
导语 | 年久失修的老接口堪称所有程序员们的噩梦,它们逻辑复杂、严重卡顿、无人维护,令经手的开发头痛不已。本文将为大家分享通过 nodejs + graphQL + redis + schedule 技术组合对老接口进行优化提速,提升前端体验的原理与实践,希望与大家一同交流。文章作者:艾瑞坤,腾讯前端研发工程师。
一、背景
最近在维护一个老项目的时候,发现页面严重卡顿,页面长时间展示“加载等待中”。经过分析发现有一个老接口调用延时非常高,平均调用时间在 3s 以上。
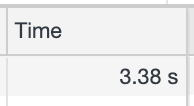
每次在加载页面和翻页时都会停顿很久,严重影响体验。老接口服务存在以下几个问题:
太多无效数据 :接口返回数组的每条数据都包含了上百个字段,而前端展示只使用了其中 10 字段,太多的无效数据占据了接口传输时间。
接口调用链过长 :接口存在复杂逻辑,并且老接口内部还调用了其他 n 个接口的服务,导致前端调用接口延时过长。
代码年久失修 :老接口服务没人维护,无人知道如何修改和部署,没有文档,调用全靠猜。
作为一个前端工程师,如何在不修改老接口代码的情况下去优化这个接口延时过长的 case 呢?
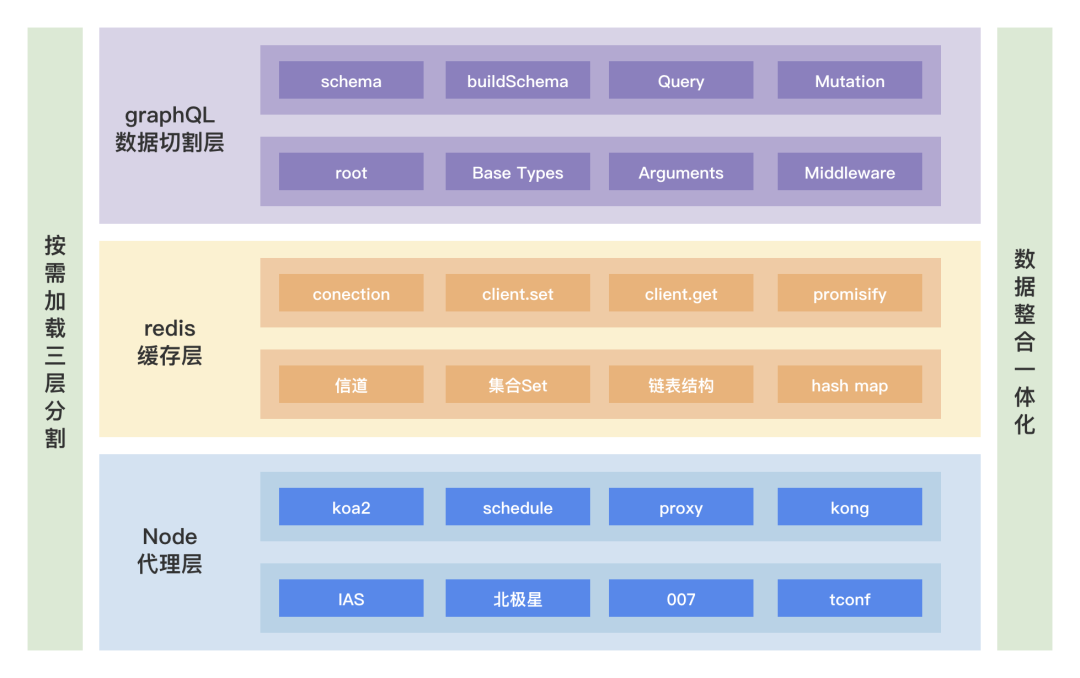
笔者决定做一个 node 代理层,用下面三个方法进行优化:
按需加载 -> graphQL :通过描述接口协议字段的结构,然后配置指定规则 schema,对数据进行字段的按需加载。
数据缓存 -> redis :用 redis 来对老接口服务返回的数据进行缓存,让用户请求绕过老接口的复杂逻辑,直接获取数据。
轮询更新 -> schedule :用 node-schedule 定时更新数据缓存,保证用户每次请求获取最新数据。
整体架构如下图所示:
二、按需加载 graphQL
由于前端需要绘制一个图表,我们每次请求接口都要返回 1000 多条数据,返回的数组中,每一条数据都有上百个字段,其实我们前端只用到其中的 10 个字段进行展示和绘制图表。
如何从一百多个字段中,抽取任意 n 个字段,这就用到 graphQL。graphQL 按需加载数据只需要三步:
定义数据池 root;
描述数据池中数据结构 schema;
自定义查询数据 query。
1. 定义数据池 root
由于原业务逻辑和接口协议比较复杂,没法一一在文中叙述。为了方便理解,我用“屌丝追求女神”的场景来说明 graphQL 按需加载字段的实现。
首先我们定义一个女神 girls 数据池,里面包含女神的所有信息,如下:
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }] }, { id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }] }]}数据池包含了两个女神的所有信息,包括女神的名字(name)、手机(iphone)、微信(weixin)、身高(height)、学校(school)、备胎们的信息(wheel)。接下来我们再对这些数据结构进行描述。
2. 描述数据池中数据结构 schema
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(` type Wheel { name: String, money: String } type Info { id: Int name: String iphone: Int weixin: String height: Int school: String wheel: [Wheel] } type Query { girls: [Info] }`);上面这段代码就是女神信息的 schema,schema 其实就是将女神的信息进行结构化,经过结构化的数据,才可以进行数据按需获取。
在 nodejs 中使用 graphql 这个库,里面包含了 graphQL 操作字段的所有 api。我们用 buildSchema 这个方法来构建女神信息的 schema。
那么如何描述女神信息的 schema 呢?首先我们用 type Query 定义了一个对女神信息的查询,里面包含了很多女孩 girls 的信息 Info,这些信息是一堆数组,所以是[Info]。
我们在 type Info 中描述了一个女孩的所有信息的维度,包括名字(name)、手机(iphone)、微信(weixin)、身高(height)、学校(school)、备胎集合(wheel)。
数据类型主要是 String 和 Int,如果出现了嵌套对象类型,就参考备胎(wheel)的定义方式,单独用 type 定义一个 Wheel 备胎类型,这样就可以进行结构化的复用类型了。
3. 定义查询规则 query
得到女神的信息描述(schema)后,就可以自定义各种组合,获取女神的信息了。比如我想和女神认识,只需要拿到她的名字(name)和微信号(weixin)。查询规则代码如下:
const { graphql } = require('graphql');// 定义查询内容const query = ` { girls { name weixin } }`;// 查询数据const result = await graphql(schema, query, root);对女神的名字、微信构造了一个 query 查询,注意这个语法不是我们前端的 json 语法,是 graphQL 特定的语法。
查询的时候,我们使用 graphql 这个库里面的 graphql 方法,将女神信息描述 schema、女神数据池 root、查询语句 query 一并传入 graphql 方法,这样就可以对数据进行按需加载了。
筛选结果如下:

我们按需获取到了女神的名字、微信,剔除女神了其他不需要的信息手机、身高、学校、备胎,这就是 graphQL 的核心思想:按需加载数据。
又比如我想进一步和女神发展,我需要拿到她备胎信息,查询一下她备胎们(wheel)的家产(money)分别是多少,分析一下自己能不能获取优先择偶权。查询规则代码如下:
const { graphql } = require('graphql');// 定义查询内容const query = ` { girls { name wheel { money } } }`;// 查询数据const result = await graphql(schema, query, root);这个例子我们涉及到了一个嵌套查询,把女神名下所有备胎的 money 全查了出来
筛选结果如下:

我们通过女神的例子,展现了如何通过 graphQL 按需加载数据。映射到我们业务具体场景中:老接口返回的每条数据都包含 100 个字段,我们配置 schema,获取其中的 10 个字段,这样就避免了剩下 90 个不必要字段的传输。
graphQL 还有另一个好处就是可以灵活配置。这个接口需要 10 个字段,另一个接口要 5 个字段,第 n 个接口需要另外 x 个字段,按照传统的做法我们要做出 n 个接口才能满足,现在只需要一个接口配置不同 query 就能满足所有情况了。
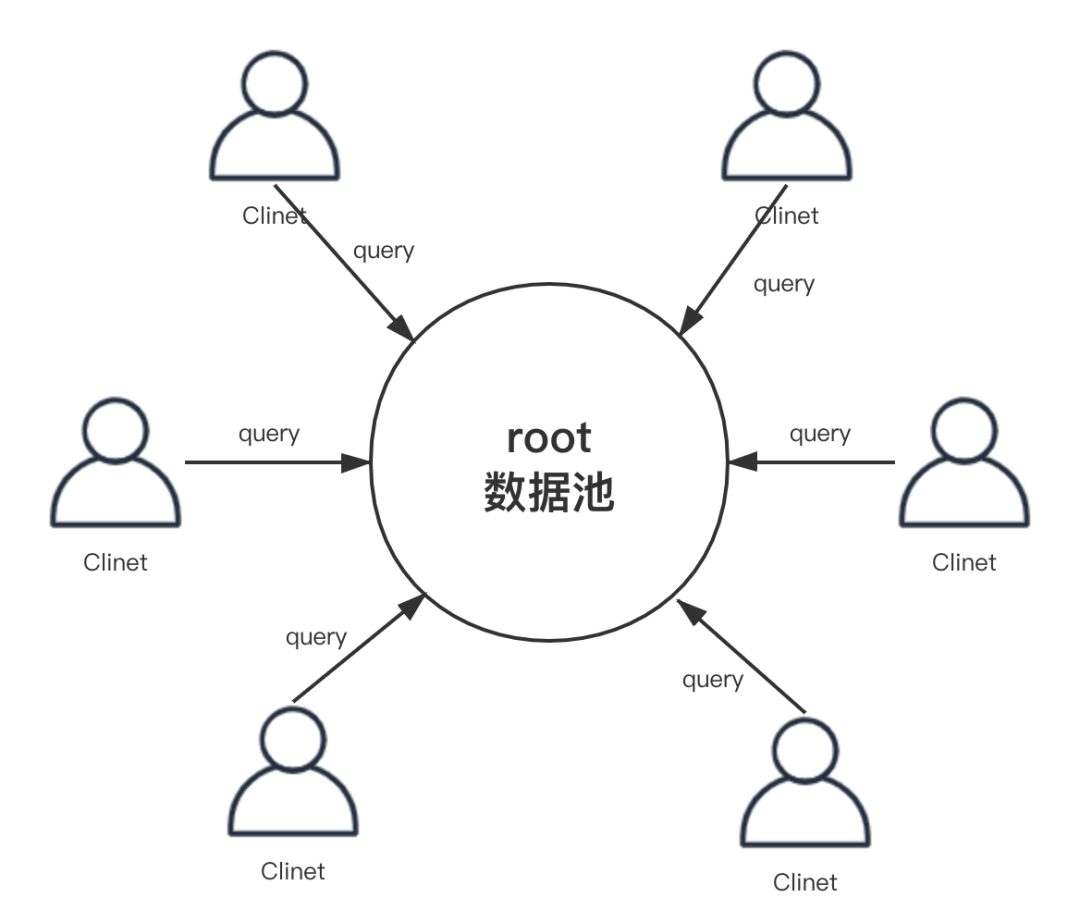
三、缓存 redis
第二个优化手段,使用 redis 缓存。老接口内部还调用了多个其他第三方接口,极其耗时耗资源。我们用 redis 来缓存老接口的聚合数据,下次再调用老接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口 let result = await getAsync("缓存"); if (!result) { // 拉接口 const data = await 老接口(); result = data; // 设置缓存数据 await setAsync("缓存", data) } return result;}list();我们用 redis 的 npm 包来进行缓存相关的操作,redis 类似咱们的数据库,开始的时候先用 redis.createClient 建立连接。
由于 redis 提供的方法都是异步回调的函数,所以我们用 promisify 给所有函数包一下让我们能用 async/await 进行同步调用。
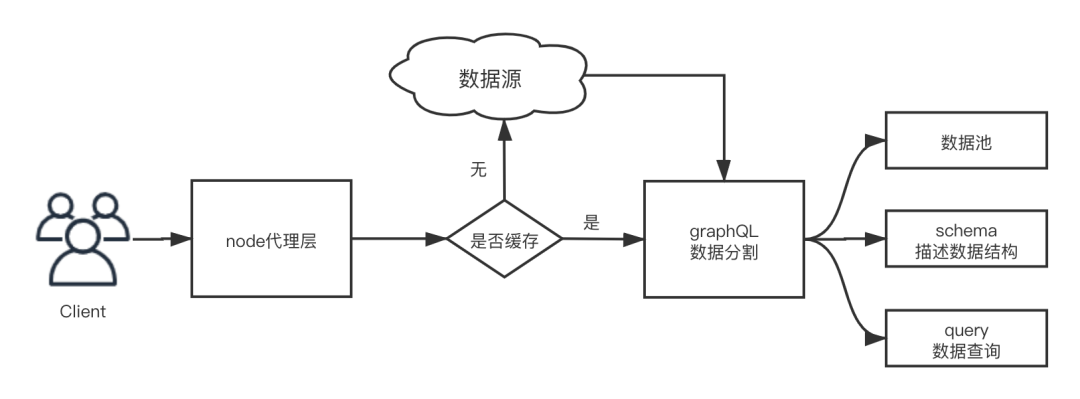
每次接口调用的时候,我们先通过 getAsync 来读取 redis 缓存中的数据,如果有数据,直接返回,绕过老接口复杂调用。
如果没有数据,就调用老接口,用 setAsync 将老接口返回的数据存入缓存中,以便下次调用。主体流程如下图所示:
因为 redis 存储的是字符串,所以在设置缓存的时候,需要加上 JSON.stringify(data)。
将数据放在 redis 缓存里有几个好处,可以实现多接口复用、多机共享缓存等。
四、轮询更新 schedule
最后一个优化手段:轮询更新 -> schedule。
数据源一直在变化,会导致缓存的数据与数据源不一致,需要定时更新。更新的方法有很多种,听专业的后端小伙伴说有分段式数据缓存、主从同步读写分离、高并发同步策略等等。
由于我不是专业的后端人员,并且老接口调用量不大,对应的数据源更新频率低。所以我用了最简单的轮询更新策略。代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据 await setAsync("缓存", data)});用 node-schedule 这个库来进行定时轮询更新缓存,设置轮询间隔为* * 0 * * *,这句代码的意思就是设置每个小时的第 0 分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中。
这样每当前端在调用接口的时候,就能获取到最新数据,避免了直接调用老接口,直接将缓存中的数据取出并快速返回前端。这就是 redis 缓存和轮询更新的好处。
五、结语
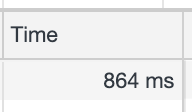
经过以上三个方法优化后,接口请求耗时从 3s 降到了 860ms,用户体验得到了显著的提升。
这些代码都是从业务中简化后的逻辑,真实的线上 ToC 业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等。
每一块技术点都需要专研和实践,由于笔者是前端开发,对后端知识和技术理解有限,如有什么说的不对和不完善的地方,欢迎在评论区与我交流。
参考资料:
[1] 本文项目 github 地址:
https://github.com/airuikun/blog/tree/master/src/graphql%2Bredis
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:




