
一、问题背景
随着社会的发展、交通方式的高度便利,人口流动的规模越来越庞大,与此同时,人口迁移、人口流向分析等受到高度关注。人口迁移是一种地理现象,更与社会经济发展紧密相连。人口迁移会同时影响迁入地和迁出地的人口结构,进而影响自然环境,推动或抑制社会经济的发展。另一方面,一个地区的经济发展水平,生活环境等因素会推动人口的迁入或迁出。所以,人口迁移空间分布和时空动态演进的相关研究变得越来越重要。对人口迁移因素、迁移空间变动的研究都将为城市建设,经济结构调整等提供政策决策依据。尤其在新冠肺炎疫情这类重大突发公共卫生安全事件发生的时候,进行精确的人口流向分析和追踪意义重大。
本文以抗击新冠肺炎疫情中的应用为例,给出了一套完整的基于轨迹数据对人口流向进行精确分析的技术方案。在疫情防控初期,各地的健康信息填报系统还不够完善,无法依据用户主动上报的位置信息实现精准的定位和追踪。然而,广泛使用的 GPS 定位技术为获取人口的精确位置信息提供了技术基础,车辆的 GPS 数据、用户的手机 GPS 数据等均可反映人口的精确位置信息。如何利用大数据技术从海量的 GPS 轨迹数据中分析人口的流向,进而在病毒传播链的追踪等相关疫情防控举措中提供精准有效的依据是一个紧迫的需求。
二、 问题定义
本文旨在解决这样一个问题:在病毒传播源地区有过到访记录的人群在当前城市的分布情况如何?比如,分析某特定时间段在武汉有过旅居史的人员目前在北京的分布情况。
数据输入:传染源地区和当前城市的用户轨迹数据。如图 1 所示为选定武汉市在特定时间范围内的一个矩形区域作为传染源区域,用于提取该区域在选定时间范围内的轨迹数据。
结果输出:来自传染源的人群在当前城市的分布情况,包括在不同空间网格内的分布和不同时间段内的分布,以及这些人曾经在传染源的具体到访位置和时间。图 2 展示的是在当前城市的特定区域、特定时间范围内,高危人群的分布情况。
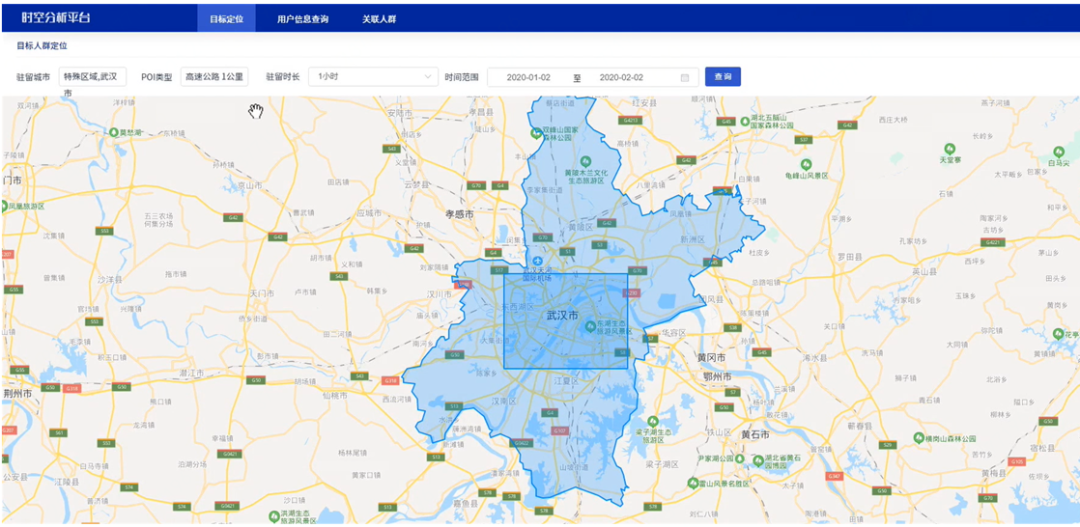
图 1 传染源的时间和空间范围选取
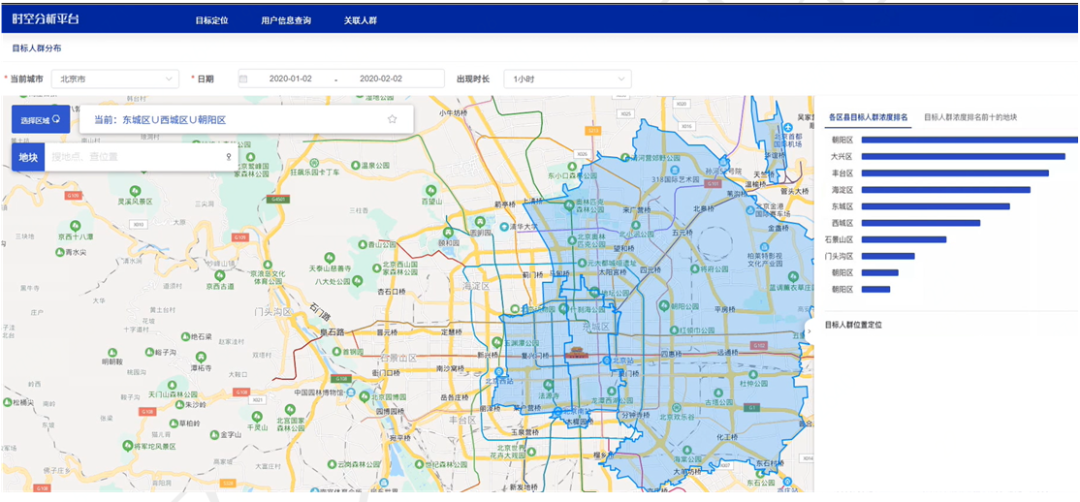
图 2 当前城市特定区域的高危人群分布
三、解决方案
我们前期的工作为海量轨迹数据在 HBase 中的存储管理提供了高效的解决方案[1]。基于此,我们使用 Spark 分布式分析引擎对大量的轨迹数据进行分析,获取人群的时空分布情况,进而筛选出到访过传染源区域的高危人群,基于高危人群在当前城市的分布情况,政府决策人员可采取及时精准的追踪和医学观察措施,从而防止疫情在当地的传播蔓延。
四、技术实现
完整的技术实现方案包括以下 3 个步骤。
4.1 轨迹数据存储
该方案选用 HBase 作为轨迹数据的分布式存储引擎。原始的轨迹数据都是以 GPS 记录的形式存储的,如图 3(a)中所示,我们称这种存储方式为纵向存储,该存储方式的不足在于一个点就是一条记录,破坏了轨迹的连续性特征,同时无法实现以轨迹为单位的压缩和查询,存储空间过大,查询效率过低。基于此,我们提出了图 3(b)所示的横向轨迹数据存储格式,该格式以一条完整的轨迹作为一条记录,在存储前做了高效的压缩,降低轨迹存储容量。同时提取轨迹的空间边界和时间范围等特征,据此创建轨迹的时空存储索引,用于实现高效的时空范围查询。具体实现细节可参考[1]。
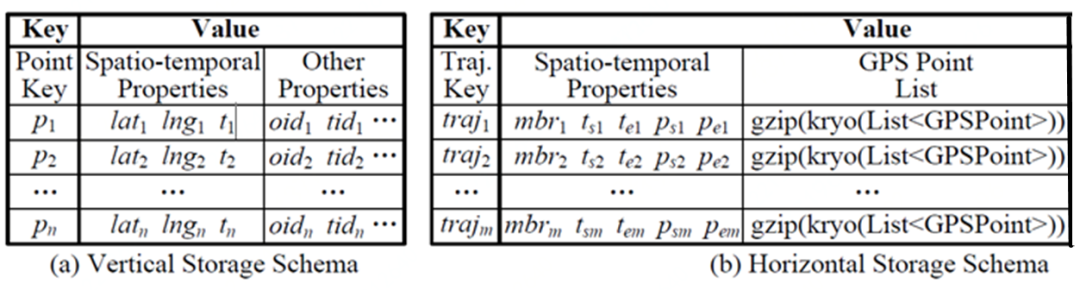
图 3 轨迹数据存储格式
4.2 轨迹数据分析
我们使用 Spark 分布式内存分析引擎对大量的轨迹数据进行分析。同时,在该解决方案中,以 OID 来唯一标识产生轨迹的主体(人)。
首先,需要将整个空间范围划分成等大的空间网格,将每条轨迹投影到与其相交的空间网格内,得到 OID 在空间网格内的分布信息,如图 4 所示, (OID,GridId, EnterTime,LeaveTime)表示 OID 在 EnterTime 时刻进入网格 GridId 内,并于 LeaveTime 时刻离开。对于传染源地区的轨迹数据集 Ts 和当前城市的轨迹数据集 Tc,分别统计分析出 OID 的时空分布情况,用集合 Ds 和 Dc 表示。
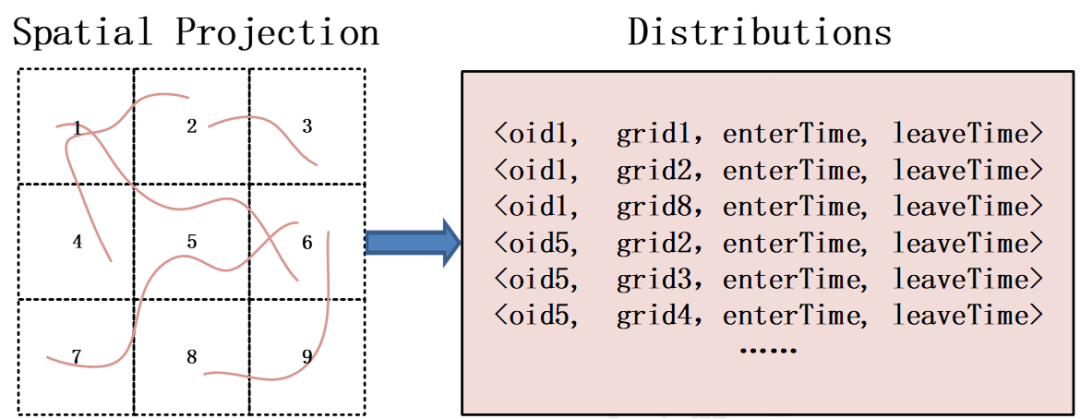
图 4 轨迹数据投影与人群时空分布统计
对时空分布集合 Ds 和 Dc,以 OID 为 Key,其他属性为 Value 组织成(Key,Value)对,然后利用 Spark 的 join 算子(内连接)计算出同时出现在 Ds 和 Dc 中的 OID 及相关属性,分析结果如表 1 所示。至此,已经获取到 3.1 问题定义中要找的来自病毒传播源地区的人员,以及他们在传染源地区和当前城市的驻留位置和时间信息。
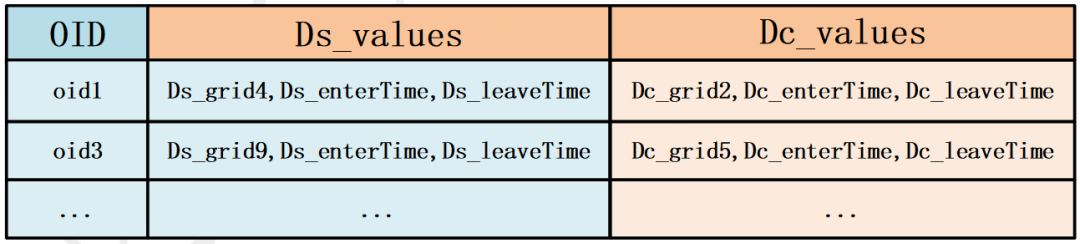
表 1 目标人群分析的中间结果
4.3 分析结果输出
为了满足不同的用途,需要对分析所得的中间结果进行分流处理。
首先,将用户在传染源地区的驻留信息提取出来,存储在一张 HBase 表中,如图 5(a)所示,该表以 OID+EnterTime 作为 Key,GridId+LeaveTime 作为 Value,提供高效的 OID 或 OID+时间范围查询,用于快速追溯一个人在传染源地区的驻留信息。
其次,将用户在当前城市的驻留信息提取出来,并在时间维度上以小时为单位进行分割,基于 GridId 和 TimeBucket 做聚合统计,得出每个空间网格每小时内来自传染源地区人员的数量 Count 和人员的 OID 集合,存储在一张 HBase 表中,如图 5(b)所示,该表以 GridId+TimeBucket 为 Key,Count+OIDs 为 Value,提供 GridId 查询或 GridId+时间范围查询,用于快速查询来自传染源区域的人员在当前城市每个时间段内的空间分布情况。
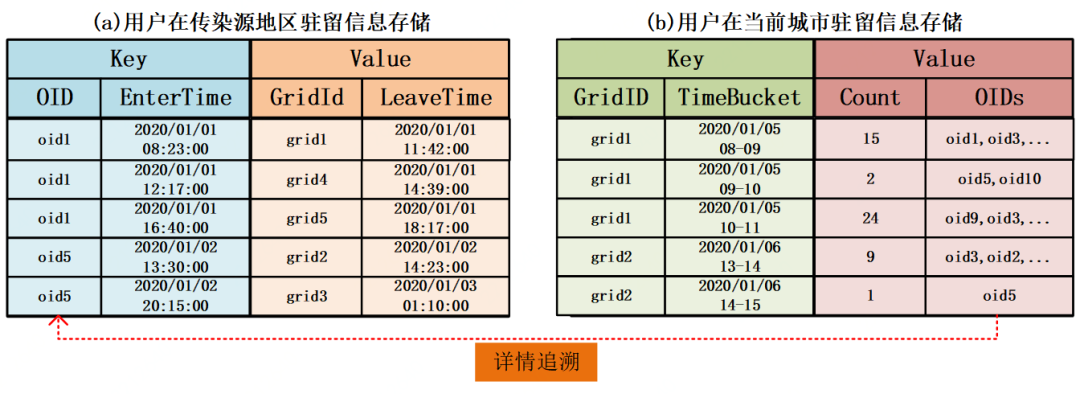
图 5 分析结果存储表结构
基于图 5(b)所示的分析结果,可以快速查询当前城市各区域在各时间段内高危人群的分布情况,并且可以基于 Count 实现直观的热力图展示效果。同时还可以通过 OID 追溯一个人在传染源地区的详细驻留信息,如图 5 虚线所示。
五、总结
本文介绍了一套基于轨迹数据的人口流向分析方案。该方案使用 HBase 分布式存储引擎和 Spark 分布式内存计算引擎,以大量轨迹数据为基础,分析来自某一地区的人口在当前城市的时空分布情况。以此分析结果为依据,政府部门可以在类似新冠肺炎疫情防控等重大事件中采取准确及时的举措,同时也为研究地方人口结构,经济发展状况,以及城市建设规划等多领域提供有价值的决策依据。
参考文献:
[1] Ruiyuan Li , Huajun He, Rubin Wang, Sijie Ruan, Yuan Sui,Jie Bao, Yu Zheng. TrajMesa: ADistributed NoSQL Storage Engine for Big Trajectory Data (Short Paper). The 36th IEEEInternational Conference on Data Engineering. (ICDE 2020)
本文转载自公众号京东数科技术说(ID:JDDTechTalk)。
原文链接:




