

作为即将告别大学的机器学习毕业狗的你,会不会有种迷茫的感觉?你知道 HR 最看重的是什么吗?在求职季到来之前,毕业狗要怎么做,才能受到 HR 的青睐、拿到心仪的 Offer 呢?负责帮助应届生找到机器学习工作的 Edouard Harris 给我们分享了他见到的例子和观点,希望对面临就业压力不断增大的毕业狗们有点用!
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
我是一名物理学家,在 YC 初创公司工作。我们的工作是帮助应届毕业生找到他们的第一份机器学习工作。
前段时间,我曾写了一篇文章《The cold start problem: how to break into machine learning》(《冷启动问题:如何顺利进入机器学习》),阐述了为得到第一份机器学习的工作,你应该做哪些事情。我在那篇文章中说过,你应该做的一件事就是,建立个人机器学习项目的投资组合。但我漏了这一部分:如何才能做到。因此,在这篇文章中,我将阐述应该如何去做这件事。[1]
得益于我们的初创公司所做的事情,我才能看到如此多的个人项目的例子。这些个人项目有非常优秀的,也有非常槽糕的。让我给你例举两个非常优秀的例子。
押上所有赌注
下面是一则真实的故事,不过,为了保护个人隐私,我使用了化名。
当杂货店需要订购新库存时,X 公司就会使用人工智能来提醒杂货店。我们有一名学生,叫 Ron,他非常渴望能够在 X 公司工作,已经急不可耐了。为了确保能够得到 X 公司的面试机会,于是,他建立了一个个人项目。
通常情况下,我们不会建议像 Ron 那样把所有的赌注都押在一家公司。如果你刚开始这样做的话,是很有风险的。但是,就像我刚才说的,Ron 真的特别想到 X 公司工作,特别特别想。
那么,Ron 做了什么呢?

红框处表示该处缺少商品。
Ron 用胶带将他的智能手机绑在购物车上。然后,他推着购物车在杂货店的过道来来回回地走,同时使用手机的摄像头记录下过道的情况。他在不同的杂货店这样做了 10~12 次。
回到家后,Ron 就开始构建机器学习模型。他的模型识别出了杂货店货架上的空白处,那是货架上缺少玉米片(或其他商品)的地方。
特别棒的是,Ron 在 GitHub 上实时构建了他的模型,完全公开。每天,他都会改进他的 repo(提高准确性,并记录 repo 自述文件的变更)。
当 X 公司发现 Ron 正在做这件事时,非常感兴趣。不止是好奇,事实上,X 公司还有点紧张。他们为什么会感到紧张呢?因为 Ron 无意中在几天内复制了他们的专有技术栈的一部分。[2]
X 公司的能力很强,他们的技术在行业中无出其右。尽管如此,4 天之内,Ron 的项目还是成功吸引了 X 公司 CEO 的注意力。
飞行员项目
这是另一则真实的故事。
Alex 主修历史专业,辅修俄语(这是真实的情况)。不同寻常的是,作为历史专业的大学生,他居然对机器学习产生了兴趣。更不寻常的是,他决定学习 Python,要知道,他从来没用 Python 写过一行代码。
Alex 选择了通过构建项目进行学习的方式。他决定构建一个分类器,用于检测战斗机飞行员在飞机上是否失去知觉。Alex 想通过观看飞行员的视频来发现是否失去意识。他知道,人们通过观察,很容易判断飞行员是否失去知觉。所以,Alex 觉得机器也应该有可能做到这一点。
以下是 Alex 在几个月的时间里所做的事情:
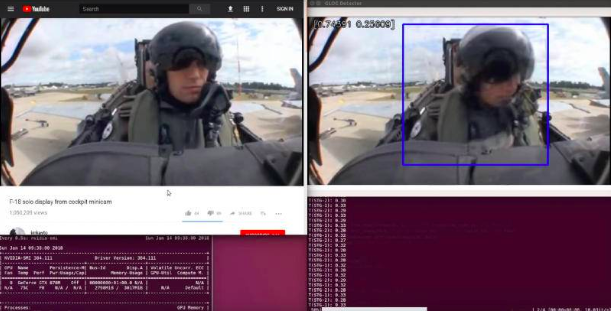
Alex 构建的地球引力引发昏厥探测器的演示。
Alex 在 YouTube 上下载了从驾驶舱拍摄的驾驶飞机时飞行员所有的视频。(如果你也感到好奇的话,这里有几十个这样的片段。)
接下来他开始标记数据。Alex 构建了一个 UI,让他能够滚动数千个视频帧,按下一个按钮表示 “有知觉”,另一个按钮表示 “无知觉”。然后自动将该视频帧保存到正确标记的文件夹中。这个标记过程非常非常无聊,花了他好几天的时间。
Alex 为这些图像构建了一个数据管道,可以将飞行员从驾驶舱背景中抠出来,这样分类器就能更容易专注于飞行员。最后,他构建了自己的昏厥分类器。
在做这些事的同时,Alex 在社交媒体上向招聘主管展示了他的项目快照。每次
他拿出手机展示这个项目时,他们都会问他是怎么做到的,构建的管道是怎么回事,以及怎么收集数据的等等。但从来没有人问过他的模型的准确度如何,要知道,这个模型的准确度就从来没超过 50%。
当然,Alex 早就计划提高模型的准确性,但是在他还没有实现这一计划时就已经被录用了。事实证明,对企业而言,他那个项目呈现出来的视觉冲击力,以及在数据收集方面表现出来的不屈不挠的精神和足智多谋,远比他的模型究竟有多好来得更为重要。
我刚才有没有提到 Alex 是一名主修历史,辅修俄语的学生?
他们有何共同之处
是什么让 Ron 和 Alex 如此成功?以下是他们做对的四件大事:
Ron 和 Alex 并没有在建模上耗费太多的精力。我知道这听上去很奇怪,但是对于现在的许多用例来说,建模是一个已解决的问题。在实际工作中,除非你做的是最先进的人工智能研究,否则无论如何,你都需要耗费 80~90% 的时间来清理数据。为什么你的个人项目会有所不同呢?
Ron 和 Alex 都收集了自己的数据。正因为如此,他们最终得到的数据比 Kaggle 或 UCI 数据库中的数据更为混乱。但是处理混乱的数据教会了他们如何处理这种混乱的数据。而且也迫使了他们从学术服务器下载数据以更好地理解自己的数据。
Ron 和 Alex 营造了可视化效果。面试,并不能让无所不知的面试官能够客观地评估你的技能。面试的本质就是将自己推荐给他人。人类是视觉动物,因此,如果你掏出手机给面试官展示你所做的东西,那么,确保你做的东西看上去很有趣是值得的。
Ron 和 Alex 所做的事似乎很疯狂。这太疯狂了。因为一般人不会把他们的智能手机用胶带绑在购物车上,也不会在 YouTube 上耗费大量时间就为了裁剪飞行员的视频。你知道是什么样的人才会这么疯狂?这样的人才会不惜一切代价去完成工作。公司真的非常、非常愿意雇佣这种人。
Ron 和 Alex 所做的事情,看上去似乎太多了,但实际上,他们所做的事儿并不比你在实际工作中所期望的多多少。这就是问题的关键:当你没有做某件事的工作经验时,招聘经理会看你做过的类似做某件事的工作经验。
幸运的是,你只需在这个级别上,构建一两个项目就可以了——Ron 和 Alex 的项目在他们各自所有面试中被反复使用。
因此,如果让我必须用一句话来总结一个卓越的机器学习项目的秘诀,那就是:用有趣的数据集去构建项目,这个数据集显然需要耗费大量精力来收集,并使其尽可能有视觉冲击力。
[1] 如果你想知道为什么这一点非常重要,那是因为招聘经理会查看你的业绩记录来评估你的技能。如果你没有业绩记录的话,那么,个人项目就是最为接近的替代者。
[2] 当然,Ron 的尝试远非完美:X 公司为这个问题投入了比他更多的资源。但情况非常相似,他们很快就要求 Ron 将他的 repo 设为 private。
原文链接:

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论