
数据库是计算机基础学科,几乎贯彻了计算机技术发展,已经成为软件系统的基石,今天银行、电信、互联网等各行各业已经不能离开数据库支撑,数据库全球产值在 2023 年也突破 1000 亿美金。从 1960s 到现在,数据库技术经历了多层变革,这里面是很多数据库领域工程师的深厚沉淀,也涌现了很多图灵奖的大师,今天和大家一起来分享这些大师的故事,向大师致敬。

1. 数据库开创者:查尔斯·巴赫曼(Charles Bachman)
1924~2017

Bachman 在二战期间是在美国陆军高射部队,退伍后开始从事计算机软件开发,1973 年获得计算机图灵奖,以表彰他在数据库管理系统和数据结构设计方面的杰出贡献。巴赫曼是数据库管理系统的开创者,1964 年在通用电气研发了网状数据库 IDS,已经具备了数据库查询语言、索引等基础理念,巴赫曼还开发了一种高级计算机语言——Data Structure Diagrams(DSDs),这种语言可以用于描述数据结构和数据处理的过程,是 E-R 图的前身。巴赫曼还是计算机数据库标准的重要建设者,建立了数据库查询语言、DDL、DML 等基础规范工作。
2012 年,Bachman 被授予美国国家技术与创新奖章,以表彰他在数据库管理、事务处理和软件工程方面的基础发明。
巴赫曼于 2017 年 7 月 13 日在马萨诸塞州列克星敦的家中因帕金森病去世,享年 92 岁。
2. 关系型数据库之父:埃德加·科德(Edgar F. Codd)
1923~2003
英国计算机科学家,1981 图灵奖得主,在第二次世界大战期间担任英国皇家空军海岸司令部的飞行员。
关系型数据库是当今最流行的数据库理论,Oracle、MySQL、DB2、SQLServer、PostgreSQL、Snowflake、Doris、OceanBase、TiDB 等主流数据库都是基于关系型模型建立。
Codd 是理论的开创者,他发表论文,推动 IBM 公司实践,在行业会议上演讲与辩论,最终关系型数据库理论被实践认可。他还提出了一系列关于关系数据库设计和查询的规范和原则,如“关系模型的 12 条规则”(Codd’s 12 Rules)等。科德还在数据建模、数据库设计和程序设计等领域做出了贡献。他提出了“第三范式”(Third Normal Form)的概念,这是一种用于设计关系数据库的规范,能够避免数据冗余和不一致性。他还在程序设计领域提出了“关系演算”(Relational Algebra)的概念,这是一种基于关系模型的查询语言。
Codd 的理论创新是划时代颠覆性的,融合了数学、计算机、数据库的多种知识,在计算机领域是神级人物,为了纪念这位杰出的天才,ACM 还设立了 ACM SIGMOD Edgar F. Codd 创新奖,每年表彰一位在数据库领域杰出的科学家,是数据库领域在最高荣誉奖项。
科德于 2003 年 4 月 18 日在佛罗里达州威廉姆斯岛的家中死于心力衰竭,享年 79 岁。
3.SQL 之父:唐纳德·张伯伦 (Donald D. Chamberlin) & 雷蒙德·博伊斯 (Raymond F. Boyce)

Chamberlin 是 ACM Fellow、IEEE Fellow 和美国国家工程院院士
Raymond F. Boyce(1946~1974) Boyce 除了发明 SQL,还与关系型数据库之父 Codd 联合设计了 BCNF(Boyce-Codd Normal Form),他于 1974 年因动脉瘤去世,年仅 28 岁,留下了他的妻子和他襁褓中的女儿。

Donald D. Chamberlin 和 Raymond F. Boyce 在 IBM 工作期间共同发明了 SQL,关系型数据库是以集合论为基础的理论模型,SQL 是面向集合操作的结构化语言,为关系型数据库发展如虎添翼。
SQL 原名 SEQUEL(A Structured English Query Language), 是数据库的标准操作语言,非常强大,并且简单易用,接近人类的自然语言,也称为第 4 代计算机语言,很多不懂编程的人都能轻松学会 SQL,程序员、数据分析师、运营分析师等都喜欢用 SQL 来操作和分析数据。
SQL 发展也不是一帆风顺,在 2010 年左右 SQL 出现了严重的危机,因为互联网带来了爆炸式的数据增长,数据库扩展性遇到了前所未有的挑战,业界有部分人士认为 SQL 是阻碍数据库扩展的罪魁祸首,于是有了轰轰烈烈的 NoSQL 浪潮,但是经过几年的发展,SQL 是用户的需求,没有 SQL 的数据库非常难用,于是很多 NoSQL 数据库又增加了 SQL 功能,今天包括 Spark、MongoDB、Neo4j 等新时代的数据产品,都支持 SQL 或者类 SQL 的语言。
SQL 在快速演进,增加了 JSON、Graph 等新型数据结构的支持,最新的标准是 SQL 2023。
Boyce 博士刚毕业就能创造 SQL 这样的语言,如果不是英年早逝,现在应该是超神经人物。
4. B-Tree 发明者:鲁道夫·拜尔 (Rudolf Bayer) & 爱德华·麦克雷特 (Edward M.McCreight)
Rudolf Bayer(德国计算机科学家,慕尼黑大学教授,ACM SIGMOD Edgar F. Codd 创新奖)
Edward M.McCreight(CMU 博士,目前在 Adobe)

Rudolf Bayer 和 Edward M.McCreight 在 1972 年共同发明了 B-Tree 数据结构,还发明了红黑树。
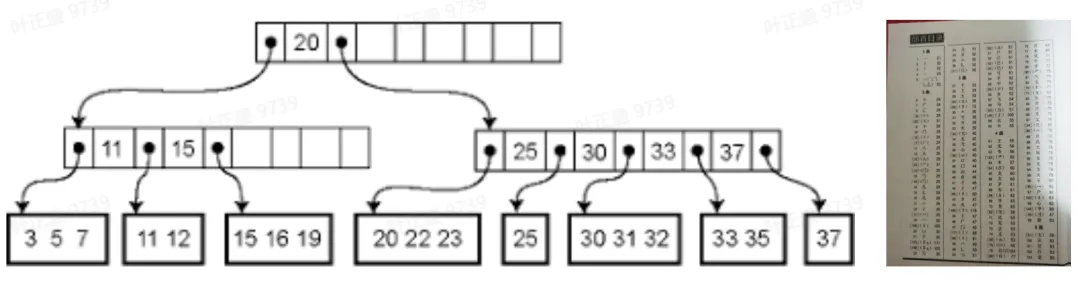
B-Tree 是数据库索引最经典的数据结构,可以用来加速数据查询,通过 B-Tree 索引,可以让数据查询提升成千上万倍,也是数据库优化最重要的手段。B-Tree 的原理和一本新华字典的目录作用很类似,如果一本字典没有目录,那几乎是不可用,B-Tree 索引的价值对于数据库也是如此,B-Tree 现在仍然是经典关系型数据库的核心数据结构。
5. 数据库事务先驱:吉姆·格雷(Jim Gray)

Jim Gray(1944~2007),图灵奖获得者,是数据库事务的重要贡献者。提出了经典的数据库事务 ACID(原子性、一致性、隔离性、持久性)概念,开创性抽象了数据库事务理论。数据库也因为支持事务,才成为了软件系统坚实的基础。没有事务的数据库,很难应用在核心业务生产系统。看看不支持 ACID 事务的系统会发生什么:
不满足一致性(C):定义的主键可能不唯一,假如这个世界有 2 个人的银行账户是一样的(如果你和马云共享同一个账户。。。)
不满足原子性 (A):你给朋友转账,你已经付款了,但是朋友的账户可能会没有收到(也可能你给朋友转账,朋友已经收到钱了,你的账户钱没少)
不满足隔离性 (I):全世界同一时间只能有一个人转账,后面的人都得排队(感受一下被上千万双眼睛盯着的感觉)
不满足持久性 (D):因为停电,银行电脑重启了,重启后发现你的存款可能会没有(如果银行停电,贷款也可能不用还。。。)
Jim 最后工作是在微软,2007 年他驾驶帆船出海,准备把母亲的骨灰撒入大海,但是一去不返,大师永远离开了我们。每年,Microsoft Research 都会向在数据密集型计算领域做出杰出贡献的研究人员颁发 Jim Gray 电子科学奖,以纪念这位传奇的数据库大师。ACM SIGMOD 每年颁发 Jim Gray 最佳博士论文奖。

6. 数据库布道大师:杰弗里·乌尔曼 (Jeffrey D. Ullman)

Ullman 是杰出的计算机科学家,图灵奖获得者,现任斯坦福大学计算机科学系教授。他是数据库领域的重要人物之一,对数据库理论和实践做出了杰出贡献。他还是计算机科学领域的重要教育家和著作家,出版了多部计算机科学领域的经典教材和著作。
Ullman 在数据库领域的研究涵盖了许多方面,如关系数据库、数据挖掘、数据压缩等。他是许多计算机科学领域的重要会议和期刊的编委和主席,如 ACM SIGMOD、IEEE Transactions on Knowledge and Data Engineering 等。他的研究成果和贡献对数据库和计算机科学领域的发展和应用具有重要意义。
Ullman 曾获得过许多荣誉和奖项,包括图灵奖、IEEE 计算机学会杰出工程师奖、ACM SIGMOD 杰出贡献奖等。他还是美国国家工程院和美国国家科学院的院士。他的教学和著作也获得了广泛的认可和赞誉,如《数据库系统实现》、《计算机科学导论》等。

他还是谷歌联合创始人之一谢尔盖·布林(Sergey Brin)的博士生导师,并在谷歌的技术顾问委员会任职。
7. 数据库战神:迈克尔·斯通布雷克(Michael Stonebraker)
Stonebraker 美国计算机科学家,2014 年图灵奖获得者。他在数据库和数据管理方面做出了杰出贡献。他于 1974 年发明了关系数据库系统 Ingres,第一个开源的关系型数据库,具有良好的可扩展性和性能,Ingres 是 PostgreSQL 的前身,Sybase、SQL Server、Informix 也基于 Ingres 发展起来的著名数据库。
Stonebraker 是学术界和工业界结合的大师,他对技术创新和商业化都非常执着:
1974 年,开发了 Ingres 数据库,后来成立了对应的商业化公司 Relational Technology
在 Ingres 基础上开发了 Postgres(后 Ingres)数据库,并成立了对应的商业化公司 Illustra,后来被 Informix 收购,Stonebraker 成为 Informix 的首席技术官
启动了 Mariposa 项目,一个大型联邦分布式数据库,该项目成为商业化公司 Cohera 的基础
发起 Aurora 项目,使用新的数据模型和查询语言,专注于流数据的数据管理, 2003 年创立了 StreamBase Systems,将 Aurora 背后的技术商业化
2005 年开始的 C-Store 项目,一种用于数据仓库的并行、无共享的面向列的 DBMS。通过分割和存储数据,C-Store 能够执行更少的 I/O,并获得比以行存储数据的传统数据库系统更好的压缩比。2005 年,Stonebraker 与他人共同创立了 Vertica,将 C-Store 背后的技术商业化
2006 年,启动了 Morpheus 项目。一个数据集成系统,它依赖于一组“转换”来调解数据源。每个转换都为特定网站或服务提供了一个可查询的接口,而 Morpheus 使搜索和组合多个转换成为可能,以提供新服务或多个服务的统一视图。2009 年,创立了基于 Morpheus 的 Goby,供人们在空闲时间探索新事物。
2007 年,Stonebraker 启动了 H-Store 项目。H-Store 是一种分布式主内存在线事务处理 (OLTP) 系统,旨在为事务处理工作负载提供非常高的吞吐量。2009 年,创立了 VoltDB,并担任其顾问,这是一家基于 H-Store 项目创意的商业创业公司。
2008 年,Stonebraker 启动了 SciDB,一个专门为科学研究应用设计的开源 DBMS。后来基于 SciDB 技术,联合创立了 Paradigm4,主要用于生命科学和金融市场。
年过 80 岁的 Stonebraker,最近,他宣布了新的创业项目 DBOS,2024 年,宣布获得了 850 万美金的投资。
DBOS 是一个面向数据库的操作系统,旨在简化和提高大规模分布式应用程序的可伸缩性、安全性和弹性。它始于 2020 年,是与麻省理工学院、斯坦福大学和卡内基梅隆大学的联合开源项目。
Stonebraker 桃李满天下,一生都是在数据库学术和产业的结合中创新,从 Ingres 到 DBOS,着实让人钦佩。
8. 数据库优化器先驱:帕特里夏 . 塞林格(Patricia G. Selinger)

Patricia G. Selinger 美国计算机科学家,哈佛大学数学博士,美国艺术与科学院院士、ACM Fellow、IBM Fellow
她在 IBM System R 的开发中发挥了重要作用,System R 是关系数据库的先驱实现,并撰写了关于关系查询优化的规范论文。她是关系数据库管理的先驱,也是基于成本的查询优化技术(CBO)的发明者。她是原始 System R 团队的关键成员,该团队创建了第一个关系数据库研究原型。
9. 数据仓库之父:威廉 · 英蒙 (William H. Inmon) & 拉尔夫·金博尔 (Ralph Kimball)

Inmon 是一位美国计算机科学家,被许多人公认为数据仓库之父。Inmon 写了第一本书,召开了第一次会议,在杂志上写了第一个专栏,并且是第一个提供数据仓库课程的人。Inmon 创建了公认的数据仓库定义 - 面向主题的、非易失性的、集成的、时变的数据集合,以支持管理层的决策。
2007 年 7 月,Inmon 被《计算机世界》评为对计算机行业前 40 年影响最大的十人之一
Kimball 是另一位数据仓库先驱
拉尔夫·金博尔(Ralph Kimball) 是数据仓库和商业智能领域的作者。他是数据仓库的原始架构师之一,并以长期的信念而闻名,即数据仓库必须设计为易于理解和快速。他的自下而上方法,也称为维度建模或 Kimball 方法。
Inmon 与 Kimball 都是数据仓库先驱,但是两个人的理念不同,Inmon 讲究的是自上向下构建数据仓库,而 Kimball 更强调自下向上的实践路线。
10. 大数据先驱:杰弗里·迪安 (Jeffrey Dean)
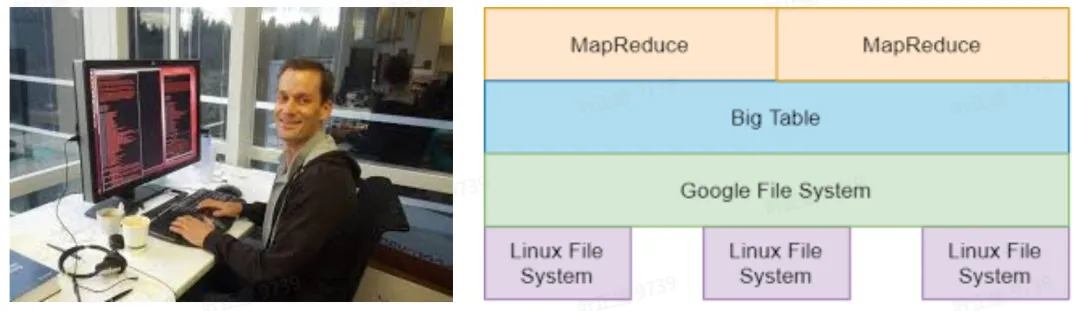
Dean 于 1999 年年中加入 Google,目前是 Google 首席科学家,Google AI 负责人。美国国家工程院院士、美国艺术与科学院院士,2021 年荣获冯. 诺依曼奖。
在谷歌工作期间,他设计并实施了公司的大部分广告、抓取、索引和查询服务系统,以及作为谷歌大多数产品基础的分布式计算基础设施的各种部分。
Dean 参与的项目包括:
Spanner,一个可扩展的、多版本的、全球分布的、同步复制的数据库
Bigtable,一个大型半结构化存储系统
MapReduce,一个用于大规模数据处理应用的系统
LevelDB,一个开源的磁盘键值存储
DistBelief,一个用于深度神经网络的专有机器学习系统,最终被重构为 TensorFlow
TensorFlow,一个开源机器学习软件库
自从 Google 发表了 Bigtable、MapReduce、GFS 大数据领域三驾马车后,大数据理念开始席卷全球,开源社区纷纷效仿 Google 的论文推出产品,包括 Hadoop、HDFS、HBase、Hive、Spark、TiDB 等等,可以说 Google 打开了大数据的大门,Dean 一时间被业界当成神一样的人存在,Dean 是 Google 技术的杰出代表人物。Dean 现在是 Google AI 的负责人,在 AI 大模型新时代,OpenAI 领先一步,Dean 能否带领 Google 王者归来呢?
11. 数据库基准测试先驱:大卫. 德威特 (David DeWitt)

DeWitt 教授以其在并行数据库、基准测试、面向对象数据库和 XML 数据库领域的研究而闻名,1998 年,他被选为美国国家工程院院士
DeWitt 硬刚 Oracle Larry 的历史
背景:DeWitt 在威斯康星大学期间发表了 Oracle 数据库性能测试的文章,文章内容显示 Oracle 数据库性能不佳,Oracle 的 CEO Larry 非常不满,要 DeWitt 道歉,但是 DeWitt 并未同意。据说 Larry 直接打电话给威斯康辛大学的计算机系,要求系里把 David DeWitt 给开除了,但是威斯康辛大学并未同意。
最后 Larry 在 Oracle 数据库中增加了一项最终用户许可协议条款,称为 DeWitt 条款,禁止研究人员和科学家在学术论文中明确使用其系统名称。后面一些商业数据库供应商也参考 Oracle 的做法,增加了同样的条款。
2023 年,Snowflake 和 Databricks 的性能大战中,双方都同意把 DeWitt 条款限制拿掉,终于能甩开膀子撕逼了。
数据库基准测试是推进数据库发展的基础,DeWitt 在威斯康辛大学期间做了大量的数据库基准测试,并形成了 Wisconsin Database Benchmark,也是业界第一个数据库基准测试。
关于作者
叶正盛,NineData 创始人 &CEO,资深数据库专家,原阿里云数据库产品管理与解决方案部总经理。NineData(www.ninedata.cloud)是云原生数据管理平台,提供数据库 DevOps(SQL IDE、SQL 审核与发布、性能优化)、数据复制(迁移、同步、ETL)、备份等功能,可以帮助用户更安全、高效使用数据。
https://en.wikipedia.org/wiki/Edgar_F._Codd
https://en.wikipedia.org/wiki/Patricia_Selinger
https://www.ibm.com/history/patricia-selinger
https://en.wikipedia.org/wiki/David_DeWitt
https://en.wikipedia.org/wiki/Rudolf_Bayer
https://en.wikipedia.org/wiki/Edward_M._McCreight
https://en.wikipedia.org/wiki/Raymond_F._Boyce
https://en.wikipedia.org/wiki/Charles_Bachman
https://en.wikipedia.org/wiki/Michael_Stonebraker
https://en.wikipedia.org/wiki/Jeffrey_Ullman
https://en.wikipedia.org/wiki/Jeff_Dean
https://en.wikipedia.org/wiki/Bill_Inmon
https://en.wikipedia.org/wiki/Ralph_Kimball
https://en.wikipedia.org/wiki/SIGMOD_Edgar_F._Codd_Innovations_Award
https://en.wikipedia.org/wiki/DBOS




