
大型语言模型(LLM)正在深刻地影响自然语言处理(NLP)领域,其强大的处理各种任务的能力也为其他领域的从业者带来了新的探索路径。推荐系统(RS)作为解决信息过载的有效手段,已经紧密融入我们的日常生活,如何用 LLM 有效重塑 RS 是一个有前景的研究问题[20, 25]。
这篇文章从生成式推荐系统和京东联盟广告的背景入手,首先引出两者结合的动因与策略,随后我们对当前的流程和方法进行了细致的回顾与整理,最后详细介绍了我们在京东联盟广告领域的应用实践。通过深入分析与案例展示,本文旨在为广告领域的推荐系统带来新的见解和启发。
一、背景
生成式推荐系统
A generative recommender system directly generates recommendations or recommendation-related content without the need to calculate each candidate’s ranking score one by one[25].
由于现实系统中的物料(item)数量巨大,传统 RS 通常采用多级过滤范式,包括召回、粗排、精排、重排等流程,首先使用一些简单而有效的方法(例如,基于规则/策略的过滤)来减少候选物料的数量,从数千万甚至数亿到数百个,然后对这些物料应用较复杂的推荐算法,以进一步选择较少数量的物料进行推荐。受限于响应时间的要求,复杂推荐算法并不适用于规模很大的所有物料。
LLM 的生成能力有可能重塑 RS,相较于传统 RS,生成式推荐系统具备如下的优势:1)简化推荐流程。LLM 可以直接生成要推荐的物料,而非计算候选集中每个物料的排名分数,实现从多级过滤范式(discriminative-based,判别式)到单级过滤范式(generative-based,生成式)的变迁。LLM 在每个解码步生成一个向量,表示在所有可能词元(token)上的概率分布。经过几个解码步,生成的 token 就可以构成代表目标物料的完整标识符,该过程隐式枚举所有候选物料以生成推荐目标物料[25]。2)具备更好的泛化性和稳定性。利用 LLM 中的世界知识和推理能力,在具有新用户和物料的冷启动和新领域场景下具备更好的推荐效果和迁移效果。同时,相比于传统 RS,生成式推荐系统的方法也更加具备稳定性和可复用性。特征处理的策略随场景和业务的变化将变小、训练数据量将变少,模型更新频率将变低。
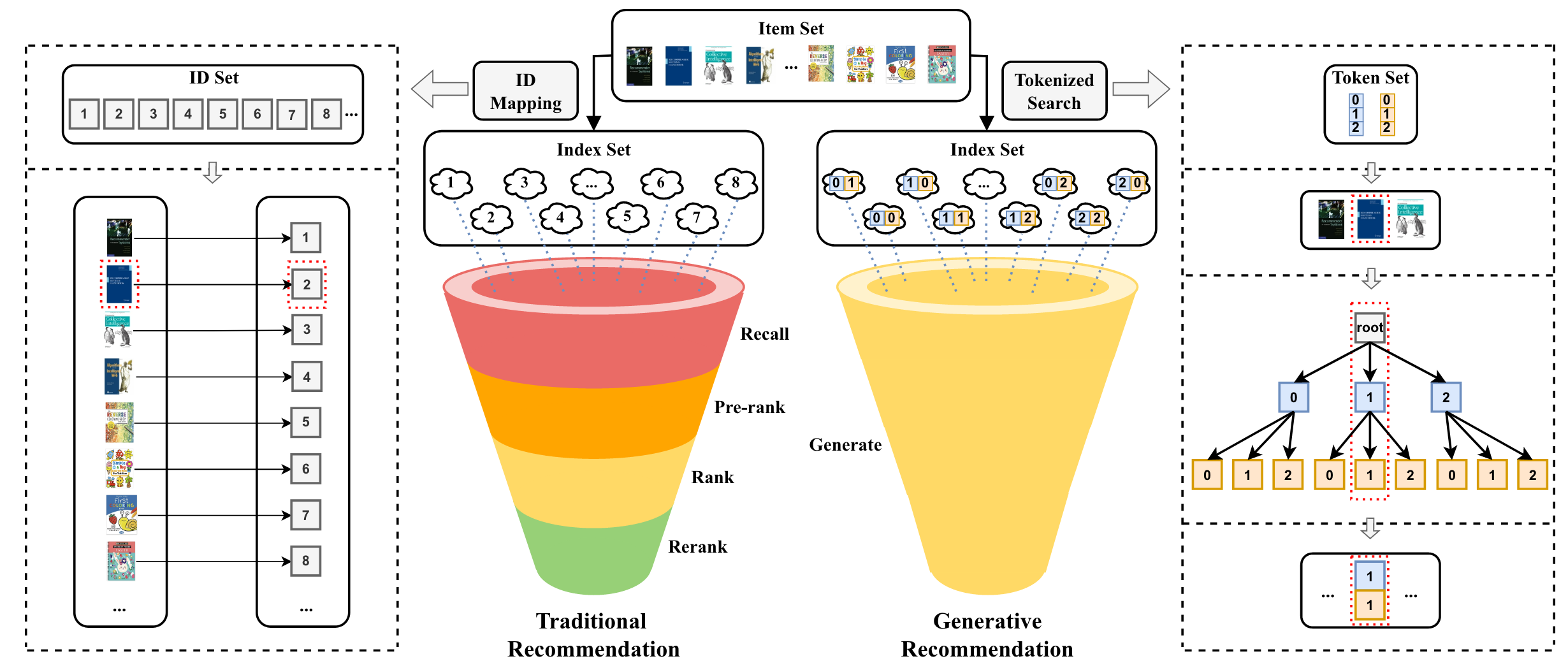
•图 1. 传统推荐系统与基于 LLM 的生成式推荐系统的流程比较[25]
京东联盟广告
京东联盟是京东的一个联盟营销平台,以投放站外 CPS 广告为主。联盟合作伙伴通过生成的链接在其他网站或社交媒体平台上推广京东商品,引导用户点击这些链接并在京东购物,从而获得销售提成(佣金)。京东联盟借此吸引流量,扩大平台的可见度和与用户的接触范围,实现拉新促活等目标。
联盟广告推荐主要针对低活跃度用户进行多场景推荐,这样的推荐面临如下的挑战:1)数据稀疏性:低活跃度用户提供的数据较少,导致更加明显的数据稀疏性问题。数据不足使得基于 ID 的传统推荐模型难以充分地对物料和用户进行表征,进而影响推荐系统的预测准确性。2)冷启动问题:对于新用户或低活跃度用户,冷启动问题尤为严重。由于缺乏足够的历史交互数据,推荐系统难以对这些用户进行有效的个性化推荐。3)场景理解困难:在多场景推荐系统中,理解不同场景下用户的具体需求尤为关键。对于低活跃度用户,由于交互数据有限,推荐系统更难以识别出用户在不同场景下的行为差异和需求变化。4)多样性和新颖性:保持推荐内容的多样性和新颖性对于吸引低活跃度用户至关重要。然而,由于对这些用户的了解有限,推荐系统难以平衡推荐的准确性与多样性。
京东联盟广告+生成式推荐系统
将 LLM 融入推荐系统的关键优势在于,它们能够提取高质量的文本表示,并利用其中编码的世界知识对用户和物料进行理解和推荐。与传统的推荐系统不同,基于 LLM 的模型擅长捕获上下文信息,更有效地理解用户信息、物料描述和其他文本数据。通过理解上下文,生成式推荐系统可以提高推荐的准确性和相关性,从而提升用户满意度。同时,面对有限的历史交互数据带来的冷启动和数据稀疏问题,LLM 还可通过零/少样本推荐能力为推荐系统带来新的可能性。这些模型可以推广到未见过的新物料和新场景,因为它们通过事实信息、领域专业知识和常识推理进行了广泛的预训练,具备较好的迁移和扩展能力。
由此可见,京东联盟广告是生成式推荐系统一个天然的应用场。
二、生成式推荐系统的四个环节
为了实现如上的范式变迁,有四个基本环节需要考虑[26]:1)物料表示:在实践中,直接生成物料(文档或商品描述)几乎是不可能的。因此,需要用短文本序列,即物料标识符,表示物料。2)模型输入表示:通过提示词定义任务,并将用户相关信息(例如,用户画像和用户历史行为数据)转换为文本序列。3)模型训练:一旦确定了生成模型的输入(用户表示)和输出(物料标识符),就可以基于 Next Token Prediction 任务实现训练。4)模型推理:训练后,生成模型可以接收用户信息来预测对应的物料标识符,并且物料标识符可以对应于数据集中的真实物料。
虽然整个过程看起来很简单,但实现有效的生成式推荐并非易事。在上述四个环节中需要考虑和平衡许多细节。下面详细梳理了现有工作在四个环节上的应用与探索:
物料表示
An identifier in recommender systems is a sequence of tokens that can uniquely identify an entity, such as a user or an item. An identifier can take various forms, such as an embedding, a sequence of numerical tokens, and a sequence of word tokens (including an item title, a description of the item, or even a complete news article), as long as it can uniquely identify the entity[25].
推荐系统中的物料通常包含来自不同模态的各种信息,例如,视频的缩略图、音乐的音频和新闻的标题。因此,物料标识符需要在文本空间中展示每个物料的复杂特征,以便进行生成式推荐。一个好的物料标识符构建方法至少应满足两个标准:
1)保持合适的长度以减轻文本生成的难度。 2)将先验信息集成到物料索引结构中,以确保相似项目在可区分的同时共享最多的 token,不相似项目共享最少的 token。
以下是几种构建物料标识符的方法:
(1)数字 ID(Numeric ID)
由于数字在传统 RS 中被广泛地使用,一个直接的策略是在生成式推荐系统中也使用数字 ID 来表示物料。传统 RS 将每个物料 ID 视为一个独立且完整的 token,不能被进一步分割。如果将这些 token 加入到模型中,需要 1)大量的内存来存储每个 token 的向量表示,以及 2)充足的数据来训练这些向量表示。为了解决这些问题,生成式推荐系统将数字 ID 分割成多个 token 组成的序列,使得用有限的 token 来代表无限的物料成为可能。为了有效地以 token 序列表示一个物料,现有的工作探索了不同的策略。1)顺序索引:基于时间顺序,利用连续的数字表示物料,例如,“1001, 1002, ...”,这可以捕捉与同一用户交互的物料的共现(基于 SentencePiece 分词器进行分词时,“1001”和“1002”分别被分词为“100”“1”和“100”“2”)。2)协同索引:基于共现矩阵或者协同过滤信息构建物料标识符,使得共现次数更多的物料或者具有相似交互数据的物料拥有相似的标识符前缀。尽管在生成式推荐系统中使用数字 ID 效果显著,但它通常缺乏语义信息,因此会遭受冷启动问题,并且未能利用 LLM 中编码的世界知识。
(2)文本元数据(Textual Metadata)
为了解决数字 ID 中缺乏语义信息的问题,一些研究工作利用了物料的文本元数据,例如,电影标题,产品名称,书名,新闻标题等。在与 LLM 结合时可借助 LLM 中编码的世界知识更好地理解物料特性。但这种方式有两个问题:1)当物料表示文本非常长时,进行生成的计算成本会很高。此外,长文本很难在数据集中找到精确匹配;仔细检查每个长文本的存在性或相关性将使我们回到判别性推荐的范式,因为我们需要将其与数据集中的每个物料计算匹配得分。2)虽然自然语言是一种强大且富有表现力的媒介,但在许多情况下它也可能是模糊的。两个不相关的物料可能具有相同的名称,例如,“苹果”既可以是一种水果也可以特指苹果公司,而两个密切相关的物料可能具有不同的标题,例如,数据挖掘中著名的“啤酒和尿布”示例[25]。
(3)语义 ID(Semantic-based ID,SID)
为了同时获得具有语义和区分性的物料标识符,现有方法主要通过如下方式对物料向量进行离散化:1)基于 RQ-VAE 模型[8]。RQ-VAE 模型由编码器,残差量化和解码器三部分构成,其输入是从预训练的语言模型(例如,LLaMA[9]和 BERT[28])提取的物料语义表示,输出是物料对应的 token 序列。在这个分支中,TIGER[7]是一个代表性的工作,它通过物料的文本描述生成对应的 token 序列,并将 token 序列命名为 Semantic ID。LC-Rec[4]设计了多种微调 LLM 的任务,旨在实现 Semantic ID 与用户交互数据或物料文本描述的语义对齐。这两种方法首先将物料的语义相关性捕获到标识符中,即具有相似语义的项目将拥有相似的标识符。然后,标识符表示将通过在推荐数据上训练来优化,以获取交互相关性。相比之下,LETTER[6]通过整合层次化的语义、协同信号和编码分配的多样性来构建高质量的物料标识符。2)基于语义层次化聚类方法。ColaRec[1]首先利用协同模型编码物料,并利用 k-means 聚类算法对物料进行层次化聚类,将分类类别作为物料标识符,之后在微调任务中对齐物料语义信息和交互信息。Hi-Gen[5]则在获取物料标识符的阶段同时考虑了交互信息和语义信息,利用 metric learning 对两种信息进行融合。
(4)小结
以上三类表示方法的对比如下:
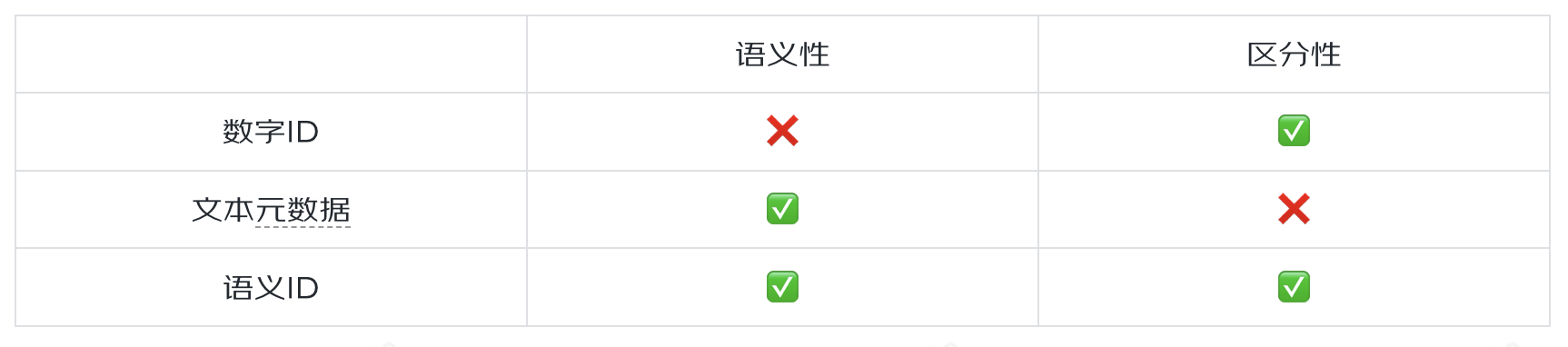
表 1. 不同离散化物料表示方法的对比
模型输入表示
在生成式推荐系统中,模型输入由如下的三个部分组成:任务描述、用户信息、上下文及外部信息。其中,用户信息主要包括用户历史交互数据和用户画像。
(1)任务描述
为了利用生成模型的理解能力,任务描述主要用来引导生成模型完成推荐任务,即将推荐任务建模为下一个物料的预测(类比语言模型的 Next Token Prediction,此处是 Next Item Prediction)。任务描述定义了提示词模版,将可利用的数据嵌入其中。例如,“这是一个用户的历史交互数据:{historical behavior},他的偏好如下:{preference},请提供推荐。”同时将用户历史交互数据和偏好作为模型输入内容[26]。
(2)用户历史交互数据
用户的历史交互数据在推荐系统中扮演着至关重要的角色,这种互动数据隐性地传达了用户对物料的偏好。用户历史交互数据的表示与上文介绍的物料表示密切相关,现有方法将其表示为:1)物料数字 ID 序列。物料数字 ID 被 LLM 作为纯文本处理,由分词器分割成几个 token。2)物料文本序列。将物料文本元数据进行拼接送入预训练语言模型,语言模型可根据世界知识建模物料之间的相关性。3)物料文本向量加物料 ID 向量序列。LLaRA[2]在物料标题向量后拼接了物料 ID 向量,以补充来自协同模型的交互信息。
(3)用户画像
为了增强用户建模,集成用户画像(例如,关于用户的基础信息和偏好信息)是推荐系统中建模用户特征的一种有效方式。在大多数情况下,用户的基础信息(例如,性别)可以直接从在线推荐平台获取。这些用户信息可与描述性文本结合使用,例如,“用户描述:女性,25-34 岁,在销售/市场营销领域工作”[26]。然而,由于用户隐私问题,获取用户画像可能具有挑战性,导致一些研究直接采用用户 ID 或 ID 向量[3]进行用户建模。
(4)上下文及外部信息
上下文信息(例如,位置、场景和时间)可能会影响用户决策,例如,在户外用品推荐中,用户可能更倾向于购买帐篷而水龙头。因此,在 LLM 中结合诸如时间之类的上下文信息,可以实现有效的用户理解。此外,外部知识也可以用来增强生成式推荐模型的性能,例如,用户-物料交互图中的结构化信息。
模型训练
在推荐数据上训练生成式推荐模型包括两个主要步骤:文本数据构建和模型优化[26]。文本数据构建将推荐数据转换为具有文本输入和输出的样本,其中输入和输出的选择取决于任务定义和物料表示方法。基于数字 ID 和文本元数据的物料表示方法可以直接构建文本数据,基于语义 ID 的方法则需要基于向量进行物料标识符的学习和获取。在模型优化方面,给定<输入,输出>数据,生成式模型的训练目标是最大化给定输入预测输出的条件似然。
针对生成式推荐系统,“用户到物料标识符的训练”是主要任务,即输入是用户构建,输出是下一个物料的标识符。基于数字 ID 和文本元数据的方法利用该任务进行模型训练。对于基于语义 ID 的方法,由于语义 ID 和自然语言之间存在差距,一般会利用如下辅助任务来增强物料文本和标识符之间的对齐[4]:1)“物料文本到物料标识符的训练”或“物料标识符到物料文本的训练”。对于每个训练样本,输入输出对包括同一物料的标识符和文本内容,可以互换地作为输入或输出。2)“用户到物料文本的训练”。通过将用户信息与下一个物料的文本内容配对来隐式对齐物料标识符和物料文本。
对于训练如 LLaMA 这样的大型语言模型,可采用多种策略来提高训练效率,例如,参数高效微调,模型蒸馏和推荐数据筛选。
模型推理
为了实现物料推荐,生成式推荐系统在推理阶段需要对生成结果进行定位,即实现生成的物料标识符与数据集中物料的有效关联。给定用户输入表示,生成式推荐系统首先通过束搜索自回归地生成物料标识符。这里的生成方式分为两种:自由生成和受限生成[26]。对于自由生成,在每一个解码步中,模型在整个词表中搜索,并选择概率最高的前 K 个 token(K 值取决于束搜索中定义的束大小)作为下一步生成的输入。然而,在整个词表上的搜索可能会导致生成不在数据集中的标识符,从而使推荐无效。
为了解决这个问题,早期工作使用精确匹配进行物料定位,即进行自由生成并简单地丢弃无效的标识符。尽管如此,它们仍然由于无效标识符而导致准确率低,特别是对于基于文本元数据的标识符。为了提高准确性,BIGRec[23]提出将生成的标识符通过生成的 token 序列的表示和物料表示之间的 L2 距离来定位到有效物料上。如此,每个生成的标识符都确保被定位到有效的物料上。与此同时,受限生成也在推理阶段被使用,例如,使用 Trie(prefix tree)或者 FM-index 进行受限生成,保证标识符的有效生成。
在预测下一个物料这样的典型推荐任务之外,也可充分利用自由生成产生新的物料描述或预测接下来 N 个物料。
现有工作总结
当前生成式推荐系统的代表性工作(RecSysLLM[22],P5[20][24],How2index[18],PAP-REC[17],VIP5[19],UniMAP[27],TIGER[7],LC-Rec[4],TransRec[16],M6-Rec[21],BIGRec[23],LMRecSys[10],NIR[12],RecRanker[13],InstructRec[11],Rec-GPT4V[14],DEALRec[15])可总结为:
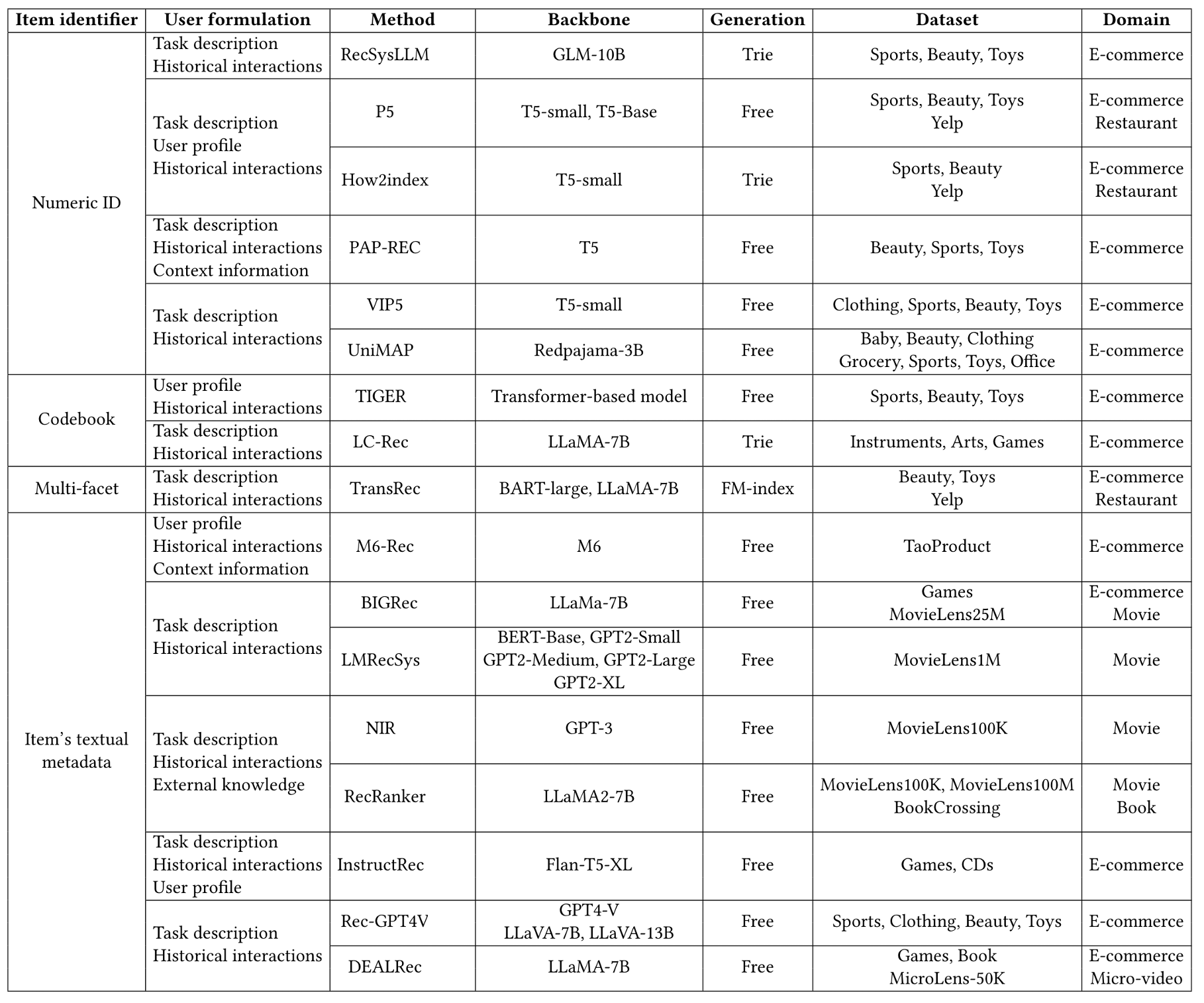
表 2. 生成式推荐系统的代表性工作[26]
三、实践方案
总体设计
基于对现有工作的调研和总结,我们的方案以“基于语义 ID 的物料表示”和“对齐协同信息和文本信息的训练任务”展开:
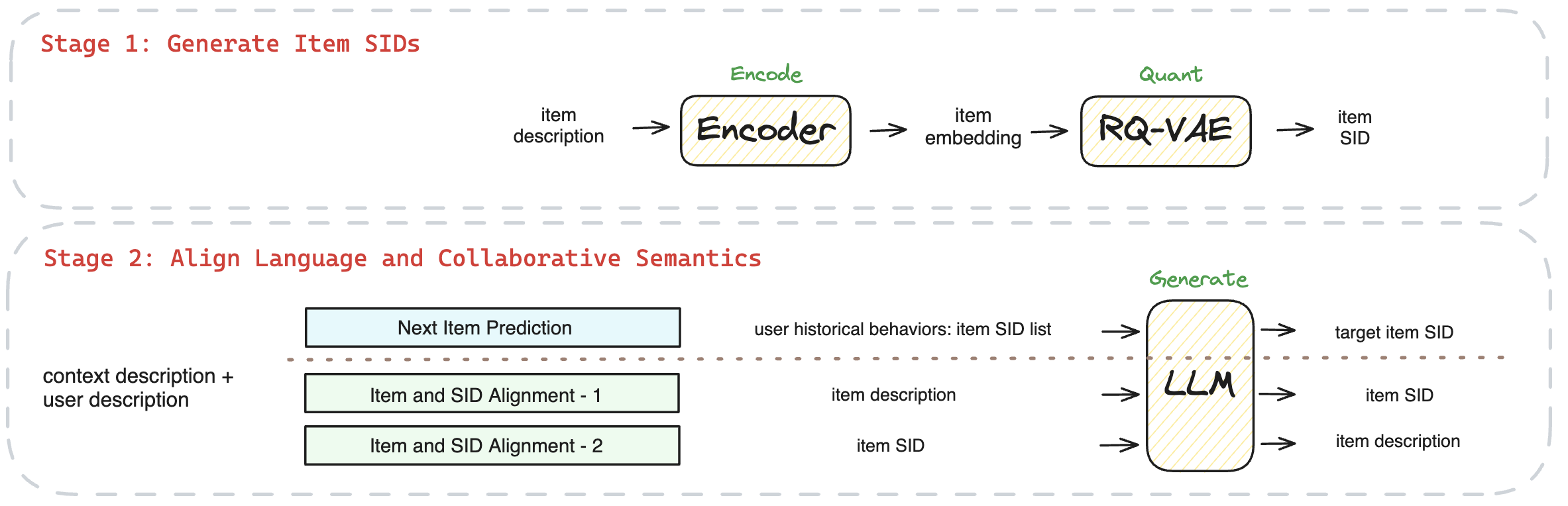
图 2. 总体设计框架图
功能模块
(1)基于语义 ID(SID)的物料表示
物料文本描述:基于商品标题表示物料。
物料向量:通过预训练的 bert-base-chinese 和 Yi-6B 分别提取文本描述对应的向量,向量维度为 768(bert-base-chinese)和 4096(Yi-6B)。
物料 SID:基于 RQ-VAE 模型对物料向量进行量化。RQ-VAE 模型由编码器,残差量化和解码器三部分构成,其输入是从预训练的语言模型中提取的向量,输出是物料对应的 SID 序列。针对冲突数据,我们采取了两种方式,一种是不进行处理,即一个 SID 对应多个商品;另一种是采用 TIGER 的方案,对有冲突的商品增加随机的一维,使得一个 SID 唯一对应一个商品。例如,商品“ThinkPad 联想 ThinkBook 14+ 2024 14.5 英寸轻薄本英特尔酷睿 ultra AI 全能本高性能独显商务办公笔记本电脑”可表示为:
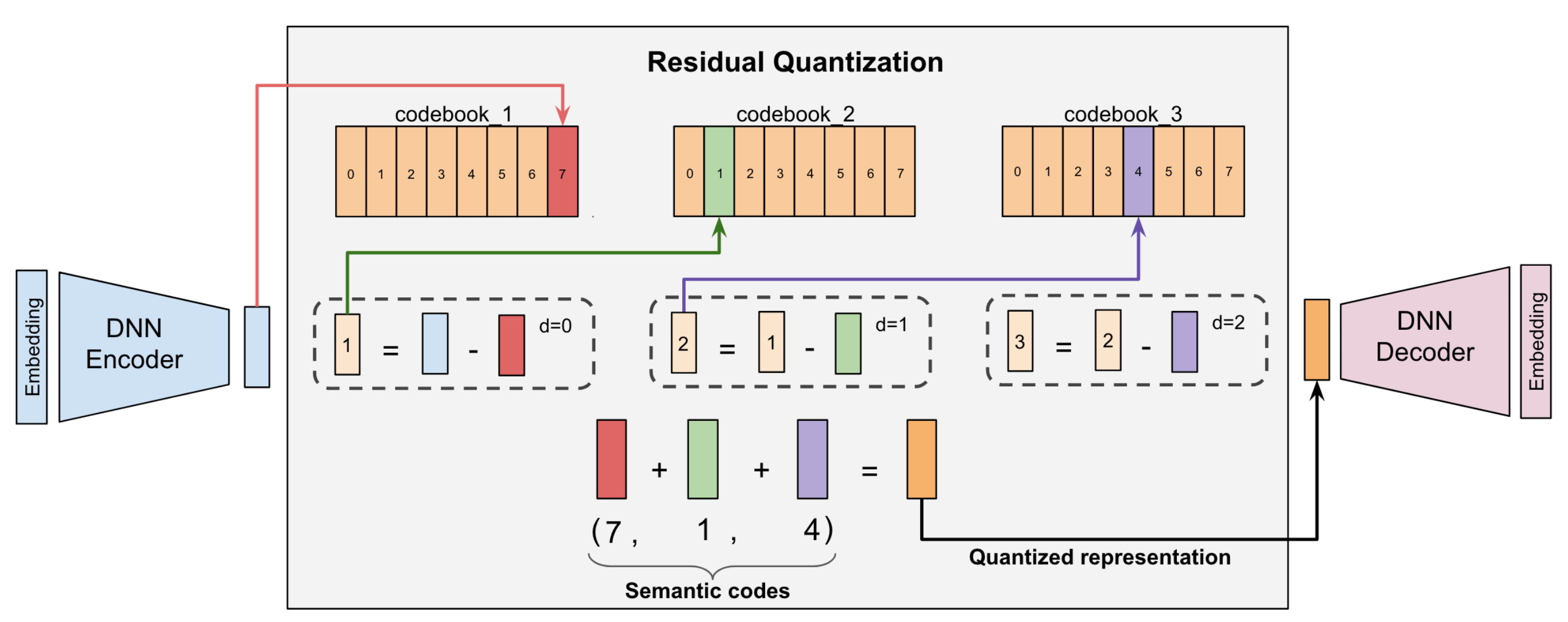
图 3. RQ-VAE 模型图[8]
(2)对齐协同信息和文本信息的训练任务
Next Item Prediction:推荐系统的主任务,即针对给定的用户描述(用户画像+历史交互数据),预测下一个推荐的物料。
Additional Alignment:由于 SID 和自然语言之前存在差距,通过额外的对齐训练,建立物料 SID 和物料文本描述之间的联系,包括 SID 到文本描述和文本描述到 SID 的两个双向任务。
四、离线与在线实验
训练数据
(1)Next Item Prediction
{ "instruction": "该用户为都市女性。用户已按时间顺序点击了如下商品:<a_112><b_238><c_33><d_113>, <a_73><b_50><c_228><d_128>, <a_20><b_251><c_30><d_178>, <a_142><b_216><c_7><d_136>, <a_190><b_171><c_15><d_201>, <a_72><b_160><c_20><d_248>, <a_158><b_101><c_54><d_107>, <a_175><b_4><c_75><d_138>, <a_142><b_20><c_175><d_136>, <a_210><b_166><c_67><d_44>, <a_10><b_89><c_96><d_143>, <a_27><b_45><c_21><d_212>, <a_142><b_27><c_192><d_159>,你能预测用户下一个可能点击的商品吗?", "response": "<a_96><b_113><c_49><d_174>"}(2)Item and SID Alignment1 - SID2Title
{ "instruction": "商品<a_99><b_225><c_67><d_242>的标题是什么?", "response": "ThinkPad 联想ThinkBook 14+ 2024 14.5英寸轻薄本英特尔酷睿ultra AI全能本高性能独显商务办公笔记本电脑 Ultra5 125H 32G 1T 3K屏 高刷屏"}(3)Item and SID Alignment2 - Title2SID
{ "instruction": "哪个商品的标题是\"ss109威震天变形MP威震玩具天金刚飞机威男孩机器人战机模型合金 震天战机(战损涂装版)\"?", "response": "<a_91><b_24><c_66><d_5>"}基座模型、训练及推理
(1)base model: Qwen1.5-0.5B/1.8B/4B 和 Yi-6B
(2)基于 SID 增加新 tokens,并利用交互数据进行训练
(3)采用基于 beam search 的受限解码策略,beam size=20
(4)实验方式:离线实验+线上小流量实验
(5)离线评估指标:HR@1,5,10; NDCG@1,5,10
(6)在线评估指标:UCTR
实验结果
(1)离线实验——同一基座模型不同参数规模的对比:
◦对比 0.5B/1.8B/4B 的结果可得,模型参数量越大,处理多种任务的能力越强,评估指标值越高;
◦由于 0.5B 模型能力较弱,不适宜处理多种任务数据,单一任务训练得到的模型相较混合任务有 8 倍提升;
◦在离线训练和测试数据有 3 个月的时间差的情况下,模型的表现仍然可观。
(2)离线实验——不同基座模型的对比:
◦Yi-6B 模型在不使用受限解码的情况下就有最佳的表现;
◦微调后的 Yi-6B 指令遵循的能力较好,可进行 next item prediction 和标题文本生成。
(3)离线实验——与协同模型结果对比:
◦在相同的数据规模和数据预处理的情况下,Yi-6B 模型的效果更好;
◦对稀疏数据进行过滤后训练的协同模型效果会有显著提升,传统模型对数据和特征的处理方式更为敏感。
(4)线上小流量实验:
◦多个置信的站外投放页面的小流量实验显示,基于生成式模型 base 版本可与传统多路召回+排序的 top1 推荐对应的 UCTR 结果持平,在部分页面更优,UCTR+5%以上。
◦更适合数据稀疏、用户行为不丰富的场景。
五、优化方向
在生成式推荐系统中,构建高质量的数据集是实现精准推荐的关键。在物料表示和输入-输出数据构建层面,将语义信息、多模态信息与协同信息结合,基于联盟场景特点,可以显著提升物料表示的准确性和相关性。
为了支持 RQ-VAE 的稳定训练和语义 ID 的增量式推理,需要开发一种可扩展的 SID 训练和推理框架,确保语义 ID 能够快速适应物料变化。
此外,优化基座模型是提高生成式推荐系统性能的另一个关键领域。通过训练任务的组合和采用多种训练方式,例如,多 LoRA 技术和混合数据策略,可以进一步增强模型的表现。推理加速也是优化的一个重要方面,通过模型蒸馏、剪枝和量化等技术,可以提高系统的响应速度和效率。同时,基座模型的选型与变更,也是持续追求优化效果的一部分。
未来,可考虑引入搜索 query 内容进行搜推一体化建模。此外,引入如用户推荐理由生成和用户偏好生成等任务,可丰富系统的功能并提高用户的互动体验。
我们的目标是通过持续的技术革新,推动推荐系统的发展,实现更高效、更个性化的用户服务。欢迎对这一领域感兴趣的合作伙伴加入我们,共同探索生成式推荐系统技术的未来。
六、参考文献
1.Wang Y, Ren Z, Sun W, et al. Enhanced generative recommendation via content and collaboration integration[J]. arXiv preprint arXiv:2403.18480, 2024.
2.Liao J, Li S, Yang Z, et al. Llara: Large language-recommendation assistant[J]. Preprint, 2024.
3.Zhang Y, Feng F, Zhang J, et al. Collm: Integrating collaborative embeddings into large language models for recommendation[J]. arXiv preprint arXiv:2310.19488, 2023.
4.Zheng B, Hou Y, Lu H, et al. Adapting large language models by integrating collaborative semantics for recommendation[J]. arXiv preprint arXiv:2311.09049, 2023.
5.Wu Y, Feng Y, Wang J, et al. Hi-Gen: Generative Retrieval For Large-Scale Personalized E-commerce Search[J]. arXiv preprint arXiv:2404.15675, 2024.
6.Wang W, Bao H, Lin X, et al. Learnable Tokenizer for LLM-based Generative Recommendation[J]. arXiv preprint arXiv:2405.07314, 2024.
7.Rajput S, Mehta N, Singh A, et al. Recommender systems with generative retrieval[J]. Advances in Neural Information Processing Systems, 2024, 36.
8.Zeghidour N, Luebs A, Omran A, et al. Soundstream: An end-to-end neural audio codec[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 30: 495-507.
9.Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
10.Zhang Y, Ding H, Shui Z, et al. Language models as recommender systems: Evaluations and limitations[C]//I (Still) Can't Believe It's Not Better! NeurIPS 2021 Workshop. 2021.
11.Zhang J, Xie R, Hou Y, et al. Recommendation as instruction following: A large language model empowered recommendation approach[J]. arXiv preprint arXiv:2305.07001, 2023.
12.Wang L, Lim E P. Zero-shot next-item recommendation using large pretrained language models[J]. arXiv preprint arXiv:2304.03153, 2023.
13.Luo S, He B, Zhao H, et al. RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation[J]. arXiv preprint arXiv:2312.16018, 2023.
14.Liu Y, Wang Y, Sun L, et al. Rec-GPT4V: Multimodal Recommendation with Large Vision-Language Models[J]. arXiv preprint arXiv:2402.08670, 2024.
15.Lin X, Wang W, Li Y, et al. Data-efficient Fine-tuning for LLM-based Recommendation[J]. arXiv preprint arXiv:2401.17197, 2024.
16.Lin X, Wang W, Li Y, et al. A multi-facet paradigm to bridge large language model and recommendation[J]. arXiv preprint arXiv:2310.06491, 2023.
17.Li Z, Ji J, Ge Y, et al. PAP-REC: Personalized Automatic Prompt for Recommendation Language Model[J]. arXiv preprint arXiv:2402.00284, 2024.
18.Hua W, Xu S, Ge Y, et al. How to index item ids for recommendation foundation models[C]//Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 2023: 195-204.
19.Geng S, Tan J, Liu S, et al. VIP5: Towards Multimodal Foundation Models for Recommendation[C]//Findings of the Association for Computational Linguistics: EMNLP 2023. 2023: 9606-9620.
20.Geng S, Liu S, Fu Z, et al. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)[C]//Proceedings of the 16th ACM Conference on Recommender Systems. 2022: 299-315.
21.Cui Z, Ma J, Zhou C, et al. M6-rec: Generative pretrained language models are open-ended recommender systems[J]. arXiv preprint arXiv:2205.08084, 2022.
22.Chu Z, Hao H, Ouyang X, et al. Leveraging large language models for pre-trained recommender systems[J]. arXiv preprint arXiv:2308.10837, 2023.
23.Bao K, Zhang J, Wang W, et al. A bi-step grounding paradigm for large language models in recommendation systems[J]. arXiv preprint arXiv:2308.08434, 2023.
24.Xu S, Hua W, Zhang Y. Openp5: Benchmarking foundation models for recommendation[J]. arXiv preprint arXiv:2306.11134, 2023.
25.Li L, Zhang Y, Liu D, et al. Large language models for generative recommendation: A survey and visionary discussions[J]. arXiv preprint arXiv:2309.01157, 2023.
26.Li Y, Lin X, Wang W, et al. A Survey of Generative Search and Recommendation in the Era of Large Language Models[J]. arXiv preprint arXiv:2404.16924, 2024.
27.Wei T, Jin B, Li R, et al. Towards Universal Multi-Modal Personalization: A Language Model Empowered Generative Paradigm[C]//The Twelfth International Conference on Learning Representations. 2023.
28.Kenton J D M W C, Toutanova L K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Proceedings of NAACL-HLT. 2019: 4171-4186.
29.Zhai J, Liao L, Liu X, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations[J]. arXiv preprint arXiv:2402.17152, 2024.
作者:广告研发部 申磊
来源:京东零售技术 转载请注明来源




