
根据一张图片,能完成什么任务?
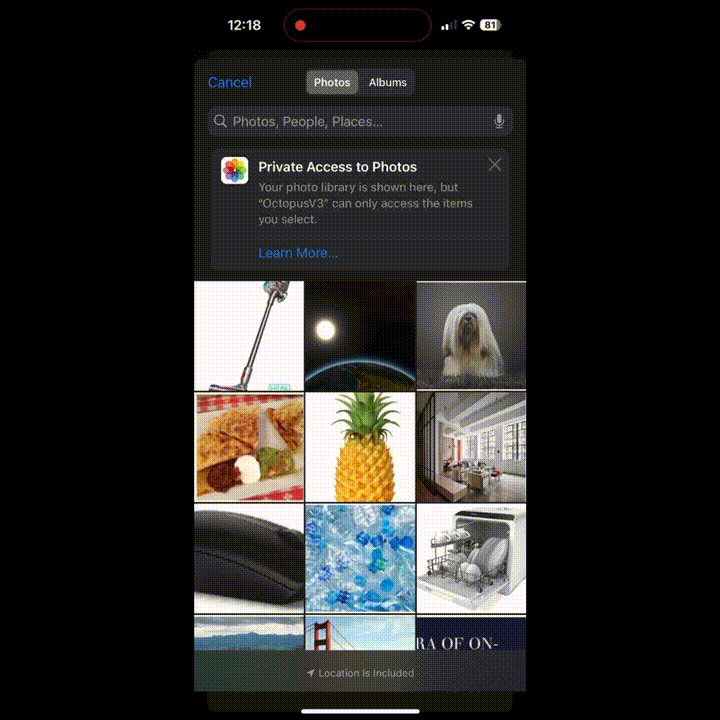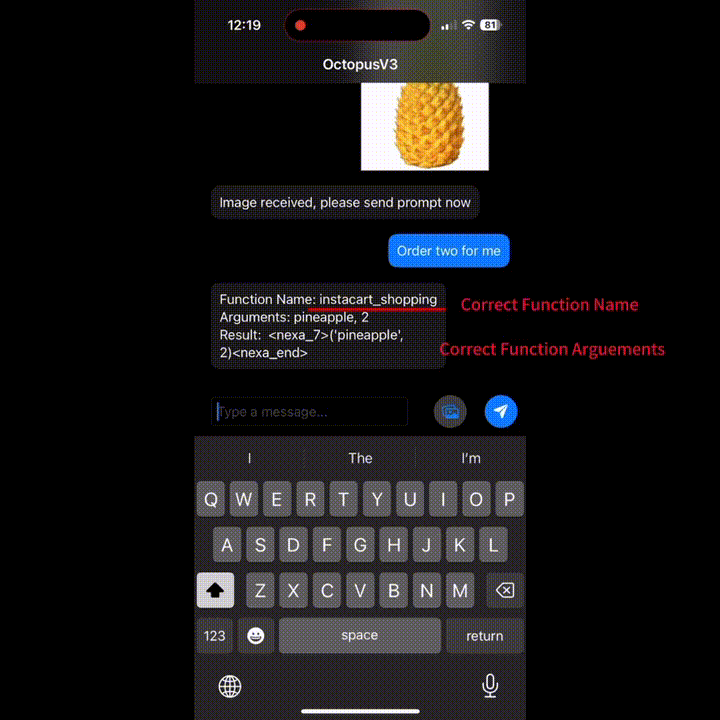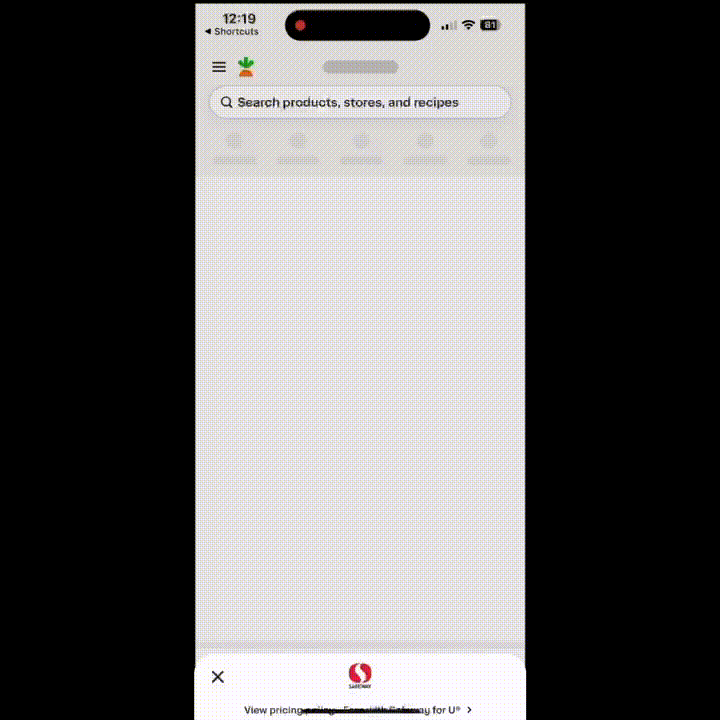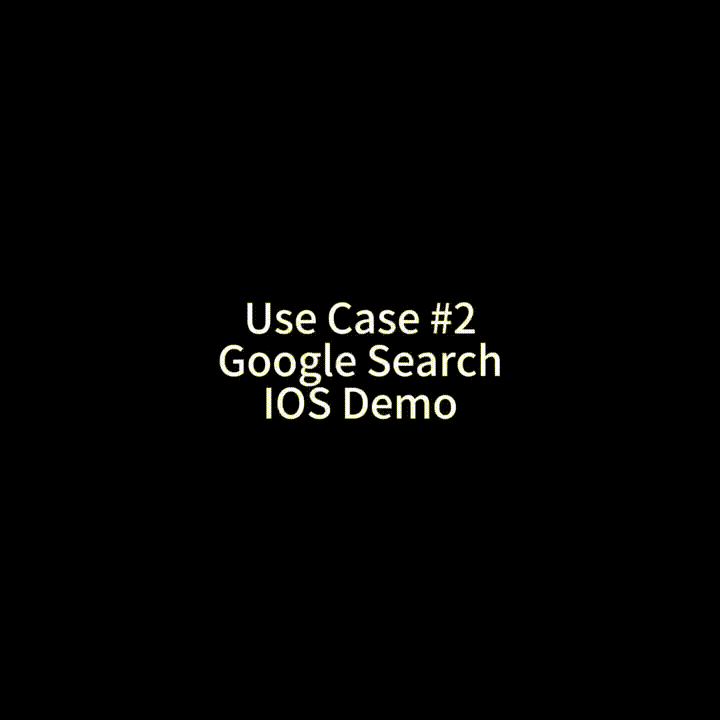
想吃菠萝了?迅速跳转 Instacart 商城界面,各种菠萝任君挑选。
想给家里添置一台吸尘器?没问题,立马来到 Amazon。
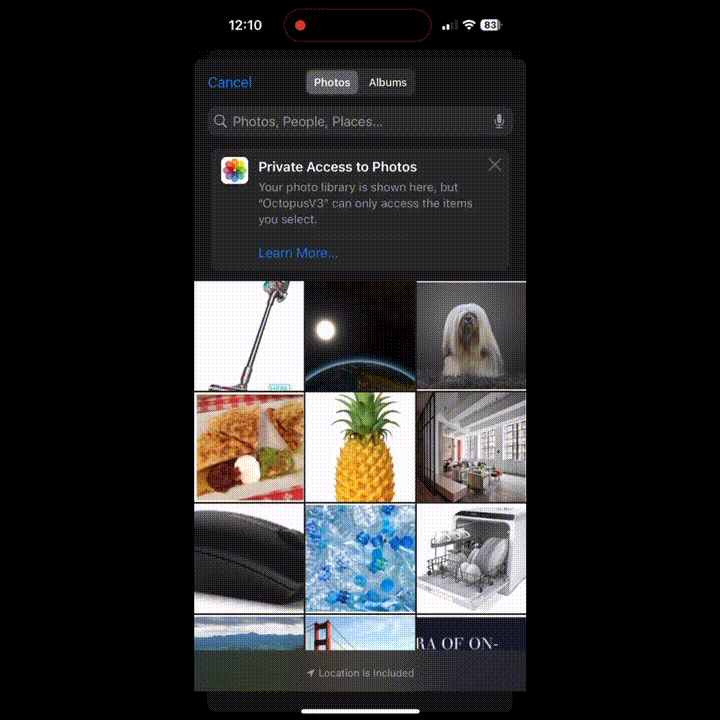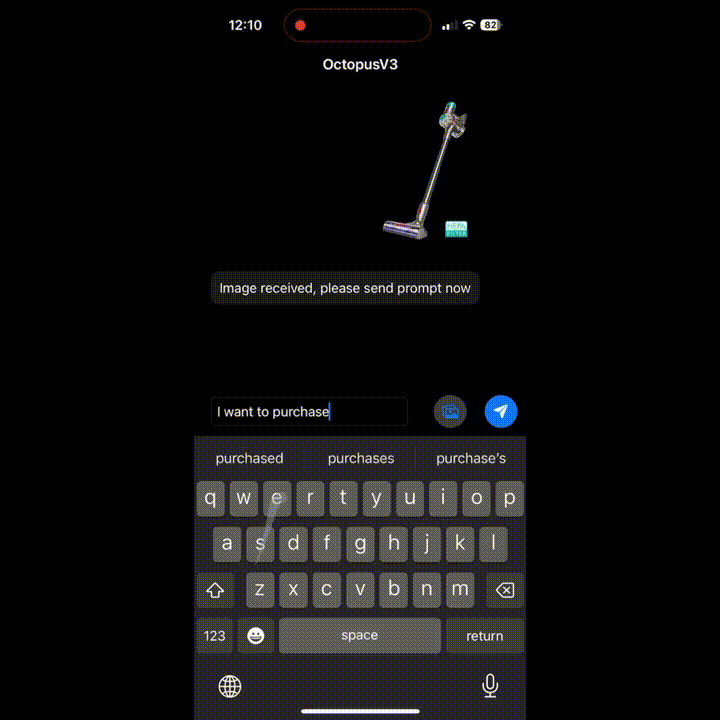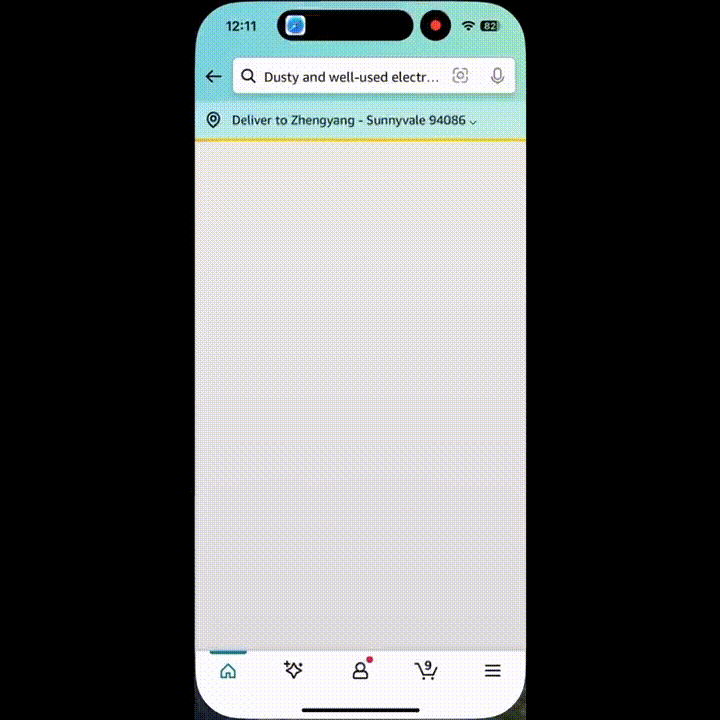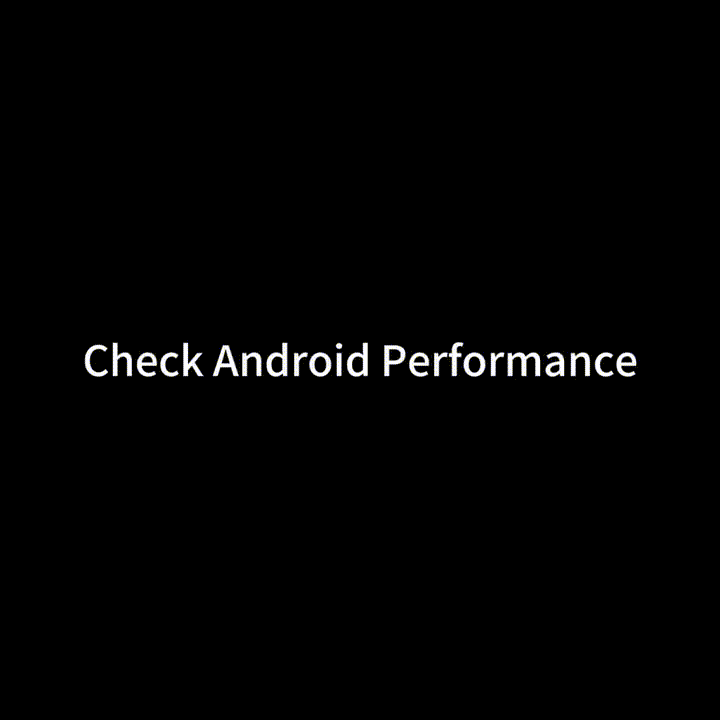
想了解路过大桥的历史?好的,Google 搜索给你想要的答案。
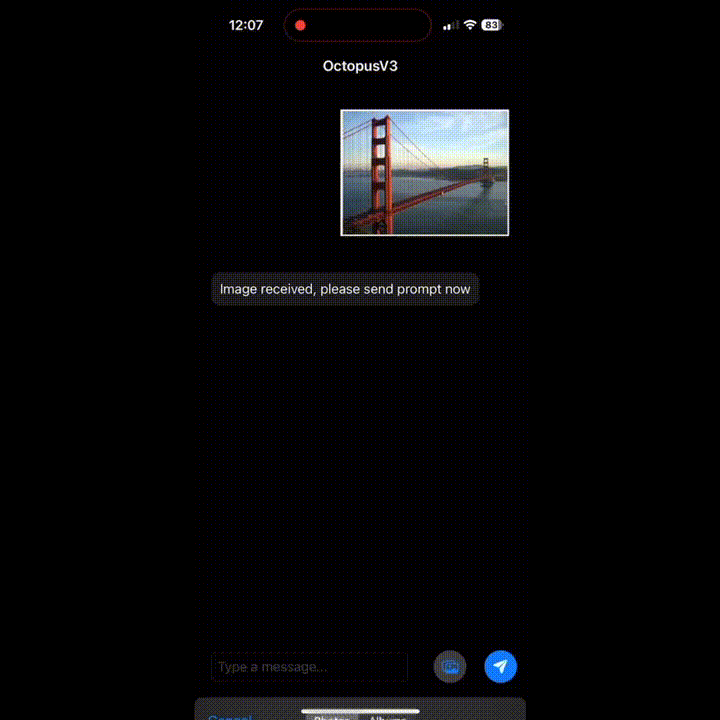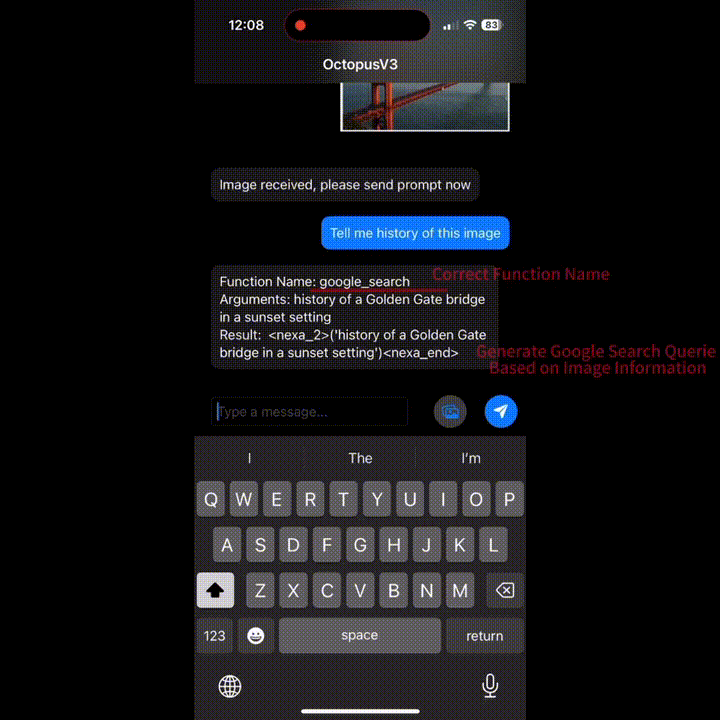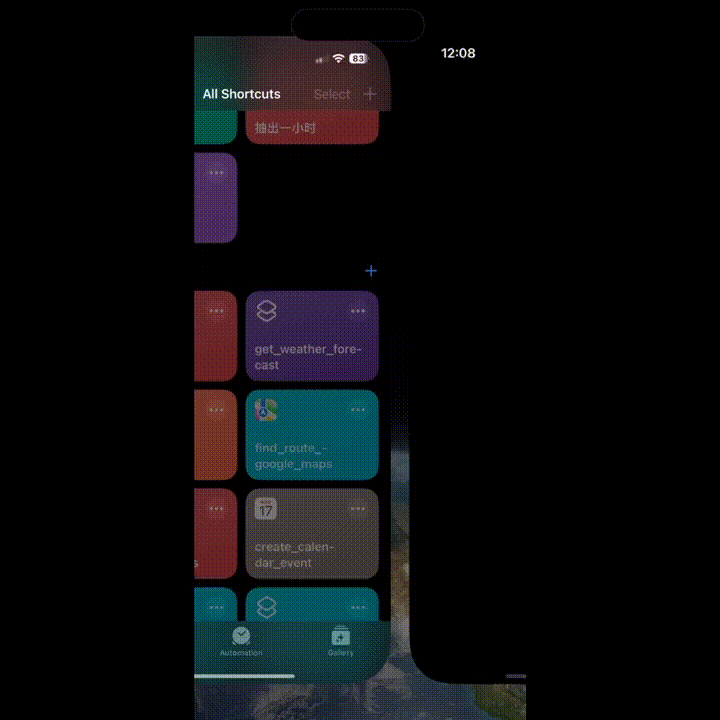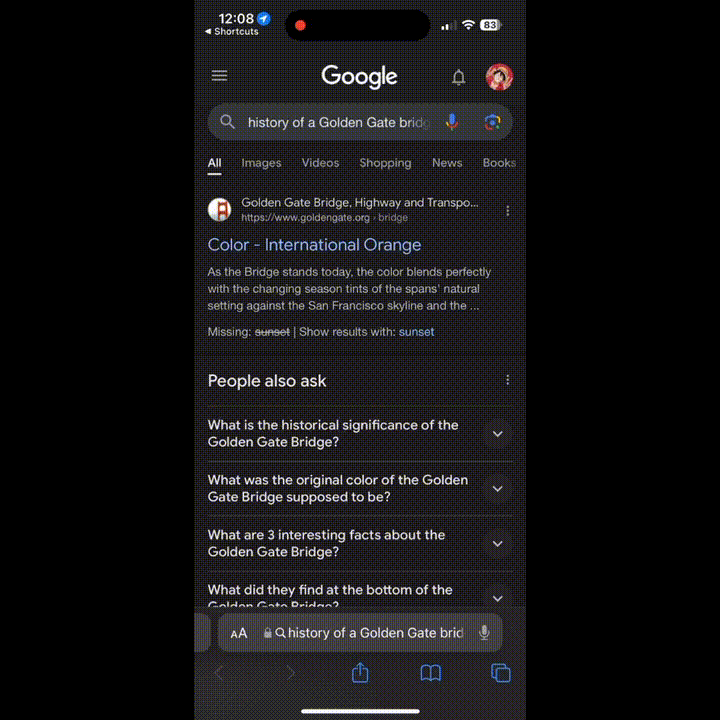
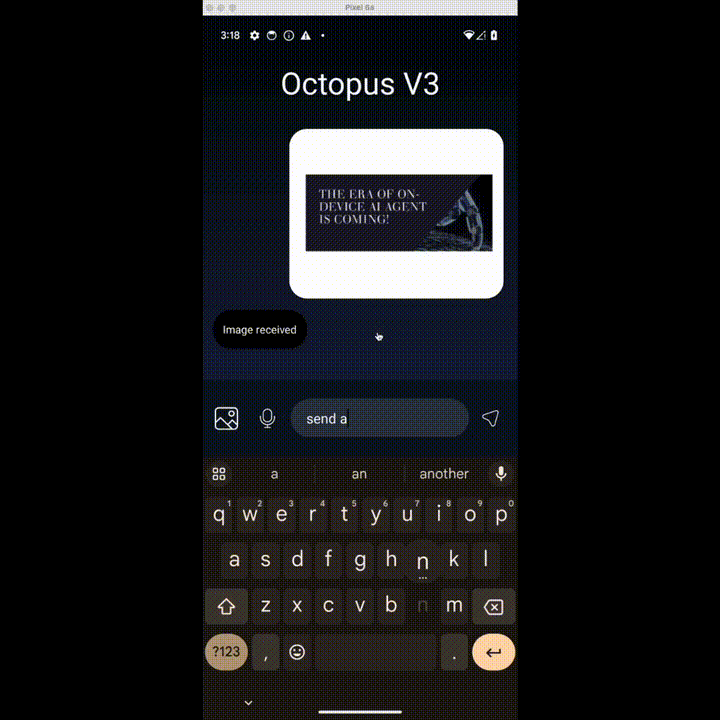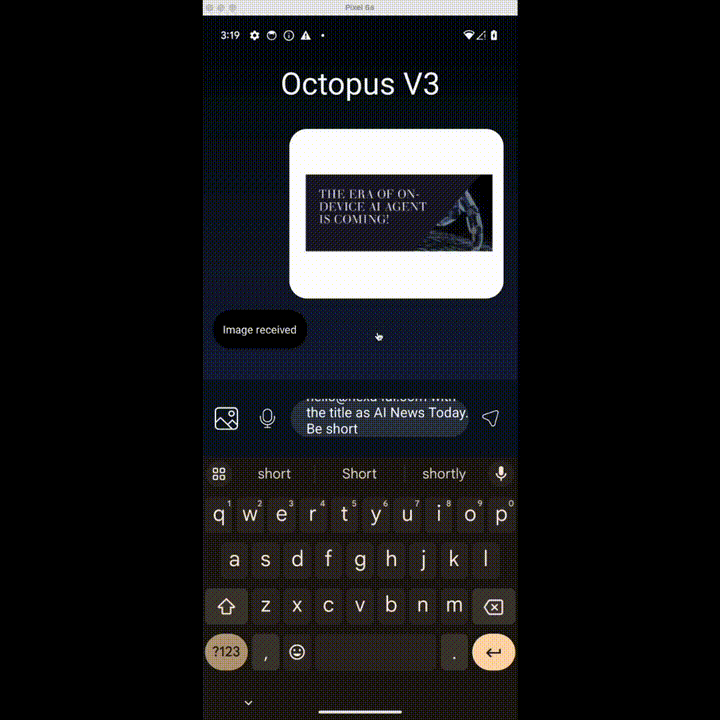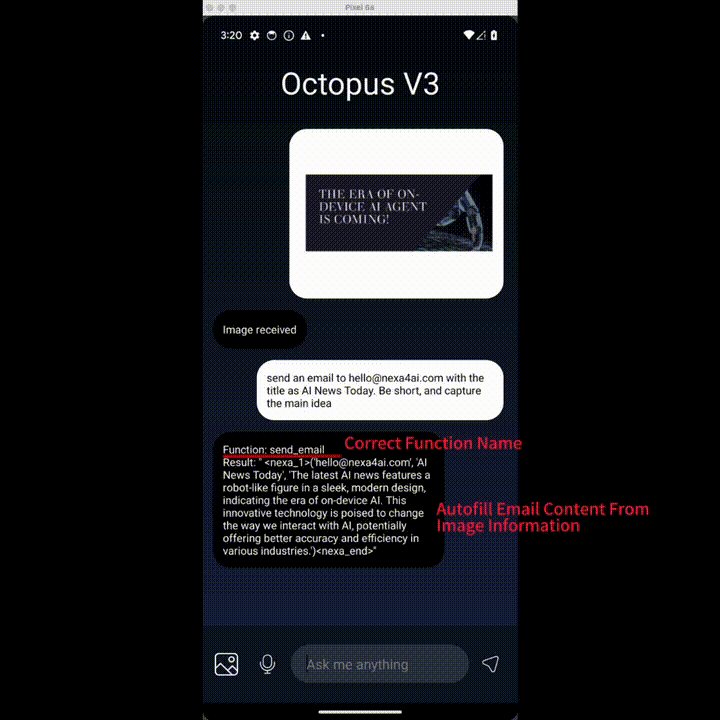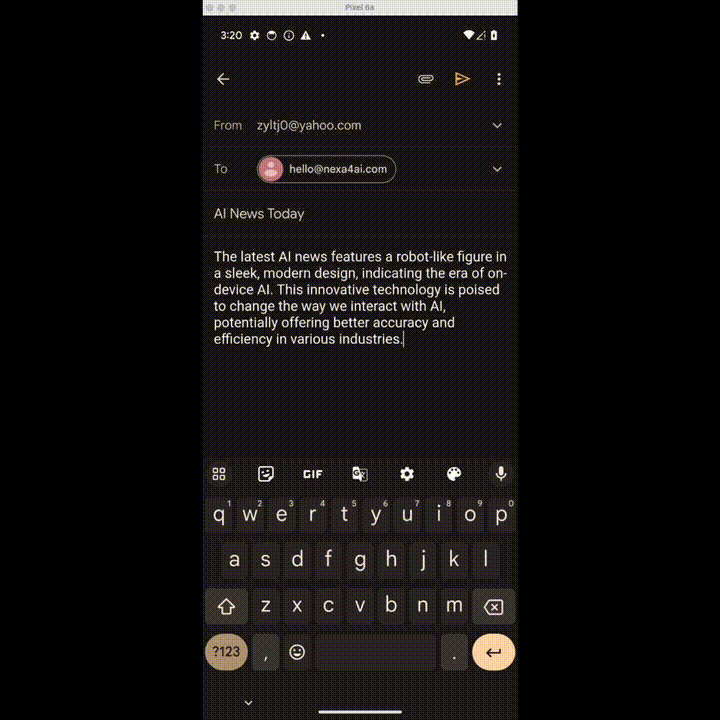
想发个邮件?OK,识别图片大意,填写收件人、标题、正文,发送!
想重新装修下客厅?Done!
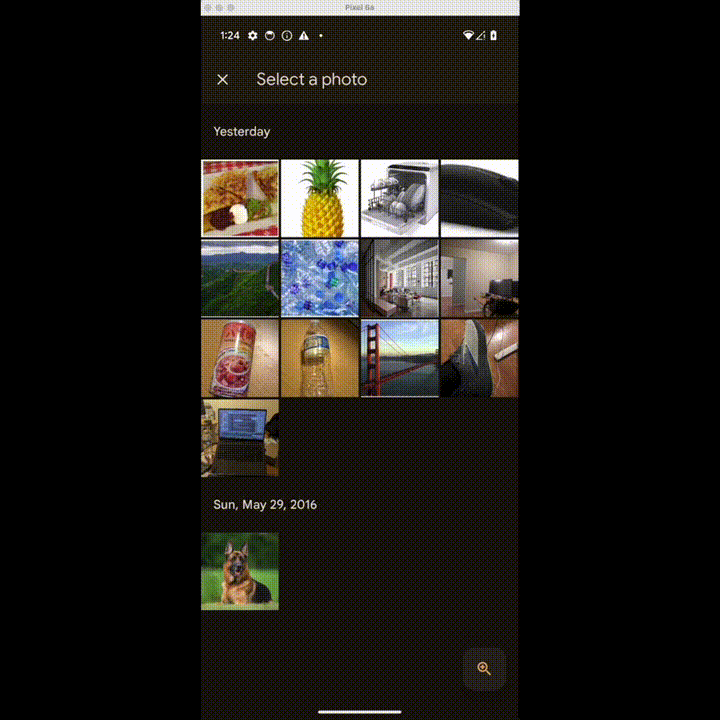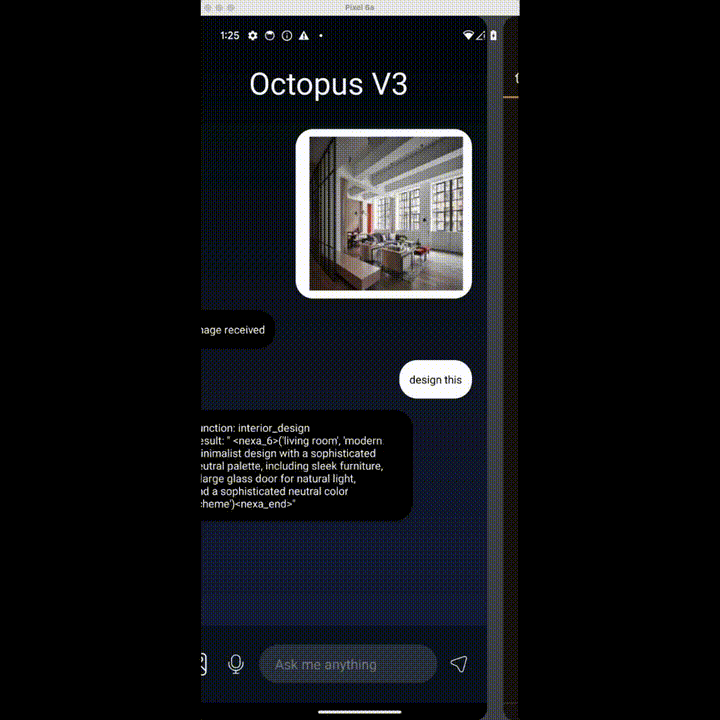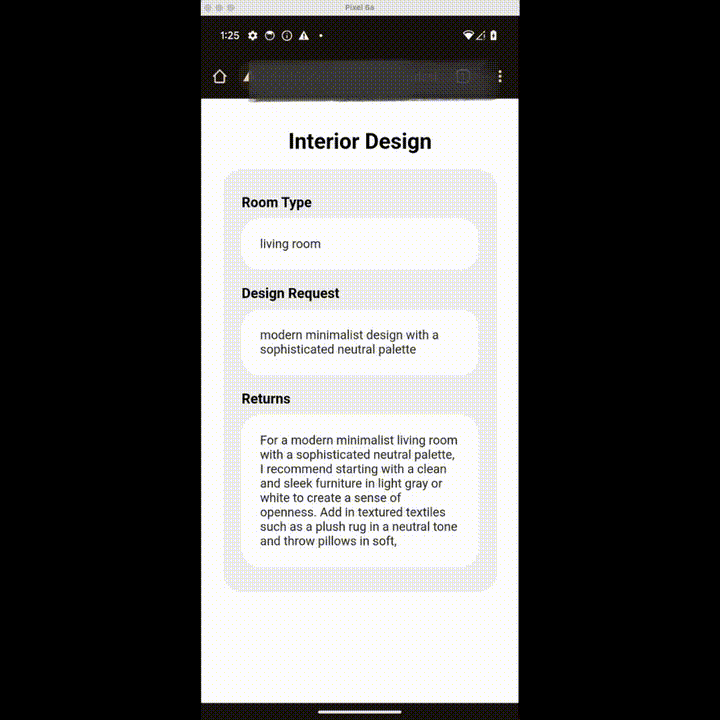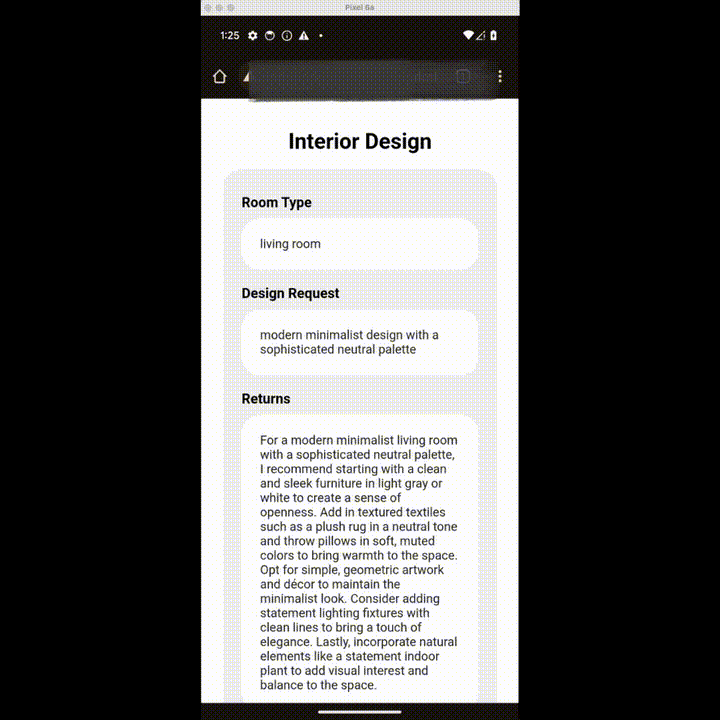
上述功能都来自 Nexa AI 团队近日推出的 OctopusV3。据介绍,OctopusV3 流利掌握英语和中文,能够熟练破译文本和图像任务目标,并实现功能调用,制定复杂的动作序列、生成可执行代码,安卓和 IOS 系统都可用。
值得注意的是,OctopusV3 参数量不到 10 亿,但拥有可媲美 GPT-4V 和 GPT-4 组合起来的性能。由此,Nexa AI 称其为“一个体积最小、性能最强大的多模态 On-Device AI 模型”。
据悉,Nexa AI 成立于 2023 年,是一家致力于研究端侧 AI 代理的初创公司。它的创始人兼 CEO Wei Chen、联合创始人兼 CTO Zhiyuan Li 分别是斯坦福大学的博士和硕士,斯坦福大学副教授 Charles (Chuck) Eesley 担任该公司顾问。
OctopusV3 是如何做到的?
根据论文,OctopusV3 开发中最关键的两点是整合图像、文本输入以及优化模型预测行动的能力。为此, Nexa AI 主要采用了视觉信息编码、功能标记、多阶段训练技术。
在图像处理中,有许多方法可以对视觉信息进行编码,其中常用的是来自隐藏层的嵌入、图像标记化等。团队研究评估各种图像编码技术后,决定采用 CLIP 模型的方法。
与应用于自然语言和图像的标记化一样,特定的功能也可以封装到 token 中。Nexa AI 为这些标记引入了一种训练策略,用于管理未见术语。这种方法类似于 word2vec 方案,即通过上下文环境来丰富标记的含义。
例如,高级语言模型最初可能很难处理 PEGylation 和 Endosomal Escape 等复杂的化学术语。然而,这些模型能够通过因果语言建模获得这些术语,尤其是在包含这些术语的数据集上进行训练时。同样,模型也可以使用并行策略来获取功能性标记。Nexa AI 的研究表明,定义功能标记的潜力是无限的,因此可以标记任何特定功能。
OctopusV3 采用了一种将因果语言模型与图像编码器整合在一起的模型架构,这种迭代训练方法增强了模型有效处理和整合多模态信息的能力。
该模型的训练过程分为多个阶段。首先,团队分别对因果语言模型和图像编码器进行训练,以建立基础基准模型;随后合并这些组件,并对模型进行对齐训练,以同步图像和文本处理能力;之后,训练采用在上一个版本 OctopusV2 框架中应用的方法,促进新版本功能标记的学习。在训练的最后阶段,这些能够与环境互动的功能标记提供反馈,用于进一步完善和优化模型。
除了上文提到的简单应用,Octopus V3 还可以针对特定领域,量身定制出高度专业化的 AI 代理。如此,在医疗保健、金融和客户服务等行业中,用人工智能驱动的解决方案显著提高效率和用户体验。
未来,Nexa AI 还会逐步开发出可容纳音频、视频等其他数据模式的训练框架。此外,他们发现视觉输入可能会带来相当大的延迟,因此正在优化推理速度。
Nexa AI 还提到:“希望这个模型可以对自动驾驶和机器人领域产生帮助,也能够在终端设备上开启无限可能。期待有更多的开发者参与使用这个框架,能看到大家的创意和应用。”
参考链接:




