
近日,微软 DeepSpeed 研究组发布最新论文,提出一种名为 FastPersist 的新方法,旨在解决大模型训练时写检查点十分耗时的问题,相比 PyTorch 基线,写入速度提升超过 100 倍。

深度学习作为推动人工智能发展的关键技术,其模型检查点(checkpoint)的生成对于确保训练过程的稳定性和容错性至关重要。然而,随着模型规模的不断扩大,传统的检查点写入方法已经无法满足日益增长的 I/O 需求,成为制约深度学习发展的瓶颈。FastPersist 技术的提出,正是为了解决这一问题。
FastPersist 是微软 DeepSpeed 团队针对深度学习模型训练中检查点创建效率低下的问题提出的解决方案。据介绍,这项技术的核心在于通过三种创新的方法,即优化 NVMe SSDs 的使用、提高写入并行性,以及实现检查点操作与独立训练计算的重叠,显著提升了检查点的创建速度,降低了训练过程中的 I/O 开销。实验结果表明,FastPersist 能够在几乎不影响训练性能的前提下,实现高达 116 倍的检查点写入速度提升。这项技术的提出,不仅解决了大规模深度学习训练中的一个关键问题,也为未来深度学习模型的进一步发展提供了强有力的技术支持。
AI 前线进一步了解到, 在微软很多重要的大模型训练中,由于工作负载高度密集,经常出现 GPU error,所以需要很高频地写检查点操作,而这些大模型训练其实都在使用 FastPersist 这套系统。
论文链接:https://arxiv.org/pdf/2406.13768
现状和问题
深度学习作为人工智能领域的一个重要分支,近年来在图像识别、自然语言处理、推荐系统等多个领域取得了突破性进展。随着研究的深入,深度学习模型的规模也在不断扩大,从早期的百万级参数模型发展到现在的百亿甚至千亿级参数的超大型模型。模型规模的增长带来了更强的表征能力和更高的准确率,但同时也带来了计算复杂度的提升和存储需求的增加。特别是模型参数、梯度信息以及中间特征图等数据的存储,对存储系统的 I/O 性能提出了更高的要求。
尽管计算性能的提升可以通过硬件加速和算法优化来实现,但 I/O 性能的提升却受到了传统存储设备和系统的限制。特别是在模型训练过程中,检查点的生成是一个不可或缺的步骤,用于保存模型在特定迭代步骤的状态,以便在发生故障时能够从最近的检查点恢复训练,从而避免重复计算。然而,检查点的生成和保存是一个资源密集型的操作,涉及到大量的数据写入。在大规模训练中,模型参数和中间数据的体积巨大,检查点的生成和保存需要消耗大量的 I/O 带宽和时间,这不仅增加了训练的总体时间,也可能导致 I/O 系统的饱和,影响其他训练操作的执行。因此,提高检查点创建的效率,成为提升深度学习模型训练性能的关键。
当前深度学习框架中的检查点生成机制,大多数基于传统的文件 I/O 操作,这些操作并没有充分利用现代存储设备,如 NVMe SSDs 的高性能特性。这导致了在大规模训练场景下,检查点写入成为制约整体性能的瓶颈。此外,由于检查点写入操作与模型训练的其他计算任务之间存在数据依赖性,传统的检查点生成方法无法实现与训练过程的完全解耦,进一步限制了检查点生成的效率。
为了解决 I/O 瓶颈问题,研究者和工程师们提出了多种解决方案,如使用更快的存储介质、优化文件系统、改进数据写入策略等。但是,这些解决方案往往存在一定的局限性。例如,简单地更换更快的存储介质虽然可以提高 I/O 性能,但成本较高,且在大规模并发写入时仍可能遇到瓶颈。优化文件系统和数据写入策略可以在一定程度上提高效率,但往往需要对现有的深度学习框架和训练流程进行较大的改动,兼容性和通用性有待提高。
针对上述问题,微软 DeepSpeed 团队提出了 FastPersist 技术。
FastPersist 技术方案
FastPersist 通过深入分析深度学习训练过程中的 I/O 需求和特点,结合现代存储设备的特性,提出了一种全新的检查点生成和保存方法。主要通过以下三个方面来提升检查点创建的效率:
1. NVMe 存储设备的优化利用
FastPersist 针对 NVMe SSDs 的高性能特性进行了优化。通过使用专为 NVMe 设计的 I/O 库,如 libaio 和 io_uring,FastPersist 能够更高效地管理数据在 GPU 和 SSD 之间的传输,从而显著提高了单节点上的检查点写入速度。
FastPersist 还采用了双缓冲技术来进一步提高写入效率。在双缓冲机制中,当一个缓冲区的数据正在写入 SSD 时,另一个缓冲区可以同时从 GPU 内存中预取数据,这样就能实现数据写入和数据预取的流水线操作,减少了等待时间,提高了整体的写入性能。
另外, FastPersist 针对 NVMe SSDs 的特性,对数据块的大小和对齐进行了优化。通过调整数据块的大小,使其匹配 SSD 的页面大小,可以减少写入操作的数量,提高写入效率。同时,通过对齐数据块到合适的边界,可以避免额外的拷贝操作,进一步提高性能。
2. 写入并行性的实现
在深度学习模型训练中,特别是在大规模分布式训练环境中,数据并行(Data Parallelism)是一种常见的训练策略。在数据并行训练中,模型被复制到多个训练节点上,每个节点处理不同的数据子集。这种训练方式可以显著提高计算资源的利用率,加快模型的训练速度。然而,如果检查点的写入操作仍然集中在单个节点上执行,那么 I/O 操作就可能成为限制整体性能的瓶颈。
FastPersist 技术通过实现检查点写入的并行性,解决了这一问题。在 FastPersist 中,检查点的写入操作被分布到所有参与训练的节点上,每个节点只负责写入其对应的模型部分。这样,写入操作就可以同时在多个节点上执行,从而显著提高了整体的写入速度。
为了实现高效的写入并行性,FastPersist 采用了以下几个关键策略:
数据分片:FastPersist 将检查点数据均匀地分割成多个片段,每个训练节点只负责写入其分配到的数据片段。这种分片策略确保了写入负载在所有节点上的均衡分配。
无通信写入:在 FastPersist 中,每个节点独立地完成其检查点数据片段的写入,无需与其他节点进行通信或协调。这种设计减少了节点间通信的开销,提高了写入操作的效率。
动态负载平衡:FastPersist 能够根据节点的计算能力和存储性能动态调整数据片段的大小,确保所有节点的写入负载保持均衡。这种动态调整机制可以适应不同的硬件环境和训练配置。
容错和恢复:在分布式训练环境中,节点的故障是不可避免的。FastPersist 通过在写入操作中实现容错机制,确保即使部分节点发生故障,也不会影响检查点的完整性和训练的连续性。
3. 操作重叠的策略
在深度学习模型训练中,检查点的生成通常需要在每个训练迭代后执行,以确保模型状态的持久化。然而,如果每次迭代后都进行完整的检查点写入操作,那么这些操作可能会占用大量的计算资源,影响模型训练的速度。为了解决这一问题,FastPersist 采用了操作重叠的策略,将检查点的写入操作与模型训练的其他计算任务并行执行。
操作重叠的核心思想是利用深度学习训练中的计算特性,将检查点写入操作与模型的前向传播和后向传播操作重叠。由于前向传播和后向传播操作通常占据了模型训练的大部分时间,通过将检查点写入操作与这些操作并行化,可以有效地隐藏 I/O 操作的延迟,提高整体的训练效率。
FastPersist 实现操作重叠的具体策略包括:
异步写入:FastPersist 采用异步写入机制,使得检查点的写入操作不会阻塞计算操作的执行。在每个训练迭代的优化器步骤之后,FastPersist 会启动检查点的异步写入过程,而计算线程可以继续执行下一个迭代的前向传播和后向传播。
双线程模型:FastPersist 引入了一个辅助线程专门负责检查点的写入操作。主线程负责执行模型的计算任务,而辅助线程在主线程的协调下执行检查点的写入。这种双线程模型确保了计算和 I/O 操作的并行执行,减少了相互之间的干扰。
数据局部性优化:FastPersist 通过优化数据的存储和访问模式,提高了数据在 GPU 和 CPU 之间的传输效率。通过利用数据的局部性原理,FastPersist 减少了不必要的数据移动,降低了 I/O 操作的延迟。
依赖性管理:在操作重叠的过程中,FastPersist 通过精确管理计算任务和检查点写入操作之间的数据依赖性,确保了检查点的一致性和完整性。即使在发生故障的情况下,FastPersist 也能够保证从最近的检查点正确恢复。
通过精心设计的操作调度策略,FastPersist 实现了检查点写入操作与模型训练的其他计算任务的重叠执行,从而在不增加额外计算负担的情况下,规避检查点的写入延迟。
效果评估
研究团队对 FastPersist 的性能表现进行多场景、多维度的评估。为了验证 NVMe 优化和并行优化在减少检查点延迟方面的有效性,团队使用单 GPU 和多节点环境的微基准测试,对检查点写入的吞吐量做了测试;并使用真实世界的密集和稀疏深度学习模型,评估了新方法相比基线(baseline)对训练性能的加速效果。
在微基准测试中,FastPersist 在单 GPU 和多节点环境下,相比于基线的 torch.save()方法,检查点写入速度显著提升。
在真实世界的深度学习模型训练测试中,FastPersist 在不同的模型规模和数据并行度下,均能够实现高速的检查点创建,且引入的开销极小。下图显示,在 128 个 V100 GPU 上,FastPersist 实现的加速比从 gpt3-13B 的 28 倍到 gpt3-0.7B 的 116 倍不等。这些改进证明了 FastPersist 技术方案在 NVMe 优化和并行优化方面的有效性。
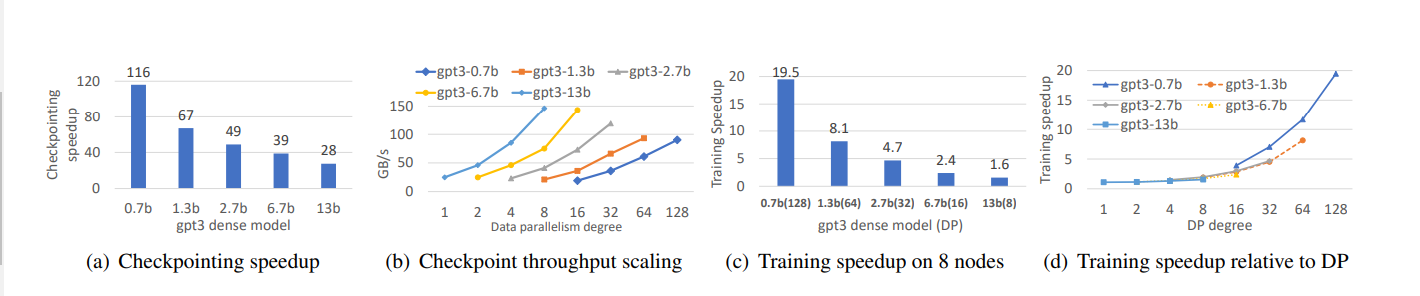
图:FastPersist 应用于 GPT-3 密集模型训练的效果
FastPersist 在大规模训练场景下的性能尤为重要。实验结果表明,即使在数千个 GPU 上进行训练,FastPersist 也能够保持检查点创建的低开销,并且随着数据并行度的增加,FastPersist 的效率提升更加明显。
鉴于 GPU 硬件的限制,研究团队通过预测高达 128 的数据并行度(即 6.7B 模型使用 1024 个 GPU,13B 模型使用 2048 个 GPU)来模拟像 GPT-3 6.7B 和 13B 这样的大型密集模型的性能表现。下图显示了 FastPersist 相对于基线的预计训练加速比,其中蓝色/橙色条代表 6.7B/13B 模型。当扩展到数千个 GPU 时,FastPersist 的检查点开销基本保持一致(小于 2%的训练计算时间),而基线的检查点开销则与数据并行度成比例增长。对于 6.7B 和 13B 模型,FastPersist 分别实现了高达 10.2 倍和 3.6 倍的训练加速。
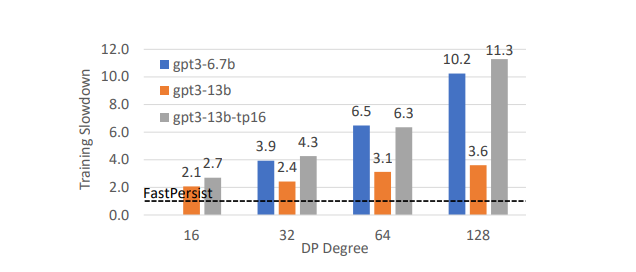
图:数据并行度≤128 的训练加速效果预测
另外如上图中灰色条所示,如果放弃流水线并行(PP),并在一个数据并行组中完全采用 16 个 GPU 的张量并行(TP)设置,与标准 TP 和 PP 结合的模型分割(即图中的橙色条)相比,FastPersist 可以做到更高的基线加速比,实现高达 11.3 倍的训练加速。




