
本文要点
相关性得分是一个搜索引擎的核心,了解它的工作原理对创建一个好的搜索引擎至关重要。
Elasticsearch 使用了两种相似度评分函数:5.0 版本之前的 TF-IDF 以及 5.0 版本之后的 Okapi BM25。
TF-IDF 通过衡量一个单词在局部的常见性以及在全局的罕见程度来确定查询的相关性。
Okapi BM25 是基于 TF-IDF 的,它解决了 TF-IDF 的缺陷,使函数结果与用户的查询更相关。
我们可以使用 Elasticsearch 提供的_explain API 来调试相似度评分函数的计算。
对查询结果进行排序始终是一项艰巨的任务。 你是否应该按照名称、创建日期、最新更改日期或其他因素对其进行排序呢? 如果你按照名称对产品搜索中的查询结果进行排序,那么很可能第一个出现的产品并不是客户想要购买的。
当创建一个搜索引擎(如以上示例中的产品搜索)时,对结果文档进行排序并不总是那么简单。
排序通常是通过计算语料库中的文档和用户查询之间的相关性或相似度评分来进行。相关性得分是一个搜索引擎的核心。
理解如何计算相关性得分是创建一个好的搜索引擎所必须采取的第一步。
使用Elasticsearch,我们可以开箱即用地计算相关性得分。 Elasticsearch 带有一个内置的相关性评分计算模块,称为相似度模块。
直到 Elasticsearch 5.0.0 版本为止,相似度模块一直使用TF-IDF作为它的默认相似度函数。
后继版本使用BM25(它是TF-IDF的变更版本)作为默认的相似度函数。
在本文中,我们将探讨TF-IDF和BM25这两个函数,以及相似度评分在 Elasticsearch 中的工作原理。
TF-IDF函数的公式如下图 1 所示:

图 1 TF-IDF 公式
TF-IDF 代表的是 Term Frequency-Inverse Document Frequency。它是文本分析和自然语言处理中常用于计算单词之间相似度的函数。 TF-IDF 通过将词频(Term Frequency)和反向文档频率(Inverse Document Frequency)相乘来工作。前者词频,是给定单词在文档中出现的次数。后者逆向文档频率,是对单词在语料库中的罕见程度进行评分的一种计算。单词越罕见,其得分就越高。
当我们要寻找与某个单词相关的文档时,我们希望这个单词是:
局部常见:该单词在文档中多次出现
全局罕见:该单词在语料库中出现的次数并不多。
如果文档中具有某个在局部常见但在全局罕见的单词,那么该文档就是与给定单词相关的文档。使用TF-IDF,在计算哪些是最相关的时候,我们可以同时考虑文档的局部常见因素和全局罕见因素。
词频
词频(Term Frequency)是一种考虑了局部常用词的计算。它的价值是显而易见的。 你可以通过计算这个单词在语料库文档中分别出现的次数来得到它。
因此,我们可以使用词频来计算文档与单词的相关性,但仅凭这一项是不够的。 我们仍然会遇到如下问题:
文档长度:如果我们在公式中只使用词频,那么文档越长将会被认为越相关。 假设我们有一个包含了 1000 个单词的文档,而另一个文档则只有 10 个单词,那么可以理解的是,我们查询的单词在包含了 1000 个单词的文档中出现的频率更高的几率自然要高得多。
常用词:如果我们只使用词频,并且查询“a”、“the”、“of”、“et”等常用词,那么最相关的文档将是包含了最多常用词的文档。 比如,我们有“The blue keyboard”和“The painting of the farmers and the plants”两个文档。 如果我们要查询“the keyboard”,则第二个文档似乎比第一个更相关,尽管从人类的角度看,我们知道这不是真的。
由于存在这些问题,所以不建议只使用词频来计算相似度评分。 幸运的是,通过引入逆向文档频率,我们可以避免上述两个问题。
逆向文档频率
逆向文档频率是一种将全局罕见词考虑在内的计算函数,某个单词在整个语料库中越罕见,那么它就越重要。
我们来看下逆向文档频率的公式:
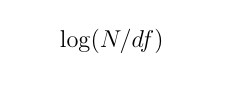
图 2 逆向文档频率公式
因此,我们可以看到N是我们语料库中的文档数,而df是包含某个单词的文档数。
让我们用一个极端的例子来说明这一点。 假设我们的语料库中有 100 个文档,每个文档中都包含单词“a”。 如果要查询单词“a”会发生什么呢?
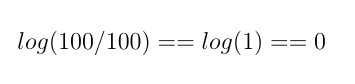
图 3 每个文档都包含某个单词的逆向文档频率计算
正是我们想要的!当某个单词在全局范围内并不罕见(它存在于每个文档中)时,得分将会降为 0。
现在我们来看另一个例子。 像之前一样,我们的语料库中有 100 个文档。 但是现在,只有一个文档中包含了单词“a”。
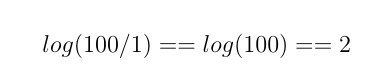
图 4 只有一个文档中包含了某个单词的逆向文档频率计算
可以看到,某个单词在语料库中越罕见,其计算评分就越高。
如果我们要查询一个以上的单词,那么逆向文档频率就非常重要了。 假设我们要查询包含两个单词“a”和“keyboard”的“a keyboard”。 我们可以认为“ a”在全局范围内并不罕见,而“keyboard”却很罕见。 如果我们只使用词频,那么包含更多“a”的文档将会显示成最相关的。 但我们知道这是错的,因为包含了 1 个“keyboard”的文档应该比包含了 10 个“ a”且没有包含“keyboard”的文档更相关。
TF-IDF 计算示例
既然我们已经理解了什么是词率和逆向文档频率,以及它们为什么会如此重要,那么让我们来看一些示例吧。
假设语料库中有五个文档,每个文档中都包含了一个产品名称:
“Blue Mouse”
“Painting of a Blue Mountain with a Blue Sky”
“Blue Smartphone”
“Red Keyboard”
“Black Smartphone”
对于语料库中的这些文档,如果我们使用TF-IDF在语料库中查询“Blue”,哪个文档是最相关的呢?
我们需要计算单词“Blue”到每个文档的距离。让我们从第一个文档“Blue Mouse”开始。
还记得我们之前学过的公式吗?
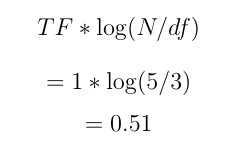
图 5 TF-IDF 计算示例
根据这个计算,我们可以看到“Blue”和“Blue Mouse”之间的距离是 0.51。那其他文档呢?
以下是我们列出的所有文档的计算结果:
“Blue Mouse” = 0.51
“Painting of a Blue Mountain with a Blue sky” = 1.02
“Blue smartphone” = 0.51
“Red Keyboard” = 0
“Black Keyboard” = 0
正如预期的那样,单词“Blue”出现次数最多的文档被计算为最相关的文档。但是如果我们在查询中再加入“Mouse”这个单词呢?
使用“Blue Mouse”作为查询,我们需要首先要将其拆分为单词“Blue”和“Mouse”,然后计算它们到每个文档的距离。
其结果为:
“Blue Mouse” = 0.51 + 1.61 = 2.12
“Painting of a Blue Mountain with a Blue sky” = 1.02 + 0 = 1.02
“Blue smartphone” = 0.51 + 0 = 0.51
“Red Keyboard” = 0
“Black Keyboard” = 0
正如我们所看到的那样,“Blue Mouse”文档已经成了最相关的文档了,这正是我们所期望的。
TF-IDF 的缺陷
TF-IDF就像变魔术一样,它可以按照我们想要的方式计算出最相关的文档!那么,为什么 Elasticsearch 和其他搜索引擎使用的是BM25而不是它呢?
Elasticsearch 在 5.0 版本之前其实一直都是使用TF-IDF来计算相似度评分的,但由于下面的这些缺陷,它后来转而使用BM25了:
它并没有考虑文档的长度:假设我们有一个包含 1000 个单词的文档,其中单词“soccer”出现 1 次和单词“soccer”出现 10 次。你认为哪次的文档与单词“soccer”更相关?应该是单词出现 10 次时,因为与 1000 个单词中只出现一次相比,出现 10 次时文档与“soccer”相关的可能性更大。
词频并不饱和:我们从上一节知道,IDF 将惩罚常用词。但是,如果有些文档本身就有这么多常用词呢?词频的值将会很大。由于 TF-IDF 函数的词频不饱和,会对含有大量常用词的不相关文档进行增强。
由于这些缺点,人们会认为BM25是最先进的相似度函数。
Okapi BM25
Okapi BM25是一个更适合现代用例的相似度评分函数。与TF-IDF一样,我们可以通过将TF和IDF相乘来获得Okapi BM25函数的结果。只是,在Okapi BM25中,TF和IDF公式本身是有不同的。
让我们来看下公式:
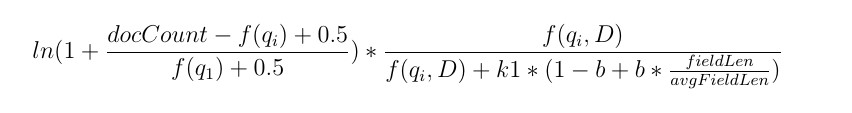
图 6Okapi BM25公式
与 TF-IDF 相比,Okapi BM25的公式似乎有点吓人。对于公式和计算,我们就不作详细介绍了。但是,如果你对公式和计算感兴趣的化,Elasticsearch 有一篇很好的文章。
为什么 Okapi BM25 在相似度评分上优于 TF-IDF
我们知道TF-IDF的缺陷使得它不太适合用于现代的搜索评分函数。那么,Okapi BM25是如何克服这些问题的呢?
TF-IDF的第一个缺陷是它没有考虑文档的长度。在这个公式的分母中,我们可以看到fieldLen/avgFieldLen。这意味着,如果文档的字段长度大于文档的平均长度,该函数将会对文档的得分进行惩罚。我们可以通过更改参数b来控制该函数对较长文档的惩罚程度。如果我们将b设置成一个较大的值,那么该函数将对较长文档的得分进行更多的惩罚。
第二个缺陷是“词频不饱和”。从上一节我们知道,TF-IDF中的词率会增强包含很多常见词的文档。在Okapi BM25函数中,参数k1将确定词频的饱和程度。k1的值越小,词频越饱和。我们可以看到词频的可视化如下图所示:
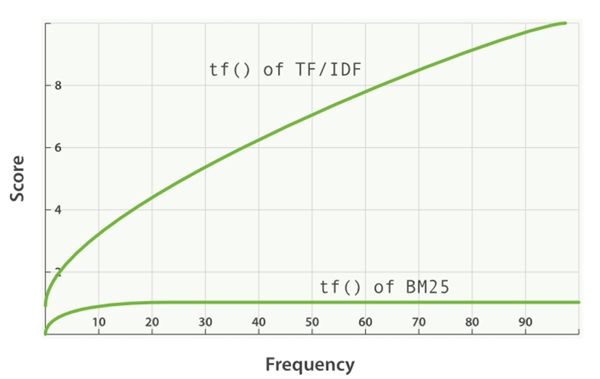
图 7 BM25 中的词频饱和度
Okapi BM25 计算示例
现在我们已经知道了Okapi BM25的工作原理,那我们来尝试一下。对于这些示例,我们将使用 Elasticsearch 中默认的k1和b。
k1= 1.2b= 0.75
我们使用TF-IDF示例中使用过的相同文档,并查询“Blue”。
“Blue Mouse” = 0.29
“Painting of a Blue Mountain with a Blue sky” = 0.23
“Blue Smartphone” = 0.29
“Red Keyboard” = 0
“Black Keyboard” = 0
正如我们看到的那样,结果与TF-IDF函数的相比有所不同。之前得分最高的“Painting of a Blue Mountain with a Blue sky”,现在比“Blue Mouse”和“Blue Smartphone”要低。这是因为我们现在考虑了文章的长度,且更喜欢较短的文章。我们也使词频变得饱和了。但是由于单词重复而产生的得分并没有 TF-IDF 函数的大,在这个例子中,这并没有真正显示出来。
所以,让我们使用b=0 来再试下。我们会得到什么呢?
“Blue Mouse” = 0.24
“Painting of a Blue Mountain With a Blue Sky” = 0.34
“Blue Smartphone” = 0.24
“Red Keyboard” = 0
“Black Keyboard” = 0
由于我们将参数b降为 0,所以该函数不再考虑文章的长度。 因此,文档“Painting of a Blue Mountain With a Blue Sky”成为得分最高的文档了。
现在,让我们试着把k1降为 0,看看会发生什么:
“Blue Mouse” = 0.24
“Painting of a Blue Mountain With a Blue Sky” = 0.24
“Blue Smartphone” = 0.24
“Red Keyboard” = 0
“Black Keyboard” = 0
所有包含单词“Blue”的三个文档的得分都是相同的,因为当k1降为 0 时,词频不会影响得分。如果我们试着将k1增加到一个更大的数字,该函数将会提高重复出现查询词的文档的评分。
Elasticsearch 中的相似度评分
现在,我们已经介绍了基础知识,我们可以在 Elasticsearch 中获得相似度评分了!在本节中,我们将学习如何配置相似度评分以及如何计算相似度评分。
从上一节中,我们知道 Elasticsearch 使用Okapi BM25作为其默认的评分函数。那么,让我们插入一些文档来看看它是如何工作的。
Elasticsearch 中的 Explain API
注意:从这一节开始,将会有许多 JSON 代码块。你可以使用此工具更好地可视化 JSON 格式。
幸运的是,如果我们想知道 Elasticsearch 是如何计算评分的,我们可以使用它提供的 API,_explainAPI。
首先,我们创建一个索引(index),并插入一些我们在TF-IDF示例中使用过的文档。
curl --request PUT \ --url http://localhost:9200/similarity-score \ --header 'content-type: application/json' \ --data '{"mappings": { "properties": { "text": { "type": "text"} }}}'curl --request POST \ --url http://localhost:9200/similarity-score/_doc/_bulk \ --header 'content-type: application/json' \ --data '{ "index":{} }{ "text": "Blue Mouse" }{ "index":{} }{ "text" : "Painting of a Blue Mountain with a Blue Sky" }{ "index":{} }{ "text" : "Blue Smartphone" }{ "index":{} }{"text" : "Red Keyboard" }{ "index":{} }{"text" : "Black Smartphone" }'创建并填充相似度评分索引
首先,我们查询“Blue”:
curl --request POST \ --url http://localhost:9200/similarity-score/_doc/_search \ --header 'content-type: application/json' \ --data '{"query": { "match": { "text": { "query": "Blue" } }}}'添加“Blue”查询到相似度评分索引
结果为:
[ { "_index": "similarity-score", "_type": "_doc", "_id": "XHk0ZXUB3iGz82DLcBwy", "_score": 0.6481823, "_source": { "text": "Blue Mouse" } }, { "_index": "similarity-score", "_type": "_doc", "_id": "Xnk0ZXUB3iGz82DLcBwy", "_score": 0.6481823, "_source": { "text": "Blue Smartphone" } }, { "_index": "similarity-score", "_type": "_doc", "_id": "XXk0ZXUB3iGz82DLcBwy", "_score": 0.5064942, "_source": { "text": "Painting of a Blue Mountain with a Blue Sky" } } ]查询“Blue”的结果
文档的顺序与我们在Okapi BM25那节中计算的是一样的,但评分有所不同。Elasticsearch 有一个boost参数,我们将在下一节中解释这个参数是如何增加或减少查询评分的。
我们使用_explainAPI 来看下计算过程:
curl --request POST \ --url 'http://localhost:9200/similarity-score/_doc/_search?explain=true' \ --header 'content-type: application/json' \ --data '{"query": { "match": { "text": { "query": "Blue" } }}}'使用 explain API
我们将会得到一个很长的应答,我们来看下第一份文档:
{ "_shard": "[similarity-score][0]", "_node": "JaAqC3tqRZGmn48z4tPrRA", "_index": "similarity-score", "_type": "_doc", "_id": "XHk0ZXUB3iGz82DLcBwy", "_score": 0.6481823, "_source": { "text": "Blue Mouse" }, "_explanation": { "value": 0.6481823, "description": "weight(text:blue in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.6481823, "description": "score(freq=1.0), computed as boost * idf * tf from:", "details": [ { "value": 2.2, "description": "boost", "details": [] }, { "value": 0.5389965, "description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:", "details": [ { "value": 3, "description": "n, number of documents containing term", "details": [] }, { "value": 5, "description": "N, total number of documents with field", "details": [] } ] }, { "value": 0.54662377, "description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:", "details": [ { "value": 1.0, "description": "freq, occurrences of term within document", "details": [] }, { "value": 1.2, "description": "k1, term saturation parameter", "details": [] }, { "value": 0.75, "description": "b, length normalization parameter", "details": [] }, { "value": 2.0, "description": "dl, length of field", "details": [] }, { "value": 3.4, "description": "avgdl, average length of field", "details": [] } ] } ] } ] } }Explain
API 的结果使用_explainAPI,我们可以知道用于评分计算的每个值,以及它所使用的公式。请注意,在这些示例中,我使用的是 ElasticSearch 7.9。如果你使用的版本和我的不同,那么公式或 boost 值可能也会与示例中的有所不同。
权重提升
你可能想知道在_explainAPI 结果中所看到的 boost 参数。它有什么作用呢?使用boost参数,可以增加或减少相应单词的评分。boost有两种类型:索引时boost(index-time boost)(已弃用)和查询时boost(query-time boost)
第一个boost,索引时boost,从 5.0.0 版本开始就已经弃用了。 你可以在本文末尾处看到 Elasticsearch 不推荐使用索引时boost的原因。
第二种类型,查询时boost,将在计算评分时更改boost参数。我们可以使用_explainAPI 尝试下。
要更改boost的值,只需将它添加到查询中即可:
curl --request POST \ --url 'http://localhost:9200/sim-score/_doc/_search?explain=true' \ --header 'content-type: application/json' \ --data '{"query": { "match": { "text": { "query": "Blue", "boost": 2 } }}}'使用查询时
boost结果如下:
{ "value": 4.4, "description": "boost", "details": []}查询时boost的结果
boost 的默认值是2.2。由于我们在查询中使用了2,所以它将乘以2,结果是4.4。
分片设置对相关性评分计算的影响
到目前为止,我们只使用了一个带有 1 个分片(share)的索引,这使得我们的评分结果是一致且可预测的。不同的分片设置会影响 Elasticsearch 中的评分计算。
原因是,当 Elasticsearch 计算一个文档的评分时,它只能访问这个分片中的其他文档。因此,公式中IDF和avgLen的值在不同分片之间是不一样的。
我们尝试创建一个包含 5 个分片的新索引:
curl --request PUT \ --url http://localhost:9200/similarity-score-3 \ --header 'content-type: application/json' \ --data '{"settings": { "index": { "number_of_shards": 5 }},"mappings": { "properties":{ "text":{"type":"text"} }}}'curl --request POST \ --url http://localhost:9200/similarity-score-3/_doc/_bulk \ --header 'content-type: application/json' \ --data '{ "index":{} }{ "text": "Blue Mouse" }{ "index":{} }{ "text" : "Painting of a Blue Mountain with a Blue Sky" }{ "index":{} }{ "text" : "Blue Smartphone" }{ "index":{} }{"text" : "Red Keyboard" }{ "index":{} }{"text" : "Black Smartphone" }'创建并填充一个具有 5 个分片的索引
如果我们将“Blue”查询添加到索引中,则结果为:
[ { "_index": "similarity-score-3", "_type": "_doc", "_id": "vXkvanUB3iGz82DL8xxR", "_score": 0.8083933, "_source": { "text": "Painting of a Blue Mountain with a Blue Sky" } }, { "_index": "similarity-score-3", "_type": "_doc", "_id": "vHkvanUB3iGz82DL8xxR", "_score": 0.2876821, "_source": { "text": "Blue Mouse" } }, { "_index": "similarity-score-3", "_type": "_doc", "_id": "vnkvanUB3iGz82DL8xxS", "_score": 0.2876821, "_source": { "text": "Blue Smartphone" } } ]添加“Blue”查询到带有 5 个分片的索引中
该结果与只有 1 个分片的相比会有所不同。现在,“Painting of a Blue Mountain With a Blue Sky”的得分最高。
这是因为 Elasticsearch 将每个文档存储在不同的分片中,因此每个文档IDF和avgLen的值都不相同。
我们可以使用?search_type=dfs_query_then_fetch告诉 Elasticsearch 在计算评分之前从每个分片中检索所需的值。
curl --request POST \ --url 'http://localhost:9200/similarity-score-3/_doc/_search?search_type=dfs_query_then_fetch' \ --header 'content-type: application/json' \ --data '{"query": { "match": { "text": { "query": "Blue" } }}}'使用dfs_query_then_fetchdfs进行查询
结果与仅使用 1 个分片时的相同:
[ { "_index": "similarity-score", "_type": "_doc", "_id": "XHk0ZXUB3iGz82DLcBwy", "_score": 0.6481823, "_source": { "text": "Blue Mouse" } }, { "_index": "similarity-score", "_type": "_doc", "_id": "Xnk0ZXUB3iGz82DLcBwy", "_score": 0.6481823, "_source": { "text": "Blue Smartphone" } }, { "_index": "similarity-score", "_type": "_doc", "_id": "XXk0ZXUB3iGz82DLcBwy", "_score": 0.5064942, "_source": { "text": "Painting of a Blue Mountain with a Blue Sky" } } ]使用dfs_query_then_fetchdfs进行查询的结果
不推荐使用?search_type=dfs_query_then_fetch,因为它会显著降低搜索速度。如果你的索引中有很多文档,那么它本身就已经确保了词频的良好分布。
如何在 Elasticsearch 中更改相似度评分函数
我们从上一节了解到,Okapi BM25是其默认的评分函数,它具有参数b和k1。
如果我们想要更改评分函数呢?幸运的是,Elasticsearch 提供了一个相似度模块,我们可以使用它来更改评分函数并配置参数。
如果要更改b和k1的值,可以在创建索引时对其进行配置:
curl --request PUT \ --url http://localhost:9200/similarity-score-4 \ --header 'content-type: application/json' \ --data '{"settings": { "index": { "number_of_shards": 1, "similarity": { "default": { "type": "BM25", "b": 0, "k1": 10 } } }},"mappings": { "properties": { "text": { "type": "text" } }}}'使用自定义的相似度参数创建索引
我们也可以选择要使用的评分函数。比如,我们选择LMDirichlet:
curl --request PUT \ --url http://localhost:9200/similarity-score-5 \ --header 'content-type: application/json' \ --data '{"settings": { "index": { "number_of_shards": 1, "similarity": { "default": { "type": "LMDirichlet" } } }},"mappings": { "properties": { "text": { "type": "text" } }}}'使用另外的相似度函数创建索引
Elasticsearch 支持以下函数:
DFR相似度DFI相似度IB相似度LM Dirichlet相似度LM Jelinek Mercer相似度脚本相似度
如果你想了解每种相似度函数的参数,可以访问Elasticsearch的文档。
结论
在本文中,我们学习了TF-IDF、Okapi BM25以及 Elasticsearch 中的评分。
我们首先学习了TF-IDF以及为什么需要词频和逆向文档频率。我们还了解到TF-IDF有缺陷,以及Okapi BM25函数是如何克服这些缺陷的 。
我们还学习了 Elasticsearch 中的评分,如何使用_explainAPI 和评分加权,为什么分片设置会影响评分结果,如何更改BM25参数以及相似度函数在 Elasticsearch 中的使用。
相似度评分可能会对 Elasticsearch 的搜索性能产生很大的影响。如果你遇到了搜索性能方面的问题,这里有10条简单的改进技巧。如果你的操作存在搜索延迟的问题,请阅读本指南以获取该简单解决方法的说明和介绍。
参考文献
作者简介:
Ziv Segal 是Opster的联合创始人兼首席执行官,该公司提供可以确保 Elasticsearch 达到最佳性能的解决方案。Ziv 拥有十多年的 Elasticsearch 工作经验,并在任务关键型应用程序中维护了数十个集群。
Brilian Firdaus 是一家电子商务公司的软件工程师,也是 Opster Elasticsearch 专家社区的一员。
原文链接:
https://www.infoq.com/articles/similarity-scoring-elasticsearch/




