
背景
Uber 致力于为全球客户提供可靠的服务。要达到这个目标,我们很大程度上依靠机器学习来作出明智的决定,如预测和增益。所以,用来产生机器学习数据和特征的实时流管道已经越来越受到重视。
Uber 公司使用了 Apache Flink 来建立实时流管道,并建立像 Gairos 和 AthenaX 这样的平台来简化开发过程。但是,由于计算的复杂性或需要处理的实时数据量,仍有很多挑战,如扩展性。
本文中,我们将以生产需求和供应特征为例,介绍我们所面临的一些挑战以及如何应对这些挑战。尤其要说明的是,如何使用性能调整框架来优化实时管道。
架构
下图显示了 Apache Flink 中的流管道负责特征计算和提取的架构。我们将在下文详细讨论这些管道。
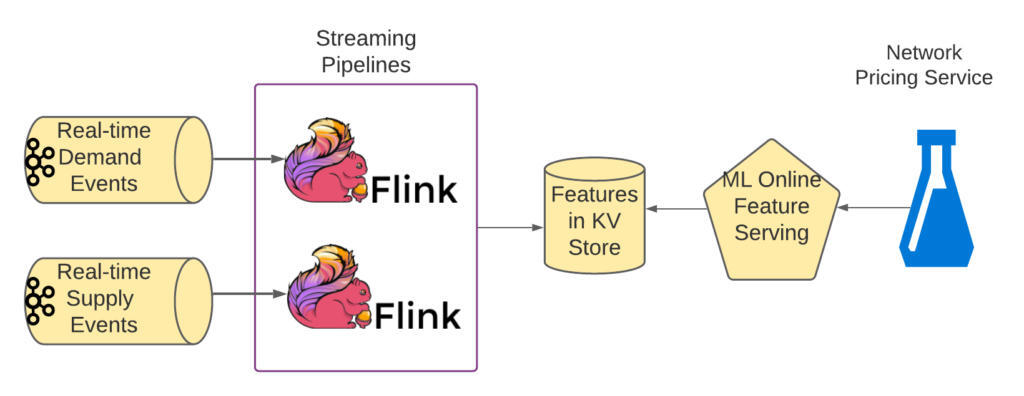
图 1:简化的架构概述
特征计算
本节详细介绍了如何通过地理空间和时间维度以及全局产品(UberX 等)对任何给定的六边形(参见此处)的原始事件,例如需求和供应事件进行聚合。以下是简化的计算算法:
在一分钟窗口内,按六边形和全局产品类型计算出不同乘客和司机所发生的原始事件数量。在一分钟窗口内,将 Kring Smooth 应用多个环,最多 20 个环(稍后进行讨论)。将每一环的平滑值聚合在多个滑动窗口大小上,最长可达 32 分钟。
总的来说,一条实时管道每分钟为一个六边形生成 54 个特征,使用 9 个环(0,1,2,3,4,5,10,15,20)和 6 个窗口大小(1,2,4,8,16,32)的组合。
接下来,我们讨论算法的第二步。
Kring Smooth
Kring Smooth 过程通过向其 Kring 邻居广播一个六边形的事件计数来计算地理空间聚合。换句话说,某一特定环的六边形的特征值考虑到了该环内所有六边形的事件计数。
为了计算给定六边形 h 在环 r 上聚合的特征值,公式为:
$ f(H, R)=\frac{\sum_{i=0}^{R} \sum_{j=1}^{N u m(i)} f\left(N_{i}^{j}, 0\right)}{\sum_{i=0}^{R} Num(i)} $
其中, $ Num(i) $ 是环 $ i $ 的六边形数量;$ N_{i}^{j} $ 是环 $ i $ 的第 $ j $ 个六边形; $ f(H,0) $ 是来自六边形 $ H $ 的事件数。
因此,让我们看看下面的例子,看看如何计算这三个特征的值:六边形 A 的第 0 环、第 1 环和第 2 环,公式如下:
$ Num(0) = 1 $
$ Num(1) = 6 $
$ Num(2) = 12 $
$ f(A, 0) = 1 $
$ f(A, 1) = (f(A, 0) + f(B1, 0) + f(B2, 0)) / (Num(0) + Num(1)) = (1 + 2 + 1) / 7 = 4 / 7 $
$ f(A, 2) = (f(A, 0) + f(B1, 0) + f(B2, 0) + f(C1, 0) + f(C2, 0) + f(C3, 0)) / (Num(0) + Num(1) + Num(2)) = (1 + 2 + 1 + 3 + 2 + 1) / (1 + 6 + 12) = 10 / 19 $
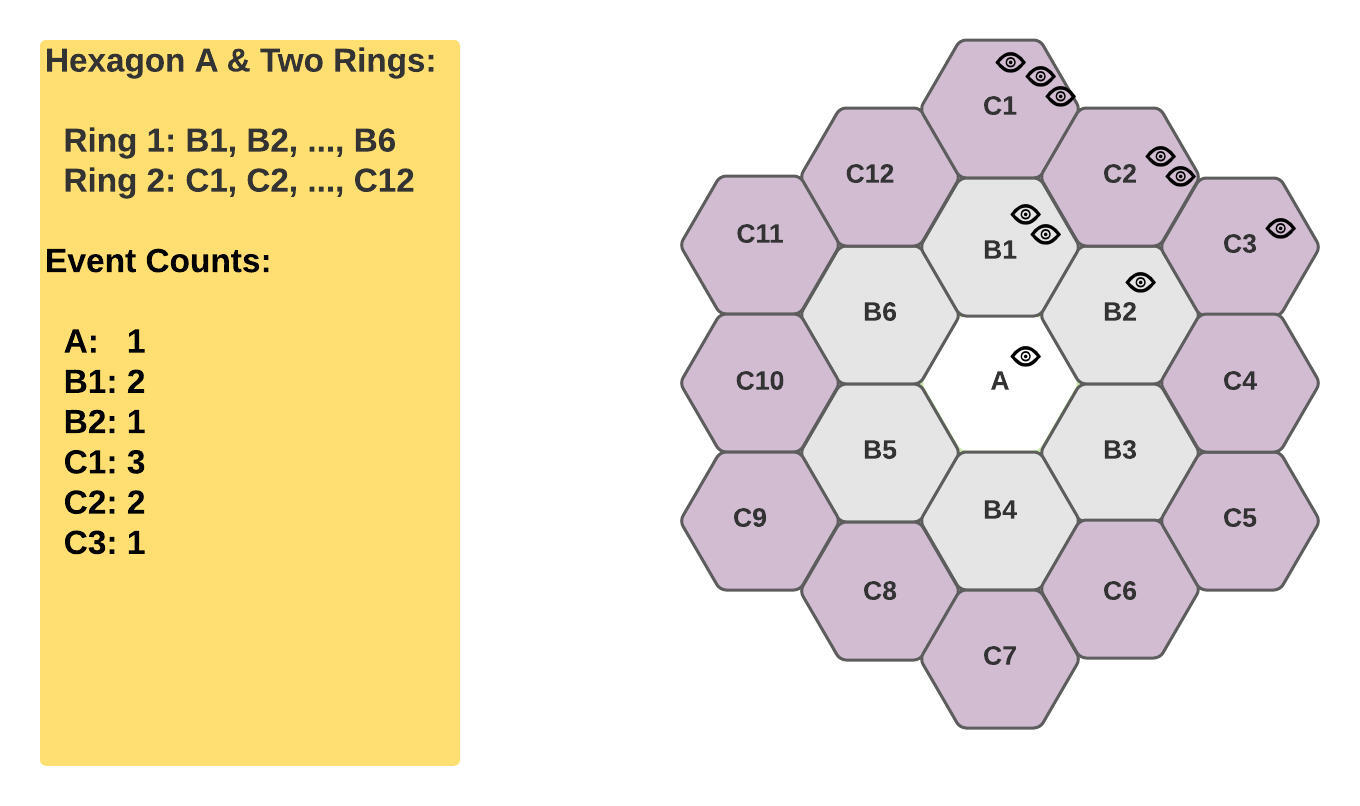
图 2:六边形 A 的第 0 环、第 1 环、第 2 环
该管道按照方程式计算出多个环形尺寸的特征值,最多可达 20。
时间聚合
在一分钟窗口的 Kring Smooth 完成后,算法的第 3 步是将平滑的事件计数在更大的窗口上聚合,最长可达 32 分钟。要计算给定的六边形 H 在更大窗口上的聚集,公式如下:
$ q(H, T, W)=\frac{\sum_{i=0}^{W-1} q(H, T+i, 1)}{W} $
其中,$ T $ 是一个窗口的起始时间戳;$ W $ 是窗口的大小,以分钟为单位;$ q(H,T,1) $ 是来自 Kring Smooth 的平滑事件计数。
下图 3 展示了如何计算 2 分钟窗口的六边形 A 的特征值:
$ W1 $ 和 数学公式: $ W2 $ 窗口的 Kring Smooth 的平滑事件计数分别为 1.0 和 3.0,分别在$ T0+1 $ 分钟和$ T0+2 $ 分钟发出;
2 分钟窗口的特征值为 2.0,通过使用平滑的事件计数,按照上述方程计算,其时间范围为 ($ T0 $, $ T0 + 2 $ 分钟)。
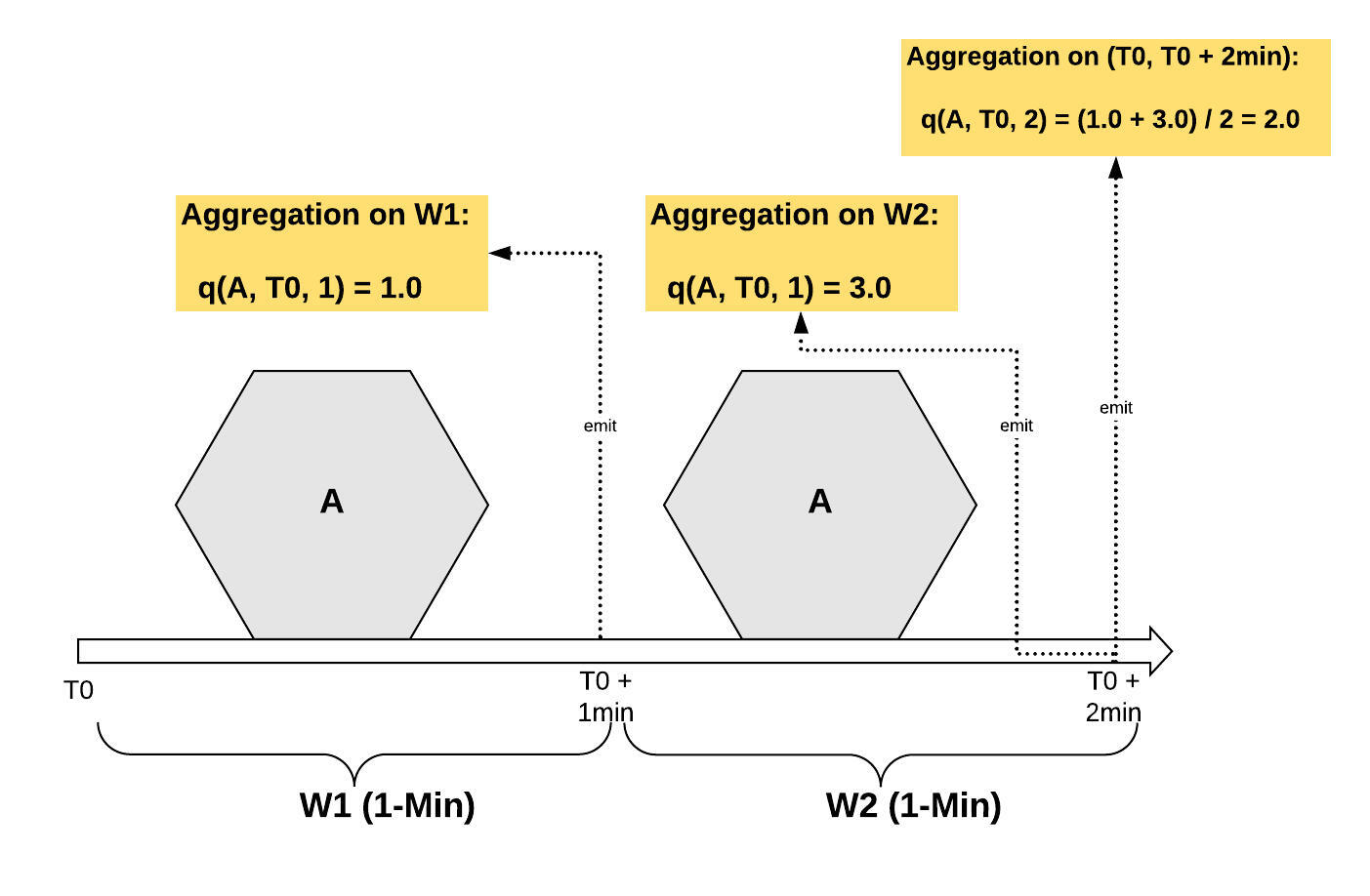
图 3:六边形 A 的 2 分钟窗口的聚合
流实现与优化
本节以需求管道为例,说明如何在 Apache Kafka 和 Apache Flink 中实现特征计算算法,以及如何调整实时管道。
逻辑作业拓扑
下图 4 说明了计算需求特征的流管道的逻辑 DAG。对于所有尺寸大于 1 分钟的窗口来说,它们是滑动窗口,这些窗口将以 1 分钟为单位滑动,这意味着一个输入事件可能包含在 63 个窗口内:32 + 16 + 8 + 4 + 2 + 1。
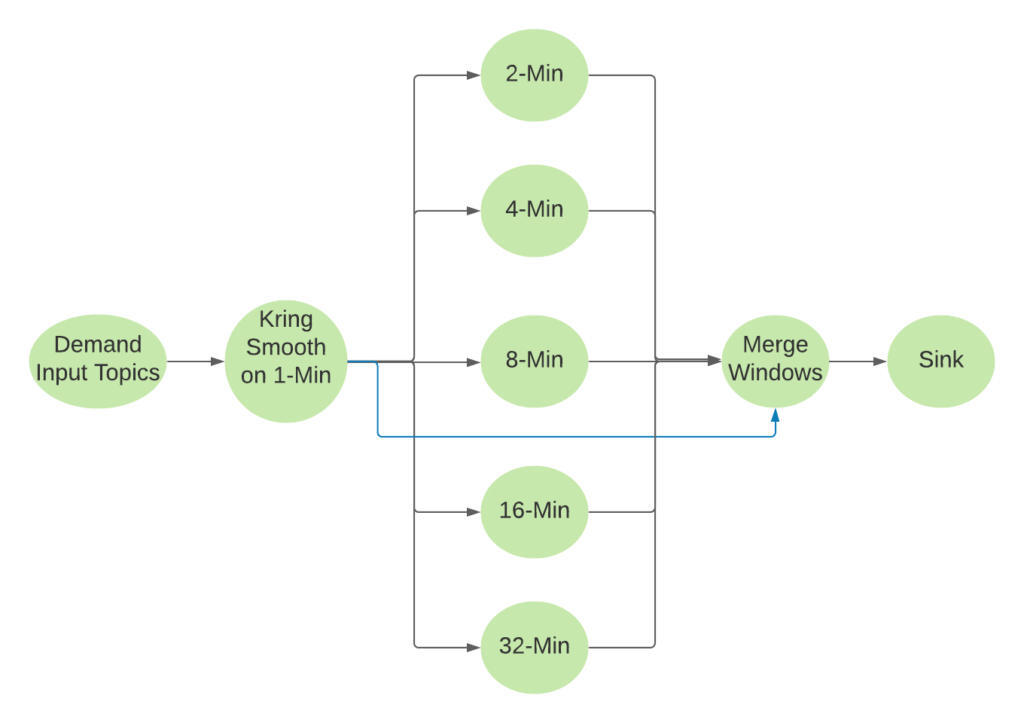
图 4:需求管道的逻辑 DAG
下表列出了逻辑 DAG 中主要运算符的功能:

表 1:需求管道的逻辑运算符
流管道的数据量
本节列出了需求管道的数据量:
Kafka 主题的平均输入速率:120k/s
六角形的计数:5M
城市的数量:1500
每个城市的六边形平均数和最大数:4000 和 76000
1 分钟内六边形需求事件的平均计数:45
环 20 的六边形计数:1261
显然,该管道具有高容量、密集的计算和大的状态需要管理。第一版实际上是按照逻辑 DAG 构建的,由于包括背压和 OOM 等问题,无法稳定运行(如下图仪表板所示)。由于我们的目标是接近实时的延迟(小于 5 分钟), 因此我们面临的真正挑战是如何建立稳定的工作通道。
内存监视器:
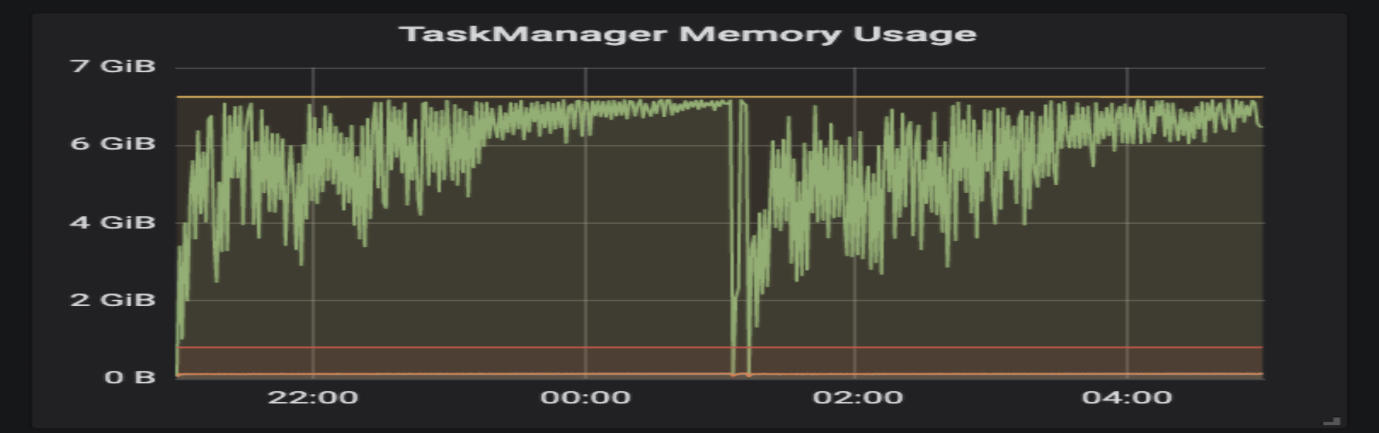
图 5:已用内存的仪表板
延迟监视器:
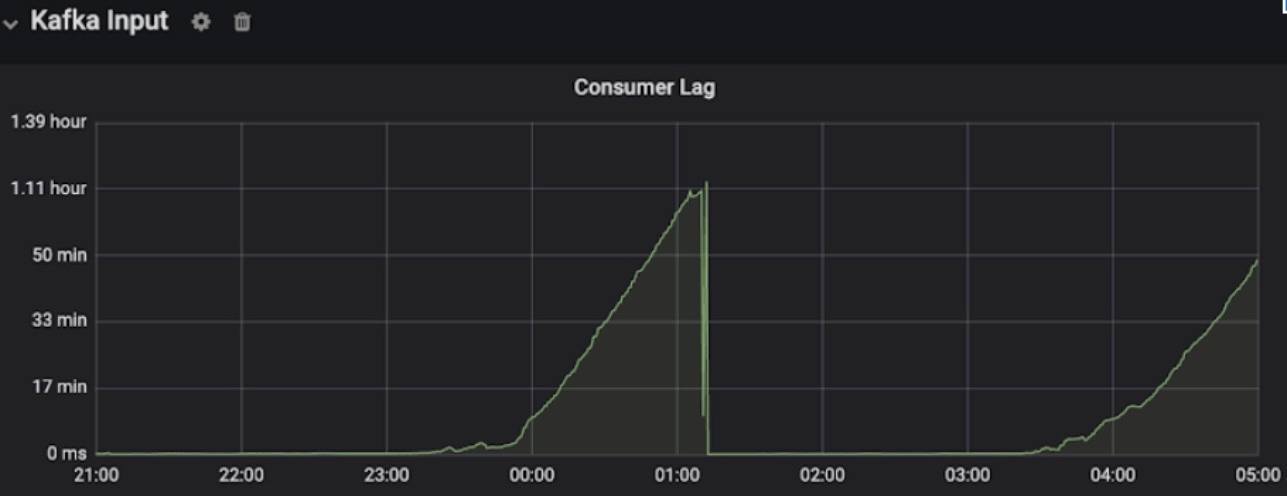
图 6:延迟的仪表板
如何优化
本节讨论如何调整流管道。Uber 已开发出一种流程管道性能调优框架,并提供端到端集成测试框架。在启动实际调整之前,Uber 就已经开发了专门的集成测试,使我们能够重构或优化流管道,并确信管道仍将产生正确的结果,类似于单元测试,保护我们免受回归。在整个优化过程中,这些集成测试变得非常有价值。
下面,我们将介绍性能调优框架。
性能调优框架
从下面的内三角可以看出,我们的框架集中在三个领域。通过 Uber uMonitor 系统提供的度量标准对网络、 CPU 和内存进行测量和监控。外五边形的顶点表示可以探索主要优化领域。
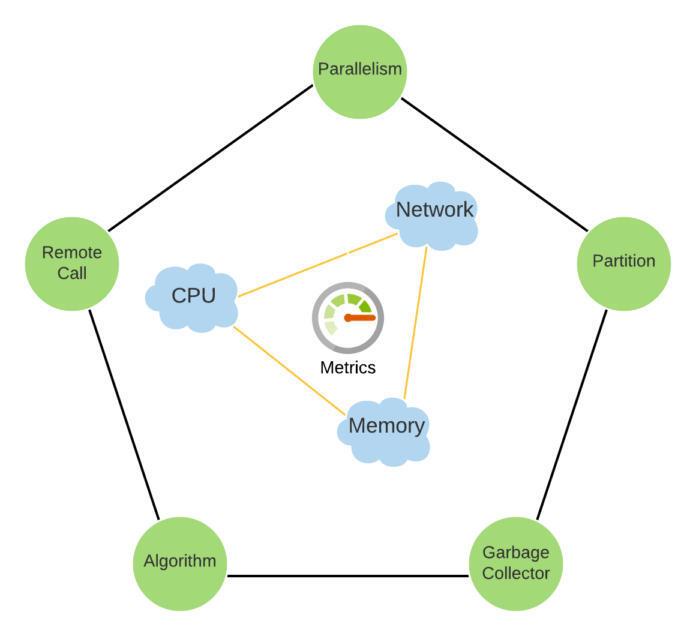
图 7:性能调优框架
下表简要解释了每个领域的技术和潜在影响:
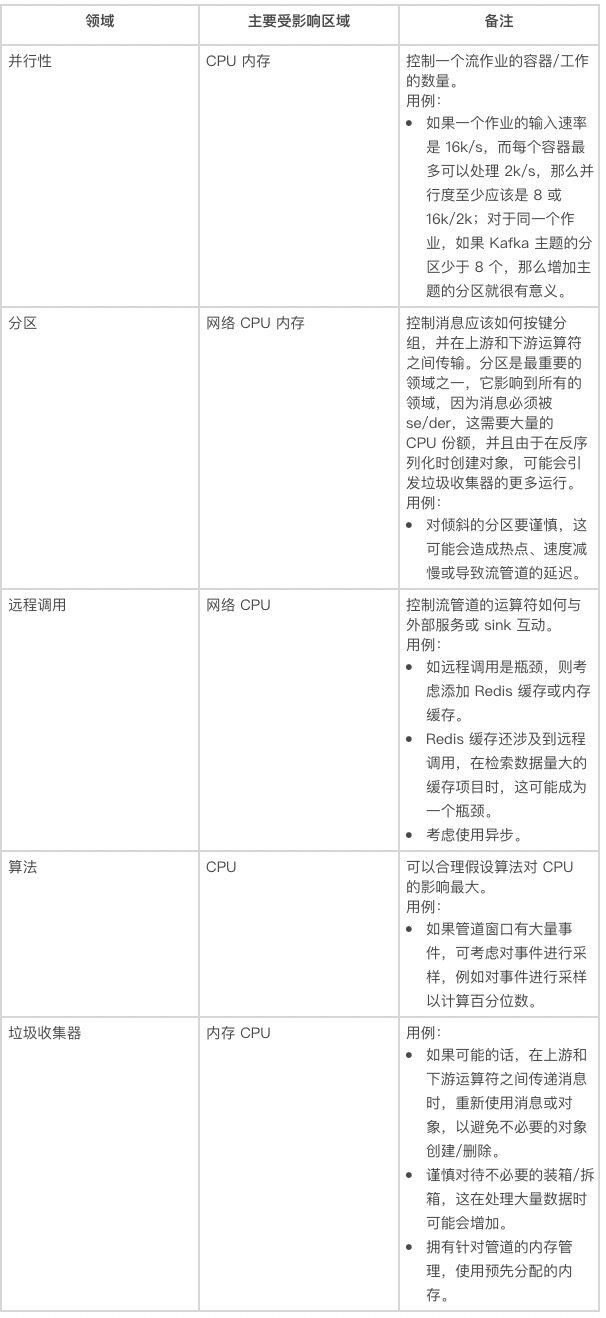
表 2:性能调优的领域
接下来,我们讨论如何优化管道。
优化
我们对流管道进行了许多优化,一些优化技术对上述多个领域都有影响。其中一项特别的技术:自定义滑动窗口,对所有三个领域都有重大影响,所以我们有一个专门的章节来讨论它,还有一个章节讨论存储。
网络优化
主要的优化技术列于下表:
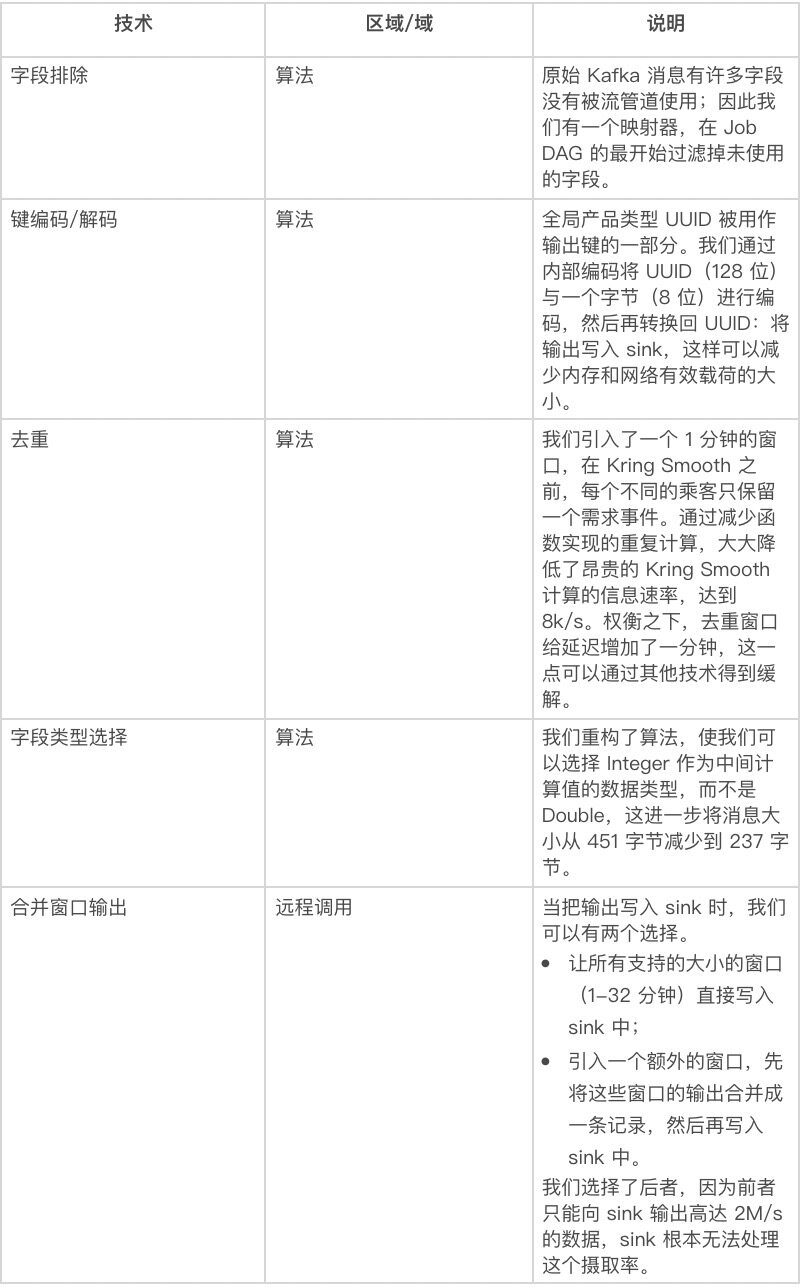
表 3:网络优化技术
正如上文所详述的,关键的改进是既提供较少的信息,也提供较小的信息。
内存优化
下表列出了内存技术:
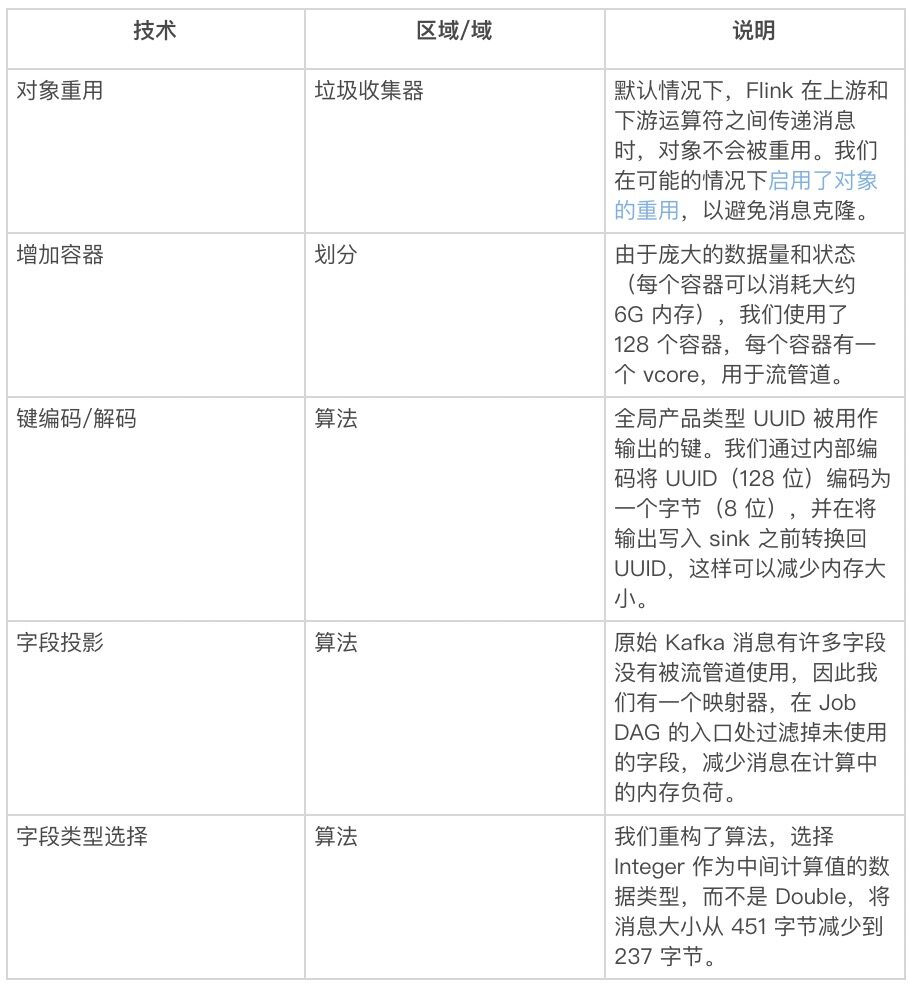
表 4:内存优化技术
注:还包括一些用于网络优化的技术。
CPU 优化
应用于 CPU 优化的技术如下:
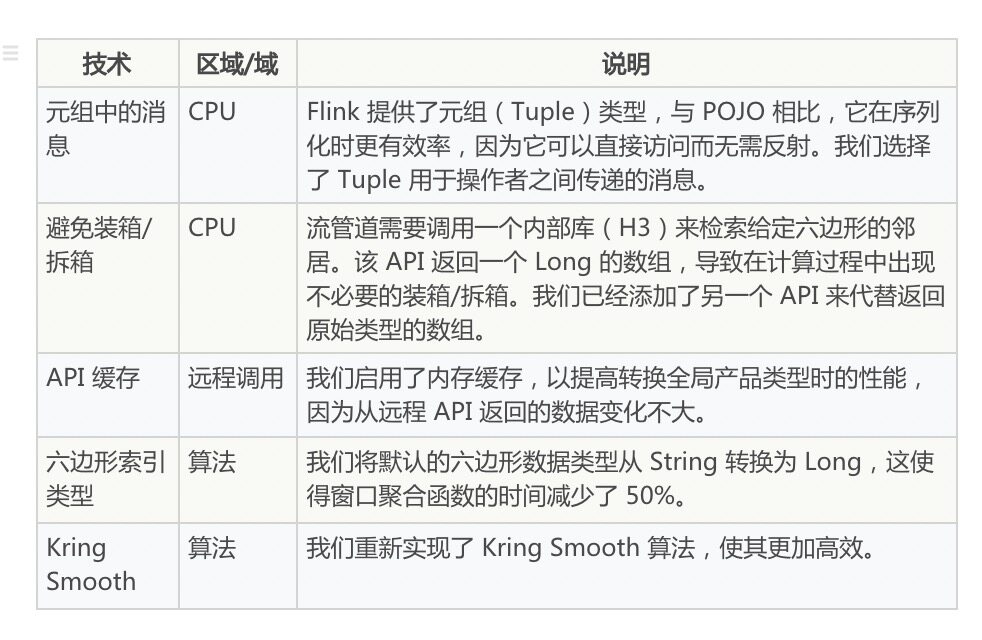
自定义滑动窗口
仅通过上面的调整,管道仍无法顺利运行,因为它需要数个滑动窗口 (2、4、8、16、32)进行聚合。由于需要按一个键划分事件,窗口聚合的开销如下:
从上游向窗口运算符传递消息时的 De/Ser;
通过网络传输消息;
反序列化时正在创建的对象;
窗口管理所需的状态管理和元数据,如窗口触发器。
这样的开销会对垃圾收集器、CPU 和网络造成巨大压力。更有甚者,滑动窗口比翻滚或固定尺寸的窗口需要更多的状态,因为一个事件需要保存在一系列滑动窗口中。就拿一个 4 分钟的滑动窗口来说:给定一个事件发生在 2021-01-01 T1:15:01 Z,此事件保存在下面的 4 分钟窗口中:
2021-01-01T01:12:00Z ~ 2021-01-01T01:16:00Z
2021-01-01T01:13:00Z ~ 2021-01-01T01:17:00Z
2021-01-01T01:14:00Z ~ 2021-01-01T01:18:00Z
2021-01-01T01:15:00Z ~ 2021-01-01T01:19:00Z
因为滑动窗口的扇出效应,给管道的状态管理带来很大的压力。针对这些问题,我们采用 FlatMap 运算符手工实现了滑动窗口逻辑,其特点如下:
如果允许重用对象,则向上游运算符传递并重用事件,从而避免分区和相关开销。
该状态在内存中被管理,因此每个事件实际上只能复制一份数据。
对于在内存中保存状态所需的最大内存,我们估计如下:
Total Memory = Count(Hexagon) Count(Product) Max(window size) * sizeof(event) = 3M 6 32 * 237b = 136G对于 128 的并行性,每个容器的内存约为 1G,这是可管理的。在生产中,实际的内存远远低于最大值,因为不是所有的六边形都有时间范围的事件。
这个自定义滑动窗口的效率非常显著,所以我们已经成功地将这个运算符重新用于超过 5 个不同的用例,这些用例需要在多个大型滑动窗口上进行聚合。
优化后的最终作业 DAG

图 8:需求管道的最终 DAG
通过对其进行优化,最终得到了一个更简单的作业 DAG,其中自定义滑动窗口代替了较大的窗口运算符。
如下面的 24 小时仪表板所示,管道始终可靠地运行:
延迟监视器:
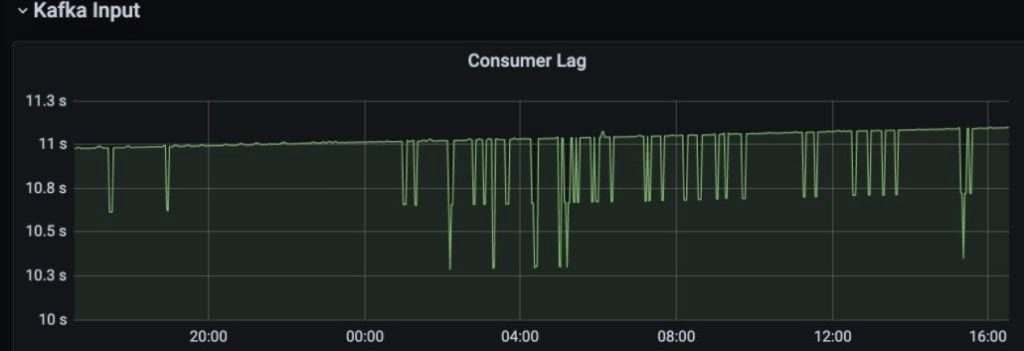
图 9:优化后显示延迟的仪表板
容器内存监视器:
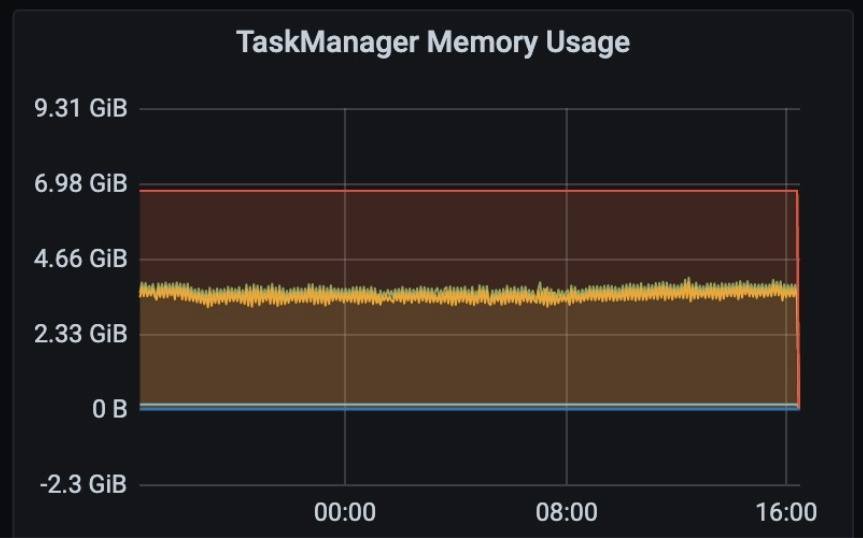
图 10:优化后显示内存使用情况的仪表板
存储
为简化管道维护和重新使用 sink,我们对管道 DAG 进行了进一步重构,在 Flink 中将 sink 运算符分离为专门的发布器作业,并将计算和发布器作业与 Kafka 连接起来。此部分主要关注此发布器作业的细节:
而在服务模型中,它会根据地理、时间和产品的要求查询供应信息。我们选择了 Docstore (Uber 的内部 KV 商店解决方案)作为存储。
我们从一个 docstore 集群开始,它由许多用例共享。
下面是每个 API 调用插入一行的结果。写入的 QPS 在 13000 左右达到峰值,但大多数时候都是几百的数量级。
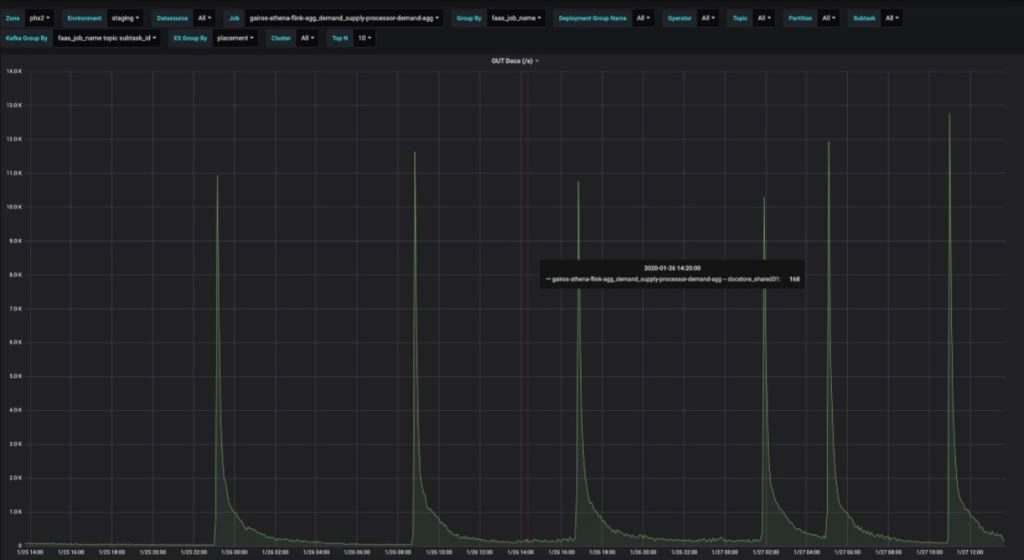
图 11:如果每个 API 调用只有一行,那么编写 QPS 就不稳定
批处理
我们尝试对这些行进行批处理写入,看看能否增加吞吐量。为使批处理更高效,我们基于 Docstore 中的分片号来划分数据。但是,应用批处理后,写入的 QPS 较低。经过深入的研究,我们发现这是因为流作业中所发出的一种度量的一个维度基数过大。我们将这一维改为常数字符串,而非随机的 UUID。写入的 QPS 可以达到 16000 左右。
在写到 Docstore 之前,我们先把数据写到 Kafka 主题。在禁用 Kafka sink 后,我们可以看到写入 QPS 增加了 10% 左右。
在我们把每个分片的批处理量改为 50 后,写的 QPS 增加了一倍,达到 34000。我们还尝试了批处理规模为 100 和 200。对于批处理大小为 100,写 QPS 增加到 37000(大约增加 20%)。
将批处理大小改为 200 后,没有发现有太大的差别。
在下表中,我们列出了不同配置下的 QPS:
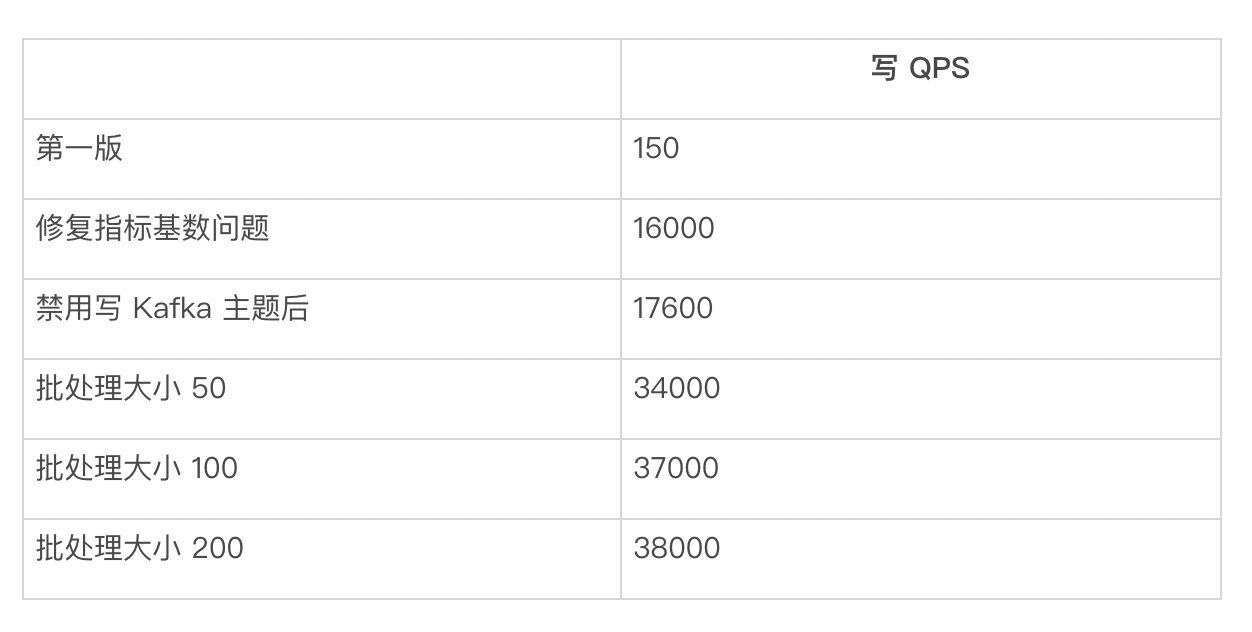
表 6:不同批处理大小下的吞吐量
并行性
Flink 作业的并行性是我们为提高 QPS 而调整的另一个参数。
在将发布器作业的并行性更新为 256 后,写入的 QPS 约为 75000,增加了一倍多。批处理小为 200,在并行度为 1024 时,我们看到 QPS 达到 112000。但是,我们发现存在大量的超时错误。将批处理改为 50 后,写 QPS 约为 120000。

表 7:不同作业并行性下的吞吐量
线程池
对于每个 Flink 作业,我们也尝试使用线程池来提高写 QPS,结果如下:
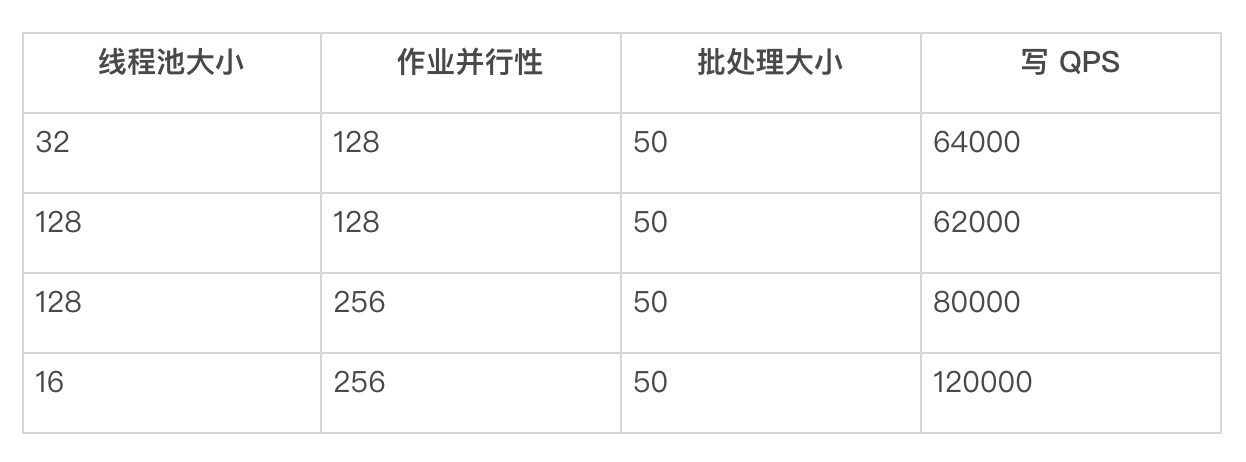
表 8:不同线程池大小下的吞吐量
如果我们使用线程池大小为 16,峰值 QPS 约为 120000,但是这并不太稳定。
经过对共享集群所能想到的所有优化之后,它仍然不能达到写 QPS 的要求。为了进行测试,我们要求一个特殊的集群。
分区调优
移除 Docstoresink,仅保留 FlatMap。没有对分区器的调用,那么 64 个容器就能处理超过 200000 的输入消息率,而不会延迟。
在 FlatMap 之前,我们添加了自定义分区策略。
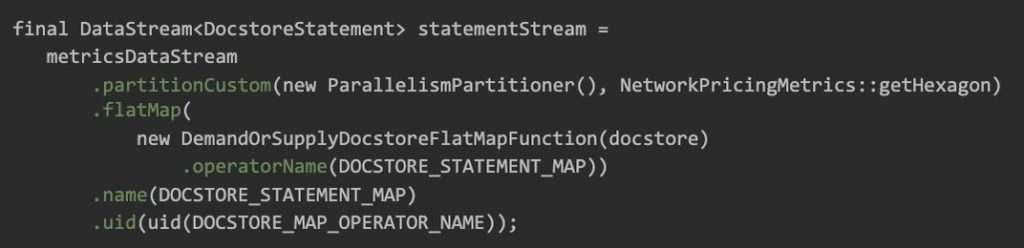
对于 384 个容器,延迟时间大约是 12 分钟。分区器的延迟范围为 0.2~5 毫秒。当增加到 512 个容器时,延迟降低到 3 分钟。随后,我们发现每个分区器调用的 0.2 毫秒成为瓶颈。在 flatmap 中,我们添加了本地分区器调用缓存。20 分钟后,缓存的点击率类似于输入信息率。
但是,延迟性仍在增加:
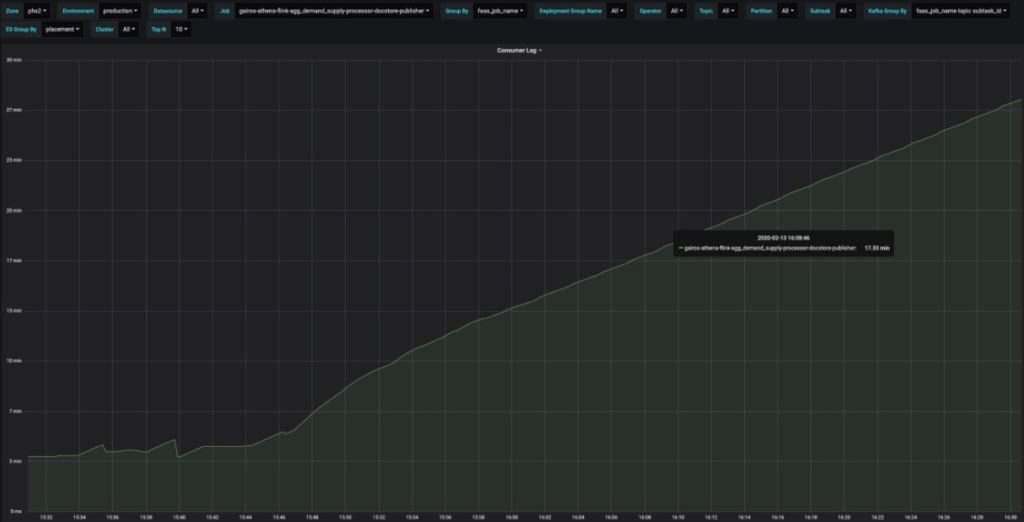
图 12:作业延迟现象持续增加。
背压处于自定义分区阶段。
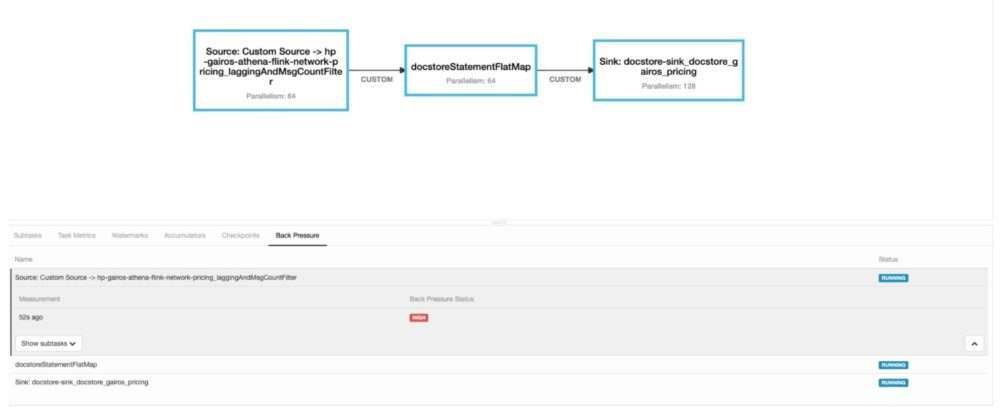
图 13:作业和背压的拓扑处于自定义分区阶段
将并行性更新为 128,有效地消除了管道中的任何延迟性。每个 DC 都可以写入 300000 QPS,没有任何问题。
数据大小
我们尝试了 3 种不同的模式来观察数据大小的差异。第一种模式为每个(环的大小,时间桶,供应/需求)元组使用一个列。第二种模式为需求和供应各使用一张地图。第三种是将颗粒度为 9 级的 7 个六边形分组为一行。
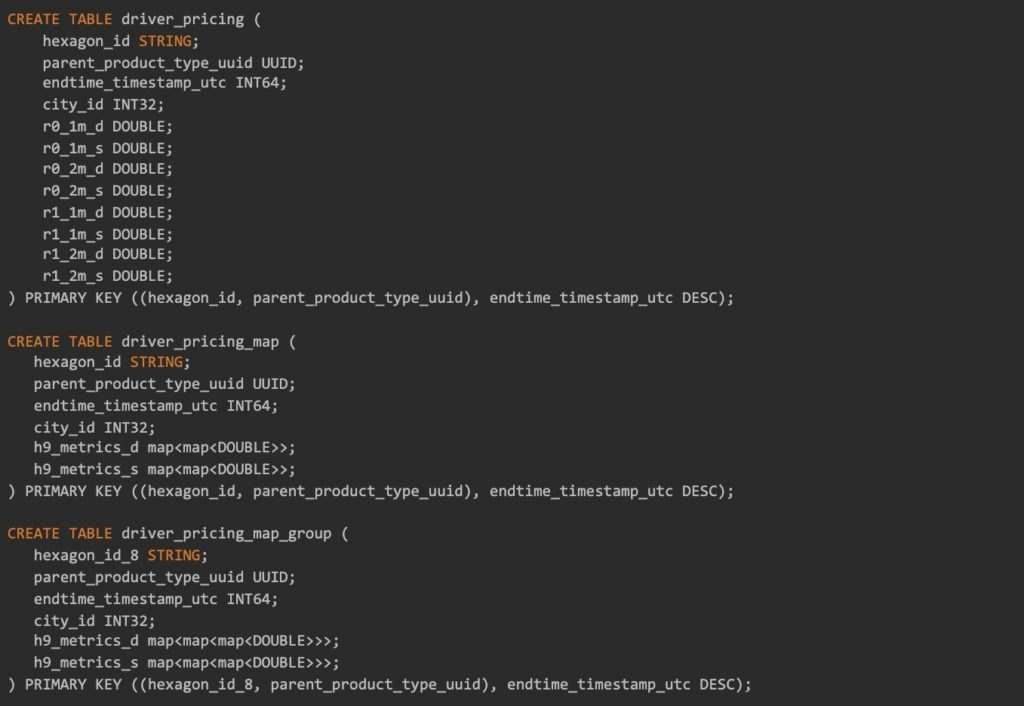
通过 6 天的数据,我们得到的数据大小如下:

表 9:不同数据模式下的压缩
在启用压缩之后,我们可以看到 3 个表可以节省大约 60% 的磁盘。
服务
在测试过程中,我们发现了一些延迟问题。P99 大约有 150 毫秒的延迟。在我们的定价工作流程中,这是不能接受的。经过调试,我们发现每个分区键都有许多行——大约 6000。这就是说,数据库引擎需要扫描至少 6000 行,然后在查询中应用传递的过滤。当分区键大小增加时,就会周期性地出现 200 毫秒的峰值。但我们知道 TTL 也是为这个表设置的,因此我们所做的就是在 Query 中部署一个热补丁,将结果限制在只有未过期的行上,然后应用查询中传递的过滤。这样降低了对底层引擎的扫描,而 P99 延迟降低到 10 毫秒。
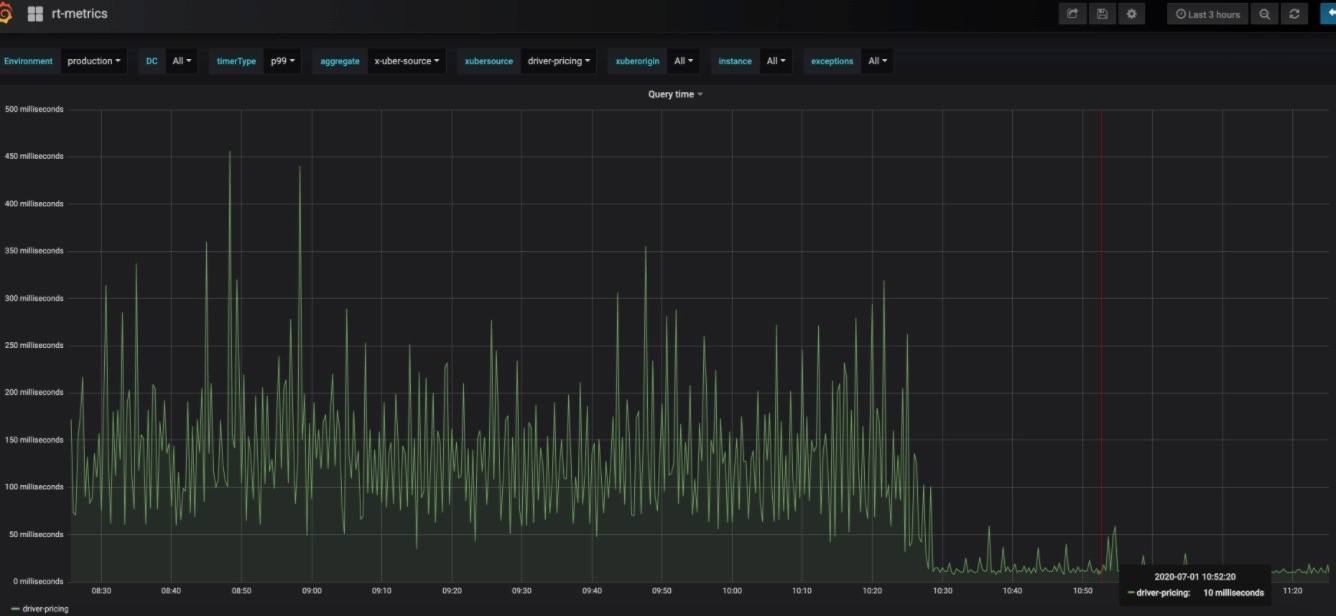
图 14:优化之后,服务延迟从 150 毫秒下降到 10 毫秒
结论
考虑到计算逻辑的复杂性、写吞吐量、服务 SLA 等因素,为具有近实时特性的机器学习模型提供性能非常具有挑战性。通过本文,我们介绍了我们所面临的问题和解决方法,希望对类似用例的同行们有所帮助。
作者介绍:
Feng Xu,Uber 高级软件工程师,领导 Gairos、uMetric 的流计算框架。
Gang Zhao,Uber 前高级软件工程师,负责 Gairos 优化、UMetric 消费,同时专注于存储层 Elasticsearch、Apache Pinot、Apache Cassandra、Docstore 和查询层优化。
原文链接:




