
整理 | 华卫
7 月 23 日凌晨,有人爆料,Meta 的新版 Llama 3.1 405 B 在 4chan 上泄露,并在大多数基准测试中击败了 GPT-4o。据爆料人称,Meta 可能会在明天正式发布 Llama 3 系列中最大的参数模型以及 70B 版本。
现在,Github 上泄露的 Llama 3.1 模型链接已 404 ,但据网友保存下来的下载链接显示,文件大约 763.84G。据悉,HugginFace 上的比推特网友爆料更早,但现在库已经被删除。“似乎 HF 的某个人忘记按时将这个存储库私有化,并且 Google 将其编入索引。”

HF 链接: https://huggingface.co/cloud-district/miqu-2
磁链:magnet:?xt=urn:btih:c0e342ae5677582f92c52d8019cc32e1f86f1d83&dn=miqu-2&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80
种子:https://files.catbox.moe/d88djr.torrent
来源:https://boards.4chan.org/g/thread/101514682#p101516633
有网友猜测,此次泄露极有可能来自第三方托管商,该托管商提前获得访问权,来准备发布前的一些工作。不少人认可了泄露模型的真实度,并认为是从微软的 GitHub 流出来的。“它在 GitHub 上线过一段时间后,他们又把它撤下来了,但我已经看到了一些自定义模型。看来有人能及时发现。”
从爆料人发出的评测数据表中可以看到,Llama 3.1 是在 3.0 版本的基础上进行了功能迭代,但即使 70B 模型的性能也在部分领域超过了 GPT-4o。
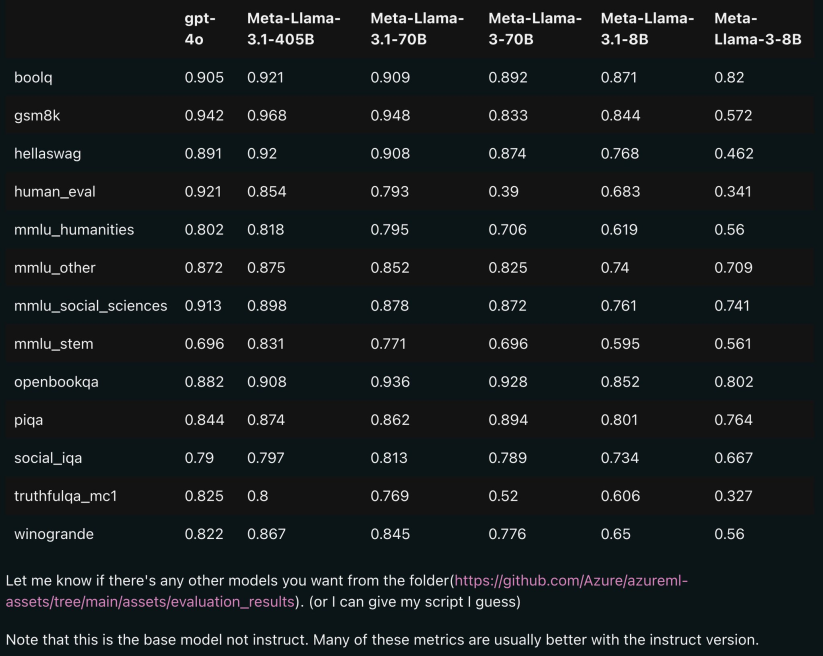
有看好的网友这样说道,“如果这份评测数据是真实的,那么从本周开始,Meta 的最顶级人工智能模型将是供所有人免费使用的开放权重模型。有趣的是,全球每个国家的政府、组织和公司都能和其他人一样获得同一套这样的人工智能能力。”
需要注意的是,尽管 Llama 3.1 开源免费, 但模型本身的使用成本似乎并不低。据悉,由于该模型的参数较大,对 GPU 的要求较高,需要一些强大的硬件才能在本地运行起来,因此并不如 GPT-4o mini 性价比高。
有网友猜测道,“一般的 GPU 肯定是跑不起来,如此大的参数在部署方面个人开发者也负担不起(如果你有一些 H100 也没问题),估计是给企业、政务公共部门用的。”也有网友表示,“虽然 Llama 3.1 是免费使用的,但没有多少人会拥有运行此模型的计算机。只有一些具备高算力基础的大公司能够自己使用它,所以也许它会成为企业的加速器。”
不过,Llama 3.1 的 70B 模型或将更接近免费,因为其支持在消费类硬件上运行。
8B 大幅提升,整体编码性能落后
Meta Llama 3.1 多语言大型语言模型 (LLM) 集合是 8B、70B 和 405B 大小(文本输入/文本输出)的预训练和指令调整生成模型的集合。Llama 3.1 指令调整的纯文本模型(8B、70B、405B)针对多语言对话用例进行了优化,在常见的行业基准测试中优于许多可用的开源和封闭聊天模型。
这是网上曝出的 Llama 3.1 模型卡中所介绍的信息,发布日期是 2024 年 7 月 23 日。此外,该模型卡还报告了 Llama 3.1 模型在标准自动基准测试下的结果。
从评分结果可以看到,405B 看起来很不错,在某些基准测试中达到了 SOTA,与 GPT-4o 和 Sonnet 3.5 不相上下,70B 则在 HumanEval 上出现了奇怪的倒退(HumanEval 是由 OpenAI 编写发布的代码生成评测数据集)。
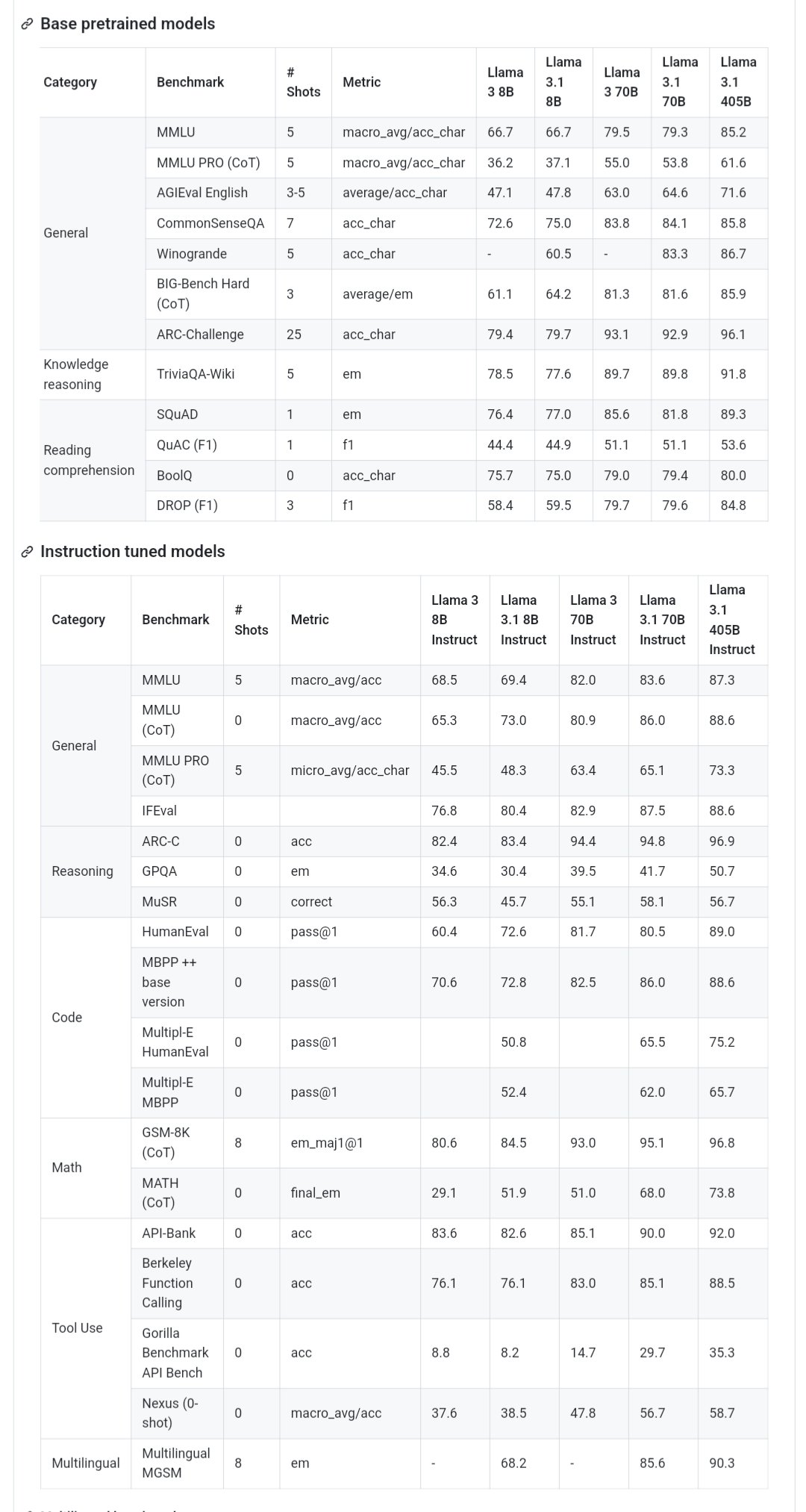
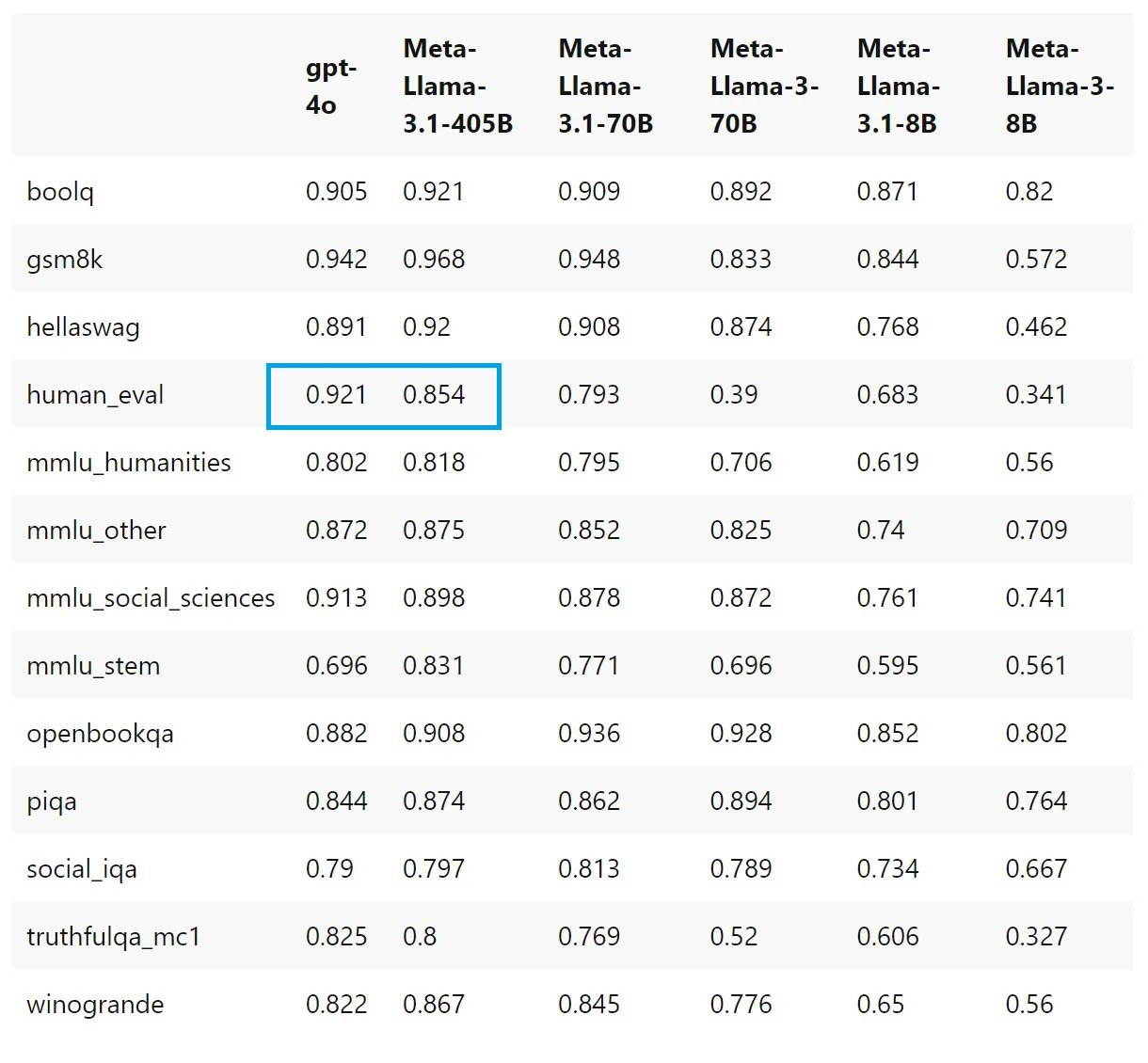
值得一提的是,在爆料人发出的评测数据表中,与 GPT 4o mini 相比, Llama 3.1 70B 似乎可以以 3 倍的成本进行推断,但编码性能也要差得多。此外,Llama 3.1 405 B 似乎也在 HumanEval 方面明显落后于 GPT-4o。
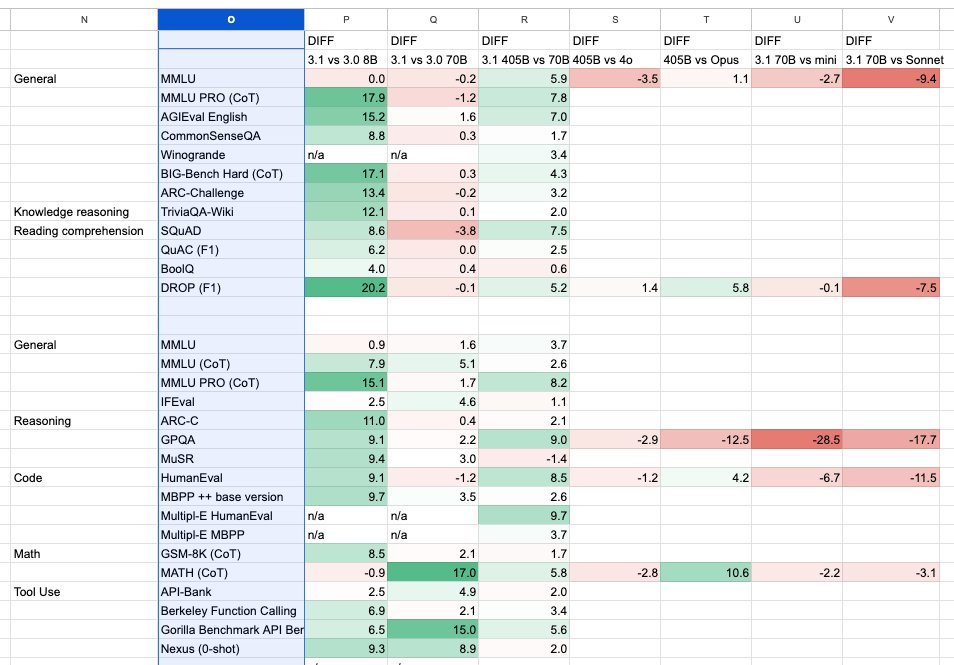
还有人根据现有的模型卡信息,对比了 Llama 3.1 与 3.0 之间的差异,并将其与其他前沿模型进行比较。得出的结果是 Llama 3.1 8B 全面大幅提升,70B 稍好,405B 仍落后于旗舰机型。
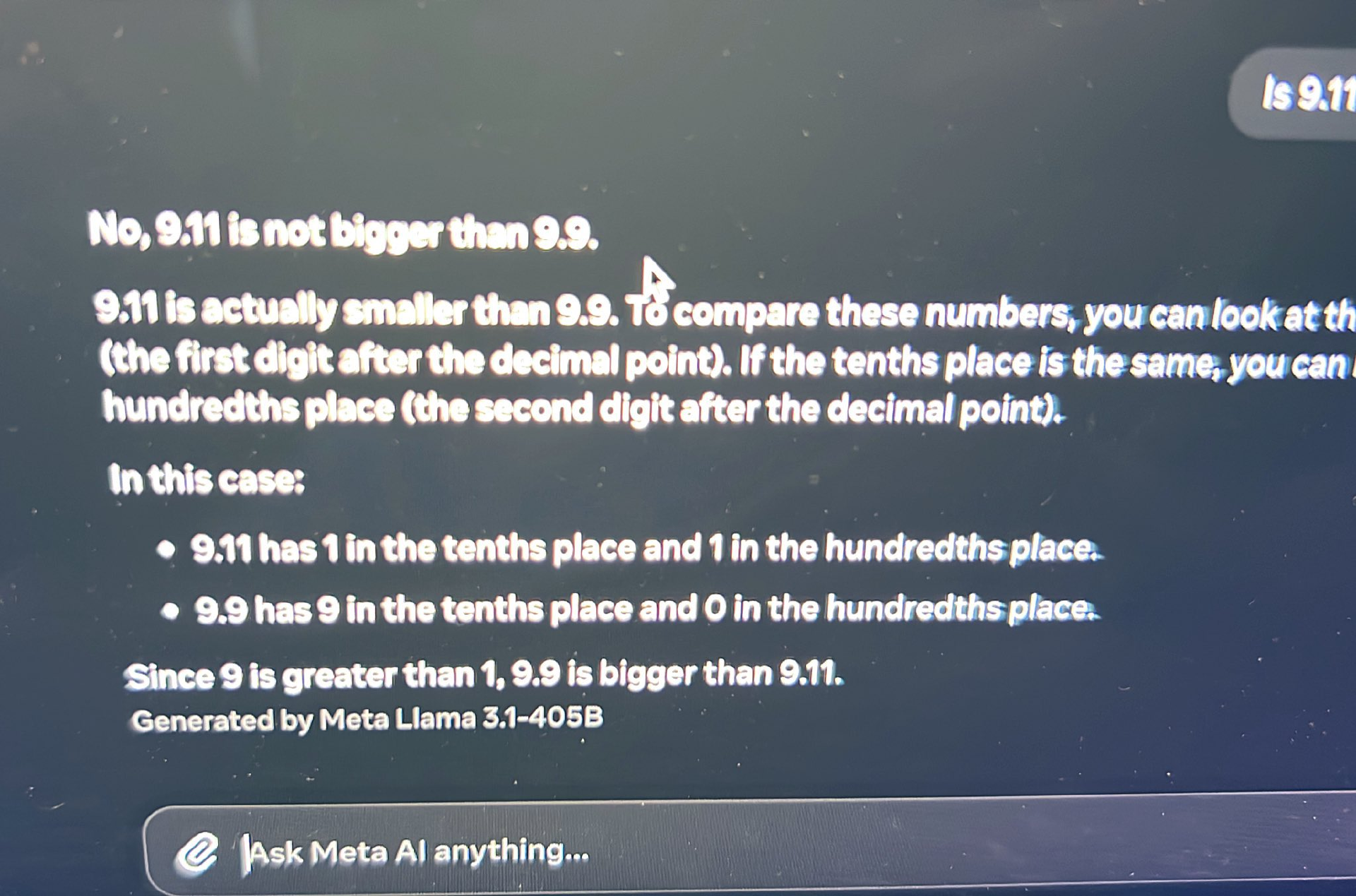
另外,Llama 3.1 的数理能力似乎也提升不少。 7 月 21 日,一位称体验了 Llama 405B 模型的网友表示,其看起来能解决 9.9 > 9.11 的问题。
15 万亿预训练数据,支持 8 种语言
模型卡还透露了许多 Llama 3.1 的技术细节。据称,Llama 3.1 是一个自回归语言模型,它使用优化的 transformer 架构。调整后的版本使用监督微调 (SFT) 和带有人类反馈的强化学习 (RLHF),以符合人类对有用性和安全性的偏好。
在 Llama 3.1 系列中,所有模型版本都使用分组查询注意力 (GQA) 来改进推理可伸缩性。据该模型卡介绍,“这是一个在离线数据集上训练的静态模型。随着我们根据社区反馈提高模型安全性,将发布调整模型的未来版本。”
使用方面,Llama 3.1 支持的语言有英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,但也接受了比 8 种支持的语言更广泛的语言集合的训练。也就是说,开发人员可以针对 8 种支持语言以外的语言对 Llama 3.1 模型进行微调,前提是他们遵守 Llama 3.1 社区许可证和可接受使用政策,并且在这种情况下,他们有责任确保以安全和负责任的方式使用 Llama 3.1。
据介绍, Llama 3.1 旨在以多种语言用于商业和研究用途。指令优化的纯文本模型适用于类似助手的聊天,而预训练模型可以适用于各种自然语言生成任务。Llama 3.1 模型集合还支持利用其模型的输出来改进其他模型的能力,包括合成数据生成和蒸馏。
训练数据方面, Llama 3.1 在来自公开来源的大约 15 万亿个 token 数据上进行了预训练,微调数据包括公开可用的指令数据集以及超过 2500 万个合成生成的示例。其中,预训练数据的截止时间为 2023 年 12 月。

Llama 3.1 使用自定义训练库、Meta 定制的 GPU 集群和生产基础设施进行预训练,还对生产基础设施进行了微调、注释和评估。据悉,其在 H100-80GB(TDP 为 700W)类型硬件上累计使用了 39.3 M GPU 小时的计算时间。同时,Llama 3.1 训练期间基于地域基准的温室气体总排放量预估为 11390 吨二氧化碳当量。
结语
Llama 3.1 的免费开放消息,令不少关注人工智能大模型的用户欢呼,但与此同时也引发了另一些人的担忧。“我们正处于范式转变的风口浪尖,像 Llama 3.1 这样强大的 LLM 的开放获取预示着巨大的潜力和前所未有的风险。这种强大人工智能模型的民主化将重塑社会、经济和治理结构,未来悬而未决。”
此前,由于监管机构和各种法案的原因,Meta 的确也一直在推迟 405B 系列模型的发布。
在 Llama 3.1 的模型卡中,谈到关于使用安全方面的立场和使用建议,“大型语言模型包括 Llama 3.1,不是为孤立部署而设计的,而是应该作为整体 AI 系统的一部分进行部署,并根据需要提供额外的安全护栏。开发人员在构建代理系统时应部署系统保护措施。安全保障措施是实现正确的有用性与安全一致性的关键,也是降低系统固有的安全和安保风险以及模型或系统与外部工具的任何集成的关键。”
为此,Llama 3.1 版本引入了新功能,包括更长的上下文窗口、多语言输入和输出以及开发人员与第三方工具的可能集成。除了通常适用于所有生成式 AI 用例的最佳实践外,使用这些新功能进行构建还需要特定的考虑因素:
工具使用:就像在标准软件开发中一样,开发人员负责将 LLM 与他们选择的工具和服务集成。他们应该为其用例定义明确的策略,并评估他们使用的第三方服务的完整性,以便在使用此功能时了解安全和安保限制。
多语言:Llama 3.1 除英语外还支持 7 种语言, 虽然其能够输出其他语言的文本,但可能不符合安全性和有用性性能阈值。
“Llama 3.1 是一项新技术,与任何新技术一样存在使用风险。迄今为止进行的测试尚未涵盖,也不可能涵盖所有情况。由于这些原因,与所有 LLM 一样,Llama 3.1 的潜在输出无法提前预测,并且该模型在某些情况下可能会对用户提示产生不准确、有偏见或其他令人反感的响应。因此,在部署 Llama 3.1 模型的任何应用程序之前,开发人员应根据其模型的特定应用程序进行安全测试和调整。”Meta 在模型卡中写道。
参考链接:




