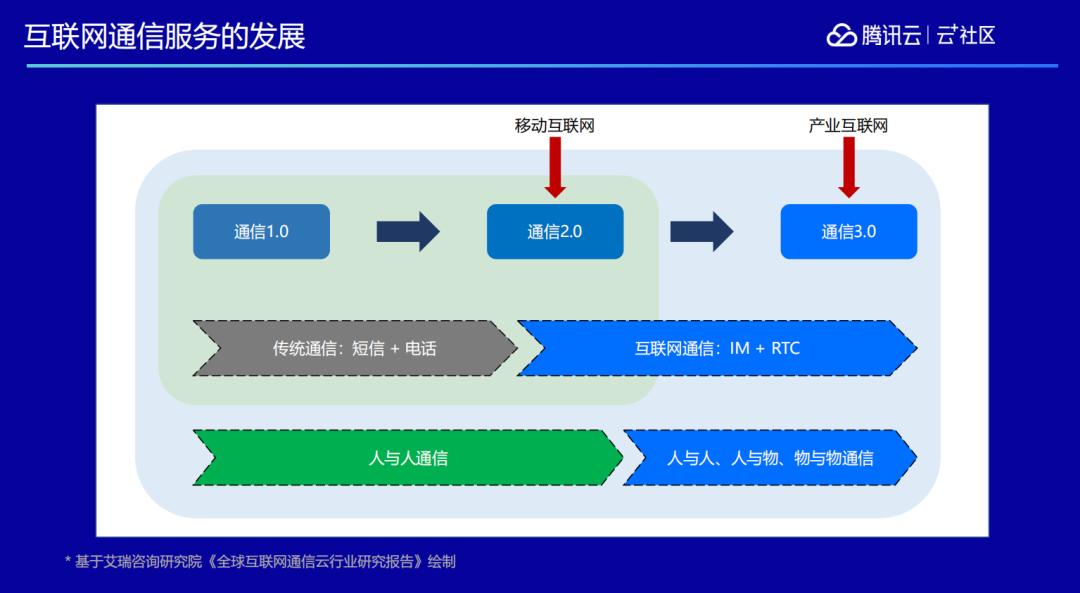
一、互联网通信服务的发展
纵观整个互联网通信发展史,最开始是传统通信,主要借助邮件、短信、电话、传真等方式进行通信。到了移动互联网时代,利用 IM 技术我们在手机上做到了更丰富的通信能力,诞生了 QQ、微信等一堆工具。再往后面发展就到了通信 3.0 时代,也即产业互联网时代。此阶段要打通的不仅仅是人跟人之间的通信,而是人跟物,人跟服务,服务跟人之间的全部联结,达到万物互联的状态。而基于万物互联的通信能力,就需要通过 IM+RTC 的能力来实现。
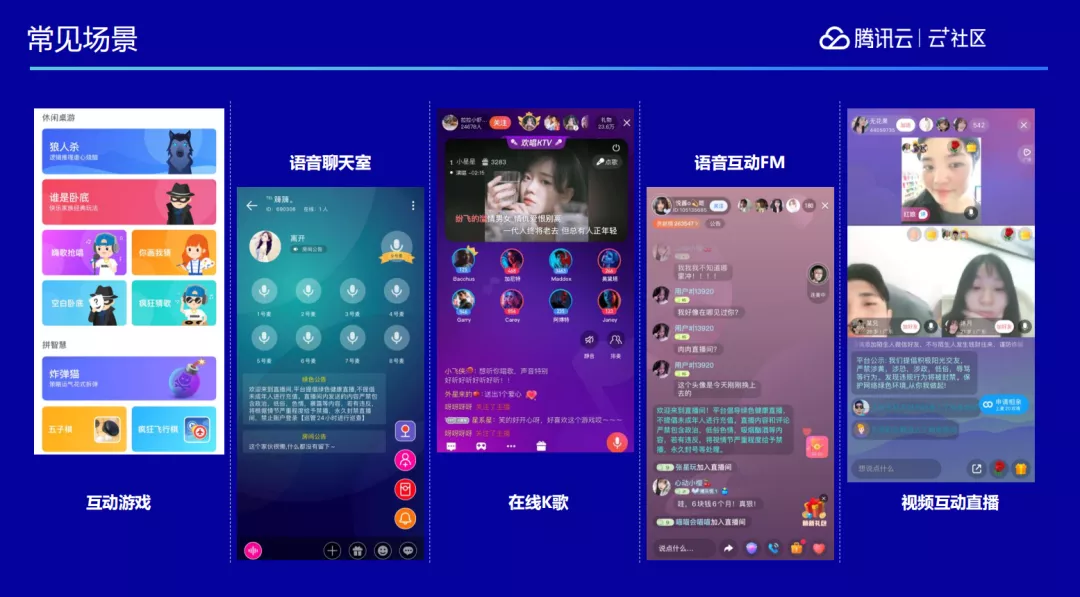
比较常见的场景包括在线会议、视频客服、在线教育等,另外还有一些娱乐场景,比如桌游直播、在线 K 歌、在线语音聊天室、音频 FM 电台、视频直播等,这些场景都是大家平时可能接触比较多的跟音视频通信相关的场景。除此以外,我们还实现了很多其他的能力和场景。

二、腾讯实时音视频 TRTC
1. TRTC 能力介绍
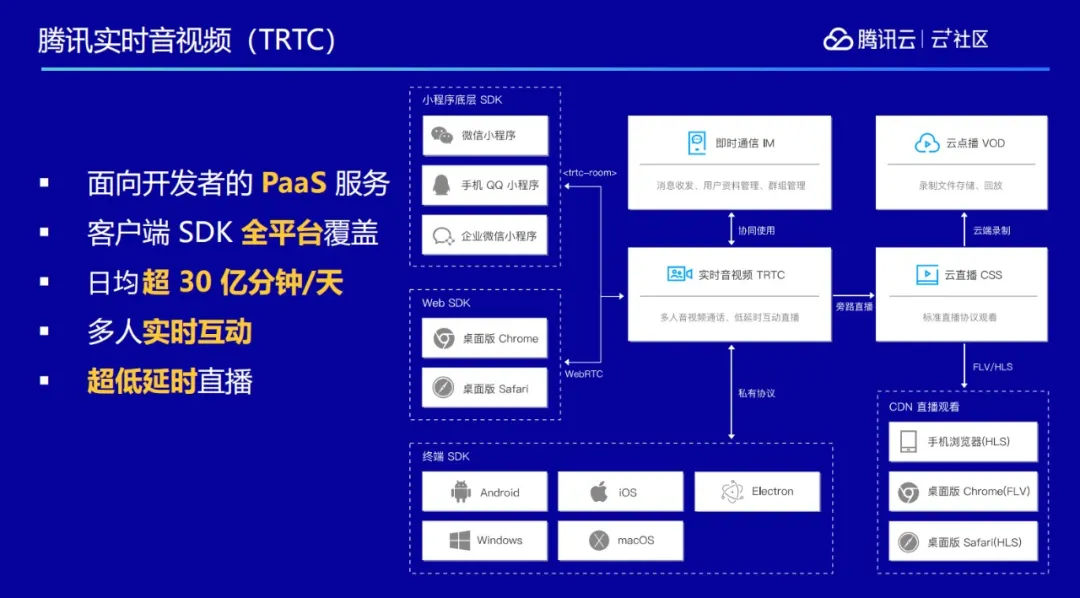
腾讯实时音视频 TRTC 是在腾讯云官网上对外售卖的面向开发者的 PaaS 服务,主要是提供音视频的通信能力。同时我们提供覆盖全平台的客户端 SDK,不管是手机、桌面或者是网页、小程序,都拥有对应的解决方案。
今年由于疫情原因,在线教育和远程办公得到了迅猛发展,我们的服务达到了日均 30 亿分钟/天的规模,是全球目前运营规模最大的 RTC 服务之一。
主要提供以下两种场景,第一种场景是多人实时互动,典型的代表就是腾讯会议。腾讯会议是基于 TRTC 做的,我们针对多人互动进行了深度优化,现在可以做到全球端到端延时在 300 毫秒以内。丢包率达 40%的时候也可以正常进行视频通话(70%丢包率下仍能保持通话能力),单房间可以做到 300 人同时在线,最多支持 30 个人同时说话。

在线教育运用也比较多,比如好未来教育、高思教育等,在疫情期间他们的线下业务完全没办法开展,所以只能把线下课堂搬往线上,在这个过程中就需要有非常可靠的音视频能力来保障。
另一个场景是超低延时直播。我们平常看到的很多直播,它们的延时通常是在 3-5 秒,尤其是用手机 H5 来观看的话,延时可能会达到几十秒,我们通过对 TRTC 的技术架构做优化,把全平台的延时做到一秒以内,并支持大规模的并发。

这个场景目前在腾讯内部的多个产品都可以体验到,比如腾讯课堂、企业微信,微信群直播功能,其中就运用到了 TRTC 的低延时直播能力,最近火热的微信视频号直播,也都是使用 TRTC 来做的。
2. 如何做到实时?
在互联网想要做到端到端延时在 300~1000 毫秒以下的实时体验,是有很多的技术难题需要攻克的。正常直播的延时例如虎牙、斗鱼、B 站那样,通常延时在三到五秒以上,实时互动能力比较欠缺。另一个典型场景如微信通话,因为走的是 UDP,所以延时非常低,双向延时能控制在 500 毫秒以内,能够带给通话双方良好的互动反馈体验。
为什么大家觉得面对面说话的感受,会比通过互联网打电话的感受更好呢?原因很简单,因为当面对面的时候,大家的交流是即时的,说出一句话那边可以马上得到反应。而如果切换到网络上,因为各种原因延时总会存在,如果延时大于 500 毫秒左右,就能明显感觉到对方的反馈会慢上一些,从而带来不好的实时体验。
为了解决这样的问题,我们首先要了解一点:在实际的互联网场景里,网络肯定是有损的。理想的情况是网络发多少包过去对方都能收到,不会丢一个包,带宽无限大,延时无限低。而现实的情况是或多或少总会有丢包,网络延时也不确定,有时快有时慢,网络带宽也不确定,我这边是 100Mbps 的高带宽,而对方却可能只有 300kbps。
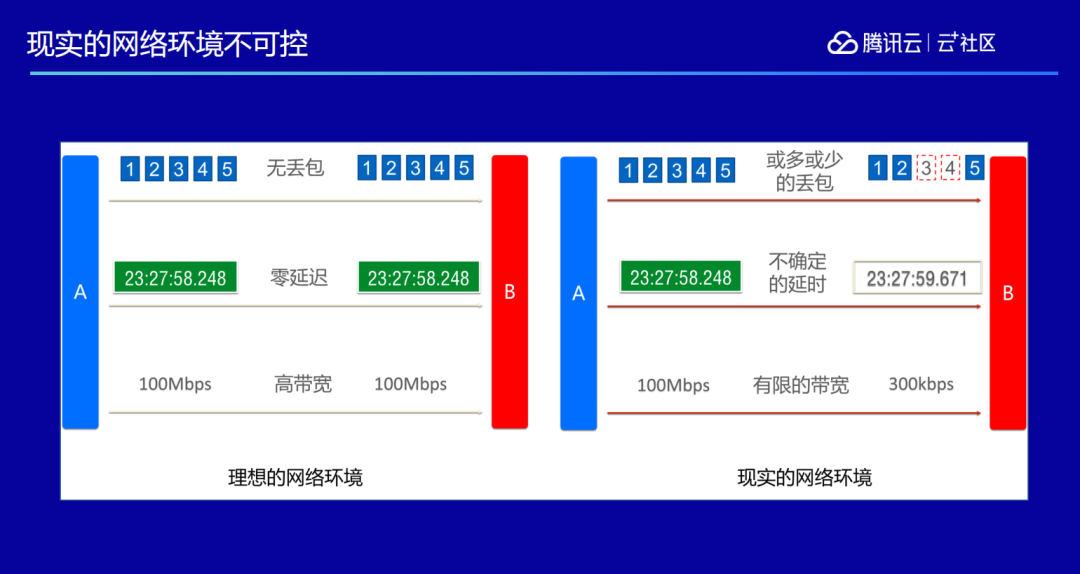
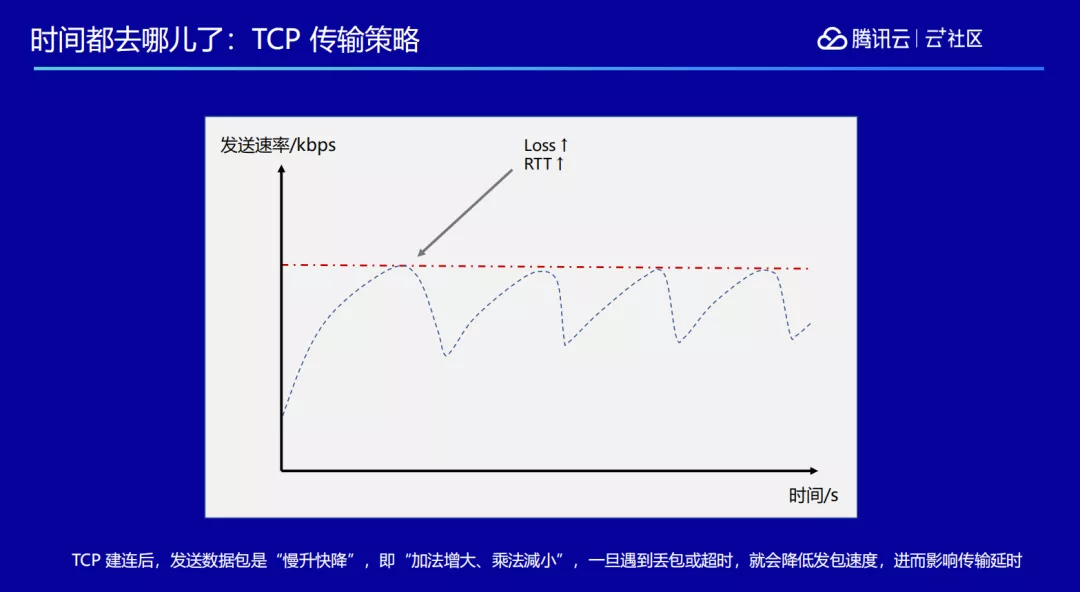
这种情况下如果用 TCP 来做会面临很多的问题,TCP 传输策略会导致在传输的过程当中,如果遇到抖动传输就会变得很慢,导致发包速度降低,数据发送变慢,延时就会拉大。
另外 TCP 的缓冲机制,在拿到数据包之后不是马上发出去,而是设置一个缓冲,因为网络抖动,有了缓冲就可以更好的抵抗抖动,但也因为有了缓冲,意味着所有的数据要等到缓冲满了后才能发出去,这个过程也会产生延时。
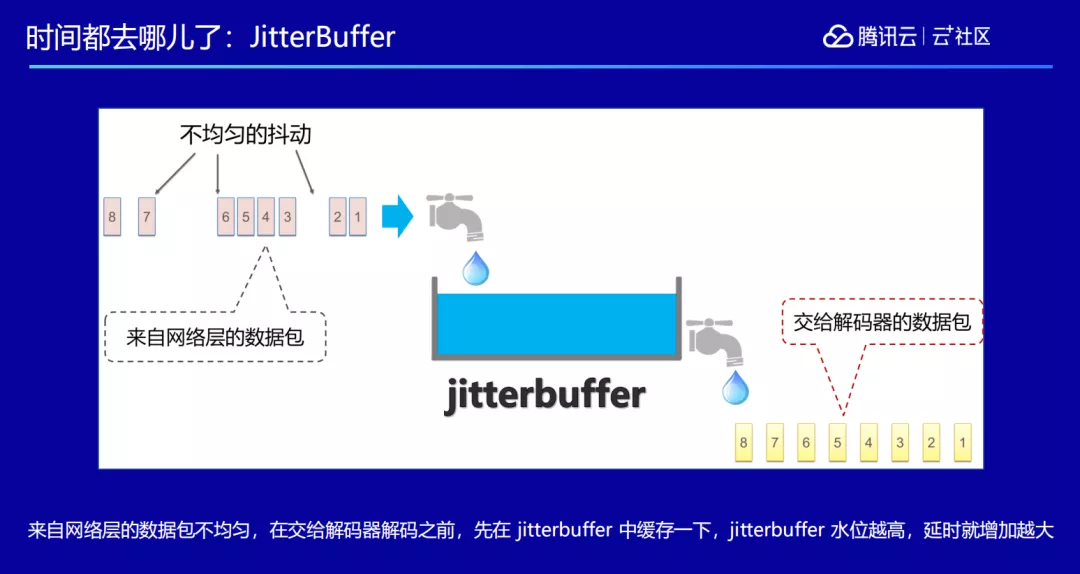
而且在播放器端,通常为了抵抗来自网络的抖动,视频帧在交给解码器解码之前,我们会设置一个区域叫 Jitter Buffer。Jitter Buffer 的作用类似于一个小水库,当我们收到了一些数据,会放在里面缓冲一下,比如拿到了对方的一帧画面,不会马上渲染出来,可能等到两帧之后再去渲染前面一帧,这样做会加强观感的流畅性,但也因为等了一两帧,增加了一些延时。
为了减少延时,在丢包的时候需要尽量减少重传,重传一次就意味着要再发一次包,延时也会增大。TCP 采用的是 ACK 机制,比如我发了 5 个包过去,其中丢失了第三个包,那么对方会告诉我:他收到了第一个和第二个,请接着把三、四、五发过来。用这样的方式可以保证每次发包对方都能收到,保证了可靠性,但是缺点就是需要不停地做确认,往返时间变得很大。
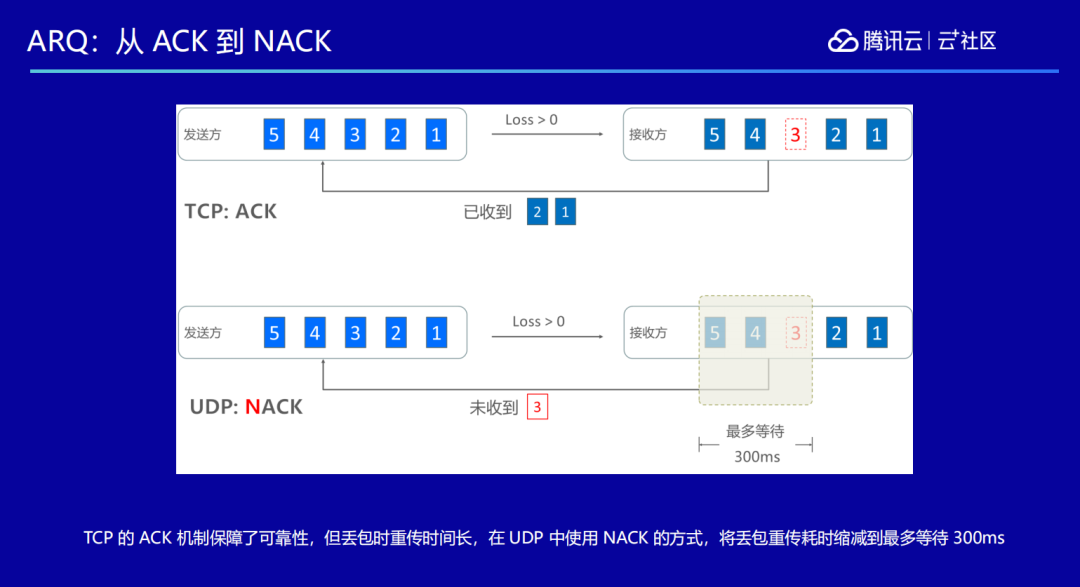
而 TRTC 使用的是 UDP 传输,采用的方式是 NACK,比如我发 5 个包过去,其中丢了第 3 个,对方就会告诉我哪个丢了,后面发包的时候,再把第 3 个发过去,通过这样的方式我们把延时控制在几百毫秒以内。
我们还通过 FEC 技术来优化网络抗性,比如本来要发 10 个包过去,为了防止中间有丢包,发的时候可能发 11 或 12 个包过去,多出来的这几个包就是做冗余数据校验的。对方收到这些包之后,如果发现中间有丢包,可以通过校验数据把丢失的数据恢复出来,避免了因网络丢包而重传的次数,从而降低延时。但是 FEC 是采用多发包的方式,所以相当于是占用更多的带宽来换取延时的降低。
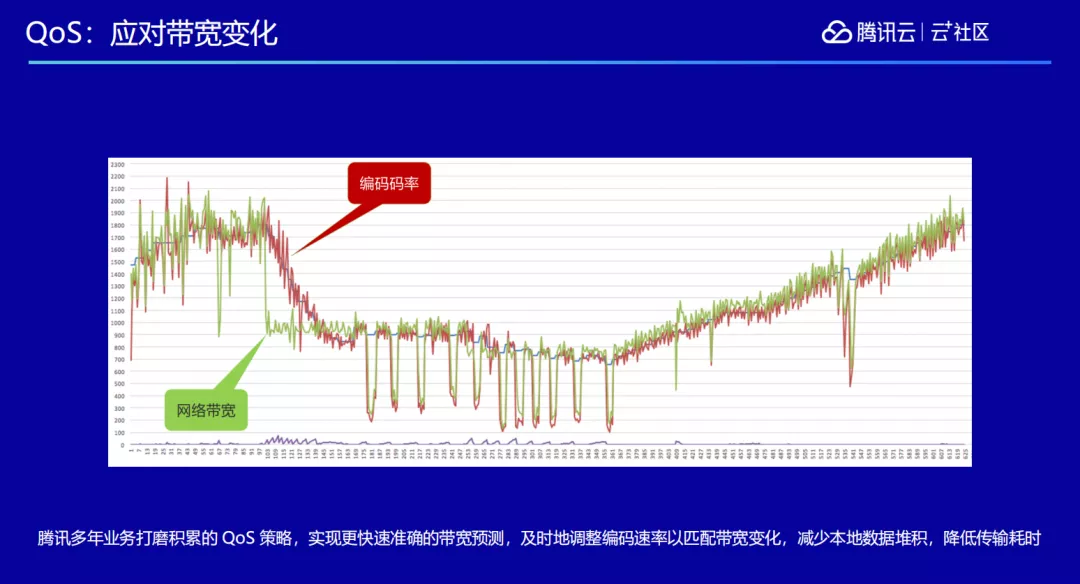
不管使用的是 FEC,还是 ARQ 的策略,如果只是单纯使用一种的话,达到的效果也是有限的,我们通常还会结合 QoS 实现更快速准确的带宽预测,及时地调整编码速率以匹配带宽变化,降低传输耗时。QoS 越准确,就可以越精确地调整发包的数量,包括要不要补发,要不要发更多的冗余包等,综合运用 QoS、FEC 和 ARQ,一般能抵挡一定的网络丢包。
为了抵抗网络抖动引起的视频损伤,我们修改了编解码器。在标准的 H264 编码里面,每一个画面都会有一个 I 帧作为开始,后面的帧依靠前面一帧作为参考,在解码的时候先拿到 I 帧,再依次把后面的帧一帧帧的解码出来,还原视频画面。但是这会带来一个问题,因为是严格依赖于前一帧,当发生网络丢包的时候,即使只丢了一帧,在解码的时候由于缺失了那一帧的数据,失去了参照关系就解不出来,对于用户来说就是卡在了那边。
对此,我们修改了参考关系,不是严格依赖于前一帧,而是可以选择性的去依赖前面某一帧。这样做带来了什么好处呢?只要控制好了依赖的顺序,就能保证在网络出现丢包的时候,即使缺失了一两帧的数据,也可以完完整整的把画面显示出来,让用户看上去不卡顿。
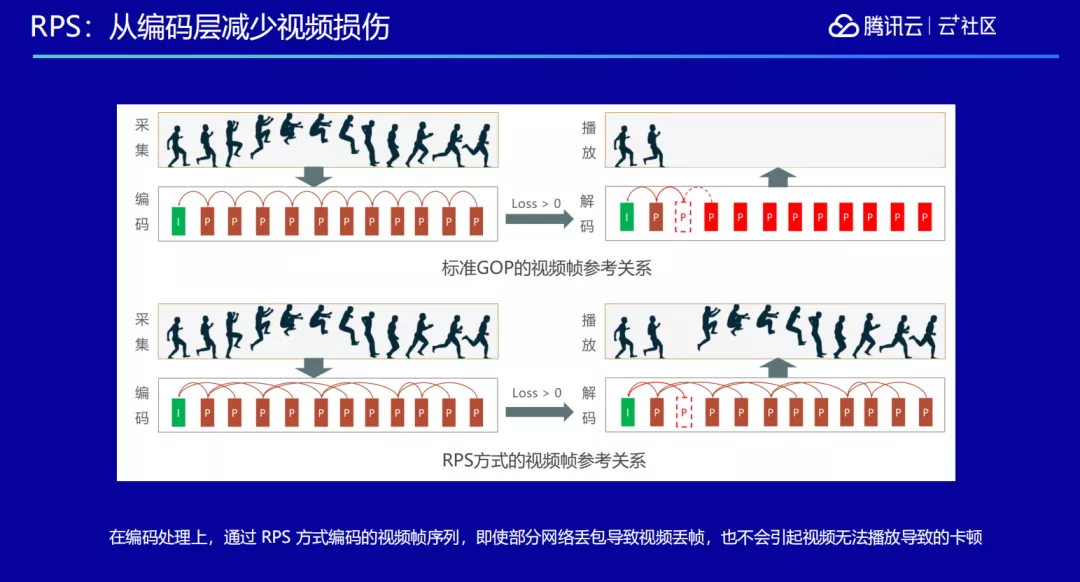
音频的敏感程度比视频更高,视频即使丢了一帧两帧,延迟一两帧人也可以脑补回来,而音频丢包哪怕很少,人也会明显感觉卡顿。音频丢包的补偿采用的方式是 PLC,我们对采集到的音频以 20 毫秒作为一帧,在编解码器里对音频的帧做一些状态保存,叫做 PLC unit,当我们发现这个 PLC unit 里有帧丢失的时候,就会通过其它关联的 PLC unit 来计算出这里丢掉的帧的声音数据是怎样的。
为什么可以这样做呢?人说话的时候,他的语音是存在一定的关联性,前面说的一句话跟后面说的一句话,在音频的音调和频率上有一定的关联性,所以可以通过前后的算法依赖去重建丢失帧的声音信息。

原理虽然简单,但是实际上算法实现的时候,需要考虑的因素是非常多的,通过 PLC 技术,可以在 70%的丢包情况下还能保持语音的通畅。
3. 深度优化
除了上述的技术应用,我们还做了一些深入的优化,第一个就是关于音画同步。因为网络会有抖动,收到音频或者视频的速度有快有慢,在得到音频数据之后,我们会先做一次抖动评估,评估出当前抖动的剧烈程度,由此评估出视频比音频究竟是来快了还是来慢了。通过这个再进行变速调节,变速调节是用来调节音频,把音频的速度拨快或拨慢一点,最终找到平衡点。音频按照平衡点的这个速度来播放,视频的帧就能和音频对齐,从而保证每一个接收端看到的画面和听到的声音可以同步播放出来的。
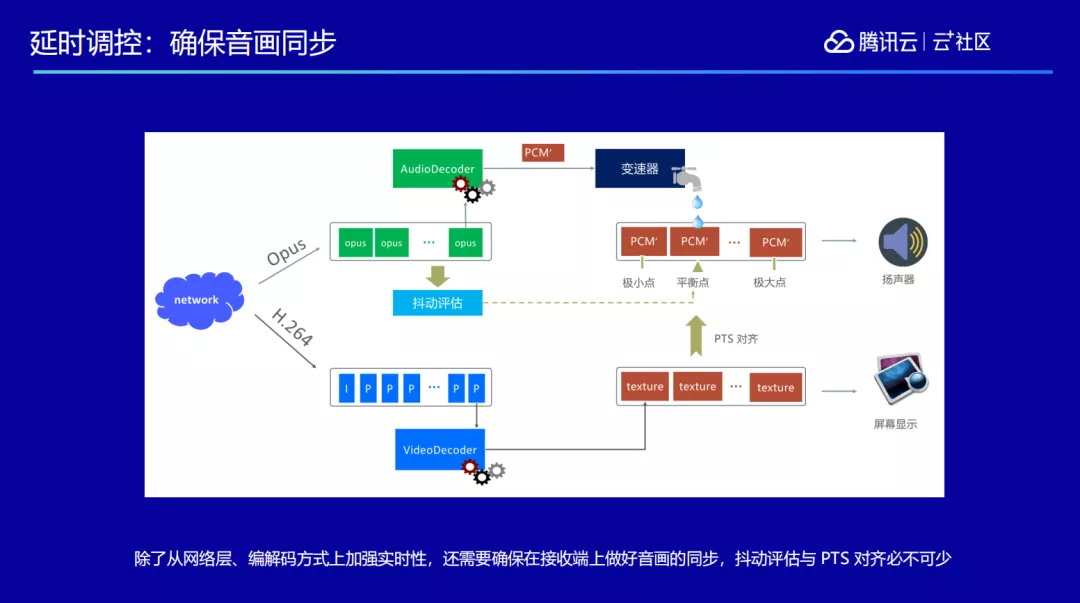
另外还要注意“回声”现象,大家如果平时注意一下手机,就会发现扬声器和麦克风一般安装在手机底部左右两边,这样就会导致:对方声音播放出来的时候,会被自己本地的麦克风再采集一遍,如果不做任何处理对方就会听到这边采集到的他说出的话,也就是自己的回声。
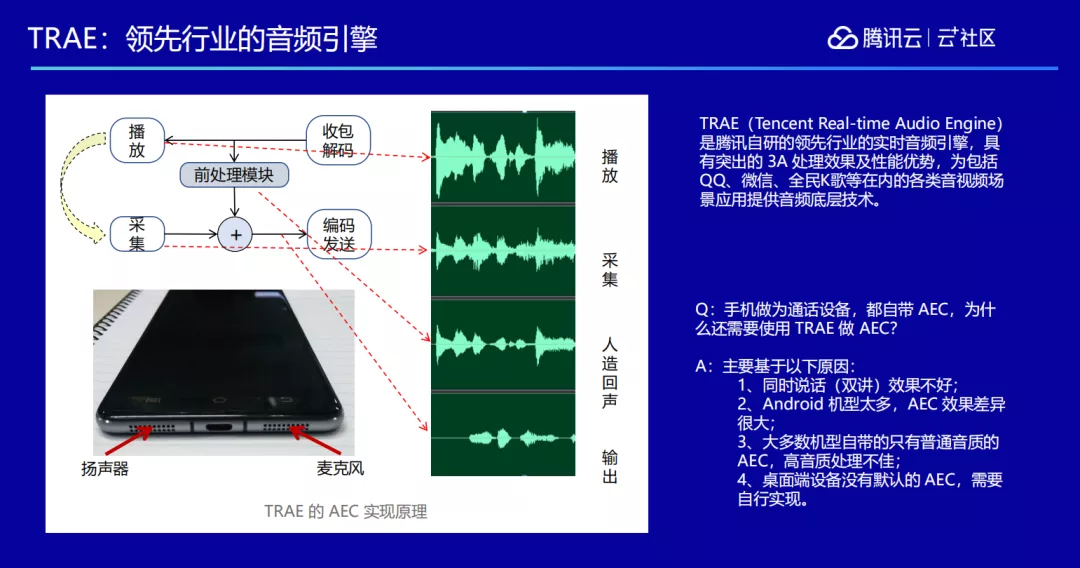
因此在这个过程中我们运用腾讯自研的领先行业的实时音频引擎—TRAE(Tencent Real-time Audio Engine)的能力来做一些 3A 处理,比如回声处理,也叫做 AEC。将拿到的对方声音跟本地采集到的声音做比对,在本地采集到的声音里把对方要播的声音反向消除掉,这样对方就不会听到自己的回声了。
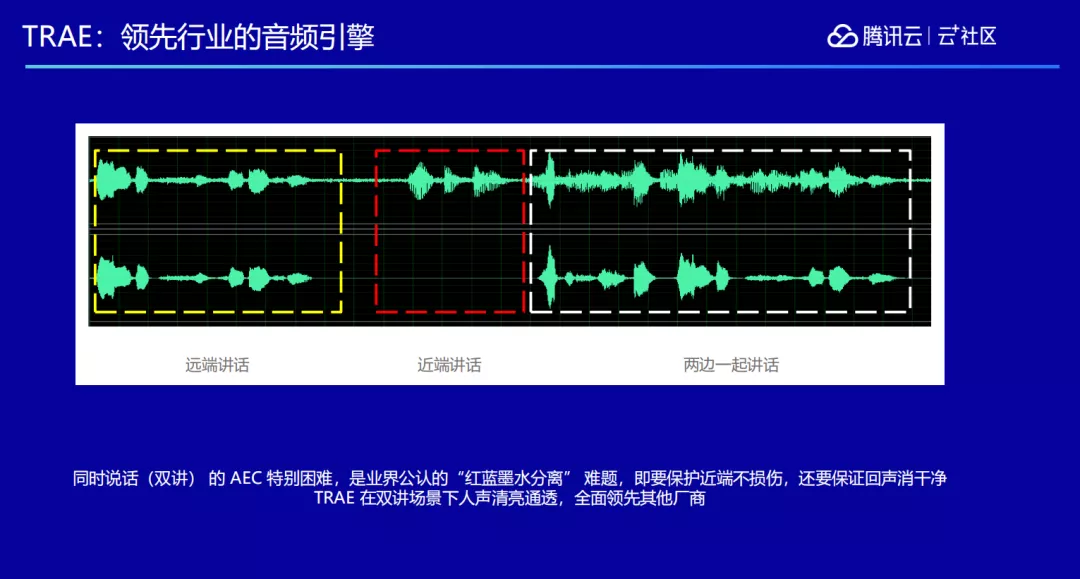
AEC 还有更复杂的场景——双讲场景。当两边一起说话的时候,双方都听不清楚对方在说什么,这种情况就叫双讲。在双讲场景下,这边说话的声音从那边播出来,那边再把这边声音采集一遍传回来,这边又会采集一遍再传回去......两边声音来回采集,最后双方都听不清楚对方说什么。
行业把这个问题形象的称之为“红蓝墨水分离”,红蓝墨水混合在一起,如何把各自的墨水再单独抽取出来?双讲问题是业界公认的难题,而腾讯在通信领域钻研多年,通过自己的算法解决了这一难题,TRAE 既能保护近端不受损伤,还能保证回声消除干净,让双讲场景下的人声清亮通透。
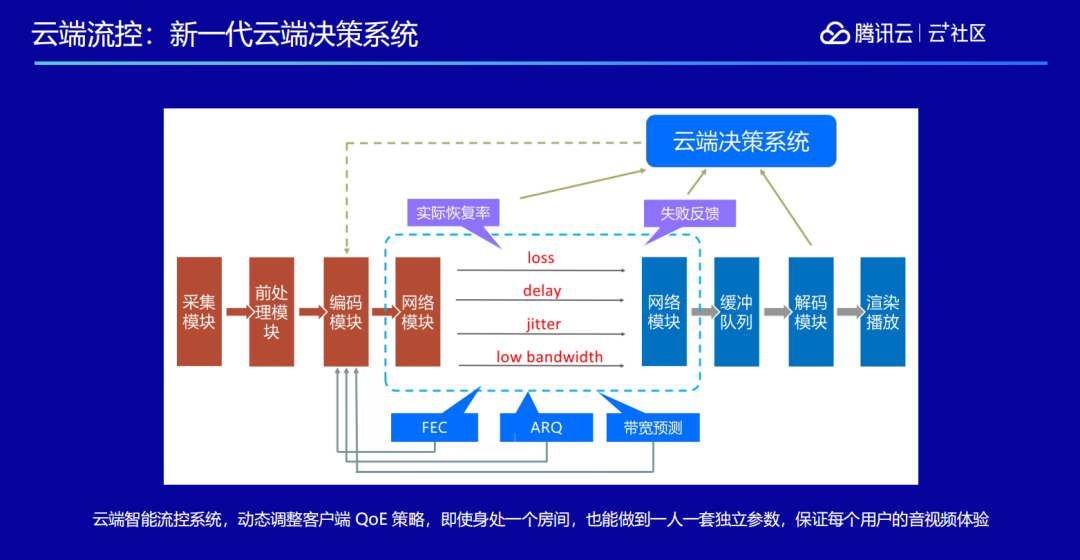
此外我们还做了一套云端决策系统。我们整个音视频的体验系统叫做 QoE,除了做 FEC、ARQ、QoS 以外,我们还需要评估用户的个人感受。因为如果完全从技术上来描述,也许一次通话已经没有丢包情况,但是视频播放的实际情况,用户看到的、听到的却并不一定能带给他自然真实的感受,所以还需要一套大数据系统,来监测线上各个环境下用户的使用体验。
我们需要打造一套提分系统,来评价线上的直播和通话质量,这样的一套东西我们称之为云端决策系统。云端决策系统通过客户端上报各项质量指标,动态地去调节每一端的参数,它能够做到哪怕大家都处在同一个房间里面,每一个人也都可以有一套不同的参数,也就是说能保证每一个端都有自己的独立参数,保证端上最好的效果。
4. 更多能力
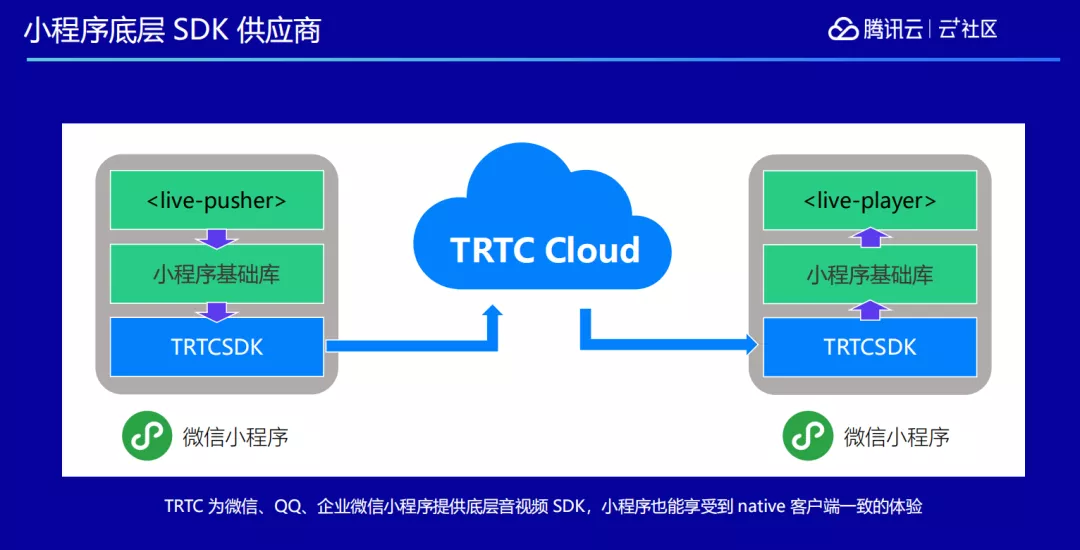
我们还做了一些其它的能力,比如跟微信小程序团队合作,为微信、QQ、企业微信小程序提供底层音视频能力的 SDK,并在小程序上对外开放。对外封装主要分为两个标签,一个叫
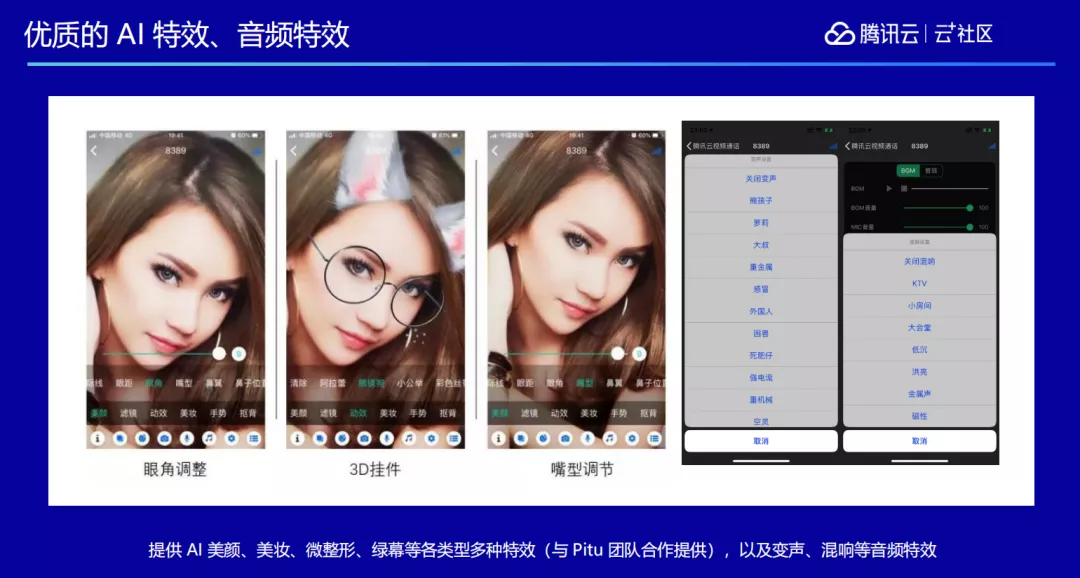
我们还跟腾讯优图实验室进行合作,比如现在无论是做直播还是普通的会议和通话,美颜功能运用得很多,于是我们基于优图非常先进的人脸算法能力,加入了人脸的美颜、动效、背景替换、高级美颜等特效。另外还跟腾讯天籁实验室合作,添加了包括变声、混响等许多音频特效。
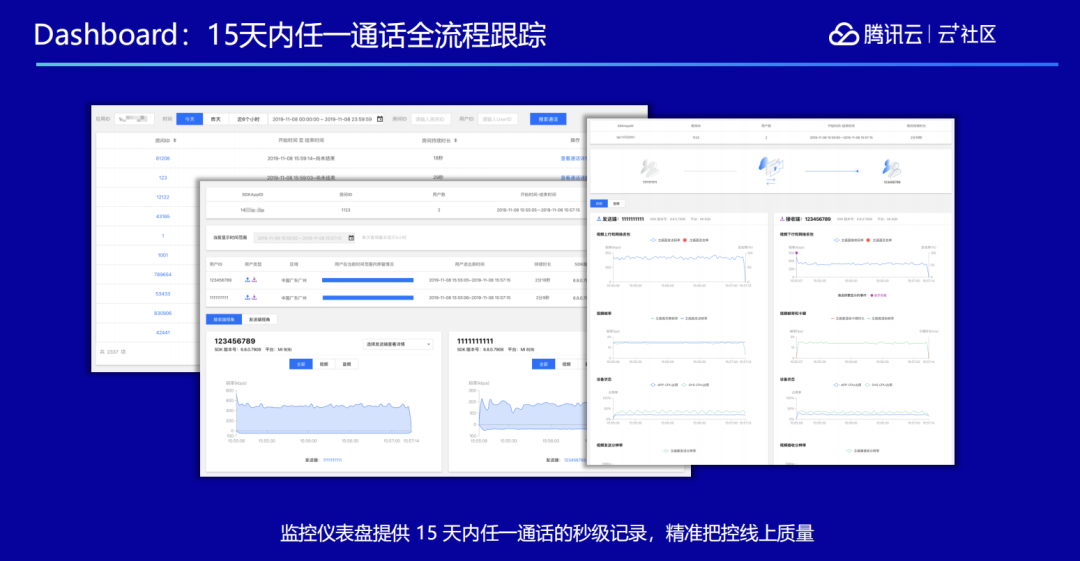
我们还提供一个运维层面的监控仪表盘。因为网络抖动和设备问题,平时通话过程中难免会发生不顺畅的时候,比如有的用户麦克风坏了,有的在高铁上过隧道网络断开,这些情况下我们就需要了解到用户的网络情况或者设备情况到底是怎么样的,因此我们做了一个全链路的仪表盘,可以追踪到 15 天以内用户从端到端的整体链路情况,能够看到这个用户到底因为什么原因遇到了问题。
通过改造 RTC 技术,我们实现了单个房间容纳十万人的低延时直播。传统 RTC 直播一个房间最多容纳几百人,而且投入的成本也比较高,需要采购很多终端,才能搭起几百人的会议。而我们通过改造技术栈,把 RTC 的播放能力从原本的几百方扩大到 10 万人级别,所有的用户都在一个房间里面,而且每一个人说的话对方都能马上清晰听到。
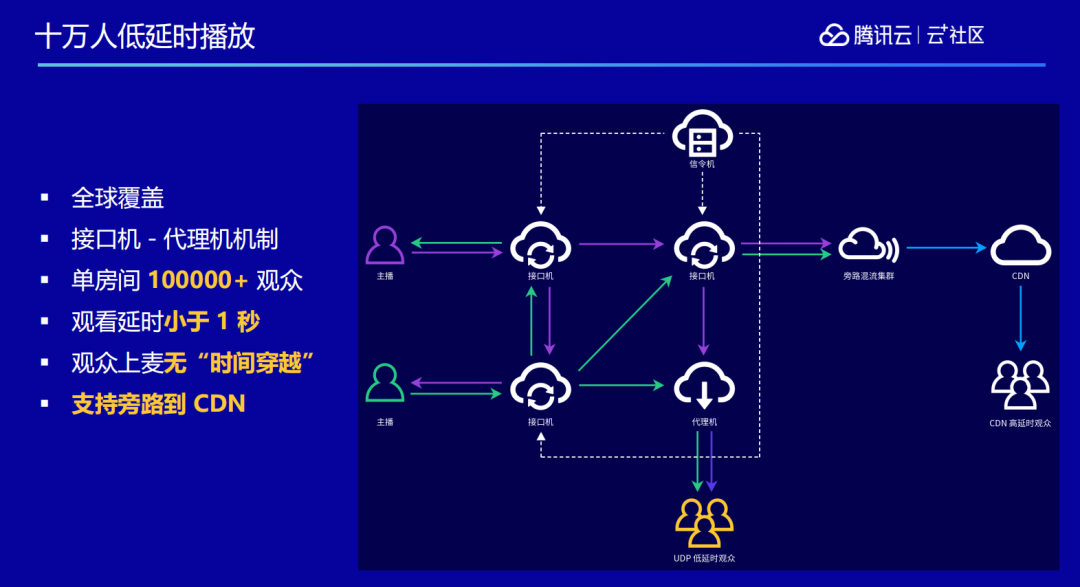
如果还有更大规模的需求,可以旁路转推到 CDN 再去进行更大规模的分发。如下图所示,我们的基础指标列在上面,包括支持 720P、1080P 高清画质,支持 48kHz 立体声高音质语音等等,这些都是我们经过许多年的积累打造出来的音视频能力。

5.客户案例
TRTC 现已上线两年多时间,我们也为各个行业一千多家客户提供了各种各样的解决方案和技术支持,比如跟金融行业合作,在金融的虚拟营业厅里联合央行的科技司起草远程手机银行音视频的标准,跟腾讯云物联网团队合作,在 IoT 物联网云上直接把实时音视频的能力嵌入进去,用户在 IoT 场景里需要使用到实时音视频能力的时候,可以直接在腾讯物联网开发平台 loT Explore 的控制台上选择使用。
我们为腾讯内部多个 BG 80%的业务场景提供了支持,也为各个行业,包括政府民生、社交娱乐、在线教育等等提供能力支持。比如跟华晨宝马合作上线了一个小程序,用户通过小程序可以在线看车,听导购实时介绍每一辆车的特点。另外还有跟贝壳合作上线了 VR 看房功能,让用户可以远程通过 VR 的方式了解每一个样板房的场景,并且在这个过程当中能够跟导购员和经纪人实时沟通,了解房子的状态。
下图所示的是我们写的一个 demo,如果大家想体验 TRTC 的相关能力,可以扫码下面二维码体验,想了解更多信息也可以到腾讯云官网上搜索 TRTC,查阅更多相关介绍。
头图:Unsplash
作者:蒋磊
原文:https://mp.weixin.qq.com/s/bmmCKf2Oqghbfu58uxVuIg
原文:后直播时代的技术弄潮儿——TRTC
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




