
大家好,我是蚂蚁隐语联邦学习团队的胡东文。今天非常高兴来分享我们的应用实践。其实拆分学习在隐语第一个版本里就已经有一些内容了,为什么在推荐场景要单独再重新提它呢?其实,在实践过程中,我们发现简单的拆分学习架构是没有办法满足很多实际应用的,在实际应用过程中需要非常多的优化,今天就会和大家分享这方面的工作。
我将从以下三个方面展开今天的分享:
1. 在跨域推荐场景中,普通拆分学习为什么没有办法满足需求
2. 从数据接入到模型设计的全链路解决方案中做了哪些东西
3. 有一整套解决方案后,如何在 SecretFlow 中使用这些功能

跨域推荐场景的挑战
跨域推荐场景介绍
跨域推荐场景是非常多的,例如在一个 APP 里搜索了一个东西,到另外一个 APP 中也会推荐相应的广告。或者在一个平台内也会出现跨域推荐的场景,例如在一个类似短视频平台的内容平台中,后面有内嵌的商家,商家需要在这个平台上做相应推荐吸引更多的用户,这个用户到底喜欢哪些东西,除了商家自己有用户信息之外,这个上架所依附的平台有更多信息。例如,我作为这个平台的用户,在上面刷了很多视频,这些视频就会展示我的兴趣点,这些展现出来的兴趣点对推荐是很有帮助的。这种情况下,如果能把这个数据和我的数据联合起来,做一个推荐模型,效果会比仅使用我在商家里的个人数据展现的推荐效果好很多。
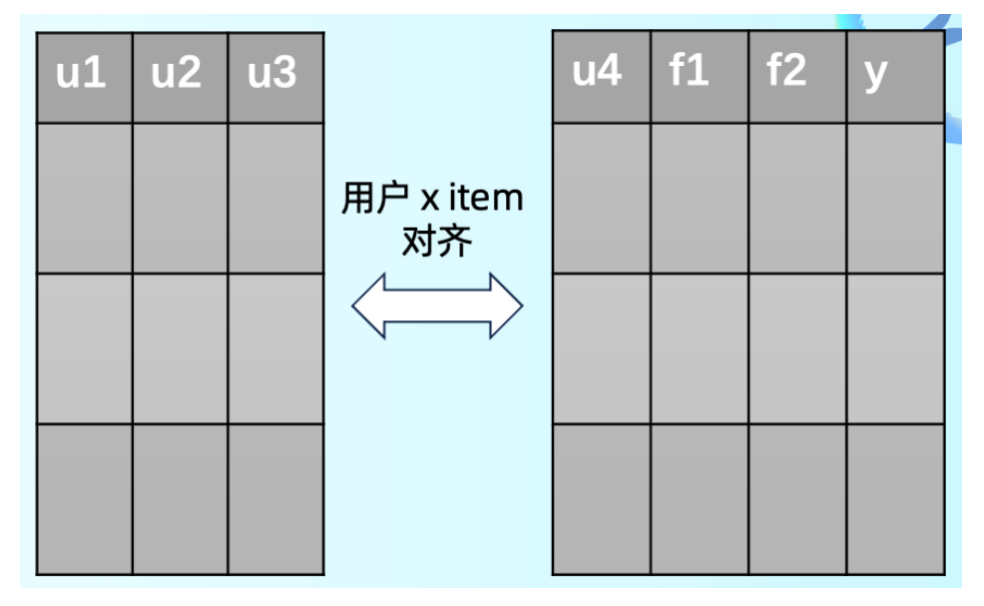
抽象一下其实就是上图的表格,左边的平台方有用户兴趣特征,右边的商家方同样也有用户特征和商品特征,同时商家方还有转化数据。相当于是在这样的垂直拆分场景下,商家想要做一些预测,这个用户会不会去买这个商品,或者点击这个商品。
在这个过程中,刚才提到了用户的感受。但其实对商家平台方来说是不希望数据在不同公司间流通的。但是从平台的维度看,商家的用户数据是他们自己的资产,商家不想把自己的资产交给别人,但是平台又想把自己的数据和平台上其他商家的数据联合起来给他们提供助力。简而言之,平台不想让商家把自己的数据给出去,但想把这些数据隐含的价值给出去,在这种情况下就很适合用联邦学习,特别是拆分学习。
拆分学习基础架构
先简单介绍一下拆分学习的基础架构。这个基础架构非常简单,就是我们虽然不能把数据给出去,但是在训练过程中可以把中间的数据做交换。这个场景中,Alice 跟 Bob 都会有一个子模型,这两个子模型可以做一些前向的计算,在有转化标签这一方可以进行融合,出现第三个子模型。在训练过程中,根据前向传播的结果和真实标签计算 loss,然后进行反向传播,使整个训练可以 work,这是基本的拆分学习架构。在隐语第一个版本中就提供了这样的架构,这个架构本身可以满足一些简单的推荐场景,有一个典型的例子是银行营销。

跨域推荐场景的挑战
在实际业务过程中,会发现基本的拆分学习架构存在很多问题:
最直接的就是怎么接入数据。在实际过程中,不同机构或不同公司大数据平台都是不一样的,SecretFlow 作为纯粹的计算引擎,不太可能接所有数据。那我们如何做这件事情。
在推荐模型上,可以用简单的推荐模型,例如可以用 DNN 做推荐模型,这种是非常简单的,但有些比较高级的推荐模型,是不是可以直接放到拆分架构里做,这也是一个问题。
因为这种架构下每一个 batch 都需要有前向和后向的通信,通信会不会成为瓶颈。
当有前向和后向的通信时,通信的中间数据会不会造成安全性的问题,例如隐私泄露和价值泄露。
最后完成了模型的训练,可以发现模型分成 A 和 B,那需要如何做在线服务,这也是个问题。
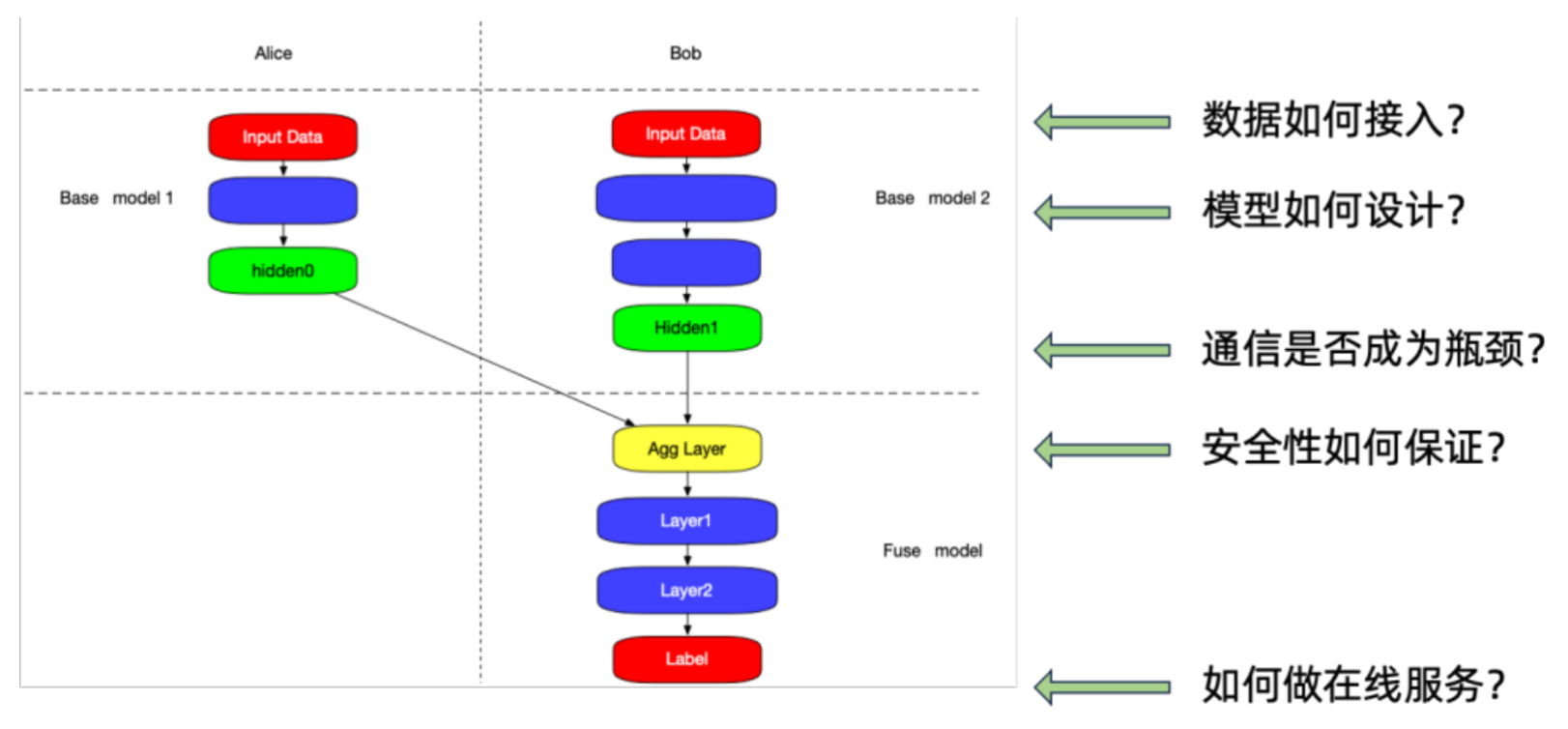
今天,我们就围绕这几个方面分享一下隐语是怎么做的。
从数据接入到模型设计的全链路解决方案
数据接入
我们先分享一下数据需要怎么接入。数据接入是比较典型的平台工程工作,这块并不是交给 SecretFlow 这一层实现的。在实际使用时,我们会依赖调度框架 Kuscia ,使用 Kusica 框架一方面可以实现屏蔽不同机构的基础设施、网络等,同时也会有一层数据网格 DataMesh,它是用来负责对应用屏蔽所有数据访问的细节。DataMesh 的设计思想是对上提供一套统一的数据接入接口。我们也不想重新造轮子,所以使用了业界比较成熟的是技术 Arrow Flight RPC,Arrow 是 Apache 开源的一个存储格式或者数据传输的格式,可以比较高性能得实现数据传输和进行零拷贝优化。

我们会基于这个 ArrowFlightRFC 去实现 DataMesh,这样 SecretFlow 就可以使用 ClientSDK 方便得接入各种数据源。关于 DataMesh,我们计划再进行很多功能的实现,且这块对用户来说是透明的。
关键的是下面 DataSource 这一层,不同的用户如果有不同数据源接入需求,只需要在 DataSource 层实现 connector,例如阿里云的 OSS,AWS 的 S3 等等,这种类似于文件的数据源可以用线性访问接口实现,SQL 数据源可以用 SQL Connector 来实现,达到整个统一接入的模式。这块目前是在α阶段,我们会在尽快开源,届时也欢迎大家一起共建 DataMesh 的体系。
模型设计
第二部分是模型设计。刚才提到 DNN 是很方便拆分的,但其他模型怎么样?
这个以 DeepFM 模型为例,这个模型其实是 CTR 里经典的模型,可以看到它的结构比 DNN 会复杂一些,拆分的方式也不是非常显而易见的。简单解释一下它的架构:
左边是和 DNN 模型不一样的部分;
右边是个普通的 DNN,一个全连接网络。

这里我们直接看跟 DNN 不同的左边。左边的核心是:它有一个一阶的特征和二阶的特征交叉。
一阶特征:指一个目标用户有 ABCD 几个特征,哪个特征重要性比较强,系数就更大。比如说我是一个喜欢看视频的人,那我就会推荐一些视频相关的东西,比如说好的显示器。
特征交叉:我们举一个经典的例子:啤酒和纸尿裤。啤酒和纸尿裤是两个特征,单独看不是很重要,但是放到一起就很重要,有时候买了纸尿裤的用户之后就会买啤酒。想要表达的就是在特征交叉后可以挖掘出用户更多的特征,这个特征更强对整个推荐的效果也更好,这就是所谓的二阶交叉。这也就是 FM 这一层要做的事情。
简单总结一下,FM 部分就是一阶特征和二阶交叉的和。
这个东西怎么拆分?因为要交叉,也就是要做个乘法。A 和 B 两方都有特征,A 和 B 之间的乘法就有问题,不可能把 A 的特征直接给到 B,因为不能把原始数据直接发出去。简单的拆分就是 A 这边自行交叉,B 也自行交叉,然后再去做融合。这种情况下,如果啤酒在 A 这边,纸尿裤在 B 这边,那就没办法发现这组有效的交叉特征,也就是没有办法发挥 DeepFM 的完整能力。
所以,我们想设计一个拆分方案,使得所有特征都可以做交叉。
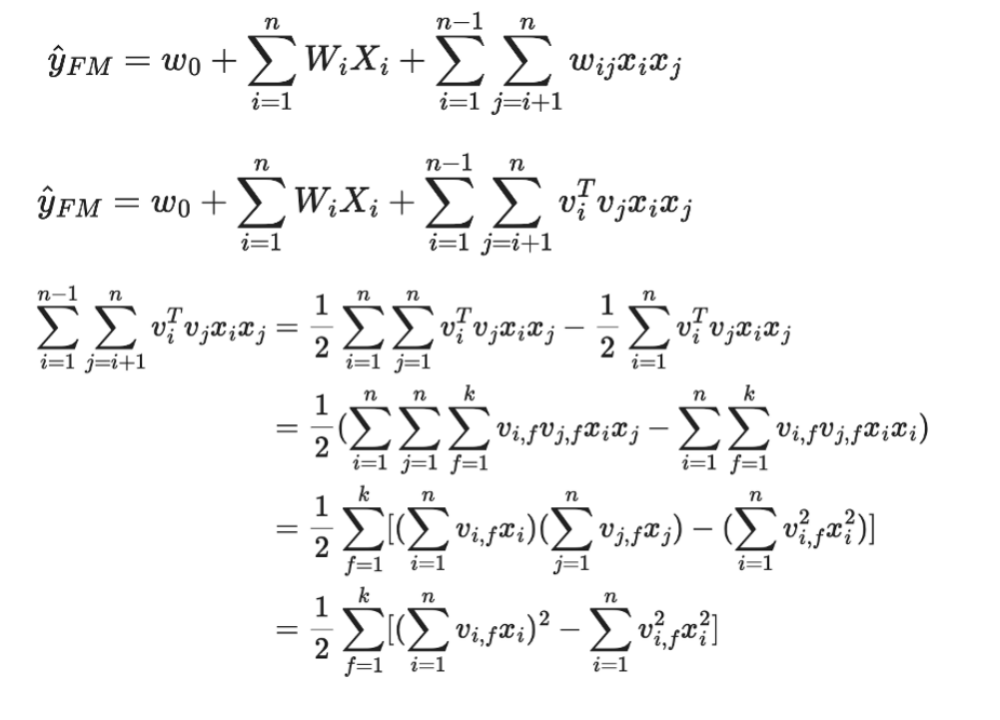
这是一些推倒公式。最上面是 FM 的公式。我们主要看一下下面的右边部分,右边就是交叉的部分,简单理解它就是两两特征之积,前面加一个参数,做个简单变换就可以变成最下面的那行:一些特征和的平方减去所有特征平方的和,也就是平方和公式,A+B 的平方,会变成平方和然后再加上一个交叉项。
我们观察一下这个公式,可以很简单的把它变成双边的东西,第一部分可以变成一阶项减去 1/2 的平方和,第二部分就是直接求和,这两个其实就是统计数据,第一部分是标量值,它不会泄露隐私的信息,第二个值是 K 维的,K 是模型的参数,也是个很小的值,可能就是 4 或者 8 个数字,本身也不会泄露隐私的信息。
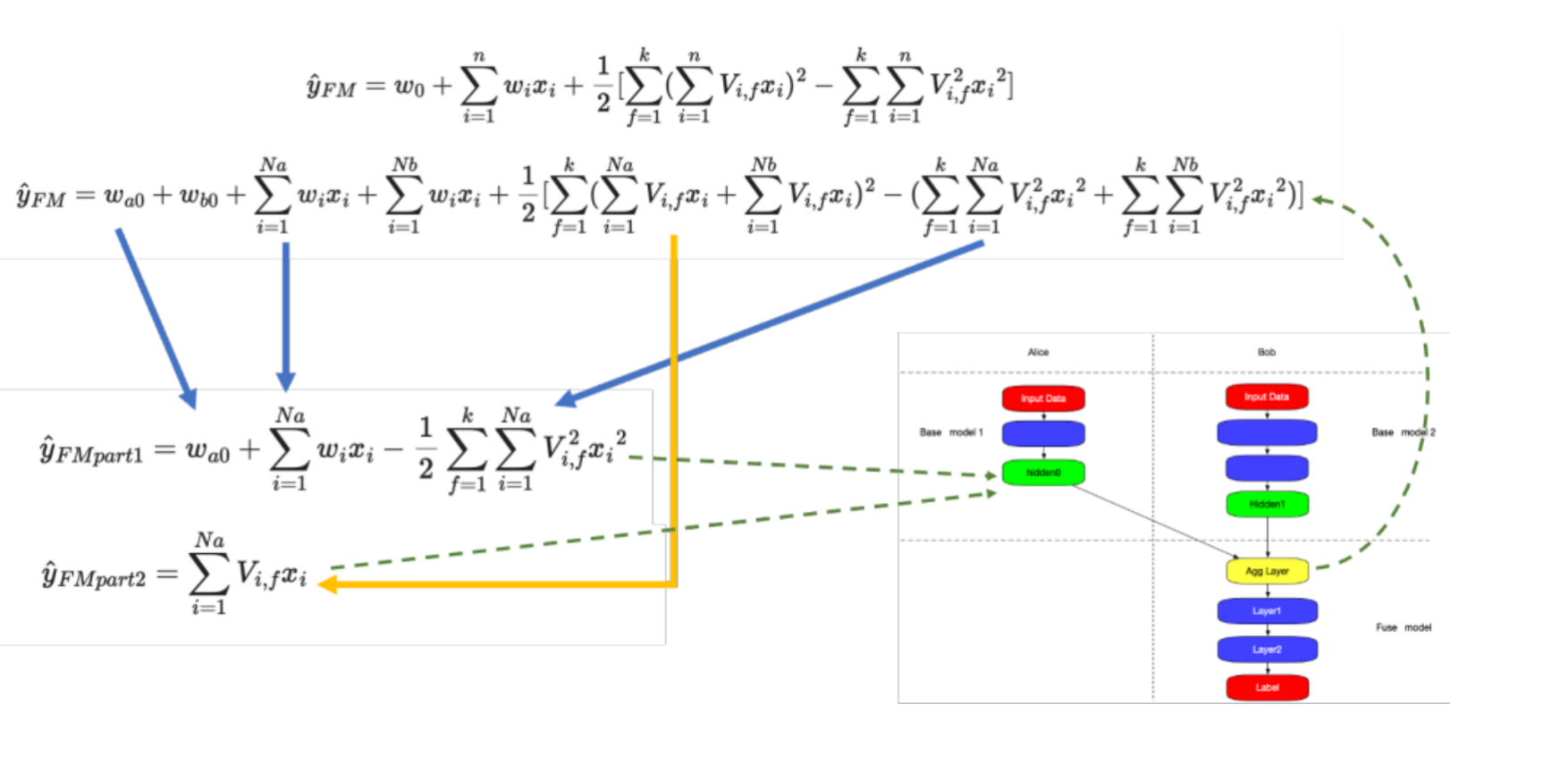
这就相当于在隐层那边算出了这两块东西,把这两块发送到 B 这一方,B 这一方只需要根据上面的公式重构出 y 就可以。这样的过程相当于整个计算既保持了所有的特征都可以做交叉,同时又使得隐私没有被泄露出来,这是以 DeepFM 为例简单介绍一下模型的设计。
DeepFM 模型已经在隐语的仓库中了,后面还会有更多的推荐模型加入,后面如果大家有其他的需求或者其他模型的拆分方案,欢迎大家参与贡献。
性能相关
第三是关于性能相关的。我们知道每个 batch 都需要做通信,做了那么多通信是不是需要确认一下通信是不是会成为瓶颈。原来拆分学习的方案是先做前向的过程,做计算后把隐层 u 传上去,然后在 Server-Side 那边做前向,接下来再做反向的梯度 d ,然后再做更新,整个过程都是串行的,同时中间有两次数据的传递,是会有比较大的性能问题。
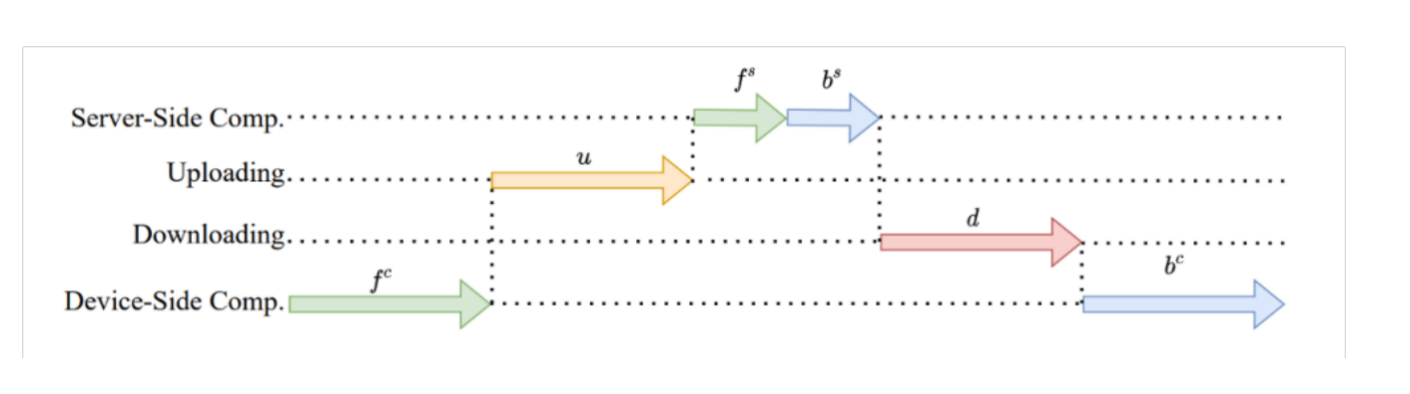
我们拆解来看可以做哪几方面的优化:
带宽:因为有通信,首先想到的是带宽问题,因为很多时候两个公司之间带宽并不会特别高,所以有个想法是减少单次的通信量,例如通过压缩的方法,这边我们也已经实现了稀疏化与量化。在代码仓库里实现了五六种稀疏化与量化方法,可以直接使用。
延迟:还有一个思路是减少通信次数,能不能使 u 和 d 的总次数变小,思路就是能不能让其他的步骤多执行几次,比如说 server-side 的 fs 和 bs 多执行几次,u 和 d 就可以少执行几次。这里面也会设计一些异步拆分的方法,目前也均已实现。
这里也稍微详细介绍一下另外一个方法:流水线并行。可以看到刚刚的流程是完全串行的计算流程,整个计算和带宽都是没有办法打满的。使用流水线计算后,计算流程不会等待所有梯度回传之后更新参数,它会直接进行下一个 batch 计算,整个流水线可以让计算和通信跑的比较满,可以更合理地使用带宽和计算资源。
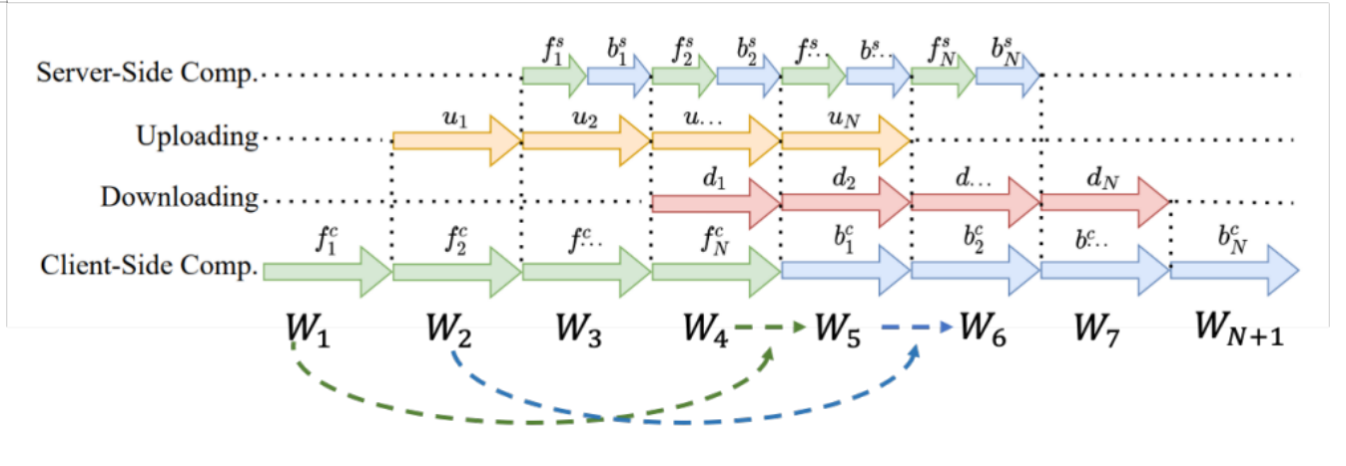
它的参数更新的流程是:
Server 端和以前一样,只需要正常计算前向和后向更新
主要的调整集中在 Client 端。它的更新模式是:一开始的参数是 W1,实际在更新时可能已经到 W5 了,那在拿到梯度时直接更新其实是有问题的,所以我会把之前 W1 的模型参数拿过来,再根据拿到的回传梯度来计算要更新的参数,再把正确的梯度应用到目前的模型参数上,这样往前更新参数,使保证整个过程的参数梯度都用到,参数更新都能更新一次,整个流程可以串起来。
安全性问题
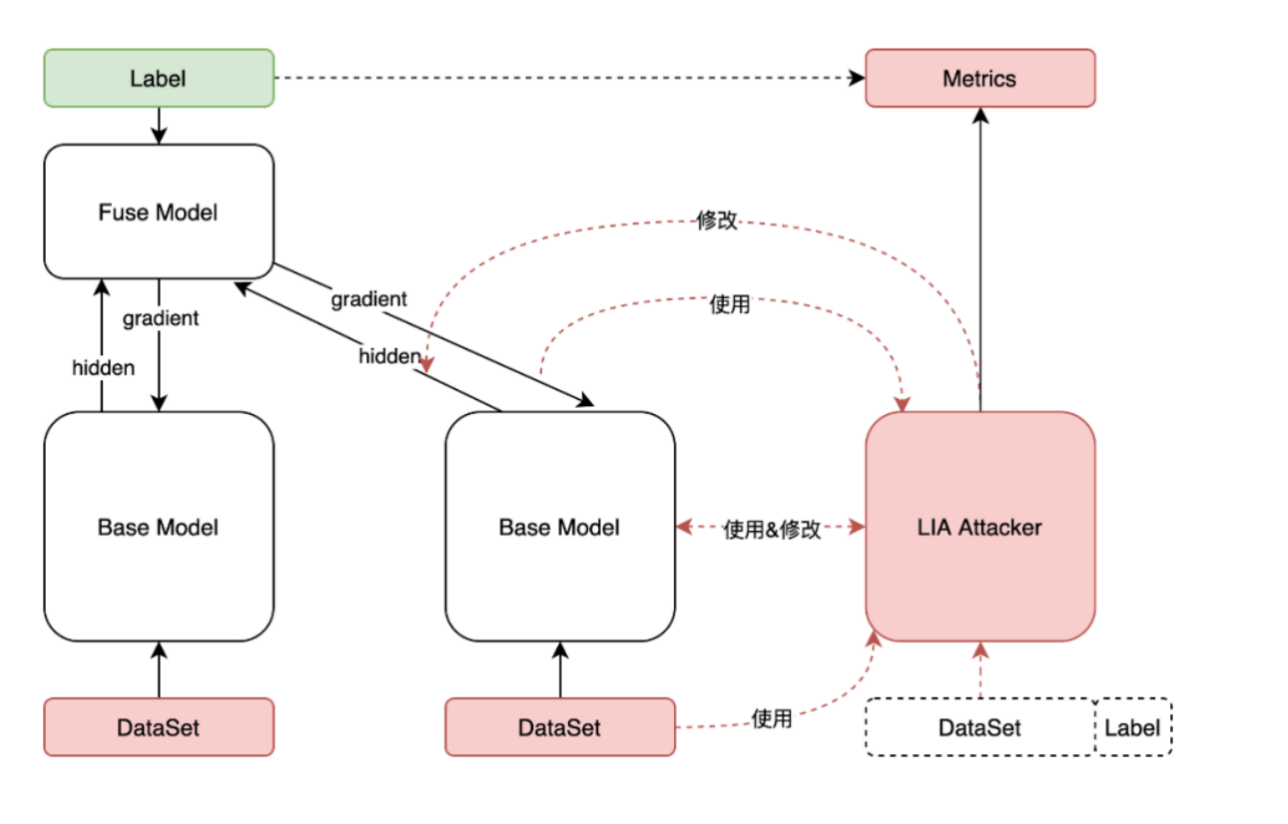
安全性问题其实是个比较大的问题。因为拆分问题中间有信息泄露,所以没办法从密码学或者从数学方式上证明其安全性,所以我们的思路是在攻击和防御的角度看它的安全性:找到一些合理有效的攻击,看其是否能防御住这些攻击。
举个例子,RIA 就是重构攻击。在 Alice 这一方想要重构 Bob 这一方的 Dataset 也就是原始数据,通过传输到的隐层等;对于 Bob 这一方来说可能想要“偷”Alice 这一方的 Lable 也就是标签,也可以通过拿到的梯度等来实现。
这是我们做的攻击框架,希望把所有攻击都集成进去。这块最大的问题是现在攻击和防御,也就是矛和盾都比较弱。我们本身就会在攻击这边做工作,想把真实场景下的攻击变的更有效。
在线服务
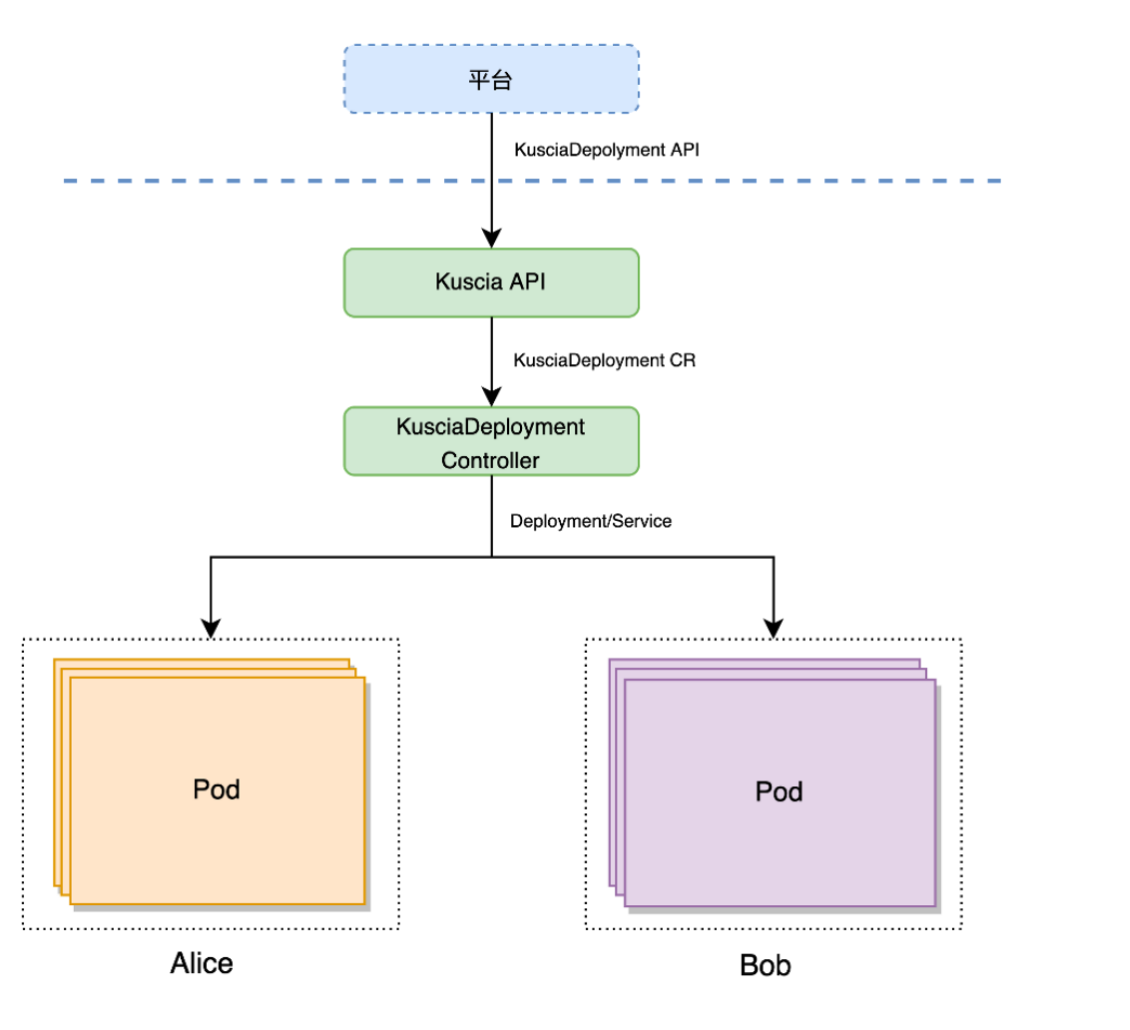
最后是在线服务,是正在进行中的工作,还没有开源出来,大家也可以期待一下,这里简单介绍一下。在线服务实际应用时在两个机构中存在的,所以需要在两个机构这边同时拉起服务,预测时提交一个 ID,两边各自去特征服务那查东西。这里会涉及到一些联合调度的问题,包括跨机构的、高可用的问题。我们还是基于 Kuscia 来实现的,KusciaDeployment 解决来类似 K8s Deployment 的高可用问题,Secretflow-Serving 是专门用来做 Serving 的引擎,后面也会计划开源。
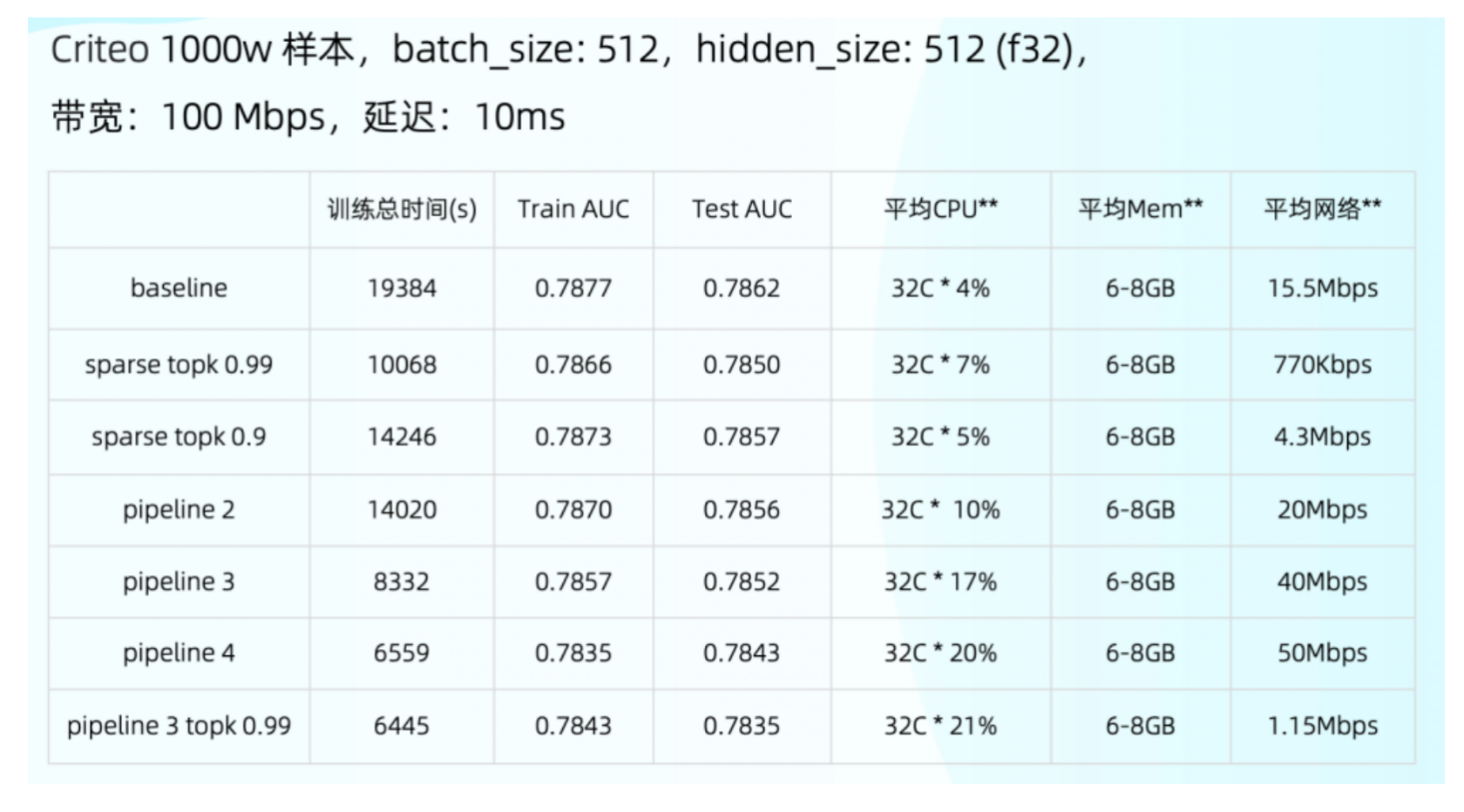
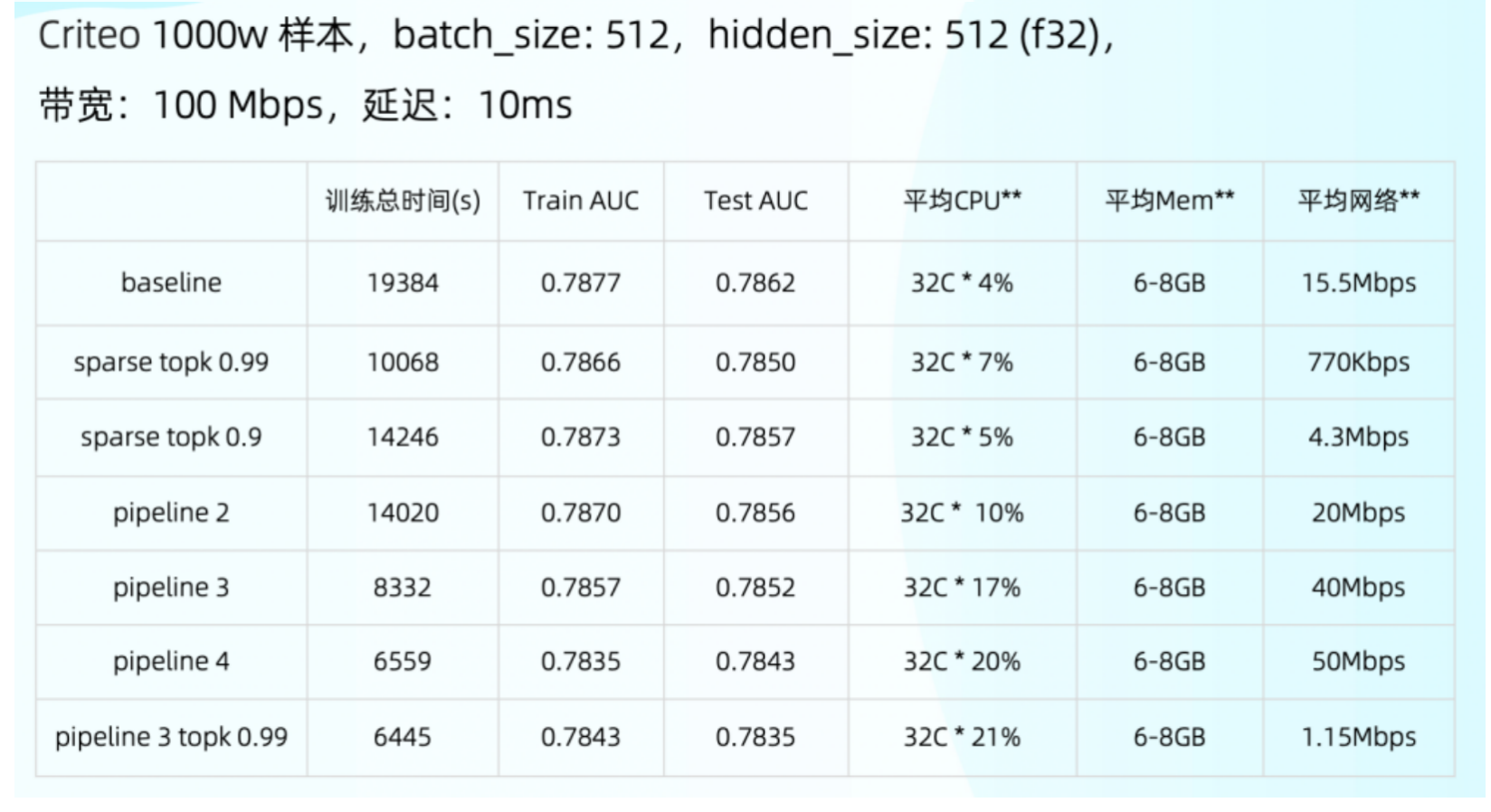
测试数据
最后简单看一下测试数据。这里加上了 sparse topk 和 pipeline,可以看到 pipeline 跟优化前的结果差了 3 倍以上,这个效果是比较好的,在 1000 万数据下这个时间已经是可以直接使用的状态。也可以看到后面的 CPU 和网络还没有完全打满,还存在优化空间。
小结
总结一下,今天讲的所有东西都可以在下方对应链接/ 位置中找到:
数据接入:https://github.com/secretflow/kuscia/tree/main/pkg/datamesh
模型:secretflow.ml.nn.applications
通信优化:
secretflow.ml.nn.sl.backend.tensorflow.strategy
secretflow.utils.compressor
安全:
secretflow.ml.nn.sl.attack
secretflow.security.privacy
如何在 SecretFlow 中使用这些功能
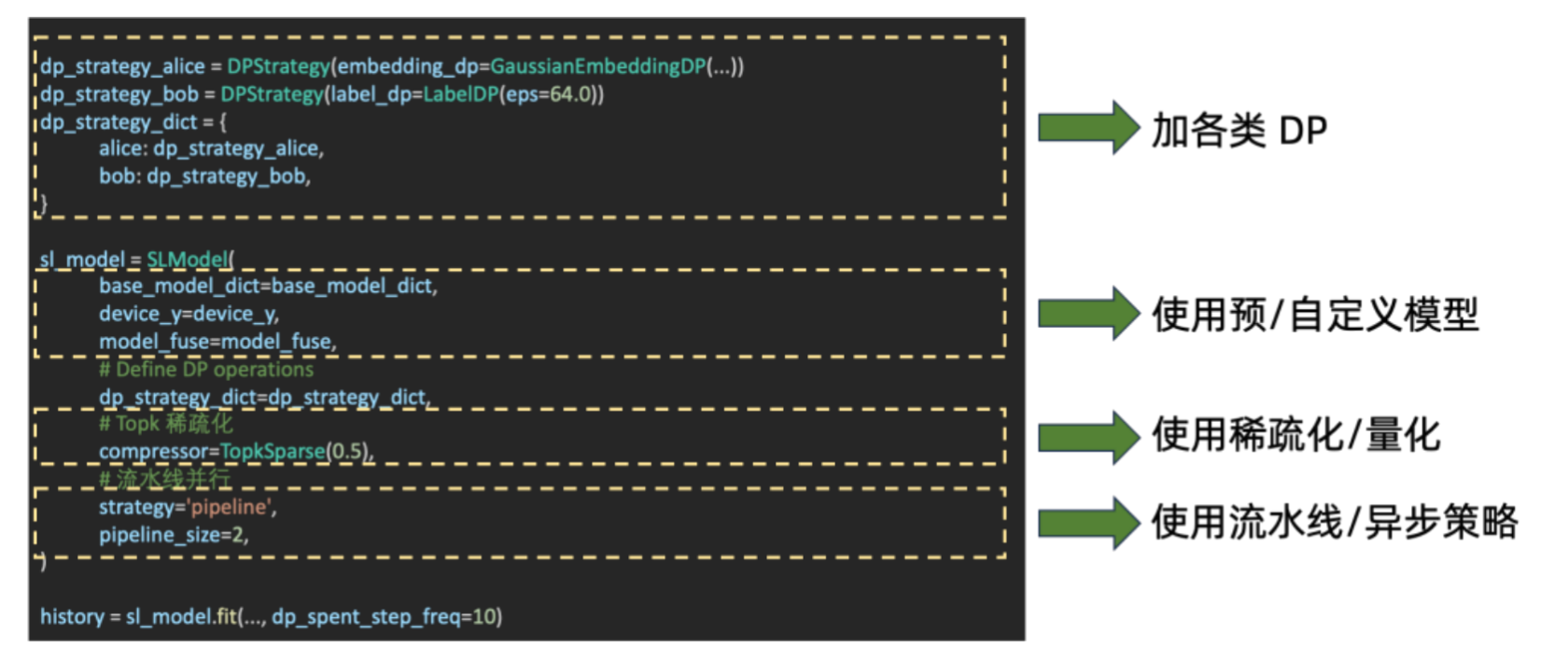
这是拆分学习怎么去训练它的简单事例
首先是可以加一些 DP
模型可以用自定义模型或者内置模型,像刚才分享的 DeepFM 模型
通信优化可以加一些通信的压缩,例如这里用了 Topk 的稀疏化
流水线并行,刚才也提到过了
这块整个加起来就可以把所有的东西串起来,进行训练。
我的分享就到这里,感谢大家。




