今年 7、8 月份杭州实行拉闸限电时,导致阿里余杭机房的机器意外断电,造成 HDFS 集群上的部分数据丢失。
在 Hadoop 2.0.2-alpha 之前,HDFS 在机器断电或意外崩溃的情况下,有可能出现正在写的数据丢失的问题。而最近刚发布的 CDH4 中 HDFS 在 Client 端提供了 hsync() 的方法调用 ( HDFS-744 ),从而保证在机器崩溃或意外断电的情况下,数据不会丢失。这篇文件将围绕这个新的接口对其实现细节进行简单的分析,从而希望找出一种合理使用 hsync() 的策略,避免重要数据丢失。
HDFS 中 sync(),hflush() 和 hsync() 的差别
在 hsync() 之前,HDFS 就已经提供了 sync() 和 hflush() 的调用,单从方法的名称上看,很难分辨这三个方法之间的区别。咱们先从这几个方法之间的差别介绍起。
在 HDFS 中,调用 hflush() 会将 Client 端 buffer 中的存放数据更新到 Datanode 端,直到收到所有 Datanode 的 ack 响应时结束调用。这样可保证在 hflush() 调用结束时,所有的 Client 端都可以读到一致的数据。HDFS 中的 sync() 本质也是调用 hflush()。
hsync() 则是除了确保会将 Client 端 buffer 中的存放数据更新到 Datanode 端外,还会确保 Datanode 端的数据更新到物理磁盘上,这样在 hsync() 调用结束后,即使 Datanode 所在的机器意外断电,数据并不会因此丢失。而 hflush() 在机器意外断电的情况下却有可能丢失数据,因为 Client 端传给 Datanode 的数据可能存在于 Datanode 的 cache 中,并未持久化到磁盘上。下图描述了从 Client 发起一次写请求后,在 HDFS 中的数据包传递的流程。
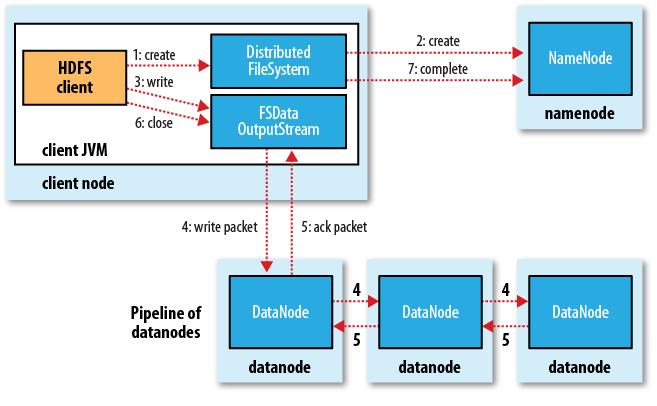
hsync() 的实现本质
hsync() 执行时,实际上会在对应 Datanode 的机器上产生一个 fsync 的系统调用,从而将内存中的相关文件的数据更新到磁盘。
Client 端执行 hsync 时,Datanode 端会识别到 Client 发送过来的数据包中的 syncBlock_ 字段为 true,从而判定需要将内存中的数据更新到磁盘。此时会在 BlockReceiver.java 的 flushOrSync() 中执行如下语句:
((FileOutputStream)cout).getChannel().force(true);
而 FileChannel 的 force(boolean metadata) 方法在 JDK 中,底层为于 FileDispatcherImpl.c 中调用 fsync 或 fdatasync。metadata 为 true 时执行 fsync,为 false 时执行 fdatasync。
Java_sun_nio_ch_FileDispatcherImpl_force0(JNIEnv *env, jobject this,
jobject fdo, jboolean md)
{
jint fd = fdval(env, fdo);
int result = 0;
if (md == JNI_FALSE) {
result = fdatasync(fd);
} else {
result = fsync(fd);
}
return handle(env, result, "Force failed");
}
当 Datanode 将数据持久化到磁盘上后,会发 ack 响应给 Client 端。当收到所有 Datanode 的 ack 响应时,hsync() 的调用结束。
值得注意的是,fsync 或 fdatasync 本身是一个非常耗时的调用,因为磁盘的读写速度远低于内存的读写速度。在不调用 fsync 或 fdatasync 的情况下,数据可能保存在各级 cache 中。
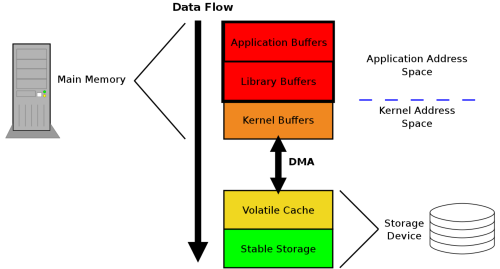
最开始笔者在测 hsync() 的读写性能时,发现不同机器上测试结果 hsync() 耗时差别巨大,有的集群平均调用耗时为 4ms,而有的集群平均调用耗时则需 25ms。后来在公司各位大神的点拨下才意识到是跟 Linux 文件系统的机制有关。在这种情况下,只有一探 Linux 相关部分的源码才能解开心中的疑惑,下面这节就将从更底层的角度来解析与 hsync() 密切相关的系统调用 fsync 及 fdatasync 方法。
fsync 和 fdatasync 的大致实现过程
对 ext4 格式的文件系统来说,fsync 和 fdatasync 方法的实现代码位于 fs/ext4/fsync.c 这个文件中。在追加写文件的情况下,fsync 和 fdatasync 的流程几乎一致,因为对 HDFS 的写操作基本都是追加写,下面我们只讨论追加写文件下的情景。ext4 格式的文件系统中布局大致如下:
Group 0 Padding
Super Block
Group Descriptors
Reserved GDT Blocks Data
Data Block Bitmap
inode Bitmap
inode Table
Data Blocks
1024 bytes
1 block
many blocks
many blocks
1 block
1 block
many block
many more blocks
在我们追加写文件时,涉及到修改的有 DataBlock BitMap、inode BitMap、inode Table、Data Blocks。但从代码中来看,实际上对文件的追加会被合并成两次写 (这里是指逻辑意义上的两次写,实际在从系统 Cache 刷新到磁盘时,读写操作会被再次合并),第一次为写 DataBlock 和 DataBlock Bitmap,第二次为写 inode BitMap 和更新 inode BitMap 中的 inode。ext4 为了支持更大的容量,使用了 extend tree 来实现块映射。在追加文件的情况下,fsync 和 fdatasync 除了更新 inode 中的 extend tree 外,还会更新 inode 中文件大小,块计数这些 metadata。对 fsync 来说,还会修改 inode 中的文件修改时间、文件访问时间(在 mount 选项不含 noatime 的情况下)和 inode 修改时间。
写障碍和 Disk Cache 的影响
在了解了 fsync() 和 fdatasync() 方法会对文件系统进行的改动后,离找出之前为什么在不同集群上 hsync() 的调用平均耗时的原因仍还有一段距离。这时我发现了不同的磁盘挂载选项会影响到 fsync() 和 fdatasync() 的执行时间,进而确定是写障碍和 Disk Cache 在搞怪。下面这节就将分析写障碍和 Disk Cache 对 hsync() 方法调用耗时的影响。
由于市面上大部分的磁盘都是带 Disk Cache 的,这导致在不开启写障碍的情况下,机器意外断电可能会对其造成 metadata 的不一致。对 ext4 这种 journal 文件系统来说,journal 写入一个事务后,会对 metadata 进行更新,更新完成后会将该事务标记从未执行修改为完成。举个例子,加入我们要创建并写一个文件,那么在 journal 中可能会产生三个事务。那么创建并写一个文件的执行流程如下:
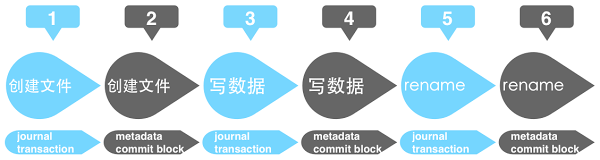
在磁盘没有 Disk Cache 的情况下,即时机器意外断电,那么重启自检时,可通过 journal 中最后事务的状态来对 metadata 进行重新执行修复或者废弃该事务。从而保证了 metadata 的一致性。但在磁盘有 Disk Cache 的情况下,IO 事件会当数据写到 Disk Cache 中就响应完成。虽然 journal 按上图的流程进行执行,但是执行完成后这些数据仍可能有部分并未持久化到磁盘上。假如在执行第 6 个步骤的时候机器意外断电,同时第 4 个步骤中的数据暂未更新到磁盘,而第 1,2,3,5 个步骤的数据已经同步到磁盘的话。这时机器重启自检时,由于第 5 个步骤中 journal 的执行状态为未完成,会重新执行第 6 个步骤一次。但第 6 个步骤对 metadata 的修改是建立在第 4 个步骤已经完成的基础之上的,由于第 4 个步骤并未持久化到磁盘,所以重新执行第 6 个步骤时会发生异常,造成 metadata 的错误。
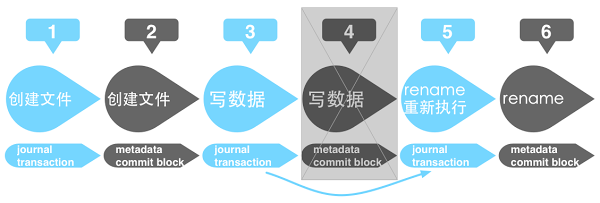
Linux 中为了避免这一情况,可以在 ext4 的 mount 选项中加 barrier=1,data=ordered 开启写障碍,来确保数据持久化到磁盘的顺序。在写障碍前的数据会先于写障碍后的数据刷新到磁盘,Linux 会在 journal 的事务写到 Disk Cache 中后放置一个写障碍。这样 journal 的事务位于写障碍之前,而对应的 metadata 的修改数据位于写障碍之后。避免了 Disk Cache 中合并 IO 时,对读写操作进行重排序后,由于读写操作执行顺序的改变而造成意外断电后 metadata 无法修复的情况。
关闭写障碍,即 ext4 的 mount 选项为 barrier=0 时,除了有可能造成在机器断电或异常崩溃重启后 metadata 错误外,fsync 和 fdatasync 的调用还会在数据更新到 Disk Cache 时就返回,而非等到数据刷新到磁盘上后才结束调用。因为在不开写障碍的情况下,Linux 会将此时的磁盘当做没有 Disk Cache 的磁盘来处理,当数据只是更新到 Disk Cache,就会认为该 IO 操作已完成,这也正是前文中提到的不同集群上 hsync() 的平均调用时长差别巨大的原因。所以关闭写障碍的情况下,调用 fsync 或 fdatasync 并不能确保数据在机器断电或异常崩溃时不丢失。
Disk Cache 的存在可以提高磁盘每秒的吞吐量,通过重排序 IO,尽量将 IO 读写变成顺序读写提高速率,同时减少文件系统碎片。而通过开启写障碍,可避免意外断电情形下 metadata 异常,同时确保调用 fsync 或 fdatasync 时 Disk Cache 中的数据持久到磁盘。
开启 journal 的影响
除了写障碍和 Disk Cache 会影响到 hsync() 的调用时长外,Datanode 上文件系统有没有打开 journal 也是影响因素之一。关闭 journal 的情况下可以减少 hsync() 的调用时长。
在不开启 journal 的情况下,调用 fsync 或 fdatasync 主要是由 generic_file_fsync 这个方法来实现将数据刷新到磁盘。在追加写文件的情况下,不论是 fsync 还是 fdatasync,在 generic_file_fsync 这个方法中都会先更新 Data Block 数据,再更新 inode 数据。如果执行 fsync 或 fdatasync 的文件为新创建的文件,在不开启 journal 的情况下,还会在更新完文件的 inode 后,更新该文件的父结点的 Data Block 和 inode。
而开启 journal 的情况下,调用 fsync 或 fdatasync 会先写 Data Block,然后提交 journal 的事务。虽然调用 fsync 或 fdatasync 是指定对某个文件进行操作,但在 ext4 中,整个文件系统只有一个 journal 文件,提交 journal 的修改事务时会将整个文件系统的 metadata 的修改事务一并提交。在文件系统写入操作频繁时,这一步操作会比较耗时。
fsync 及 fdatasync 耗时测试
测试使用的代码如下:
代码中以追加的方式向一个已存在的文件写入 4k 数据,4k 刚好为内存页和磁盘块的大小。下面分别以几种模式来测试 fsync 和 fdatasync 的耗时。
#define BLOCK_LEN 1024
static long long microseconds(void) {
struct timeval tv;
long long mst;
gettimeofday(&tv, NULL);
mst = ((long long)tv.tv_sec) * 1000000;
mst += tv.tv_usec;
return mst;
}
int main(void) {
int block = open("./block", O_WRONLY|O_APPEND, 0644);
long long block_start, block_end, fdatasync_time, fsync_time;
char block_buf[BLOCK_LEN];
int i = 0;
for(i = 0; i < BLOCK_LEN; i++){
block_buf[i] = i % 50;
}
if (write(block, block_buf, BLOCK_LEN) == -1) {
perror("write");
exit(1);
}
block_start = microseconds();
fdatasync(block);
block_end = microseconds();
fdatasync_time = block_end - block_start;
if (write(block, block_buf, BLOCK_LEN) == -1) {
perror("write");
exit(1);
}
block_start = microseconds();
fsync(block);
block_end = microseconds();
fsync_time = block_end - block_start;
printf("fdatasync spent: %lld, fsync spent: %lld\n",
fdatasync_time,
fsync_time);
close(block);
exit(0);
}
测试准备
- 文件系统:ext4
- 操作系统内核:Linux 2.6.18-164.el5
- 硬盘型号:WDC WD1003FBYX-1 1V02,SCSI 接口
- 通过 sdparm–set=WCE /dev/sdx 开启 Disk Write Cache,sdparm–clear=WCE /dev/sdx 关闭 Disk Write Cache
- 通过 barrier=1,data=ordered 开启写障碍,barrier=0 关闭写障碍
- 通过 tune4fs-O has_journal /dev/sdxx 开启 Journal,tune4fs-O ^has_journal /dev/sdxx 关闭 Journal
关闭 Disk Cache,关闭 Journal
类型
耗时(微秒)
fdatasync
8368
fsync
8320
Device
wrqm/s
w/s
wkB/s
avgrq-sz
avgqu-sz
await
svctm
%util
sdi
0.00
120.00
480.00
8.00
1.00
8.33
8.33
100.00
可以看到,iostat 为 8ms,对 inode、Data Block、inode Bitmap、DataBlock Bitmap 的数据更新合并为了一次写操作。
关闭 Disk Cache,开启 Journal
类型
耗时(微秒)
fdatasync
33534
fsync
33408
Device
wrqm/s
w/s
wkB/s
avgrq-sz
avgqu-sz
await
svctm
%util
sdi
37.00
74.00
444.00
11.95
1.22
16.15
13.32
99.90
通过使用 blktrace 跟踪对磁盘块的读写,发现此处写 journal 会比较耗时,下面的记录为 fsync 过程中对磁盘发送的写操作,已预处理掉了大部分不重要的信息,可以看到,后面三条记录都是 journal 的写操作(通过此处 kjournald 的进程 id 为 3001 来识别)。
0,0
13
1
0.000000000
8835
A
W
2855185 + 8 <- (8,129) 2855184
0,0
4
5
0.000313001
3001
A
W
973352281 + 8 <- (8,129) 973352280
0,0
4
1
0.000305325
3001
A
W
973352273 + 8 <- (8,129) 973352272
0,0
4
12
0.014780357
3001
A
WS
973352289 + 8 <- (8,129) 973352288
开启 Disk Cache,开启写障碍,开启 Journal
类型
耗时(微秒)
fdatasync
23759
fsync
25006
从结果可以看到,Disk Cache 的开启可以合并更多 IO,从而减少耗时。
值得注意的是,在开启 Disk Cache 时,iostat 的 await 是按照从内存写完到 Disk Cache 中来统计耗时,并非是按照写到磁盘上来计时,所以此种情况下 iostat 的 await 参数会比较小,并无参考意义。
小结
从这次测试结果可以看到,虽然 CDH4 提供了 hsync() 方法,但是若我们对每次写操作都执行 hsync(),会严重加剧磁盘的写延迟。通过一些策略,比方说定期执行 hsync() 或当存在于 Cache 中的数据达到一定数目时,执行 hsync() 会是更可行的方案,从而尽量减少机器意外断电所带来的影响。
附:术语解释
- Hadoop: Apache 基金会的开源项目,用于海量数据存储与计算。
- CDH4: Cloudera 公司在 Apache 社区发行版基础之上进行改进后的发行版,更稳定更适用于生产环境。
- Namenode: Hadoop 的 HDFS 模块中管理所有文件元数据的组件。
- Datanode: Hadoop 的 HDFS 模块中存储文件实际数据的组件。
- HDFS Client: 这里指连接 HDFS 对其中文件进行读写操作的客户端。
作者简介
黄浩松,华南农业大学学生,现于阿里巴巴数据平台实习。微博 ID: @华农金中菊




