
在 AI 绘画领域,阿里提出的 Composer 和斯坦福提出的基于 Stable diffusion 的 ControlNet 引领了可控图像生成的发展。但是,业界在可控视频生成上的探索依旧处于相对空白的状态。相比于图像生成,可控的视频更加复杂,除了视频内容的空间的可控性之外,还需要满足时间维度的可控性。而现在,阿里巴巴和蚂蚁集团的研究团队率先做出了尝试,提出 VideoComposer,即通过组合式生成范式同时实现视频在时间和空间两个维度上的可控性。
论文地址:https://arxiv.org/abs/2306.02018

项目主页:https://videocomposer.github.io
前段时间,阿里巴巴在魔搭社区和 Hugging Face 低调开源了文生视频大模型,但迅速受到国内外开发者的广泛关注,而该模型生成的视频甚至得到马斯克本尊的回应,该模型在魔塔社区上连续多天获得单日上万次国际访问量(主页地址)。
Text-to-Video 在推特
VideoComposer 作为该研究团队的最新成果,毫无悬念再次受到国际社区的广泛关注。


VideoComposer 在推特
事实上,可控性已经成为视觉内容创作的更高基准,其在定制化的图像生成方面取得了显着进步,但在视频生成领域仍然具有三大挑战:
复杂的数据结构,生成的视频需同时满足时间维度上的动态变化的多样性和时空维度的内容一致性;
复杂的引导条件,已存在的可控的视频生成需要复杂的条件是无法人为手动构建的。比如 Runway 提出的 Gen-1/2 需要依赖深度序列作条件,其能较好的实现视频间的结构迁移,但不能很好的解决可控性问题;
缺乏运动可控性,运动模式是视频即复杂又抽象的属性,运动可控性是解决视频生成可控性的必要条件。
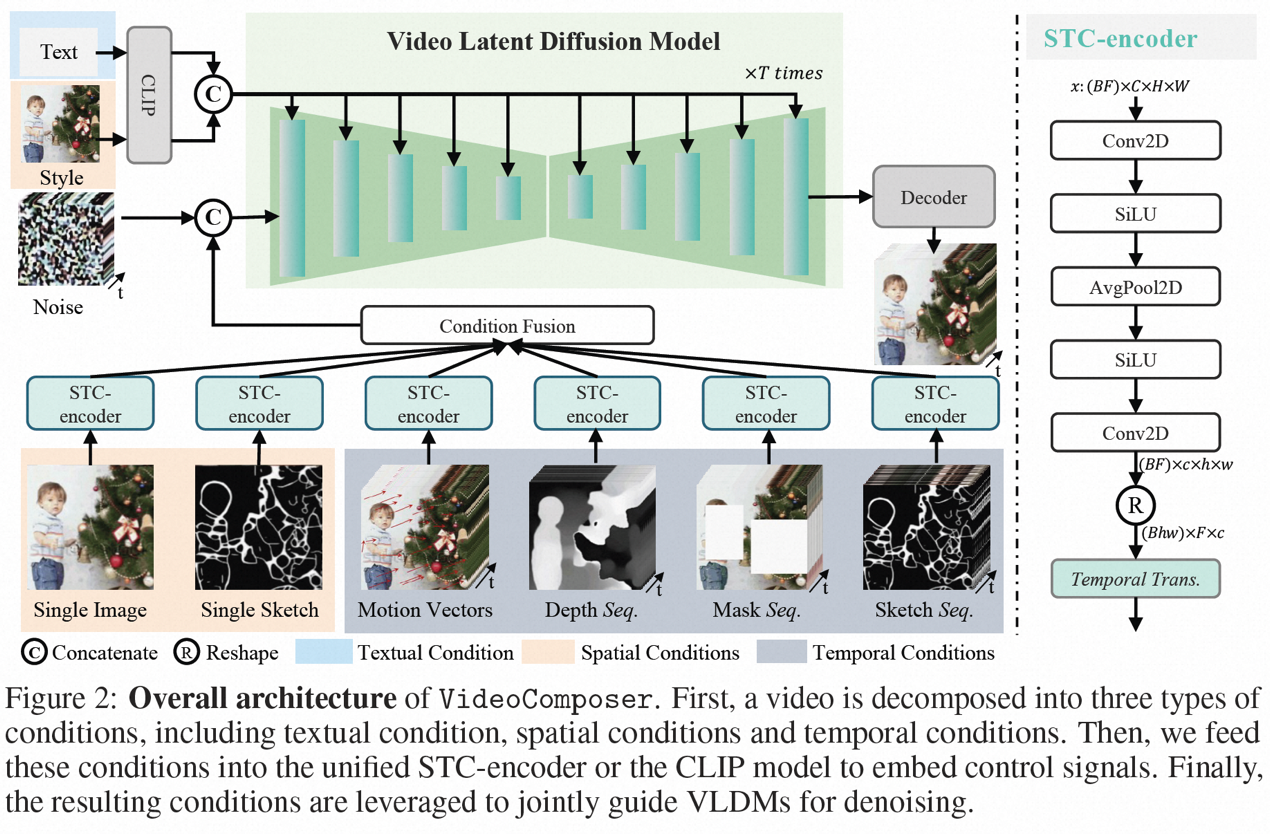
在此之前,阿里巴巴提出的 Composer 已经证明了组合性对图像生成可控性的提升具有极大的帮助,而 VideoComposer 这项研究同样是基于组合式生成范式,在解决以上三大挑战的同时提高视频生成的灵活性。具体是将视频分解成三种引导条件,即文本条件、空间条件、和视频特有的时序条件,然后基于此训练 Video LDM (Video Latent Diffusion Model)。特别地,其将高效的 Motion Vector 作为重要的显式的时序条件以学习视频的运动模式,并设计了一个简单有效的时空条件编码器 STC-encoder,保证条件驱动视频的时空连续性。在推理阶段,则可以随机组合不同的条件来控制视频内容。
实验结果表明,VideoComposer 能够灵活控制视频的时间和空间的模式,比如通过单张图、手绘图等生成特定的视频,甚至可以通过简单的手绘方向轻松控制目标的运动风格。该研究在 9 个不同的经典任务上直接测试 VideoComposer 的性能,均获得满意的结果,证明了 VideoComposer 通用性。
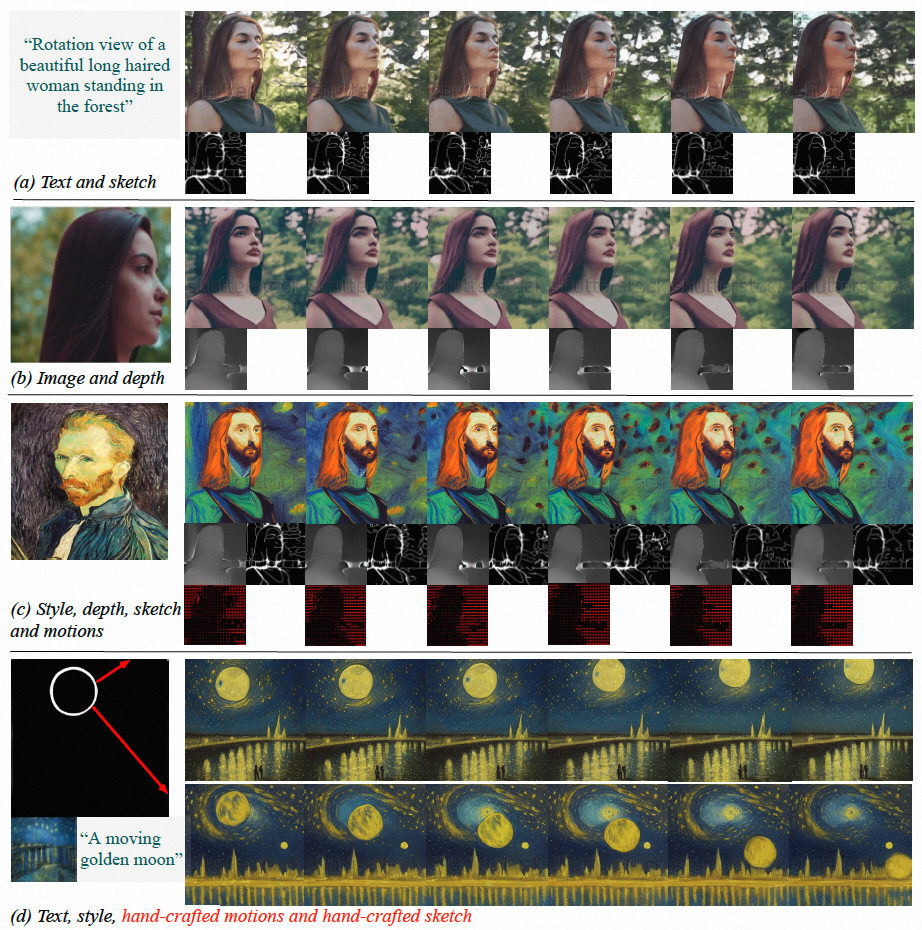
图(a-c)VideoComposer 能够生成符合文本、空间和时间条件或其子集的视频;(d)VideoComposer 可以仅仅利用两笔画来生成满足梵高风格的视频,同时满足预期运动模式(红色笔画)和形状模式(白色笔画)
方法介绍
Video LDM
隐空间。Video LDM 首先引入预训练的编码器将输入的视频$x\varepsilon \mathbb{R}^{F\times H\times W \times 3}$映射到隐空间表达$z=\mathcal{E}(\boldsymbol{x})$,其中$z\varepsilon \mathbb{R}^{F\times h\times w \times c}$。然后,在用预先训练的解码器 D 将隐空间映射到像素空间上去$\overline{\boldsymbol{x}}=\mathcal{D}(\boldsymbol{z})$。在 VideoComposer 中,参数设置$H\setminus h= W\setminus w= 8$。
扩散模型。为了学习实际的视频内容分布$P \left( x \right)$,扩散模型学习从正态分布噪声中逐步去噪来恢复真实的视觉内容,该过程实际上是在模拟可逆的长度为 T=1000 的马尔可夫链。为了在隐空间中进行可逆过程,Video LDM 将噪声注入到$z$中,得到噪声注入的隐变量$z_{t}$。然后其通过用去噪函数$\epsilon_{\theta}(\cdot, \cdot, t)$作用在
$z_{t}$和输入条件 c 上,那么其优化目标如下:
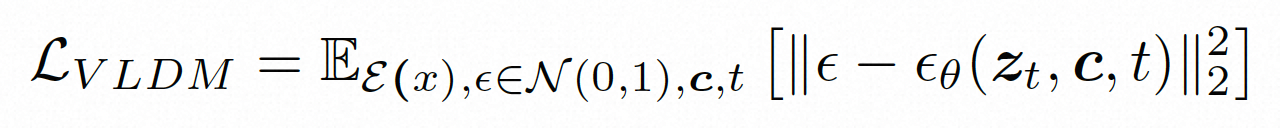
为了充分探索利用空间局部的归纳偏置和序列的时间归纳偏置进行去噪,VideoComposer 将$\epsilon_{\theta}(\cdot, \cdot, t)$实例化一个 3D UNet,同时使用时序卷积算子和交叉注意机制。
VideoComposer
组合条件。VideoComposer 将视频分解为三种不同类型的条件,即文本条件、空间条件和关键的时序条件,它们可以共同确定视频中的空间和时间模式。VideoComposer 是一个通用的组合式视频生成框架,因此,可以根据下游应用程序将更多的定制条件纳入 VideoComposer,不限于下述列出的条件:
文本条件:文本(Text)描述以粗略的视觉内容和运动方面提供视频的直观指示,这也是常用的 T2V 常用的条件;
空间条件:
单张图(Single Image),选择给定视频的第一帧作为空间条件来进行图像到视频的生成,以表达该视频的内容和结构;
单张早图(Single Sketch),使用 PiDiNet 提取第一个视频帧的草图作为第二个空间条件;
风格(Style),为了进一步将单张图像的风格转移到合成的视频中,选择图像嵌入作为风格指导;
时序条件:
运动矢量(Motion Vector),运动矢量作为视频特有的元素表示为二维向量,即水平和垂直方向。它明确地编码了相邻两帧之间的逐像素移动。由于运动矢量的自然属性,将此条件视为时间平滑合成的运动控制信号,其从压缩视频中提取标准 MPEG-4 格式的运动矢量;
深度序列(Depth Sequence),为了引入视频级别的深度信息,利用 PiDiNet 中的预训练模型提取视频帧的深度图;
掩膜序列(Mask Sequence),引入管状掩膜来屏蔽局部时空内容,并强制模型根据可观察到的信息预测被屏蔽的区域;
草图序列(Sketch Sequnce),与单个草图相比,草图序列可以提供更多的控制细节,从而实现精确的定制合成
时空条件编码器。序列条件包含丰富而复杂的时空依赖关系,对可控的指示带来了较大挑战。为了增强输入条件的时序感知,该研究设计了一个时空条件编码器(STC-encoder)来纳入空时关系。具体而言,首先应用一个轻量级的空间结构,包括两个 2D 卷积和一个 avgPooling,用于提取局部空间信息,然后将得到的条件序列被输入到一个时序 Transformer 层进行时间建模。这样,STC-encoder 可以促进时间提示的显式嵌入,为多样化的输入提供统一的条件植入入口,从而增强帧间一致性。另外,该研究在时间维度上重复单个图像和单个草图的空间条件,以确保它们与时间条件的一致性,从而方便条件植入过程。
通过 STC-encoder 处理条件后,最终的条件序列具有与$z_{t}$相同的空间形状,然后通过元素加法融合。最后,沿通道维度将合并后的条件序列与$z_{t}$连接起来作为控制信号。对于文本和风格条件,利用交叉注意力机制注入文本和风格指导。
训练和推理
两阶段训练策略。虽然 VideoComposer 可以通过图像 LDM 的预训练进行初始化,其能够在一定程度上缓解训练难度,但模型难以同时具有时序动态感知的能力和多条件生成的能力,这个会增加训练组合视频生成的难度。因此,该研究采用了两阶段优化策略,第一阶段通过 T2V 训练的方法,让模型初步具有时序建模能力;第二阶段在通过组合式训练来优化 VideoComposer,以达到比较好的性能。
推理。在推理过程中,采用 DDIM 来提高推理效率。并采用无分类器指导来确保生成结果符合指定条件。生成过程可以形式化如下:
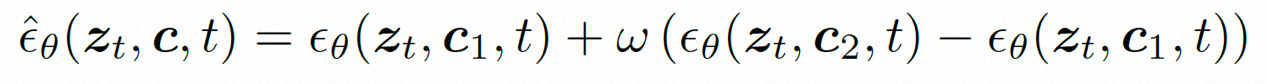
其中,ω是指导比例;c1 和 c2 是两组条件。这种指导机制在两条件集合判断,可以通过强度控制来让模型具有更加灵活的控制。
实验结果
在实验探索中,该研究证明作为 VideoComposer 作为统一模型具有通用生成框架,并在 9 项经典任务上验证 VideoComposer 的能力。
此处为语雀视频卡片,点击链接查看。
生成视频集合
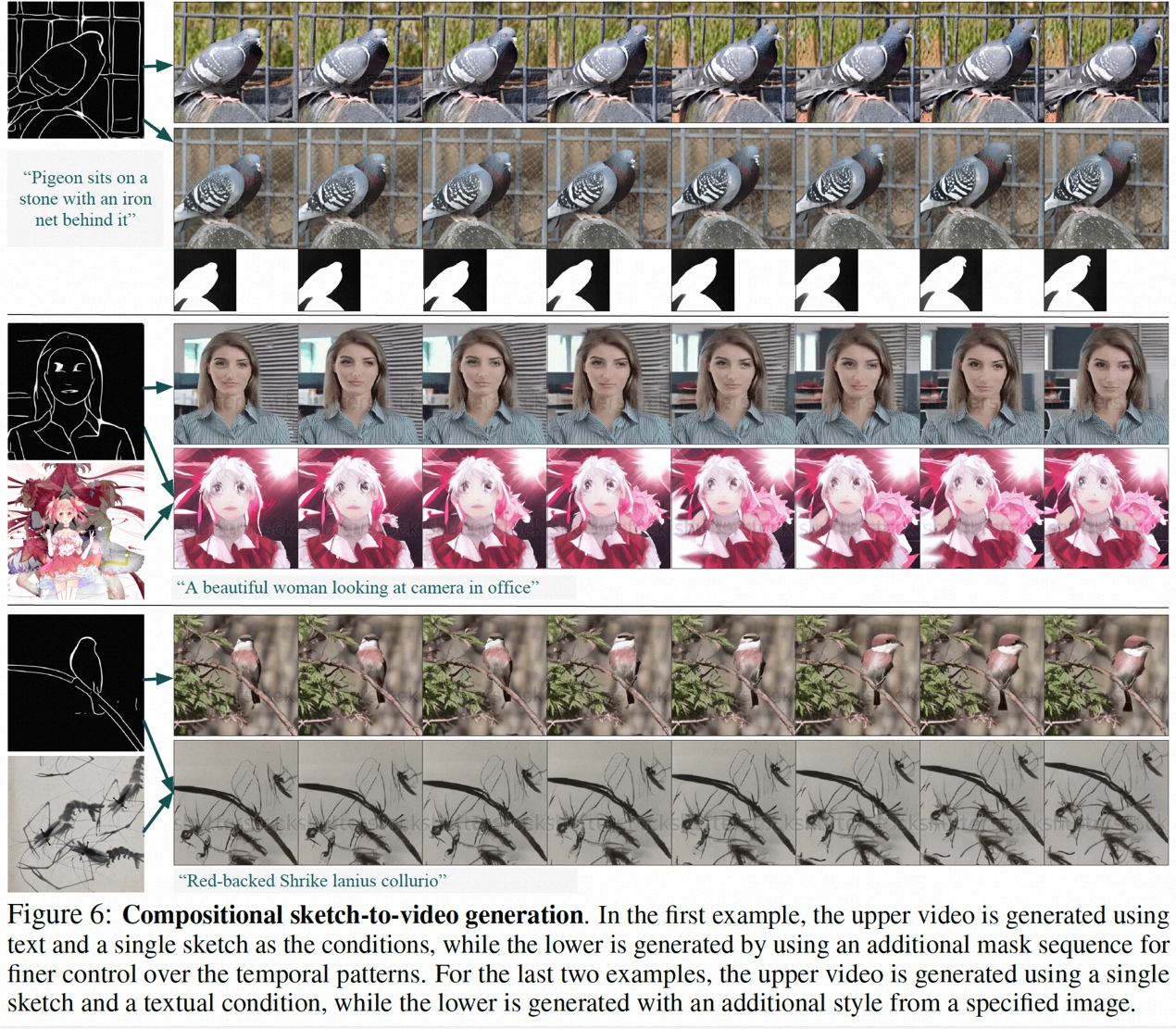
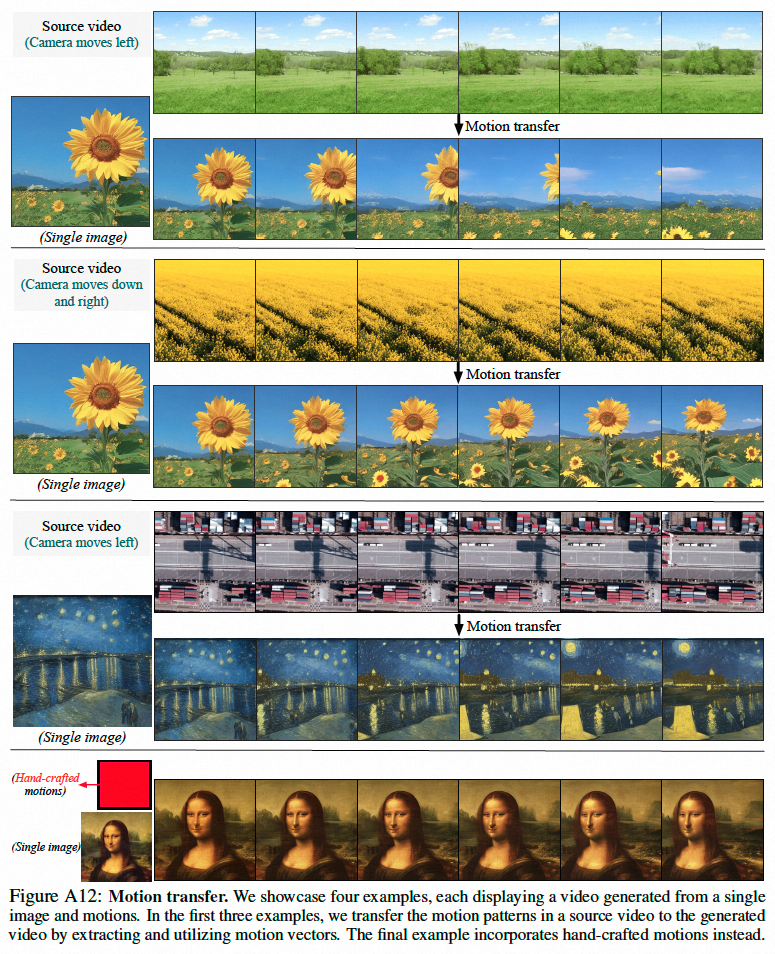
该研究的部分结果如下,在静态图片到视频生成(图 4)、视频 Inpainting(图 5)、静态草图生成生视频(图 6)、手绘运动控制视频(图 8)、运动迁移(图 A12)均能体现可控视频生成的优势。



公开信息显示,阿里巴巴在视觉基础模型上的研究主要围绕视觉表征大模型、视觉生成式大模型及其下游应用的研究,并在相关领域已经发表 CCF-A 类论文 60 余篇以及在多项行业竞赛中获得 10 余项国际冠军,比如可控图像生成方法 Composer、图文预训练方法 RA-CLIP 和 RLEG、超长视频自监督学习 HiCo/HiCo++、说话人脸生成方法 LipFormer 等均出自该团队。




