
前言
TalkingData 是一家总部在北京的数据智能服务提供商,通过提供数据智能产品和服务,来帮助企业获得对消费者行为、偏好和倾向的洞察。TalkingData 的一项重要服务是基于机器学习的用户行为分析:通过分析用户信息,可以为用户提供更具有价值的广告。比如有一个汽车经销商想要为想买车的用户投放最近的促销信息,他可以通过这个产品来找到在未来三个月有买车倾向的用户群,进而定向投放广告。最开始,TalkingData 的模型是基于 XGBoost 构建的。后来随着技术演进和精度要求的提升,TalkingData 研发部门进一步开发了基于深度学习模型的应用。经过实验以及测试论证,他们的数据科学家成功用 PyTorch 将模型的 recall rate(recall rate 是模型在阈值下是否能够提供推理的比例)提升了 13%。换句话说,相比于传统机器学习模型,他们的深度学习模型在基于相同的精度情况下可以带来更多的深度学习推理结果。
但是 TalkingData 在大规模部署深度学习应用中遇到了很大的挑战:模型需要每天对数亿的数据进行深度学习推理。为了能够更高效地进行大规模计算,他们使用了基于 Apache Spark 的大规模分布式架构来快速批量推理。可是,由于 Spark 主要是基于 JVM 的框架,使用 Python 应用(PySpark) 进行深度学习推理往往会造成内存溢出问题。因为基于 JVM 本身的内存管理很难去对一个 Python 的进程产生影响。在过去,因为 XGBoost 对于 Java 的支持,TalkingData 可以使用 XGBoost Java API 在 Spark 平台进行部署。现今使用了 PyTorch,由于没有一个很好设计的 Java API,以及各种内存溢出问题,他们没有办法在 Apache Spark 上调用 PyTorch 模型进行推理任务。这导致了他们被迫转向使用一个 GPU 的实例来单独进行深度学习推理,这种方案大大增加了后期维护成本。
通过这篇文章,TalkingData 发现了 AWS 基于 Java 开发的深度学习框架 DJL(Deep Java Library)可以很好的解决上述的困境。在这个博客中,我们将带领大家了解 TalkingData 部署的模型,以及他们是如何利用 DJL 在 Apache Spark 上实现生产环境部署深度学习模型。这个解决方案最终将之前的生产架构简化,一切任务都可以在 Apache Spark 轻松运行,总时间也减少了 66%。从长远角度上,这也显著节省了维护成本。
关于模型
该模型为一个用于推断活跃用户是否有可能购买汽车的二分类模型,使用的特征来自于嵌入 TalkingData SDK 的应用收集的数据。在将原始数据聚合和处理的过程中,特征不可避免地会成为稀疏的分类特征。当 TalkingData 使用传统的机器学习模型(例如逻辑回归和 XGBoost)时,这些简单的模型在从这些稀疏的特征中学习的过程中很容易过拟合。 另外,考虑到数以百万计的训练数据可以支持更复杂,更强大的模型,TalkingData 将其模型升级为了 DNN(深度神经网络)模型。
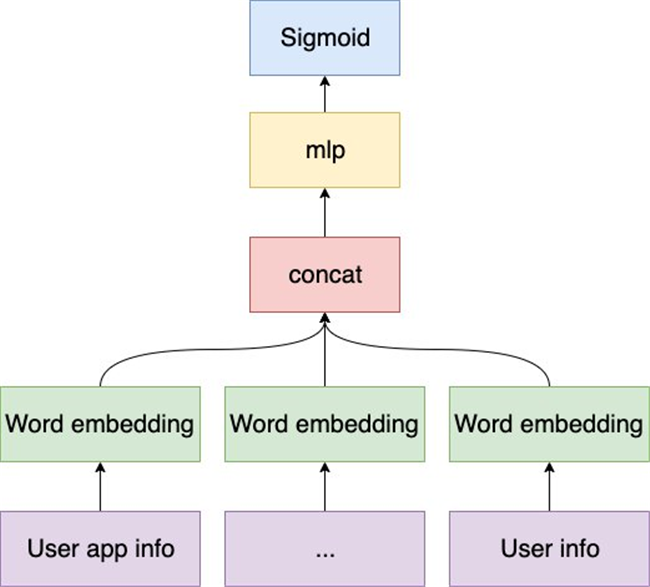
在合规性前提下,TalkingData 模型将用户信息、用户应用信息和广告事件作为输入。用户信息包括设备名称和设备型号,用户应用信息包含嵌入 SDK 的应用包名,广告事件信息是用户参与的广告活动信息。这些不同域的输入根据时间聚合,然后预处理成分类特征,预处理包括标记化(tokenization)和规范化(normalization)。 受 Wide and Deep learning 和 YouTube Deep Neural Networks 的启发,首先将分类特征根据预先生成的映射表映射到对应的索引,截断或添补为固定长度,然后再输入到 PyTorch DNN 模型。模型基于对应每个域的词嵌入进行训练。嵌入 (embedding) 是一种用数值向量表征分类变量的方法:用于降低稀疏的分类变量维度。例如,百万维的类别特征可以用几百维的向量表征,实现模型特征的降维。然后对不同域的嵌入简单的求平均,再拼接成固定长度的向量,喂入前馈神经网络。在训练过程中,最大训练轮数设置为 40,提前停止轮数设置为 15。与 Spark XGBoost 模型相比,DNN 模型在测试集上的 AUC(Area under the ROC Curve)提升了 6.5%,期望精确度下的召回提升了 26%。考虑到 TalkingData 巨大的数据量,DNN 模型的结果很不错 。
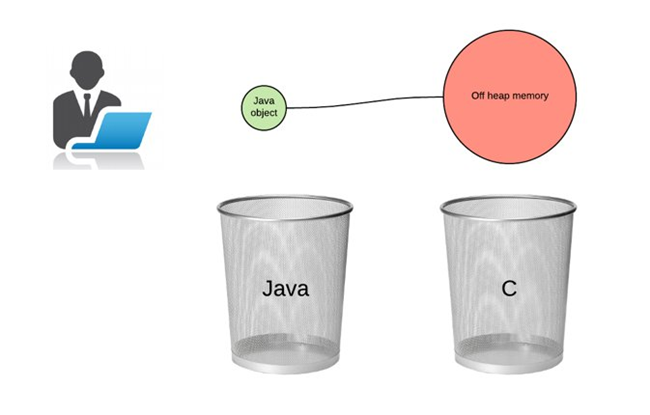
生产环境中的困境
虽然模型的效果很令人满意,但是部署深度学习模型成为了很大的困难。由于生产环境中主要的代码都是基于 Scala 的,直接部署 PyTorch 在 Scala 上面临着内存溢出的挑战:JVM 的资源回收系统无法看到 C++所使用的资源(底层 PyTorch API). 为了避免频繁的任务失败问题,最终 TalkingData 选择使用了单独开启一个 GPU 的实例来做离线的大数据推理任务。
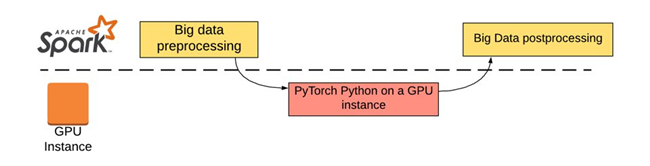
但是,这个解决方案没有很好的解决下面几个问题
性能问题:下载和上传数据需要花费大约 30 分钟时间
单点故障问题:无法使用类似于 Spark 的多点计算功能。推理任务完全在一个单 GPU 的机器上进行,如果出现任务失败,那 GPU 本身没有回退机制可以良好应对。
维护问题:生产环境中需要同时维护 Scala 和 Python 两个环境
扩展问题:如果数据量再增大一些,单 GPU 的处理性能可能不足。
总体的数据量大约几百 GB。总体任务在上述框架下需要 6 个多小时才可以完成,比 TalkingData 预期的时间超出两倍。这个设计最终成为了整个生产环节的性能瓶颈。
基于 DJL 的实现
为了优化这个方案,TalkingData 采用 DJL 重构了他们的推理应用。DJL 提供了基于 Java 的 PyTorch 引擎库,这使得他们可以直接将这个库部署在 Spark 上。如下图所示,所有的任务都可以在 Spark 集群中实现:
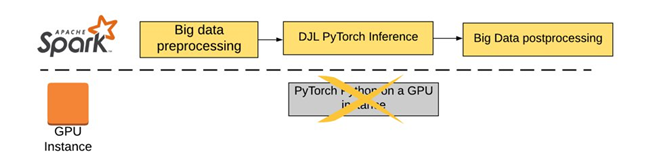
这个设计体现了下面几个优势:
降低了失败率:相比于单点故障,Spark 可以很轻松的调度算力来进行重启。
降低算力成本:相比于 GPU 的解决方案,完全基于 Spark 的方案可以充分使用 Apache Spark 本身的算力,从而节约成本。减少使用 GPU 机器大约节省了 20%的总计算成本。
降低维护成本:Spark 的容错机制可以轻松应对故障,同时单一语言降低了多个语言维护的成本。
大幅提升性能:DJL 的多线程支持在 Apache Spark 上提升了性能。
在使用了 DJL 之后,TalkingData 成功的将总体任务运行时间降低到了 2 小时左右。相比于从前的单 GPU 解决方案,性能提升了三倍。同时,这套方案无论从短期还是长期都降低了运行成本。
DJL 的多线程优势
DJL 可以让用户更灵活的调度分布式算力。在 PyTorch 高级设置中,用户可以选择优化算子的并行数,还有最多线程的并行数(用于提升推理性能)。DJL 提供了类似的选项:只需设定 numinteropthreads 和 num_threads 便可以轻松调度。这些选项可以同时与 Apache Spark 每个 Executor 的核心数目一起改变 –num-executors 这样他们都可以使用相同的 CPU 数目。这样,DJL 可以像 PyTorch 本身一样帮助用户进一步调优算力。
准确度测试
为了确保基于 DJL 的 PyTorch 解决方案与基于 Python 的 PyTorch 结果一致。TalkingData 数据科学组进行了严谨的比对测试。测试集大约 44 万条。下面是 PyTorch Python 与 DJL 的比对结果:
这个实验验证了 DJL 在推理应用上十分可靠,超过 99%的数据都是在 10^-7 以内的,换句话说,浮点数差别低于 0.0000001。我们同时也验证了最大偏差值的产生原因:是因为数据在传递过程中的精度损失导致的。
想了解更多关于 DJL 在 Spark 上的应用,可以参考 GitHub 上DJL Spark的案例,也可以参考这篇博客了解更多关于 Spark 的推理应用。
总结
TalkingData 现今已经在生产环境中使用 DJL 在 Apache Spark 上进行大规模的深度学习推理应用。他们选择 DJL 的几个主要原因 1)显著减少了很大的其他架构的维护成本 2)DJL 帮助 TalkingData 充分利用了已有的 Spark 算力 3)DJL 不局限于深度学习引擎,他们可以在很少改变代码的情况下,在未来新的任务上很轻松的部署任何深度学习模型。
关于 DJL

Deep Java Library (DJL) 是一个基于 Java 的深度学习框架,同时支持训练以及推理。DJL 博取众长,构建在多个深度学习框架之上 (TenserFlow, PyTorch, MXNet, etc)也同时具备多个框架的优良特性。你可以轻松使用 DJL 来进行训练然后部署你的模型。它同时拥有着强大的模型库支持:只需一行便可以轻松读取各种预训练的模型。现在 DJL 的模型库同时支持高达 70 个来自 GluonCV, HuggingFace, TorchHub 以及 Keras 的模型。
请参考我们的 GitHub, demo repository, Slack channel 以及知乎来获取更多信息!
作者介绍:
Qing Lan, AWS AI 软件开发工程师。DJL 深度学习框架作者之一,Apache 软件基金会项目管理委员会成员。
TalkingData 数据科学家,目前负责企业级用户画像平台的搭建以及高效营销投放算法的研发,长期关注互联网广告、用户画像、欺诈检测等领域。
本文转载自亚马逊 AWS 官方博客。
原文链接:




