
作者 | 刘泽强 作业帮高级数据研发工程师
摘要
随着业务的高速发展和实时计算的迭代,业务对实时计算的需求越来越多,对实时任务的稳定性要求也越来越高。对实时计算平台而言,底层调度系统及计算引擎的稳定性、高可用性就变的十分重要。本文主要围绕作业帮实时计算平台底层调度系统,从背景现状、目标与挑战、方案设计以及未来规划等几方面来展开。
背景现状
开始之前,先简单了解一下之前实时计算平台后台调度的架构,如图 1 所示:
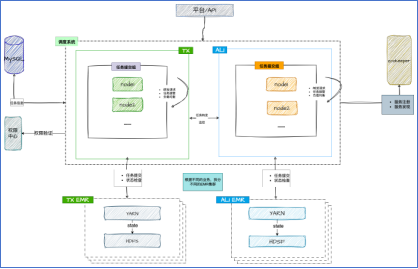
图 1
实时调度系统采用的是分布式、去中心无主架构,技术上,使用 AKKA 作为基本框架,实现高性能、纯异步的任务管理。功能上,我们将服务分为了不同的 group,一个 group 包含多个任务管理节点,一个节点可以同时隶属于多个 group。在作业帮内部,一个 group 可以理解为一个集群环境。为了达到分布式负载均衡的目的,每个 node 会负责对应 group 的一部分任务,对任务进行起停、状态同步。不同 group 的 node 之间,会根据收到的请求的不同,进行请求的转发与可用性监控。相同 group 的 node 之前,主要涉及到请求的转发与任务的负载均衡。在外部依赖方面,主要依赖 MySQL、Zookeeper、权限中心和 EMR。 其中:
MySQL: 主要负责存储任务相关的元信息,比如作业配置、执行历史等
Zookeeper: 主要负责服务的注册与监听。新节点启动的时候,会注册对应的临时节点,并通知给集群里其他节点;节点下线或者丢失的时候,也会通知集群其他节点。
权限中心:大数据统一的权限校验服务,主要用于校验用户针对任务的权限。
EMR:我们使用半托管的云 EMR 产品,使用 Yarn 作为底层计算引擎,HDFS 作为 Flink 任务的 state 存储。
从目前的平台架构来看,平台的稳定性在如下三个方面还有一些欠缺和不足:
1. 调度服务本身:
(1) 调度服务内部虽然本身是分布式的,但是根据任务所提交的 EMR 集群,进行了分组,比如腾讯云的任务分组,只能提交到腾讯云 EMR,这样当单云/AZ 故障的时候,调度服务就会故障,无法服务。
(2) 调度服务同云的 EMR 共用一个调度分组,不同业务之间在集群故障的时候,会相互影响。
2. EMR:目前 EMR 属于半托管模式,虽然有云上的支持,但是稳定性最多也只能达到 99.9%
3. 服务依赖:zookeeper 也是使用云上 EMR 半托管产品,稳定性也只有 99.9%,故障的时候会导致调度服务不可用。
目标与挑战
随着越来越多的公司核心业务在使用实时计算平台运行任务,业务对实时计算平台提出了更高的要求:
服务可用性要求 99.95%
支持 AZ 即或者 region 级容灾
在现有的架构下,显然无法满足这样的要求。
服务稳定性的保障一般情况下,可以分为三层:
1. 围绕研发需求、设计、上线、变更管控来降低故障的发生概率
2. 通过故障演练/预案建设的维度,思考怎么缩短故障处理时长
3. 通过可观测性等手段,提前预防和发现故障
方案设计
整体架构
针对新的稳定性的挑战和现有架构,我们主要从以下几个方面进行改造优化:
调度服务:
支持双云部署
服务级别或者服务内部限流队列针对不同业务进行拆分
EMR 集群支持 AZ/双云级别的互备,同时能够快速切换任务,缩短 flink 任务的异常时间
服务依赖等组件多云:
MySQL 和权限服务目前都已经是双云部署,无需调整
Zookeeper 升级为全托管的、多 AZ 部署产品
加强服务/组件监控,提前发现问题
根据上面的优化点,改造后的整体架构如图 2 所示。
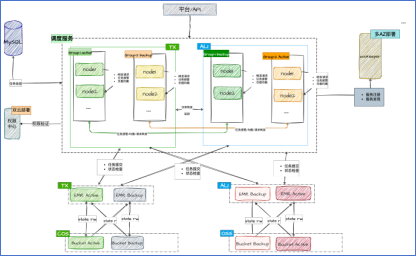
图 2
主要模块设计
了解目前项目的整体架构后,下面主要从调度服务多云/多可用区支持、EMR 集群多 AZ/多云互备和其他改造项方面阐述实现细节。
调度服务多可用区/多云
从上面的架构图,可以看到,调度服务层面,我们给每个任务组打了标签。其中 active,表示正常情况下该组实例负责所有任务的管理工作;backup 表示该组实例作为 active 组的备份组,只有在所有 active 组的都挂掉的情况,才会接管并负责任务的管理工作。之所以这么设计,是因为我们目前 80%的 flink 任务都是使用 per-job 模式运行的,为了防止跨云造成提交任务性能损耗。虽然目前的设计是针对多云部署的,但是同样支持多 AZ 部署。当多 AZ 部署的时候,可以将任务组的标签都设置为 active,这样,所有的节点都会参数任务的管理工作。
调度服务主备在任务负载均衡和管理的流程如下:
当 Active 任务组节点全部丢失的情况下, Backup 任务组接管全部任务,并内部进行负载均衡和任务管理。
当只有部分 Active 任务组 节点 丢失的情况下,Active 任务组内部剩余节点进行负载均衡和任务管理。
当 Active 任务组有节点新增的时候, 如果当前有其他存活 Active 任务组节点,Active 任务内部进行负载均衡和任务管理,如果当前没有其他存活 Active 任务组节点,则从 Backup 任务组接管所有任务,进行管理。
当 Backup 任务组 部分节点丢失情况下,如果当前没有存活 Active 任务组节点,Backup 任务组内部进行负载均衡和任务管理,否则,不做处理。
当 Backup 任务组新增节点的情况下, 如果当前没有存活 Active 任务组节点,Backup 任务组内部进行负载均衡和任务管理,否则,不做处理。
目前调服服务的任务负载均衡/管理 逻辑,采用 hash(task_name) % num_of_group_nodes 的方式决定任务应该由哪个节点进行负责。
EMR 集群主多 AZ/多云备切换
想要实现高效快速 EMR 集群灾备需要有几个问题需要解决:
1. 往什么地方切。一般情况下,企业的跨云或者跨城带宽是有限的。所以 EMR 灾备最好是多 AZ 部署。
2. 基于什么标准切。EMR 集群故障的情况下,怎么保证 Flink 任务真正的被杀死了,避免任务双跑,影响数据的准确性。
3. 如何透明的切作业。因为 Flink 任务都是长生命周期的,带着 state 中间计算结果,我们目前的 state 是存储在 EMR 的 HDFS 上的,切换集群的话,就需要保证 state 在切换后可用。
Flink 任务存算分离
目前 Flink 任务的 state 使用的是 EMR 的 HDFS 存储的,是存算一体的,想要满足 Flink 任务切换集群后 state 仍然可用,只能存算分离。业界推荐的方案是使用对象存储来存储 state。
我们都知道,对象存储和 HDFS 在性能上面还是有比较大的差异的,在使用对象存储替代之前,我们需要想看看切换到对象存储后,checkpoint 的时长业务是否可以接受。
作业帮内部,基本上大家用的都是 FSBackend, 没有特别大的状,状态基本都在 1G 以下。下表为目前我们内部任务的 state 大小统计情况:
我们重点测试了一下 1M, 64M, 512M, 1G 状态在使用 HDFS OSS 作为 FsStateBackend 的性能区别,发现对应的 checkpoint 时间差别不大,都在可接受范围。
我们重点测试了一下 1M, 64M, 512M, 1G 状态在使用 HDFS OSS 作为 FsStateBackend 的性能区别,发现对应的 checkpoint 时间差别不大,都在可接受范围。
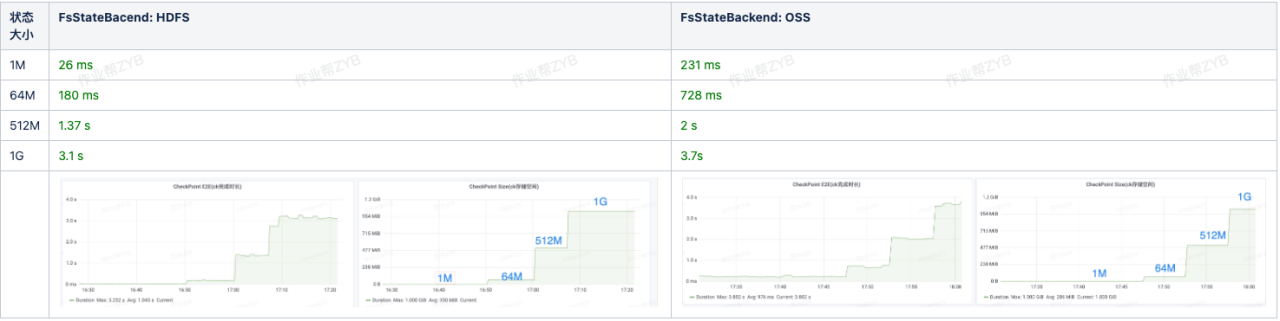
因此将 state 切换到对象存储,在作业帮内部是完全可行的。
为了防止业务之间的相互影响,我们针对每个 EMR 集群,都设置了专属的存储桶,针对自身 EMR 可读写,针对其他 EMR 只可读。出于性能和成本的考虑,针对不是稳定性要求不是很高的业务,我们仍然将 state 存储在 HDFS 上。
EMR 集群容灾切换
首先,往什么地方切?我们目前选择的是 EMR 多 AZ 互备,防止跨云数据传输导致专线打满。
其次,基于什么标准切?在决定切换标准前,我们需要知道,EMR 的故障都有哪些场景?在什么场景下,我们可以确认 Flink 任务能否被杀死,确保任务不会双跑。
EMR 故障的场景,大体可以分为两大类:
网络问题:EMR 可能正常,也可能不正常。
EMR 集群异常:
服务 GC 无响应等问题
两个 Master 均为 standby 状态
两个 Master 因为内存等原因频繁启停,无法正常工作
......
目前我们的任务都开启了 Flink 的高可用,这样当 JobManager 因为某种原因挂掉的情况下,任务可以自行恢复。同时,在 EMR 层面,我们设置了 yarn.resourcemanager.recovery.enable=true, 这样在 ResourceManager 从异常恢复的时候,会自动恢复之前异常的任务。
因此,为了确保 EMR 集群故障的情况下,任务能够被杀死,我们需要达成两个条件之一:
1. 调度服务可以明确知道,任务被杀死了
2. ResourceManager 异常恢复的时候,不要恢复应该被杀死的任务
针对条件一,我们可以通过 Yarn Java SDK API 进行杀死任务和通过 Flink Rest API 杀死任务。
YarnClient.kill(app_id)
curl -XPATCH http://
: /jobs/ ?mode=cancel,其中 jm_addr 可以通过 AppReport 的 originalTrackingUrl 获取。
针对条件二,我们可以通过设置一些参数,保证 ResourceManager 异常的情况下,不会恢复任务。相关参数参考下表:

之前我们任务的杀死逻辑很简单,收到 kill 命令以后,会不断循环的通过 YarnClient.kill(app_id)的方式,杀死任务。为了应对 EMR 异常的场景:
我们首先添加了 EMR 异常的检测逻辑,使用一个专有的 actor 定期检测 Yarn 状态,将 EMR 集群的状态分为了四种状态:
Normal: 状态正常
VoteAbNormal: 投票异常状态
ThresholdAbnormal:超过阈值异常状态
MaunalAbnormal:任务标记异常状态
具体检测逻辑如下:

考虑到目前平台没有任务优先级的概念,因此,目前 EMR 集群异常切换,是需要用户手动发起的,通过平台选择高优的任务,批量先杀死故障 EMR 集群的任务,然后更新任务并迁移的备用的 EMR 集群上。
调度服务内部的杀死任务流程如下图所示:
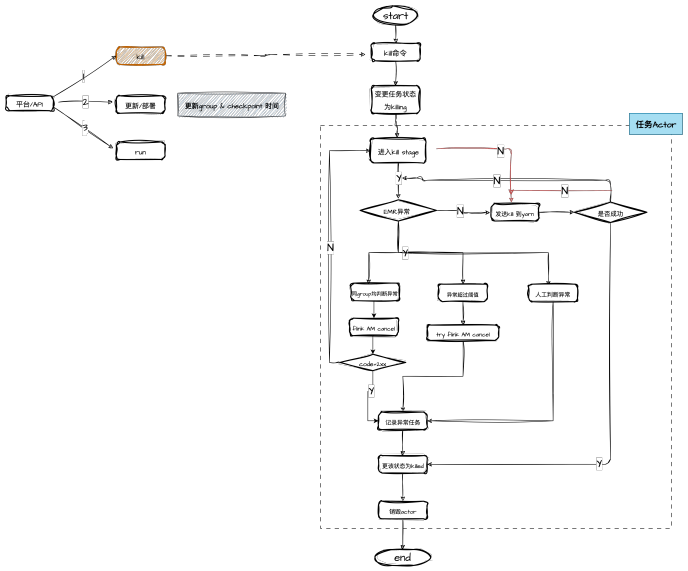
其他功能项
为了避免业务之间的相互影响,保证异常切换任务提交速度。我们针对任务提交组做了如下改造:
针对稳定性要求高的业务,我们准备了专用的任务提交组节点。
针对稳定性要求不是很高的业务,仍然共用任务提交组,只是基于 EMR Yarn 队列,针对不同业务方的任务,做了提交限流队列的分组。
未来规划
未来我们实时计算调度平台在稳定性方面的一些规划:
计算引擎迁移到云 K8S 上,降低运维成本,同时提升引擎的 SLA。
底层实时调度服务容器化,提升稳定性、快速扩缩容。
调度服务依赖如 Zookeeper 等多云部署,兼容云间断网等
参考链接
https://hadoop.apache.org/docs/r2.8.5/hadoop-yarn/hadoop-yarn-common/yarn-default.xml




