
本文主要介绍 Apache Kudu 及在网易实时数据采集、维表数据关联、实时数仓 ETL、ABtest 等场景的实践应用。主要内容包括:
系统概述:认识 kudu,理解 Kudu 的系统设计与定位
生产实践:分享网易内部的典型使用场景
遇到的问题:实际使用过程中遇到的问题和问题的排障过程
功能展望:对 Kudu 功能特性的展望
Kudu 定位与架构
Kudu 是一个存储引擎,可以接入 Impala、Presto、Spark 等 Olap 计算引擎进行数据分析,容易融入 Hadoop 社区。Kudu 整合了随机读写和大数据分析能力,具有低延迟的随机读写能力和高吞吐量的批量查询能力。
与 HBase、Casandra 不同,Kudu 要求声明 Schema。Schema 可以为上层计算引擎提供更多元数据,进行计算优化。Kudu 的每个字段有主键、列名和列类型。拿到列类型信息后能够对不同列进行编码和压缩,优化存储空间,减少磁盘开销。Kudu 支持 bitshuffle、运行长度编码、字典编码等列编码方式,这些编码会根据列的类型不同做不同设计。比如对于重复值多、重复值变化不大的数据的压缩率很好。
Kudu 使用列式存储给 Kudu 带来了如下特性:
1. 存储上可以节约空间
2. 可以对查询做更多优化,如将过滤条件下推到 kudu 执行,节约计算资源
3. 支持向量化操作
Kudu 的 Schema 和列存
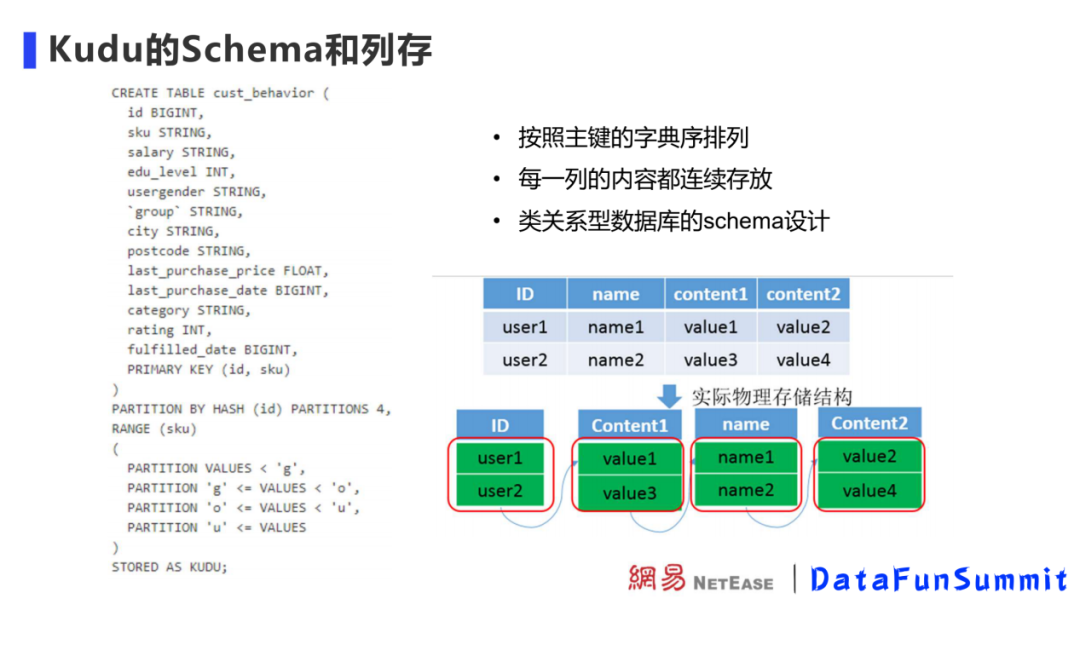
Kudu 数据存储在 Table 中,Tablet 是 Kudu 的读写单元,Table 内的数据会划分到各个 Tablet 进行管理。
创建 Table 时,需要指定 Table 的分区方式。Kudu 提供了两种类型的分区方式 range partitioning ( 范围分区 ) 、 hash partitioning ( 哈希分区 ),这两种分区方式可以组合使用。分区的目的是把 Table 内的数据预先定义好分散到指定的片数量内,方便 Kudu 集群均匀写入数据和查询数据。范围分区支持查询时快速定位数据,哈希分区可以在写入时避免数据热点,可以适应各个场景下的数据。
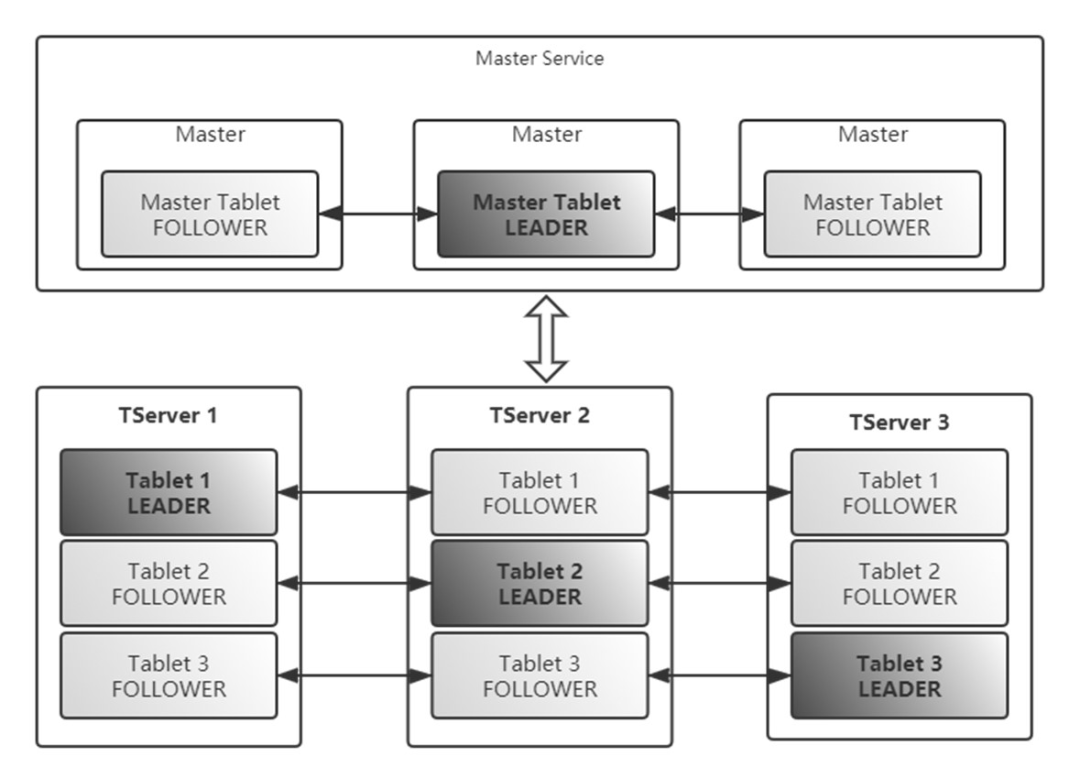
Kudu 有管理节点(Master)和数据节点(Tablet Server)。管理节点管理元数据,管理表到分片映射关系、分片在数据节点内的位置的映射关系,Kudu 客户端最终会直接链接数据节点。
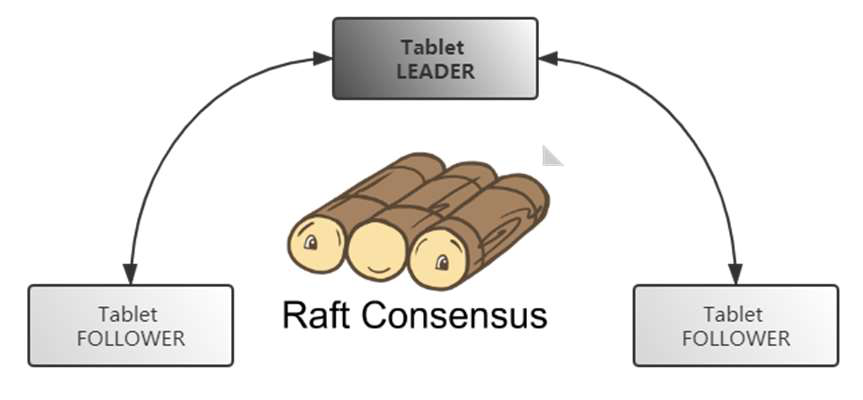
Kudu 作为分布式系统,为了保障数据可用性和高可用,支持多副本。Kudu 使用 Raft 协议来实现分布式环境下副本之间的数据一致性。Raft 算法数据不依赖其他存储和文件系统,优势在于可以保证服务高可用、服务可用性、一致性的均衡。
Kudu 的 update 设计
Olap 中对 update 的设计会影响到 Olap 性能。update 操作可能引发数据多版本问题和 update 引发的数据 merge 问题。
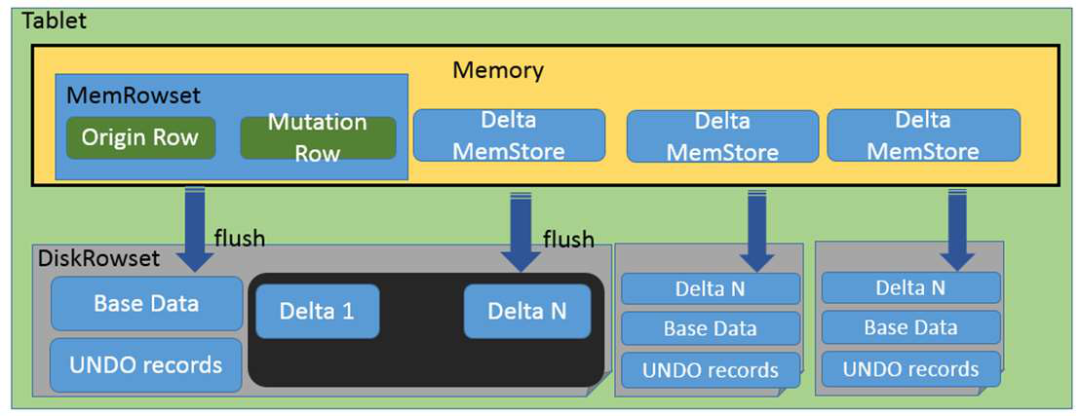
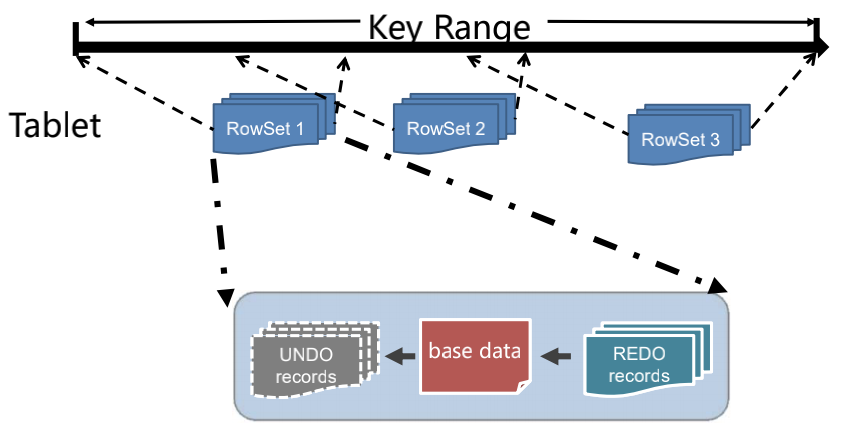
Tablet 是 Kudu 数据读写单元,Tablet 下更细分的数据存储单元是 RowSet。RowSet 有两种, 分别是 MemRowSet 和 DiskRowSet,不同 RowSet 维护了不同组件范围内的数据。内存中的 MemRowSet 在到达一定大小后会刷盘成为 DiskRowSet。

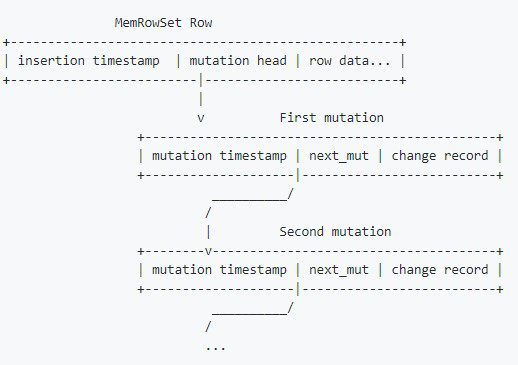
Kudu 把更新操作当作一条新操作,而不是写一条新日志。更新操作是 Undo/Redo 记录,这些内存中的更新操作会被整合为 DeltaMemstore 持久化。Base 数据、Undo 数据、Redu 数据写在同一个 RowSet 中。这样的存储设计优点是可以在更新时候快速找到数据,缺点是查询时需要确认查询的主键在哪个 RowSet 位置中。
Kudu 也使用了 LSM 的结构。Kudu 的 comopaction 有多种:MinorDeltaCompaction、MajorDeltaCompaction、MergingCompaction。
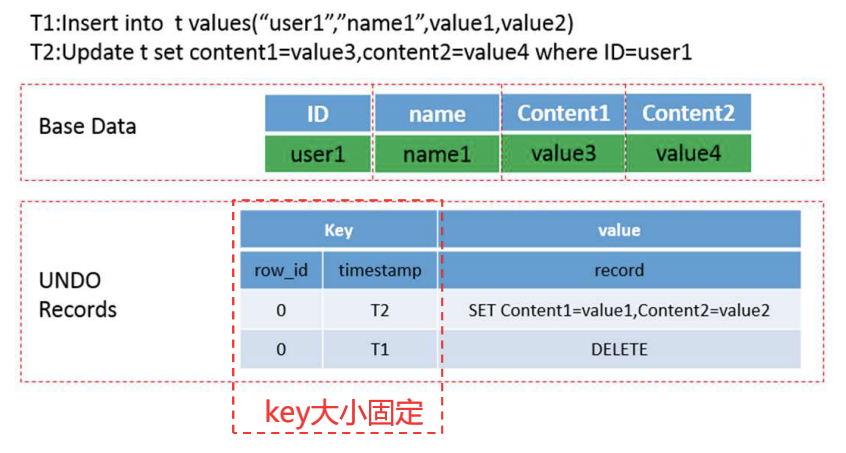
Kudu 的 update 是一个多版本操作,目的是写入和读取时互相不干扰、不需要读时额外加锁。
小结
Kudu Update 设计特点:
• 更新已经 flush 的数据和写入新数据走不通的处理逻辑,原始数据和更新位于同一个 Rowset,不用跨 Rowset 进行 merge
• 通过 base 数据的 RowID 和更新时间戳作为 REDO/UNDO 数据的 key,读取更新高效
• Key 大小固定,存储和比较效率高
• 不需要查询出主键数据也能获取更新数据
• 在大多数使用场景下能够实现更高效的读取
• 如果返回的结果不要求顺序,直接从 RowSet 中读出数据,不用 merge
• 如果更新较少,REDO 会快速 merge 到 base 数据,这时在读取最新数据时,可以不进行 apply REDO 的操作
生产实践
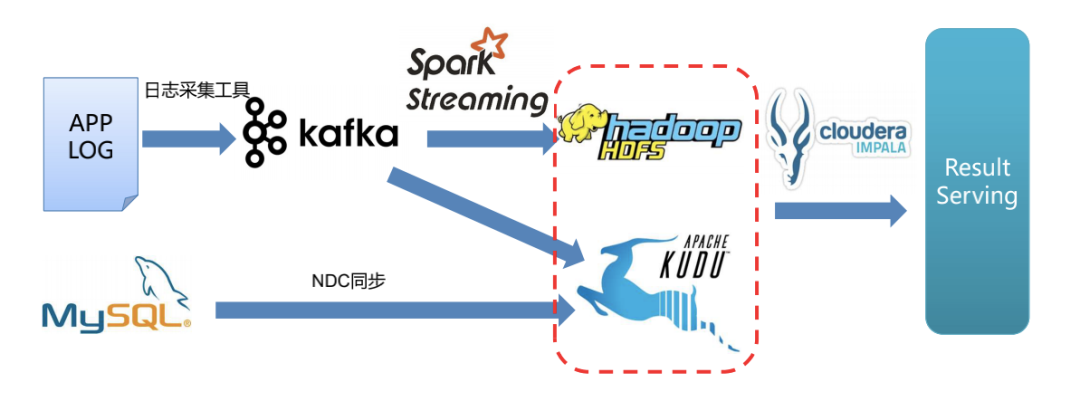
实时数据采集场景
实时数据分析中,一些用户行为数据有更新的需求。没有引入 Kudu 前,用户行为数据会首先通过流式计算引擎写入 HBase,但 HBase 不能支撑聚合分析。为了支撑分析和查询需求,还需要把 HBase 上的数据通过 Spark 读取后写入其他 OLAP 引擎。使用 Kudu 后,用户行为数据会通过流式计算引擎写入 Kudu,由 Kudu 完成数据更新操作。Kudu 可以支持单点查询,也可以配合计算引擎做数据分析。
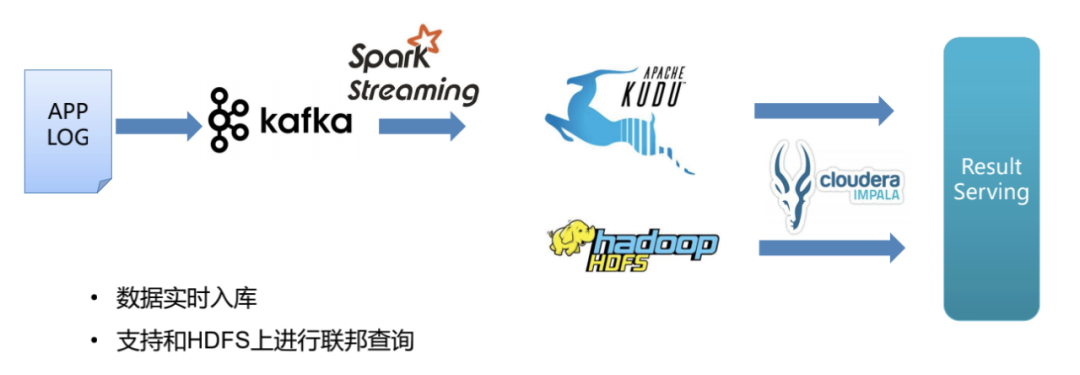
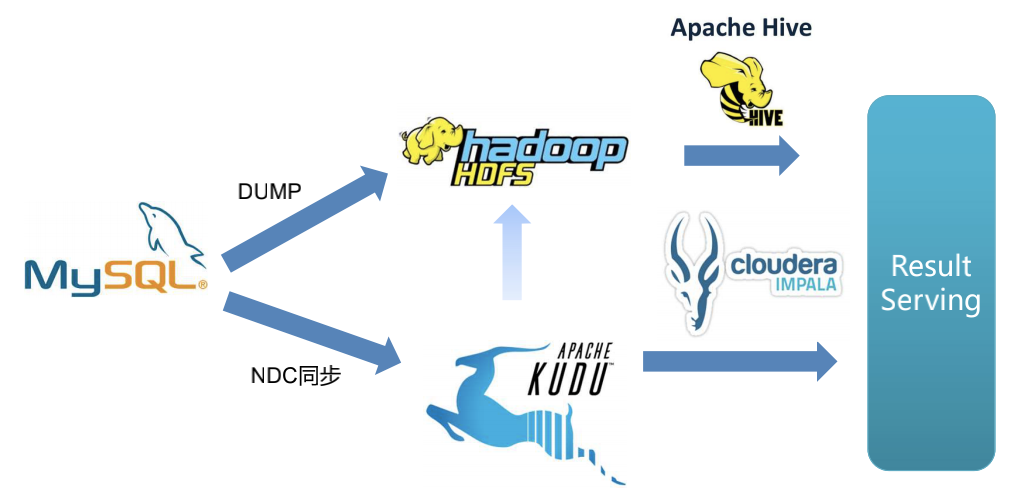
维表数据关联应用
有些场景中,日志的事件表还需要和 MySQL 内维度表做关联后进行查询。使用 Kudu,可以利用 NDC 同步工具,将 MySQL 中数据实时同步导入 Kudu,使 Kudu 内数据表和 MySQL 中的表保持数据一致。这时 Kudu 配合计算引擎就可以直接对外提供结果数据,如产生报表和做在线分析等。省去了 MySQL 中维度表和数据合并的一步,大大提升了效率。
实时数仓 ETL
Kudu 作为分布式数据存储引擎,可以和 Hadoop 生态更好结合,因此在生产中我们采用了使用 Kudu 替换 Oracle 的做法,提升了扩展性。
ABTEST
在我们的 ABTest 业务中有两种日志,行为日志和用户分流日志。
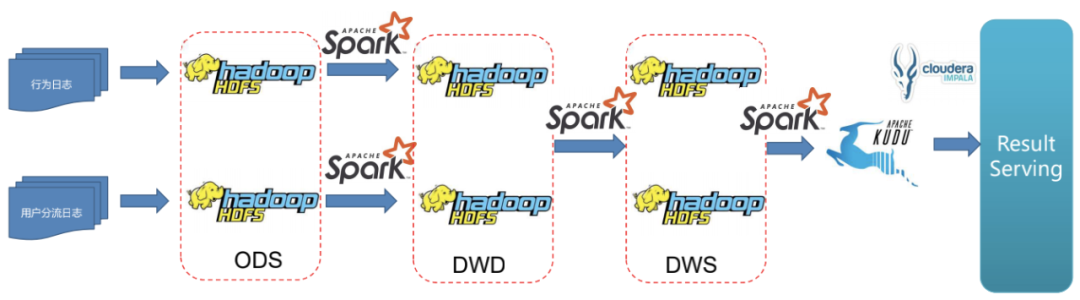
架构升级前,我们采用了比较传统的模式,将用户行为日志和用户分流日志分别写入 HDFS 作为存储的 ODS 层,通过 Spark 做清洗、转换后导入 HDFS 作为存储的 DWD 层,再通过 Spark 进行一步清洗、按照时间或其他纬度做简单聚合后写入 DWS 层。
这个架构的问题是数据产出时间比较长,数据延迟在天级别。业务方需要更及时地拿到 ABTest 结果。
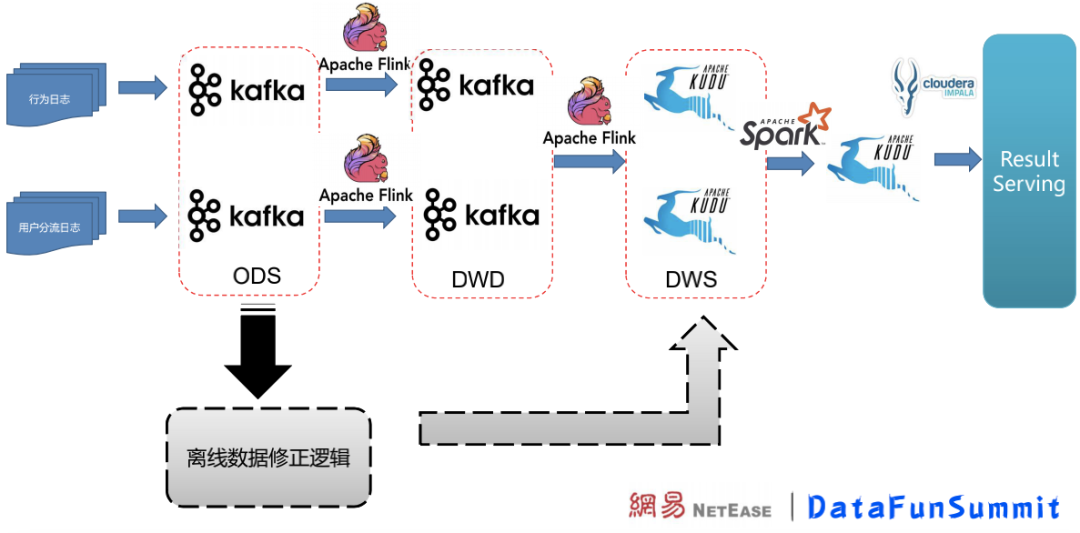
架构升级后,使用 Kafka 作为 ODS、DWD 层存储。Flink 在 ODS 层数据的基础上继续做一层整理和过滤,写入 DWD 形成明细表数据;DWD 层在 Flink 中做简单聚合后写入 DWS 层,Kudu 在 DWS 层作为数据存储。
Flink 开窗口实时修正实验数据,这一操作在 Kudu 完成;超出了 Flink 时间窗口的数据更新则由离线补数据的操作在 Kudu 中完成修正。
架构升级后,数据延迟大大降低,能够让 ABTest 业务方更实时地拿到结果。
我们遇到的问题
问题 1: 节点负载不均衡
一些大表场景下会有负载不均衡问题。Kudu 不会把 range 下的哈希分片当作一张表,而是把整个表的分片当成了平等的表进行处理。而在真实使用场景中,range 基本是时间字段;需要让 range 的 hash 分片更均匀地分布在各节点上,防止数据倾斜。下图是数据倾斜的情况展示:
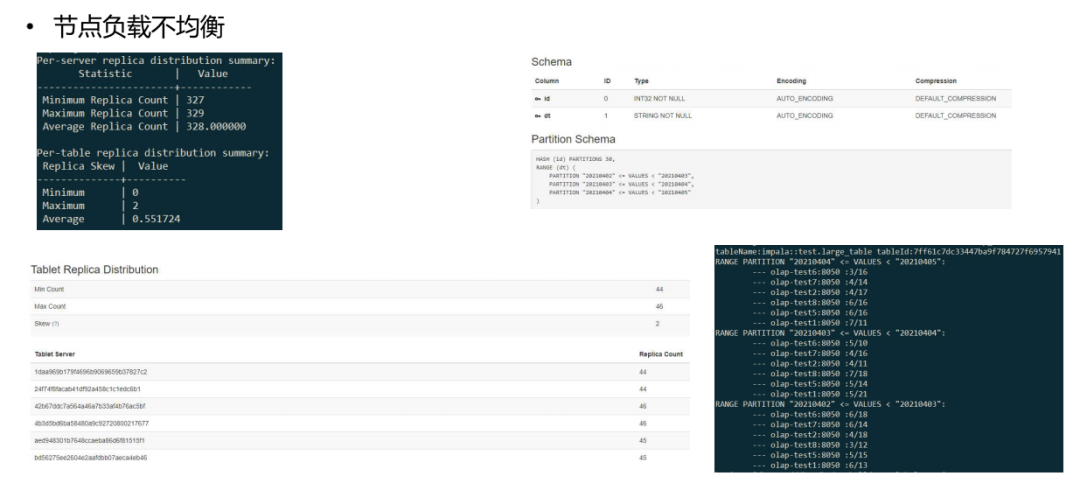
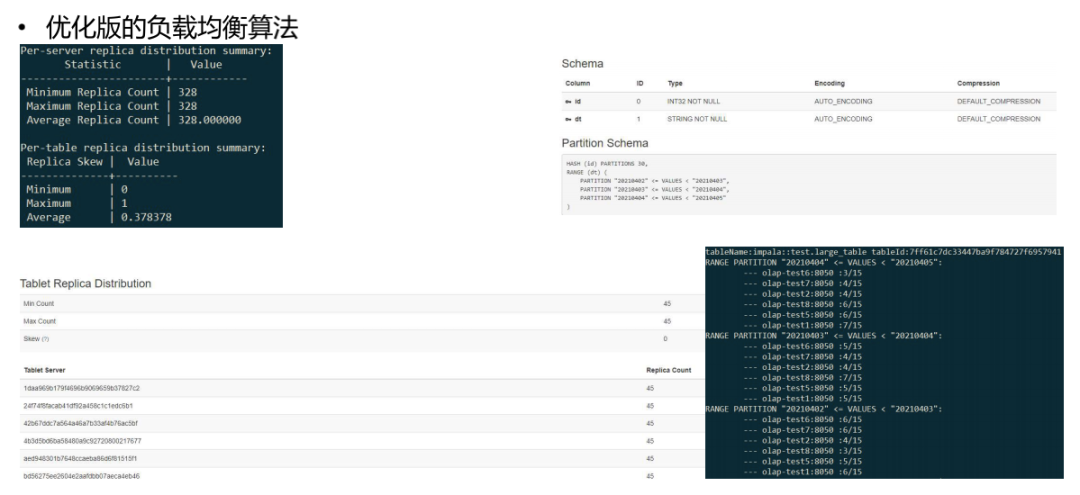
我们的解决方案是实现了一套优化版本的负载均衡算法,这个算法能够把 range 表当作单独的表做负载均衡,解决了数据倾斜。下图是优化后效果:
问题 2: 表结构设计复杂
问题 3: 没有二级索引,只能通过控制主键顺序和分区键来优化某几种查询模式
问题 4: 创建表时需要根据业务场景专门设计表结构
问题 2-4,对业务方要求比较高,经常需要专人介入引导业务方导入数据。为了解决问题,我们内部设计了二级索引来解决上述问题。二级索引可以满足查询性能的要求,同时减少用户设计表时候的复杂度:
通过支持二级索引来优化包含非主键列过滤的查询
支持二级索引能够降低业务设计表结构的复杂度
社区对二级索引的支持进度 KUDU-2038:Add b-tree or inverted index on value field
Kudu 功能展望
BloomFilter
BloomFilter 成本较低、效率较高。Join 场景下,小表动态生成 BloomFilter 下推到存储层,防止大表在 Join 层做数据过滤。最近的 Kudu 中已经支持了 BloomFilter 作为过滤条件。
灵活分区哈希
Kudu 每个 range 的 hash bucket 数量是固定的。考虑到时间和业务增长,在项目实施前期阶段要给 Kudu 哈希桶数量设置略大,但是数据量较小的场景下过大的分片个数对资源是一种浪费,社区也不推荐 hash bucket 设置得比较大。期望后续 Kudu 可以更灵活地适配 hash bucket 数。
> KUDU-2671:Change hash number for range partitioning
多行事务
Kudu 暂时不能支持多行事务。目前更新主键需要业务自己实现逻辑检测。
> KUDU-2612:Implement multi-row transactions
Flexible Schema
一些业务场景下业务没有唯一主键,但只希望利用 Kudu 的大批量写入、聚合分析查询的特性。接入业务时 Kudu 对 Schema 的要求比较高,一些业务场景无法支持。
> KUDU-1879:Support table without a primary key
本文转载自:Datafuntalk(ID:datafuntalk)
原文链接:Apache Kudu在网易的实践




