
数据是现代企业的生命线。
15 万美元,这是 2020 年湾区一位中等水平的数据工程师的年薪。类似地,国内 IT 行业为数据工程师开出的薪资也常常达到 30-50 万元的水平,百万以上比比皆是。这一岗位的热门程度可见一斑。
数据工程师薪资高涨的背后,是现代企业对大数据能力的极度重视。如今,没有任何企业的成功能离开海量数据的支持。数据是企业的宝库,而数据处理能力就是打开宝库大门的钥匙。以金融行业为例,无论是银行、保险公司还是证券公司,都需要依赖高质量数据来获取客户画像、评估投资风险和收益、发起精准营销。数据已经取代资本成为金融行业的第一决胜要素,堪称企业的“生命线”。
然而数据科学终归是一个年轻的行业,资源严重供不应求。企业难寻高水平的数据人才,有志踏上数据职业生涯的程序员也往往对自己的发展方向感到迷茫困惑。但稀缺意味着机遇,只要找到正确的学习方法与资源,程序员就能迅速提升自身的数据技能,进而在这片就业蓝海中抢占先机。同时,随着 Hadoop 开源技术的不断发展和成熟,传统数据仓库的局限性日益凸显,如何减轻 ETL 开发的工作量成为横亘在大数据工程师进阶之路上的思考难点。
为了解决以上痛点,2020 年 11 月 7 日,大数据及人工智能解决方案领导厂商索信达联合致力于帮助企业数字化的全球性软件及咨询公司 ThoughtWorks ,于北京举办了一场主题为“传统数据仓库的迭代升级之路”的技术分享沙龙,本场沙龙邀请了多位数据科学家、大数据行业资深专家,分享大数据相关热门话题与一线实践经验,内容覆盖数据仓库系统、从业人员技能进阶、行业实用实践案例等,助力数据科学从业者找到快速成长的秘诀。

图 / 活动现场
本文总结自三场分享课程,内容有调整。
数据技能进阶之路:打造“钉耙式”技能栈

讲师 / 索信达数据科学家 刘桂宾
对于刚刚踏足数据科学领域的开发人员来说,都希望尽快成长为独当一面的专业数据科学家 / 工程师。但面对五花八门的技术选项、业务需求和岗位职责时,即便是有一定经验的大数据开发人员也很容易迷失方向。
无论你主攻的方向是 ETL 还是 Hadoop,无论你熟悉的语言是 Java 还是 Python,感兴趣的是研发还是运维,需要关注的核心内容是不变的。总结起来,数据技能提升的关键在于“五大法宝”:业务能力、管理能力、技术技能、架构技能和沟通能力。这五大法宝仿佛神话中降妖除魔的“钉耙”一般,打磨好这些能力,数据科学的职业生涯自然就会一帆风顺。
要打造自身高水平的“钉耙式”技术栈,典型的方法是“向前看”和“向后看”。所谓“向前看”,就是根据自身的职业目标拟定发展路径,调研所需的各项能力,了解技术前沿发展趋势,并就自己的弱项进行学习强化,逐渐构筑通向目标的技能“天梯”。例如,去 IOE 是当下的行业趋势之一,那么传统 Oracle 数据库与 Gauss、teradata 之类的方案有何异同?新兴技术有哪些机制是自己不够了解,需要提升的部分?下一个工作项目需要提前做哪些准备?
而“向后看”则指的是根据以往的工作内容与实践经验做深度复盘总结,找出自身的问题和不足,探索可能的优化方向,再做针对性的查漏补缺。例如,作为 ETL 工程师,上一个参与的数仓项目都涉及哪些技术细节?源系统、ETL 服务器和目标系统都有哪些组成部分?操作步骤有哪些瓶颈和亮点?
无论是向前看还是向后看,都需要把握的一个核心思想就是“数据价值”。任何技能、方案的最终目的都是要充分挖掘数据中潜藏的价值。以金融领域客户画像为例,为了从海量信息中描绘出符合需求的画像,首先要知道运用哪些数据可以更好地了解客户的消费、借贷习惯?如何高效地收集、处理这些数据?使用哪些工具可以获得最佳的成本产出比?始终牢记,无论是技术积累还是软性能力,终归要服务业务需求,立足于企业的价值实现目标。
索信达根据这些原则,总结出了从业者构建知识框架和项目框架的 BIAS 架构体系:B,业务架构;I,信息架构;A,应用架构;S,系统架构。具体来说,就是根据业务需求设计业务模式,梳理筛选支撑业务的数据类型,结合大数据 / 数仓平台构建应用,并处理好底层系统组件之间的复杂关系。
“钉耙式”技术栈并非死板的教科书,而是根据实践灵活调整适应的方法论。这套体系中,不变的是对职业成长、项目目标、数据价值的追求,变化的是根据具体项目作出的技术选择、成本取舍、优先级设定等内容。优秀的数据科学人才会随着每一个项目、每一次培训甚至每一天的知识学习不断提升进步,为企业提供长久而稳定的价值输出,职业生涯的前景自然一片光明。
实战大数据:传统数仓的升级宝典

讲师 / 索信达大数据平台技术总监 安伟
企业数据仓库一直是企业数字化转型的核心驱动力。面临快速增长的数据量、数据分析需求和日益上涨的经济成本,传统数仓已经越来越力不从心。为了解决这一问题,实现数仓的迭代升级,与大数据技术融合成为了行业公认的解决方案。
目前除传统数仓(Oracle、SQL Server、MySQL 等)外,主流数据仓库产品还包括 MPP 数据仓库(Teradata、IBM DB2、GreenPlum 等)及 Hadoop 平台数据仓库。
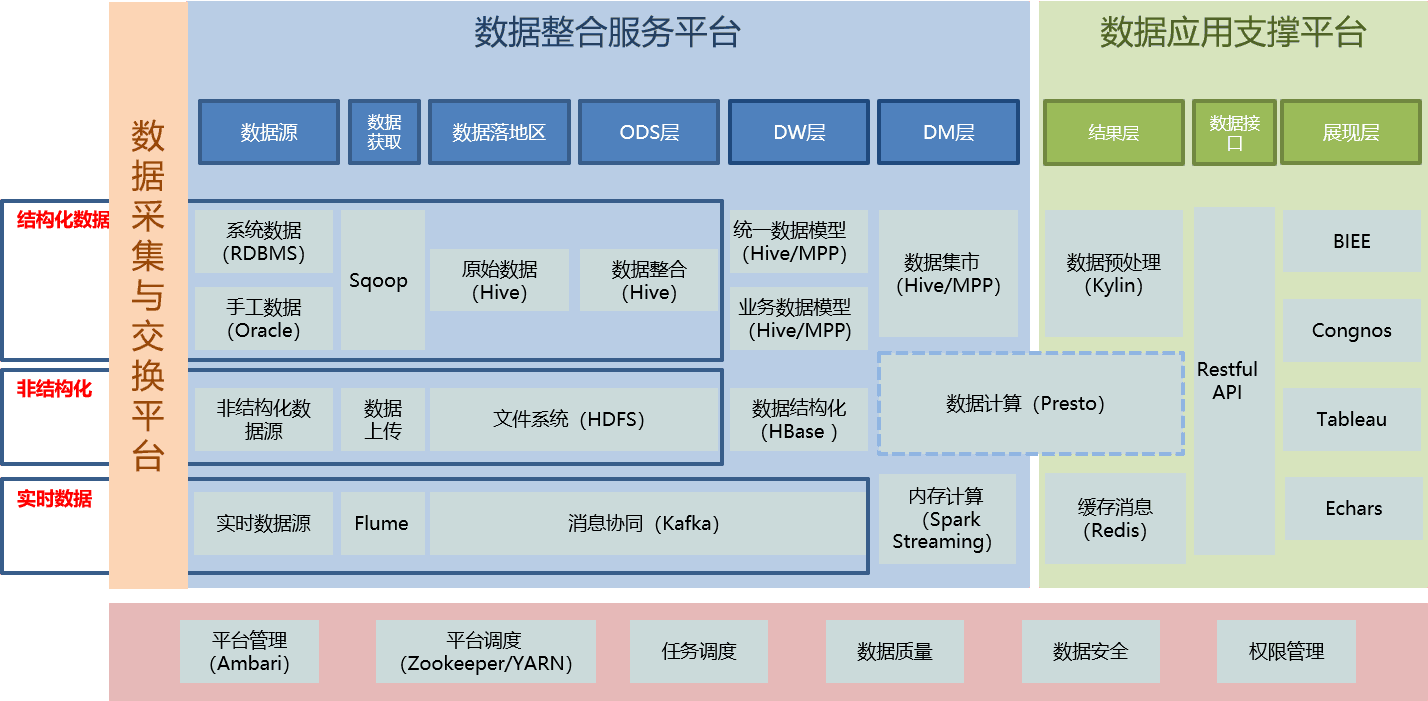
大数据平台技术架构
如上图所示,大数据平台架构主要包括数据整合服务平台和应用支撑平台两大部分,前者承担数据采集与交换职责。相比传统数仓,大数据平台具备结构化 / 非结构化数据混合分析能力,基于消费级通用硬件,以常态化硬件故障为设计出发点,并具备强大的扩展能力。面对海量数据分析需求,传统数仓需要针对具体场景选择最合适的技术手段,融合大数据架构解决已有瓶颈。
大数据底层存储技术的关键是 HDFS (Hadoop Distributed File System)集群,是一个部署在通用硬件,提供海量文件存储与读取的分布式文件系统,主要包括 NameNode 和 DataNode。为了提升吞吐量和稳健性,大型 HDFS 集群可采用联邦机制,并根据磁盘传输速率对应设置 HDFS 块大小(100MB/s 速率对应 128MB 块,以此类推)。
HDFS 文件块设置规则如下:

Hive 是流行的大数据 SQL 批处理引擎,负责将 SQL 作业转译成 MR 作业,在 Yarn 的资源调度下访问 HDFS 数据,对外则呈现为 SQL 数据库,其特性包括兼容性、可扩展性、支持多租户模式、统一访问。在设计 Hive 数据库时,重点关注的环节有分库、表设计、存储 / 压缩格式和计算引擎(默认为 mapreduce,另外较常用的还包括 Tez 和 Spark)的选项。其典型优化步骤包括减少处理数据量、合理设置 map/reduce 数、小文件合并、优化 Shuffle 过程和 Join、优化数据倾斜等。
在数仓建设过程中,为了解决跨部门数据协调、数据安全隐私、数据质量、信息孤岛等问题,就需要做好数据治理工作。所谓数据治理,就是结合组织、制度、流程和技术来处理数据,保证可用性、一致性、安全性等指标,从而提升数据质量到所需水平。在数据治理过程中,典型的途径是发现问题——提出应对策略——实施修正工作,打通数据的获取——管理——变现通道。实践中还应结合多种调研方式来评估数据治理效果,从而准确了解各领域状况并及时应变。
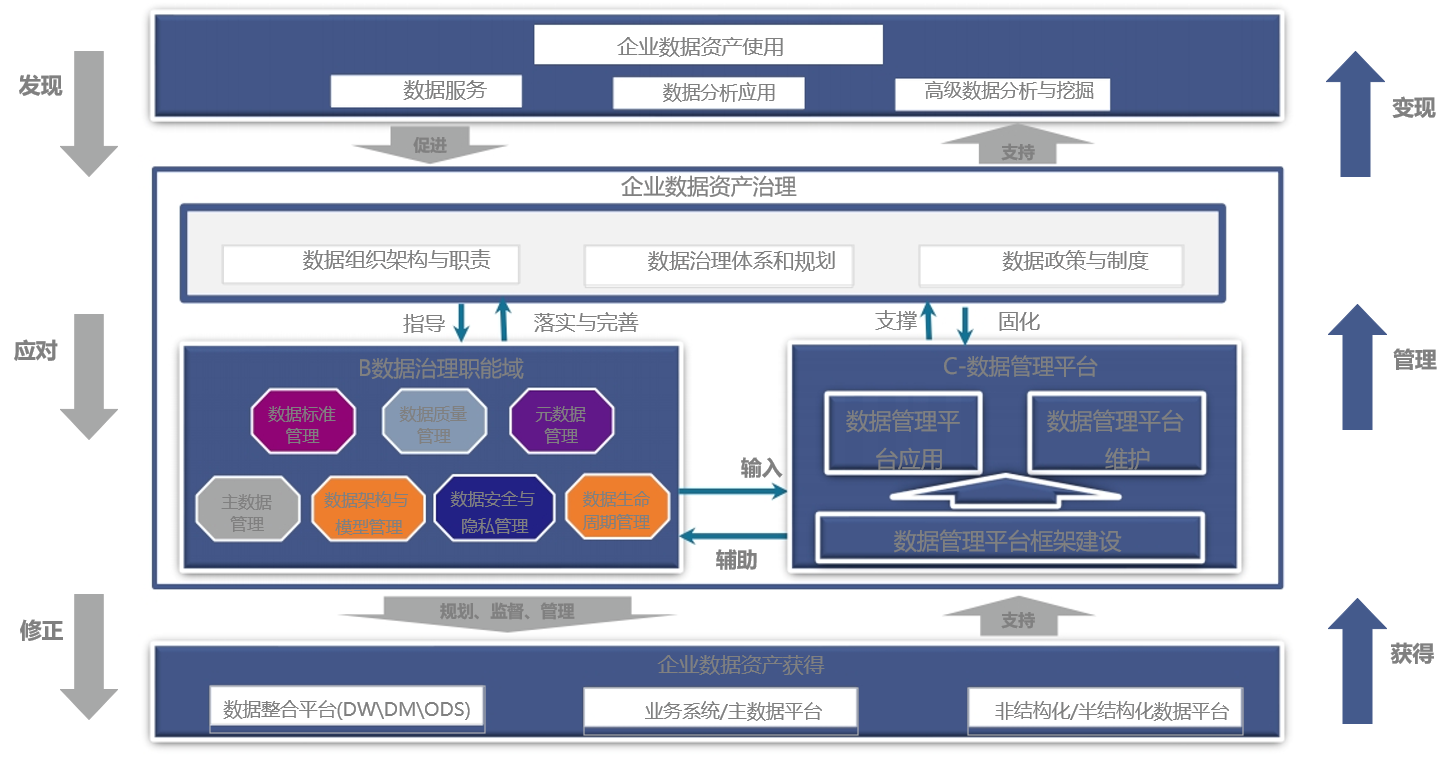
数据治理体系框架
大数据平台和数据治理是传统数仓升级路线上的两大关键词。与大数据平台的融合偏向于“硬”升级,主要涉及技术迭代优化,通过前沿技术解决已有的处理瓶颈;数据治理则侧重“软”提升,核心是利用新理念改进组织对数据的应对策略。通过软硬结合的优化路线,企业就可以在传统数仓的基础上发展出应对新兴挑战的能力,同时还能尽可能利用已有资产和资源,平稳完成数字化转型任务。
从设计到实现:搭建 ETL 框架的演进式架构

讲师 / ThoughWorks 高级咨询师 窦衍森
ETL(Extract-Transform-Load)是数据处理的一般逻辑。企业在搭建 ETL 架构时,架构的演进能力是需要重点考虑的要素。从开发到运维再到用户,ETL 架构所处的环境在持续变化,为了针对这样的环境设计出可以长期保持良好状态的架构,就要充分利用已有的资源做好平衡,支持频繁增量改进,将变化作为架构各维度的第一设计原则。
市面上常见的 ETL 框架选项有很多,具体选型时需要考虑项目的协作需求、技术需求和功能定位来做决策。ETL 框架应当具备良好的任务追踪能力、多数据源接入支持和通用逻辑处理能力,并能复用与业务 / 调度无关。针对 ETL 的常见实践需求,ETL 框架的主要评价指标还包括性能、幂等性、可撤销能力、可扩展性、可审计性等。
在设计 ETL 框架实现时,最佳路径往往是从小而简单的 MVP 实现开始,逐渐改进、扩展和增强,直至满足项目设计目标。
MVP 实现的第一步确定最小功能集和技术选型、技术架构。包括 ETL 框架依赖的表结构设计,整体的代码框架,并从任务追踪、多数据源接入和通用逻辑处理三大维度编写具体实现。第一版本的实现完成后,很容易发现这一版本存在很多痛点,如代码重复率高、Processor 过多、部分需求未实现、调度参数复杂等等。总结出具体的问题列表后就可以着手开始优化。但优化改进工作不宜一次性完成,而是分为多个版本,一步步逐渐解决问题。例如,第二版的优化重点可以放在简化处理逻辑和重构 Processor 上,第三版完善为实现的功能,第四版提升性能,等等。
基于配置的 ETL 框架设计是实践中很优秀的设计方式,其中框架不包含业务逻辑,后者依靠 Sql 实现或反射注册 Udf 来调用。每个 ETL 任务包含 n 个 Step 步骤,每个步骤分别执行读写两部分逻辑,所有数据源的读写接口是统一实现的。
一个典型的 ETL 作业流程如下:
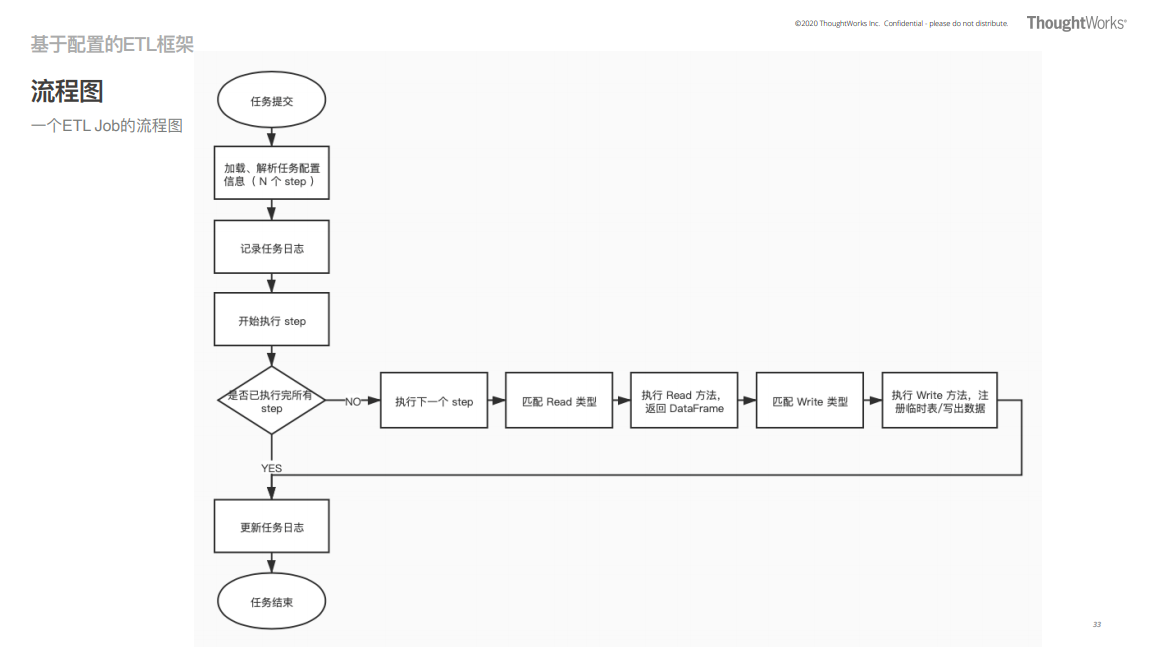
无论是 MVP 设计方式还是基于配置的设计方式,最终成果都可以归纳到 ETL 的目标函数(Fitness Function)上。目标函数包含 8 大维度:性能、可重用性、准确性、可审计性、敏捷性、模块化、运维和简洁性。但 ETL 框架并不可能同时在所有这些维度上都取得非常高的成绩,实际设计过程中必须根据成本、时间、人力等资源做好取舍。与此同时,演进式的 ETL 框架也不必永远遵循相同的设计目标,随着环境变化,ETL 框架的目标也可以随时改变,并在每次版本迭代中根据新的目标做出适应性调整。
持续演进,紧跟趋势:数据科学家的成功秘籍
数据科学行业的前景是毋庸置疑的,而无论是企业还是普通的开发人员,最关心的问题就是如何在这一前途光明的领域找到自己的最佳位置,发挥自身最大的价值并收获丰厚回报。
回顾分享沙龙,可以发现贯穿始终的一条线索就是“变化”。技术在变,资源在变,目标也在不断改变。在持续变化的环境中,数据科学从业者要把握好“变”与“不变”的平衡,持续学习新知识、掌握新技能,同时维持自身的软实力水平,快速适应每一次变化,迎接好每一个新的挑战。这种持续的应变能力,也是索信达多年来占据金融数据科学领域领导地位的秘诀,值得每一家企业和每一位数据科学家参考和学习。




