
持续集成(CI)管道已经成为软件开发团队非常重要、甚至是无处不在的一部分,这是因为它们为团队带来的价值,即能够在不同层面上持续测试代码并自动化许多复杂的部署过程。如果你想获得最大的价值,仅仅有一个 CI 管道还不够。
如何跟踪 CI 管道和流程的有效性最好?如何确保管道实际交付的软件达到了应有的质量水平,而不是默认它会成功?如何更好地利用管道来排除软件问题,并使不同的应用程序更有效地运行?
只要我们实现有效的监控和可观察性,CI 管道就可以提供所有这些问题的答案。要做到这一点,首先需要解决以下问题:
在涉及 CI 管道时,需要了解可观察性的哪些方面?
如何在管道中配置这种监控?
为了更好地理解 CI 管道和软件应用程序,应该监控哪些指标?
如何更好地可视化这些指标?
在本文中,我们将探讨其中的许多问题,让你可以借助可观察性来更好地利用 CI 管道。虽然在本文中,我们将介绍团队应该努力培养的几项重要特质,但你也要认识到,每个团队和软件应用程序都是不同的,这一点很重要。你可能需要根据团队的具体需求进行调整。同样,本文探讨的大多数技术解决方案都涉及到像 InfluxDB 和 Grafana 这样的工具,并展示了如何通过它们配置各种仪表板。你的团队可能使用了不同的工具,但在很大程度上,这些原则还是适用的。你可能需要针对特定的工具集,研究下如何更好地实现相同的结果。
可观察性技术面面观
CI 管道中有几个关键的可观察性组件,包括监控、日志记录和跟踪。
监控是指对管道操作的持续跟踪,包括各个阶段的性能、构建和部署的状态以及管道的总体健康状况。这可以借助各种工具来实现,比如 Prometheus 和 Grafana。它们可以提供管道的实时可见性,并提醒开发人员可能出现的任何问题。
日志记录是指收集和存储来自管道的日志数据,包括与构建、部署和管道性能有关的信息。这些数据可以用于故障排除和根因分析,并且可以存储在集中式的日志管理系统(如 ELK 或 Splunk)中,便于访问和分析。
跟踪是指跟踪通过管道的请求或事务流的能力,从开发到生产。这可以通过跟踪工具来完成,例如 Jaeger 或 Zipkin。它们可以提供关于管道各个阶段的详细信息,包括每个阶段所花费的时间、使用的资源以及可能发生的任何错误。
总的来说,CI 管道的可观察性对于保持管道的可靠性和有效性至关重要,而且让开发人员可以快速识别和解决可能出现的任何问题。这可以通过组合使用监控、日志记录和跟踪工具来实现。这些工具可以提供管道的实时可见性,并帮助进行故障排除和根因分析。
除此之外,你还可以使用应用程序性能管理(APM)解决方案这样的可观察性工具,如 New Relic 或 Datadog。APM 提供了整个应用程序和基础设施的端到端可见性,可以帮助开发人员识别管道中的瓶颈、性能问题和错误。
值得注意的是,可观察性应该集成到整个管道中,从开发到生产,保证任何问题都能被快速有效地识别和解决。
CI 管道的监控如何配置最好?
关于这一部分,最困难的部分也许是如何选择恰当的工具。可供选择的工具有很多,每种工具都有各自的优缺点,本文就不展开介绍了。我建议你多花些时间和精力,研究一下市场上存在的不同工具,看看哪些工具与你现有的技术栈、预算和技能集最匹配,然后尝试不同的选项,看看哪些适合你。
像 Prometheus、Grafana 和 ELK 技术栈(Elasticsearch、Logstash、Kibana)这样的工具是 CI 管道监控中比较流行的选项。不过,我们在决策的时候不能只看哪些工具提供了最好的监控可视化以及哪些工具提供了最好的报告或预警功能,还要看哪些工具能更好地收集数据,这也许更重要。
以下是配置数据收集和管道流程的关键步骤,你可以从这些方面比较各种工具:
从多个数据源收集数据:这包括构建过程、测试过程和部署过程,可以提供管道性能的完整视图。
将数据集中存储:利用数据仓库或集中式日志记录系统,方便日志访问和分析。
使用 API 自动收集数据:使用 API 从管道和其他数据源(如代码存储库和问题跟踪系统)收集数据。这样就可以轻松地与其他工具和系统集成,实现比较简单的自动化,在不需要人工干预的情况下提取数据。
使用日志记录和监控框架:可以使用 Logstash 和 Prometheus 等框架来收集和分析数据。它们为数据收集、存储和分析提供了内置支持。
使用数据可视化工具:在将数据收集到集中式存储后,就该研究可视化数据的方法了(将在下文讨论)。使用数据可视化工具,如 Grafana 或 Tableau,可以获得相对更容易理解的格式,简化趋势识别,并基于特定的数据需求和模式进行过滤。
设置预警:设置预警机制,以便在管道出现问题时发送通知,包括团队聊天工具、Slack 频道、电子邮件、短信,在 PagerDuty 等事件管理工具中创建事件,甚至将事件记录到 JIRA 等问题管理工具中。
跟踪数据保留策略:我们正在讨论的是收集所有这些数据,但如果最终只是不断地存储所有数据,并不能带来什么帮助。虽然拥有大量的数据有用,但成本很高,而且可能会降低系统的性能,并成为一种阻碍。跟踪数据保留策略,并确保数据保存足够长的时间以供分析及满足合规性要求。
持续监控和优化:不用说,数据收集了,也可视化了,现在要做的是持续监控管道,并在必要时做出调整,包括调整数据收集配置、添加新的数据点以及优化管道、提升性能。
如何通过管道推送数据?
有许多方法可以将数据从 CI 管道推送到数据源,具体的方法取决于数据源和你正在使用的 CI 工具。下面是一些使用代码将数据从管道推送到数据源的示例。
借助 REST API
许多数据源都提供 REST API,允许我们使用 HTTP 请求将数据推送到数据源。例如,可以使用 Python 的 requests 库向 REST API 端点发送 POST 请求,将数据推送到数据源。
示例:
import requests data = {'key1': 'value1', 'key2': 'value2'} response = requests.post('https://example.com/data', json=data)借助 SDK
有些数据源会提供 SDK 或客户端库,可用于将数据推送到数据源。例如,可以使用 AWS SDK For Python(boto3)将数据推送到 Amazon S3 桶。
示例:
import boto3 s3 = boto3.client('s3') s3.put_object(Bucket='my-bucket', Key='data.json', Body=data)借助命令行工具
有些数据源提供可以将数据推送到数据源的命令行工具。例如,可以使用 curl 命令将数据推送到 REST API 端点。
示例:
curl -X POST -H "Content-Type: application/json" -d '{"key1": "value1", "key2": "value2"}' https://example.com/data借助数据管道工具
有些数据源提供数据管道工具,可用于将数据推送到数据源。例如,可以使用 Apache NiFi 将数据推送到数据湖。
这些示例非常基础,但应该也可以让你有一个基本的了解。在此基础上,团队可以着手从 CI 管道中将数据提取到目标数据源。
下面是一个完整的示例代码,使用 Typescript 在 CI 管道中设置数据存储,并将相关结果推送到数据存储中。在这个例子中,考虑到其可配置性和低成本,我们使用了
import { config as dotenv } from 'dotenv';import * as influxDB from 'influx';let dbName: string;let connection: influxDB.InfluxDB;export async function streamMeasurement( measurement: string, points: influxDB.IPoint[]): Promise<void> { if (connection == null) { dotenv({ path: '.influxconfig' }); dbName = process.env.INFLUXDB_METRICS_DBNAME; if (dbName == null) { return; } await createConnection(); await createDatabase(); } await connection.writeMeasurement(measurement, points);}export async function executeQuery<T>( influxQl: string): Promise<influxDB.IResults<T>> { await createConnection(); return connection.query(influxQl);}async function createConnection(): Promise<void> { dbName = process.env.INFLUXDB_METRICS_DBNAME; const host = process.env.INFLUXDB_METRICS_HOST; const port = process.env.INFLUXDB_METRICS_PORT; connection = new influxDB.InfluxDB(`http://${host}:${port}/${dbName}`);}async function createDatabase(): Promise<void> { dbName = process.env.INFLUXDB_METRICS_DBNAME; const dbNames = await connection.getDatabaseNames(); if (dbNames.includes(dbName)) { return; } await connection.createDatabase(dbName); await connection.createRetentionPolicy(dbName, { duration: '700d', database: dbName, replication: 1, isDefault: true, });}通过 CI 管道可以度量哪些指标?
通过 CI 管道,我们可以捕获许多不同类型的指标。为了获得最可靠、最有价值的结果,你可能希望在 CI 管道的不同阶段度量不同的东西。
指标清单也可能非常详尽,但要注意,不要想着什么都度量,那会导致分析瘫痪。团队访问了大量的信息,但却无法理解关注哪些指标才有助于他们理解、处理或纠正某些问题,经常会出现未能有效完成工作的情况。
注意,下面列出的具体指标只与 CI 过程相关。度量应用程序性能之类的东西也很重要,也应该做,只不过不应该作为 CI 过程的一部分。
以下是需要跟踪的最重要的指标:
构建时间:该指标度量完成构建所需的时间,即从构建流程开始到完成测试所耗费的时间。我们可以用它来识别缓慢的构建时间,并以此为基础优化构建管道,提升构建速度。
测试通过率:该指标度量在构建过程中测试通过的百分比。我们可以用它来识别不可靠的测试,并提高代码的整体质量。
安全扫描结果:任何管道都应该有某种形式的静态分析,检查代码中任何已知的漏洞或不受支持的包。虽然这个问题似乎微不足道,因为任何具有重大漏洞的 pull 请求都可能会失败,但仍然需要跟踪不同的安全风险,并确保识别出的风险确实是风险。
部署频率:该指标度量将代码部署到生产环境的频率。我们可以用它识别管道的瓶颈并优化部署过程。
失败率:该指标度量构建或部署失败的百分比。我们可以用它识别管道中存在的问题,并优化流程,减少故障。
平均恢复时间(MTTR):该指标度量应用程序从故障中恢复所需的时间。我们可以用它识别管道中存在的问题并优化流程,加快恢复速度。
资源利用率:这类指标度量底层系统资源(如 CPU、内存、磁盘或网络带宽)的使用情况。我们可以用它识别管道的瓶颈,并优化流程以便更好地利用资源。
代码质量指标:这类指标度量代码的质量,例如 Bug 数量、代码复杂性、可维护性和测试覆盖率。我们可以用它识别管道中存在的问题,提高代码的整体质量。
用户参与度指标:该指标衡量用户如何与系统交互,例如活动用户数、响应时间或错误率。我们可以用它识别管道中存在的问题,并优化流程,提升用户参与度。
务必要记住,并不是所有的指标对所有的管道都同样重要,这要视管道和组织的特定需求而定。选择与管道和组织目标最相关的指标,这很重要。
数据可视化工具
在详细讨论数据可视化的方法之前,我想简单地介绍一些一般来说最适合 CI 可观察性的可视化工具。并不是只有这些工具,但由于它们在处理大量数据时用起来比较简单,比较容易与各种旨在跟踪 CI 管道的工具集成,而且还具备可重配置能力,所以它们是使用最广泛的工具。
GrafanaGrafana
是一个开源的仪表板和可视化工具,可用于显示来自各种数据源(包括 Prometheus、InfluxDB、Graphite、Elasticsearch 等)的指标。我们可以用它创建自定义仪表板和预警,它内置了各种可用于显示管道指标的面板和插件。
KibanaKibana
是一个开源的数据可视化和探索工具,是 Elastic Stack 的一部分。它可以用来显示来自 Elasticsearch 的指标,也可以用来创建自定义可视化和仪表板。你还可以用它搜索及探索数据,并设置预警。
DatadogDatadog
是一个基于云的监控和分析平台,可用于显示来自各种数据源的指标,包括代理、集成和 API。你可以用它创建自定义仪表板,设置预警,以及显示管道指标。
New RelicNew Relic
是一个基于云的性能监控和分析平台,可用于显示来自各种数据源的指标,包括代理、集成和 API。你可以用它创建自定义仪表板,设置预警,以及显示管道指标。
PrometheusPrometheus
是一个开源的监控和预警系统,可用于从各种数据源收集以及存储指标。它还提供了一个内置的可视化和探索工具,名为 Prometheus Web UI,可用于显示管道指标。
其中许多工具都有的一个好处是,它们可以使用 HTML 或 JSON 结构来传递信息,这意味着你可以轻松地分发或扩展仪表板,让它在不同的领域中发挥作用,而不需要什么都从头开始构建。
下面是一些 JSON 脚本的示例,完全用代码配置 Grafana 仪表板。(注意,实际的文件相当大,为了让代码看起来简单些,这里只显示了一小部分)。
"description": "A dashboard for visualizing results from the k6.io load testing tool, using the InfluxDB exporter.Based on https://grafana.com/dashboards/4411", "editable": true, "gnetId": 10660, "graphTooltip": 0, "id": 18, "iteration": 1607358257072, "links": [], "panels": [ { "cacheTimeout": null, "colorBackground": true, "colorValue": false, "colors": [ "rgba(86, 166, 75, 0.5)", "rgba(242, 204, 12, 0.5)", "rgba(224, 47, 68, 0.5)" ], "datasource": "k6", "decimals": 2, "fieldConfig": { "defaults": { "custom": {} }, }, "format": "ms", "gauge": { "maxValue": 100, "minValue": 0, "show": false }, "gridPos": { "h": 3, "w": 4, "x": 0, "y": 0 }, "height": "50px", "id": 16, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "postfixFontSize": "50%", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ],…. ], "thresholds": "1000,2000", "title": "Response Minimum", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "min" },如何可视化这些指标?这个主题也涉及许多不同的选项,因为有许多显示各种指标的方法。有些工具提供了许多内置的指标和仪表板,简化了我们的工作。尽管如此,考虑到不同软件需求的多样性,对于组织来说,最好是针对自己的具体情况组合仪表板。
以下是一些重要的建议:
保持简单:使用简单、易于理解的可视化,如柱状图、折线图和饼图,而不是复杂或不好解释的可视化。
合理搭配颜色:合理搭配颜色突出数据及重要的趋势或模式。
使用标签和注释:使用标签和注释来帮助解释数据,使用户更容易理解数据所代表的内容。
使用实时数据:使用实时数据来显示最新信息,让用户可以查看数据如何随时间而变化。
保持设计一致性:保持设计一致性,方便用户理解数据,并确保可视化易于阅读和解释。
使其易于访问:确保所有用户都可以访问可视化,包括那些有视觉障碍或色觉缺陷的用户。
最重要的是要记住,设法跟踪关键指标和预警。许多团队会将一些好看的仪表板组合在一起,让其看起来很有用,提供了大量信息,但可观察性的目的是为了维护和监控管道的有效性,而不是为了好看。
举例来说,在一个好看的时间轴图中可视化每个管道作业的数据很简单,但是如果你的管道每天在不同的构建和环境中运行多次,那么信息将很快变得让人不堪重负,难以有效地可视化。相反,你可以将管道通过率和运行时间作为一个指标来展示,然后使用图形来可视化有问题的管道,从而更好地了解那里发生了什么。
可视化还有助于快速识别醒目的内容,但不一定会为你提供排查某个情况所需的所有信息。这时,上文提到的日志就变得很重要了,它能够在你需要时提供更具体的数据。
下面是一些仪表板示例,可以帮你很好地可视化 CI 管道。这些仪表板都是在 Grafnan 中创建的,不过这类可视化也可以在其他工具中展示。可以看出,我们要根据自己的需求配置仪表板的外观,而不仅仅依赖于作用有限的通用仪表板模板。
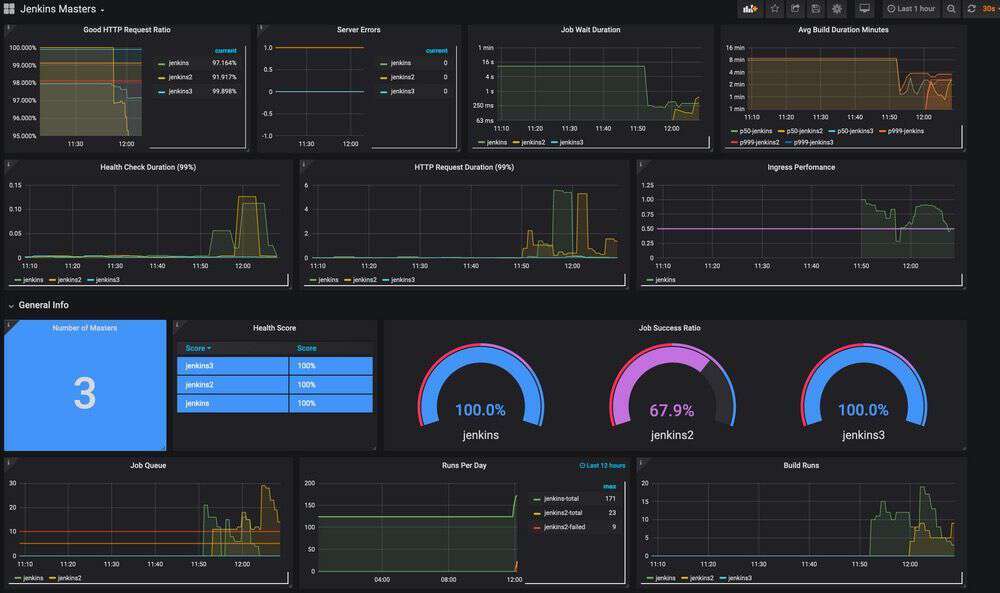
如果你想分析趋势,那么上面的仪表板构思可能非常有用。有一些图形表盘带颜色,但重点是分析仅仅在趋势分析时才经常见到的低谷和异常值。这一点很重要,因为如果你的指标基于简单的通过率或平均性能,那么总体值可能看着还不错,但你可能会错过不频繁,但从长远来看又可能非常重要的峰值。尤其是规模很大的时候。
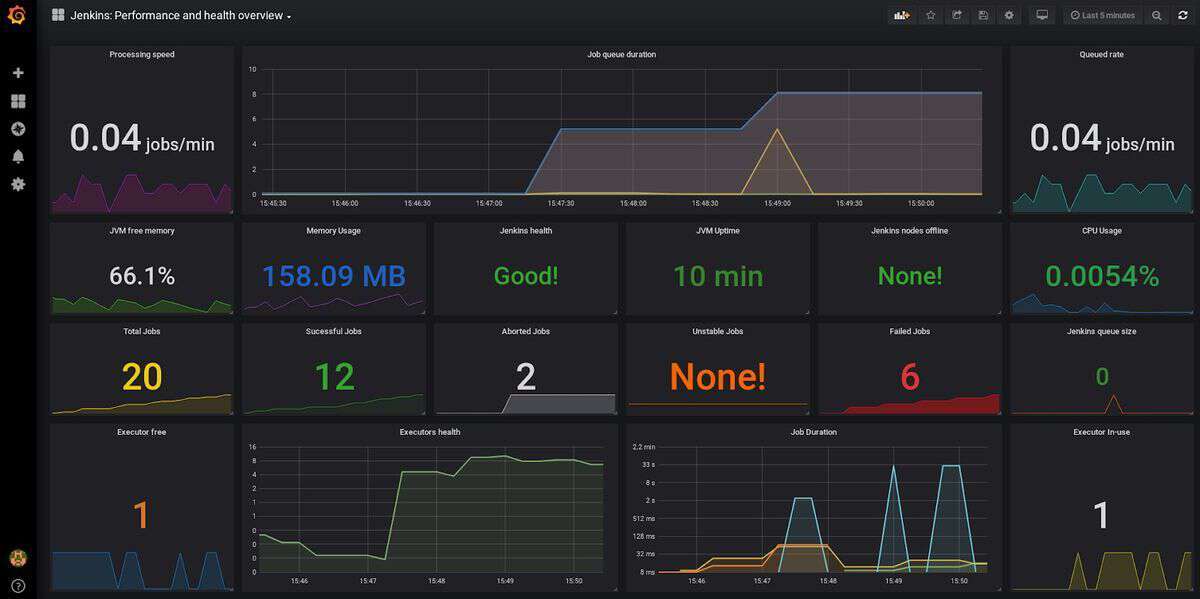
这个仪表板示例提供了视觉效果和信息的良好组合。并不是所有的东西都要显示在图上,有时只需以文本或数字格式提供所有你真正需要知道的信息,并且让你可以通过颜色分级来了解需要注意的内容。如果需要特定的图表或趋势,也可以使用它们。让你看到所需的数字,而不被数据压垮,这是一种可以确保事情健康发展的简单方法。当数字令人担忧时,你还可以设置预警触发策略。
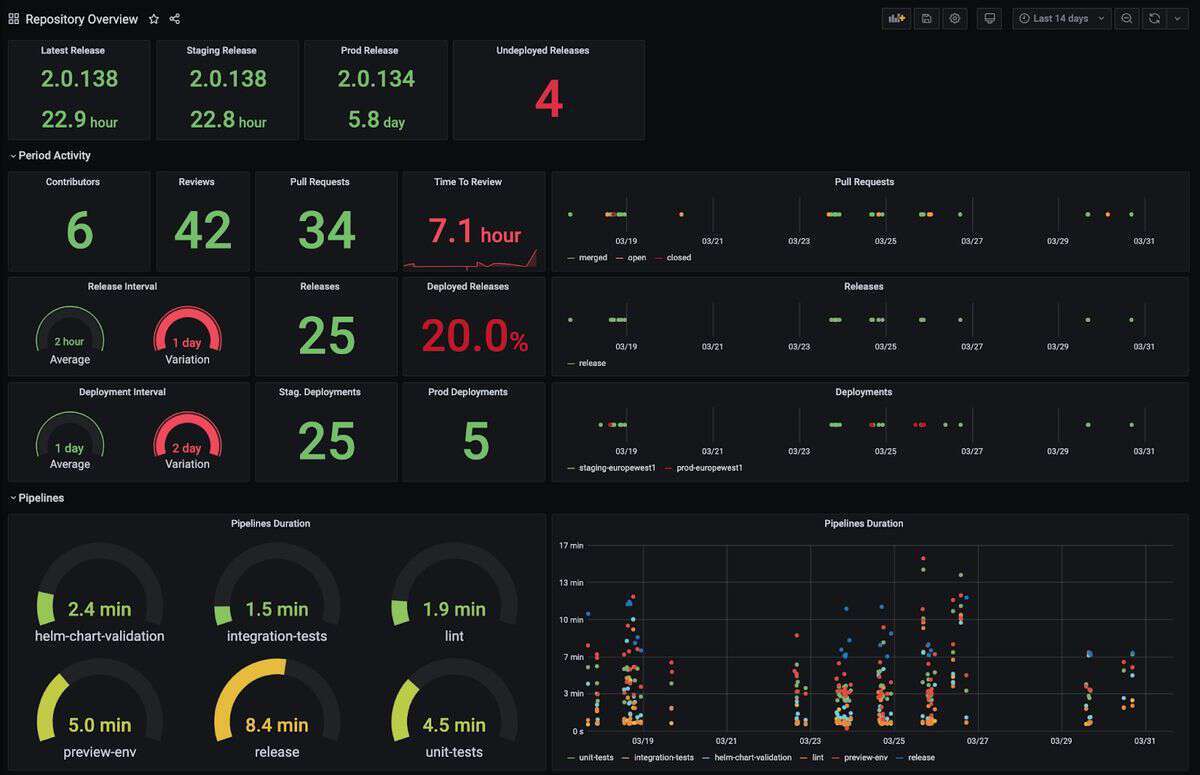
下面这个仪表板构思融合了各种可视化技术,包括易于阅读的数字和彩色编码,可以突出这些数字相对于预定基准的健康状况,同时,它还使用了一些图形可视化来更清晰地展示问题。它很好地混合了不同的技术,提供了有趣的信息。不过,可能有人会认为,右下角的管道持续时间图可能显示的信息太多,应该只显示有问题的管道,而不是尝试显示所有内容。
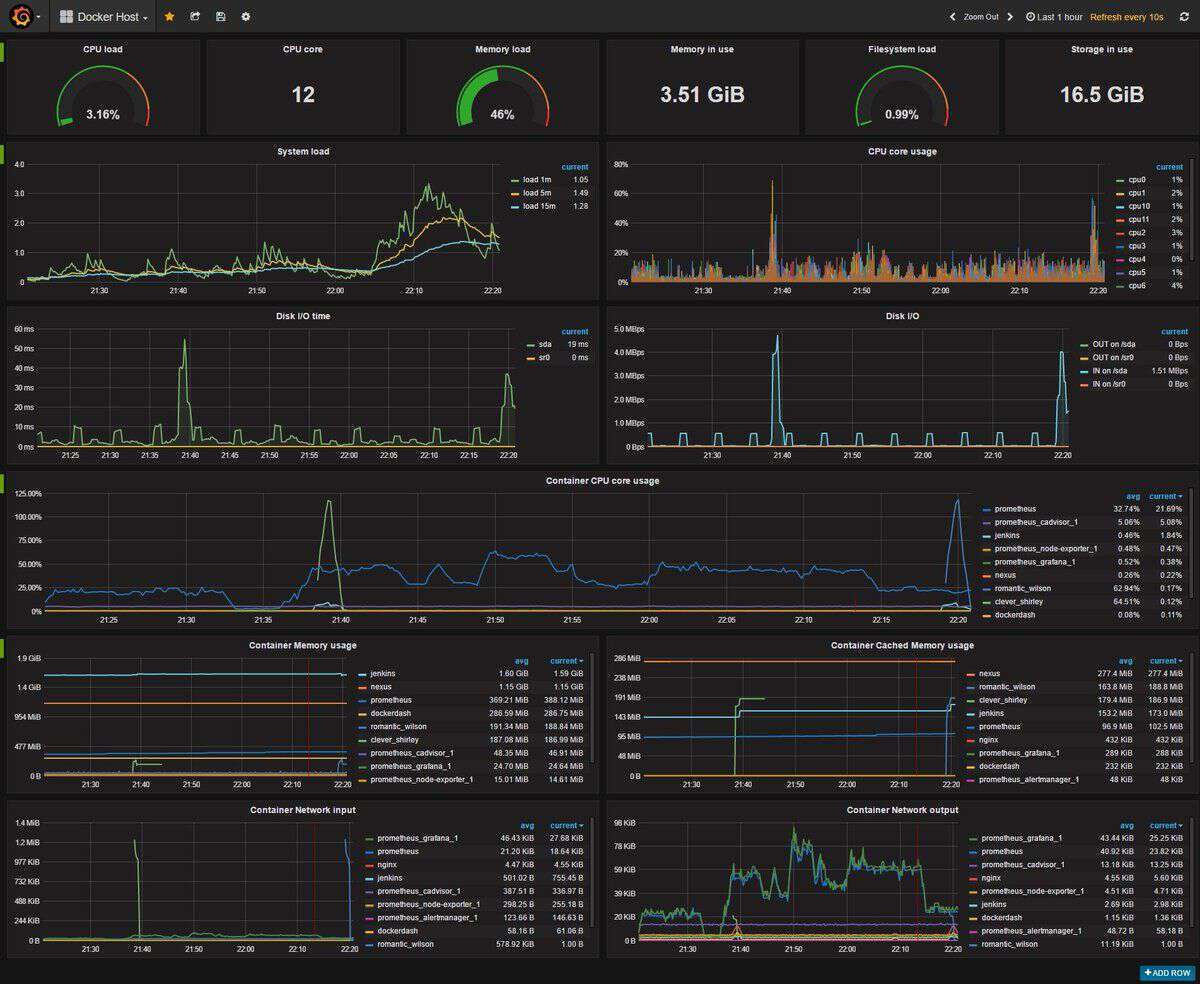
这个仪表板做的事情可能太多了。这里的信息跟踪了运行管道作业的服务器的性能,虽然非常详细且进行了可视化,但要了解具体问题可能在哪里却很困难。对于调试性能问题,这样的信息或许有用,但由于数据太多,所以很难将其与正在发生的事情联系起来,因而团队很可能无法集中精力寻找问题。
所有这些信息都应该为你在管道中尝试和实现可观察性提供一个入手点。可供选择的方法有很多,重要的是,作为一个团队和公司,你要设法确定最适合自己的信息和策略,以及一个在前进的过程中完善和改进一切的目标。如果你愿意改进和完善,那么最终不仅可以获得合适的 CI 管道监控,而且还可以获得提高其利用率所需的信息。
原文链接:
https://www.infoq.com/articles/ci-cd-observability/
相关阅读:




