
概述
一般来讲我们是通过写单元测试来验证程序在执行过程中的代码覆盖。覆盖率结果可以从代码行、逻辑判断及函数方法等维度进行分析。得到的数值可以用来检验我们对系统功能的实现程度,也可以反馈出程序设计的完整性。
然而对于一个没有维护单元测试的旧系统,想通过收集覆盖率来检验系统功能和熟悉系统结构不是一件容易的事情。为此我们进行了诸多思考与尝试最终完成阶段性目标。接下来给大家分享下我们的实现方案。
实现原理
不同语言的覆盖率收集,在实现机制甚至语法规范层面都大同小异。先将特定的标记按照一定规则插入到代码行中,这一步我们称为“代码插桩“,然后在执行 case 的过程中收集这些标记的执行情况,最终计算输出覆盖率然后格式化输出结果。大体流程如图所示:

源码编译是可选的,根据源码语言特性进行编译。在 Javascript 的生态中,代码插桩、覆盖率统计这些基础的操作已经有较为完善的第三方类库可以使用,我们选用的是 IstanbulJS。在方案设计时为便于扩展我们没有直接使用它提供的命令行工具:nyc,而是基于 IstanbulJS 的接口 API 进行了重新设计和开发。开发的过程中我们先后使用过 IstanbulJS API 1.0 和 2.0 两个版本,虽然在使用方法上有些差别,但功能大体一致。具体可以参考其官网说明,这里不再赘述 API 的差异性。
工具有了之后接下来的问题就是如何指定 case ?如果是初建项目,功能比较少的情况下手动编写相对完善的 case 还比较可控。如果面对的是功能不熟悉的系统或者逻辑复杂的旧系统呢?由于我们本次针对的 NodeJS 工程是运行在服务端的项目,参考公司内部其它服务端工程 case 的收集方法,最终确定通过日志回放、定时任务等形式来整理 case 。尽管在数量上会有一定的冗余,但是相较于补充单元测试来讲成本更可控。
方案细节
大致了解了实现原理之后,接下来把我们具体实践的方案细节介绍下。
代码插桩
代码插桩是覆盖率收集的前提,这一步主要是对现有代码进行语法层面的分析,并在行内指定的位置加入预设标记。咱们通过一段代码看下处理前后的对比:
原文件:

插桩后文件:

可以看到代码当中多了一些额外的逻辑,其实是针对代码进行不同维度的计数,具体分析这里先不展开。整个过程有几点需要注意:
· 插桩文件的范围,具体范围是针对项目的物理文件目录进行遍历得出,不会分析代码行内的文件依赖关系;
· 是否保留源文件目录,这个需要从工程化层面考虑,最终取决于后续步骤是否在部署机器上完成?最好能有集中的平台处理后续步骤,可以提高部署流程的效率,而且去除源码还能减少 size;
· 源文件插桩时 path 路径的设置,这个路径用于最终回溯源码生成报告使用。要想提高可移植性最好使用相对路径,生成报告时源码路径可以不受绝对路径的限制。这一点在 IstanbulJS API 2.0 的版本中很容易指定;
· 插桩过程的性能,这个涉及到选择同步还是异步 I/O,对于文件数量比较多或者体积较大的工程,可以根据实际情况尝试使用多线程处理(这个要根据实际情况,有的工程文件不超过 10 个,有的则有上千文件)。
收集数据
我们收集 NodeJS 覆盖率数据的过程是动态的,服务启动后不同的外部请求访问可以实时的更新覆盖率数据。下面仍以前文的 demo 为例,通过展开被折叠的代码部分一探究竟!

结合插桩部分的代码,基本可以了解这个文件的覆盖率收集逻辑。程序运行的过程中,不同的请求 case 会执行不同的代码逻辑,同时会执行覆盖率计数逻辑,如此反复执行最终完成覆盖率的统计。
顺便说下,这些用于覆盖率计数的节点其实和不同维度的抽象语法树集合一一对应。
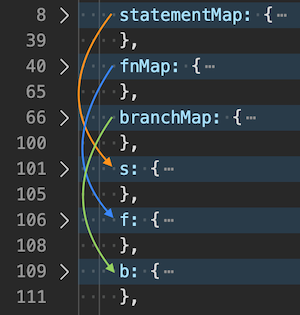
感兴趣的可以深入了解下 JS 语法解析相关的知识。
从前文得知每个模块的数据保持在各自的模块中,然后挂在全局命名空间上实现所有文件共享。那么当程序运行的时候如何获得这些数据呢?我们进行了两个方向的尝试:
首先是内存共享,由于我们的服务一般是通过 PM2 实现的进程守护,所以这个方案是第一时间考虑到的。通过 Message Bus 机制,将不同进程中的覆盖率数据以消息的形式进行传递。数据交互如图所示:
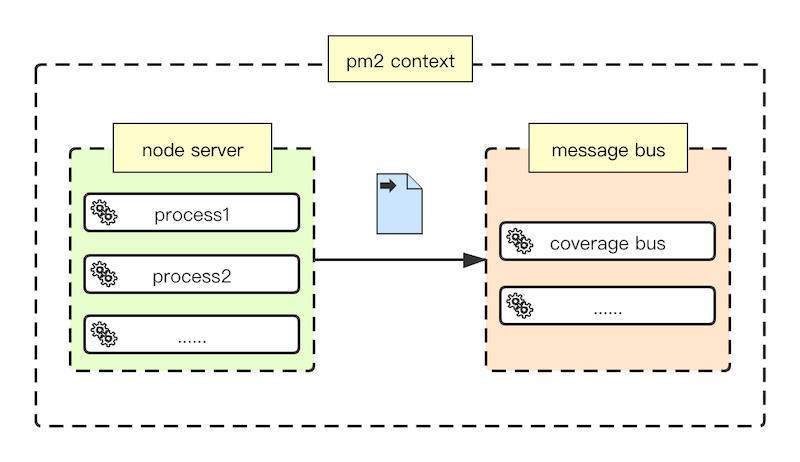
从内存中读取、处理数据可以保证极高的实时性,但是也带来一些问题:
· 可靠性低,内存中的数据一旦丢失不易找回;
· 要注意稳定性,主要表现在当多进程服务传递的数据集较大时(覆盖率数据以 MB 计数很普遍),PM2 内部的消息反序列化消耗很大,消息频次控制不好极易造成较大的硬件压力;
· 耦合性高,功能实现强依赖于 PM2,耦合度太高,无法移植到其它应用场景。
其次是文件存储,把每个进程的内存数据序列化后写入文件,文件按进程 ID 命名避免冲突。数据交互变化如图:
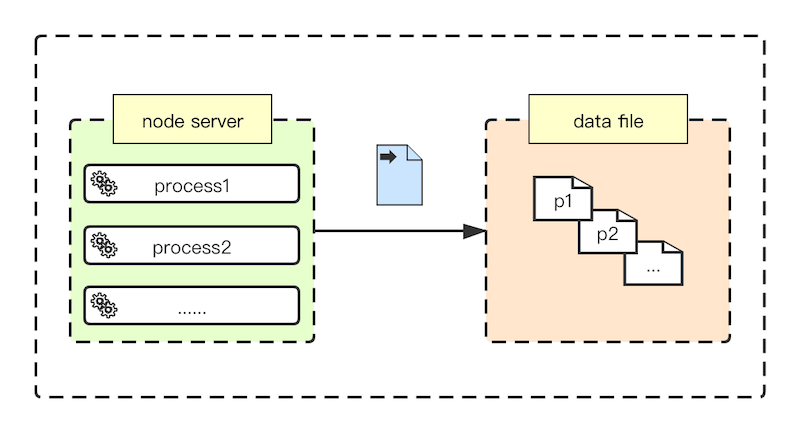
文件存储的方式明显优化了之前的一些问题:
· 可靠性变高,即便是服务出现问题,我们依然可以从数据文件中恢复之前的状态。就如同断点续传,效率上的提升显而易见;
· 稳定性依然要注意,既然涉及到 I/O 操作,那么读写文件时都需要经过周密的设计。尤其是写入频次和读取时机以及同步异步的选择,最常见的一个问题就是频繁操作一个数据文件导致系统 I/O 死锁,瞬间消耗大量资源;
· 耦合性大大降低,文件存储的方式摆脱了对进程守护工具的依赖,理论上可以移植到任意的服务上。经过一段时间的项目实践之后我们决定采用第二种方案!
事实上无论哪种方案还需要一个前提来完成数据收集,就是在服务启动的时候需要预加载一个指定的模块。为了实现任意工程的零成本接入,我们可以采用预设环境变量 NODE_OPTIONS 的方式来引入预加载模块(因为这个设置会影响全局,建议服务启动后移除)。
输出报告
这一步是将之前收集的数据,以摘要或者 HTML 等格式化文档的形式输出结果。如图所示是一种格式:
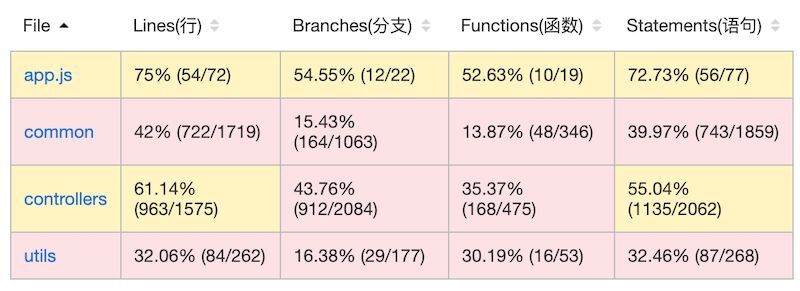
报告的输出格式是多样性的,生成后可以方便的移动和存储。一般来讲报告改动的场景比较少,如果有需求也可以根据覆盖率数据集合中的文件行级别数据进行二次开发。报告内容里有一点需要注意,凡是没有被服务启动脚本引用的文件这里不会输出索引!这个和插桩不一样,报告是根据程序运行时,实际执行到的文件产生的。
总结
我觉得覆盖率是工程质量的一个重要指标,无论开发还是测试都需要关注到这一点,尤其是工程面临比较大的改动的时候。而且从某种意义上讲,覆盖率收集的数据是不是还可以用来做性能监控、代码优化等,这些都值得去深入挖掘。
头图:Unsplash
作者:马涛
原文:https://mp.weixin.qq.com/s/w303m03ZO0qlBUFPs6dCvA
原文:Qunar 酒店 NodeJS 覆盖率收集实践
来源:Qunar 技术沙龙 - 微信公众号 [ID:QunarTL]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




