
上周五的人工智能顶级会议 NeurIPS 2024 上,Safe SuperIntelligence 实验室创始人,原 OpenAI 联合创始人兼首席科学家 Ilya Sutskever 打破了长久的沉默,公开露面并发表了一段演讲,题为《Sequence to sequence learning with nueral networks: what a decade》,作为这篇十年前的重磅论文荣获今年度 NeurIPS 时间检验奖的获奖演说。Ilya 在演讲中回顾了人工智能技术过去十年来的进步,并对行业接下来的发展给出了展望。他提出了一个重磅观点:预训练时代已经结束了。本文是这篇演讲的文本整理。
Ilya:感谢组织者将这个奖项(Test of Time Awards,时间检验奖)颁发给了我们十年前的这篇论文《Sequence to sequence learning with nueral networks》,真是太棒了。我还要感谢我的合著者和合作者,Oriol Vinyals 和 Quoc Le。

上面这张图片是 10 年前的蒙特利尔,在 2014 年 NeurIPS 上我们所作演讲的截图。那是一个更加纯真的时代。照片里是我们三个人。
但在这里我想谈谈这项工作本身,也许还可以回顾一下过去这 10 年,因为这项工作中的很多东西都是正确的,也有些不是。我们可以回顾过去,看看这些年业界都发生了什么事情,如何一步步走到今天。
我们先来讲讲我们当时做了什么,搭配一些十年前演讲中使用的幻灯片。我们所做的事情总结起来就是三个要点:
这是一个在文本上训练的自回归模型。
这是一个大型神经网络。
训练使用的是一个大型数据集。
现在我们来更深入地了解一下细节。

上图是 10 年前用的幻灯片,谈的是深度学习的假设。我们在这里说的是,如果你有一个十层的大型神经网络,那么它就可以做到人类用几分之一秒的时间能做到的任何事情。为什么我们要强调“人类在几分之一秒内能做的事情”?为什么特别强调这些事情?如果你相信深度学习所标榜的东西,也就是说人工制造的神经元和生物神经元是很像的,或者至少没有太大的不同,那么你也会知道真正的神经元的速度比我们人类能迅速做到的各种事情都更慢。那么即使全世界只有一个人速度快到能在几分之一秒内完成某项任务,那么十层的神经网络也能做到这一点。接下来,你只需将它们连接起来,然后嵌入到你的神经网络中,也就是人工智能网络中就行了。
这就是动机,人类在几分之一秒内能做到的任何事情,我们用一十层的神经网络也能做到。我们一开始只盯着十层神经网络,因为那时候我们只会训练这么多层。如果你能以某种方式训练更多层数,那么你能做的事情也会更多了。但那时我们只能做十层,这就是为什么我们当时会强调“人类在几分之一秒内能做到的一切事情”。
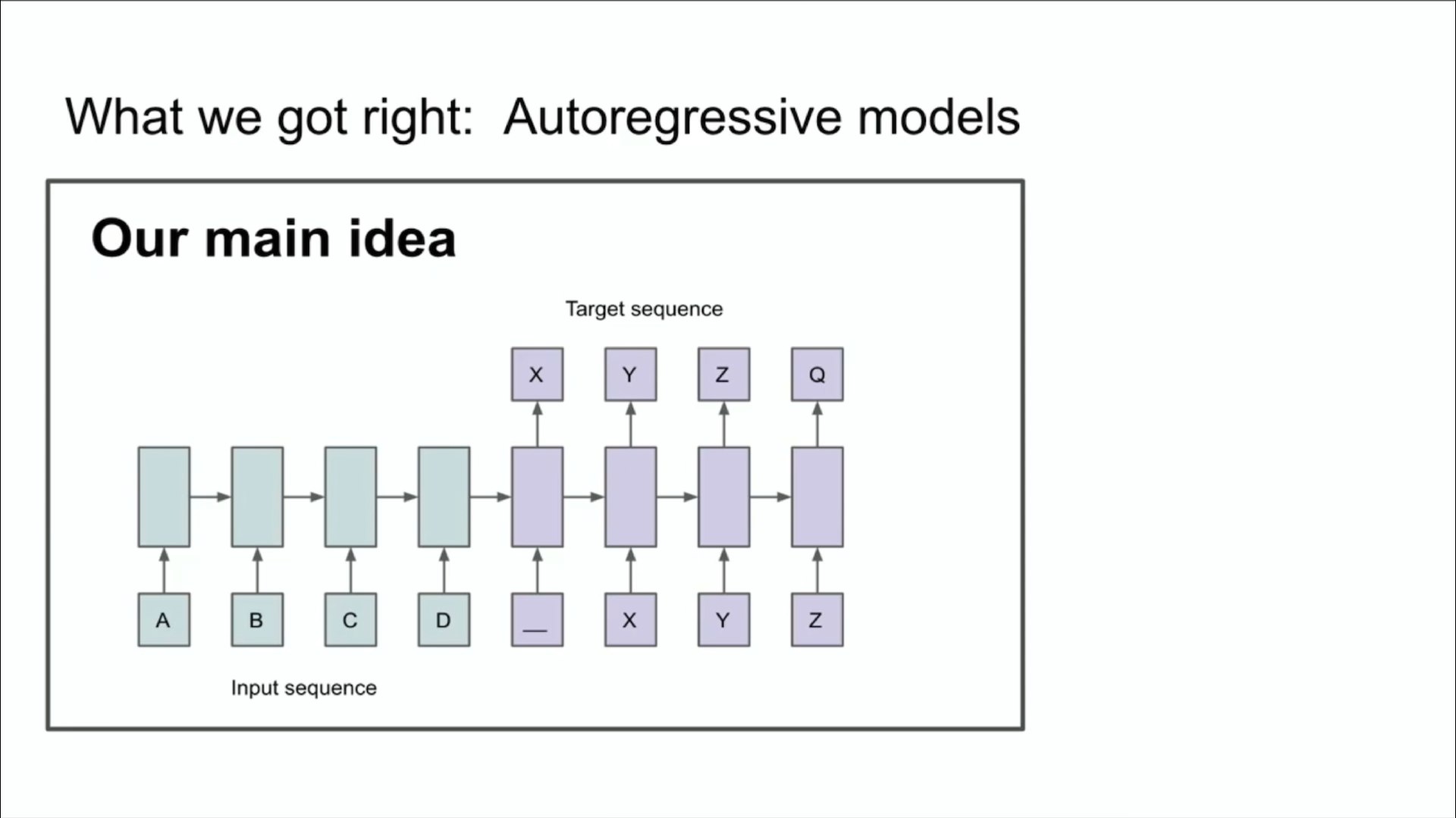
上面是当年演讲所用的另一张幻灯片,这张幻灯片表达了我们的主要思想。你可能从中看出来了两件事,或者至少一件事。你可能意识到这里发生了一些自回归。这张幻灯片说的是,如果你有一个自回归模型,并且它预测下一个 token 的能力足够好的话,那么它就能抓住、捕获并掌握接下来的任何序列的正确分布。
这里的结论在当时就比较创新了。它并不是有史以来第一个自回归神经网络。但我认为它是第一个让我们真的相信,如果你训练得很好,那么你就能得到你想要的任何东西的自回归神经网络。在我们看来,当时的任务今天看来很不起眼,但那时候却非常大胆。
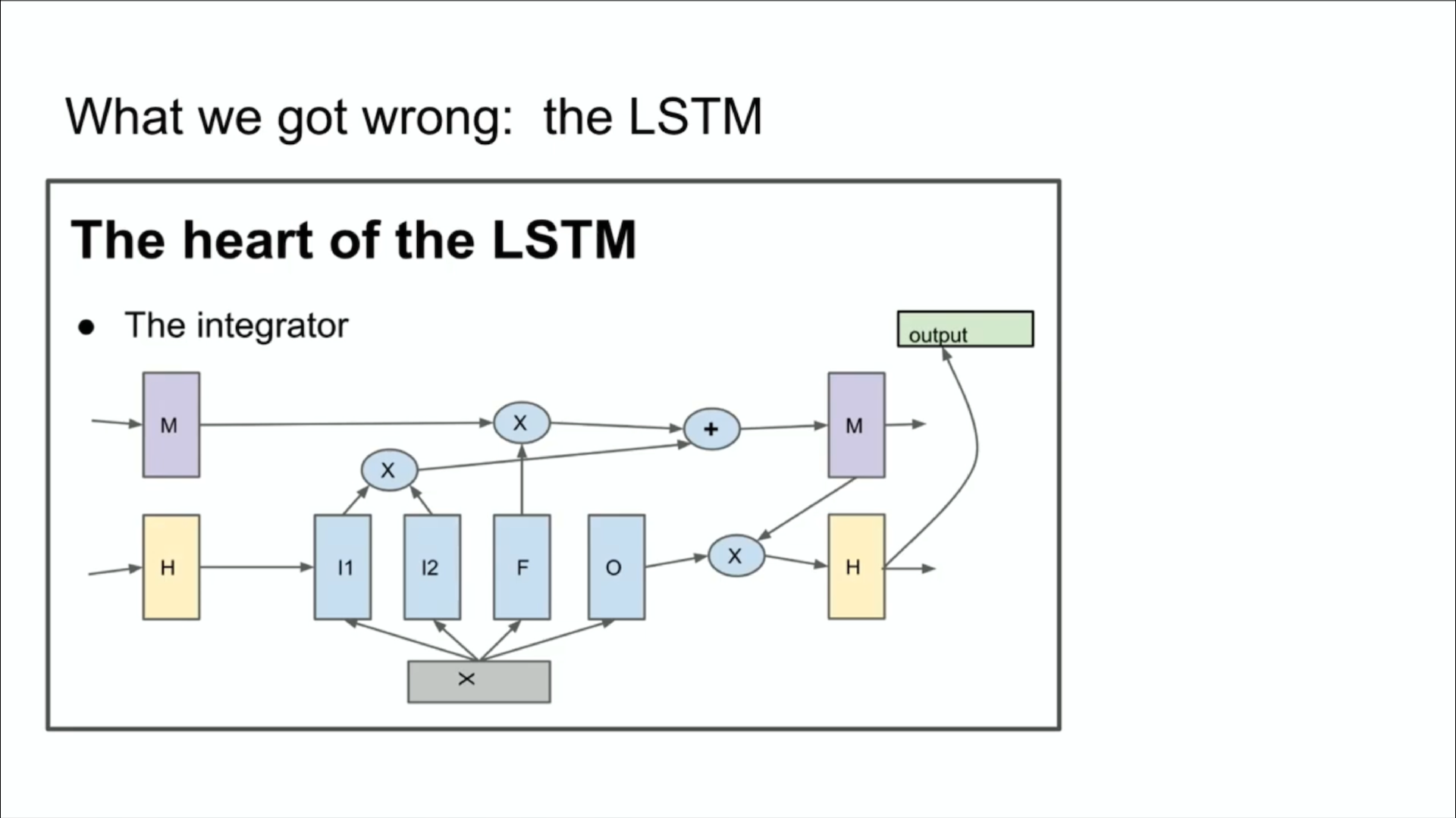
下面我会向你们展示一些你们许多人可能从未见过的古老历史。有的人可能不熟悉,它被称为 LSTM。LSTM 是可怜的深度学习研究人员在 Transformer 之前做的工作。它基本上是一种 resnet,但旋转了 90°。所以上图里是一个 LSTM。它有点像稍微复杂一点的 resnet。你可以看到这里有 integrator,现在称为残差流。图上还有些比较复杂的乘法步骤。总之以前业界做的就是这些。

十年前那场演讲提到的另一个很酷的特性是我们使用的并行化,但那不是一般的并行化。我们使用了流水线,这张图就提到了每个 GPU 处理一层。我们现在已经知道了流水线不是个明智的想法,但当时我们并没有那么明智,所以我们使用了它,用八张 GPU 获得了 3.5 倍的加速比。
从某种意义上说,那次演讲中最后的结论是最重要的部分,因为它可以说是 Scaling Law 这个假设的起源。当时的结论写的是,如果你有一个非常大的数据集,并且能训练一个非常非常大的神经网络,那么你肯定就能成功了!
很多人会说这确实是现在正在发生的事情,不过我想提一下我自己的另一个想法。我认为这个想法才是真正经受住时间考验的那个。这是“部署”本身的核心思想,也是连接主义的思想。这个想法说的是,如果你让自己相信一个人工神经元和一个生物神经元是类似的,那么你就会有信心得出结论:只要有非常大的神经网络(它们不需要真正达到人类大脑的规模,可能稍微小一点),你就可以配置它来做我们人类能做的几乎所有事情。不过这里还是有区别的,因为人类的大脑还能搞清楚如何重新配置它自己,而我们现有的最好的学习算法也需要与参数一样多的数据点。在这方面,人类仍然更胜一筹。
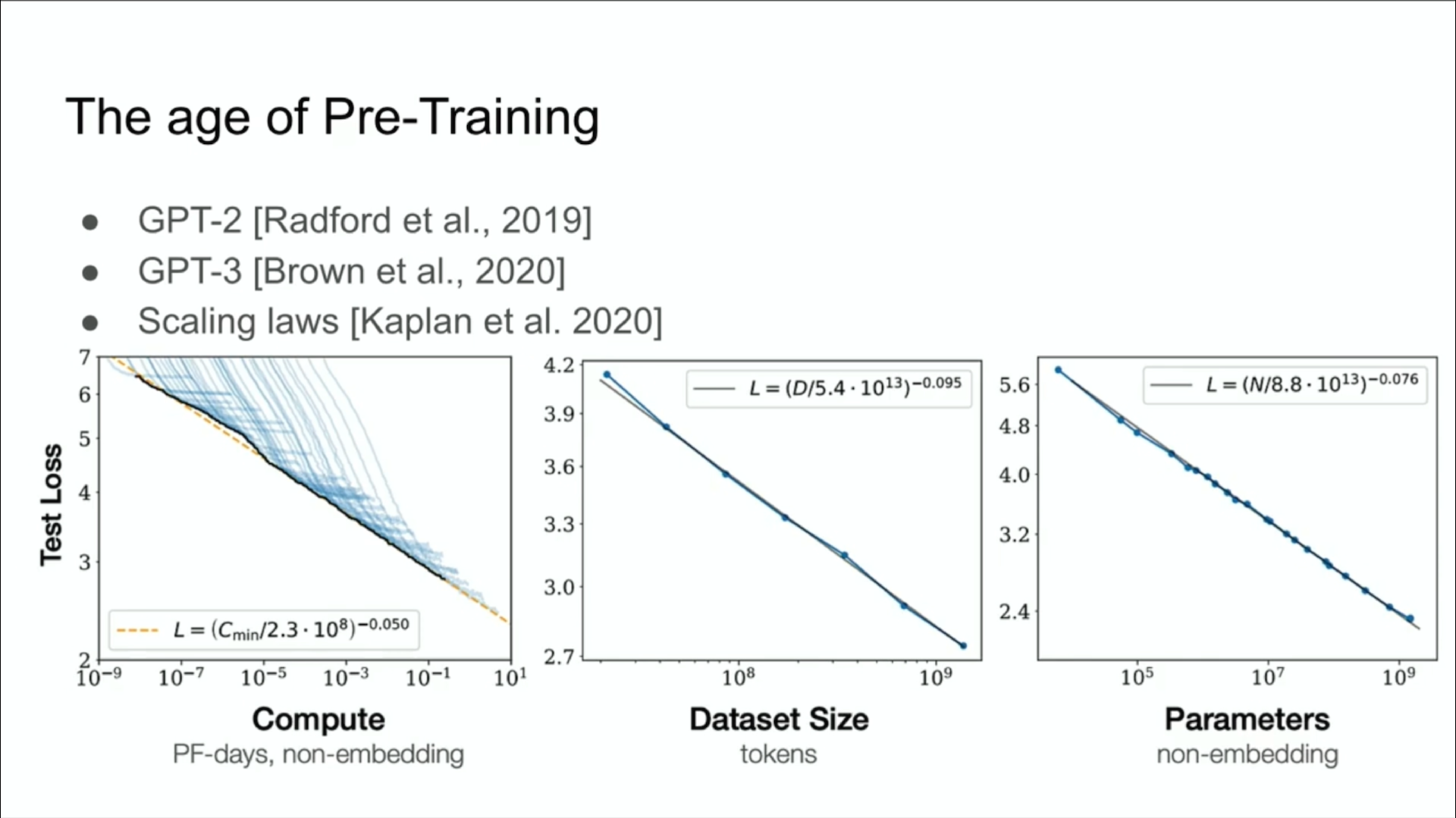
不管怎样,我认为是这个想法引领了预训练时代的到来。我们可以说预训练时代的关键词就是 GPT-2、GPT-3 模型、缩放定律。这个想法就是推动行业进步的动力源泉,也是我们今天看到的所有进步的根源。我们看到了超大型神经网络,在庞大的数据集上进行训练。
但我们理解的预训练时代无疑会迎来终结。为什么?因为虽然计算机行业有了更好的硬件、更好的算法和更大的集群,不断向前发展,但所有这些因素都只会不断增加你的计算能力。数据并没有增长,因为我们只有一个互联网。你甚至可以说,数据是人工智能的化石燃料,它就像以某种方式被预先创造出来的一样(就像化石燃料是古生物化石转化而来的一样)。
现在我们就在使用这些燃料,而且我们已经把数据都用尽了。我们以后只能用现有的这些数据来做事。这些数据还能让我们往前走很长一段路,但不管怎样我们只有一个互联网。
所以在这里,我会稍微猜测一下接下来行业会发生什么事情。
你可能听说过 Agent 这个短语,它很常见,我相信这个领域会有很大前景,但有很多人觉得 Agent 就是未来。下一个是合成数据。合成数据是什么意思?弄清楚这个概念是一个很大的挑战,我相信各种人在这方面有各种有趣的进展。还有推理时间计算,最近我们看到了这方面最生动的例子,就是 GPT o1。这些都是人们试图弄清楚预训练时代结束后大家该做什么事情的探索,也都是非常有价值的探索。
我想再举一个生物学的例子,我觉得这个例子很酷。这个例子是这样的:很多年前,在这个会议上有人在演讲中展示了这张图表。
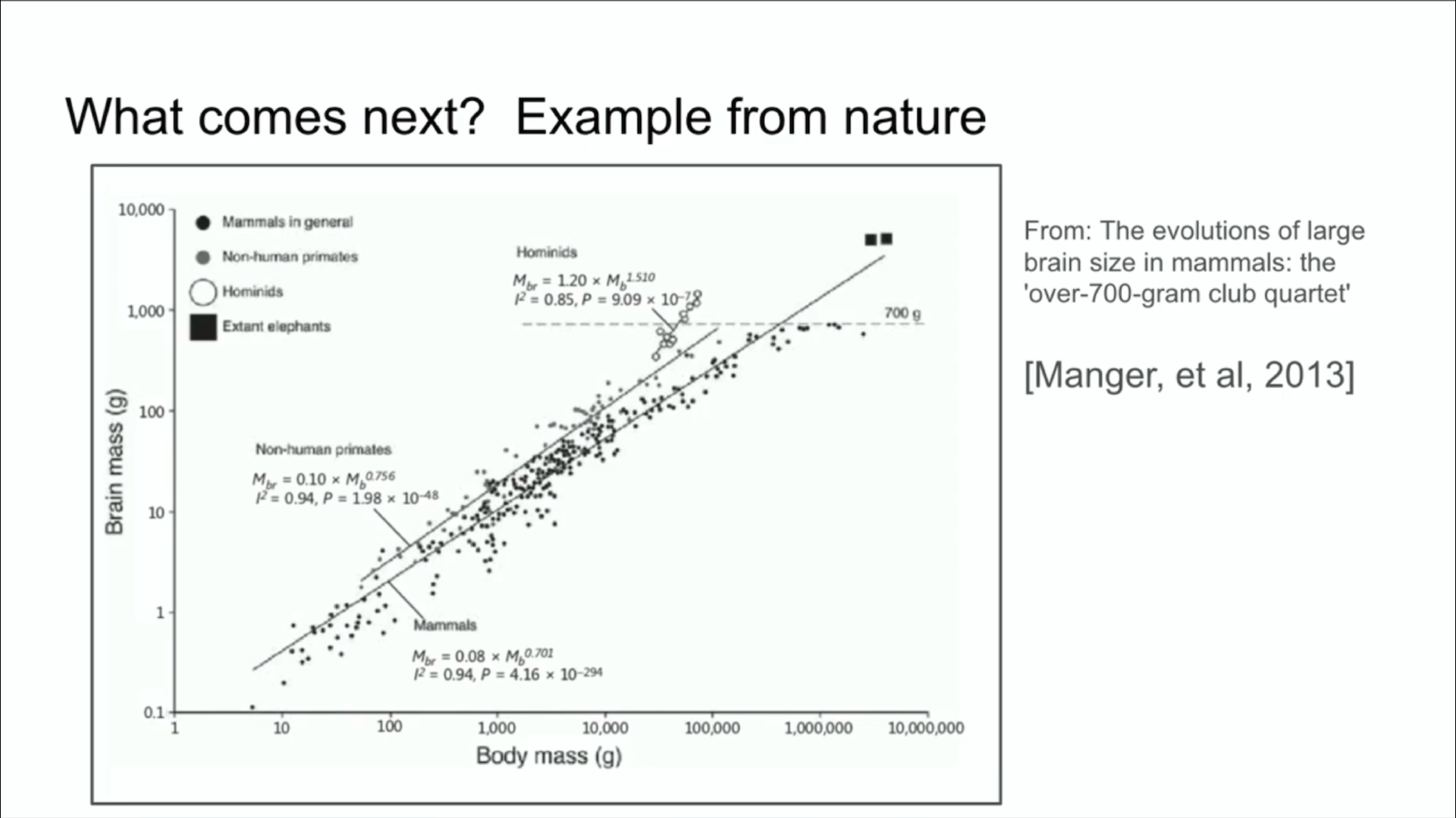
这张图表显示了哺乳动物的身体大小和大脑大小之间的关系,收集了大量数据。那次演讲我印象很深,他们说生物学的领域本来一切都是很混乱的,但这里有一个罕见的例子,就是说动物的身体大小和大脑大小之间存在非常紧密的关系。这张图上有各种哺乳动物,还有非人类的灵长类动物,还有原始人。据我所知,原始人是人类进化过程中的近亲,比如尼安德特人,总之有很多种类。
有趣的是,他们的大脑与身体的比例指数的斜率和别的哺乳动物是不一样的。这意味着自然界有了一个先例。这个例子表明生物圈正在探索某种不同的比例,我认为这很酷。也就是说自然是可以有不同的路径的。我们正在做的事情,我们迄今为止一直在扩展的事情,实际上是我们迈出的第一步,那就是弄清楚该如何扩展。
现在我想花几分钟时间推测一下,长期来看我们都将走向何方?我们已有的所有这些进展都非常惊人,毕竟十年前我们就在这个领域,我能回想起来当时一切都是多么令人感到无助。但我想和大家谈一点超级智能的话题,因为这显然是这个领域的发展方向。超级智能的特点是,它在质量上与我们现有的智能是不一样的。我想尝试给你们一些具体的概念,告诉你们它到底不一样在哪里,这样你们就可以探讨它了。
现在我们有了各种令人难以置信的语言模型,它们是水平非常高的聊天机器人,甚至可以做很多事情,但它们也有点不可靠,有时候会变得很糊涂,但很多时候能表现出远超人类的水平。目前我们还不清楚如何调和这一点。但最终,我们迟早会实现以下目标:
首先,这些系统会真正实现代理化(Agentic)。而现在,这些系统在任何意义上都算不上代理,或者说它们只有那么非常轻微的一点代理化,只是刚刚迈出了第一步而已。
其次,它们能真正掌握推理能力。这里顺便说一句,如果一个系统能做推理的话,它推理得越多,就会变得越不可预测。我们常用的所有深度学习系统都是非常可预测的,因为如果你一直在努力复制人类的直觉,本质上它就会获得这种直觉。我们对人工智能系统赋予了一些直觉。但推理是不可预测的。一个例子是,最高水平的国际象棋 AI 下棋的路数就是顶尖人类选手无法预测的。所以我们将不得不面对非常不可预测的人工智能系统。它们会从有限的数据中理解事物。它们不会对所有有着非常大约束和局限的事物感到困惑。顺便提一下,这里我没提到这样的未来会如何实现,也没说什么时候会实现,我只是说它终将到来。
接下来,所有这些事情实现后,人工智能的自我意识也会相伴而生。因为有什么理由可以阻止这一点呢?自我意识很有用,它是我们人类自己的世界模型的一部分。当所有这些事情结合在一起时,我们将拥有与今天所见的这些 AI 具有完全不同品质和属性的新系统。当然,它们将具有令人难以置信的惊人能力。
但是像这样的系统会带来什么样的问题呢?那就请大家畅想吧,想象一下它与我们今天习惯的一切会有多么大的不同。另外我想说的是,准确预测未来也是人类做不到的,毕竟什么样的可能性都会存在。但在这个令人振奋的时刻,我要说的就是上面这些。
现场问答
问:在 2024 年的今天,还有哪些人类认知的生物结构是你觉得我们值得以类似(探索神经元)的方式探索,或者你觉得很感兴趣的吗?
答:在我看来,如果有人在这方面有一些特别的见解,他觉得我们都太愚蠢了,很明显大脑有一些结构是我们没学过来的,那么这个方向应该是值得他探索的。不过我个人不这么认为。在某种程度上你可以说受生物启发的人工智能技术取得了很大成功,或者说文明的一切成果都受到了生物的启发,但另一方面,生物启发的局限也是很大的。生物只能做到让我们试一试神经元的类似物这种程度,仅此而已,更具体的细节很难通过生物研究出来,但我不会排除这种可能性。我认为,如果有人在这方面有特殊的洞察力,他们可能会看到一些有用的东西。
问:你提到推理可能是未来模型的核心之一,也许是一个差异化因素。我们今天是通过统计分析方法来分析模型是否产生幻觉的,因为我们知道模型欠缺推理能力。那么你是否认为,未来具备推理能力的模型可以自我纠正?它是否能用推理方法发现和理解自己什么时候出现了幻觉?
答:这个答案也是肯定的。我认为你所描述的未来非常非常合理。今天的一些具备早期推理能力的模型中也许已经有了这种能力,而长远来看,未来的模型肯定能做到这一点。
问:有人在讨论未来的人工智能是否需要人类权利的问题。那么我们该如何让今天的人类有动力创造这样的人工智能呢?毕竟它们有可能要求和我们一样的自由。
答:从某种意义上说,这是我们今天应该更多思考的一个问题。但我没信心回答你的问题,因为这可能需要创建某种自上而下的社会治理结构,我想不出来。但顺便说一句,你所描述的情况确实有可能会发生,从某种意义上说,这不是一件坏事。如果我们创造了一种智能,他们想要的只是与我们共存,并且也只是获得一些权利,也许这样就很好了。但具体的东西我就不知道了,我觉得未来很难预测,但我鼓励大家畅想。
问:你认为 LLM 的多跳推理是分布外泛化吗?
答:这个问题的答案不应该是简单的是或者否,首先分布外泛化是什么意思?什么是分布内,什么又是分布外?很久以前,在人们使用深度学习技术之前,他们使用的是字符串匹配之类的东西。对于机器翻译场景,人们当时使用的是成千上万的统计短语表。当时,泛化指的是是否真的与数据集中的措辞是不一样的。
现在,我们的模型可能在数学竞赛中取得非常高的分数,但也许这是因为互联网上一些论坛讨论了竞赛中类似的题目,也就是说这是模型记下来的内容。也许这是分布内的,也许是记下来的。但我也认为我们对泛化能力的标准已经提高了,提高幅度非常大,甚至大到难以想象。我认为人类的泛化能力确实要好得多。但与此同时,模型肯定在某种程度上可以超越分布进行泛化。




