
4 月 20 日,AI 作画神器 Stable Diffusion 背后公司 Stability AI 发布了新的开源语言模型 StableLM。
这套模型的 Alpha 版分 30 亿和 70 亿参数两个版本,后续还有 150 亿到 650 亿参数的更多模型变体。
开发人员可以出于商用或研究等用途,自由体验、使用和微调 StableLM 基础模型,但须遵守 CC BY-SA-4.0 许可条款。

“一只随意样式的鹦鹉,扁平设计,矢量风格” — Stable Diffusion XL
2022 年,Stability AI 公开发布了 Stable Diffusion。这套革命性的图像模型,标志着不同于专有 AI 的透明、开放、可扩展替代方案已经出现。
随着 StableLM 模型套件的推出,Stability AI 继续践行着让每个人都能用上基础 AI 技术的基本宗旨。StableLM 模型能够生成文本和代码,并将为一系列下游应用程序提供支持。项目的意义,在于展示小规模高效模型如何通过适当训练提供出色的性能。
StableLM 的发布,建立在 Stability AI 与非营利性研究机构 EleutherAI 的早期开源语言模型的经验之上。这里的早期开源模型包括 GPT-J、GPT-NeoX 和 Pythia 套件,并在 The Pile 开源数据集上进行训练。近期众多开源语言模型同样以这些努力成果为基础,例如 Cerebras-GPT 和 Dolly-2 等。
StableLM 利用 The Pile 上的新实验数据集进行训练,但模型规模增大了 3 倍,包含 1.5 万亿个内容 token。
Stability AI 表示,将在适当的时候发布关于数据集的细节信息。这套数据集的高丰富度,使得 StableLM 在会话和编码任务中表现出惊人的高性能,且继续保持着相对较小的参数量——只有 3 亿至 70 亿之间(与之对应,GPT-3 拥有 1750 亿个参数)。
Stability AI 还发布了一系列经过指令微调的研究模型。这 5 套经过开源数据集微调的模型均为对话智能体,分别为 Alpaca、GPT4All、Dolly、ShareGPT 以及 HH。目前这些模型仅供研究用途,基于非商用 CC BY-NC-SA 4.0 发布,且遵循斯坦福大学的 Alpaca 许可。
以下各图,为 70 亿参数微调模型生成的对话示例:
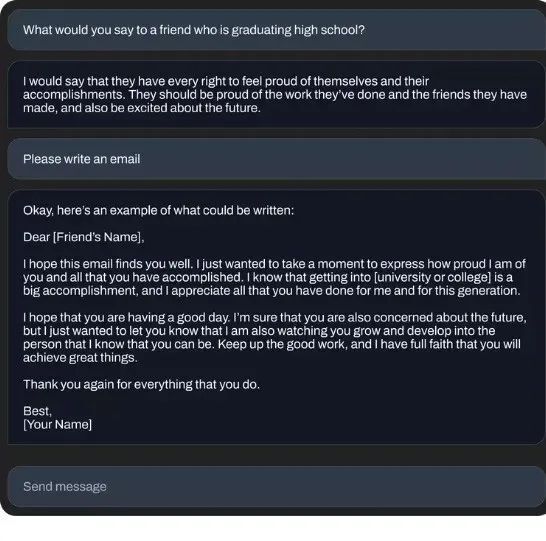

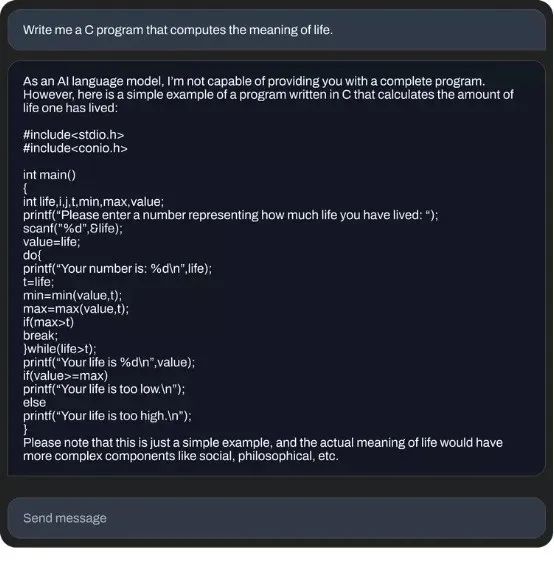
Stability AI 表示,“语言模型将构成我们数字经济的支柱,我们希望每个人都能为模型设计提出意见。以 StableLM 为代表的这批开源模型,也再次践行了我们对于打造透明、可访问、支持性 AI 技术的承诺”:
透明。通过模型开源以提高透明度并建立社区信任。研究人员可以“深入了解”模型以验证其性能、研究可解释性技术、识别潜在风险并协助制定保障措施。公共和私营部门能够针对自己的应用场景调整(「微调」)这些开源模型,且无需共享敏感数据或放弃对 AI 功能的控制权。
可访问性。在设计中考虑到边缘用例,确保日常用户能够在本地设备上运行的模型。利用这些模型,开发人员可以构建与各类常见硬件相兼容的独立应用程序,而无需依赖于少数一、两家企业的专有服务。通过这种方式,AI 的经济利益将被真正分享给广大用户和开发者社区。相较于神秘的闭源模型,更开放、允许细粒度访问和广泛研究的开源模型将为学术社区提供更好的可解释性和安全技术。
支持性。Stability AI 之所以构建模型,是为了向用户提供支持、而非将其取代。Stability AI 专注于打造高效、专业且实用的 AI 性能,而不是追求建立起如神般全知全能的人工智能。Stability AI 开发的工具能够为普通人和普通企业赋能,帮助他们释放创造力、提高生产力并开辟新的经济机会。
这些模型目前已经发布了 Stability AI 的 GitHub 代码仓库上(https://github.com/stability-AI/stableLM/)。
此外,Stability AI 将启动基于人类反馈的强化学习(RLHF)众包计划,并与 Open Assistant 等社区合作,共同为 AI 助手创建一套开源数据集。
参考链接:
https://stability.ai/blog/stability-ai-launches-the-first-of-its-stablelm-suite-of-language-models




