
文 | 王伟戌、王强强
背景
在深度学习火爆的今天,大规模数据下训练的大规模模型在线上任务中日益常见。随着大模型效果的提升, 随之带来了一些使用上的不便。通常情况下,大模型需要基于大量语料、文本训练,迭代周期长。且对于特定场景下词语在训练语料中出现次数不多,常常拟合不好。本文介绍的是关键词即特定场景语料,在序列到序列任务中通过构建状态转移自动机的方法改善最终效果的方案。
生成模型即生成模型解码
序列到序列模型常用于机器翻译、语音识别等任务。其架构提出于 2014 年[1],包含两个核心组件:编码器、解码器。本文中略去这种模型的训练过程,对该模型在使用过程中解码这一过程进行介绍:
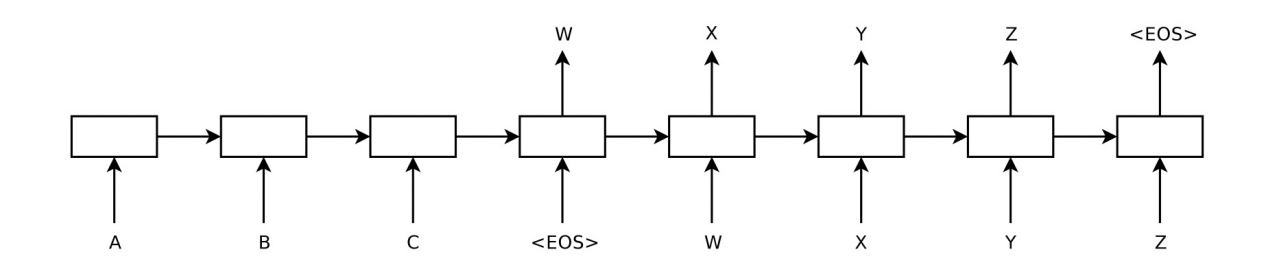
通过这个图我们不难发现,每个时刻的生成结果不仅于输入时刻序列有关,还与输出序列相关,一个简单的想法,将每个时刻置信度最高的结果存下来,做为下一个时刻输入,但这样很容易产生问题:在一个时刻缺乏全局视野,即某一个时刻最优不代表是全局最优的结果。而将所有结果都记录下来,这将会是指数级增长的数据量。因此一种 beam search 的方法被提出用来解决这一问题,我们用一个形象的例子来讲述 beam search 这一过程。
假设我们得到了一串拼音序列:
我们如何知道这个拼音序列代表什么意思呢?
如下图所示,我们展现了一个通过简单概率模型产生的文本,在第零个时刻的 5 个候选(为了展示方便,这里省略了编号为④的候选),在第一个时刻各产生了三个延伸在这 15 个候选中,通过语言模型概率选取了 top5 保留,剩余的舍弃掉,以达到缩减搜索空间的目的。通过这样的方法,每一个时刻不保留全部结果只保留 top N,最终将指数级增长的搜索空间变为平方级增长的搜索空间。
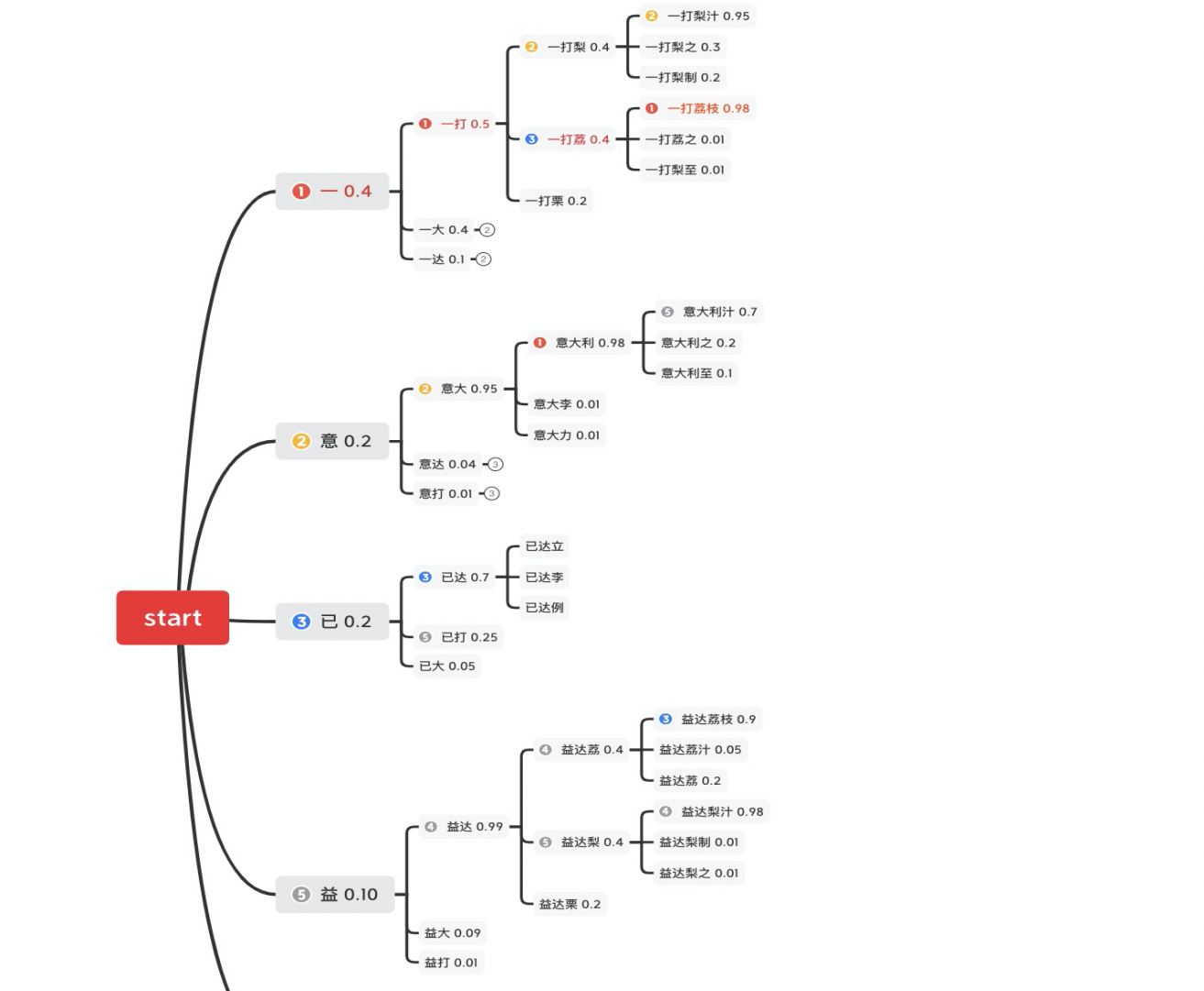
传统解码应用问题与改进
这种方法与全部状态保存的方案相比牺牲了准确度以换取时间,具有一定局限性。对于通常情况,每个时刻 top N 能覆盖当前时刻 90%以上的情况,但是这种方法在面对关键词检测、风控词语检测等任务会产生两个问题:
1、待检测关键字在日常语料中较少出现,传统 beam search 非常容易漏召回。
2、时效性强,经常有实时插入的新检测词语,要即时生效。
对于第一个问题,一种直观的思想是通过标注数据,弱标注数据等重新训练模型,但这显然迭代周期长且迭代预期不稳定。
Google 在 2018 年论文中[2],提出一种设计方案调整 beam search 的结果,即不重新训练模型,仅在解码时通过追加模型进行重新打分来改善对小众语料的拟合。
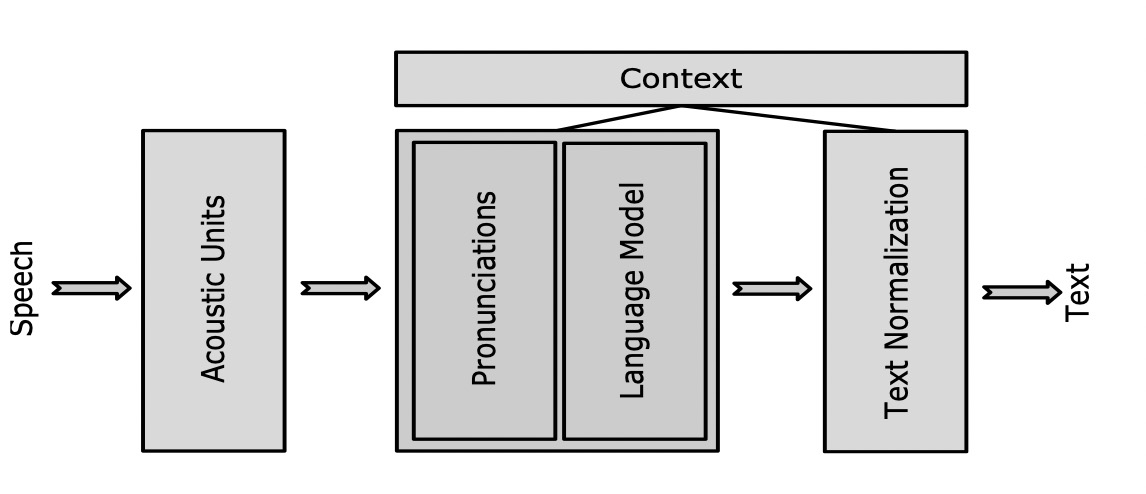
以上图中识别系统设计为例,除去传统声学识别模块还增加了上下文模块,这个模块举例了几个功能,包括标点,语言模型打分,文本归一。其中语言模型的使用如下图,用 beam search 对中间结果进行追加打分,更新 beam search 中 top N,并将当前结果作为下一时刻解码的输入。这种方式的优点是,在不更新语音识别模型的情况下,也可以通过添加不同语境的语言模型影响 beam search 过程中 top N 选取,从而达到改善结果的目的。缺点便是显著增加了计算量;尽管语言模型计算量常常不高,但 beam search 过程中每个候选结果都要多次经过语言模型,次数过多,耗时上升比较明显。
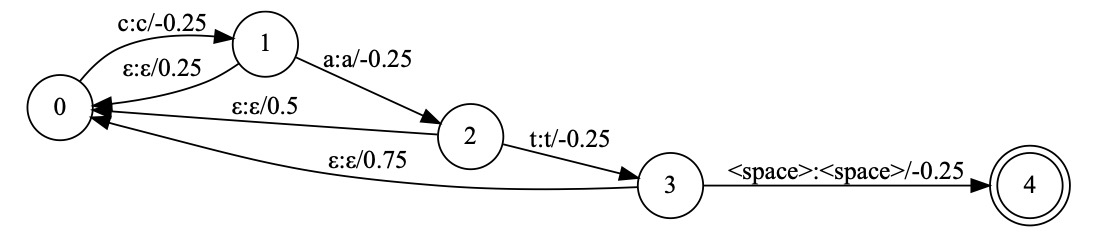
为了改进计算效率,经典 wfst 解码[3]方案重新在 seq2seq 模型中使用[4],这种解码方案注意到了我们是在一个序列过程中重打分,不需在每一个时刻对从开始至当前所有文本进行重新计算,我们将语言模型生成新的概率转移自动机[5],解码时,维护当前 beam search 过程中 top N 于图 2 状态。如下图为 cat(音标:kæt)这个单词的状态转移图,当声学识别模块产出 c 对应的 k 的音其转移到状态 1,而当 a 对应的æ产生时,不在需要从状态 0 计算 k æ一起的概率,而是计算当前状态 1 的后继状态中是否有æ。没有则计算回退到初始状态的概率。这样对于在序列生成中的计算,只需要记录其处于图中状态,在新的识别结果产生时对当前状态计算可行的转移状态即可。与普通语言模型相比,相当于省去了从状态 0 至当前状态的重复计算,复杂度大为降低。
这种浅融合的方案很好的解决了训练语料不均衡的问题,缺点是不能实时对图进行修改,且缺乏对特定词的加权,为此我们引入了前缀自动机来对这一过程改进。
基于前缀自动机的解码加权方案
前缀自动机,是一种经典算法,常应用于多模式串匹配。如果我们有一个字典,对于输入文本想检测是否命中字典中词语,这便是一个多模式串匹配任务。对于这类任务,一个显然的方案是遍历全部字典,但这样复杂度太高。
对此我们开始优化,一种方式是优化字典结构,即字典中字符有公共部分的比如 teach 和 teacher 都在字典中,那如果 teach 不匹配了,teacher 这个单词也不用匹配了。将顺序的字典变为前缀树的存储方式。
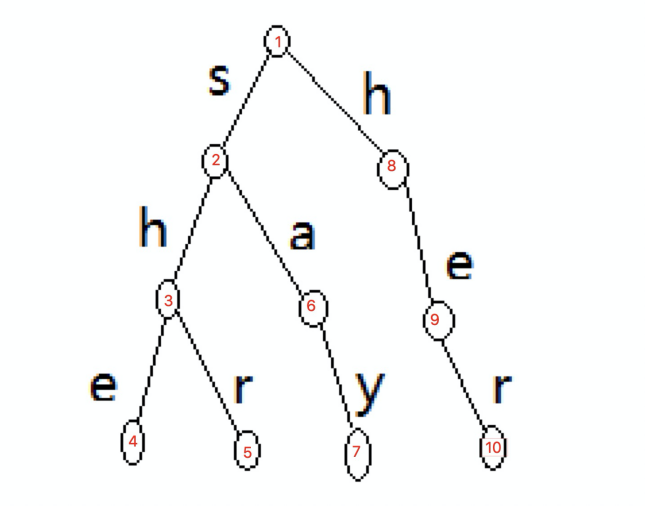
与此同时,我们继续在这种情况下优化,如果一个词前缀为另一个词的子串,如图 6 中 she 和 her,检测字符串 sher 中含有前缀树中多个词,当 she 在状态 4 匹配成功后我们知道 he 也是待匹配串中的,因此我们不需要跳回到状态 1,而是从 h 开始匹配,而是直接跳转至状态 9,从 r 开始匹配即可。便是前缀自动机的核心思想。
这种跳转关系构建方法是一种递归过程。用一句话来概括,一层一层的构建,如果我的父节点的跳转状态的子节点中有与我相同的,那就是我的跳转状态,否则我的跳转状态就是根结点。按照这个思路,我们将上图的点按遍历顺序重新标号以便于理解。
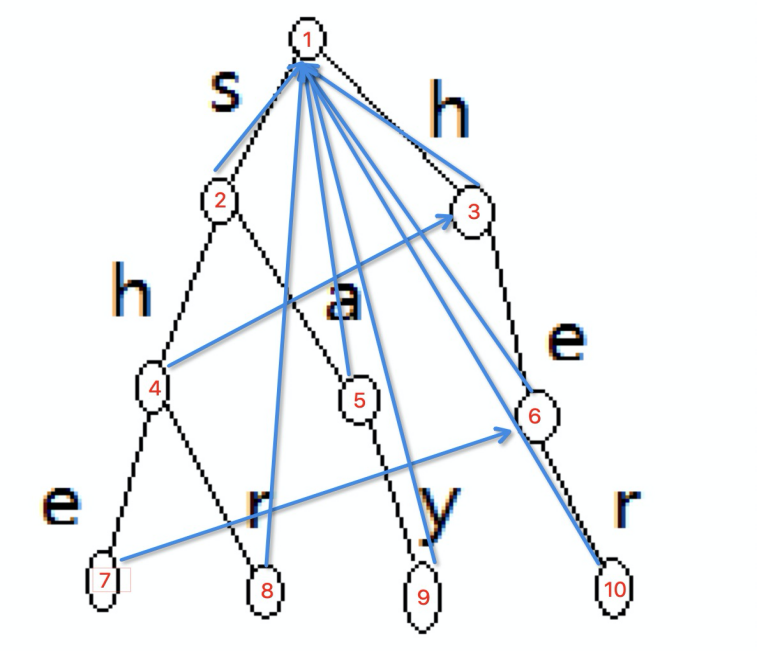
有了这个前缀转移关系,我们便能高效的处理热词构建及查询,一个带有前缀自动机的解码流程如下:

即对于每个 beam search 过程我们不仅维护 beam search 过程中结果,同时维护其处于前缀自动机状态;此状态便于维护,仅存储状态指针即可。从性能上看,执行时的额外计算量及内存使用量都可以认为是常数增加。
前缀自动机实时增加新词方案
前一段中我们介绍了通过前缀自动机的解码方案,但这一过程依然不能很好解决“实时”这一要求,如果我希望实时向解码过程中添加热词,需要怎么改进?
回顾上一节的内容,我们了解到前缀自动机构建应分为两步,即前缀树的构建与状态转移的构建。其中,前缀树是算法正确性的保证,而状态转移可以大幅优化时间。同时,状态转移需要层次遍历整棵前缀树,这意味转移状态的构建不能随前缀树形态更改而自动更改,而必须全量重新构建。
当我们插入一个新词,由于前缀树的特性,可以在字符长度的复杂度将该词插入前缀树,但是构建新的转移状态需要遍历所有节点,如果每次插入新词都要重新访问整棵树全部节点,这种复杂度是难以接受的。比较起来,损失一些转移状态等价于将部分词的查询复杂度变大,对比遍历全部词典的复杂度这种损失是可以接受的。
根据上述想法,我们将整体查询变为两棵树,一棵为带转移状态的前缀自动机,另一棵为普通字典树,当新词插入时我们在普通字典树插入,当普通字典树规模大于一规定阈值后我们将他们合并,并在合并后的树上构建转移状态。对于一次查询,复杂度从词长变为小字典树规模,但能够节省构建转移状态遍历全文的时间。
方案效果
我在语音识别系统中应用了这种解码方案,并通过两方面指标评估该模块效果,一方面通过标注带关键词语音数据集,评估关键词准召。在下表中,beam search 代表普通方案,ac automation 代表前缀自动机加权解码方案,发现在识别结果中对关键词召回相对提升 4.6%。另外,我们对比在普通语音识别数据集上字错误率(CER),由于对特殊词提升了权重使整体准确率有一定的下降,但整体损失可以接受,低于对关键词召回的收益。

总结
本文主要基于 seq2seq 类模型,通过追加状态转移自动机来减少模型在面对专有领域语料时的识别准确率;同时可以使语料实时生效,并将该工作的实时性流程构建方法加以介绍。对于语音转录文本中的关键词检测,常常局限于语音模型不能实时调整,很难识别出新词,通过这种方案可以做到秒级别新词添加,显著改变这一困扰。
参考文献:
[1] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems 27 (2014).
[2] Zhao, Ding, et al. "Shallow-Fusion End-to-End Contextual Biasing." Interspeech. 2019.
[3] Hori T, Hori C, Minami Y, et al. Efficient WFST-based one-pass decoding with on-the-fly hypothesis rescoring in extremely large vocabulary continuous speech recognition[J]. IEEE Transactions on audio, speech, and language processing, 2007, 15(4): 1352-1365.
[4] Williams I, Kannan A, Aleksic P S, et al. Contextual Speech Recognition in End-to-end Neural Network Systems Using Beam Search[C]//Interspeech. 2018: 2227-2231.
[5] Hori T, Nakamura A. Speech recognition algorithms using weighted finite-state transducers[J]. Synthesis Lectures on Speech and Audio Processing, 2013, 9(1): 1-162.
[6] https://blog.csdn.net/weixin_53360179/article/details/119718426




