
本文将向你介绍为什么我们需要像 BPF 这样的东西,并帮助你了解何时及如何使用它,以及它是如何帮助作为工程师的你改进你正在进行的项目的。我们还将研究它与 Go 相关的一些详细信息。
每个人都有自己最喜欢的魔术。对一个人来说他是托尔金(Tolkien),对另一个人来说是普拉切特(Pratchett),对于第三个人来说,比如我,是马克斯·弗雷(Max Frei)。今天我要给大家讲的是我最喜欢的 IT 魔术:BPF 以及围绕它的现代基础设施。
BPF目前正处于流行的高峰期。这项技术正在飞速发展,深入到了意想不到的领域,并且越来越容易被普通用户所接受。现在几乎每个流行的会议都有关于这个主题的演讲,早在 8 月份,我就应邀在 GopherCon Russia 上做了该主题相关的演讲。
我在那里有过非常好的体验,所以我想与尽可能多的人分享一下。本文将向你介绍为什么我们需要像 BPF 这样的东西,并帮助你了解何时及如何使用它,以及它是如何帮助作为工程师的你改进你正在进行的项目的。我们还将研究它与 Go 相关的一些详细信息。
我真正希望的是,你读完这篇文章后,就像第一次读完《哈利波特》的小孩儿那样,眼睛里闪着光芒,并且希望你能够亲自去尝试一下这个新“玩具”。
一些背景知识
好吧,让一个 34 岁、留着大胡子、眼神灼热的家伙来告诉你这个魔术是什么?
我们生活在 2020 年。打开推特,你可以看到愤怒的技术人员发来的推文,他们都说今天编写的软件质量太差了,需要扔掉,我们需要重新开始。有些人甚至威胁说要彻底离开这个行业,因为他们无法忍受这些,一切都是如此的糟糕、不方便且缓慢。
他们可能是对的:如果不阅读上千条评论,就无法确定原因。但有一点我绝对同意,那就是现代软件堆栈比以往任何时候都要复杂:我们有 BIOS、EFI、操作系统、驱动程序、模块、库、网络交互、数据库、缓存、编排器(如 K8s)、Docker 容器,最后还有我们自己带有运行时和垃圾收集器的软件。
一个真正的专业人士可能会花上几天的时间才能回答这样一个问题:当在你的浏览器中输入 google.com 后会发生什么。
要理解你的系统发生了什么是非常复杂的,尤其是在当前情况下,出现了问题,你正在赔钱的时候。正是由于这个问题,才出现了能够帮助你了解系统内部情况的企业。在大公司里,有的整个部门都是像夏洛克·福尔摩斯(Sherlock holmes)那样的侦探,他们知道在哪里敲敲锤子,知道用什么拧紧螺栓以节省数百万美元。
我喜欢问人们如何在最短的时间内调试出突发问题。通常,人们最先想到的方法是分析日志。但问题在于,唯一可访问的日志是开发人员放在他们的系统中的日志,这是很不灵活的。
第二种最流行的方法是研究度量指标。最流行的三个度量指标处理系统都是用 Go 编写的。度量指标非常有用,但是,虽然它们确实可以让你看到症状,但它们并不总是能够帮助你定义出问题的根本原因。
第三种方法是所谓的“可观察性”:你可以对系统的行为提出尽可能多的复杂问题,并获得这些问题的答案。由于问题可能会非常复杂,所以答案可能会需要最广泛的信息,而在问题被提出之前,我们并不知道这些信息是什么,这意味着可观察性绝对需要灵活性。
提供一个“动态”更改日志级别的机会怎么样呢?如果使用调试器,在程序运行时连接到程序,并在不中断程序运行时执行某些操作,又会怎么样呢?了解哪些查询会被发送到系统中,可视化慢查询的来源,通过 pprof 查看内存消耗情况,并获取其随时间变化的曲线图呢?如何测量一个函数的延迟以及延迟对参数的依赖性呢?我将所有这些方法都归为“可观测性”这一总称。这是一套实用程序、方法、知识和经验,它们结合在一起,共同为我们提供了机会,即使不能做到我们想做的任何事,至少在系统工作时,它可以在系统中做很多“现场”工作。它相当于现代 IT 界的一把瑞士军刀。

但是我们怎样才能做到这一点呢?市场上已经有很多现成的工具了:有简单的、有复杂的、有危险的、也有缓慢的。 但是今天这篇文章是关于 BPF 的。
Linux 内核是一个事件驱动系统。实际上,在内核以及整个系统中所发生的一切都可以看作是一组事件。中断是一个事件;通过网络接收数据包是一个事件;将处理器的控制权转移到另一个进程是一个事件;运行函数也是一个事件。
是的,所以 BPF 是 Linux 内核的一个子系统,它使你有机会编写一些由内核运行以响应事件的小程序。这些程序既可以帮忙你了解系统正在发生什么,也可以用来控制系统。
现在让我们来深入了解一下详细细节。
什么是 eBPF?
BPF 的第一个版本于 1994 年问世。有些人在为 tcpdump 实用程序编写用于查看或“嗅探”网络数据包的简单规则时,可能会遇到过它。你可以为 tcpdump 设置过滤器,这样你就不必查看所有的内容,只需查看你感兴趣的数据包即可。例如,“只查看 TCP 协议和 80 端口”。对于每个传递的数据包,都会运行一个函数来确定其是否需要保存有问题的特定数据包。可能会有很多数据包,所以我们的函数必须要很快。实际上,我们的 tcpdump 过滤器被转换为 BPF 函数。下面是一个例子。
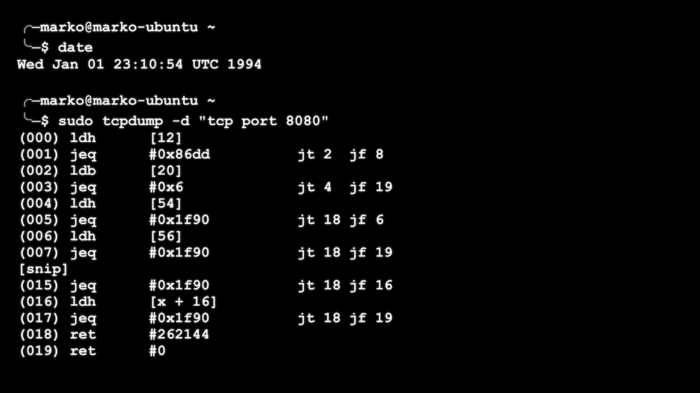
一个简单的以 BPF 程序形式呈现的 tcpdump 过滤器
最初的 BPF 代表了一个非常简单带有多个寄存器的虚拟机。但是,尽管如此,BPF 还是大大加快了网络数据包的过滤速度。在当时,这是一个很重要的进步。
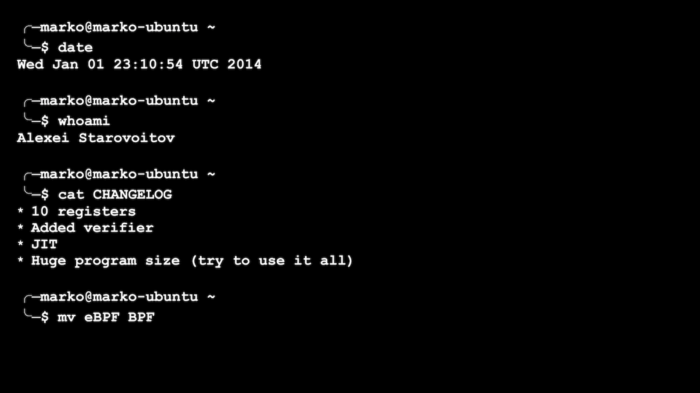
在 2014 年,Alexei Starovoitov,一个非常著名的内核黑客,扩展了 BPF 的功能。他增加了寄存器的数量和程序允许的大小,添加了 JIT 编译,并创建了一个用于检查程序是否安全的检查器。然而,最令人印象深刻的是,新的 BPF 程序不仅能够在处理数据包时运行,而且还能够响应其他内核事件,并能在内核和用户空间之间来回传递信息。
这些变化为使用 BPF 的新方法提供了机会。一些过去需要通过编写复杂而危险的内核模块来实现的功能,现在可以相对简单地通过 BPF 来实现。为什么能这么好呢?是因为在编写模块时,任何错误通常都会导致死机(panic),不是“温和”Go 风格的死机,而是内核死机,一旦发生,我们唯一能做的就是重启。
普通的 Linux 用户突然拥有了一项新的超能力:能够查看“引擎盖下”的情况——这是以前只有核心内核开发人员才能使用的东西,或者根本不会提供给任何人。这个选项可以与为 iOS 或 Android 编写程序的能力相媲美:在旧手机上,这要么是不可能的,要么就是要复杂得多。
Alexei Starovoitov 新版本的 BPF 被称为 eBPF(e 代表扩展,extended)。但是现在它已经取代了所有旧的 BPF 用法,并且已经变得非常流行了,为了简单起见,它仍然被称为 BPF。
BPF 可用于何处?
好了,你可以将 BPF 程序附加到哪些事件或触发器上呢,人们又是如何开始使用它们以获取新的能力的呢?
目前,主要有两大组触发器。
第一组用于处理网络数据包和管理网络流量。它们是 XDP、流量控制事件及其他几个事件。
以下情况需要用到这些事件:
创建简单但非常有效的防火墙。Cloudflare 和 Facebook 等公司使用 BPF 程序来过滤掉大量的寄生流量,并打击最大规模的 DDoS 攻击。由于处理发生在数据包生命的最早阶段,直接在内核中进行(BPF 程序的处理有时甚至可以直接推送到网卡中进行),因此可以通过这种方式处理巨量的流量。这些事情过去都是在专门的网络硬件上完成的。
创建更智能、更有针对性、但性能更好的防火墙——这些防火墙可以检查通过的流量是否符合公司的规则、是否存在漏洞模式等。例如,Facebook 在内部进行这种审计,而一些项目则对外销售这类产品。
创建智能负载均衡器。最突出的例子就是 Cilium 项目,它最常被用作 K8s 集群中的网格网络。Cilium 对流量进行管理、均衡、重定向和分析。所有这些都是在内核运行的小型 BPF 程序的帮助下完成的,以响应这个或那个与网络数据包或套接字相关的事件。
这是第一组与网络问题相关并能够影响网络通信行为的触发器。 第二组则与更普遍的可观察性相关;在大多数情况下,这组的程序无法影响任何事件,而只能“观察”。这才是我更感兴趣的。
这组的触发器有如下几个:
perf 事件(perf events)——与性能和 perf Linux 分析器相关的事件:硬件处理器计数器、中断处理、小/大内存异常拦截等等。例如,我们可以设置一个处理程序,每当内核需要从 swap 读取内存页时,该处理程序就会运行。例如,想象有这样一个实用程序,它显示了当前所有使用 swap 的程序。
跟踪点(tracepoints)——内核源代码中的静态(由开发人员定义)位置,通过附加到这些位置,你可以从中提取静态信息(开发人员先前准备的信息)。在这种情况下,静态似乎是一件坏事,因为我说过,日志的缺点之一就是它们只包含了程序员最初放在那里的内容。从某种意义上说,这是正确的,但跟踪点有三个重要的优势:
有相当多的跟踪点散落在内核中最有趣的地方
当它们不“开启”时,它们不使用任何资源
它们是 API 的一部分,它们是稳定的,不会改变。这非常重要,因为我们将提到的其他触发器缺少稳定的 API。
例如,假设有一个关于显示的实用程序,内核出于某种原因没有给它时间执行。 你坐着纳闷为什么它这么慢,而 pprof 却没有显示任何什么有趣的东西。
USDT——与跟踪点相同,但是它适用于用户空间的程序。也就是说,作为程序员,你可以将这些位置添加到你的程序中。并且许多大型且知名的程序和编程语言都已经采用了这些跟踪方法:例如 MySQL、或者 PHP 和 Python 语言。通常,它们的默认设置为“关闭”,如果要打开它们,需要使用 enable-dtrace 参数或类似的参数来重新构建解释器。是的,我们还可以在 Go 中注册这种类跟踪。你可能已经识别出参数名称中的单词DTrace。关键在于,这些类型的静态跟踪是由Solaris操作系统中诞生的同名系统所推广的。例如,想象一下,何时创建新线程、何时启动 GC 或与特定语言或系统相关的其他内容,我们都能够知道是怎样的一种场景。
这是另一种魔法开始的地方:
Ftrace 触发器为我们提供了在内核的任何函数开始时运行 BPF 程序的选项。这是完全动态的。这意味着内核将在你选择的任何内核函数或者在所有内核函数开始执行之前,开始执行之前调用你的 BPF 函数。你可以连接到所有内核函数,并在输出时获取所有调用的有吸引力的可视化效果。
kprobes/uprobes 提供的功能与 ftrace 几乎相同,但在内核和用户空间中执行函数时,你可以选择将其附加到任何位置上。如果在函数的中间,变量上有一个“if”,并且能为这个变量建立一个值的直方图,那就不是问题。
kretprobes/uretprobes——这里的一切都类似于前面的触发器,但是它们可以在内核函数或用户空间中的函数返回时触发。这类触发器便于查看函数的返回内容以及测量执行所需的时间。例如,你可以找出“fork”系统调用返回的 PID。
我再重复一遍,所有这些最奇妙之处在于,当我们的 BPF 程序为了响应这些触发器而被调用之后,我们可以很好地“环顾四周”:读取函数的参数,记录时间,读取变量,读取全局变量,进行堆栈跟踪,保存一些内容以备后用,将数据发送到用户空间进行处理,和/或从用户空间获取数据或一些其他控制命令以进行过滤。简直不可思议!
我不知道你是怎么想的,但对我来说,这个新的基础设施就像是一个我很早之间就想要得到的玩具一样。
API:怎么使用它
好了,让我们开看一下 BPF 程序由什么组成的,以及如何与它交互。
首先,我们有一个 BPF 程序,如果它通过验证,就会被加载到内核中。在那里,它将被 JIT 编译器编译成机器码,并在内核模式下运行,这时附加的触发器将会被激活。
BPF 程序可以选择与第二部分交互,即与用户空间程序交互。有两种方式可以做到这一点。我们可以向循环缓冲区写入,而用户空间程序可以从中读取。我们也可以对键值映射(也就是所谓 BPF 映射)进行写入和读取,相应地,用户空间程序也可以做同样的事情,并且相应地,它们就可以相互传递信息了。
基本用法
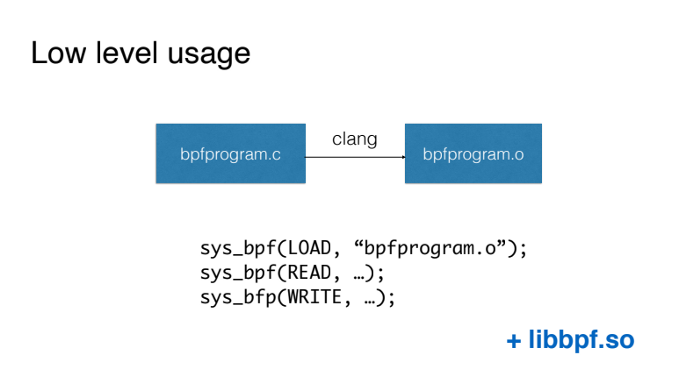
使用 BPF 最简单的方法是用 C 语言编写 BPF 程序,然后用 Clang 编译器将相关的代码编译成虚拟机的代码(在任何情况下都不应该采用这种从头开始的方式)。然后,我们直接使用 BPF 系统调用加载该代码,并同样采用 BPF 系统调用的方式与我们的 BPF 程序进行交互。
第一种可用的简化方法是使用 libbpf 库。它是随内核源代码一起提供的,允许我们直接使用 BPF 系统调用。基本上,它为加载代码和使用 BPF 映射将数据从内核发送到用户空间并返回提供了方便的包装器。
bcc
显然,这对人们来说一点也不方便。幸运的是,在 iovizor 这个品牌下,BCC 项目出现了,这使我们的生活变得更加轻松了。

基本上,它为我们准备了整个构建环境,并允许我们编写单个的 BPF 程序,其中С语言部分会被自动构建并加载到内核中,而用户空间部分则可以用 Python 来实现,这既简单又清晰明了。
bpftrace
然而,BCC 似乎在很多方面都很复杂。出于某些原因,人们特别不喜欢用С语言来写内核的这部分。
同样那些来自 iovizor 的人也提供了一个工具,bpftrace,它允许我们用类似于 AWK 这样的简单脚本语言(甚至是单行代码)来编写 BPF 脚本。

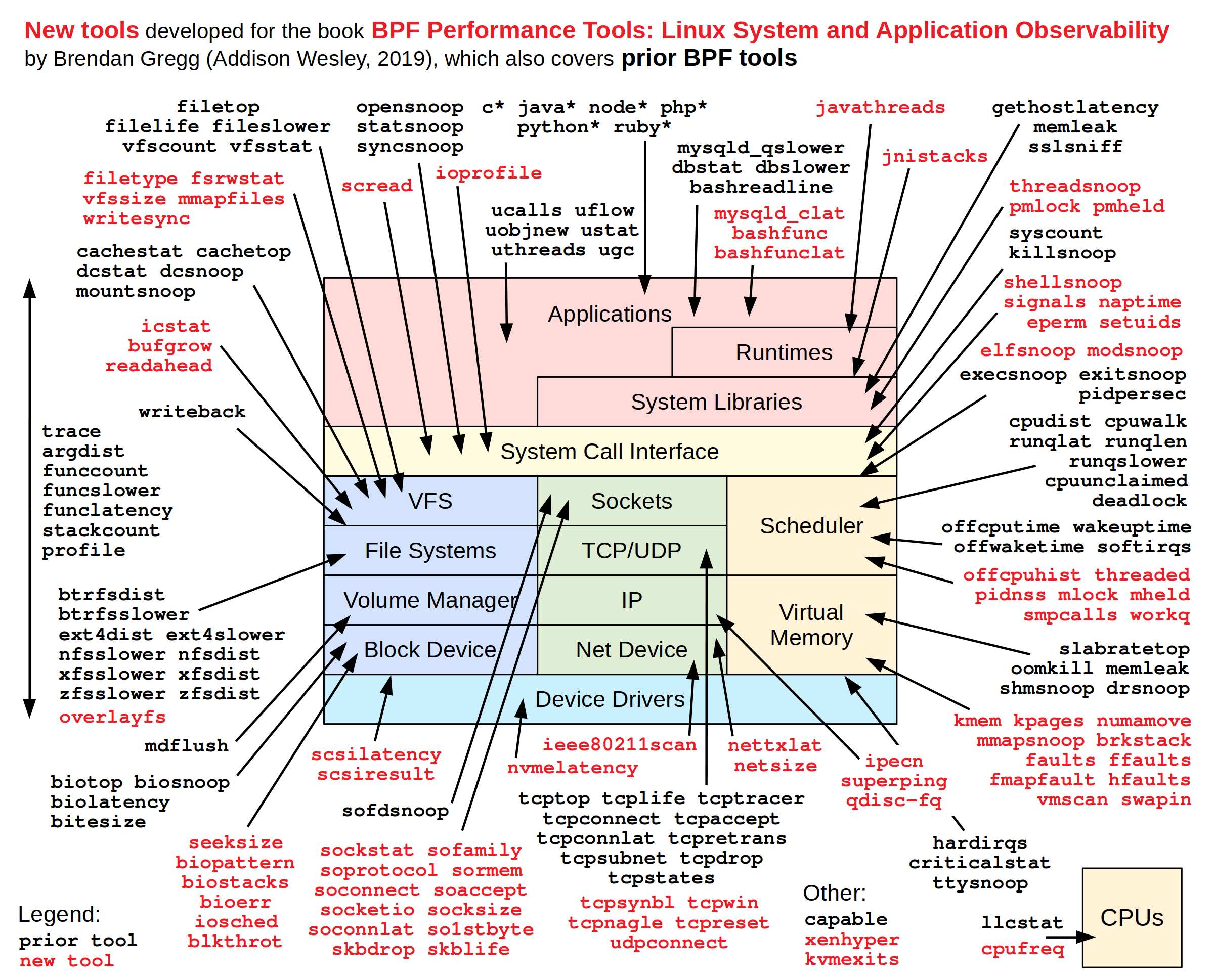
Brendan Gregg 是生产力和可观察性领域的知名专家,他对 BPF 的可用工作方式进行了可视化,如下图所示:

纵轴显示的是给定工具的易用性,而横轴显示则是其功能。我们可以看到,BCC 是一个非常强大的工具,但它并不是一个超级简单的工具。而 bpftrace 要简单得多,但同时,它的功能则稍弱一些。
使用 BPF 的示例
现在,让我们来看一些具体的例子,看看这些我们可以利用的神奇的力量。
BCC 和 bpftrace 都包含了一个“工具”目录,其中包含了大量的有趣且有用的现成脚本。它们也可以用作本地的 Stack Overflow,你可以从中复制代码块以用于自己的脚本。
例如,下面是一个显示 DNS 查询延迟的脚本:
╭─marko@marko-home ~╰─$ sudo gethostlatency-bpfccTIME PID COMM LATms HOST16:27:32 21417 DNS Res~ver #93 3.97 live.github.com16:27:33 22055 cupsd 7.28 NPI86DDEE.local16:27:33 15580 DNS Res~ver #87 0.40 github.githubassets.com16:27:33 15777 DNS Res~ver #89 0.54 github.githubassets.com16:27:33 21417 DNS Res~ver #93 0.35 live.github.com16:27:42 15580 DNS Res~ver #87 5.61 ac.duckduckgo.com16:27:42 15777 DNS Res~ver #89 3.81 www.facebook.com16:27:42 15777 DNS Res~ver #89 3.76 tech.badoo.com :-)16:27:43 21417 DNS Res~ver #93 3.89 static.xx.fbcdn.net16:27:43 15580 DNS Res~ver #87 3.76 scontent-frt3-2.xx.fbcdn.net16:27:43 15777 DNS Res~ver #89 3.50 scontent-frx5-1.xx.fbcdn.net16:27:43 21417 DNS Res~ver #93 4.98 scontent-frt3-1.xx.fbcdn.net16:27:44 15580 DNS Res~ver #87 5.53 edge-chat.facebook.com16:27:44 15777 DNS Res~ver #89 0.24 edge-chat.facebook.com16:27:44 22099 cupsd 7.28 NPI86DDEE.local16:27:45 15580 DNS Res~ver #87 3.85 safebrowsing.googleapis.com^C%
这是一个实时显示 DNS 查询完成时间的实用程序,因此,你可以捕获一些意外的异常值(举个例子)。
如下则是一个“监视”别人在终端上输入的内容的脚本:
╭─marko@marko-home ~╰─$ sudo bashreadline-bpfcc TIME PID COMMAND16:51:42 24309 uname -a16:52:03 24309 rm -rf src/badoo
这种脚本可以用来捕获“坏邻居”,或者对公司的服务器执行安全审计。
用于查看高级语言调用流的脚本如下所示:
╭─marko@marko-home ~/tmp╰─$ sudo /usr/sbin/lib/uflow -l python 20590Tracing method calls in python process 20590... Ctrl-C to quit.CPU PID TID TIME(us) METHOD5 20590 20590 0.173 -> helloworld.py.hello 5 20590 20590 0.173 -> helloworld.py.world 5 20590 20590 0.173 <- helloworld.py.world 5 20590 20590 0.173 <- helloworld.py.hello 5 20590 20590 1.174 -> helloworld.py.hello 5 20590 20590 1.174 -> helloworld.py.world 5 20590 20590 1.174 <- helloworld.py.world 5 20590 20590 1.174 <- helloworld.py.hello 5 20590 20590 2.175 -> helloworld.py.hello 5 20590 20590 2.176 -> helloworld.py.world 5 20590 20590 2.176 <- helloworld.py.world 5 20590 20590 2.176 <- helloworld.py.hello 6 20590 20590 3.176 -> helloworld.py.hello 6 20590 20590 3.176 -> helloworld.py.world 6 20590 20590 3.176 <- helloworld.py.world 6 20590 20590 3.176 <- helloworld.py.hello 6 20590 20590 4.177 -> helloworld.py.hello 6 20590 20590 4.177 -> helloworld.py.world 6 20590 20590 4.177 <- helloworld.py.world 6 20590 20590 4.177 <- helloworld.py.hello ^C%
Brendan Gregg 同样制作了一张图片,它汇集了所有相关的脚本,箭头指向每个实用程序允许你观察的子系统。正如你所看到的那样,我们已经拥有了大量的随时可用的实用程序以供我们使用,实际上它们几乎已经可以应对任何可能发生的情况了。
不要试图阅读图片上的任何内容。 该图片仅供参考
那 Go 呢?
现在我们来谈谈 Go。我们有两个基本问题:
你能用 Go 编写 BPF 程序吗?
我们能分析用 Go 编写的程序吗?
我们按顺序来逐步看下。
目前,唯一能够编译成 BPF 机器可以理解的格式的编译器是 Clang。另一种流行的编译器 GСС仍然没有 BPF 后端。而能够编译成 BPF 的编程语言,只有 C 语言的一个非常受限的版本。
然而,BPF 程序还有一个在用户空间中的第二部分。这部分可以用 Go 来编写。
正如我前面提到的那样,BCC 允许你用 Python 编写这一部分,而 Python 是该工具的主要语言。同时,在主库中,BCC 还支持 Lua 和 C++,并且在辅库中,它还支持Go。

这个程序看起来和 Python 中的程序完全一样。一开始,它有一个字符串,其中的 BPF 程序是 C 语言编写的,然后我们通信将给定的程序附加到那里,并以某种方式与它进行交互,例如,从 BPF 映射中提取数据。
基本上就是这样。可以在Github上查看这个例子的更多详细信息。
主要的缺点可能是,我们使用的是 C 库、libbcc 或 libbpf,而用 C 库构建 Go 程序远非“在公园里散步”那么容易。
除了 iovisor/gobpf 之外,我还发现了其他三个最新的项目,它们允许你在 Go 中编写用户空间(userland)部分。
Dropbox 的版本不需要任何 C 库,但你需要自己使用 Clang 构建 BPF 的内核部分,然后使用 Go 程序将其加载到内核中。
Cilium 版本与 Dropbox 版本具有相同的细节。但值得一提的是,它是由来自 Cilium 项目的人制作的,这意味着它只能成功。
出于完整性的考虑,我列出了第三个项目。就像前面两个项目一样,它没有外部的 C 语言依赖项,需要用 C 语言手动构建 BPF 程序,但是,它的前途看起来并不是特别好。
事实上,我们还应该问一个问题:为什么要用 Go 来编写 BPF 程序?因为如果你看 BCC 或 bpftrace,那么 BPF 程序只占用不到 500 行代码。但是,仅仅用 bpftrace 语言编写一个小脚本,或者使用一点 Python,不是更简单吗?我有两个理由不支持这样做。
第一个原因是:你真的很喜欢 Go,并且更愿意用 Go 来做所有的事情。此外,将 Go 程序从一台机器迁移到另一台机器可能会更简单:静态链接、简单的二进制文件等等。但事情远没有这么简单,因为我们被绑定到一个特定的内核上。我就讲到这里吧,否则,我的文章又要多 50 页了。
第二个原因是:你编写的不是一个简单的脚本,而是一个大型的系统,它也在内部使用了 BPF。我甚至在Go中看到过一个关于这样的系统的例子:
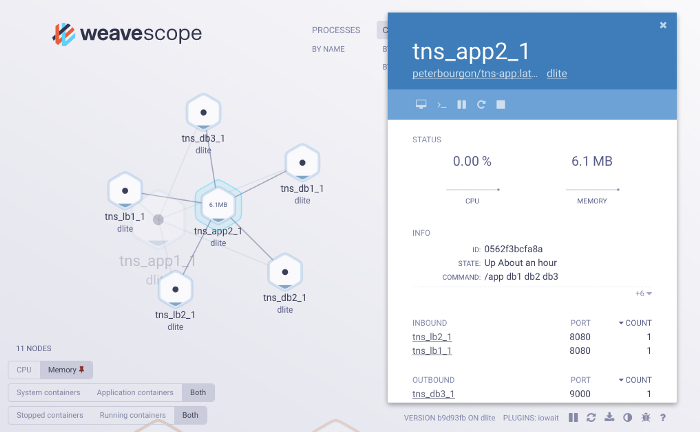
Scope 项目看起来像是一个二进制文件,当它在 K8s 或其他的云基础设施上运行时,它会分析周围发生的一切,并显示有哪些容器和服务,以及它们是如何交互的等等。这些很多都是用 BPF 来实现的。这是一个有趣的项目。
Go 程序分析
如果你还记得,我们还有一个问题:我们可以用 BPF 来分析用 Go 编写的程序吗?我们的第一反应是,“可以,我们可以!”程序用什么语言编写又有什么区别呢?毕竟,它只是编译后的代码,就像其他程序一样,在处理器中计算一些东西,疯狂地占用内存,并通过内核与硬件交互,通过系统调用与内核交互。原则上这是正确的,但也有一些具体问题——这些问题有不同程度的复杂性。
传递参数
其中一个问题是,Go 不使用大多数其他语言所使用的 ABI(Application binary interface,应用二进制接口)。结果是,这位“开创者”决定将 ABI 从它们所熟悉的Plan 9系统中移除。
与 API 一样,ABI 也是一种接口约定——只是在位、字节和机器码级别。
我们对 ABI 感兴趣的点主要在于它的参数是如何传递给函数的,以及响应是如何从函数中返回的。如果在标准的 ABI x86-64 中,处理器的寄存器是用于传递参数和响应的,而在 Plan 9 ABI 中,堆栈则是用于实现该目标。
Rob Pike 和他的团队并没有打算制定另一个标准;他们已经为 Plan 9 系统提供了一个几乎随时可用的 C 编译器,就像计算 2x2 一样简单。在很短的时间内,他们将其改造成了 Go 编译器。这就是一个工程师的方法。
然而,事实上,这并不是一个关键问题。 一方面,我们可能很快就会看到参数在 Go 中通过寄存器来传递,其次,从 BPF 中获取堆栈参数并不复杂:sargX别名已经添加到了 bpftrace 中,另一个别名很可能会在不久的将来出现在 BCC 中。
更新:自从我做了演讲之后,Go 官方的详细提案甚至已经出台,并建议在 ABI 中使用寄存器。
唯一线程标识符
第二个具体问题与 Go 的一个深受喜爱的特性相关,即 goroutines。度量函数延迟的方法之一是保存函数被调用的时间,获取函数的退出时间,并计算其差值。我们需要保存开始时间以及一个包含函数名和 TID(线程 ID)的键。线程 ID 是必需的,因为同一个函数可以被不同的程序或者被同一个程序的不同线程同时调用。

但是,在 Go 中,goroutine 在系统线程之间移动:前一分钟,goroutine 在一个线程上执行,下一分钟,则在另一个线程上执行。而且,在 Go 的情况下,最好不要将 TID 放入键中,而是将 GID(即 goroutine 的 ID)放入其中,这对我们来说是有好处的,但不幸的是,我们无法获得它。从纯技术的角度来看,这个 ID 确实存在。你甚至可以使用肮脏的黑客攻击来提取它,因为可以在堆栈中的某个位置找到它,但这样做是被关键开发人员小组建议严格禁止的。他们认为这是我们永远不需要的信息。对于 goroutine 的本地存储也是如此,但这是偏离主题的。
扩展栈
第三个问题是最严重的。它是如此严重,以至于即使我们以某种方式解决了第二个问题,也无法帮助我们度量 Go 函数的延迟。
大多数读者可能已经对什么是栈有了很好的理解。这是同一个栈中,与堆不同,你可以为变量分配内存,而不必考虑释放。
但是对于 C 语言来说,在这种情况下,栈的大小是固定的。如果超出了这个固定的大小,就会出现众所周知的堆栈溢出现象。
在 Go 中,栈是动态的。在旧版本中,它是通过内存块的链表实现的。现在,它是一个大小动态变化的连续块。这意味着,如果分配的内存块对我们来说不够,我们就扩展当前的内存块。如果我们不能扩展它,我们就分配一个更大的,然后把所有的数据从旧的位置移动到新的位置。这一点非常吸引人,并且涉及了安全保证、cgo 和垃圾收集等问题,但这是另一篇文章的主题。
重要的是要知道,为了让 Go 能够移动栈,它必须能够调用栈,并遍历栈中的所有指针。
而这就是基本问题的所在之处:uretprobes,用于将 BPF 探测附加到函数的返回重,动态地改变栈,以集成对其处理程序的调用,也就是所谓的“蹦床”(trampoline)。而且,在大多数情况下,这会改变栈,这是 Go 不期望的事情,它会导致程序的崩溃。糟糕!
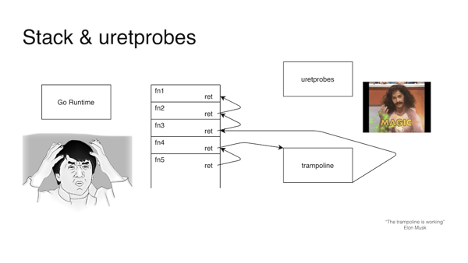
顺便说一句,这并不是 Go 所独有的。当处理异常时,C++栈拆分器也会每隔一段时间就崩溃一次。
这个问题没有解决的办法。像往常一样,在这种情况下,双方都会相互指责对方,并各自都能提出完全有根据的论点。
但是,如果你真的需要设置一个 uretprobe,有一种方法可以绕过这个问题。怎么用呢?不要设置 uretprobe。你可以在退出函数的所有位置设置一个 uprobe。可能只有一个这样的位置,也可能有五十个这样的位置。

这就是 Go 的独特之处。
通常情况下,这种伎俩是行不通的。一个足够聪明的编译器知道如何执行所谓的尾部调用优化,当我们只是简单地跳到下一个函数的开始处,而不是从函数返回并沿着调用栈返回时。这种优化对于诸如Haskell这样的函数式语言来说至关重要。如果没有它,在不发生堆栈溢出的情况下,你就会寸步难行。然而,通过这种优化,我们根本不可能找到从函数返回的所有位置。
具体来说,Go 1.14 版本的编译器还不能执行尾部调用优化。 这意味着,附加到函数的所有显式退出的技巧都是有效的,即使它非常笨重。
示例
不要认为 BPF 对 Go 没用。远非如此。我们可以做所有其他不涉及上述问题的事情。而且我们也会这样做的。
让我们来看一些例子。
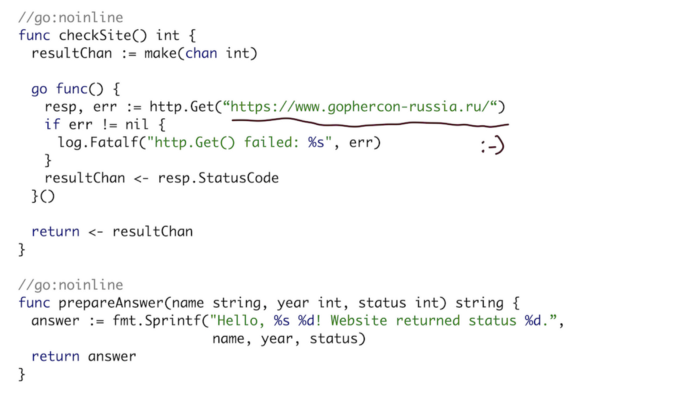
首先,让我们来看一个简单的程序。基本上,它是一个监听 8080 端口的 Web 服务器,并有一个 HTTP 查询的处理程序。处理程序从 URL 中获取名称参数和年份参数,执行检查,然后将所有这三个变量(名称、年份和检查状态)发送到 prepareAnswer()函数,然后该函数准备一个字符串形式的答案。

站点检查(Site check)是一个 HTTP 查询,通过通道和 goroutines 检查会议站点是否正常工作。prepare 函数只是简单地将所有这些参数转换为一个可读的字符串。
我们将通过 curl 进行简单的查询来触发我们程序:
对于我们的第一个示例,我们将使用 bpftrace 打印所有程序的函数调用。在这种情况下,我们将对“main”下的所有函数进行附加。在 Go 中,所有函数都有一个符号,其形式如下:包名.函数名。我们的包是“main”,函数的运行时是“runtime”。
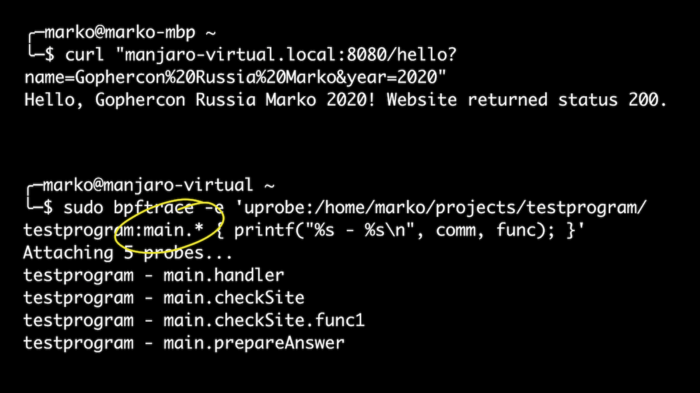
当我使用 curl 时,会执行处理程序、站点检查函数和 goroutine 子函数,然后执行准备答案函数。太好了!
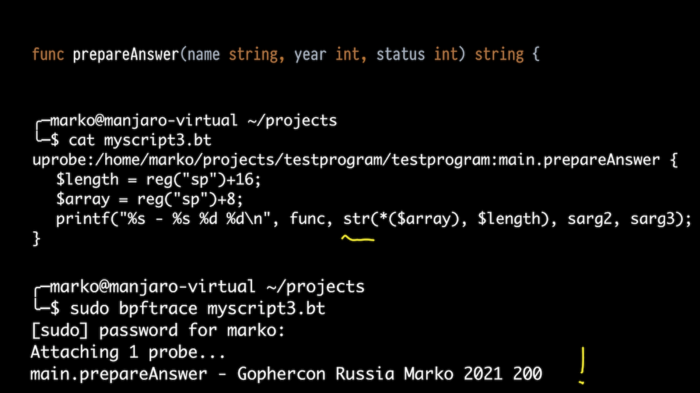
接下来,我不仅要导出那些正在执行的函数,还要导出它们的参数。让我们以函数 prepareAnswer() 为例。它有三个参数。让我们试着输出两个整数。
让我们以 bpftrace 为例,只不过这次不是执行单行代码,而是执行一个脚本,我们将其附加到我们的函数上,并使用别名作为堆栈的参数,就像我所说的那样。
在输出中,我们可以看到,我们发送了 2020,获取的状态是 200,此外,还发送了一次 2021。
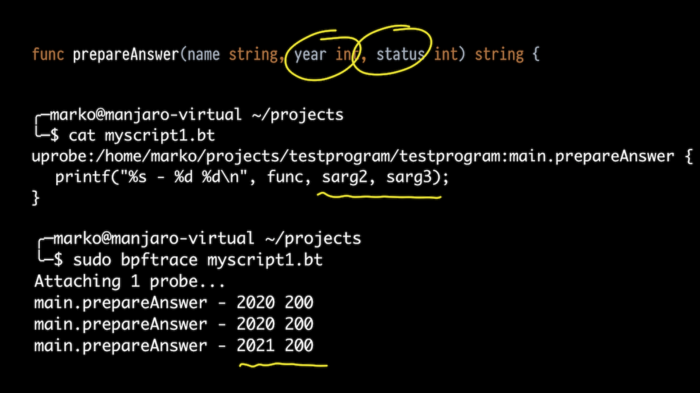
但是这个函数有三个参数。其中第一个参数是字符串。那它怎么处理呢?
让我们简单地导出从 0 到 3 的所有堆栈参数。我们看到了什么?一个很大的数字,一个稍小点的数字,还有我们原来的数字 2021 年和 200。开头这些奇怪的数字是什么呢?
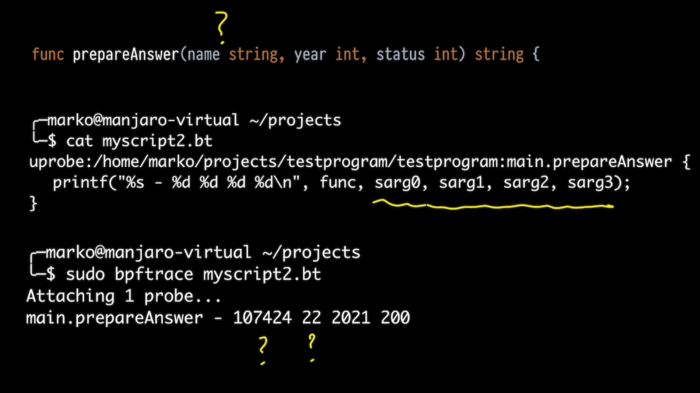
这时,熟悉 Go 的内部结构是很有帮助的。如果在 C 语言中,字符串只是一个以 0 结尾的字节数组,那么在 Go 中,字符串实际上是一个结构体,它由指向字节数组的指针(顺便说一句,这它不是以 0 结尾的)和长度组成。
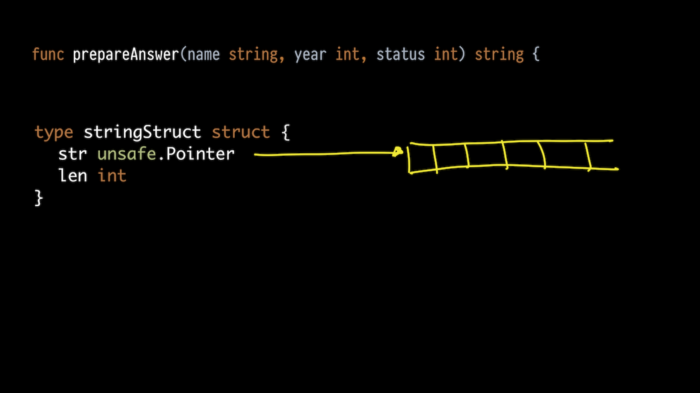
但是 Go 编译器,当它以参数的形式发送一个字符串时,会展开这个结构体,并将它作为两个参数发送。 所以,第一个奇怪的数字确实是一个指向我们数组的指针,第二个是长度。
果然:预期的字符串长度是 22。
相应地,我们稍微修正了一下我们的脚本,以便通过堆栈指针寄存器获取问题中的两个值及其正确的偏移量,并且在集成的 str()函数的帮助下,我们将其导出为字符串。 一切顺利:
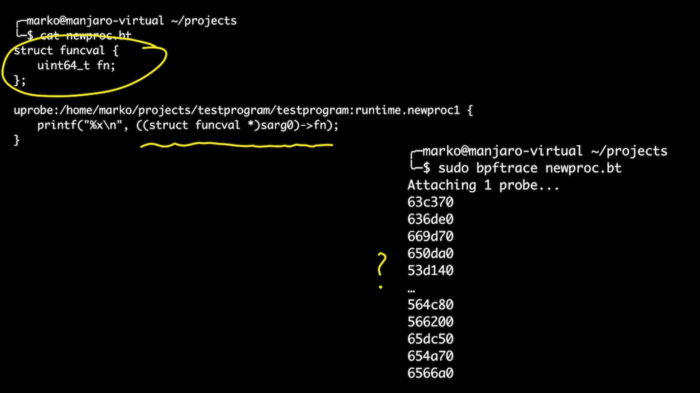
我们也来看看运行时。 例如,我想知道我们的程序启动了哪些 goroutines。我们知道 goroutines 是由函数 newproc()和 newproc1()启动的。 让我们附着一下它们。 指向函数结构的指针是 newproc1()函数的第一个参数。它只有一个字段,即指向函数的指针:
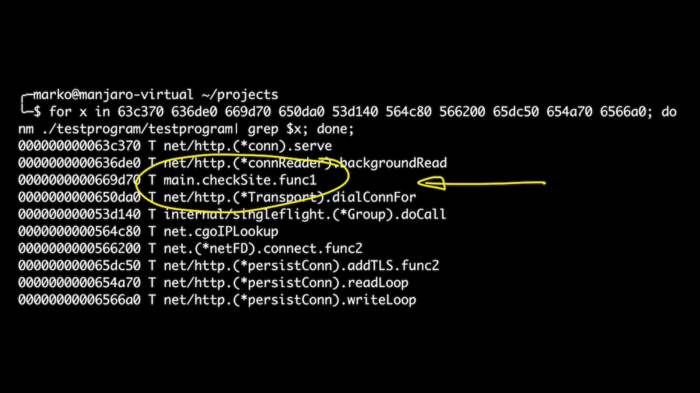
在本例中,我们将使用直接在脚本中定义结构的功能。 这比玩偏移要简单一些。 我们已经导出了处理程序被调用时启动的所有 goroutines。之后,如果我们想要获取偏移量的符号名称,那么我们就可以在其中看到我们的 checkSite 函数了。 欢呼!
就 BPF、BCC 和 bpftrace 的功能而言,这些示例只是沧海一粟。只要对内部工作原理有了足够的了解和经验,你就可以从一个正在运行的程序中获得几乎所有的信息,而无需停止或更改它。
结论
这就是我想告诉你的全部内容,我希望它对你有所启发。
BPF 是 Linux 中最流行也是最有前途的领域之一。而且我相信,在未来的几年里,我们将会看到更多有趣的东西——不仅是技术本身,还有工具以及它的传播。
现在开始还不算太晚,并不是每个人都知道 BPF,所以赶快开始学习吧,成为魔术师,解决问题,帮助你的同事。他们都说魔术只有一次效果。
当谈到 Go 时,像往常一样,我们最终会变得非常独特。 我们总是有一些怪癖,无论是不同的编译器,还是 ABI,需要 GOPATH,有一个你无法 Google 的名字。 但我认为,可以说我们已经成为一股不可忽视的力量,在我看来,事情只会变得越来越好。
原文链接:
https://medium.com/bumble-tech/bpf-and-go-modern-forms-of-introspection-in-linux-6b9802682223#e0e4





{kind=link}