今年 11.11,京东数据中心操作系统(JDOS)阿基米德已经全面接管了应用资源调度。每日调度百万台容器实例运转,每日为离线计算提供了多达 3000 万核·小时的计算资源,SLA 履约率达到 98.3%。在保证业务的正常运行下,集群的平均资源利用率提升 3 倍。仅在 11.11 备战期间,通过资源调度节省数亿元服务器采购成本。本文对京东阿基米德项目的架构和核心技术进行分享,希望能为业界提供一些参考。
另外,由 InfoQ 举办的 ArchSummit 全球架构师峰会即将于 12 月 8-11 日北京举行,大会与阿里巴巴合作策划了双 11 架构专场,并邀请了顶级技术专家担任出品人,设置了“新一代 DevOps”、“人工智能与业务应用”、“架构升级与优化”等 17 个热门话题,目前大会日程已出,欢迎前来讨论交流。
调度困境
JDOS(Jingdong Datacenter Operating System) 2.0 于 2016 年推出,基于 kubernetes 进行了深度定制,并在国内率先将 kubernetes 引入大规模生产环境,经历了 2017 年 618 的考验,逐步完善了内核、网络、存储、监控、镜像中心等生态建设后,调度系统的优化逐渐提上了日程。在长期的容器运营过程中,团队积累了大量的监控数据,也发现了很多痛点。
- 京东有大量的服务器资源,而资源使用不够充分。
- 在大促前各个业务主要靠新增机器来应对高峰瞬时流量。
- 应用业务系统资源申请量和使用量之间差距巨大。
- 资源使用呈现明显的高峰低谷,不同的机器的资源使用率差距较大。
- 资源碎片导致的资源浪费严重。
对于以上种种问题,简单的调度分配资源算法已经无法满足复杂的调度需求,阿基米德项目应运而生。阿基米德项目是作为 JDOS 的核心调度组件,是撬动整个数据中心的支点,负责整个京东数据中心的资源调度与驱逐。
(点击放大图像)

应用画像
应用对于资源的使用存在一定的规律。一般常规的做法是将其对于资源使用的特点,分为计算密集型、内存密集型、存储密集型等。这种简单的做法无法从CPU/ 内存/ 存储/ 网络多个资源维度和时间维度上对于资源的使用进行描述。我们采用了强化机器学习算法,根据应用的历史数据,提取其资源使用的特征,进而将不同的应用进行归类,形成应用画像。
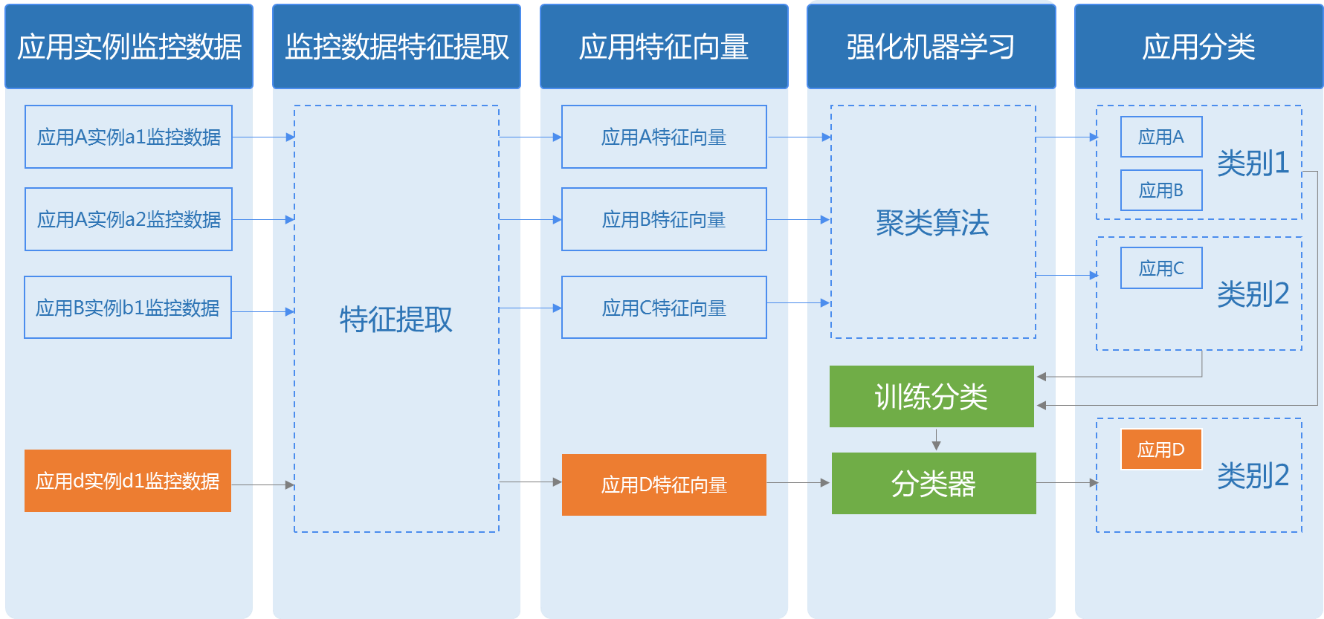
应用画像可以为调度提供依据。不同的应用根据应用画像的结果,进行亲和/ 反亲和的调度,将不同类的应用容器调度在一起,使其资源需求得到时空互补,而不会相互影响。同时对于一个应用中多个容器,可以依据应用画像对容器的健康状态进行评估预警,及早进行容器的自动扩容或者迁移,以免影响业务。另外,应用画像还为之后应用的资源使用提出指导意见,以便其在保证资源使用的同时,防止资源超配导致的浪费。
Serverless 与延迟容忍
在以往的技术架构中,大量的业务应用属于长期服务 (long-running services),其特点是需要长时间提供服务。而实际上,许多应用并不需要长期提供服务。以图片转换应用为例,商户上传的商品图片需要转换成多种尺寸,并在图片中打上水印 /logo 等,并上传到存储中。图片转换应用只需要在用户上传图片时提供服务,其他时间并不需要占用资源;而且应用对于延迟不敏感,允许最长几十秒级别的延迟执行。对于这种事件驱动、延迟容忍的应用,我们推动其由长期服务,转向使用 JDOS 提供的 serverless 架构。serverless 的架构在将长期服务转为离线计算任务方面发挥了巨大的作用。
serverless 的应用任务和大数据的离线计算任务,抽象为统一的批处理任务 (batch jobs)。批处理任务提交到阿基米德时,需要提供任务描述,描述内容包括任务函数、任务类型、资源描述以及任务的延迟容忍时间等,由阿基米德进行调度执行。延迟容忍时间是指该任务可以容忍的最长延迟执行时间。也就是说任务提交后不必立即执行,可以容忍一定时间后才获得资源执行,这就为阿基米德的调度规划提供了重要依据,以便其提前进行流水线编排规划。
资源碎片与时空复用
不同批次采购的服务器的资源配比不同,而不同的应用申请的资源配比也不同。基于资源适配的调度算法容易导致一台服务器上的 CPU 的配额已经分配完毕,但是内存还空余几十 GB 或者内存分配完毕,CPU 还空余几核。这种情况我们称之为资源碎片。
资源碎片在几乎每台物理机上都有发生。长期服务,特别是面向用户的任务,在每天的执行中会出现明显的高峰低谷。而且不同的长期服务的资源消耗也不同。因此集群中的时空资源利用率不均是常态。资源碎片和时空分布不均问题造成了巨额的资源浪费。
我们倾向于长期服务稳定存在,尽量低频度迁移。因此对于资源碎片和时空不均的情况,阿基米德采用批处理任务进行统一填充式调度,以达到资源碎片的充分利用和资源的时空复用的效果。阿基米德不仅仅可以对当前的资源和任务进行调度,还可以综合应用画像和批处理任务的描述,对未来一段时间的任务调度进行提前规划,使得业务能够正常运行的同时,资源得到充分的利用,有效防止了批处理任务与长期服务的资源竞争。阿基米德会时刻保持一定的资源 buffer 应对突发流量的资源需求。
SLA
无论是长期服务还是批处理任务,均会与阿基米德签订 SLA 协议。阿基米德将会保证服务或者任务的资源使用量、服务可用性等。特别是长期服务,阿基米德将会优先保证其资源使用和服务可用。在批处理任务与长期服务、长期服务与长期服务即将出现资源竞争时,阿基米德会根据 SLA 协议的可用性和优先级进行筛选排序,依序对于任务或者服务进行驱逐迁移,保证高优先级的长期服务能够优先使用资源,非必要情况不进行迁移,不受其他任务 / 服务的资源竞争影响。
集群自治
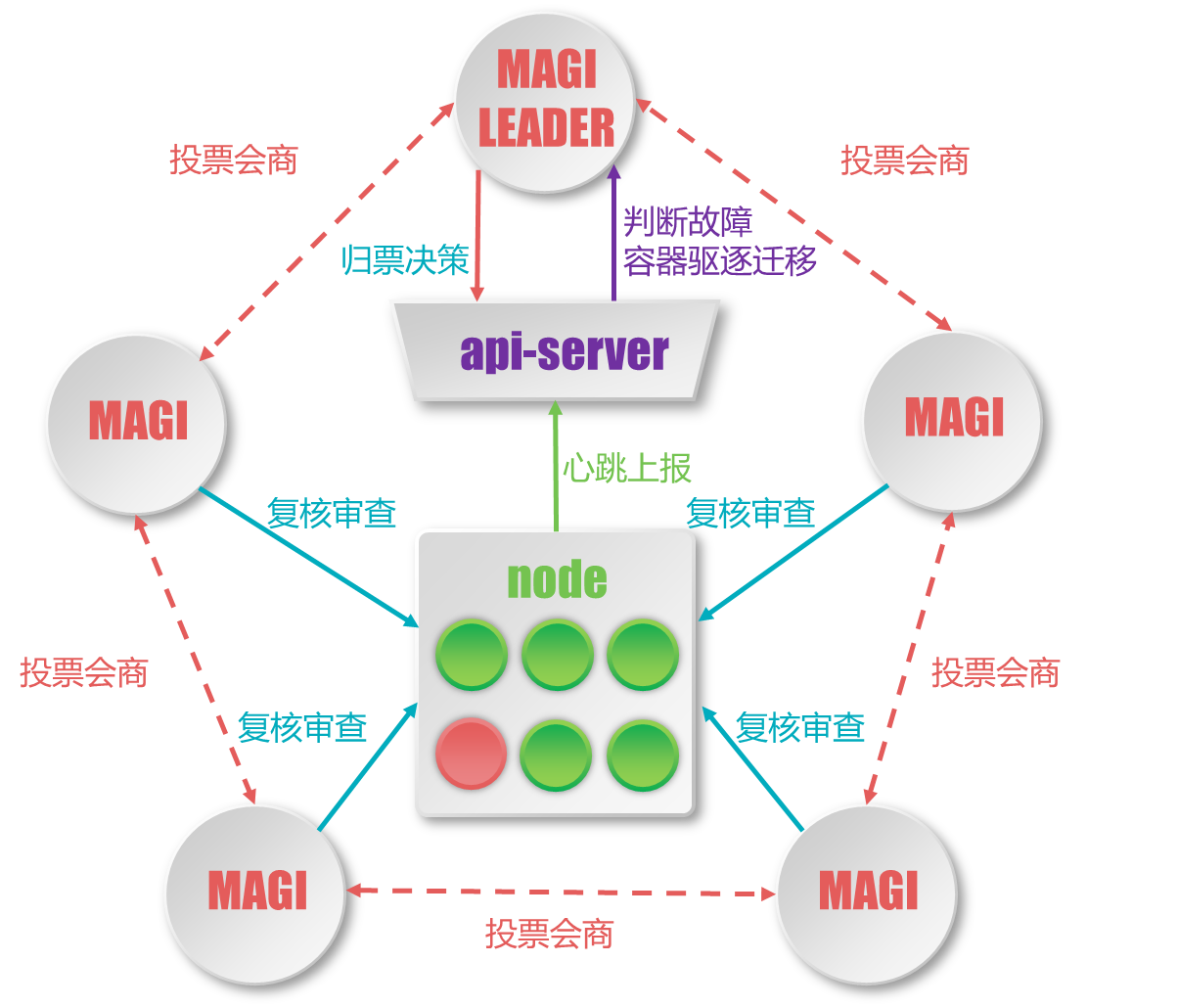
JDOS 提供了集群的自动化管理,阿基米德则将集群从自动化转为了自治的管理系统。社区的 kube-controller 提供了一个控制器的范例,但是存在着诸多弊端,比如 controller 获取的信息量过少,只能从 apiserver 获取 node 状态,无法准确判断 node 节点是否离线,从而导致误判,致使容器发生频繁迁移。因此阿基米德中扩展了 controller,成为一个单独的系统 MAGI。MAGI 共有五个节点,分布在数据中心的不同物理 POD 内。MAGI 系统负责集群的自治决策,采用投票会商制,用以对节点是否离线、容器是否需要迁移等决策进行复核。经 MAGI 系统归票决策后,才会实际触发节点的离线摘除和容器的迁移。
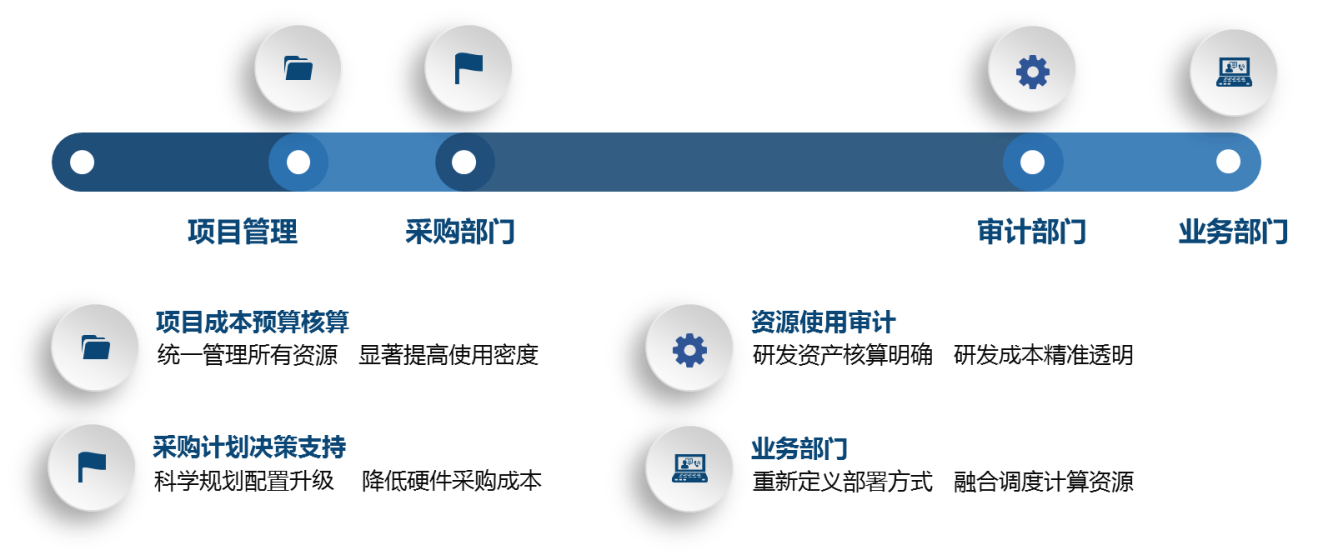
不止于调度
阿基米德不仅仅是 JDOS 的调度系统,更是应用资源使用情况的数据分析平台。阿基米德为项目管理、业务、审计、采购等部门的相关工作,提供了直接的数据支持。
机房的主要电力消耗用于制冷,而制冷的主要目的是为 CPU 降温。阿基米德会根据应用画像与调度规划,对于服务器的 CPU 的主频进行相应调整,以达到节能降耗的作用。此功能已在 2 个核心机房进行了大规模的实践,取得了降低 17% 电力的成果。
在 2018 年,我们将进一步推动优化调度算法,精确应用画像,提升调度的准确性,在整合计算、提升效率、节能降耗方面进行更多的实践。届时也将把更多的生产一线的调度数据和模型与业界分享。
作者介绍
鲍永成,京东商城研发体系 - 基础平台部技术总监。2013 年加入京东商城研发体系,负责京东容器平台 JDOS 研发,带领团队完成京东容器大规模战略项目落地,有效支撑京东日常业务系统运行和大促高峰流量。目前聚焦在京东 JDOS 阿基米德战略项目和敏捷智能数据中心等方向。
感谢蔡芳芳对本文的策划。




