
控制理论中的可观测性是指:系统可以由其外部输出确定其内部状态的程度。在复杂 IT 系统中,具备可观测性是为了让系统能达到某个预定的稳定性、错误率目标。随着微服务数量的急速膨胀和云原生基础设施的快速演进,建设可观测性已经成为了保障业务稳定性的必要条件。
然而,传统的 APM 无法实现真正的可观测性:一方面插桩行为已经修改了原程序,逻辑上已无法实现原程序的可观测性;另一方面云原生基础设施组件越来越多,基础服务难以插桩导致观测盲点越来越多。实际上,插桩的方式在金融、电信等重要行业的核心业务系统中几乎无法落地。eBPF 由于其零侵扰的优势,避免了 APM 插桩的缺点,是云原生时代实现可观测性的关键技术。
本文依次论述 APM 无法实现真正可观测性的原因,分析为什么 eBPF 是可观测性的关键技术,介绍 DeepFlow 基于 eBPF 的三大核心功能,并进一步阐述如何向 eBPF 的观测数据中注入业务语义。在此之后,本文分享了 DeepFlow 用户的九大类真实使用案例,总结了用户在采用 eBPF 技术前的常见疑问。最后,本文进一步分析了 eBPF 对新技术迭代的重大意义。同时,欢迎大家报名参与 9 月 16 日 DeepFlow 开展的线下活动《可观测性 Meetup》。
使用 APM 无法实现真正的可观测性
APM 希望通过代码插桩(Instrumentation)的方式来实现应用程序的可观测性。利用插桩,应用程序可以暴露非常丰富的观测信号,包括指标、追踪、日志、函数性能剖析等。然而插桩的行为实际上改变了原始程序的内部状态,从逻辑上并不符合可观测性「从外部数据确定内部状态」的要求。在金融、电信等重要行业的核心业务系统中,APM Agent 落地非常困难。进入到云原生时代,这个传统方法也面临着更加严峻的挑战。总的来讲,APM 的问题主要体现在两个方面:Agent 的侵扰性导致难以落地,观测盲点导致无法定界。
第一,探针侵扰性导致难以落地。插桩的过程需要对应用程序的源代码进行修改,重新发布上线。即使例如 Java Agent 这类字节码增强技术,也需要修改应用程序的启动参数并重新发版。然而,对应用代码的改造还只是第一道关卡,通常落地过程中还会碰到很多其他方面的问题:
代码冲突:当你为了分布式追踪、性能剖析、日志甚至服务网格等目的注入了多个 Java Agent 时,是否经常遇到不同 Agent 之间产生的运行时冲突?当你引入一个可观测性的 SDK 时,是否遇到过依赖库版本冲突导致无法编译成功?业务团队数量越多时,这类兼容性问题的爆发会越为明显。
维护困难:如果你负责维护公司的 Java Agent 或 SDK,你的更新频率能有多高?就在此时,你们公司的生产环境中有多少个版本的探针程序?让他们更新到同一个版本需要花多长时间?你需要同时维护多少种语言的探针程序?当企业的微服务框架、RPC 框架无法统一时,这类维护问题还将会更加严重。
边界模糊:所有的插桩代码严丝合缝的进入了业务代码的运行逻辑中,不分你我、不受控制。这导致当出现性能衰减或运行错误时,插桩代码往往难辞其咎。即使探针已经经过了长时间的实战打磨,遇到问题时也免不了要求排除嫌疑。
实际上,这也是为什么侵扰性的插桩方案少见于成功的商业产品,更多见于活跃的开源社区。OpenTelemetry、SkyWalking 等社区的活跃正是佐证。而在部门分工明确的大型企业中,克服协作上的困难是一个技术方案能够成功落地永远也绕不开的坎。特别是在金融、电信、电力等承载国计民生的关键行业中,部门之间的职责区分和利益冲突往往会使得落地插桩式的解决方案成为「不可能」。即使是在开放协作的互联网企业中,也少不了开发人员对插桩的不情愿、运维人员在出现性能故障时的背锅等问题。在经历了长久的努力之后人们已经发现,侵入性的解决方案仅仅适合于每个业务开发团队自己主动引入、自己维护各类 Agent 和 SDK 的版本、自己对性能隐患和运行故障的风险负责。当然,我们也看到了一些得益于基建高度统一而取得成功的大型互联网公司案例,例如 Google 就在 2010 年的 Dapper 论文中坦言:
True application-level transparency, possibly our most challenging design goal, was achieved by restricting Dapper’s core tracing instrumentation to a small corpus of ubiquitous threading, control flow, and RPC library code.
再例如字节跳动在 2022 年的对外分享《分布式链路追踪在字节跳动的实践》中也表示:
得益于长期的统一基建工作,字节全公司范围内的所有微服务使用的底层技术方案统一度较高。绝大部分微服务都部署在公司统一的容器平台上,采用统一的公司微服务框架和网格方案,使用公司统一提供的存储组件及相应 SDK。高度的一致性对于基础架构团队建设公司级别的统一链路追踪系统提供了有利的基础。
第二,观测盲点导致无法定界。即使 APM 已经在企业内落地,我们还是会发现排障边界依然难以界定,特别是在云原生基础设施中。这是因为开发和运维往往使用不同的语言在对话,例如当调用时延过高时开发会怀疑网络慢、网关慢、数据库慢、服务端慢,但由于全栈可观测性的缺乏,网络、网关、数据库给出的应答通常是网卡没丢包、进程 CPU 不高、DB 没有慢日志、服务端时延很低等一大堆毫无关联的指标,仍然解决不了问题。定界是整个故障处理流程中最关键的一环,它的效率至关重要。
这里我们想澄清两个概念:排障边界和职责边界。虽然开发的职责边界是应用程序本身,但排障边界却需要延展到网络传输上。举个例子:微服务在请求 RDS 云服务时偶现高达 200ms 的时延,如果开发以此为依据向云服务商提交工单,得到的应答大概率会是「RDS 没有观察到慢日志,请自查」。我们在很多客户处碰到了大量此类案例,根因有的是 RDS 前的 SLB 导致、有的是 K8s Node 的 SNAT 导致,背后的原因千奇百怪,但若不能在第一时间完成故障定界,都会导致租户(开发)和云服务商(基础设施)之间长达数天乃至数周的工单拉锯战。从排障边界的角度来讲,若开发能给出「网卡发送请求到收到响应之间的时延高达 200ms」,就能快速完成定界,推动云服务商排查。找对了正确的人,之后的问题解决一般都非常快。我们在后文也会分享几个真实案例。
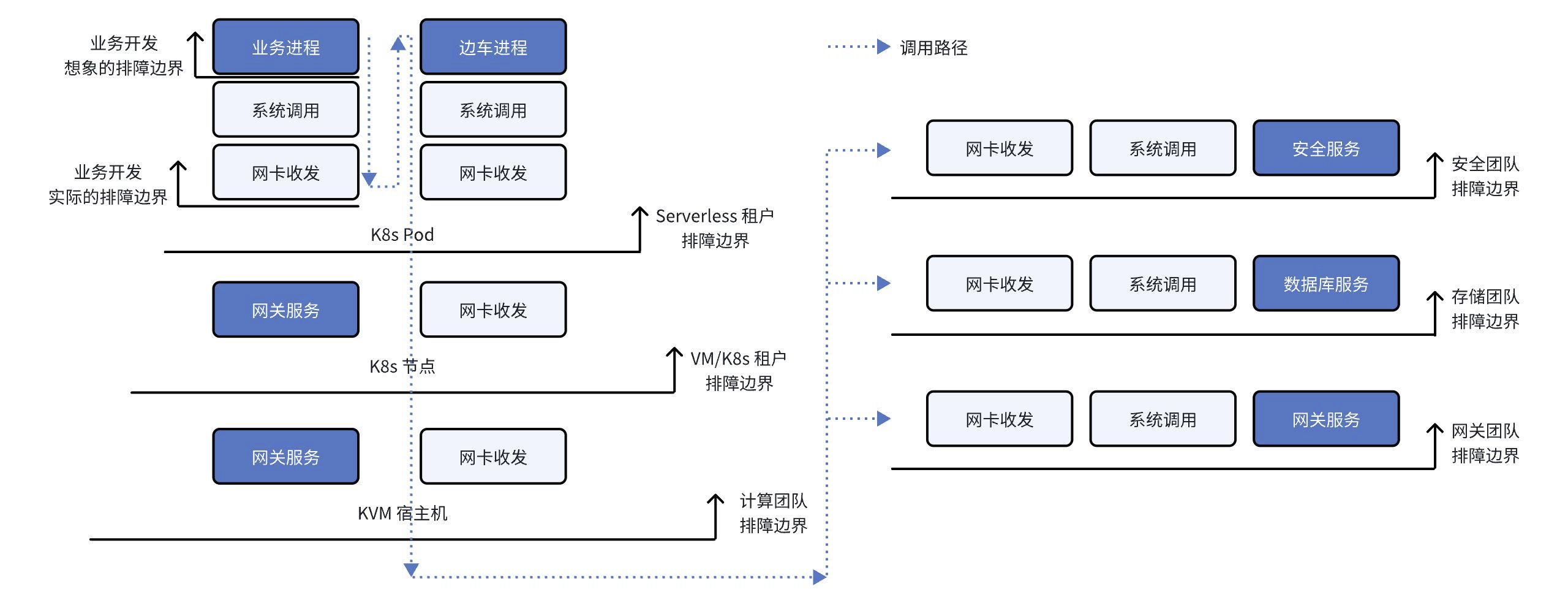
上图中我们对不同场景下的排障边界进行了总结:如果你是一个业务开发工程师,除了业务本身以外,还应该关心系统调用和网络传输过程;如果你是一个 Serverless 租户,你可能还需要关注服务网格边车及其网络传输;如果你直接使用虚拟机或自建 K8s 集群,那么容器网络是需要重点关注的问题点,特别还需注意 K8s 中的 CoreDNS、Ingress Gateway 等基础服务;如果你是私有云的计算服务管理员,应该关心 KVM 宿主机上的网络性能;如果你是私有云的网关、存储、安全团队,也需要关注服务节点上的系统调用和网络传输性能。
实际上更为重要的是,用于故障定界的数据应该使用类似的语言进行陈述:一次应用调用在整个全栈路径中,每一跳到底消耗了多长时间。通过上述分析我们发现,开发者通过插桩提供的观测数据,可能只占了整个全栈路径的 1/4。在云原生时代,单纯依靠 APM 来解决故障定界,本身就是妄念。
eBPF 是可观测性的关键技术
本文假设你对 eBPF 有了基础的了解,它是一项安全、高效的通过在沙箱中运行程序以实现内核功能扩展的技术,是对传统的修改内核源代码和编写内核模块方式的革命性创新。你可访问 ebpf.io 以了解更多的 eBPF 相关知识,本文聚焦于讨论 eBPF 对云原生应用可观测性的革命性意义。
eBPF 程序是事件驱动的,当内核或用户程序经过一个 eBPF Hook 时,对应 Hook 点上加载的 eBPF 程序就会被执行。Linux 内核中预定义了一系列常用的 Hook 点,你也可以利用 kprobe 和 uprobe 技术动态增加内核和应用程序的自定义 Hook 点。得益于 Just-in-Time (JIT) 技术,eBPF 代码的运行效率可媲美内核原生代码和内核模块。得益于 Verification 机制,eBPF 代码将会安全的运行,不会导致内核崩溃或进入死循环。
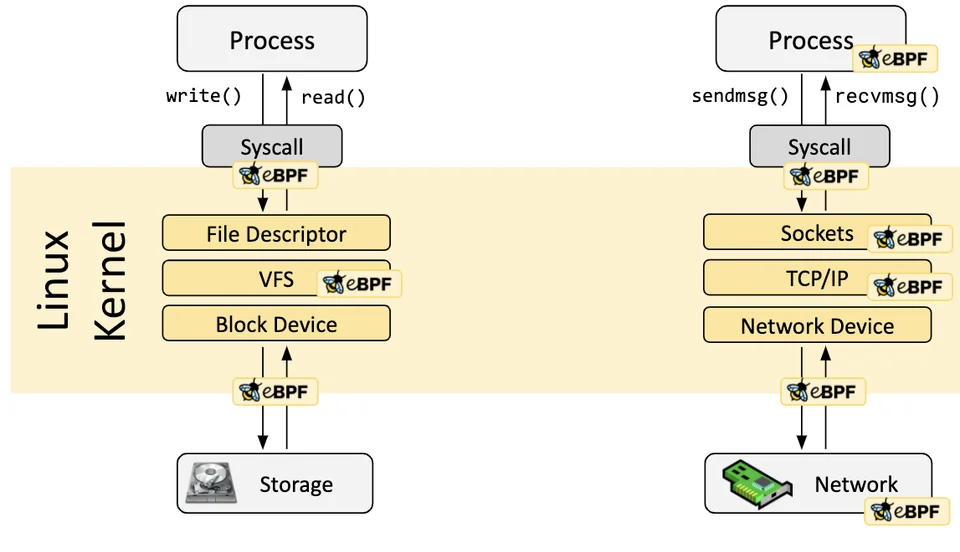
回到可观测性上,沙箱机制是 eBPF 有别于 APM 插桩机制的核心所在,「沙箱」在 eBPF 代码和应用程序的代码之间划上了一道清晰的界限,使得我们能在不对应用程序做任何修改的前提下,通过获取外部数据就能确定其内部状态。下面我们来详细分析下为何 eBPF 是解决 APM 代码插桩缺陷的绝佳解决方案:
第一,零侵扰解决落地难的问题。由于 eBPF 程序无需修改应用程序代码,因此不会有类似 Java Agent 的运行时冲突和 SDK 的编译时冲突,解决了代码冲突问题;由于运行 eBPF 程序无需改变和重启应用进程,不需要应用程序重新发版,不会有 Java Agent 和 SDK 的版本维护痛苦,解决了维护困难问题;由于 eBPF 在 JIT 技术和 Verification 机制的保障下高效安全的运行,因此不用担心会引发应用进程预期之外的性能衰减或运行时错误,解决了边界模糊问题。另外从管理层面,由于只需要在每个主机上运行一个独立的 eBPF Agent 进程,使得我们可以对它的 CPU 等资源消耗进行单独的、精确的控制。
第二,全栈能力解决故障定界难的问题。eBPF 的能力覆盖了从内核到用户程序的每一个层面,因此我们得以跟踪一个请求从应用程序出发,经过系统调用、网络传输、网关服务、安全服务,到达数据库服务或对端微服务的全栈路径,提供充足的中立观测数据,快速完成故障的定界。
然而,eBPF 并不是一个易于掌握的技术,它需要开发者有一定的内核编程基础,它获取的原始数据缺乏结构化信息。下文将会以我们的产品 DeepFlow 为例,介绍如何扫清这些障碍,充分发挥 eBPF 对可观测性工程的关键作用。
DeepFlow 基于 eBPF 的三大核心功能
DeepFlow [GitHub] 旨在为复杂的云原生应用提供简单可落地的深度可观测性。DeepFlow 基于 eBPF 和 Wasm 技术实现了零侵扰(Zero Code)、全栈(Full Stack)的指标、追踪、调用日志、函数剖析数据采集,并通过智能标签技术实现了所有数据的全关联(Universal Tagging)和高效存取。使用 DeepFlow,可以让云原生应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 DevOps/SRE 团队提供从代码到基础设施的监控及诊断能力。
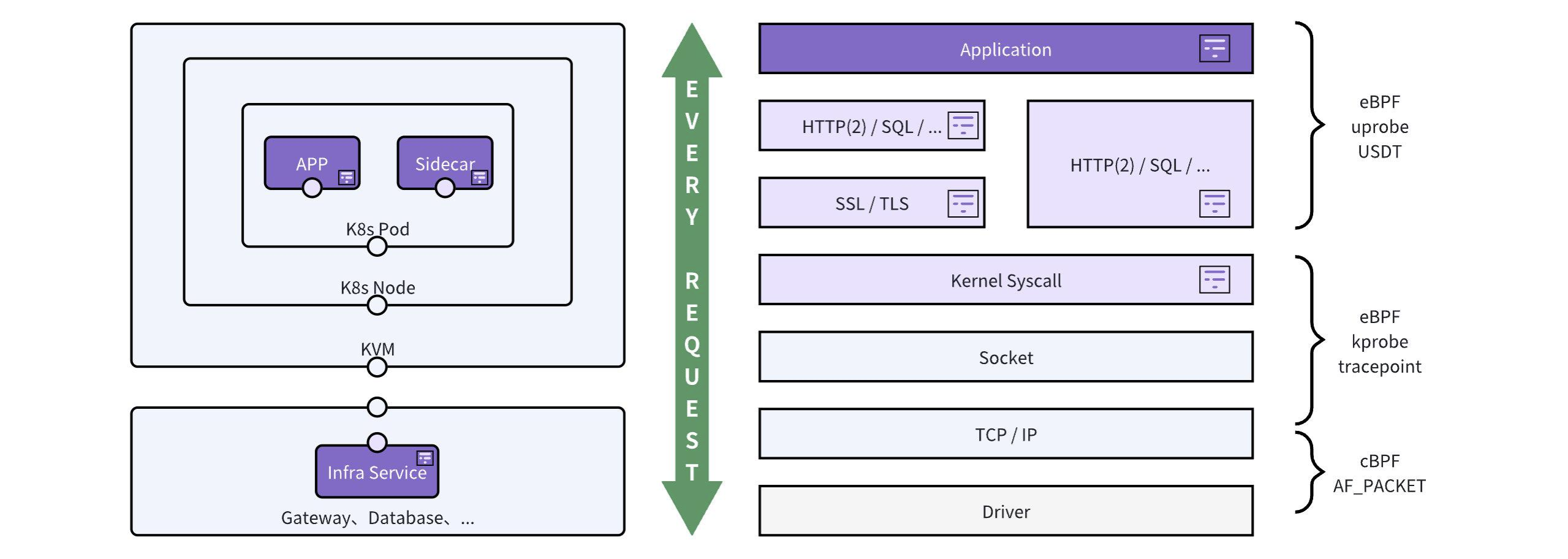
通过利用 eBPF 和 cBPF 采集应用函数、系统调用函数、网卡收发的数据,DeepFlow 首先聚合成 TCP/UDP 流日志(Flow Log);通过应用协议识别,DeepFlow 聚合得到应用调用日志(Request Log),进而计算出全栈的 RED(Request/Error/Delay)性能指标,并关联调用日志实现分布式追踪。除此之外,DeepFlow 在流日志聚合过程中还计算了 TCP 吞吐、时延、建连异常、重传、零窗等网络层性能指标,以及通过 Hook 文件读写操作计算了 IO 吞吐和时延指标,并将所有这些指标关联至每个调用日志上。另外,DeepFlow 也支持通过 eBPF 获取每个进程的 OnCPU、OffCPU 函数火焰图,以及分析 TCP 包绘制 Network Profile 时序图。所有这些能力最终体现为三大核心功能:
Universal Map for Any Service,任意服务的全景图
Distributed Tracing for Any Request,任意调用的分布式追踪
Continuous Profiling for Any Function,任何函数的持续性能剖析

核心功能一:任意服务的全景图。全景图直接体现出了 eBPF 零侵扰的优势,对比 APM 有限的覆盖能力,所有的服务都能出现在全景图中。但 eBPF 获取的调用日志不能直接用于拓扑展现,DeepFlow 为所有的数据注入了丰富的标签,包括云资源属性、K8s 资源属性、自定义 K8s 标签等。通过这些标签可以快速过滤出指定业务的全景图,并且可以按不同标签分组展示,例如 K8s Pod、K8s Deployment、K8s Service、自定义标签等。全景图不仅描述了服务之间的调用关系,还展现了调用路径上的全栈性能指标,例如下图右侧为两个 K8s 服务的进程在相互访问时的逐跳时延变化。我们可以很快的发现性能瓶颈到底位于业务进程、容器网络、K8s 网络、KVM 网络还是 Underlay 网络。充足的中立观测数据是快速定界的必要条件。
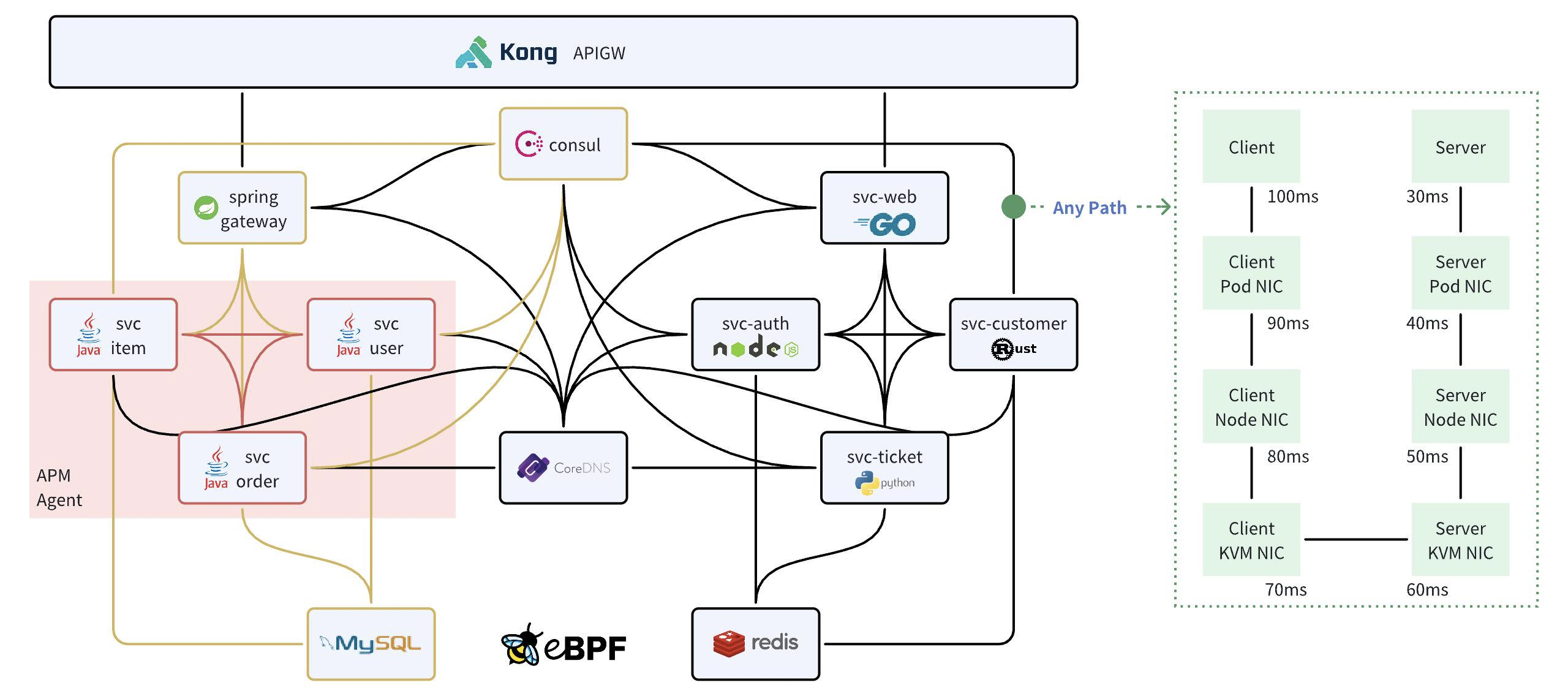
核心功能二:任意调用的分布式追踪。零侵扰的分布式追踪(AutoTracing)是 DeepFlow 中的一个重大创新,在通过 eBPF 和 cBPF 采集调用日志时,DeepFlow 基于系统调用上下文计算出了 syscall_trace_id、thread_id、goroutine_id、cap_seq、tcp_seq 等信息,无需修改应用代码、无需注入 TraceID、SpanID 即可实现分布式追踪。目前 DeepFlow 除了跨线程(通过内存 Queue 或 Channel 传递信息)和异步调用以外,都能实现零侵扰的分布式追踪。此外也支持解析应用注入的唯一 Request ID(例如几乎所有网关都会注入 X-Request-ID)来解决跨线程和异步的问题。下图对比了 DeepFlow 和 APM 的分布式追踪能力。APM 仅能对插桩的服务实现追踪,常见的是利用 Java Agent 覆盖 Java 服务。DeepFlow 使用 eBPF 实现了所有服务的追踪,包括 Nginx 等 SLB、Spring Cloud Gateway 等微服务网关、Envoy 等 Service Mesh 边车,以及 MySQL、Redis、CoreDNS 等基础服务(包括它们读写文件的耗时),除此之外还覆盖了 Pod NIC、Node NIC、KVM NIC、物理交换机等网络传输路径,更重要的是对 Java、Golang 以及所有语言都可无差别支持。
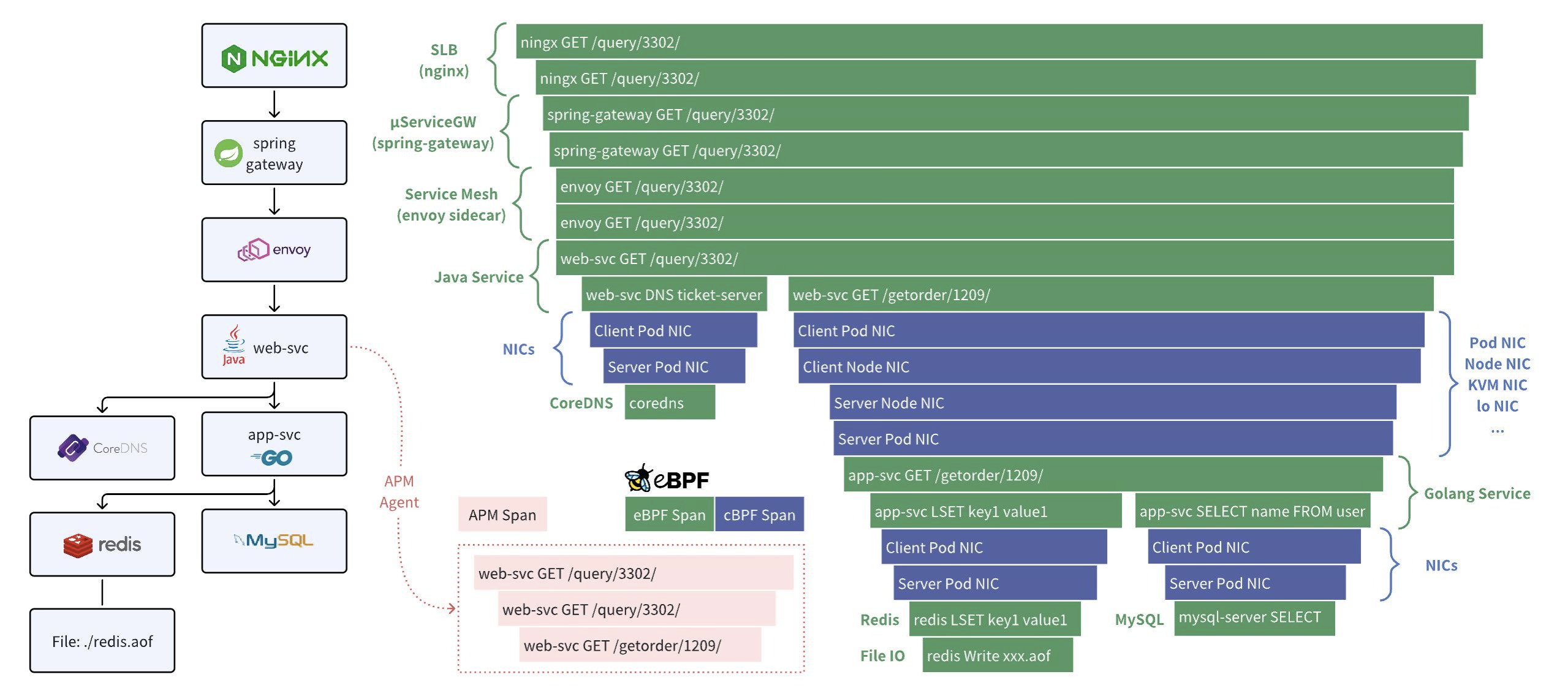
注意 eBPF 和 APM 的分布式追踪能力并不是矛盾的。APM 能用于追踪应用进程内部的函数调用路径,也擅长于解决跨线程和异步场景。而 eBPF 有全局的覆盖能力,能轻松覆盖网关、基础服务、网络路径、多语言服务。在 DeepFlow 中,我们支持调用 APM 的 Trace API 以展示 APM + eBPF 的全链路分布式追踪图,同时也对外提供了 Trace Completion API 使得 APM 可调用 DeepFlow 以获取并关联 eBPF 的追踪数据。
核心功能三:任意函数的持续性能剖析。通过获取应用程序的函数调用栈快照,DeepFlow 可绘制任意进程的 CPU Profile,帮助开发者快速定位函数性能瓶颈。函数调用栈中除了包含业务函数以外,还可展现动态链接库、内核系统调用函数的耗时情况。除此之外,DeepFlow 在采集函数调用栈时生成了唯一标识,可用于与调用日志相关联,实现分布式追踪和函数性能剖析的联动。特别地,DeepFlow 还利用 cBPF 对网络中的逐包进行了分析,使得在低内核环境中可以绘制每个 TCP 流的 Network Profile,剖析其中的建连时延、系统(ACK)时延、服务响应时延、客户端等待时延。使用 Network Profile 可推断应用程序中性能瓶颈的代码范围,我们在后文中也会分享相关案例。

本文无法完整的解释这些激动人心的特性背后的原理,DeepFlow 同时也是一个开源项目,您可以阅读我们的 GitHub 代码和文档了解更多信息,也可阅读我们发表在网络通信领域顶级会议 ACM SIGCOMM 2023 上的论文 Network-Centric Distributed Tracing with DeepFlow: Troubleshooting Your Microservices in Zero Code。
向 eBPF 观测数据中注入业务语义
使用 APM Agent 的另一个诉求是向数据中注入业务语义,例如一个调用关联的用户信息、交易信息,以及服务所在的业务模块名称等。从 eBPF 采集到的原始字节流中很难用通用的方法提取业务语义,在 DeepFlow 中我们实现了两个插件机制来弥补这个不足:通过 Wasm Plugin 注入调用粒度的业务语义,通过 API 注入服务粒度的业务语义。
第一、通过 Wasm Plugin 注入调用粒度的业务语义:DeepFlow Agent 内置了常见应用协议的解析能力,且在持续迭代增加中,下图中蓝色部分均为原生支持的协议。我们发现实际业务环境中情况会更加复杂:开发会坚持返回 HTTP 200 同时将错误信息放到自定义 JSON 结构中,大量 RPC 的 Payload 部分使用 Protobuf、Thrift 等依赖 Schema 进行解码的序列化方式,调用的处理流程中发生了跨线程导致 eBPF AutoTracing 断链。为了解决这些问题 DeepFlow 提供了 Wasm Plugin 机制,支持开发者对 Pipeline 中的 ProtocolParser 进行增强。
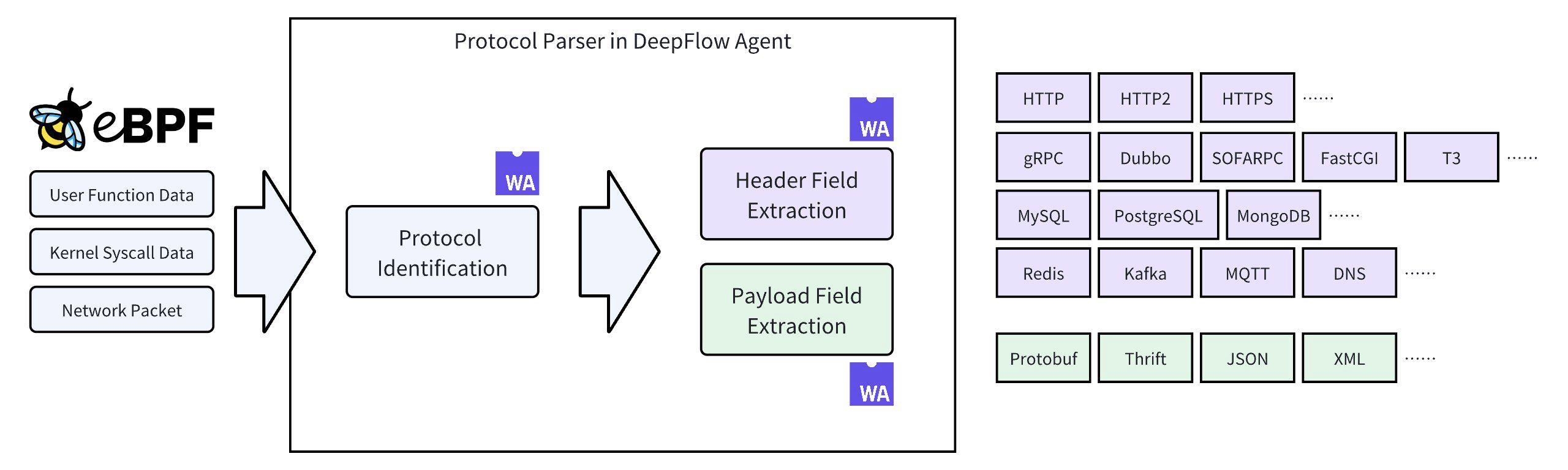
实际上,我们也观察到在金融、电信、游戏等行业中,已经存在了「天然」的分布式追踪标记,例如金融业务中的全局交易流水号,电信核心网中的呼叫 ID、游戏业务中的业务请求 ID 等等。这些 ID 会携带在所有调用中,但具体的位置是业务自身决定的。通过 Wasm Plugin 释放的灵活性,开发者可以很容易的编写插件支持将这些信息提取为 TraceID。
第二、通过 API 注入服务粒度的业务语义:默认情况下,DeepFlow 的 SmartEncoding 机制会自动为所有观测信号注入云资源、容器 K8s 资源、K8s 自定义 Label 标签。然而这些标签体现的只是应用层面的语义,为了帮助用户将 CMDB 等系统中的业务语义注入到观测数据中,DeepFlow 提供了一套用于业务标签注入的 API。
DeepFlow 用户的实战案例
在本章节中,我们将为大家分享 DeepFlow 用户的九大类实战案例。这些案例都是一些难以提前预料的疑难杂症,我们将会看到在仅有 APM 数据时,它们通常持续了数天甚至数周都还找不到方向,而依靠 eBPF 的能力往往能在 5 分钟之内完成故障定界。在开始介绍它们之前我还想澄清一下,这并不意味着 eBPF 的能力只擅长于解决疑难杂症,我们现在已经知道 eBPF 能够零侵扰的采集 Metrics、Request Logs、Profiles 等观测信号,DeepFlow 也已经基于这些信号实现了通用的全景图(包括性能指标、调用日志等)、分布式追踪、持续性能剖析功能。
第一类案例,快速定位引发问题的服务:
案例 1:5 分钟定位访问共享服务的 Top 客户端。MySQL、Redis、Consul 等基础设施通常被很多微服务共享使用,当它们的负载过高时通常很难判断是哪些客户端造成的。这是因为容器 Pod 访问这些共享服务时通常会做 SNAT,服务端看到的是容器节点的 IP;非容器环境下每个主机上也会有大量进程共享使用主机的 IP。可以想象从服务端的调用日志中分析 IP 地址是十分低效的,而我们也不能寄期望于所有客户端都注入了 APM Agent。使用 DeepFlow,我们的一个大型银行客户在 5 分钟内从近十万个 Pod 中快速定位了请求 RDS 集群最高频的微服务,我们的一个智能汽车客户在 5 分钟内从上万个 Pod 中快速定位了请求 Consul 最高频的微服务。
案例 2:5 分钟定位被忽视的共享服务。DeepFlow 的一个大型银行客户在进行「分布式核心交易系统」上线测试时,发现由物理环境迁移到私有云上的交易系统性能非常差。经过了两周的排查、在注入了一大堆 APM Agent 以后,最终只能定位到问题位于名为 cr****rs 的服务访问授权交易服务 au****in 的链路上,但这两个服务在迁移上云之前没有任何性能问题。开发团队一度开始怀疑私有云基础设施,但没有任何数据支撑。毫无头绪时找到了 DeepFlow 团队,在部署 eBPF Agent 以后所有微服务之间的访问关系和性能指标全部呈现在了眼前,立即发现了在 cr****rs 访问授权交易服务 au****in 时,还会经过 Spring Cloud Gateway,而后者正在以极高的速率请求服务注册中心 Consul。至此问题明确了,这是由于网关的缓存配置不合理,导致服务注册中心成为了瓶颈。
案例 3:5 分钟定位被忽视的背景压力。在软件开发过程中,压力测试环境通常由多人共享,甚至开发、测试等多个团队也会使用同一套压测环境。DeepFlow 的一个智能汽车客户的测试人员在压测某服务中,发现总是有少量的 HTTP 5XX 错误出现,而这将直接导致一次压测结果作废。正当测试人员一筹莫展时,打开 DeepFlow 全景图后马上发现还有其他服务正在以不可忽视的速率访问着被测服务。

第二类案例,快速定界访问托管服务的故障:
案例 1:5 分钟定界托管云服务故障 - SLB 会话迁移。由于托管服务无法插桩,以往通常会给故障排查带来困难。DeepFlow 的一个智能汽车客户,充电业务每 10min 发生一次高时延现象。通过 APM Agent 只能定位到问题由充电核心服务访问 RDS 导致,但公有云服务商在仔细检查慢日志和 RDS 性能指标之后关闭了工单,因为没有发现任何异常。这个问题持续了一周仍未解决,而通过 DeepFlow 的全栈指标数据,清晰的看到故障发生时从系统调用、Pod 网卡、Node 网卡观测到的 RDS 访问时延均超过了 200ms,并伴随着网络指标中的「服务端 RST」数量激增。这些数据使得公有云服务商重新开始排查此问题,最终发现 RDS 之前的 SLB 集群在高并发时触发会话迁移导致了此问题。可以看到全栈可观测性是跨团队排查问题的关键。
案例 2:5 分钟定界托管云服务故障 - K8s SNAT 冲突。这个案例中同样也出现了 SLB,但根因大不相同。DeepFlow 的一个智能汽车客户,车控服务在访问账户服务时偶发超时,每个 Pod 每天发生 7 次。公有云服务商同样也没有看到任何 SLB 异常指标,此工单持续一个月仍未解决。查看 DeepFlow 全景图之后又一次快速完成了定界,可以看到故障发生时网络指标中的「建连异常」数量激增,进一步查看关联的流日志发现此时 TCP 连接的失败原因为「SNAT 端口冲突」。可以看到即使对于「没有调用日志」的超时类故障,利用全栈性能指标也能快速定界故障原因。

第三类案例,快速定界各类网关和云基础设施的问题:
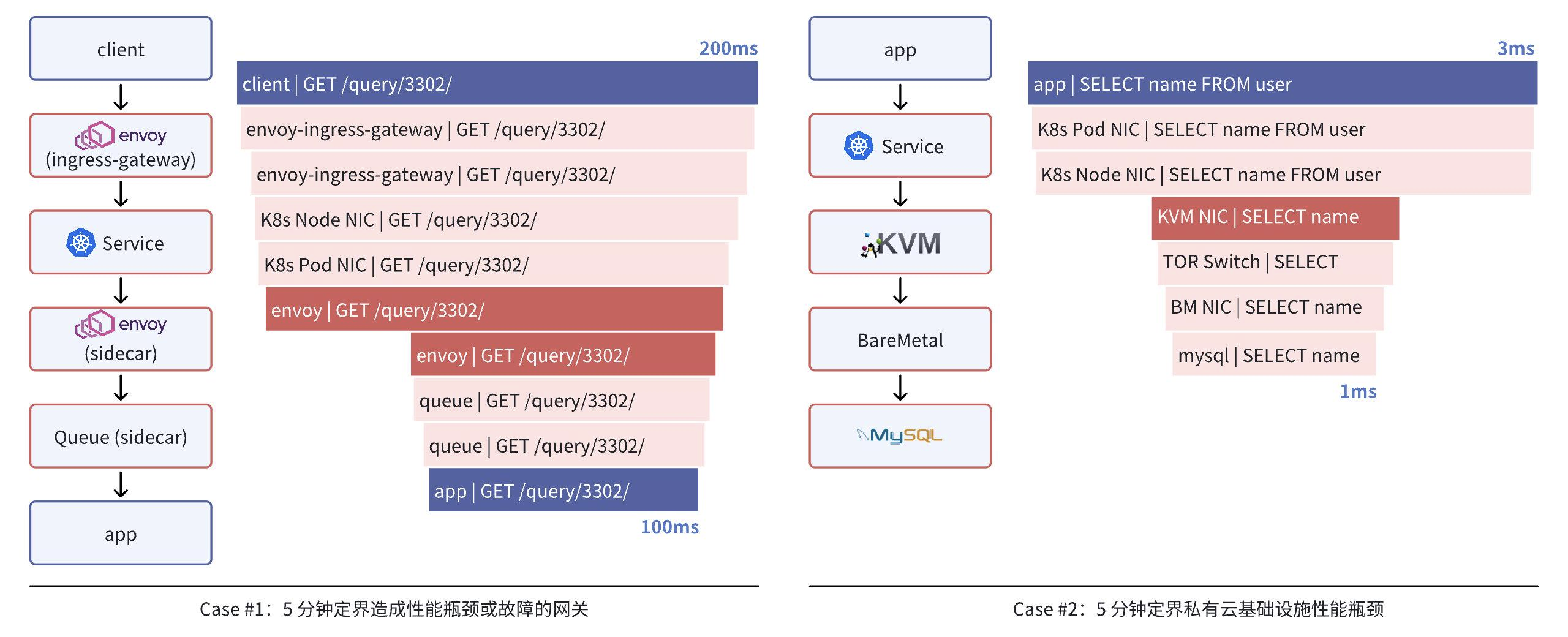
案例 1:5 分钟定界造成性能瓶颈或故障的网关。为了集中实现负载均衡、安全审计、微服务拆分、限流和熔断等功能,云原生基础设施中通常会部署各类网关。DeepFlow 的一个游戏客户使用 KNative 作为 Serverless 基础设施,在该环境下任何一个客户端在访问微服务时,都要穿越 Envoy Ingress Gateway、K8s Service、Envoy Sidecar、Queue Sidecar 共四种网关。当客户端侧的调用时延远高于服务端侧的调用时延,或者发生 HTTP 5XX 调用故障时,以往客户主要通过检索日志文件、tcpdump 抓包来排查问题,而利用 DeepFlow 可以在 5 分钟内定位网关路径上的性能瓶颈或故障位置。例如某一次就快速发现了 Envoy Sidecar 配置不合理导致的慢请求问题。
案例 2:5 分钟定界私有云基础设施性能瓶颈。DeepFlow 的一个大型银行客户在「分布式核心交易系统」上线私有云之前进行了大量的性能测试,期间发现 K8s 集群中的微服务访问裸金属服务器上的 MySQL 服务时,客户端侧的时延(3ms)与 DBA 团队看到的时延(1ms)有较大的差距,这意味着整个过程中基础设施的耗时占了 67%,但并不清楚具体是哪个环节引入的。通过 DeepFlow 可以看到,整个访问过程中的主要时延消耗在 KVM 宿主机上。这些数据反馈到私有云供应商以后进行了快速的排查,发现该环境下宿主机使用了 ARM CPU 和 SRIOV 网卡,并开启了 VXLAN Offloading,复杂的环境下一些不合理的配置导致流量转发时延过高。通过修改配置,DeepFlow 观测到 KVM 处的时延下降了 80%,有效的保障了整个分布式核心交易系统的顺利上线。
第四类案例,快速定位代码问题:
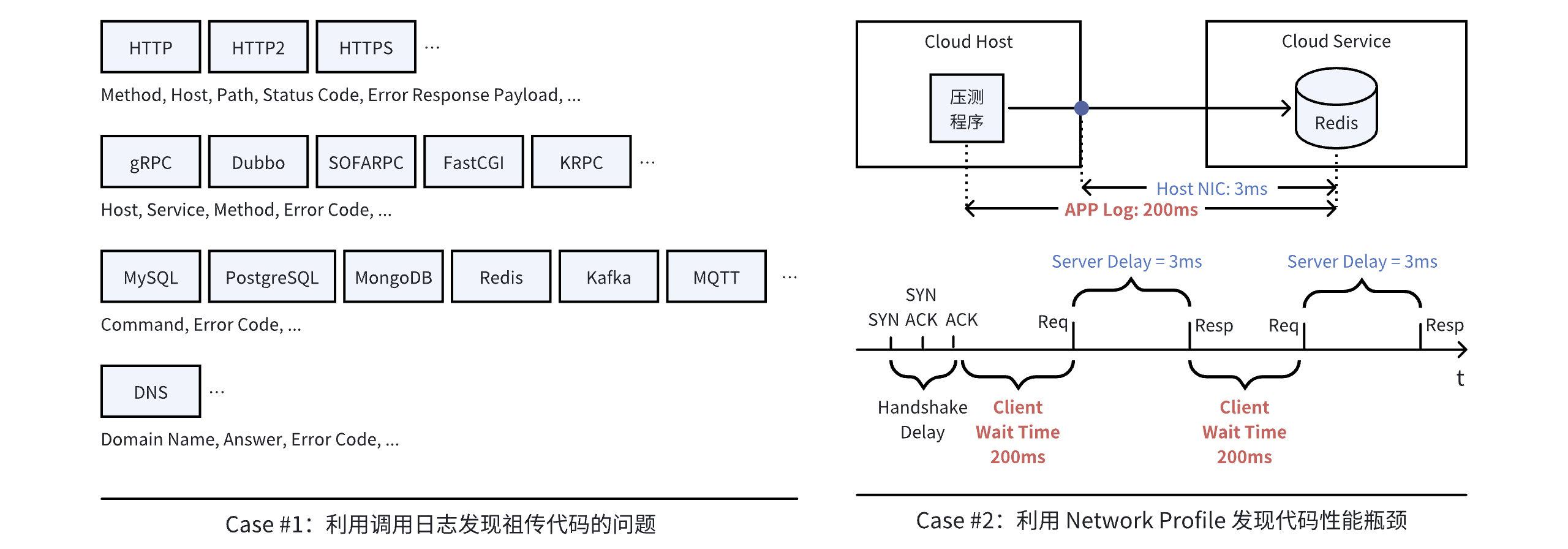
案例 1:利用调用日志发现祖传代码的问题。这里的祖传代码指的是那些开发人员已经离职,或者接手它的开发者已经更换了好几次,又或者是一个外部供应商提供的没有源代码的服务。即使客户想通过插桩的方式提升服务的可观测性,对此类服务也是力不从心。我们的很多客户在部署 DeepFlow 的第一天就能立即发现此类服务的一些问题,例如一个游戏客户发现某个游戏的 Charge API 正在报错,虽然对玩家没有任何影响,但却给公司带来着持续的经济损失。例如一个云服务商的开发团队发现某个服务正在写入一个不存在的数据库表,而这个服务的负责团队已经更换了好几次,它没有造成业务的故障,但却导致了运营数据的错误。
案例 2:利用 Network Profile 发现代码性能瓶颈。在 Linux 内核 4.9 以上的运行环境中,利用 eBPF Profile 定位代码性能瓶颈是一个非常方便的能力。而 DeepFlow 的 Network Profile 在更普遍的内核环境下也能实现一部分效果。例如我们的一个游戏客户在压测 Redis 托管服务时发现压测程序打印的时延高达 200ms,查看 DeepFlow 性能指标后显示主机网卡上观测到的时延只有不到 3ms。压测人员并不是压测程序的编写者,压测程序所在的服务器内核也不具备 eBPF 能力。为了弄清楚原因,压测人员查看通过 cBPF 数据生成的 Network Profile,马上发现了客户端等待时延(Client Wait Time)高达 200ms。这意味着压测程序在两次调用的间隙中花费了太多的时间,这个信息反馈给压测程序的开发团队时对方非常惊喜,立即进行了优化并取得了立杆建议的效果。
本章节介绍的所有案例均为 DeepFlow 客户实际工作中的真实案例,希望能让你更真实的感受 eBPF 技术对可观测性的重要性。
使用 eBPF 技术前的常见疑问
问题一,eBPF Agent 能在多大程度上替代 APM Agent?如果我们仅考虑分布式追踪目的,即使存在跨线程和异步调用,也可在 Wasm Plugin 的加持下,充分利用金融、电信、游戏等典型业务的请求头中的唯一 ID 字段完成追踪,同时 Wasm Plugin 也可用于业务语义的提取,因此使用 eBPF Agent 可完全替代 APM Agent。对于追踪应用内部函数之间调用路径的需求,一般聚焦在对微服务框架、RPC 框架、ORM 框架的追踪,由于这类函数相对标准,我们相信未来可实现基于 Wasm plugin 驱动的 eBPF 动态 Hook,以获取程序内部的 Span 数据。
问题二,eBPF Agent 对内核的要求很高吗?DeepFlow Agent 中超过一半的能力基于内核 2.6+ 的 cBPF 即可实现,当内核达到 4.9+ 时可支持函数性能剖析功能,当内核达到 4.14+ 时可支持 eBPF AutoTracing 以及 SSL/TLS 加密数据采集功能。另外在 Wasm Plugin 的加持下,AutoTracing 并不是强依赖 4.14+ 内核的,通过提取请求中现有的唯一 ID 字段可以在任何 2.6+ 的内核上实现 AutoTracing。
问题三,采集全栈数据是否会占用大量的存储空间?四层网关不会改变一个调用的内容,七层网关一般只会修改一个调用的协议头。因此网络流量中采集到的调用日志可以非常简单,仅包含少部分关联信息和时间戳信息即可,无需保留详细的请求和响应字段。这样计算下来,网络转发路径上采集到的 Span 只会增加很小的存储负担。
问题四,eBPF 能用于实现 RUM 吗?eBPF 并不是一项浏览器上的技术,因此不适用于 Web 侧。eBPF 是一项主机范围的数据采集技术,因此不适合运行在个人移动设备上采集所有 APP 的数据。但对于由企业完全控制的终端系统来讲,eBPF 是有着广泛的应用场景的,例如基于 Linux 或 Andriod 操作系统的 IoT 终端、智能汽车的车载娱乐系统等。
eBPF 对新技术迭代的重大意义
以往 APM Agent 无法实现基础设施的可观测性,使得用户会倾向于追求基础设施的稳定和低频变更,但这必然会导致创新被抑制。因此,基于 eBPF 实现可观测性对新技术的迭代发展有着重大意义。各行各业的创新正在解决业务面临的痛点,人们看到收益之后也会加快对创新的采纳速度,零侵扰的可观测性是对创新速度的有力保障。
云原生基础设施的持续创新:以网关为例,云原生环境下微服务接入的网关数量可能会令你大吃一惊,下面这张漫画非常形象的表达了这个现状。这些网关正在解决着业务上遇到的实际问题,负载均衡器避免了单点故障;API 网关保障了 API 暴露的安全性;微服务网关让同一个业务系统中的前端可以很方便的访问到后端的任意一个微服务;Service Mesh 提供了限流、熔断、路由能力,减少了业务开发的重复工作。纵使不同的网关可能存在能力的交叠,这也是技术发展过程中不可避免的中间态。另外,不同的网关往往由不同的团队负责管理,且管理人员通常没有二次开发能力。若无法实现网关的零侵扰可观测性,对故障排查会带来灾难性的后果。

金融核心交易系统的分布式改造:以往金融业务的核心交易系统是由专用硬件来承载的,不易于扩展迭代且价格昂贵。DeepFlow 的银行、证券、保险客户近两年纷纷开启了核心交易系统的分布式改造,这些系统关系着国计民生,零侵扰的可观测性正是保障这类系统顺利上线的前提。

电信核心网面向服务的架构改造:与金融类似的是,电信核心网以往也是由专用硬件来承载的。然而从 5G 核心网开始,3GPP 已经明确的提出了面向服务的架构(SBA)规范,核心网网元已经拆分为一系列微服务运行在了 K8s 容器环境中。同样,零侵扰的可观测性也是保障电信核心业务系统顺利上线的前提。
智能网联汽车的发展:智能汽车网络由中心云、边缘云(工厂/园区)、终端(车载系统)组成。为了给用户带来持续更新的软件体验,整个智能汽车网络中的服务均采用微服务架构、云原生部署。一个具备可观测性的基础设施同样也是这张大网持续迭代的前提。

对 AIOps 发展的重要意义:以往,AIOps 方案落地之前,观测数据(通常是指标和日志)需要进行集中和清洗。这是一个漫长的过程,通常耗时数月都难以完成。eBPF 有望对这一现状进行根本上的改变,由于 eBPF 采集的数据覆盖了所有服务、具有高度一致的标签信息和数据格式,将会极大降低 AIOps 解决方案的落地门槛。
总结
APM Agent 由于其侵扰性,难以在金融、电信、电力等行业的核心业务系统中落地,难以在云原生基础设施中插桩。eBPF 的零侵扰优势很好的解决了这些痛点,是云原生时代实现可观测性的关键技术。DeepFlow 基于 eBPF 的全景图、分布式追踪、持续性能剖析能力已服务于各行各业,帮助金融行业的分布式核心交易系统、电信行业的 5G 核心网、能源行业的分布式电力交易系统、智能网联汽车、云原生游戏服务等快速实现了零侵扰的可观测性,保障了新一代业务和基础设施的持续创新。

作者介绍:
向阳,清华大学博士,云杉网络研发 VP,曾获网络测量领域国际顶会 ACM IMC 颁发的第一届 Community Contribution Award,现负责云原生可观测性产品 DeepFlow。产品基于 eBPF 等新技术帮助云原生应用快速实现零侵扰、全栈的可观测性,相关论文被通信领域国际顶会 ACM SIGCOMM 2023 主会录用。




