
作者|杨鷖 资深大数据开发工程师
编辑整理|SelectDB
领健是健康科技行业 SaaS 软件的引领者,专注于消费医疗口腔和医美行业,为口腔诊所、医美机构、生美机构提供经营管理一体化系统,提供了覆盖单店管理、连锁管理、健康档案/电子病历、客户关系管理、智能营销、B2B 交易平台、进销存、保险支付、影像集成、BI 商业智能等覆盖机构业务全流程的一体化 SaaS 软件。 同时通过开放平台连接产业上下游,与优质的第三方平台合作,为机构提供完整配套的一站式服务。截止当前,领健已经在全国设立了 20 余个分支机构,超过 30000 多家中高端以及连锁机构正在使用其服务。
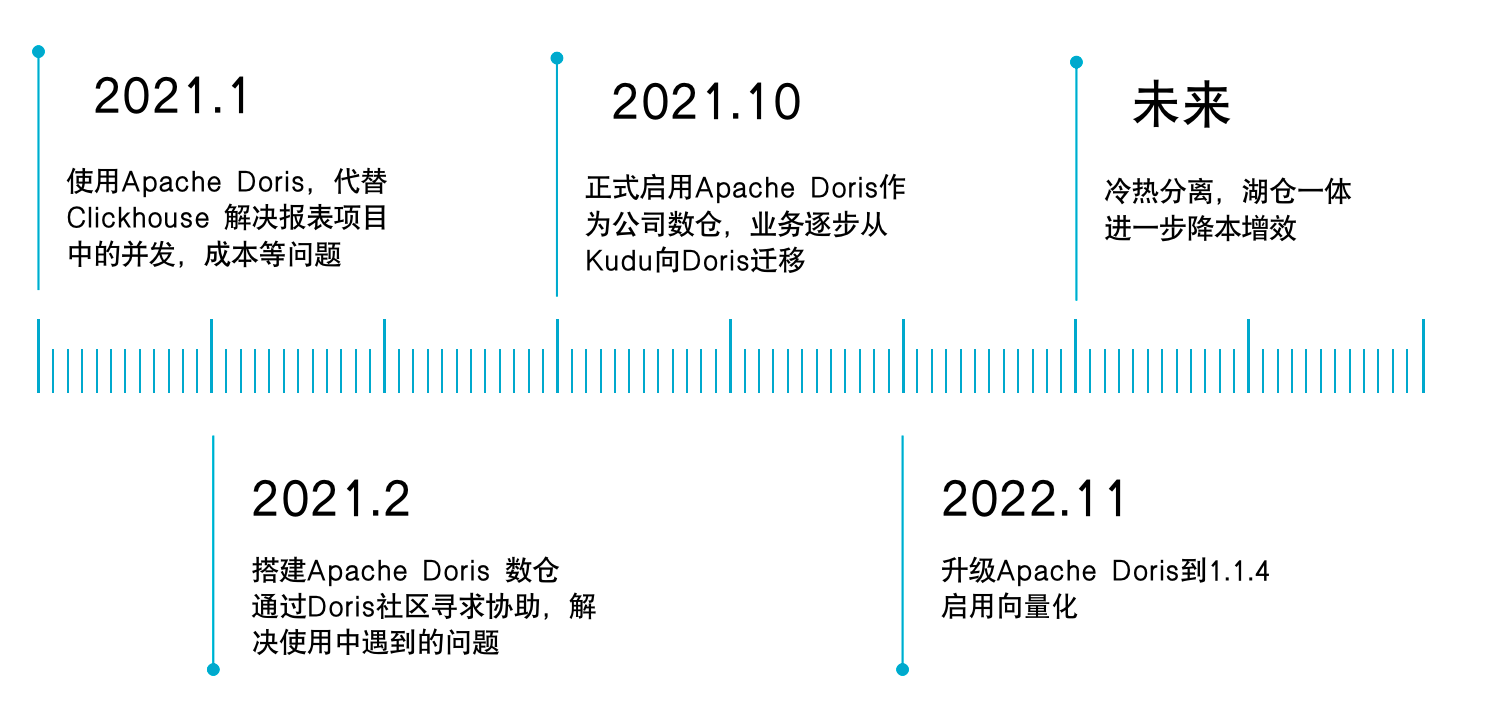
Doris 在领健的演进历程
在进入正文之前,简单了解一下 Doris 在领健的发展历程。最初 Doris 替代 ClickHouse 被应用到数据服务项目中,该项目是领健为旗下客户提供的增值报表服务;后在项目服务中发掘出 Doris 查询性能优异、简单易用、部署成本低等诸多优势,在 2021 年 10 月,我们决定扩大 Doris 应用范围,将 Doris 引入到公司的数仓中,在 Doris 社区及 SelectDB 专业技术团队的支持下,业务逐步从 Kudu 迁移到 Doris,并在最近升级到 1.1.4 向量化版本。我们将通过本文为大家详细介绍领健基于 Doris 的演进实践及数仓构建的经验。
数据服务架构演进
项目需求
领健致力于为医疗行业客户提供精细化门店运营平台,为客户提供了数据报表工具,该工具可实现自助式拖拽设计图表、支持多种自带函数自建、数据实时更新等功能,可以支持门店订单查询、客户管理、收入分析等,以推动门店数字化转型,辅助门店科学决策。为更好实现以上功能,数据报表工具需满足以下特点:
支持复杂查询:客户进行自助拖拽设计图表时,将生成一段复杂的 SQL 查询语句直查数据库,且语句复杂度未知,这将对数据库带来不小的压力,从而影响查询性能。
高并发低延时:至少可以支撑 100 个并发,并在 1 秒内得到查询结果;
数据实时同步: 报表数据源自于 SaaS 系统,当客户对系统中的历史数据进行修改后,报表数据也要进行同步更改,保持一致,这就要求报表数据要与系统实现实时同步。
低成本易部署:SaaS 业务存在私有云客户,为降低私有化部署的人员及成本投入,这要求架构部署及运维要足够简单。
ClickHouse 遭遇并发宕机
最初项目选用 ClickHouse 来提供数据查询服务,但在运行过程中 ClickHouse 遭遇了严重的并发问题,即 10 个并发就会导致 ClickHouse 宕机,这使其无法正常为客户提供服务,这是迫使我们寻找可以替代 ClickHouse 产品的关键因素。
除此之外还有几个较为棘手的问题:
云上 ClickHouse 服务成本非常高,且 ClickHouse 组件依赖性较高,数据同步时 ClickHouse 和 Zookeeper 的频繁交互,会对稳定性产生较大的压力。
如何进行无缝迁移,不影响客户正常使用。
技术选型
针对存在的问题及需求,我们决定进行技术选型,分别对 Doris(0.14)、Clickhous、Kudu 这 3 个产品展开的调研测试。
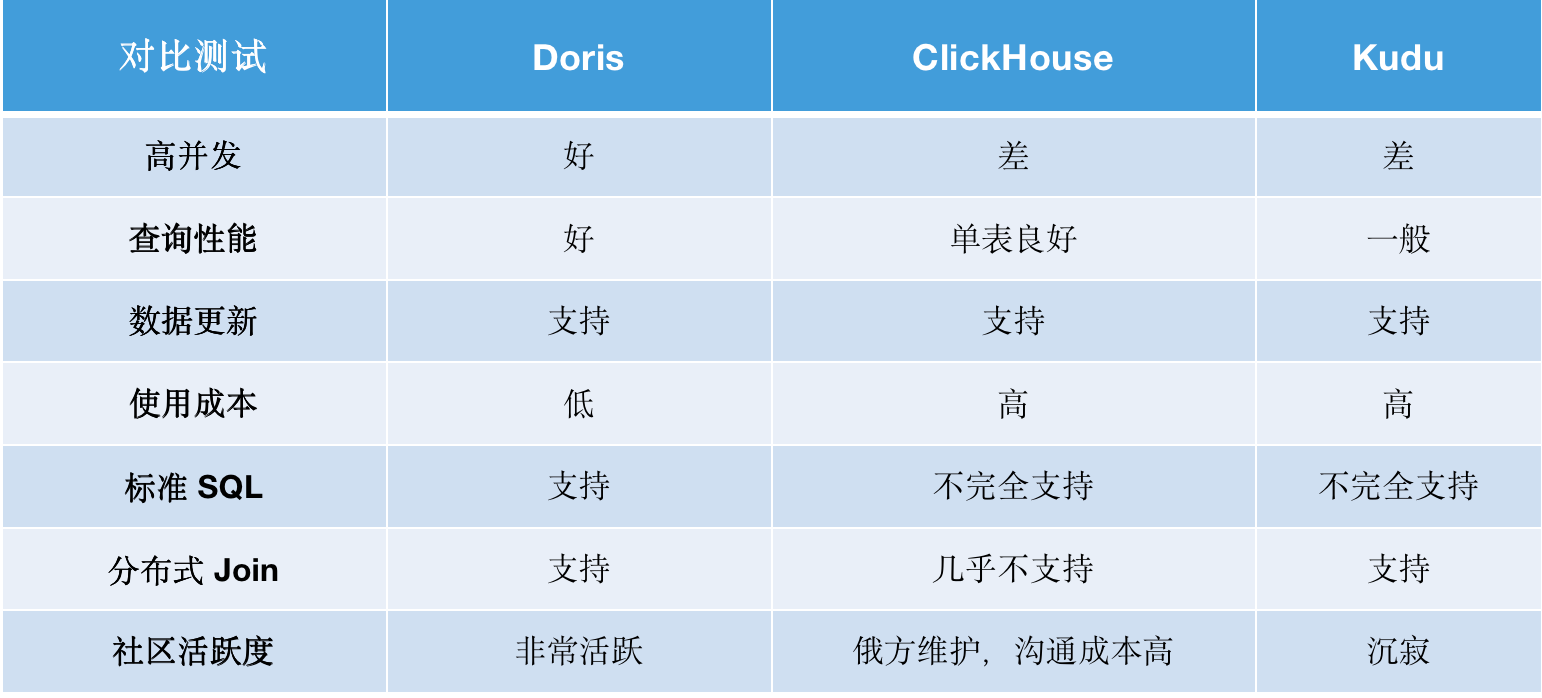
如上表所示,我们对这 3 个产品进行了横向比较,可以看出 Doris 在多方面表现优异:
高并发:Doris 并发性好,可支持上百甚至上千并发,轻松解决 10 并发导致 ClickHouse 宕机问题。
查询性能:Doris 可实现毫秒级查询响应,在单表查询中,虽 Doris 与 ClickHouse 查询性能基本持平,但在多表查询中,Doris 远胜于 ClickHouse ,Doris 可以实现在较高的并发下,QPS 不下降。
数据更新:Doris 的数据模型可以满足我们对数据更新的需求,以保障系统数据和业务数据的一致性,下文将详细介绍。
使用成本:Doris 架构简单,整体部署简单快速,具有完备的导入功能,很好的弹性伸缩能力;同时, Doris 内部可以自动做副本平衡,运维成本极低。而 ClickHouse 及 Kudu 对组件依赖较高,在使用上需要做许多准备工作,这就要求具备一支专业的运维支持团队来处理大量的日常运维工作。
标准 SQL:Doris 兼容 MySQL 协议,使用标准 SQL,开发人员上手简单,不需要付出额外的学习成本。
分布式 Join :Doris 支持分布式 Join,而 ClickHouse 由于 Join 查询限制、函数局限性、以及可维护性较差等原因,不满足我们当前的业务需求。
社区活跃:Apache Doris 是国内自研数据库,开源社区相当活跃,同时 SelectDB 为 Doris 社区提供了专业且全职团队做技术支持,遇到问题可以直接与社区联系沟通,并能得到快速解决,这对于国外的项目,很大的降低与社区沟通的语言与时间成本。
从以上调研中可以发现,Doris 各方面能力优秀,十分符合我们对选型产品的需求,因此我们使用 Doris 替代了 ClickHouse ,很好解决了 ClickHouse 并发性能差、宕机等问题,很好的支撑了数据报表查询服务。
数仓架构演进
在数据报表的使用过程中,我们逐渐发掘出 Doris 诸多优势,因此决定扩大 Doris 应用范围,将 Doris 引入到公司的数仓中来。接下来将为大家介绍公司数仓从 Kudu 到 Doris 的演进历程,以及在搭建过程中的优化实践分享。
早期公司数仓架构
早期的公司数仓架构使用 Kudu、Impala 来作为运算存储引擎,整体架构如下图所示。
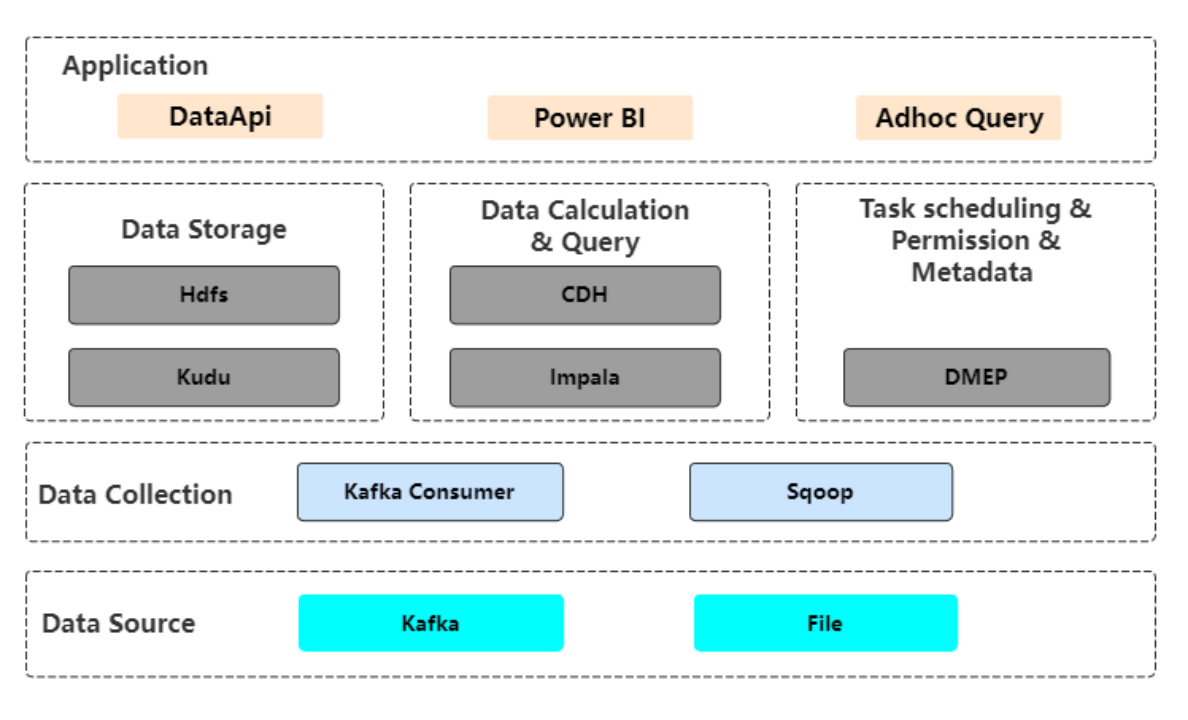
从上图可知,数据通过 Kafka Consumer 进入 ODS 层;通过 Kudu 层满足数据更新需要;运用 Impala 来执行数据运算和查询;通过自研平台 DMEP 进行任务调度。 在 ETL 代码中会使用大量的 Upsert 对数据进行 Merge 操作,那么引入 Doris 的首要问题就是要如何实现 Merge 操作,支持业务数据更新,下文中将进行介绍。
基于 Doris 的新数仓架构设计
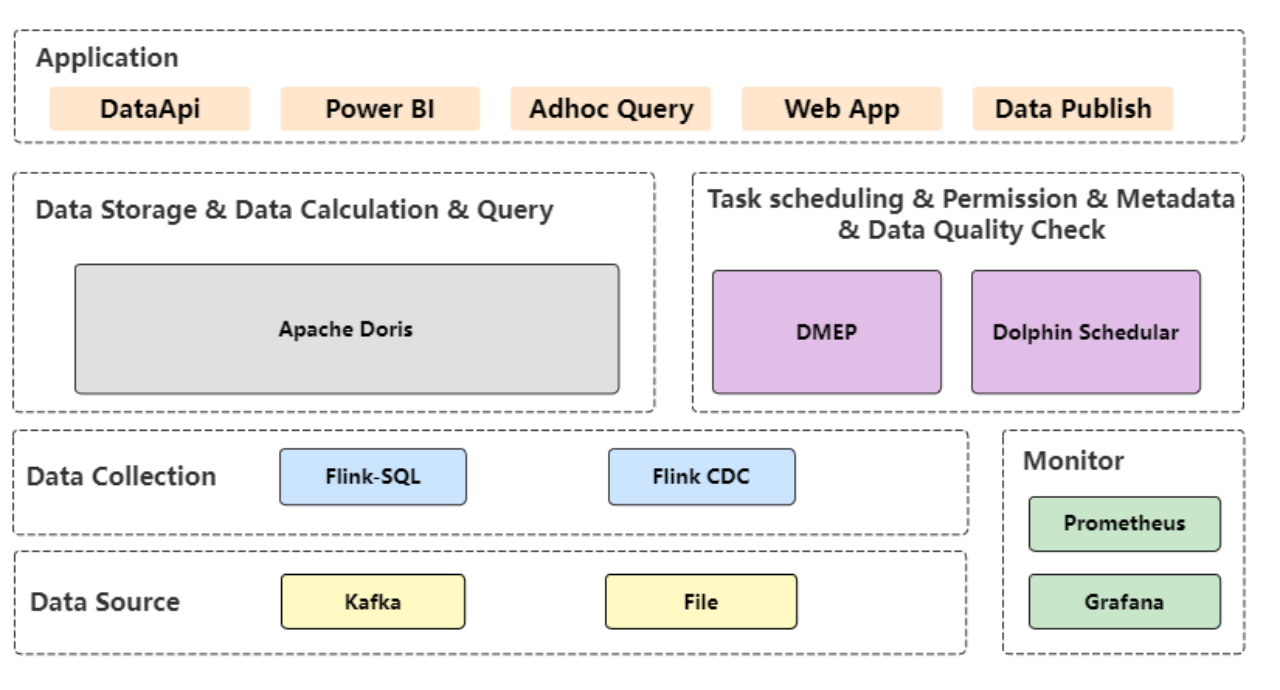
如上图所示,在新架构设计中使用 Apache Doris 负责数仓存储及数据运算;实时数据、 ODS 数据的同步从 Kafka Consumter 改为 Flink ;流计算平台使用团队自研的 Duckula;任务调度则引入最新 的 DolphinSchedular,Dolphin schedule 几乎涵盖了自研 DMEP 的大部分功能,同时可以很方便拓展 ETL 的方式,可调度很多不同的任务。
优化实践
数据模型选择
上文中提到,当客户对系统中的历史数据修改后,报表数据也要进行同步更改,同时,客户有时只更改某一列的数值,这要求我们需要选择合适的 Doris 模型来满足这些需求。我们在测试中发现,通过 Aggregate 聚合模型Replace_if_not_null 方式进行数据更新时,可以实现单独更新一列,代码如下:
drop table test.expamle_tbl2CREATE TABLE IF NOT EXISTS test.expamle_tbl2( `user_id` LARGEINT NOT NULL COMMENT "用户id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE_IF_NOT_NULL COMMENT "用户最后一次访问时间", `cost` BIGINT REPLACE_IF_NOT_NULL COMMENT "用户总消费", `max_dwell_time` INT REPLACE_IF_NOT_NULL COMMENT "用户最大停留时间", `min_dwell_time` INT REPLACE_IF_NOT_NULL COMMENT "用户最小停留时间")AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 1PROPERTIES ("replication_allocation" = "tag.location.default: 1");insert into test.expamle_tbl2 values(10000,'2017-10-01','北京',20,0,'017-10-01 06:00:00',20,10,10);select * from test.expamle_tbl ;insert into test.expamle_tbl2 (user_id,date,city,age,sex,cost)values(10000,'2017-10-01','北京',20,0,50);select * from test.expamle_tbl ;如下图所示,当写 50 进去,可以实现只覆盖Cost列,其他列保持不变。


Doris Compaction 优化
当 Flink 抽取业务库全量数据、持续不断高频写入 Doris 时,将产生了大量数据版本,Doris 的 Compaction 合并版本速度跟不上新版本生成速度,从而造成数据版本堆积。从下图可看出,BE Compaction Score 分数很高,最高可以达到 400,而健康状态分数应在 100 以下。
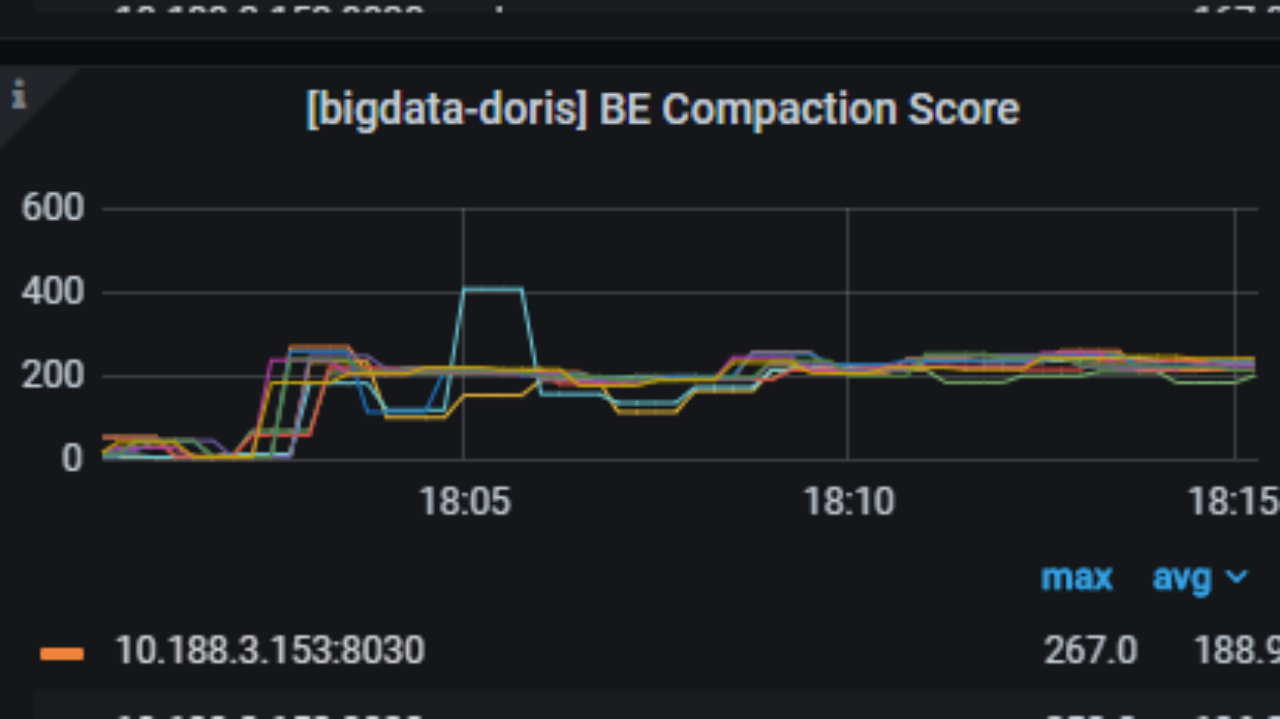
针对以上我们做了以下调整:
全量数据不使用实时写入的方式,先导出到 CSV,再通过 Stream Load 写入 Doris;
降低 Flink 写入频率,增大 Flink 单一批次数据量;该调整会降低数据的实时性,需与业务侧进行沟通,根据业务方对实时性的要求调整相关数值,最大程度的降低写入压力。
调节 Doris BE 参数,使更多 CPU 资源参与到 Compaction 操作中;
compaction_task_num_per_disk单磁盘 Compaction 任务线程数默认值 2,提升后会大量占用 CPU 资源,阿里云 16 核,提升 1 个线程多占用 6% 左右 CPU。max_compaction_threads compaction线程总数默认为 10。max_cumulative_compaction_num_singleton_deltas参数控制一个 CC 任务最多合并 1000 个数据版本,适当改小后单个 Compaction 任务的执行时间变短,执行频率变高,集群整体版本数会更加稳定。
通过调整集群, Compaction Score 稳定在了 50-100,有效解决了版本堆积问题。
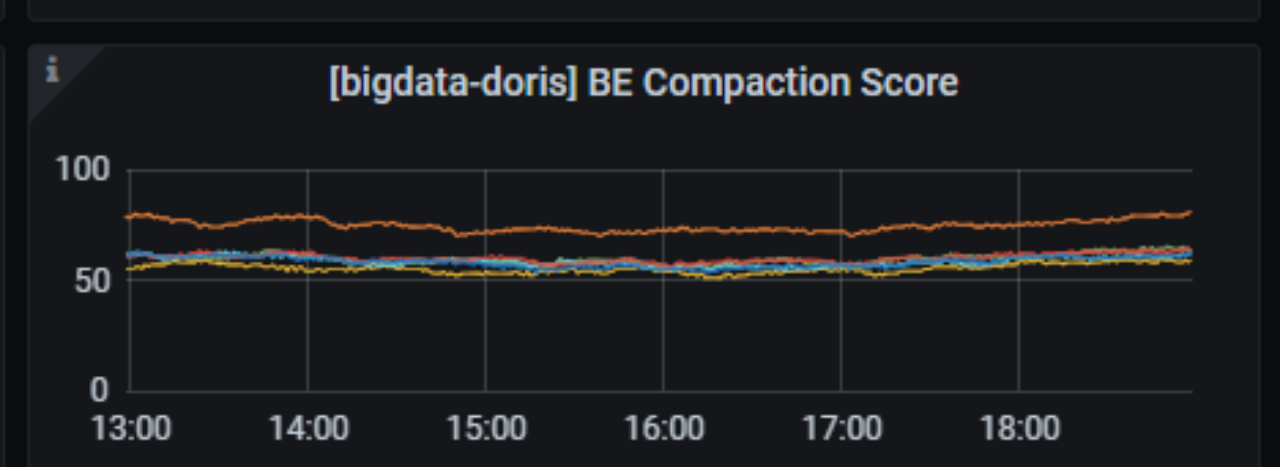
值得关注的是,在 Doris 1.1 版本中对 Compaction 进行了一系列的优化,在任务调度层面,增加了主动触发式的 Compaction 任务调度,结合原有的被动式扫描,高效的感知数据版本的变化,主动触发 Compaction。在任务执行层面,对资源进行隔离,将重量级的 Base Compaction 和轻量级的 Cumulative Compaction 进行了物理分离,防止任务的互相影响。同时,针对高频小文件的导入,优化文件合并策略,采用梯度合并的方式,保证单次合并的文件都属于同一数量级,逐渐有层次的进行数据合并,减少单个文件参与合并的次数,大幅节省系统消耗。
负载隔离
最初我们只有 1 个 Doris 集群,Doris 集群要同时支持高频实时写、 高并发查询、ETL 处理以及 Adhoc 查询等功能。其中高频实时写对 CPU 的占用很高,而 CPU 的上限决定高并发查询的能力,另外 Adhoc 查询无法预知 SQL 的复杂度,当复杂度过高时也会占用较高的内存资源。这就导致了资源竞争,业务之前互相影响的问题。为解决这些问题,我们进行了以下探索优化。
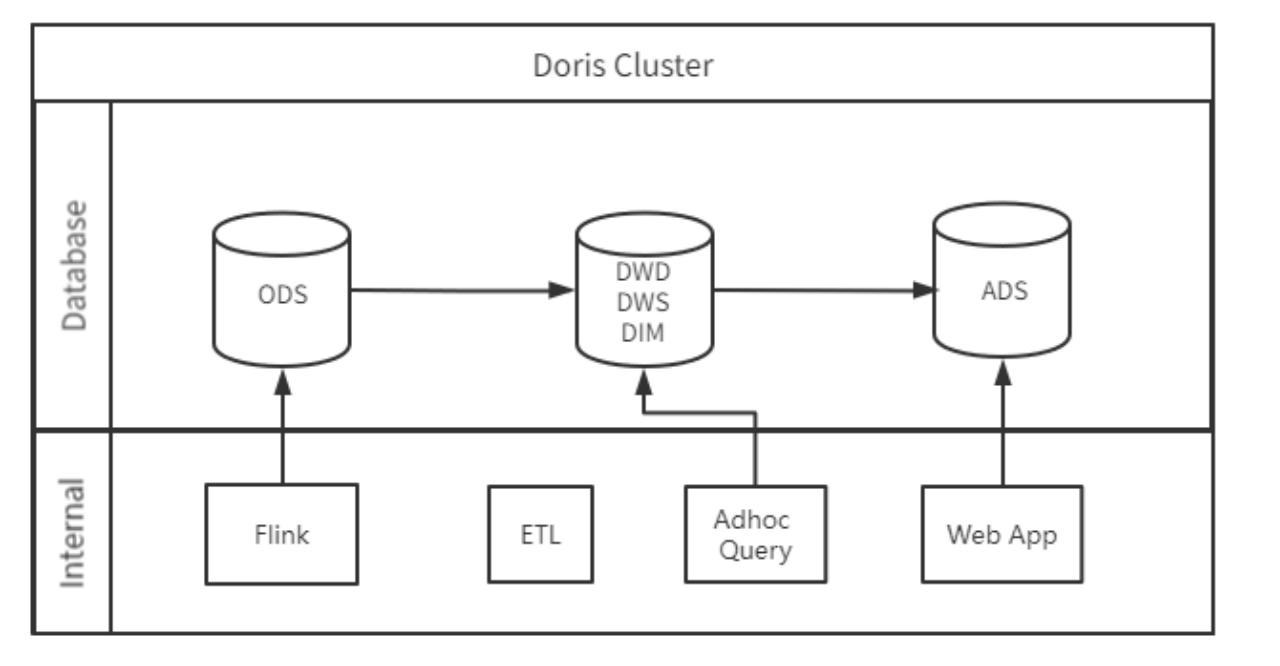
Doris 集群拆分
最初我们尝试对 Doris 集群进行拆分,我们把 1 个集群拆分为 3 个集群,分别为 ODS 集群、DW 集群、ADS 集群。我们将 CPU 负载最高的 ODS 层分离出去, ETL 时,通过 Doris 外表连接另一个 Doris 集群抽取数据;同时也将 BI 应用访问的集群分离出去,独立为业务提供数据查询。如下所示为各集群负责的任务:
ODS 集群:数仓 ODS 层,Flink 写数据集中在此层进行。
DW 集群:数仓 DW 层,DIM 层,主要负责 ETL 处理,Adhoc 查询任务。
ADS 集群:数仓 ADS 层,主要支持 Web 应用的数据查询
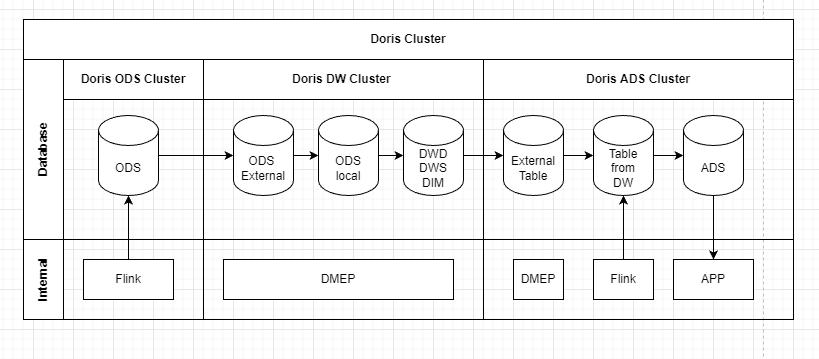
通过集群拆分,有效降低各个资源间的相互影响,保证每个业务运转都有较充足的资源。但是集群的拆分也存在集群之间数据同步 ETL 时间较长、从 ADS 到 ODS 跨 3 个集群的数据校验复杂度较高等问题。直到 Doris 0.15 发布后,这些问题也得到了相对有效的解决。
资源隔离优化集群资源
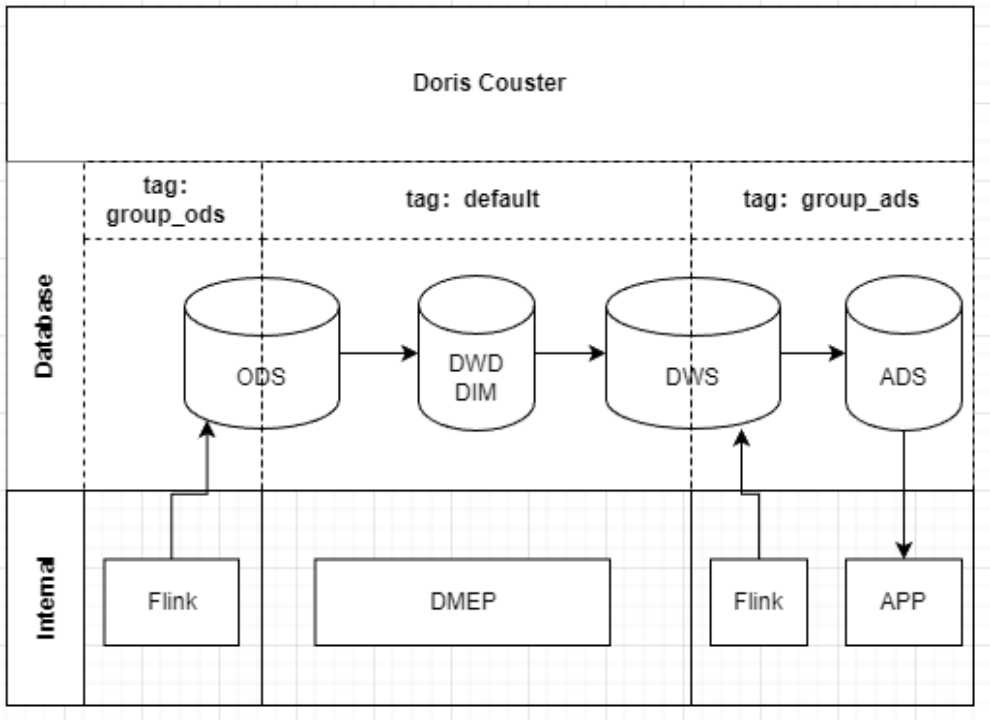
Doris 0.15 版本新增了资源标签功能以及查询 Block 功能,资源标签功能允许 Doris 集群实现资源隔离,该功能有效减少集群之间同步数据的时间,降低了跨集群数据校验复杂度。其次查询 Block 功能的上线,可以对 SQL 进行查询审计,阻塞简单/不合规的查询语句,降低资源占用率,提升查询性能。除此之外,通过资源隔离的方式,我们将 3 个集群合并成 1 个集群,被合并的 6 个入口节点 FE 被释放掉,将节省的资源加到核心的运算节点上来。
升级到 Doris 0.15 后,我们将 ODS 表的副本修改为 group_ods3 份,default3 份。 Flink 写入时只写 group_ods 资源组的节点,数据写入后,得益于 Doris 内部的副本同步机制,数据会自动实时同步到 default资源组。ETL 则可以使用 default 资源组的节点资源取用 ODS 数据,进行查询和数据处理。同理 ADS 也做了相同处理,原先需要通过外表进行数据抽取同步的表,均被做成了副本跨资源组的形式。此方式有效缩短了跨集群数据同步的 ETL 时长 。
离线 ETL 内存高
我们使用的是离线 ETL 方式直接在 Doris 上做 ETL 操作,在 Join 时,如果右表数据量比较大的情况下会消耗大量的内存,从而造成 OOM。在 1.0 版本之前内存跟踪能力较弱,容易造成 BE 节点超出 Linux 限制,导致进程被关闭 ,这时候会收到以下报错信息:Host is down或者 Fail to initialize storage reader。在 1.0 及更高版本中, Doris 由于优化了内存跟踪,则容易见到以下报错:Memory exceed limit. Used: XXXX ,Limit XXXX.
针对内存受限问题,我们开始寻找优化方案,另外由于公司内部资源受限,优化方案必须在不增加集群成本的情况下把超出集群负荷的任务跑通。这里为大家介绍 2 个解决方法:
优化调整 Join 的方式:
Doris 内部 Join 分为 4 种,其内存开销以及优先级如下图所示:

从上图可知,Join 类型优先级从左往右依次变低,Shuffle 的优先级最低,排在 Broadcast 之后。值得注意的是, Broadcast 内存开销非常大,它将右表广播到所有 BE 节点,这相当于每个 BE 节点会消耗一个右表的内存,这将造成很大的内存开销。针对 Broadcast 比较大的内存开销,我们通过 Hint 条件强制 Join 类型的方式,使 Join 语句跳过 Broadcast 到 Shuffle Join ,从而降低内存消耗。
select * from a join [shuffle] b on a.k1 = b.k1;数据分批处理
我们尝试将数据按照时间分批,每批涵盖某一个或某几个时间段的数据,分批进行 ETL,有效降低内存消耗,避免 OOM 。分批须知:需要将分批的标记列放在主键中,最大程度提升搜索数据的效率;注意分桶和分区的设置方式,保证每个分区的数据量都比较均衡,避免个别分区内存占用较高的问题。
总结
新架构收益
基于 Doris 的新数仓架构不再依赖 Hadoop 生态组件,运维简单,维护成本低。
具有更高性能,使用更少的服务器资源,提供更强的数据处理能力。
支持高并发,能直接支持 WebApp 的查询服务。
支持外表,可以很方便的进行数据发布,将数据推送其他数据库中。
支持动态扩容,数据自动平衡。
支持多种联邦查询方式,支持 Hive、ES、MySQL 等
得益于新架构的优异能力,我们所用集群从 18 台 16C128G 减少到 12 台 16C128G,集群资源较之前节省了 33% ,大大降低了投入成本;并且运算性能得到大幅提升,在 Kudu 上 3 小时即可完成的 ETL 任务, Doris 只需要 1 小时即可完成 。除此之外,高频更新的场景下,Kudu 内部数据碎片文件不能进行自动合并,表的性能会越来越差,需要定期重建;而 Doris 内部的 Compaction 机制可以有效避免此问题。
社区寄语
首先,Doris 的使用成本很低,仅需要 3 台低配服务器、甚至是台式机,就能相对容易的部署一套基于 Doris 的数仓作为数据中台基础;我认为对于想要进行数字化,但介于资源投入有限而又不想落后于市场的企业来说,非常建议尝试使用 Apache Doris ,Doris 可以助力企业低成本跑通整个数据中台。
其次,Doris 是一款国人自研的的 MPP 架构分析型数据库,这令我感到很自豪,同时其社区十分活跃、便于沟通,Doris 背后的商业化公司 SelectDB 为社区组建了一支专职技术团队,任何问题都能在 1 小时内得到响应,近 1 年社区更是在 SelectDB 的持续推动下,推出了一系列十分抗打的新特性。另外社区在版本迭代时会认真考虑中国人的使用习惯,这些会为我们的使用带来很多便利。
最后,感谢 Doris 社区和 SelectDB 团队的全力支持,也欢迎开发者以及各企业多多了解 Doris、使用 Doris,支持国产数据!
1.2.0 版本
Apache Doris 于 2022 年 12 月 7 日迎来 1.2.0 Release 版本的正式发布!新版本中实现了全面的向量化、实现多场景查询性能 3-11 倍的提升,在 Unique Key 模型上实现了 Merge-on-Write 的数据更新模式、数据高频更新时查询性能提升达 3-6 倍,增加了 Multi-Catalog 多源数据目录、提供了无缝接入 Hive、ES、Hudi、Iceberg 等外部数据源的能力 ,引入了 Light Schema Change 轻量表结构变更、 实现毫秒级的 Schema Change 操作并可以借助 Flink CDC 自动同步上游数据库的 DML 和 DDL 操作,以 JDBC 外部表替换了过去的 ODBC 外部表,支持了 Java UDF 和 Romote UDF 以及 Array 数组类型和 JSONB 类型,修复了诸多之前版本的性能和稳定性问题,推荐大家下载和使用!
相关链接:
GitHub 下载:https://github.com/apache/doris/releases
官网下载页:https://doris.apache.org/download
源码地址:https://github.com/apache/doris/releases/tag/1.2.0-rc04




