
有赞是通过 SaaS 起家的,经过多年的数据沉淀,有大量数据,可以说是一家大数据公司,但是有赞的最终目标是成为 AI 公司。在这个阶段,数据积累到一定体量,数据治理是非常有必要的。数据治理的最终目的也是服务 AI、做智能应用,发挥数据的价值,而质量和成本是数据价值的核心所在。在有赞,是如何衡量质量好坏、成本高低的?又是如何依靠产品,结合运营的手段,提升质量,降低成本的?本文,为你揭晓。
数据治理概述
1. 数据治理是什么
数据:复杂业务场景下,由系统或人沉淀下来的大数据
治:为整治,关注数据质量,保障数据稳定性、准确性,合理控制数据的生命周期,降低成本。
理:为梳理和管理,数据的基本信息、状态、关联关系等,目标是搞清有哪些数据、从哪来到哪去,最终用到什么地方。
2. 有赞是怎么做数据治理的
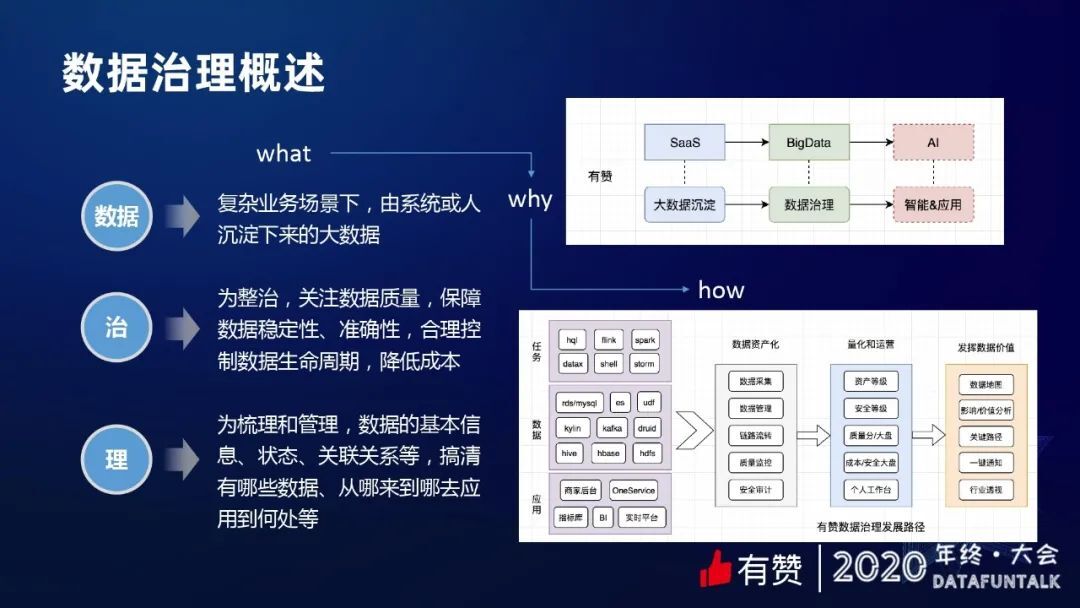
① 数据资产化
通过数据采集、数据管理,然后做各种质量监控和安全审计,把我们各种数据相关的东西当做是数据资产。
② 数据量化和运营
包括衡量资产等级、安全等级,做质量分和成本。让大家直观地感受到数据的质量以及成本是怎样的。然后去构建个人工作台,用户可以知道自己的数据资产有哪些。
③ 发挥数据价值
比如说通过数据地图高效地发现数据,挖掘有效、有价值的数据,然后通过地图的能力做关键路径分析、一键通知、行业透视等。
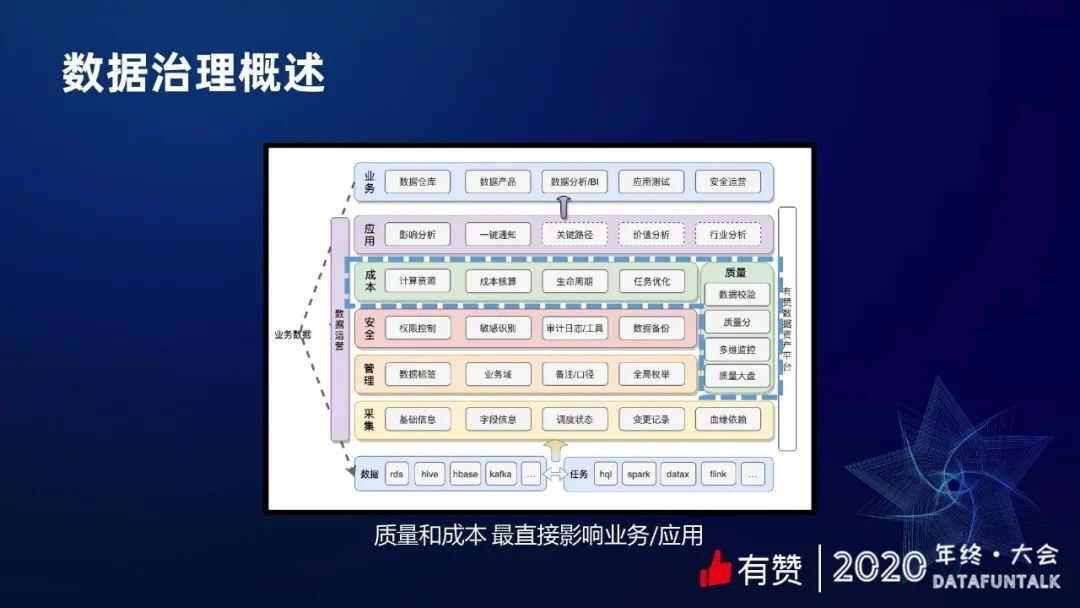
目前有赞的数据治理,处在量化和运营阶段。上图是有赞数据资产平台的简化图,可以看出数据治理涉及到的方方面面。从这个图也可以看出,质量和成本最直接影响业务和应用。
质量保障体系
1. 什么是数据质量
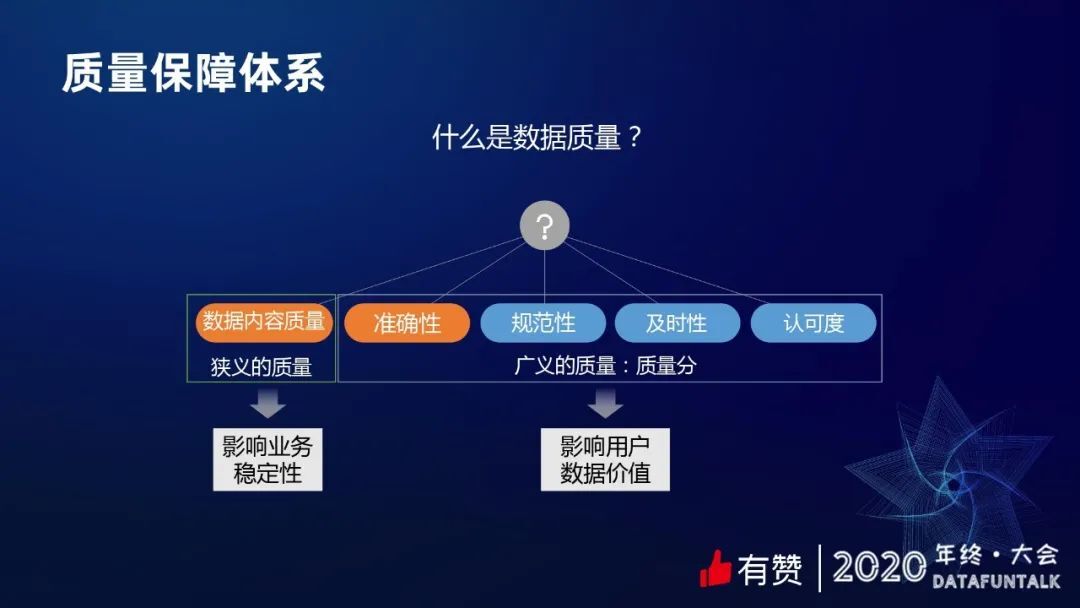
说到数据质量,大家最先涌到脑海的可能是数据内容质量。也就是说,怎么去保证数据内容的准确性,这是比较狭义的质量。质量其实还包括很多方面,比如说准确性、规范性、及时性和认可度,称为广义的质量。我们为广义的质量去做了一个产品,叫质量分。狭义的质量会影响业务的稳定性,比如说哪个数据出错了,比如说商家的 GMV 肯定是不能出错的,出错了会影响业务的稳定。而广义的质量会影响用户,且最终会影响数据价值的挖掘。
2. 内容质量校验
数据和任务强相关,因为数据是由任务加工产出的。所以,内容质量校验也和任务强相关,每个任务完成之后,我们都会对产出的数据做各种质量校验。
质量校验包括两个方面,预定义校验和自定义校验。预定义校验,我们系统自动执行的,不需要人工做任何的配置,包括数据量的波动、文件还有组件唯一性的校验等等。自定义校验需要每个数据 owner 做一些配置,在我们系统上也支持了很多,比如说非空校验、数值范围校验、还支持自定义 SQL 校验。
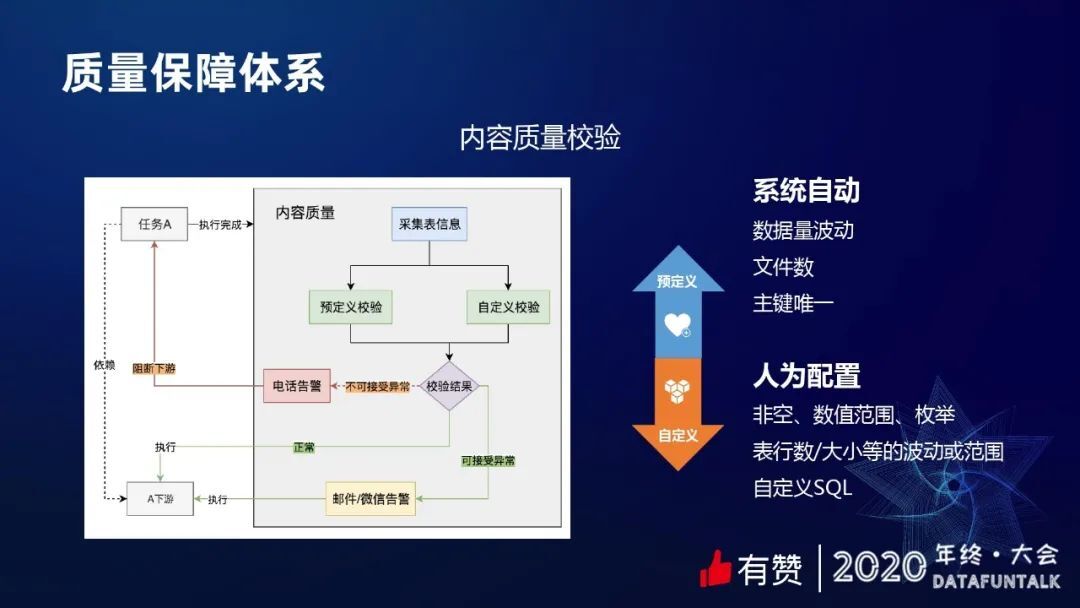
质量校验的结果正常的话,下游任务就可以正常进行;如果是可接受的异常,这时候会触发邮件和企业微信的报警;如果是不可接受的异常,结果数据是有问题的,则阻断下游的任务执行以避免数据资源的浪费,同时触发电话报警,通知相关人去处理。
3. 质量分
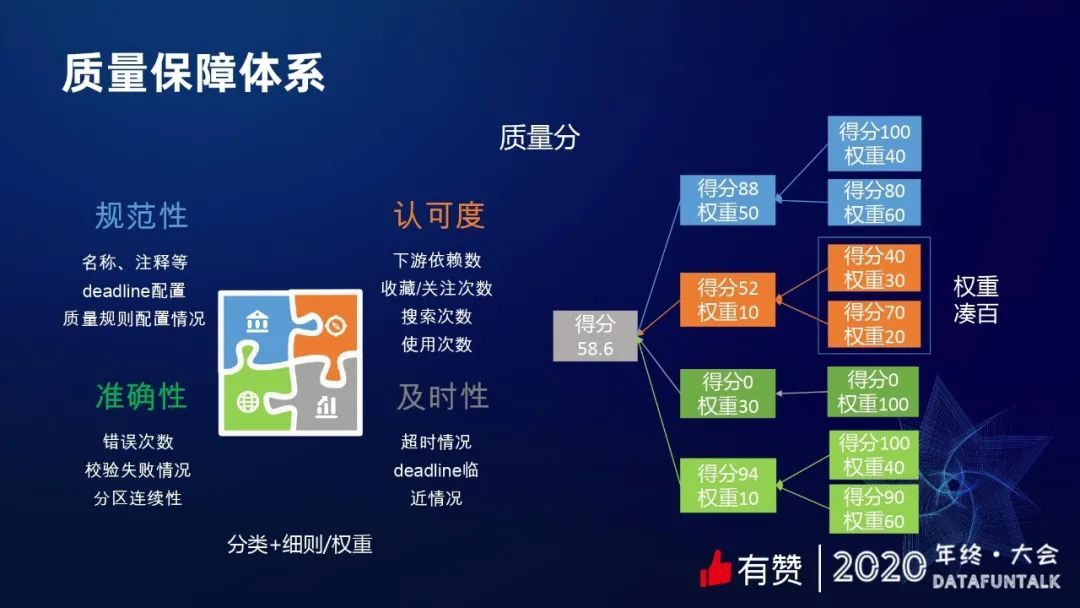
质量分包括:规范性、认可度、准确性以及及时性。规范性很好理解,比如名字规不规范,注释有没有填,必须的质量检验有没有配。认可度要关注数据的使用情况,包括下游依赖情况、搜索、收藏、关注的次数等等。准确性也比较好理解,就是数据的质量校验是不是经常出错,如果经常出错,这个数据可能就有一些问题,不值得信赖;还有数据的分区是不是连续的,是不是有缺失。及时性,我们会去关注数据的超时情况,还有 deadline 临近情况等等。
我们把这四项定义好,确定分类和细则、定义好权重,通过简单的公式就可以算出一个质量分。如下图所示,不同颜色代表不同的分类,最右边是细则的得分以及权重,通过得分加权重的计算方式,就可以最终算出一个数据的总得分。为了模型的可扩展性,有一个小细节,就是权重自动凑百,比如橙色框里的权重,一个是 30 个是 20,总分是 50,实际上算权重的时候,我们会去给它折算到 100。如果加减规则,不需要做很多的调整,权重都能自适应。
4. 提质手段
我们的质量提升手段,是从这几个方面去做的:
第一是预防,就是事前我们会去做 DDL 入口的限制。比如说你的表的命名不规范,或者注释显得不够,或者说该有的属性缺失了,我们会在第一 DDL 的入口去做限制。还有 deadline 预警,每天白天的时候进行检测,并提前发出告警。同时也会去做静态检查,所有的数据、任务变更的时候,都会进行静态检查,提前发现问题。
第二是发现异常,事后任务超时,或者说检验失败的时候,我们会去触发告警,提醒到相关的人。
第三是质量大盘,目的是为了让质量分引起大家的关注,同时在集团大盘里做很多优化的提示,让大家用起来,最终把质量提升上去。
最后是推进优化,其实做完前面那几步,大家可能只是对质量有一个比较明显的感知,但是真正去做质量的提升其实还需要很多运营动作,这就是我们在推进优化这块做的事情。
5. 提质效果
定义完质量分之后,经过一段时间推动,以及大家自觉地做一些提升之后,规范性上,消除了 99%的同义不同名表,业务率和归属率提升到 95%以上。准确性上,消灭了 95%以上的屡败规则,屡败规则指的一些经常失败的数据检验规则,或者最近一段时间经常失败,但是没有人去关注。在做质量分之前,有大量这样的规则存在,不仅是浪费了计算资源,同时也会让告警接收人对异常情况产生麻木情绪,所以说这个收敛是非常有必要的。另外一个指标是失败率,也从 11%降到 1.25%,有比较大的提升。稳定性和技术性,这是我们的一个提质效果。
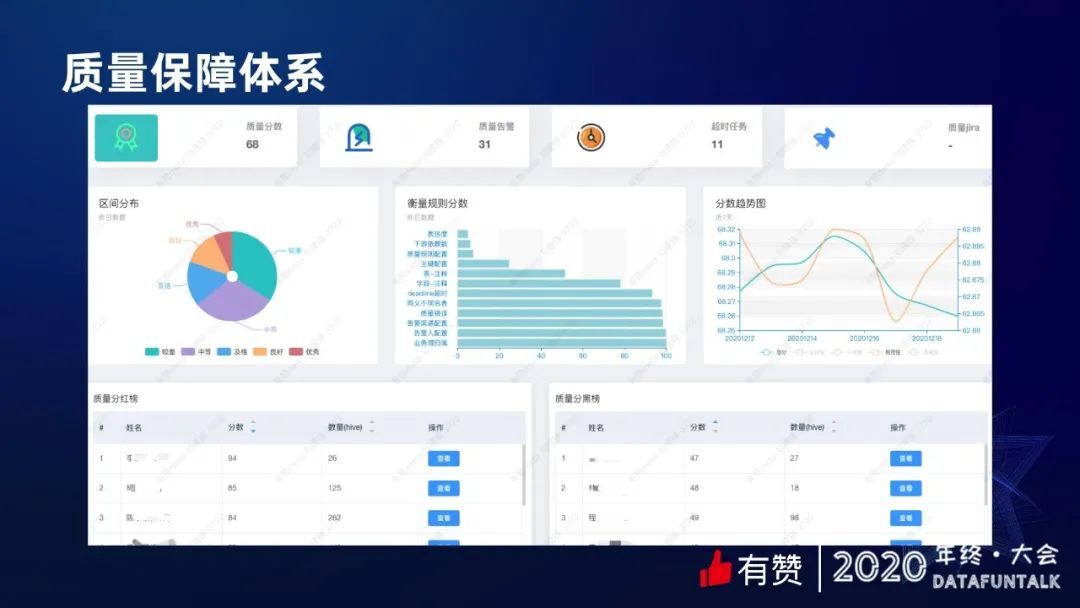
上图是我们的质量大盘,最上边会有几大模块,一个是质量分数,然后是只要告警,还有超时任务,每个模块里面都会有具体的一些细节展现。
降本运营机制
1. 资产成本量化
前面提过数据资产会有很多类型,对于开发人员来讲,他们看到的是一张张表,但是对于管理者或者运维人员,他们看到的是一堆堆机器,这些机器都是有成本的。我们的目标就是把成本分摊到表,让人感受到每张表的成本是多少。
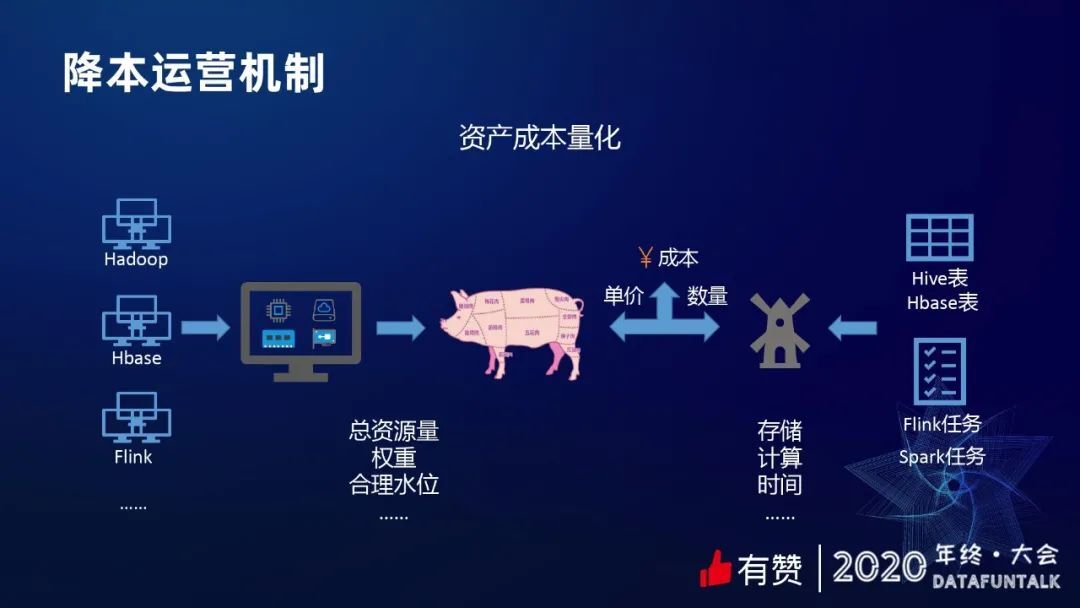
首先,我们对机器资源去做分类,因为机器资源其实就是一堆 CPU、内存和磁盘,不同的资源,也有不同的稀缺性,我们需要对每种资源定价。就跟一头猪的不同部位,价格是不一样的,因为它们的稀缺性是不一样的。
从表的角度去看,每个表的产出都对应一个任务,同时也对应一些存储,它们占用计算资源和存储资源。我们大的思路就是对每一类资源去做一个定价,形成一个单价,然后采集到每个表占用的资源的量。单价乘以数量,就是成本。
数据成本是由资源单价和消耗资源这两个最关键因素决定的。
资源单价有四个方面:总成本、资源总量、稀缺性和合理水位。下面分别解释一下:
对于离线计算,比如 Hadoop 集群的总成本是多少,它的资源总量是多少,我们最关心的是 CPU 和内存资源,这是我们是可以采集到的。
稀缺性,可以从资源瓶颈的角度来考量,对于离线计算,CPU 会比内存更稀缺。
合理水位,是说为了保证性能和稳定性,资源的负载需要维持在一定水平。比如 CPU,我们不可能把它用满,可能用到 80%左右就到极限了,再往上就是非常危险的状态。所以说我们去算有效资源的时候,不会按资源真正的总量去算,而是按它的总量去乘以合理水位计算的。合理水位因不同的数据而异,需要具体去分析确定。
消耗资源有三个方面,存储和计算比较好理解。时间怎么理解?以离线计算为例,大多数离线计算场景可能都是 T+1 的,然后大家可能也能感受到凌晨的时候资源是非常稀缺的,但是白天的时候往往是空闲的。所以凌晨的时候资源应该是贵一点的,白天的时候稍微便宜一些。我们去采集计算资源的时候,也会去考虑任务的计算资源占用的时间段。在凌晨我们会去给他打一个系数,比如说 1.3、1.5,但在白天我们会给他一个折扣,比如 0.6、0.8。
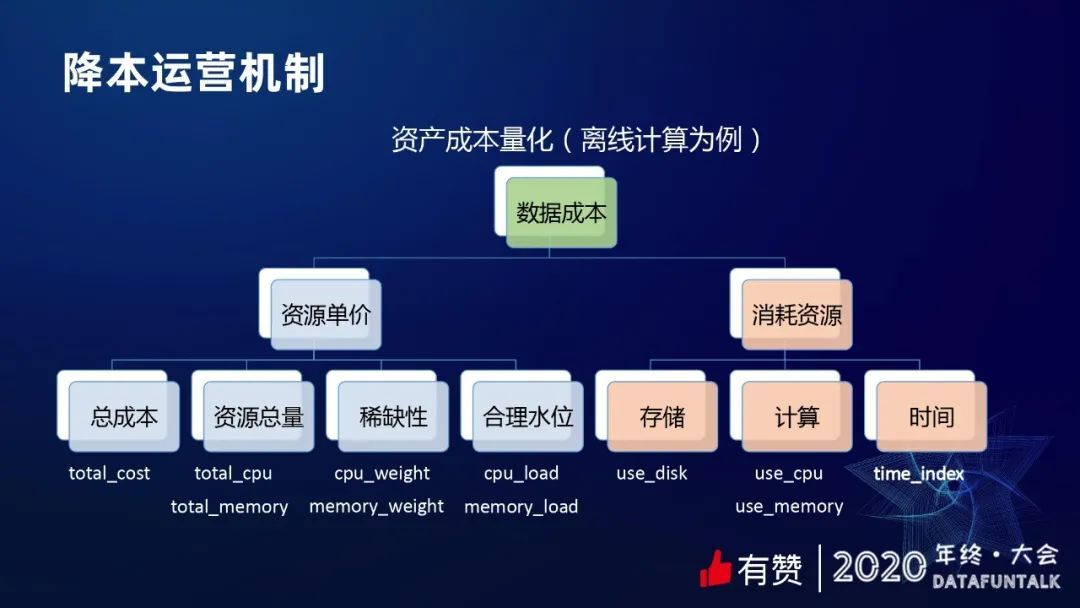
按照上面的原理很容易得出一个计算公式,每个 CPU 的单价是多少,内存单价是多少,然后采集到使用到的资源数据,就可以算出数据的成本。
cpu 单价,cpu_price = total_cost * cpu_weight / (total_cpu * cpu_load)
内存单价,memory_price = total_cost * memory_weight / (total_memory * memory_load)
任务成本,cost = cpu_price * use_ cpu + memory_price * use_memory + disk_price * use_disk
2. 成本账单建设
成本量化之后,只是有了一个比较直观的成本数据。为了让各个层级的人都能直观的去看他们有多少数据、成本分布以及趋势是怎样的,我们做了成本账单,支持了三大类能力。
第一是分析,支持全类型多视角、灵活的分析,有三类分析手段、有多种降本的方式、有五维视图。五维视图指的是说个人的、部门的、业务域的、业务线的以及全局视角的成本,都可以看。此外,账单也支持钻取、级联和趋势分析。因为大家看账单的时候,可能不光只想看到一个数。如果我看到这个数差距特别大,或者说我们这个波动特别明显,就要去分析为什么会出现这种情况,所以需要支持很多分布分析、下钻分析、甚至展现一些成本的细节。
第二是降本,给大家看到成本之后,希望说大家做一些降本的工作,减少浪费。所以我们也做了很多降本的挖掘,包括怎么挖出哪些数据可以下线、哪些数据可以做延迟启动。延迟就跟上面我们讲的运行时间段有关,比如不重要的任务,不一定要在凌晨的时候跟那些高优先级的任务抢占资源,可以把它挪到白天的时候执行,这样我们在算成本的时候会给一些折扣,这也算是降本的一种方式。还有很多任务,可能是小时级、甚至分钟级调度的,小时调度的任务,一天跑 24 次,它成本就是每天调度任务的 24 倍。实际有没有必要?未必,通过我们的调研发现存在很多这样的人物,是可以做调度周期的优化。此外,还有一些调优的具体手段,怎么去避免数据倾斜,怎么去减少数据量的使用等等。
第三是我们把账单算到业务线上。数据中台在很多人看来是一个成本大户,消耗了资源,但是离业务比较远,很难讲出价值。但其实我们消耗的资源都是为业务服务的,所以我们要想办法把成本也分摊到业务线,让业务线也关注到,原来在创造价值的同时,其实也消耗了这么多成本。
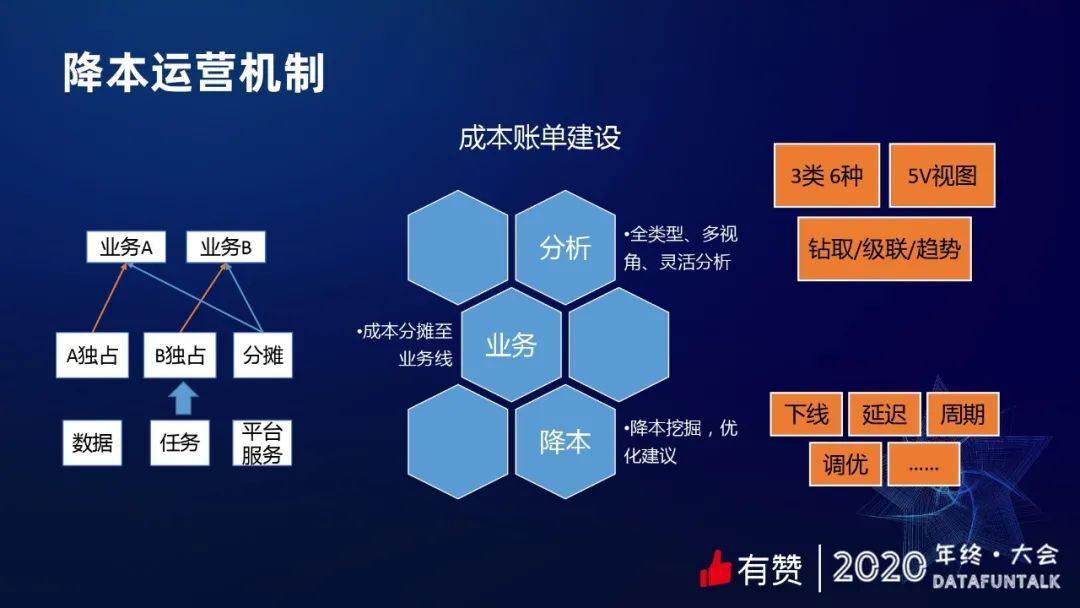
上图是分摊业务线的大致逻辑,底层是数据、任务和平台服务。成本有两类,独占成本和分摊成本。独占成本就是有些集群平台或者任务就是为某个业务服务的,这些成本全部归到业务。分摊成本,比如说数仓中间层,它的订单交易或者店铺可能有很多业务线都用到了,数仓去建立这些能力需要的成本,就需要分摊到这些业务线。
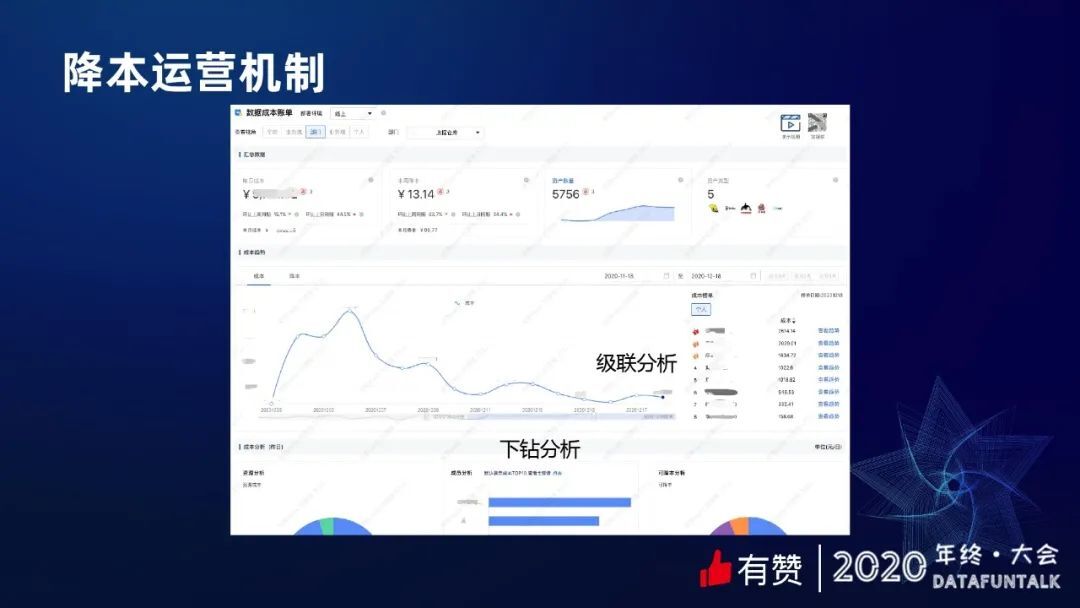
上图是数据成本账单的截图,这是一个部门视角,每个部门都可以看到自己成本是怎么样的,部门视角可以看到部门里边每个人的成本情况。最上面是一些数据指标的概览,可以看到我的成本情况、降本情况、资产的数量。然后中间是成本的趋势,在趋势图的每一个点都可以点击,右侧会有成本的榜单分析。比如说我看到 12 月 6 号成本特别高,点一下就可以在右边看具体的成本是怎么样的。最下边是成本分析模块,我们可以看到成本分布。分成平台的成本、表的成本、还有各种各样的成本的分类,同时也支持按成员去分析它的成本。比如说条形图,它其实是可以点击下钻看某个具体的人,有哪些表。右下角的模块是一个可降本分析,上面讲过给他们看成本,是希望他们去做降本的事情,所以很多挖掘降本的点也在平台上去支持。
3. 成本分摊
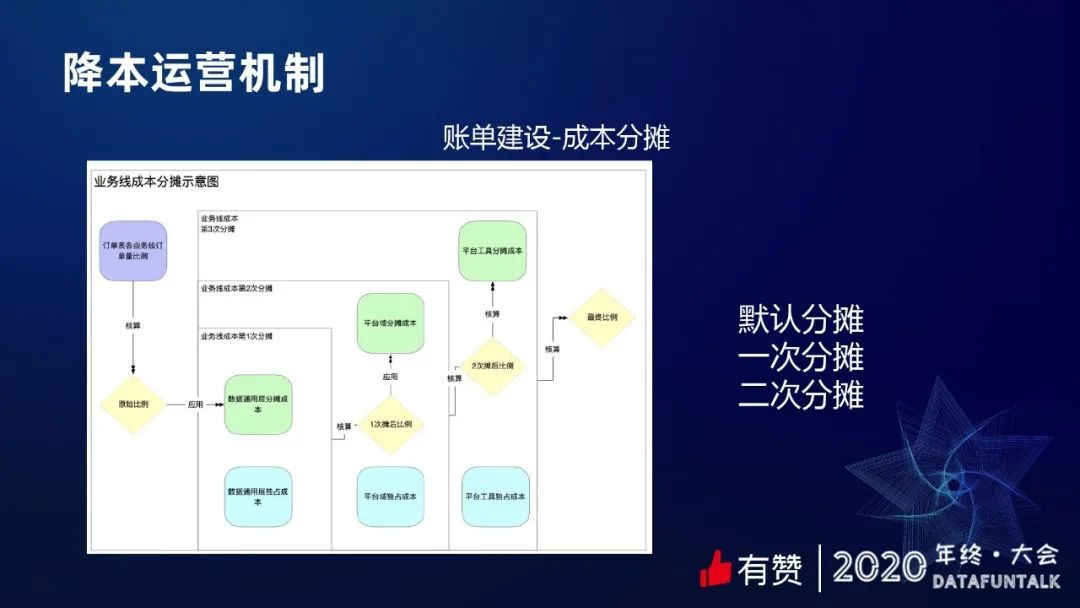
在成本分摊的时候,怎么做默认的分摊,怎么设置分摊的比例?大概的过程三步,首先设定一个默认的分摊比例,按照各个业务线的订单量算比例,算是默认分摊比,这个数据通用层的分摊,加上一些独占的成本的分摊,会生成第二个比例。然后再结合平台域的分摊成本生成第三个比例。最后我们再把平台工具独占成本结合进去,形成了一个最终的比例。
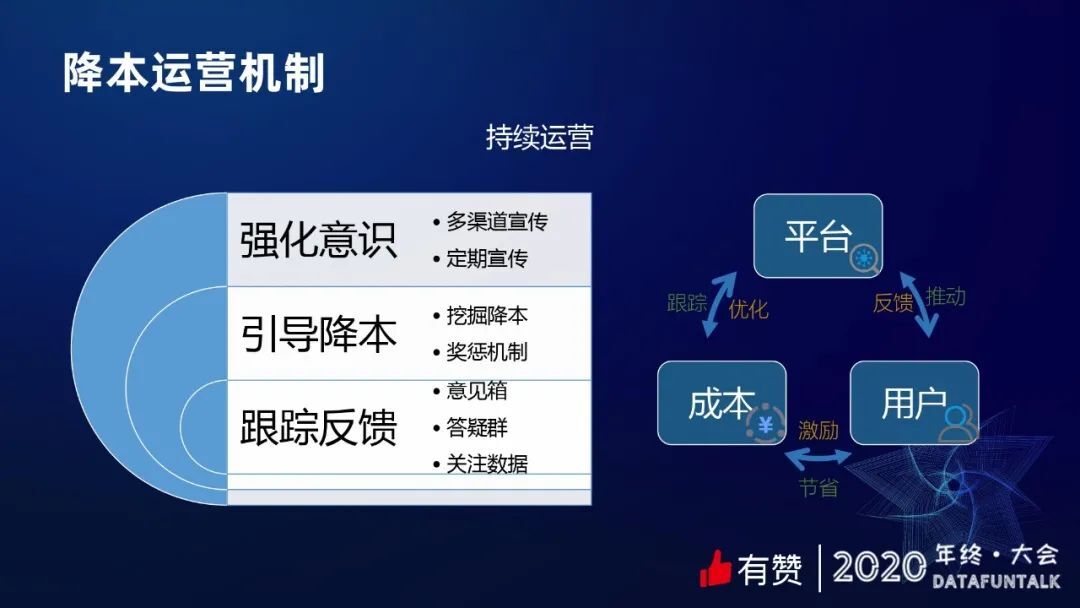
4. 持续运营
建了很多规范后,计算出质量分、成本、账单,但如果不运营是很难把这个事情跑起来的。因为大家对这个东西的感觉不深,也没有特别强的动力,所以我们也做了很多运营的事情。
① 强化意识
我们从多渠道进行成本意识的宣传,比如每次上线产品通过海报或者小视频,进行产品宣传,告诉大家用法,鼓励大家多去使用。还有上文提到的,挖掘出一些改进的空间给到大家,让大家很明确的就可以去做一些事情。
② 奖惩机制
有赞内部有一个“有赞币”文化,可以把有赞币送给自己欣赏的人、或者帮助到自己的人,给他们一些鼓励。
③ 跟踪反馈
比如说意见箱、答疑群,还有怎么关注降本的一些实际的数据等等。
这些事情其实是平台围绕着用户,为降本去做事情的,运营的目的是为了让平台用户和成本之间形成一个良性的互动。我们通过运营去推动用户去做降本的事情,跟踪这些动作同时反馈在平台上面,这样的话就形成了一个正向的循环,最终达到一个比较好的降本效果。
5. 运营成绩

经过大半年的努力,我们也有一些小小的成绩。上图是实际运营的数据情况,第一个参与用户,是说目前有成本的用户中,超过 32%的用户采取了降本相关动作。降本动作累计有 1400 多次,并且自主降本的比例超过了 38%,这个也反映出大家对成本的意识已经有非常大的提升。在做这个事情过程中,我们也清理了超过 2P 的数据、下线超过 300 个任务,在成本方面每年节省了 300 多万。
总结与展望
质量成本,其实是围绕着量化、产品以及运营这三个方面进行的,这也是数据治理的三辆马车。量化是为了让大家更直观地感受到当前的质量、成本现状,有哪些问题。让大家了解之后需要通过产品作为载体去支持大家做降本以及分析的需求。有了产品之后,还需要通过有效的运营手段,把这一套降本机制,以及提升大家成本意识的意图,给跑起来,最终形成一个良性的循环。
成本和质量的发展方向,如下图:
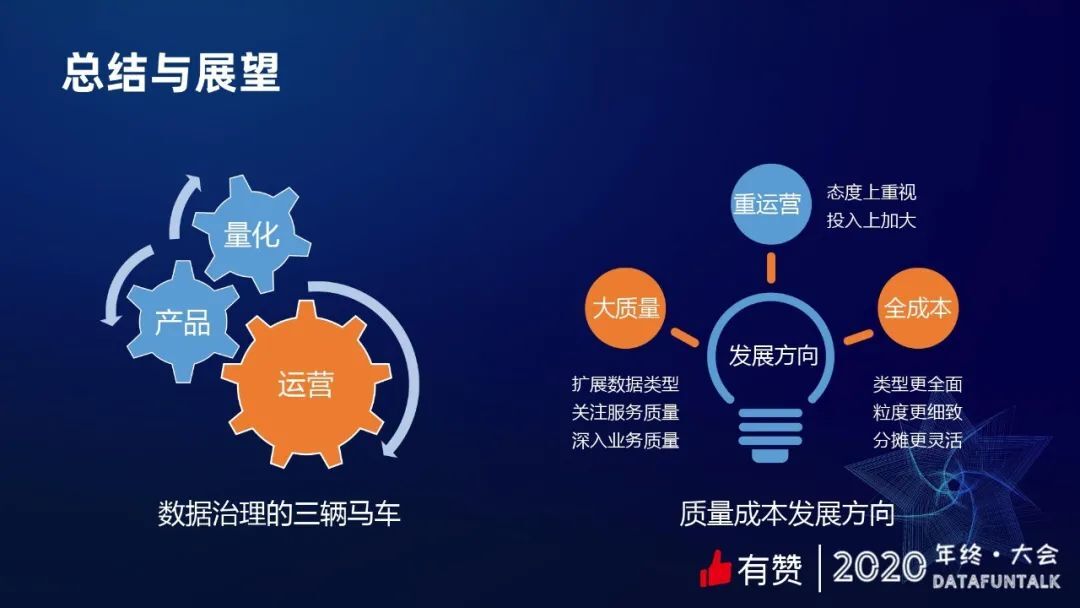
1. 大质量
首先,我们目前的质量主要集中在离线表,我们可以去扩展数据类型(实时数据,如 Kafka;在线数据,如 Hbase)。其次是服务的质量,我们现在有很多数据相关的平台系统,它们的服务稳定性、效率延迟是怎么样的?其实是没有统一关注的,这块也需要关注起来。最后是深入业务质量,包括线上服务,比如商家后台,它的服务的稳定性,接口的延迟等等。这些就是大质量。
2. 全成本
我们的成本已经做得很全了,各种各样的数据类型平台、成本都做到了量化、以及能做到成本账里面去了。但是还有一些更上游的 MySQL 表等等,这些还没有去做量化,也可以去做扩展,然后力度更细致,分摊更灵活。
3. 重运营
我们已经意识到运营是成本治理达到较好的效果必不可少的,而且应该是加大投入的一个环节,我们首先要从态度上重视,继续加大投入。
最后送给大家一句话,也是我们团队比较喜欢的一句话:高质量,低成本,让数据更有价值。
嘉宾介绍:
刘建锋
有赞科技 | 数据治理负责人
曾先后任职于百度、阿里,目前在有赞负责有赞大数据治理工作。在元数据管理、数据安全、质量、血缘、成本等方面,有深入的研究和实践。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:有赞数据治理之提质降本




