
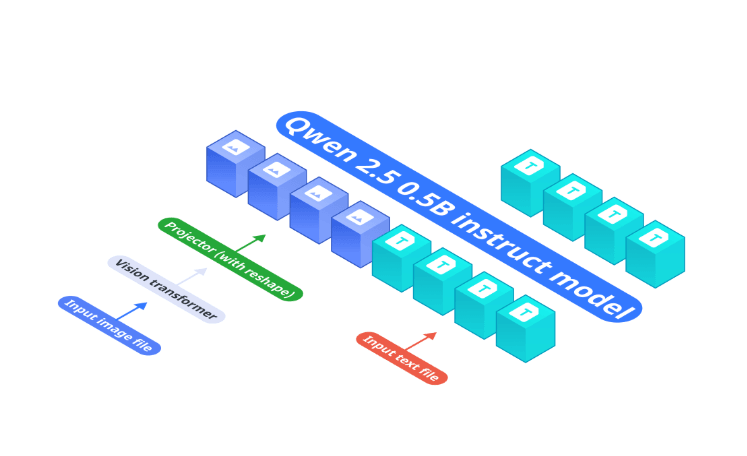
Nexa AI 发布 了专为边缘设备定制的紧凑型视觉语言模型 Omnivision。它将图像 token 从 729 个大幅减少到了 81 个,降低了延迟和计算要求,并且在视觉问答和图像字幕等任务中保持了强劲的性能。该模型的架构集成了语言中枢 Qwen-2.5-0.5B、SigLIP-400M 视觉编码器和经过优化的投影层,以确保可以无缝地处理多模态输入。
Omnivision 的架构专为高效的多模态处理而设计,具有三个核心组件。Qwen-2.5-0.5B 模型是处理文本输入的基础,而 SigLIP-400M 视觉编码器则从输入图像生成图像嵌入。该编码器的分辨率为 384,块大小为 14×14,优化了视觉数据提取。然后,投影层使用多层感知器(MLP)将图像嵌入与语言模型的 token 空间对齐,从而简化了视觉语言集成。
图片来源:Nexa AI 博客
Omnivision 的其中一项关键创新是将图像 token 减少了 9 倍,这样可以在不影响准确性的情况下降低处理要求。例如,Omnivision 可以在 MacBook M4 Pro 上用不到两秒的时间为高分辨率图像生成标题,所需的 RAM 不到 1GB。为了确保准确性和可靠性,它采用了直接偏好优化 (DPO),利用高质量数据集最大限度地减少幻觉,提高预测的可信度。
该模型的训练管道分为三个不同的阶段。预训练阶段主要是对齐视觉和文本输入,以建立基础能力。随后是监督微调,以增强模型解释上下文和生成相关响应的能力。最后,直接偏好优化 (DPO)通过最大限度地减少不准确性和提高特定上下文输出的精确度来完善决策。
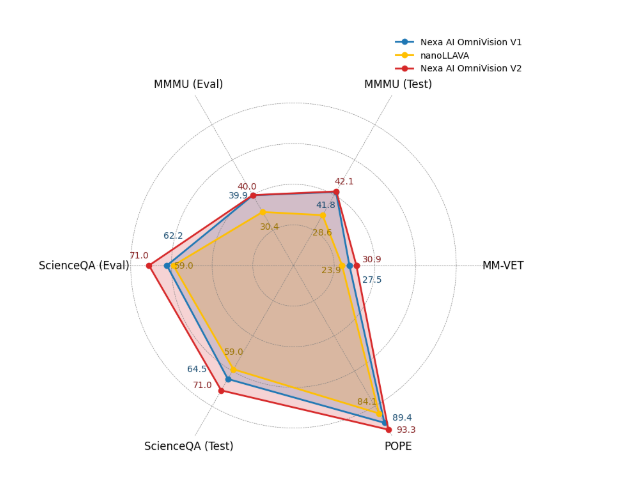
在基于 ScienceQA、MM-VET 和 POPE 等数据集的基准测试中,Omnivision 的性能优于其前身 nanoLLAVA。它取得了显著的进步,包括在 ScienceQA 测试数据上达到 71.0% 的准确率,在 POPE 基准测试中达到 93.3% 的准确率。这些证明了它在复杂推理任务中的可靠性。
图片来源:Nexa AI 博客
目前,Omnivision 专注于视觉问答和图像字幕。不过,据 Nexa AI 透露,他们计划扩展该模型的功能,以支持光学字符识别(OCR)。在最近的一次 Reddit 讨论中,AzLy 分享道:
目前,OCR 并不是该模型的预期用途之一。它主要用于视觉问答和图像字幕。不过,支持更好的 OCR 是我们的下一步工作。Omnivision 是一个开源框架,支持多种多模式任务,可以使用 Nexa-SDK 进行本地部署。该模型仍处于早期开发阶段,团队正在积极收集用户反馈,用于指导未来的改进工作。
查看原文链接:
https://www.infoq.com/news/2024/12/nexa-ai-unveils-omnivision/




